”JAVA爬虫初识之模拟登录_周无缺啊的博客-程序员宅基地“ 的搜索结果




为什么要模拟登陆 Python网络爬虫应用十分广泛,但是有些网页需要用户登陆后才能获取到信息,所以我们的爬虫需要模拟用户的登陆行为,在登陆以后保存登陆信息,以便... 保存用户信息 ...# 导入requests模块...
import urllib.request weburl = "https://www.douban.com/" webheader = { 'Accept': 'text/html, application/xhtml+xml, */*', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN',


注:对代码及思路进行了改进—Java网络爬虫(十一)–重构定时爬取以及IP代理池(多线程+Redis+代码优化) 定点爬取 当我们需要对金融行业的股票信息进行爬取的时候,由于股票的价格是一直在变化的,我们不可能...





SeimiAgentDemo.java 分析原网页代码 Boot.java 同系列文章 准备工作 新手的话推荐使用seimiagent+seimicrawler的爬取方式,非常容易上手,轻松爬取动态网页,目测初步上手10分钟以内...

1、环境准备工作 ...环境上需要准备java、selenium和chrome浏览器及对应的chrmoedriver(也可以使用firefox等浏览器,需要另外进行简单的配置),mac os下selenium+chrome的环境准备可以参见我的另一篇博客:http:
但是,按照常规的爬取方法是不可行的,因为数据是分页的:最关键的是,不管是第几页,浏览器地址栏都是不变的,所以每次爬虫只能爬取第一页数据。为了获取新数据的信息,点击F12,查看页面源代码,可以发现数据是...
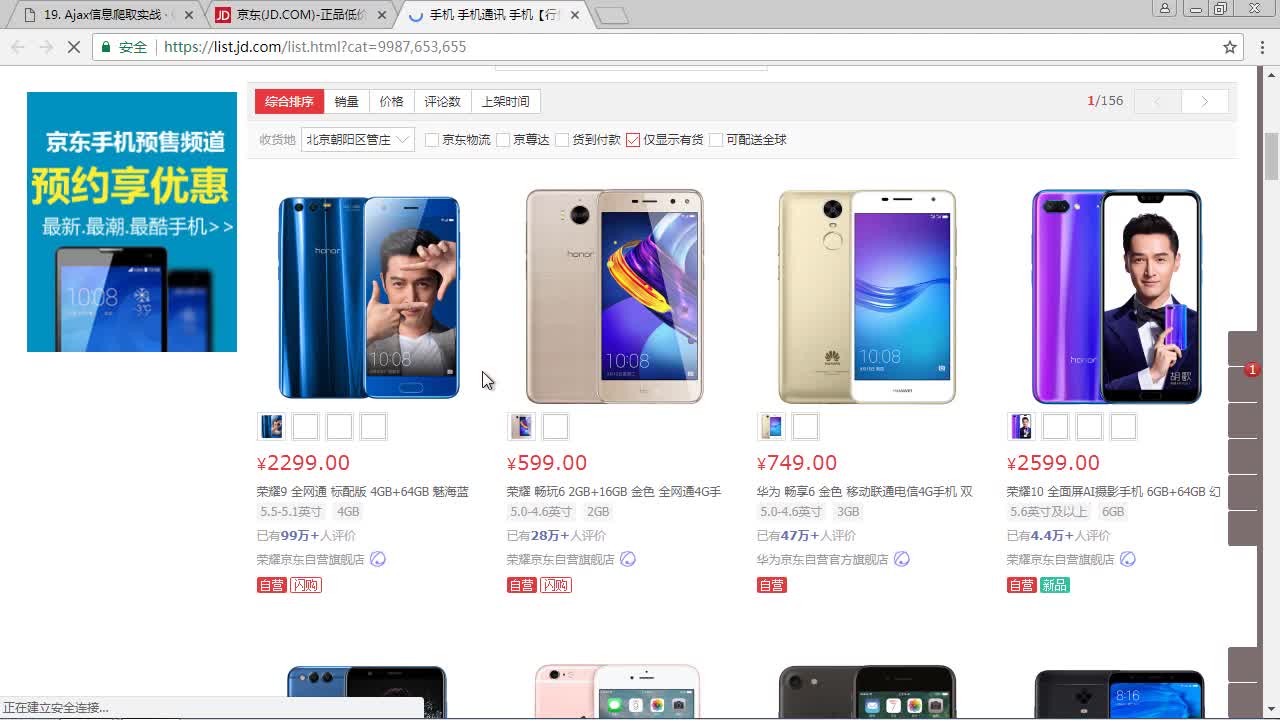
业务背景 大家在平时的生活或工作种多少都会遇到类似下面的情况吧 非技术人员: 我身边有同学在一家装修设计公司上班,她每天...比如我喜欢看一些技术帖子(微信公总号,技术博客等),有时候会觉得文章中的一些...
Python 爬虫实战,模拟登陆爬去数据 从0记录爬取某网站上的资源连接: 模拟登陆 爬取数据 保存到本地 结果演示: 源网站展示: 爬到的本地文件展示: 环境准备: python环境安装 略 安装requests库 使用以下...
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所有对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrapy,人民邮电出版社 基础...
提取,编辑和轻松评估XPath查询。 XPath的助手很容易提取,编辑,并在任何网页评估XPath查询。 重要提示:安装此扩展后,必须重新加载任何现有的选项卡或重新启动Chrome浏览器扩展工作。 说明: ...


推荐文章
- html 保存成word (富文本编辑器导出内容成word)_wangeditor导出word-程序员宅基地
- 认识YOLOv5模型结构目录_yolo的框架在哪个文件-程序员宅基地
- jeecg-boot安装和使用(入门)_jeecgboot-程序员宅基地
- 转载:不是所有DDR3都可以用Fly by结构_ddr3 fly_by拓扑之应用实例-程序员宅基地
- pads铺铜不能开启drp_PADS中常见问题解决方案-程序员宅基地
- android oppo 权限,OPPO Reno可尝鲜Android Q:教程如下-程序员宅基地
- MYGUI/CEGUI中文输入的问题(3)-程序员宅基地
- c++实现对内存泄露的检测——windowns以及ubuntu下_clion 内存泄漏-程序员宅基地
- 华为交换机 配置练习2 trunk_适合练习用的华为交换机-程序员宅基地
- java.lang.ClassNotFoundException: org.springframework.web.context.ContextLoa解决方案-程序员宅基地