Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。 Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以...
”Impala与Hive的比较“ 的搜索结果
基于Hive,使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。 是CDH平台首选的PB级大数据实时查询分析引擎。 Impala的优缺点 优点 基于内存运算,不需要把中间结果写入磁盘,省掉了大量的I/O开销...
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由QueryPlanner、Query...
把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。...
与MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的...
Impala简介 Impala是由Cloudera公司开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase上的PB级...Impala采用了与商用并行关系数据库类似的分布式查询引擎,可以直接与HDFS和HBase进行交互查询...
由cloudera公司主导开发的大数据实时查询分析工具,宣称比原来基于MapReduce的HiveSQL查询速度提升3~90倍,且更加灵活易用。提供类SQL的查询语句,能够查询存储在Hadoop的HDFS和Hbase中的PB级大数据。查询速度快是...
Impala与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在...
把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。...
状态管理进程,定时检查The Impala Daemon的健康状况,协调各个运行Impalad的实例之间的信息关系,Impala正是通过这些信息去定位查询请求所要的数据,进程名叫作 statestored,在集群中只需要启动一个这样的进程,...
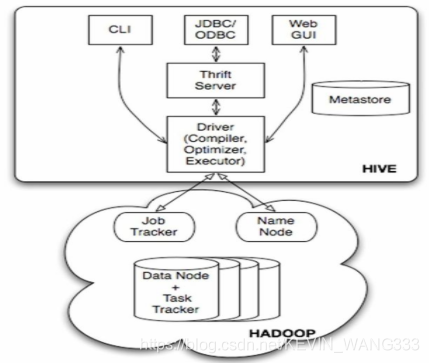
Hive 和 Impala的异同 Hive是一个建立在APACHE HADOOP之上的数据仓库软件项目,由Jeff在Facebook的团队开发,目前已经发布了2.3.0的稳定版本。它被用于总结大数据,使查询和分析变得容易。Apache Hive是SQL-in ...
一直在网上找不到impalajdbc的pom依赖,项目是maven的,所以整理了所用的pom
在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与Impala的设计有关,因为Impala定位于实时查询,一次查询失败,再查一次就好了,再查一次的成本很低)。但从整体来看,Impala是能很好的...
Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。8.使用Impala,您可以访问存储在...
最近读的几篇关于impala的文章,这篇良心不错:https://www.biaodianfu.com/impala.html(本文截取部分内容) &n...
状态管理进程,定时检查The Impala Daemon的健康状况,协调各个运行Impalad的实例之间的信息关系,Impala正是通过这些信息去定位查询请求所要的数据,进程名叫作 statestored,在集群中只需要启动一个这样的进程,...
把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。...
impala Impala的优缺点 优点 基于内存运算,不需要把中间结果写入磁盘,省掉了大量的I/O开销。 无需转换为Mapreduce,直接访问存储在HDFS,...对内存的依赖大,且完全依赖于hive。 实践中,分区超过1万,性能严..

与MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的...
把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。...
impala与hive的区别1
标签: hive
2、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率 3、充分利用可用的硬件指令(SSE4.2)
impala同步hive数据
标签: impala
impal同步 #bin/sh set -e shopt -s expand_aliases #这里是可以在shell里面用重命名 .~/.bash_profiles typeset -u sub_part_flag #把变量转换成大写 # typeset的-l选项将一...dw_hdfs_path="/user/hive/warehouse" if
1、通过亿级数据量在hive和impala中查询比较text、orc和parquet性能表现(一) 网址:https://blog.csdn.net/chenwewi520feng/article/details/130465139 本文通过在hdfs中三种不同数据格式文件存储相同数量的数据,...
1、通过亿级数据量在hive和impala中查询比较text、orc和parquet性能表现(二) 网址:https://blog.csdn.net/chenwewi520feng/article/details/130465463 本文通过在hdfs中三种不同数据格式文件存储相同数量的数据,...
最近读的几篇关于impala的文章,这篇良心不错:https://www.biaodianfu.com/impala.html(本文截取部分内容) Impala是Cloudera...已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引...
Impala与HBase整合 impala可以通过Hive外部表的方式和Hbase进行整合 -步骤一:创建HBASE表,添加数据 create 'test_info','info'; put 'test_info','1','info:name','similarFish'; put 'test_info','2','info:...
Impala与hive对比
标签: Impala
其架构如图1所示Impala主要由ImpaladStateStore和CLI组成。同时Impalad也与StateStore保持连接用于确定哪个Impalad是健康和可以接受新的工作。
一.原理 ...采用了impala库查询,将查询到的结果存储到本地mysql数据库中。 重点:impala库安装 pip安装依赖: thrift thriftpy thrift_sasl pure_sasl impyla bitarray 开启hadoop集群 start-all...
推荐文章
- Pytorch Dataloader 模块源码分析(二):Sampler / Fetcher 组件及 Dataloader 核心代码-程序员宅基地
- Asp类型判断及数组打印-程序员宅基地
- Adroid Studio 2022.3.1 版本配置greendao提示无法找到_plugin with id 'org.greenrobot.greendao' not found-程序员宅基地
- esxi查看许可过期_解决Vsphere Client 60天过期问题-程序员宅基地
- CMake_cmake_module_path-程序员宅基地
- 生产者消费者模型-程序员宅基地
- Adaptive AUTOSAR 解决方案 INTEWORK-EAS-AP_autosar的eas-程序员宅基地
- 穿山甲SDK错误码40025_穿山甲sdk错误码4025-程序员宅基地
- css firefox下的兼容问题_css 只用于firefox-程序员宅基地
- 【Python】对大数质因数分解的算法问题_python分解多个质因数代码-程序员宅基地