”Hadoop能做什么“ 的搜索结果
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,...

今天突然想到这个问题 但网上都是些复制粘贴的内容 不能很好地解答 经过查找资料 我在这里给出我的说明 仅供参考: 尽管Spark相对于Hadoop而言具有较大优势(速度快),但Spark并不能完全替代Hadoop,主要用于...
Hadoop常用端口号
标签: hadoop
Hadoop常用端口号
1、启动Hadoop提示WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable 在/etc/profile中添加 export HADOOP_OPTS="$HADOOP_OPTS...
Hadoop实现单词计数
标签: hadoop

解决Cannot execute /home/hadoop/libexec/hadoop-config.sh.的方法
#!/bin/bash # 判断参数个数 if [ $# -ne 1 ];then echo "need one param, but given $#" fi # 操作hadoop case $1 in ... echo " ========== 启动... ssh node1 "/develop/server/hadoop-2.7.5/sbin/start-dfs.sh.

1、Hadoop各目录说明 文件夹名称 作用 bin 存放对hadoop相关服务(HDFS,YARN)进行操作的脚本 sbin 存放启动或停止hadoop相关服务的脚本 etc hadoop的配置文件目录,存放hadoop的配置文件 lib 存放...


1.ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode. 2.云服务器启动hadoop,namenode没启动起来 3.Failed to start namenode,Directory /tmp/hadoop-root/dfs/name is in an ...
命令基本格式:hadoop fs -cmd < args >1.lshadoop fs -ls /列出hdfs文件系统根目录下的目录和文件hadoop fs -ls -R /列出hdfs文件系统所有的目录和文件2.puthadoop fs -put < local file > < hdfs ...
Hadoop Spark 类型 基础平台,包含计算、存储、调度 分布式计算工具 场景 大规模数据集上的批处理 迭代计算,交互式计算,流计算 价格 对机器要求低,便宜 对内存有要求,相对较贵 编程范式 Map+Reduce,...
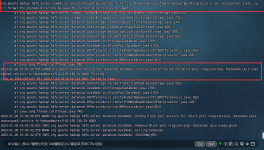
云服务器搭建Hadoop集群一、配置服务器1. 创建普通用户2. 安装 Java 环境3.安装hadoop4.网络配置5.hadoop配置 一、配置服务器 1. 创建普通用户 说明:由于 root 环境下操作比较危险,所以这里新建一个普通用户来...



代码】Hadoop创建目录。
Linux安装hadoop-配置Hadoop环境变量 一、安装Hadoop 进入到Hadoop安装包路径下cd /opt/software/ 解压安装文件到/opt/module下面tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ 二、配置环境变量 修改配置文件...
Hadoop-2.8.3,winutils-2.8.3。 1,下载Hadoop发布的稳定包:https://archive.apache.org/dist/hadoop/common/ 下载后把文件解压,如图: 本文基于Hadoop版本hadoop-2.8.3 2,当前电脑要安装有java的jdk...

Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或者存储出现故障,也不会导致数据的丢失。 2. 高扩展性: 在集群间分配任务数据,可方便的扩展数以千计的节点。 3. 高效性: 在MapReduce的思想下,...

sbin/start-dfs.sh 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode、DataNode。sbin/stop-dfs.sh 停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode。sbin/hadoop-daemons.sh start namenode ...
推荐文章
- Pytorch学习笔记09——多分类问题_pytorch normalize mean, std-程序员宅基地
- 学习open62541 --- [15] 使用建模工具UaModeler-程序员宅基地
- Linux里的防火墙:netfilter简介与Iptables的使用(上)_netfilter (policy drop)-程序员宅基地
- 你了解 JDK 8 Stream 数据流效率吗?千万级数据量性能如何?-程序员宅基地
- 2023最新软件测试学习思维导图(从小白到大师进阶之路)_测试进阶路线图-程序员宅基地
- Zabbix监控系统与部署Zabbix5.0监控(系列操作完整版)-程序员宅基地
- 在MyEclipse中将项目部署Tomcat_myeclipse部署web项目到tomcat-程序员宅基地
- Linux系统部署可视化数据多维表格APITable并实现无公网IP远程协同办公-程序员宅基地
- FFMPEG 最简滤镜filter使用实例(实现视频缩放,裁剪,水印等)_filters_descr-程序员宅基地
- C++ vector容器的常用用法_c++ vector修改数据可以直接赋值吗-程序员宅基地