在PyTorch中使用多个GPU进行模型训练时,各个参数和指标之间存在一定的关系。GPU显存是限制模型训练规模的关键因素。当使用多个GPU进行训练时,每个GPU都会分配一部分显存用于存储中间变量、梯度、权重等。GPU显存的...
”GPU利用率提升“ 的搜索结果
- 三进程异步协作:分词、模型推理、去分词异步进行,GPU利用率大幅提升。 - Nopad (Unpad):提供跨多个模型的nopad注意力操作支持,以有效处理长度差异较大的请求 - Dynamic Batch: 启用请求的动态批处理调度- ...



答:能否启用 GDRDMA 和 NCCL 版本有关,经测试,使用 PyTorch1.7(自带 NCCL2.7.8)时,启动 GDRDMA 失败,和 Nvidia 的人沟通后确定是 NCCL 高版本的 bug,暂时使用的运行注入的方式来修复;优化:a、设置 tf.data...
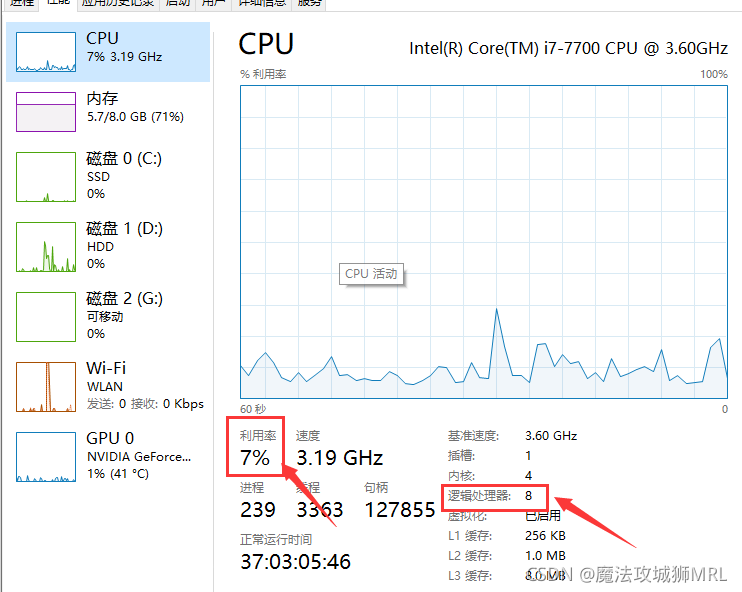
pytorch跑Unet代码,gpu利用率在0%-20%闪现,主要问题是GPU一直在等cpu处理的数据传输过去。利用top查看cup的利用率也是从0省道100%且显然cup的线程并不多,能处理出的数据也不多。在一般的程序中,除了加载从...
尤其是苦恼于GPU显存都塞满了利用率却上不去的童鞋,这篇文章或许可以给你打开新世界的大门噢( ̄∇ ̄) 如果发现经过一系列改良后训练效率大大提高了,记得回来给小夕发小红包( ̄∇ ̄) 不过,这并不是一篇怒贴一堆...
在torch框架下,GPU显存的合理利用方式。
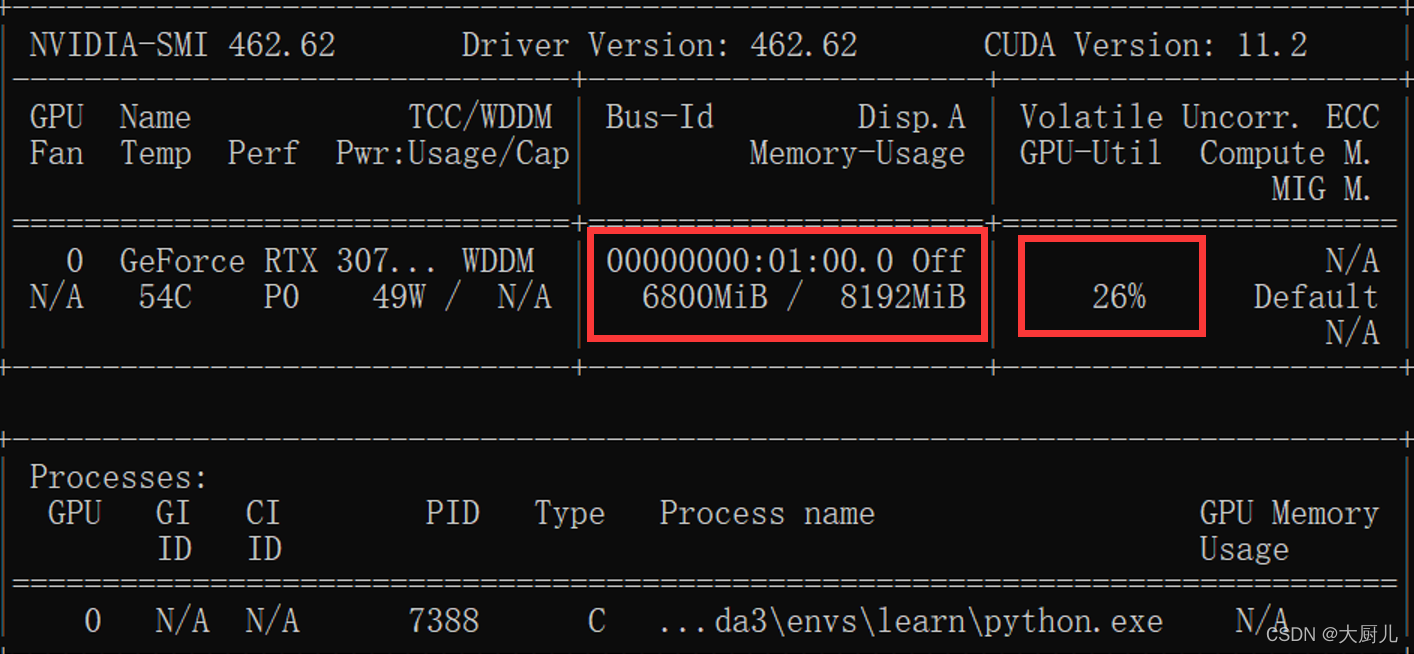




首先就一笔带过说一下GPU的重要性吧,以Pytorch为例,就是使用CUDA,cuDNN对深度学习的模型推理时执行的各种计算转换为矩阵乘法进行加速,来达到从猴年马月的运行,到现在几十成百倍的提速。 至于我们爱之深恨之切的...
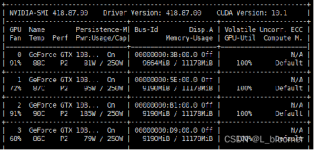
上周,在一个使用Pytorch搭建的目标训练项目中,训练时,通过使用命令行执行NVIDIA-SMI(仅支持英伟达显卡)命令发现GPU的利用率基本一直停留在0%,并且显存占用率也较低。CSDN上有一篇分析比较好的博文,我将其中与...
使用tensorflow2.0进行cifar100数据集的图像分类时发现GPU的使用率始终不高,且波动较大,在网上查询资料后尝试从数据处理和使用@tf.function图执行模式入手,其中模型结构使用ResNet18,电脑配置显卡为2070super,...
记录下跑深度学习遇到的问题:模型跑的很慢,GPU利用率低

点击左上方蓝字关注我们在深度学习的产业应用中,千万不要认为炼制出神丹就万事大吉了,企业还需要面临一个挑战,那就是大规模推理部署。对工业级部署而言,要求的条件往往非常繁多且苛刻,模型大小、业...
data,label = data.cuda(),label.cuda() model.cuda()
最近在训练SSD模型时发现GPU的利用率只有8%,而CPU的利用率却非常高。 后来了解到,一般使用CPU进行数据的读取和预处理,而使用GPU进行模型的正向传播和反向传播。由于CPU数据读取跟不上(读到内存+多线程+二进制...
https://blog.csdn.net/qq_24407657/article/details/103992170 真是节省了我这种小白很多时间,谢谢这篇文章
关于GPU利用率低的一种可能
标签: RL
本人用STABLE_BASELINES3里面的算法进行实验,结果发现GPU利用率一直很低,只会偶尔高一下然后又下去,原来是我的算法写的有问题,采样时间非常的长,智能体会受限于采样时间。关闭一切可能的IO操作!
推荐文章
- 小说网站系统源码|PHP付费小说网站源码带app-程序员宅基地
- Swift编码规范_swift 正则判断文件类型-程序员宅基地
- 关于shell 中return用法解释(转)_shell return-程序员宅基地
- Linux编译宏BUILD_BUG_ON_ZERO-程序员宅基地
- c51语言单片机打铃系统设计,基于单片机的自动打铃系统的设计-程序员宅基地
- 在php中使用SMTP通过密抄批量发送邮件-程序员宅基地
- python数据清洗+数据可视化_python课程题目数据清除与可视化-程序员宅基地
- 【11g】3.3 Oracle自动存储管理存储配置_oraclestorageoptions-程序员宅基地
- signature=b2f9171fa2897cefe08a669efaf58433,FULFILLMENT TRACKING IN ASSET-DRIVEN WORKFLOW MODELING-程序员宅基地
- 宜兴市计算机中等学校,重磅!江苏省陶都中等专业学校正式揭牌!-程序员宅基地