深度学习(9)之 easyOCR使用详解-程序员宅基地
技术标签: python 计算机视觉 深度学习 人工智能 # 深度学习 OCR
easyOCR使用详解
- 本文在 OCR-easyocr初识 基础上进行修改
- EasyOCR 是一个python版的文字识别工具。目前支持80中语言的识别。其对应的 github 地址:EasyOCR
- 可以在网站版测试 demo 测试效果:https://www.jaided.ai/easyocr/
- 其在字符识别上的效果如下:

一、介绍
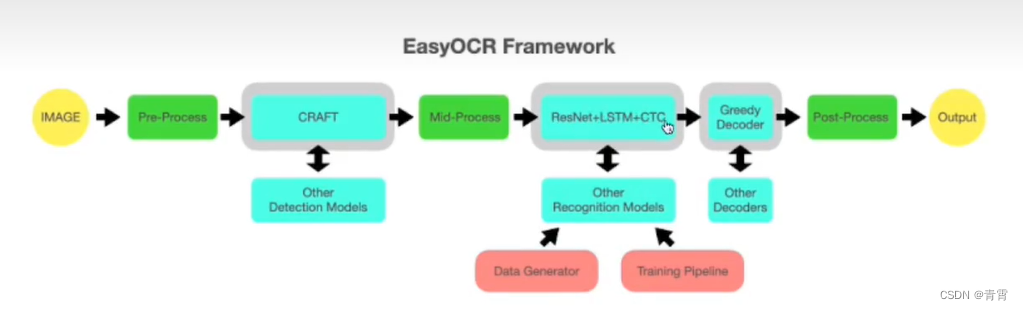
二、安装
- Install using pip
For the latest stable release:
pip install easyocr
For the latest development release:
pip install git+https://github.com/JaidedAI/EasyOCR.git
- 模型储存路径:
windows: C:\Users\username\.EasyOCR\linux:/root/.EasyOCR/
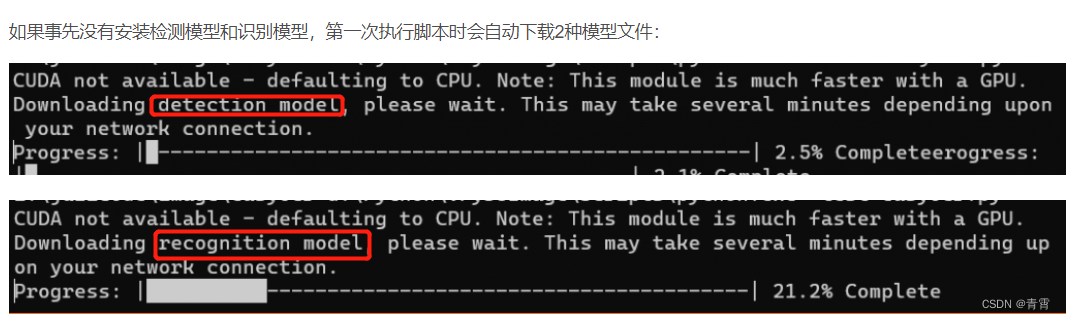

三、API文档
3.1、easyocr.Reader class:
-
lang_list (list) - 识别的语言代码列表,例如 ['ch_sim','en']
-
gpu (bool, string, default = True) - 启用 GPU
-
model_storage_directory (string, default = None) - 模型数据目录的路径。如果未指定,将从环境变量 EASYOCR_MODULE_PATH(首选)、MODULE_PATH(如果已定义)或 ~/.EasyOCR/ 定义的目录中读取模型。
-
download_enabled (bool, default = True) - 如果 EasyOCR 无法找到模型文件,则启用下载;
-
user_network_directory (bool, default = None) - 用户模型存储的路径。如果未指定,将从 MODULE_PATH + '/user_network' (~/.EasyOCR/user_network) 读取模型;
-
recog_network (string, default = 'standard') - 用户模型、模块和配置文件的名称;
-
detector (bool, default = True) - 将检测模型加载到内存中
-
recognizer (bool, default = True) - 将识别模型加载到内存中
-
lang_char - 显示当前模型中的所有可用字符
3.2、reader.readtext()
-
image (string, numpy array, byte) - 输入图像;
-
decoder (string, default = 'greedy')- 选项有 'greedy'、'beamsearch' 和 'wordbeamsearch';
-
beamWidth (int, default = 5) - 当解码器 = 'beamsearch' 或 'wordbeamsearch' 时要保留多少光束;
-
batch_size (int, default = 1) - batch_size>1 将使 EasyOCR 更快但使用更多内存;
-
worker (int, default = 0) - 数据加载器中使用的编号线程;
-
allowlist (string) - 强制 EasyOCR 只识别字符的子集。对特定问题有用(例如车牌等);
-
blocklist (string) - 字符的块子集。如果给定了允许列表,则此参数将被忽略。
-
detail (int, default = 1) - 将此设置为 0 以进行简单输出;
-
paragraph (bool, default = False) - 将结果合并到段落中;
-
min_size (int, default = 10) - 过滤文本框小于最小值(以像素为单位);
-
rotation_info (list, default = None) - 允许 EasyOCR 旋转每个文本框并返回具有最佳置信度分数的文本框。符合条件的值为 90、180 和 270。例如,对所有可能的文本方向尝试 [90, 180 ,270]。
-
contrast_ths (float, default = 0.1) - 对比度低于此值的文本框将被传入模型 2 次。首先是原始图像,其次是对比度调整为“adjust_contrast”值。结果将返回具有更高置信度的那个;
-
adjust_contrast (float, default = 0.5) - 低对比度文本框的目标对比度级别。
-
text_threshold (float, default = 0.7) - 文本置信度阈值
-
low_text (float, default = 0.4) - 文本下限分数
-
link_threshold (float, default = 0.4) - 链接置信度阈值
-
canvas_size (int, default = 2560) - 最大图像尺寸。大于此值的图像将被缩小。
-
mag_ratio (float, default = 1) - 图像放大率
-
slope_ths (float, default = 0.1) - 考虑合并的最大斜率 (delta y/delta x)。低值意味着不会合并平铺框。
-
ycenter_ths (float, default = 0.5) - y 方向的最大偏移。不应该合并不同级别的框。
-
height_ths (float, default = 0.5) - 盒子高度的最大差异。不应合并文本大小非常不同的框。
-
width_ths (float, default = 0.5) - 合并框的最大水平距离。
-
add_margin (float, default = 0.1) - 将边界框向所有方向扩展某个值。这对于具有复杂脚本的语言(例如泰语)很重要。
-
x_ths (float, default = 1.0) - 当段落=True 时合并文本框的最大水平距离。
-
y_ths (float, default = 0.5) - 当段落 = True 时合并文本框的最大垂直距离。
四、识别模型
 https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md
https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md4.1、训练识别模型
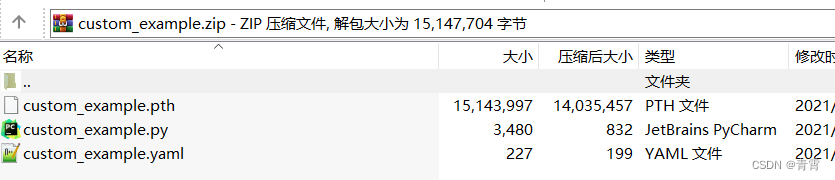
4.2、使用自定义的识别模型
五、使用
5.1、基本使用1
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True
5.2、基本使用2

代码实现如下:
import easyocr
reader = easyocr.Reader(
lang_list=['ch_sim', 'en'], # 需要导入的语言识别模型,可以传入多个语言模型,其中英语模型en可以与其他语言共同使用
gpu=False, # 默认为True
download_enabled=True # 默认为True,如果 EasyOCR 无法找到模型文件,则启用下载
)
result = reader.readtext('id_card.jpg', detail=1 ) # 图片可以传入图片路径、也可以传入图片链接。但推荐传入图片路径,会提高识别速度。包含中文会出错。设置detail=0可以简化输出结果,默认为1
print(result)
readtext 返回的列表中,每个元素都是一个元组,内含三个信息:位置、文字、置信度:
[
([[27, 37], [341, 37], [341, 79], [27, 79]], '姓 名 爱新觉罗 。玄烨', 0.6958897643232619),
([[29, 99], [157, 99], [157, 135], [29, 135]], '性 别 男', 0.914532774041559),
([[180, 95], [284, 95], [284, 131], [180, 131]], '民蔟满', 0.4622474180193509),
([[30, 152], [94, 152], [94, 182], [30, 182]], '出 生', 0.6015505790710449),
([[110, 152], [344, 152], [344, 184], [110, 184]], '1654 年54日', 0.42167866223467815),
([[29, 205], [421, 205], [421, 243], [29, 243]], '住 址 北京市东城区景山前街4号', 0.6362530289101117),
([[105, 251], [267, 251], [267, 287], [105, 287]], '紫禁城乾清宫', 0.8425745057905053),
([[32, 346], [200, 346], [200, 378], [32, 378]], '公民身份证号码', 0.22538012770296922),
([[218, 348], [566, 348], [566, 376], [218, 376]], '000003165405049842', 0.902066405195785)
]
detail=0,从而只返回文字内容:
['姓 名 爱新觉罗 。玄烨', '性 别 男', '民蔟满', '出 生', '1654 年54日', '住 址 北京市东城区景山前街4号', '紫禁城 乾清宫', '公民身份证号码', '000003165405049842']
5.3、基本使用3


智能推荐
Python 入门的60个基础练习_练习python基础语法-程序员宅基地
文章浏览阅读4.2w次,点赞329次,收藏2.7k次。Python 入门的60个基础练习_练习python基础语法
iOS6和iOS7代码的适配(2)——status bar_ios7 statusbar-程序员宅基地
文章浏览阅读1w次。用Xcode5运行一下应用,第一个看到的就是status bar的变化。在iOS6中,status bar是系统在处理,应用_ios7 statusbar
gdb调试时No symbol "var" defined in current context && No Register_no registers调试显示-程序员宅基地
文章浏览阅读2.1k次。问题描述:,在gdb调试程序输出变量:p var,会提示No symbol "var" in current context.原因:程序编译时开启了优化选项,那么在用GDB调试被优化过的程序时,可能会发生某些变量不能访问,或是取值错误码的情况。这个是很正常的,因为优化程序会删改程序,整理程序的语句顺序,剔除一些无意义的变量等,所以在GDB调试这种程序时,运行时的指令和你所编写指_no registers调试显示
IDGeneratorUtil 主键id生成工具类_idgeneratorutils.generateid()-程序员宅基地
文章浏览阅读3.4k次。import java.util.Random;import org.drools.util.UUIDGenerator;/** * * * 类名称:GenerateIdUtil * 类描述: 主键生成工具类 * @author chenly * 创建时间:Jul 10, 2012 8:10:43 AM * 修改人: * 修改时间:Jul 10, 2012 8..._idgeneratorutils.generateid()
关于汇编 BX 和 BLX 跳转指令_汇编blx-程序员宅基地
文章浏览阅读5k次。BX:跳转到寄存器reg给出的目的地址处,如:BX R2BLX:跳转到寄存区reg给出的目的地址处并将返回地址存储到LR(R14)使用这两个指令时有一点特别需要注意:跳转的目的地址必须是奇数,若不是奇数则在后面加1,如某函数的起始地址是0x80000f00,则要跳转到此函数则应该跳转到0x80000f01处!否则会进入硬件错误中断!..._汇编blx
前端vue,打包整合进后端springboot的resources里面后,运行只要刷新就报404_前端项目放入resource-程序员宅基地
文章浏览阅读2.6k次,点赞2次,收藏4次。vue打包后,其实就剩index.html和一堆静态资源,页面的加载和替换都是通过刷新index.html种的dom来实现的(应该是这样,可能表述不是很好),所以做个重定向就可以了。(博主是这么解决的,网上还有很多人是各种路径错误,大家可以尝试下自己是哪个原因)import org.springframework.boot.web.server.ConfigurableWebServerFa..._前端项目放入resource
随便推点
添加远程github仓库时报错 Warning: Permanently added the RSA host key for IP address 52.74.223.119_cmd warning: permanently added-程序员宅基地
文章浏览阅读9.7k次。1.问题展示2.解决方案1.任意窗口, 打开git bash2.命令行界面, 输入cd C:3.cat ~/.ssh/id_rsa.pub正常下面应该显示一大串公钥如果没有,显示如下图, 则进行下一步, 创建公钥4.创建公钥, 输入 ssh-keygen5.然后一直下一步, 直到出现6.再次输入cat ~/.ssh/id_rsa.pub下面一大串数字便是公钥,复制这些字符串, 打开github, 点击头像, 打开settings, 打开SSH and GPG Keys_cmd warning: permanently added
SQL*Plus 使用技巧1-程序员宅基地
文章浏览阅读154次。[code="java"]1. SQL/Plus 常用命令 a. help [topic] 查看命令的使用方法,topic表示需要查看的命令名称。 如: help desc; b. host 该命令可以从SQL*Plus环境切换到操作系统环境,以便执行操作系统命名。 c. host [command] 在sql*plus环境中执行操作系统命令,如:host notepad.exe..._sql+plus的使用方法
域控服务器搭建与管理论文,校园网络服务器的配置与管理 毕业论文.doc-程序员宅基地
文章浏览阅读441次。该文档均来自互联网,如果侵犯了您的个人权益,请联系我们将立即删除!**学校毕 业 论 文**学校园网络服务器的配置与管理姓 名: **学 号: **指导老师:系 名:专 业: 计算机网络技术班 级:二0一一年十二月十五日摘 要随着网络技术的不断发展和Internet的日益普及,许多学校都建立了校园网络并投入使用,这无疑对加快信息处理,提高工作效..._服务器配置与应用论文
mysql单实例多库与多实例单库_数据库单实例和多实例-程序员宅基地
文章浏览阅读1k次。一、单实例多库:一个mysql实例,创建多个数据目录。规划:实例路径:/usr/local/mysql数据目录路径:(1)/usr/local/mysql/data(2)/usr/local/mysql/data2步骤:安装mysql。配置my.cnf文件。初始化各个数据库。用mysqld_multi启动。1、安装mysql。平常安装。2、m..._数据库单实例和多实例
MFC解决找不到MFC90.DLL的问题_microsoft v90.debugmfc-程序员宅基地
文章浏览阅读6.3k次。今天装了第三方的MFC软件库Xtreme ToolkitPro v15.0.1,听说搞MFC的人都知道它的强大,我刚学习,所以装了一个,然后想运行一下它自带的例子看看。出现一个“找不到mfc90.dll“的问题,百度一下,记录如下:vs2008已经打过sp1补丁,编译C++程序会提示找不到mfc90.dll文件的错误,但是如果是release版的话就能正常运行csdn看到解决方案,粘贴_microsoft v90.debugmfc
XeLaTeX-中文排版解决方案_latex 中文排版 texlive-程序员宅基地
文章浏览阅读2.1k次。以前使用CJK进行中文的排版,需要自己生成字体库,近日,出现了XeTeX,可以比较好的解决中文字体问题,不需要额外生成LaTeX字体库,直接使用计算机系统里的字体,本文以在Linux下为例说明XeTeX的使用。操作系统: UbuntuTeX:除了texlive包外,还需要安装的包是texlive-xetex。字体:可以使用fc-list查看你自己的字体库,注意字体的完整名称,在XeTe..._latex 中文排版 texlive