深度学习(Deep Learning)未完待续……-程序员宅基地
目录
(11)损失函数:衡量模型输出与真实标签的差异(损失函数越小,表示模型越好)
(1)卷积核:用于对输出图像进行特征提取,输出通常称为特征图
(2)填充: 在输入图像周围添加额外的行/列 。 作用:使卷积后图像分辨率不变,方便计算特征图尺寸的变化,
(3)步幅(步长):卷积核滑动的行数和列数称为步幅,控制输出特征图大小,(会被缩小1/n倍?)
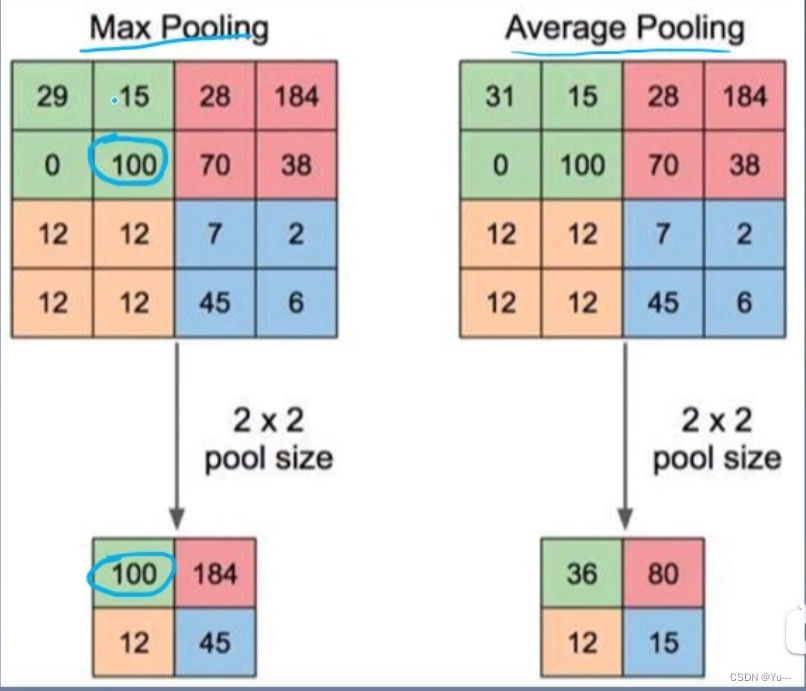
(6)最大池化:用这个像素区域的最大值来代替这个区域,如下图100
(7)平均池化:用这个像素区域的平均值来代替这个区域,如下图求31,15,0,100的平均值
一. 基础知识
1.基本概念:
(1)人工神经元
从人类神经元中抽象出来的数学模型。
(2)人工神经网络:
大量神经元以某种连接方式构成的机器学习模型
(3)激活函数:
在神经网络中,输入经过权值加权计算并求和之后,需要经过一个函数的作用,这个函数就是激活函数。作用:防止网络退化为单层网络

(4)感知机(第一个神经网络模型)
缺点:不能解决异或问题
(5)多层感知机
在单层感知机的基础上,引入一个或多个隐藏层,使神经网络有多个网络层,因此叫多层感知机
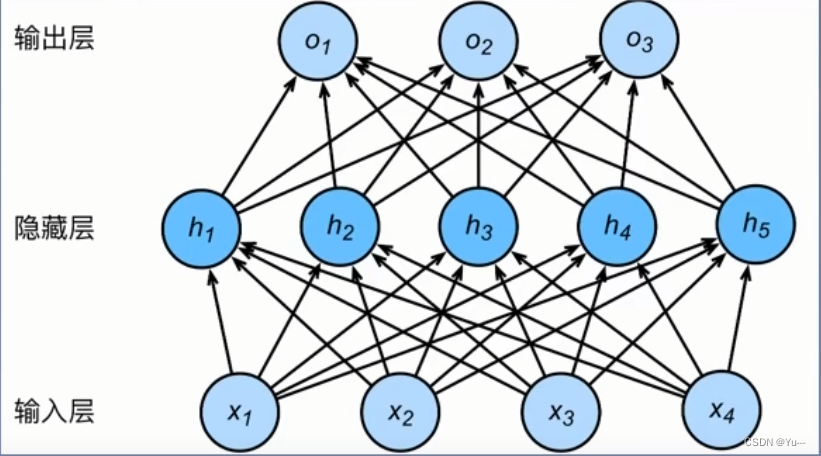
(6)前向传播:
输入层开始从前向后,数据逐步传输至输出层(数据在模型中从前到后顺序走一遍)
(7)反向传播:
损失函数开始从后向前,梯度逐步传递至第一层
- 反向传播作用:用于权重更新,使网络输出更接近标签
- 反向传播原理:微积分中的链式求导法则
- 损失函数:衡量模型输出与真实标签的差异(损失函数越小,表示模型越好)
(8)梯度
增长最快的方向
(9)梯度下降:
权值沿着梯度负方向更新,使函数值减小
(10)学习率:
控置更新步长
(11)损失函数:衡量模型输出与真实标签的差异(损失函数越小,表示模型越好)
(12)代价函数:
(13)目标函数:
(14)正则化方法:减小方差的策略

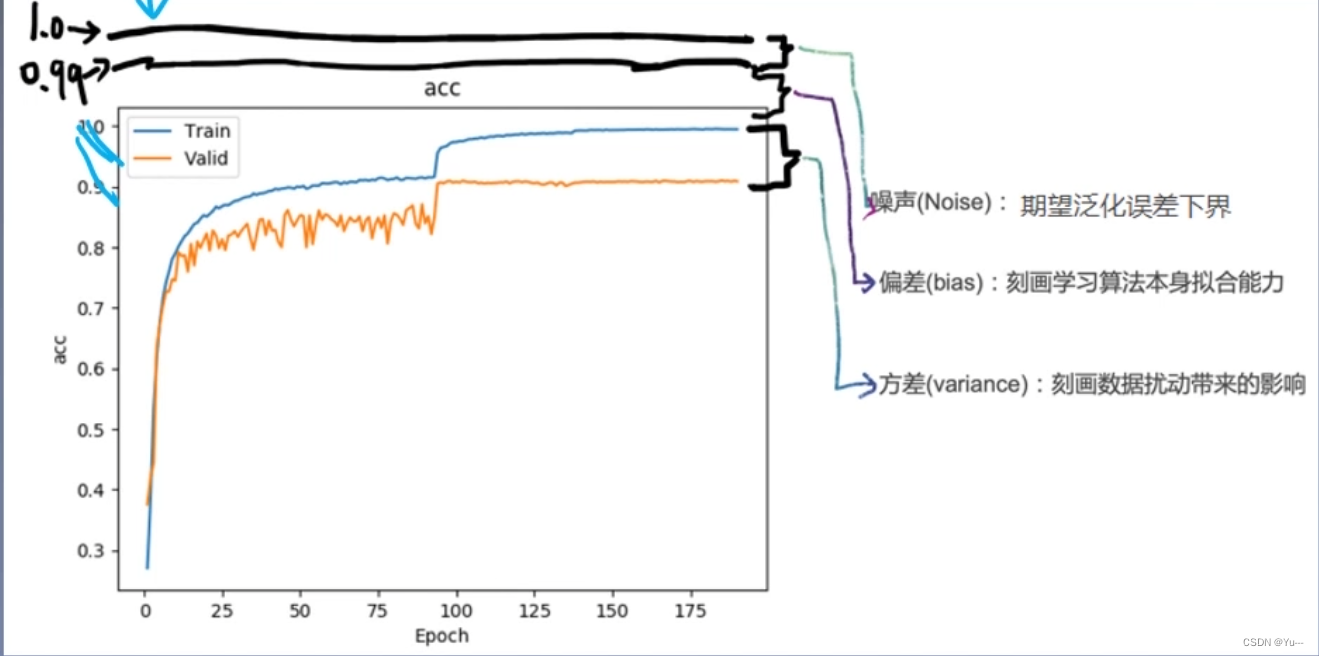
(15)偏差、方差、噪声
通俗化解释;噪声: 能达到的最高精度与1.0之间的距离就是噪声(不可能达到1)
偏差: 训练集与模型最高精度之间的差距
方差: 训练集与测试集之间的差距
如上图解释
(16)感受野:
神经元存在的局部感受区域(输入图像中与卷积核进行卷积运算的那个区域,随着步幅的移动感受野也会发生变化)
(17)神经网络训练过程
先进行前向传播---------->计算预测值与真实值误差(损失函数)---------->由损失函数进行反向传播更新权重w和偏置b
2.神经网络实战过程
- 数据准备
- 搭建模型model
- 开始训练(包括学习率,训练轮次等参数的设置)
- 前向传播
- 计算误差(损失函数)
- 反向传播(梯度下降法更新权重和偏置)
- 直到训练轮次结束
- 产生新的model(w和b已优化到最优的model)
- 开始测试(测试通过,直接应用;测试不通过,在通过调整学习率,训练轮次等参数进行训练)
- 应用
二、CNN
什么是卷积神经网络? 含有卷积运算的网络都可以叫卷积神经网络,这是个统称,具体的有LeNet-5、AlexNet等
1.基本概念
(1)卷积核:用于对输出图像进行特征提取,输出通常称为特征图
(2)填充: 在输入图像周围添加额外的行/列 。 作用:使卷积后图像分辨率不变,方便计算特征图尺寸的变化,
(3)步幅(步长):卷积核滑动的行数和列数称为步幅,控制输出特征图大小,(会被缩小1/n倍?)
(4)多通道卷积:
(5)池化:用一个像素表示一块区域的像素值,降低图像分辨率
方法一:Max Pooling 最大池化 方法二:Average Pooling 平均池化
(6)最大池化:用这个像素区域的最大值来代替这个区域,如下图100
(7)平均池化:用这个像素区域的平均值来代替这个区域,如下图求31,15,0,100的平均值
(8)激活函数
为什么要用非线性激活函数?因为线性函数会让网络坍缩 成一层,不能发挥神经网络层数深的优势。
-
1)Sigmoid激活函数
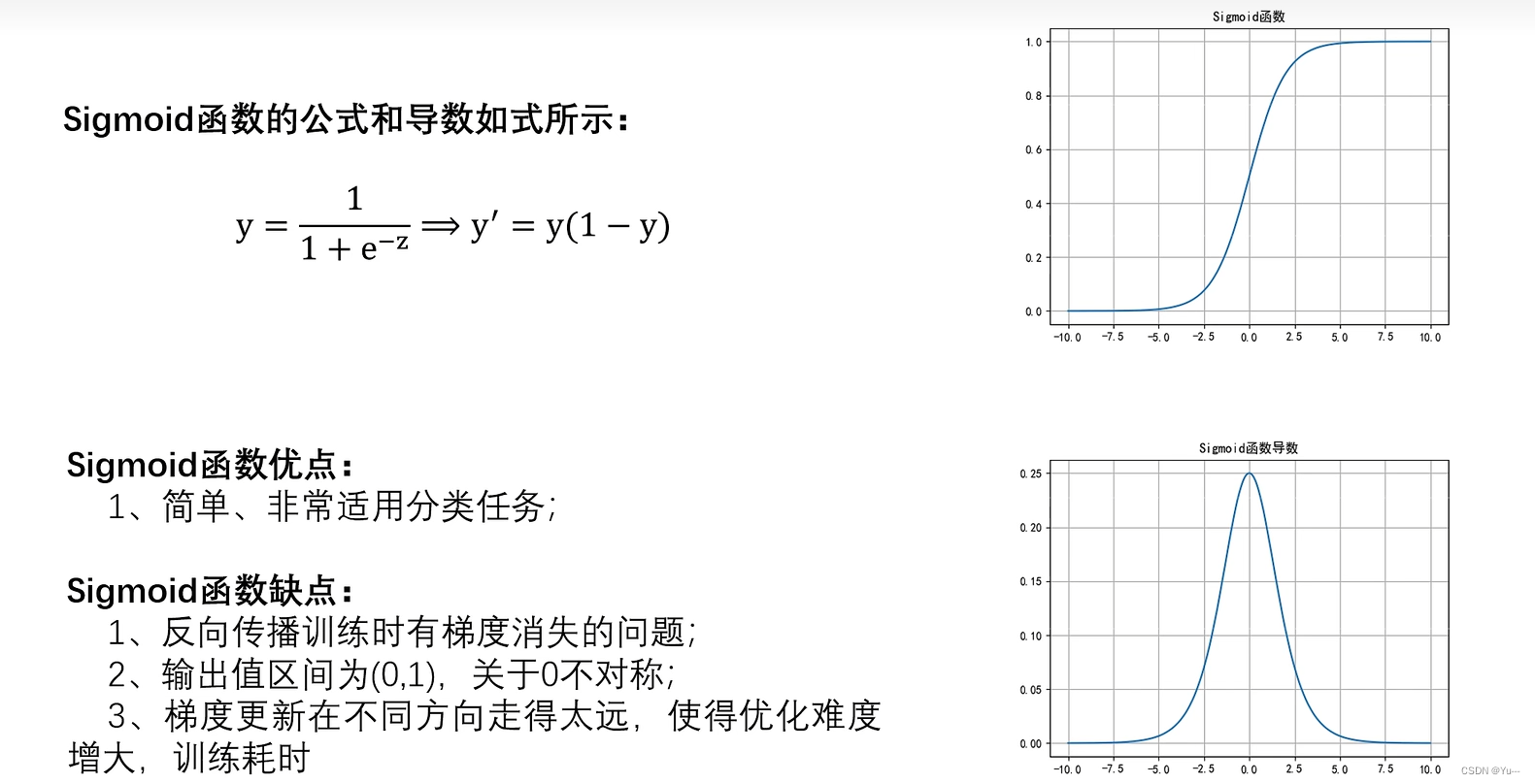
-
2)Tanh函数

-
3)ReLU激活函数(用的比较多)
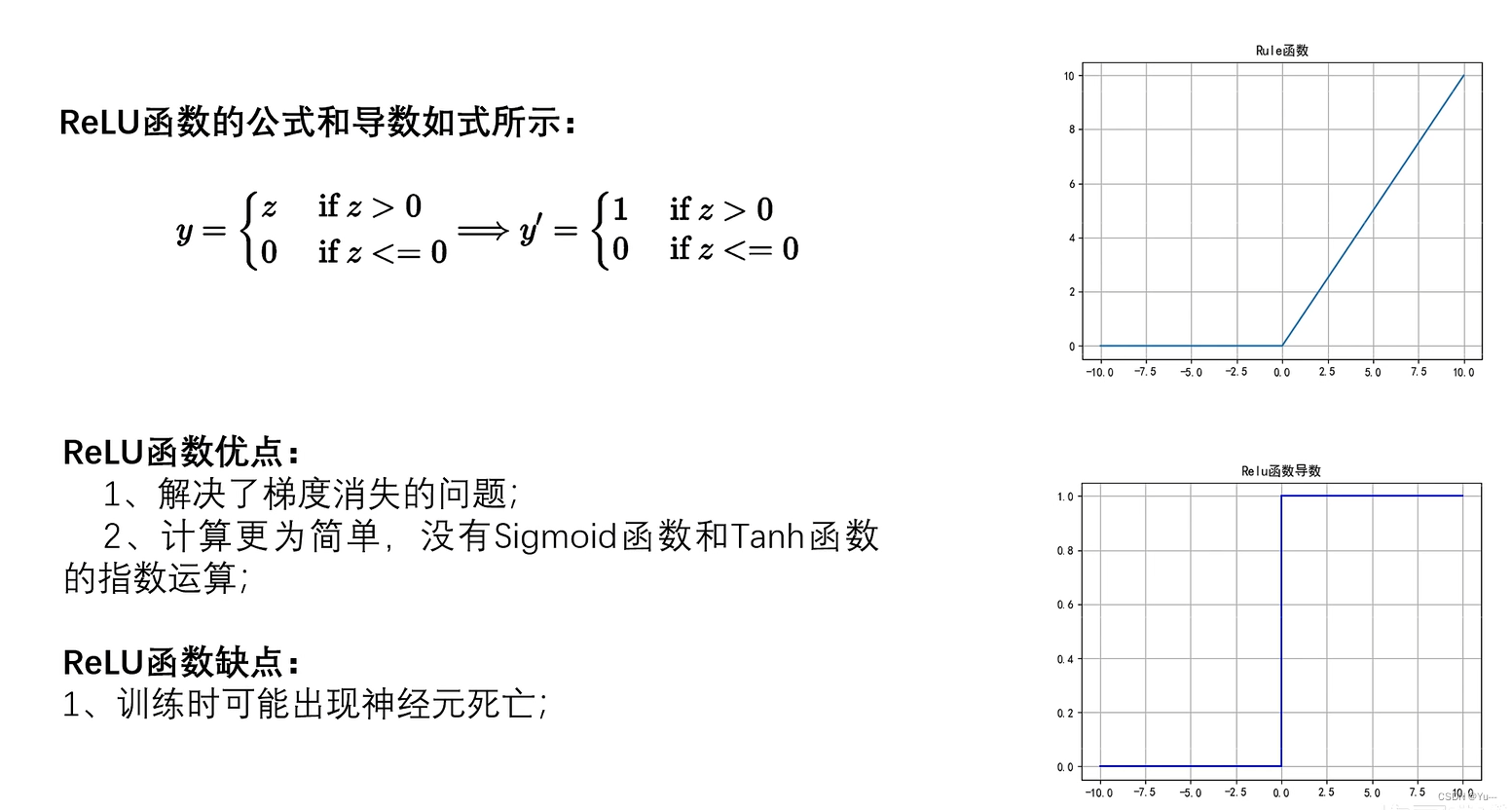
-
4)Leaky ReLU激活函数

(9) 前向传播
前向传播(Forward Propagation)是指从输入数据开始,通过神经网络的各个层,逐层计算并传递数据,最终得到输出结果的过程。
具体过程如下:x输入数据,w是权重,b为偏置,sigmoid和relu为激活函数
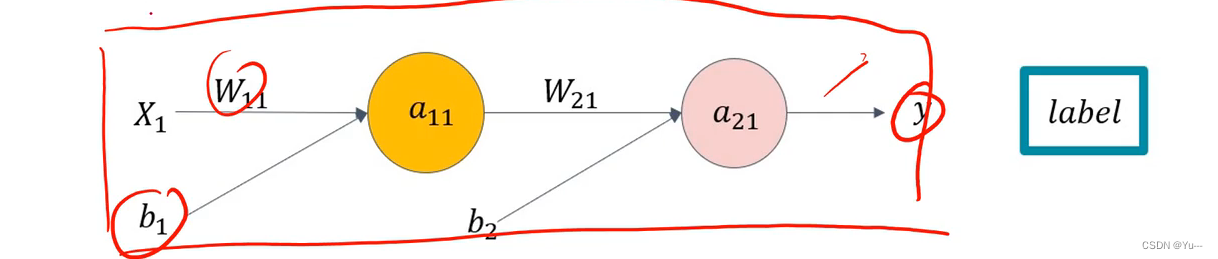

(10)损失函数
损失函数用于衡量模型预测结果与真实标签之间的差异。常见的损失函数包括交叉熵损失函数、均方误差损失函数等。
损失函数越小表示模型越好
(11)梯度下降法
梯度下降(Gradient Descent)是一种常用的优化算法,用于最小化损失函数并更新模型参数。它是基于函数的梯度信息来确定下降的方向,并以此迭代地更新参数,直到达到最优解或者收敛。
梯度下降的基本思想是通过计算损失函数对参数的梯度,确定参数的更新方向。梯度是一个向量,指示了函数在某一点上的最大变化方向。在梯度下降中,我们希望沿着梯度的反方向进行更新,以使损失函数逐渐减小。
2.基本运算
(1)卷积层------ 卷积运算

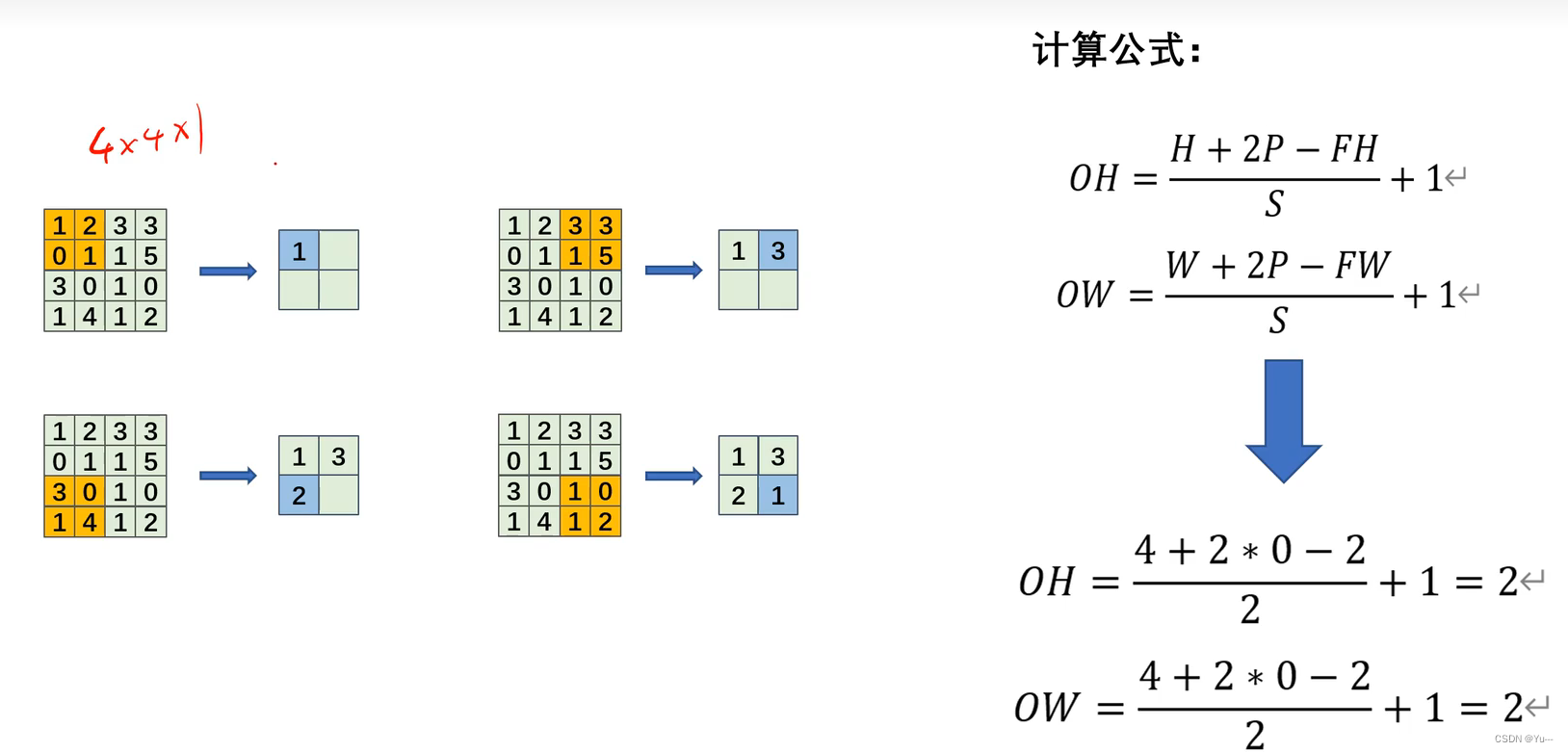
(2)卷积层-----经过卷积运算后的特征图大小
计算公式如下:

公式中:H:未填充前图像的高; W:未填充前图像的宽; OH:卷积运算后输出图像的高; OW:卷积运算后输出图像的宽;
FH:卷积核的高; FW:卷积核的宽; p:填充的圈数; S:步幅
(3)卷积层------多通道数据卷积运算
计算过程是:每个通道先分别进行卷积运算,每个通道的结果再相加为第一个数值(63),然后再按步幅进行移动在进行卷积运算得到第二个数值(55)依次类推。过程图如下

(4)池化层-----最大池化运算 见 二、1.(6)
(5)池化层-----平均池化运算 见 二、1.(7)
(6)池化层-----经过池化后特征图的大小
经过池化后特征图大小的计算,同样可以用卷积层的公式, ,
.
只不过FH和FW不再表示卷积核的高和宽,而是表示感受野的高和宽
3.典型网络
(1)LeNet-5
- 结构及参数

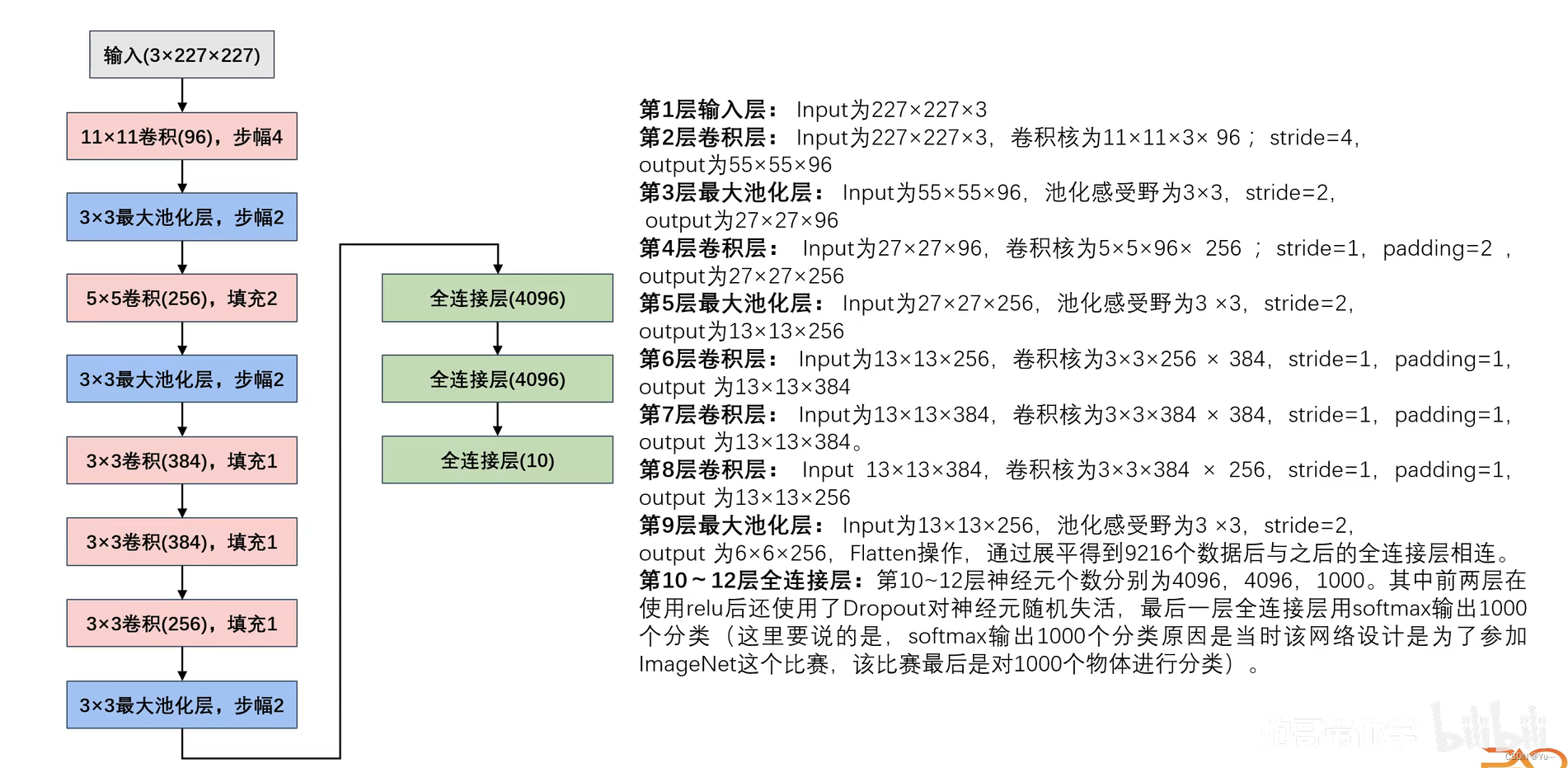
(2)AlexNet网络
- AlexNet网络与LeNet网络的区别

- 结构及参数
4.图像增强
- 水平翻转,
- 随机裁剪
- PCA
- LRN正则化(局部归一化)
5.创建网络(以LeNet网络为例)
代码格式:
#创建网络模型(下面的格式是约定俗成的,固定格式)#第三行的LeNet必须和第一行的LeNet保持一致
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
搭建具体的网络层及前向传播:
法一:
#创建网络模型(下面的格式是约定俗成的,固定格式)#第三行的LeNet必须和第一行的LeNet保持一致
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
#搭建网络模型的每一层
self.c1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5,padding=2) #in_channels:输入通道,out_channels:输出通道,kernel_size:卷积核, padding:填充,stride:步幅,bias:偏置
self.sig = nn.Sigmoid() #定义激活函数
self.s2 = nn.AvgPool2d(kernel_size=2,stride=2) #定义池化层,这里选用平均池化,kernel_size:池化核,stride:步幅
self.c3 = nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5)
self.s4 = nn.AvgPool2d(kernel_size=2,stride=2)
self.flatten = nn.Flatten() #Flatten:展平层
self.f5 = nn.Linear(in_features=400,out_features=120) #Linear:全连接层
self.f6 = nn.Linear(in_features=120,out_features=84)
self.f7 = nn.Linear(in_features=84, out_features=10)
#定义前向传播
def forward(self,x): #forward:前向传播,括号中x:意思是模型的输入数据
x = self.sig(self.c1(x)) #把值都付给x,x的值在前向传播过程中一直在更新
x = self.s2(x)
x = self.sig(self.c3(x))
x = self.s4(x)
x = self.flatten(x)
x = self.f5(x)
x = self.f6(x)
x = self.f7(x)
return x #到此为止模型搭建完毕法二:运用 nn.Sequential 将各层组成一个整体网络,并且能顺序执行及前向传播,前向传播中 y = self.net(x) 代替了法一中x值得更新,类似于用循环代替法一中x值更新的步骤
#定义模型
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.net = nn.Sequential( #nn.Sequential将各个层组合在一起形成网络模型
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(), #卷积层,输入通道为1,输出为6,卷积核5*5,填充2,激活函数Tanh()
nn.AvgPool2d(kernel_size=2, stride=2), #池化层,池化核2*2,步幅2,用的是平均池化
nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(),
nn.Flatten(), #展平层,将多维数据展平为一维向量
nn.Linear(120, 84), nn.Tanh(), #全连接层,输入特征大小120,输出特征大小84,激活函数Tanh()
nn.Linear(84, 10)
)
#定义了前向传播方法
def forward(self, x):
y = self.net(x)
return y数据加载函数
# 加载数据
'''DataLoader常用参数如下:
train_Data,test_Data 分别是训练集和测试集的数据集实例
shuffle参数是把数据随机打乱,通常训练集True打乱增加随机性,测试集False不打乱
batch_size指每个批次中样本数量
还有一个参数num_workers:表示用于数据加载的子进程的数量(默认为0就是用主程序加载,大于0则表示创建多个子进程加载数据,提高加载效率)'''
train_loader = DataLoader(train_Data, shuffle=True, batch_size=256)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=256)
定义优化器和损失函数
#定义优化器 (优化器是梯度下降法的变形或改进,本质上还是梯度下降法,)
optimizer = torch.optim.Adam(model.parameters(),lr=0.001) #选择Adam优化器, model.parameters()表示返回模型所有参数,lr表示学习率#定义损失函数
criterion = nn.CrossEntropyLoss()绘制损失函数曲线
#绘制损失函数曲线
Fig = plt.figure() #创建一个figure赋值给Fig
plt.plot(range(len(losses)), losses) #画损失曲线,第一个参数是训练次数,第二个参数是损失函数的值
plt.show()
模型训练函数
# 训练网络
epochs = 5 #训练模型的轮数,轮数越大模型泛化能力越强,但训练时间也越长
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):
for (x, y) in train_loader: # 获取小批次的x与y
x, y = x.to('cuda:0'), y.to('cuda:0') # 把小批次搬到GPU上
Pred = model(x) # 一次前向传播(小批量)
loss = loss_fn(Pred, y) # 计算损失函数
losses.append(loss.item()) # 记录损失函数的变化
optimizer.zero_grad() # 清理上一轮滞留的梯度
loss.backward() # 一次反向传播
optimizer.step() # 优化内部参数
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 局部关闭梯度计算功能
for (x, y) in test_loader: # 获取小批次的x与y
x, y = x.to('cuda:0'), y.to('cuda:0') # 把小批次搬到GPU上
Pred = model(x) # 一次前向传播(小批量)
_, predicted = torch.max(Pred.data, dim=1)
correct += torch.sum((predicted == y))
total += y.size(0)6.手写数字识别代码及注释
#导入所需要的库
import torch
import torch.nn as nn #pytorch中自带的一个函数库,里面包含了神经网络中使用的一些常用函数
from torch.utils.data import DataLoader #用于加载数据并生成小批量数据
from torchvision import transforms #提供了一系列图像预处理的函数和类,用于对图像进行常见的预处理操作,例如缩放、裁剪、旋转、翻转、归一化等
from torchvision import datasets #提供了一些计算机视觉的小数据集,如MINIST
import matplotlib.pyplot as plt #画图函数
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg') #图片格式为svg格式
# 制作数据集
# 设定下载参数 预处理
transform = transforms.Compose([
transforms.ToTensor(), #将图像数据从0-255的整数范围转换为0-1的浮点数范围,并且调整图像的维度顺序从(H, W, C)转换为(C, H, W)。
transforms.Normalize(0.1307, 0.3081) #对图像进行标准化处理。它会对每个通道的像素值进行减均值除以标准差的操作,以使得图像的像素值分布接近于均值为0、标准差为1的正态分布。在这个例子中,均值为0.1307,标准差为0.3081。
])
# 下载训练集与测试集
train_Data = datasets.MNIST(
root = 'D:/Jupyter/dataset/mnist/', #下载路径
train = True, #是否下载训练集,Ture就是下载训练集,False就是下载测试集
download = True, #是否下载数据集
transform = transform #是否对数据集进行预处理, transform = transform 这里后面的transform是指上面定的
)
test_Data = datasets.MNIST(
root = 'D:/Jupyter/dataset/mnist/',
train = False,
download = True,
transform = transform
)
# 加载数据
'''DataLoader常用参数如下:
train_Data,test_Data 分别是训练集和测试集的数据集实例
shuffle参数是把数据随机打乱,通常训练集True打乱增加随机性,测试集False不打乱
batch_size指每个批次中样本数量
还有一个参数num_workers:表示用于数据加载的子进程的数量(默认为0就是用主程序加载,大于0则表示创建多个子进程加载数据,提高加载效率)'''
train_loader = DataLoader(train_Data, shuffle=True, batch_size=256)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=256)
#定义模型
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.net = nn.Sequential( #nn.Sequential将各个层组合在一起形成网络模型
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(), #卷积层,输入通道为1,输出为6,卷积核5*5,填充2,激活函数Tanh()
nn.AvgPool2d(kernel_size=2, stride=2), #池化层,池化核2*2,步幅2,用的是平均池化
nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(),
nn.Flatten(), #展平层,将多维数据展平为一维向量
nn.Linear(120, 84), nn.Tanh(), #全连接层,输入特征大小120,输出特征大小84,激活函数Tanh()
nn.Linear(84, 10)
)
#定义了前向传播方法
def forward(self, x):
y = self.net(x)
return y
# 查看网络结构
X = torch.rand(size= (1, 1, 28, 28)) #torch.rand表示生成一个指定形状的随机张量,size= (1, 1, 28, 28)第一维度1表示一个样本,第二维度1表示单通道,第三第四维度表示高和宽为28
for layer in CNN().net:
X = layer(X)
print( layer.__class__.__name__, 'output shape: \t', X.shape )
# 创建子类的实例,并搬到GPU上
model = CNN().to('cuda:0')
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss() # 自带softmax激活函数
# 定义优化器
learning_rate = 0.9 # 设置学习率
optimizer = torch.optim.SGD(
model.parameters(),
lr = learning_rate,
)
# 训练网络
epochs = 5 #训练模型的轮数,轮数越大模型泛化能力越强,但训练时间也越长
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):
for (x, y) in train_loader: # 获取小批次的x与y
x, y = x.to('cuda:0'), y.to('cuda:0') # 把小批次搬到GPU上
Pred = model(x) # 一次前向传播(小批量)
loss = loss_fn(Pred, y) # 计算损失函数
losses.append(loss.item()) # 记录损失函数的变化
optimizer.zero_grad() # 清理上一轮滞留的梯度
loss.backward() # 一次反向传播
optimizer.step() # 优化内部参数
#绘制损失函数曲线
Fig = plt.figure() #创建一个figure赋值给Fig
plt.plot(range(len(losses)), losses) #画损失曲线,第一个参数是训练次数,第二个参数是损失函数的值
plt.show()
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 局部关闭梯度计算功能
for (x, y) in test_loader: # 获取小批次的x与y
x, y = x.to('cuda:0'), y.to('cuda:0') # 把小批次搬到GPU上
Pred = model(x) # 一次前向传播(小批量)
_, predicted = torch.max(Pred.data, dim=1)
correct += torch.sum((predicted == y))
total += y.size(0)
print(f'测试集精准度: {100 * correct / total} %')7.ResNet-18和LeNet区别
ResNet-18和LeNet是两个不同的卷积神经网络架构,它们有以下几个区别:
1. 网络深度:ResNet-18是一个相对较深的网络,有18层(包括卷积层、池化层、全连接层等),而LeNet只有7层。
2. 残差连接:ResNet-18使用了残差连接(residual connection)来解决梯度消失和梯度爆炸的问题,这种连接方式可以跳过几层,直接将输入传递给后面的层,使得网络可以学习到输入与输出之间的残差,进一步改善模型的性能。而LeNet没有使用这种连接方式。
3. 卷积核的大小:ResNet-18使用了较大尺寸的卷积核(如7x7的卷积核),这样可以更好地捕捉图像中的全局特征。而LeNet主要使用较小的尺寸(如5x5和3x3)的卷积核,适用于处理较小的图像。
4. 任务类型:ResNet-18主要用于图像分类和目标检测等复杂任务,适用于处理更大和更复杂的图像数据集。而LeNet最初是用于手写数字识别任务,适用于处理小尺寸的图像数据集。
总之,ResNet-18是一个更深、更复杂的网络结构,适用于处理更大和更复杂的图像数据集,而LeNet则是一个相对简单的网络结构,适用于处理较小的图像数据集。
三、RNN
1.概述:
循环神经网络(Recurrent Neural Network,RNN)是一种具有循环连接的神经网络结构,被广泛应用于自然语言处理、语音识别、时序数据分析等任务中。相较于传统神经网络,RNN的主要特点在于它可以处理序列数据,能够捕捉到序列中的时序信息。
RNN的基本单元是一个循环单元(Recurrent Unit),它接收一个输入和一个来自上一个时间步的隐藏状态,并输出当前时间步的隐藏状态。在传统的RNN中,循环单元通常使用tanh或ReLU等激活函数。
2.基本结构
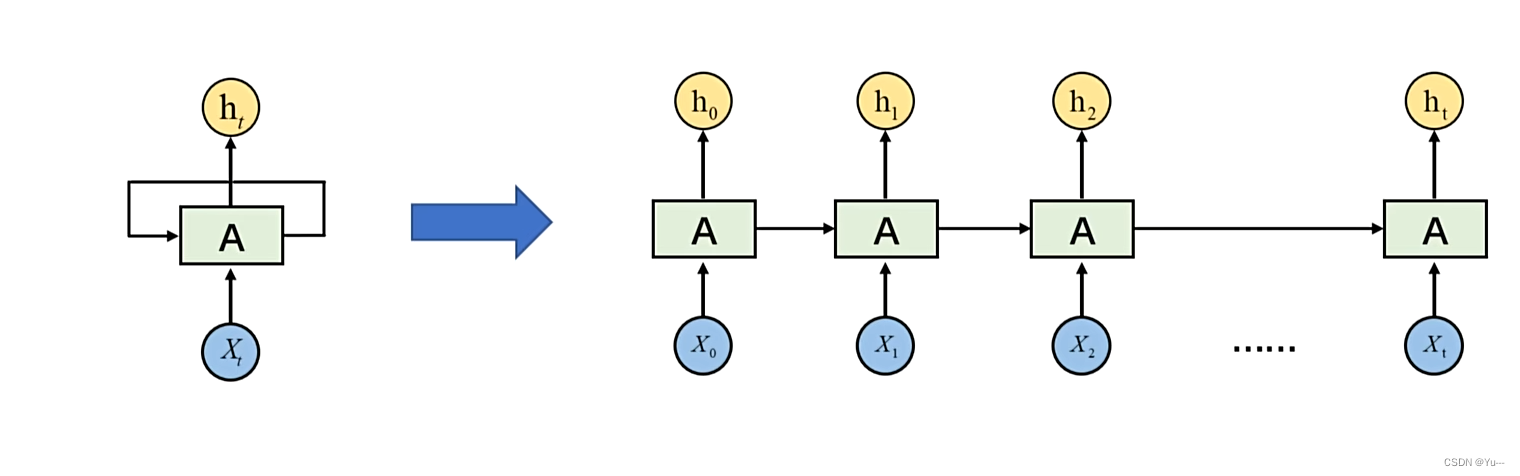
通俗解释就是:某一时刻的输出是由该时刻的输入和上一时刻的输出共同决定,只不过权重不一样而已。循环神经网络循环的就是上一时刻的结果对以后时刻的影响(在时间维度上)
注意:上一时刻不仅能影响下一时刻还能影响之后的所有时刻(即前面能影响后面所有时刻,只是影响的权重不一样而已)数学表达式:
其中:f 为激活函数
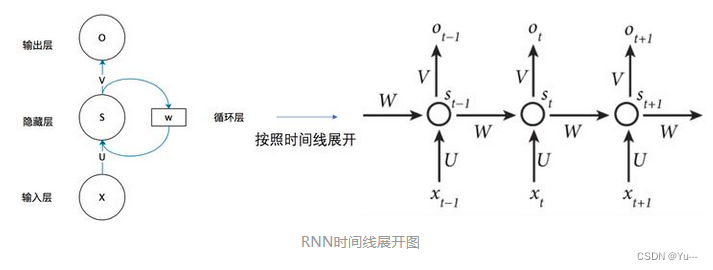


3.分类:
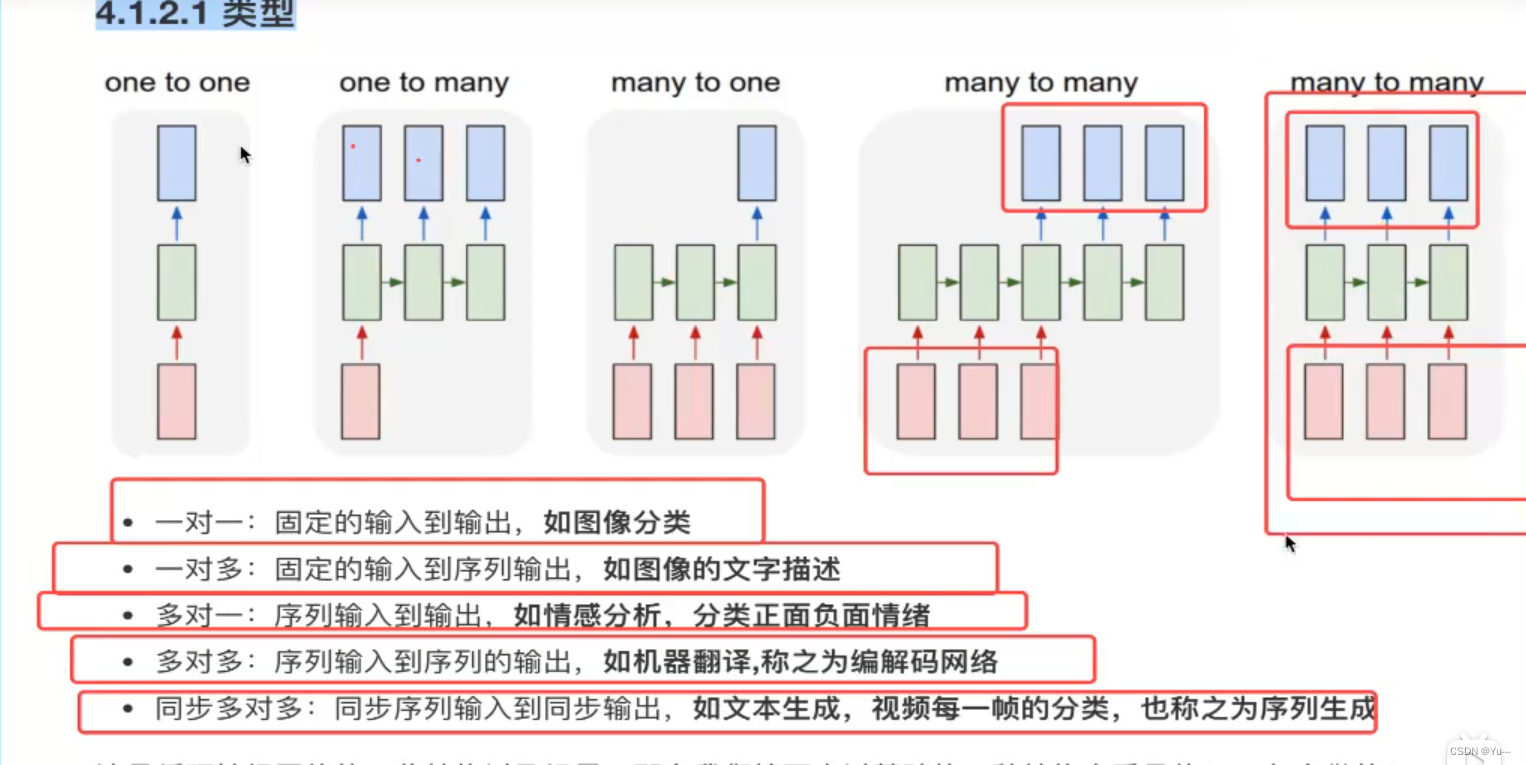
多对一:情感识别
一对多:序列数据生成器。如文章生成、音乐生成
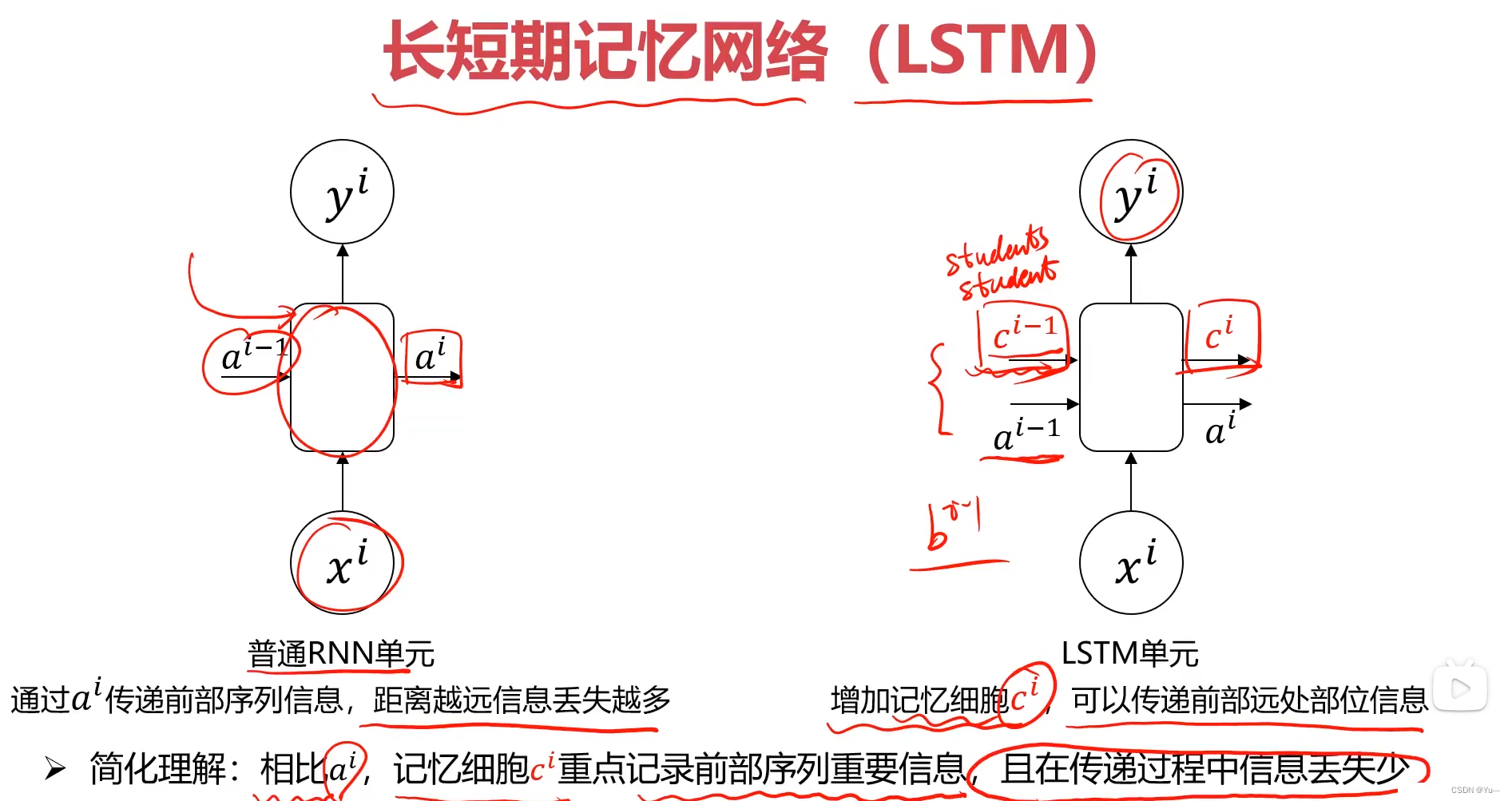
4.普通RNN结构的缺陷:

如下图所示:蓝色y1在传递过程中会逐渐被 稀释,占比越来越小,可能会导致重要信息丢失。
解决方法:长短期记忆网络(LSTM)

5.LSTM
(1)概述:
长短时记忆网络( Long short-term memory,LSTM )是一种循环神经网络 (Recurrent neural network, RNN)的特殊变体,具有“门”结构,通过门单元的逻辑控制决定数据是否更新或是选择丢弃,克服了 RNN 权重影响过大、容易产生梯度消失和爆炸的缺点,使网络可以更好、更快地收敛,能够有效提高预测精度。LSTM 拥有三个门, 分别为遗忘门、输入门、输出门,以此决定每一时刻信息记忆与遗忘。输入门决定有多少新的信息加入到细胞当中,遗忘门控制每一时刻信息是否会被遗忘,输出门决定每一时刻是否有信息输出。结构如下:
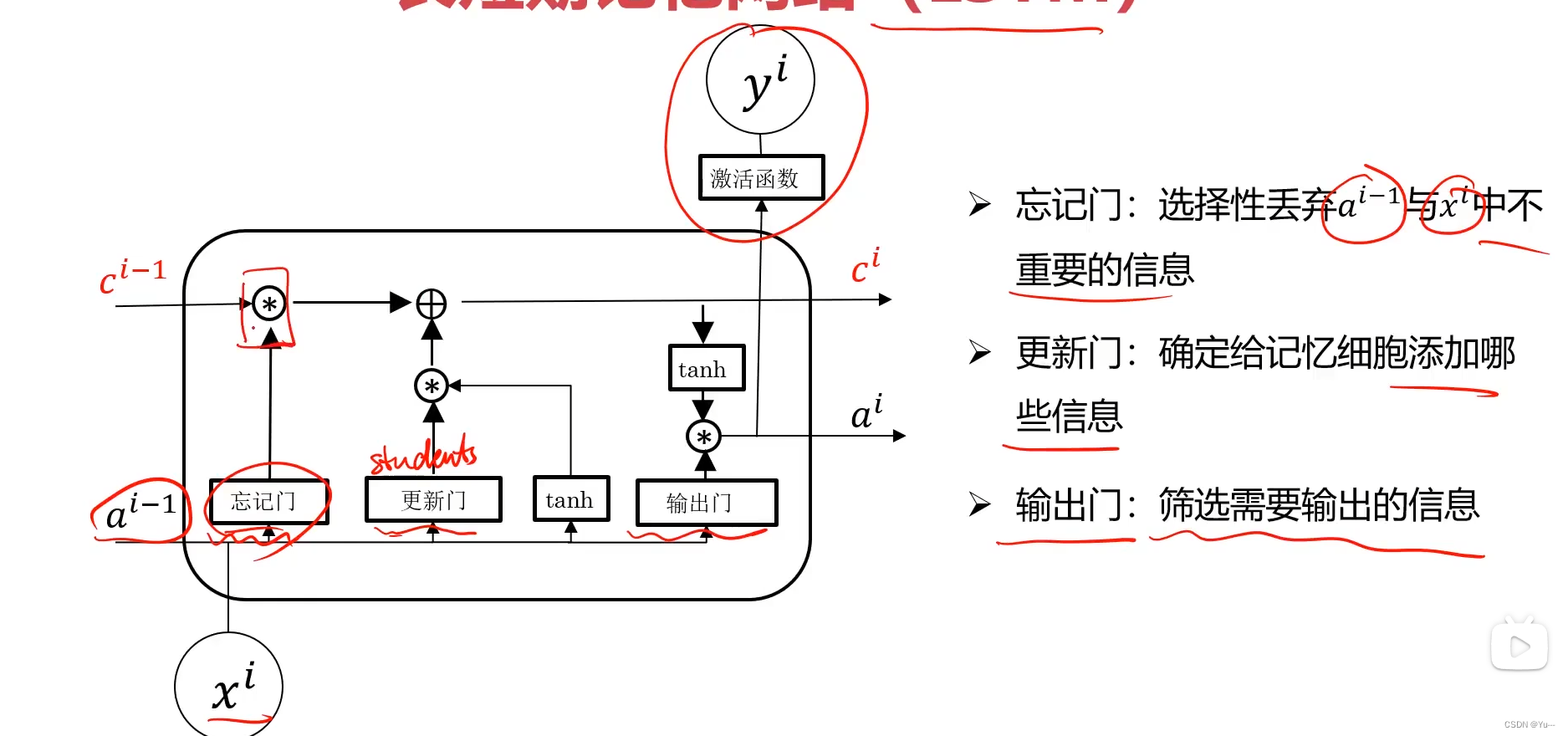 (2)LSTM与普通RNN在结构上的区别:
(2)LSTM与普通RNN在结构上的区别:
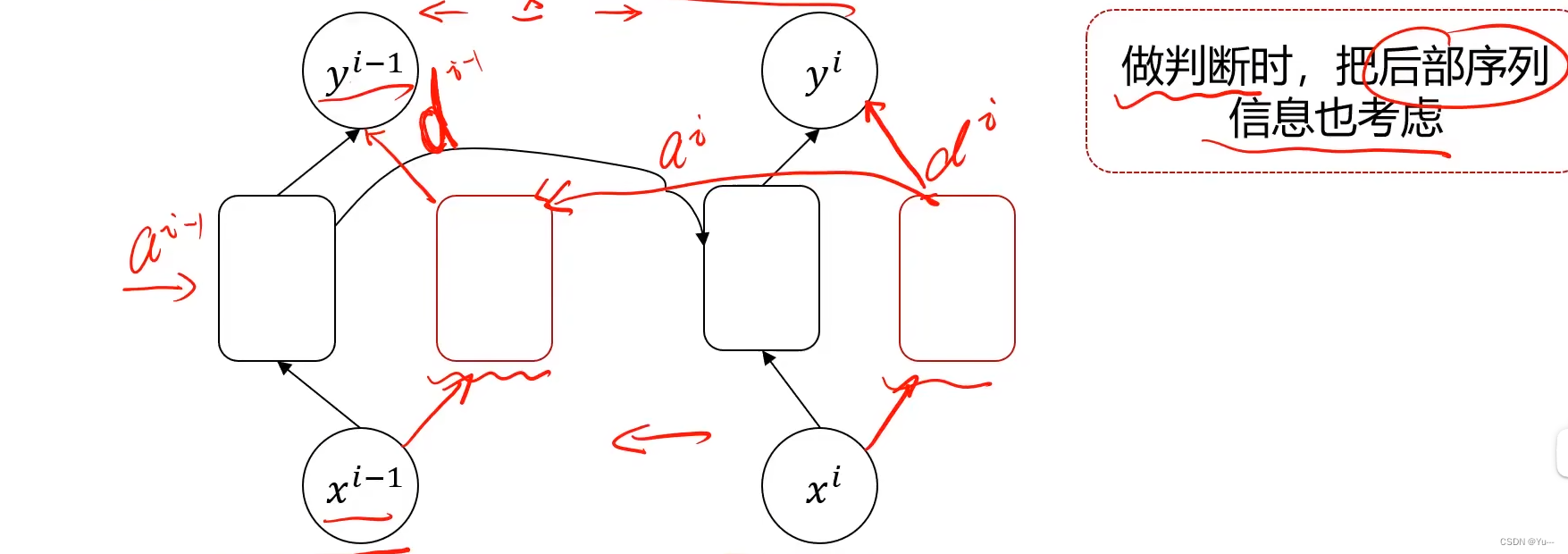
6.BRNN(双向循环神经网络)
简单来说就是后部序列的信息也可以影响前面的判断,LSTM只能前影响后,这个BRNN还可以后影响前
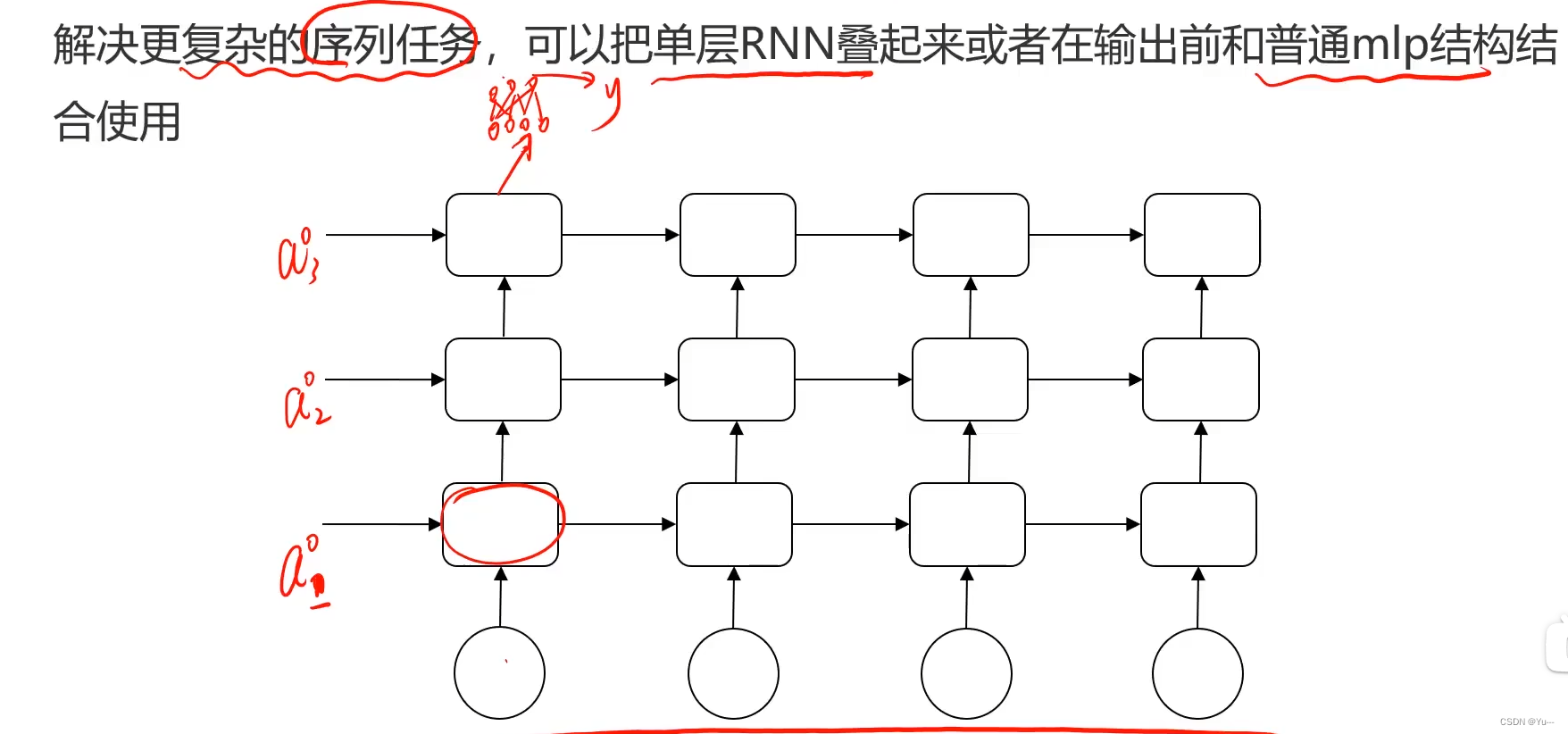
7.DRNN(深层循环神经网络 )
四、GNN(图神经网络)
1.GNN流程:
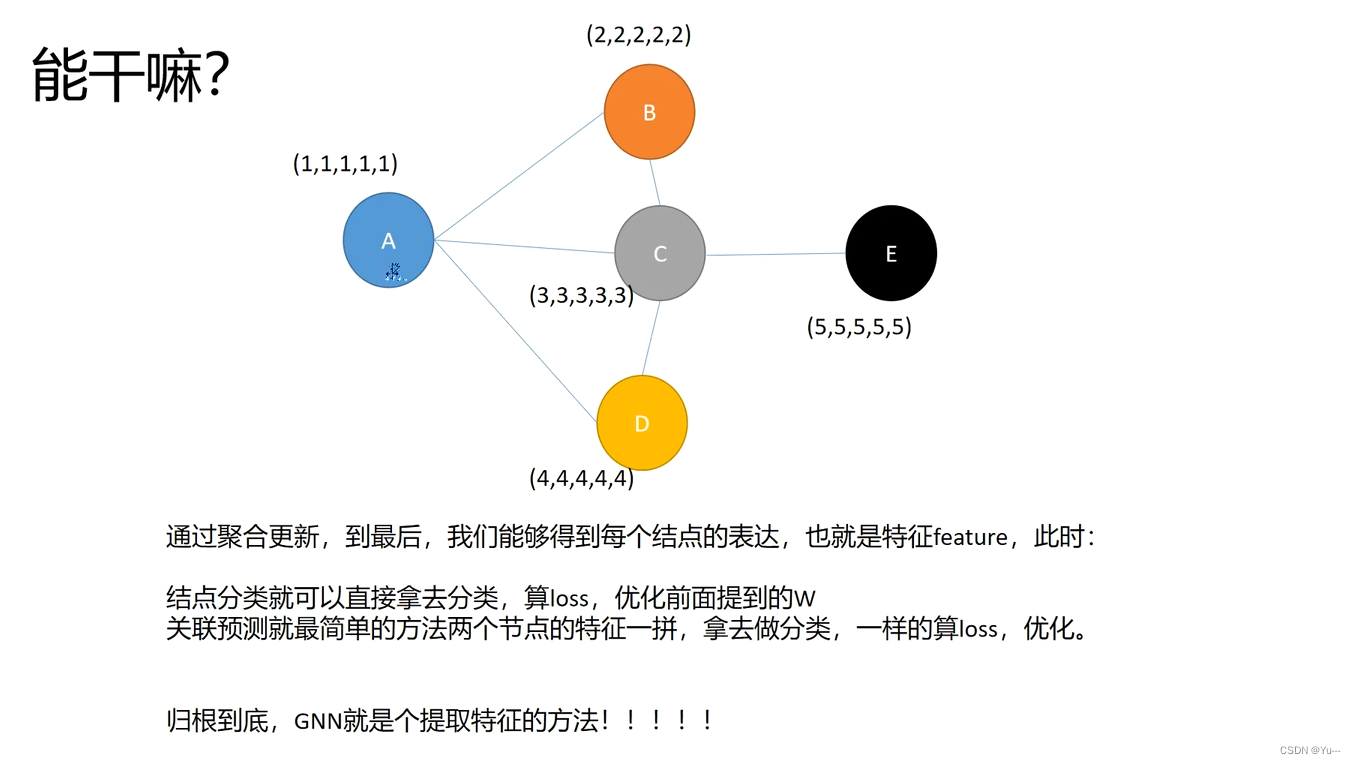
聚合:聚合你邻居的信息用来代表的信息。近朱者赤近墨者黑

上图中,(1,1,1,1,1)(2,2,2,2,2)等为ABCDE的本身特征 abc为权重
更新:

循环

能干嘛?
 2.应用领域
2.应用领域
场景分析与问题推理
推荐系统相关 (如抖音推荐系统)
欺诈检测,风控相关
知识图谱
道路交通动态流量预测
自动驾驶,无人机场景
化学、医疗领域
物理模型相关
3.图的基本组成
点、边、图
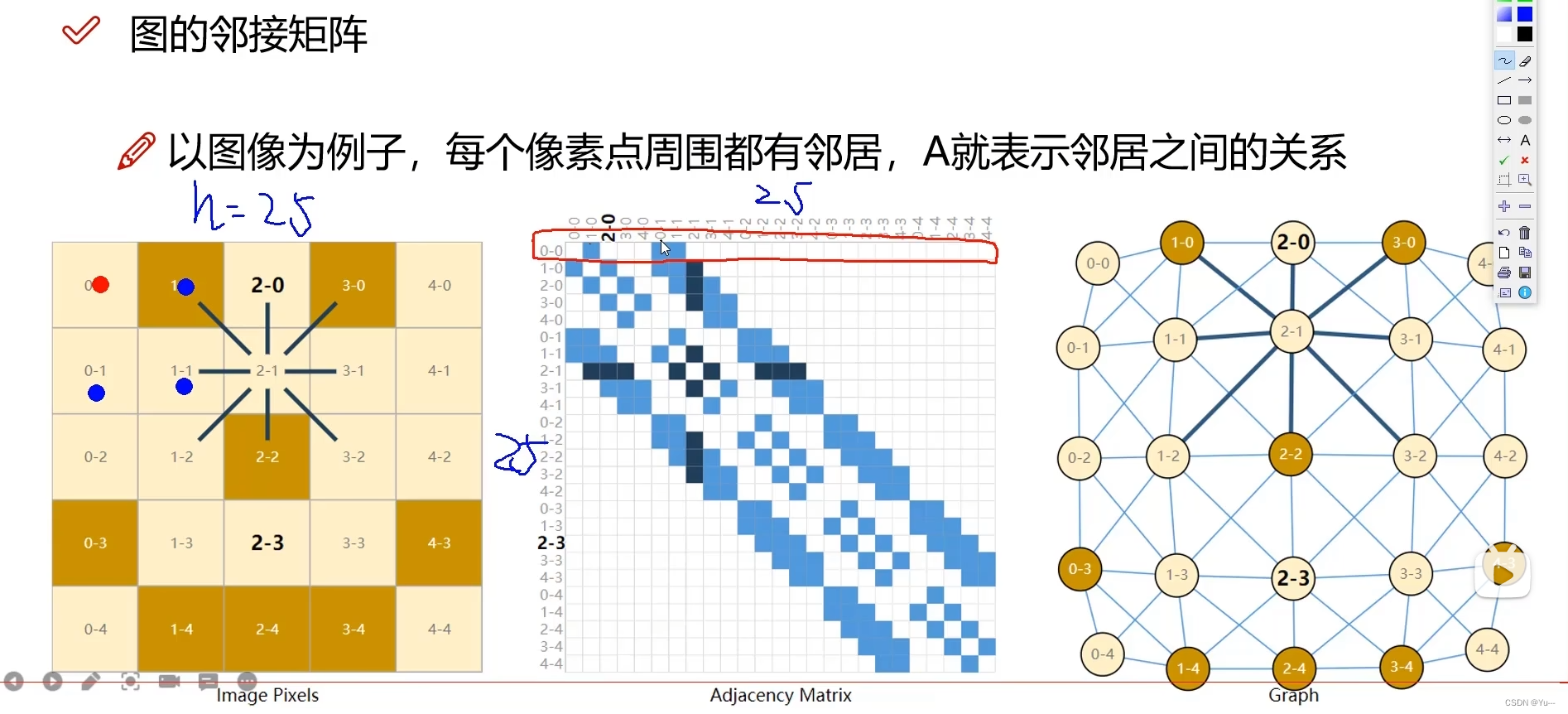
4.邻接矩阵
表示点之间的邻接关系,(谁和谁相连,谁和谁是邻居)
五、GCN(图卷积神经网络)
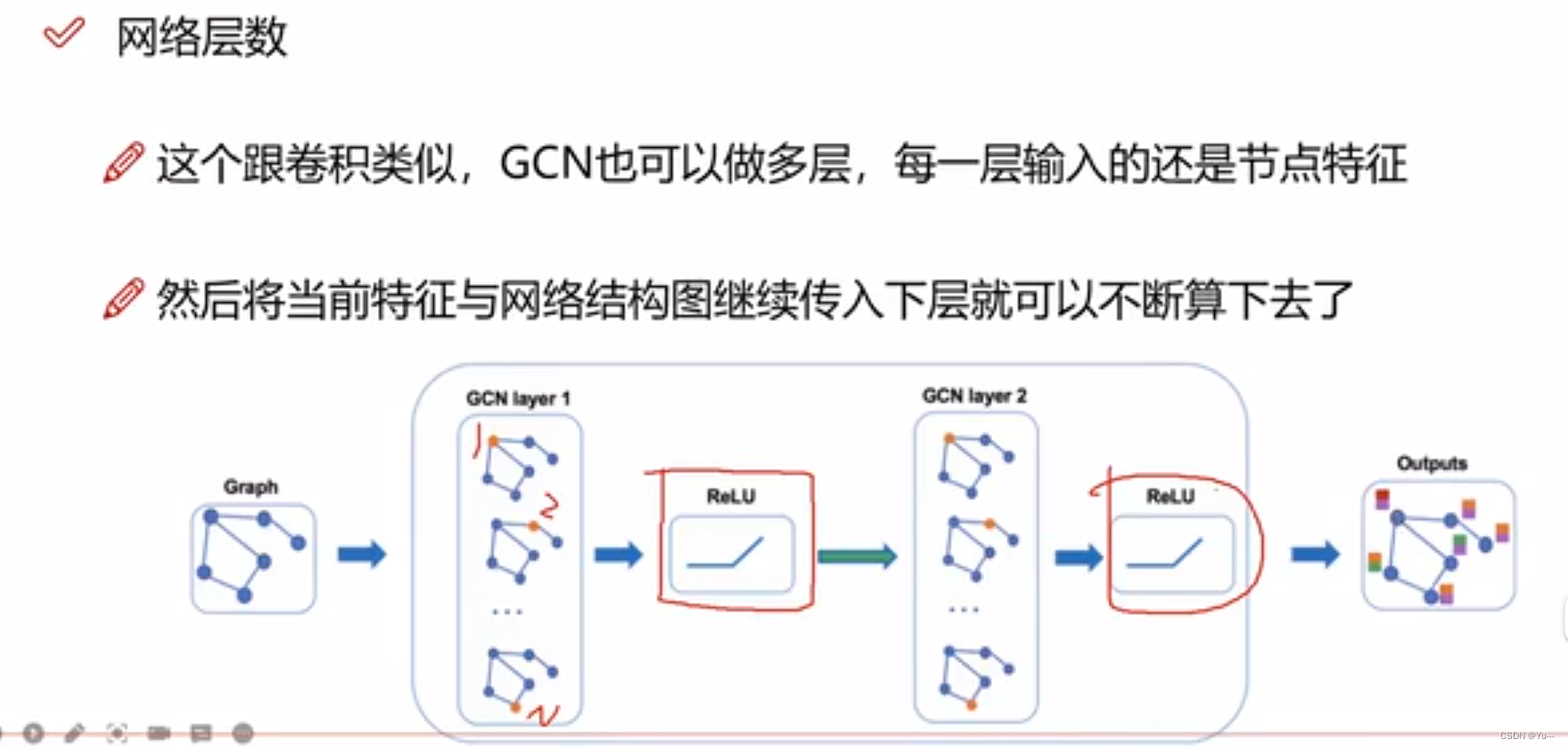
1.GCN基本思想 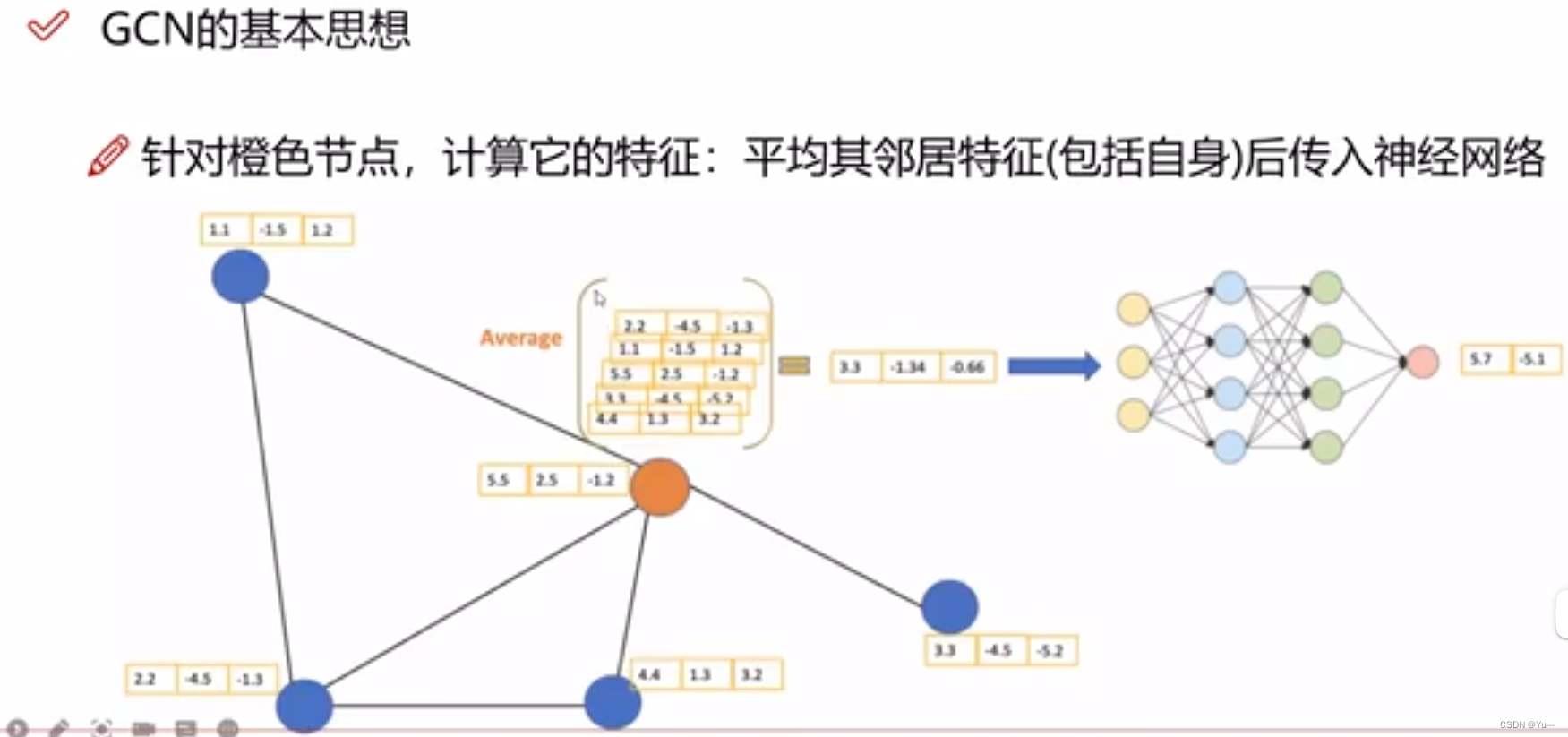

智能推荐
VR全景云端看车,让你享受不一样的购车体验_vr看车-程序员宅基地
文章浏览阅读127次。此外,VR全景看车还可以提供个性化选车服务,根据消费者的喜好和需求来匹配合适的车型,消费者自定义汽车的外观和配置,以此来挑选更符合心意的车辆。消费者通过VR全景技术,身临其境云端看车,720度多角度缩放查看,同传统的图文视频的看车模式相比,VR看车展现的更加详细,3D可视化说明书、热点标注、一键更换外观等,帮助消费者解决了不少的看车难题。除此之外,在VR虚拟车展中,我们还可以适当的添加一些营销活动,例如签到有礼、分享转发、砸金蛋等趣味化游戏,让消费者得到一些购车优惠,这样能更有效提升意向客户的购买率。_vr看车
vue购物车案例,v-model 之 lazy、number、trim,与后端交互_input v-modal原生并实现lazy-程序员宅基地
文章浏览阅读460次,点赞5次,收藏8次。3 axios 第三方ajax,只有ajax,没有别的,小--》底层还是基于XMLHttpRequest。提供了一个 JavaScript 接口,用于访问和操纵 HTTP 管道的一些具体部分。# 1 使用jq的ajax ===》不好---》引入了jq框架,好多功能用不到。number:数字开头,只保留数字,后面的字母不保留;lazy:等待input框的数据绑定时区焦点之后再变化。# 2 原生js fetch。trim:去除首位的空格。_input v-modal原生并实现lazy
Python+Tkinter实现RGB数值转换为16进制码_python_tkinter 颜色16进制代码大全-程序员宅基地
文章浏览阅读158次。设置控件,这里用rVar,gVar,bVar来储存rgb数值,用Scale制作滑块。_tkinter 颜色16进制代码大全
全角半角互相转换_r如何切换全角半角-程序员宅基地
文章浏览阅读185次。【代码】全角半角互相转换。_r如何切换全角半角
02架构管理之研发管理-程序员宅基地
文章浏览阅读178次。研发管理(Research and Development Management,R&D Management)是一种系统性的管理活动,是以产品开发流程为基础的项目管理体系,旨在规划、组织、协调和监督研发项目,对研发项目的人员、计划、质量、成本等进行综合管理,从而打造高效能的研发团队,更好更快地实现项目目标。研发管理的本质是从流程化,标准化,制度化等维度建立管理机制。最终的核心目标是通过管理的法治建立标准化的操作规范,再通过标准化的规范提升人员的协作效率、监督机制、系统稳定性/安全性等。
磁盘访问性能分析及RAID简介_吞吐量和raid关系-程序员宅基地
文章浏览阅读1.3k次。简要介绍了磁盘访问性能相关指标,CPU的交互方式,和RAID_吞吐量和raid关系
随便推点
react 里面的东西居中_react图片居中-程序员宅基地
文章浏览阅读437次。react 里面的东西居中。_react图片居中
zookeeper_zookeeper访问地址-程序员宅基地
文章浏览阅读5.2k次。1.linux下安装完zookeeper之后,进入conf目录编辑zoo.cfg文件,找到dataDir属性更改其路径为zookeeper目录下的zkData文件夹.(因为其默认的目录在Linux下会定清理)(1)进入到zookeeper目录下的bin目录启动zookeeper,使用sh zkServer.sh命令启动zookeeper(或者zkServer.sh start命令启动).(2) 继续在bin目录下使用sh zkCli.sh命令启动zoo..._zookeeper访问地址
windows以G为单位整数分区公式(精准)_win7分盘100g公式-程序员宅基地
文章浏览阅读572次。下面是js的脚本,100G为例:// JS var num = 100Math.ceil(Math.ceil(num*1024/7.84423828125)*7.84423828125)使用方法,只要有浏览器就行,打开浏览器进入开发者模式F12,选择控制台将上面的代码粘贴到控制台中,红字部分为100G应分配的M数.如需其它容量大小自行修改100为对应的值..._win7分盘100g公式
新书推荐|Windows黑客编程技术详解-程序员宅基地
文章浏览阅读70次。《Windows黑客编程技术详解》面向对计算机系统安全开发感兴趣,或者希望提升安全开发水平的读者,以及从事恶意代码分析研究的安全人员。理论技术与实战操作相辅相成,凸显“道与术”庖丁解牛式剖析Windows用户层和内核层黑客技术原理代码兼容性高,支持Windows 7到Windows 10全平台系统近年来,全球大规模爆发勒索病毒和挖..._demongan
【UE4】制作加载图片Splash_ue4 splash image-程序员宅基地
文章浏览阅读5.2k次,点赞7次,收藏18次。很多小伙伴都会有疑惑,有的大神可以有自己独特的加载界面,其实这个编辑过程很简单,今天带大家来一起Try一Try! 长话短说,如果我们不做改变,每一个编辑器加载时的界面都是一样的,那我们怎么样去根据自己的喜好来改变这个logo呢?1.打开虚幻编辑器,项目设置2.项目设置中找到这个更改界面,然后把鼠标放在logo上,我们可以看到这个图片是虚幻自带的文件中原本就默认存在的,那我们就..._ue4 splash image
Acwing算法提高课_acwing提高课-程序员宅基地
文章浏览阅读154次。90%的dp问题都能转化为最短路问题,拓扑图可以转化为dp问题。记住模型,到相似题目就会有更清晰的思路,不会到无从下手。_acwing提高课