https://engineering.linkedin.com/blog/2016/10/building-the-linkedin-knowledge-graph
Authors: Qi He, Bee-Chung Chen, Deepak Agarwal
A shorter version of this post first appeared on Pulse, our main publishing platform at LinkedIn. In this version, we’ll dive deeper into the technical details behind the construction of our knowledge graph.
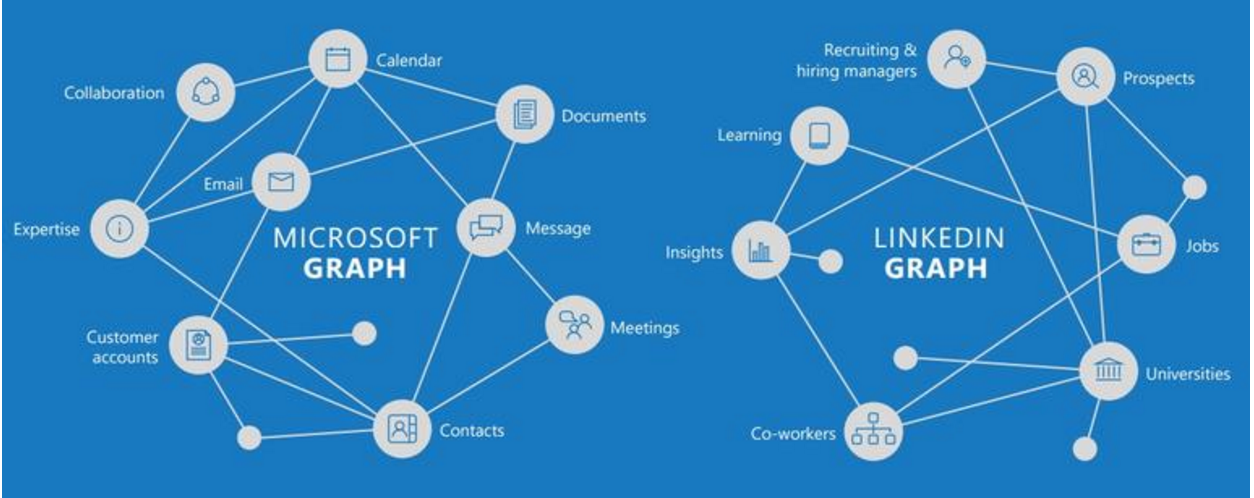
At LinkedIn, we use machine learning technology widely to optimize our products: for instance, ranking search results, advertisements, and updates in the news feed, or recommending people, jobs, articles, and learning opportunities to members. An important component of this technology stack is a knowledge graph that provides input signals to machine learning models and data insight pipelines to power LinkedIn products. This post gives an overview of how we build this knowledge graph.
LinkedIn’s knowledge graph
LinkedIn’s knowledge graph is a large knowledge base built upon “entities” on LinkedIn, such as members, jobs, titles, skills, companies, geographical locations, schools, etc. These entities and the relationships among them form the ontology of the professional world and are used by LinkedIn to enhance its recommender systems, search, monetization and consumer products, and business and consumer analytics.
Creating a large knowledge base is a big challenge. Websites like Wikipedia and Freebase primarily rely on direct contributions from human volunteers. Other related work, such as Google's Knowledge Vault and Microsoft's Satori, focuses on automatically extracting facts from the internet for constructing knowledge bases. Different from these efforts, we derive LinkedIn’s knowledge graph primarily from a large amount of user-generated content from members, recruiters, advertisers, and company administrators, and supplement it with data extracted from the internet, which is noisy and can have duplicates. The knowledge graph needs to scale as new members register, new jobs are posted, new companies, skills, and titles appear in member profiles and job descriptions, etc.
To solve the challenges we face when building the LinkedIn knowledge graph, we apply machine learning techniques, which is essentially a process of data standardization on user-generated content and external data sources, in which machine learning is applied to entity taxonomy construction, entity relationship inference, data representation for downstream data consumers, insight extraction from graph, and interactive data acquisition from users to validate our inference and collect training data. LinkedIn’s knowledge graph is a dynamic graph. New entities are added to the graph and new relationships are formed continuously. Existing relationships can also change. For example, the mapping from a member to her current title changes when she has a new job. We need to update the LinkedIn knowledge graph in real time upon member profile changes and when new entities emerge.
Construction of entity taxonomy
For LinkedIn, an entity taxonomy consists of the identity of an entity (e.g., its identifier, definition, canonical name, and synonyms in different languages, etc.) and the attributes of an entity. Entities are created in two ways:
-
Organic entities are generated by users, where informational attributes are produced and maintained by users. Examples include members, premium jobs, companies created by their administrators, etc.
-
Auto-created entities are generated by LinkedIn. Since the member coverage of an entity (number of members who have this entity) is key to the value that data can drive across both monetization and consumer products, we focus on creating new entities for which we can map members to. By mining member profiles for entity candidates and utilizing external data sources and human validations to enrich candidate attributes, we created tens of thousands of skills, titles, geographical locations, companies, certificates, etc., to which we can map members.
To date, there are 450M members, 190M historical job listings, 9M companies, 200+ countries (where 60+ have granular geolocational data), 35K skills in 19 languages, 28K schools, 1.5K fields of study, 600+ degrees, 24K titles in 19 languages, and 500+ certificates, among other entities.
Entities represent the nodes in the LinkedIn knowledge graph. We need to clean up user-generated organic entities, which can have meaningless names, invalid or incomplete attributes, stale content, or no member mapped to them. We inductively generate rules to identify inaccurate or problematic organic entities. For auto-created entities, the generation process includes:
-
Generate candidates. Each entity has a canonical name which is an English phrase in most cases. Entity candidates are common phrases in member profiles and job descriptions based on intuitive rules.
-
Disambiguate entities. A phrase can have different meanings in different contexts. By representing each phrase as a vector of top co-occurred phrases in member profiles and job descriptions, we developed a soft clustering algorithm to group phrases. An ambiguous phrase can appear in multiple clusters and represent different entities.
-
De-duplicate entities. Multiple phrases can represent the same entity if they are synonyms of each other. By representing each phrase as a word vector (e.g., produced by a word2vec model trained on member profiles and job descriptions), we run a clustering algorithm combined with manual validations from taxonomists to de-duplicate entities. Similar techniques are also used to cluster entities if the taxonomy has a hierarchical structure.
-
Translate entities into other languages. Given the power-law nature of the member coverage of entities, linguistic experts at LinkedIn manually translate the top entities with high member coverages into international languages to achieve high precision, and PSCFG-based machine translation models are applied to automatically translate long-tail entities to achieve high recall.
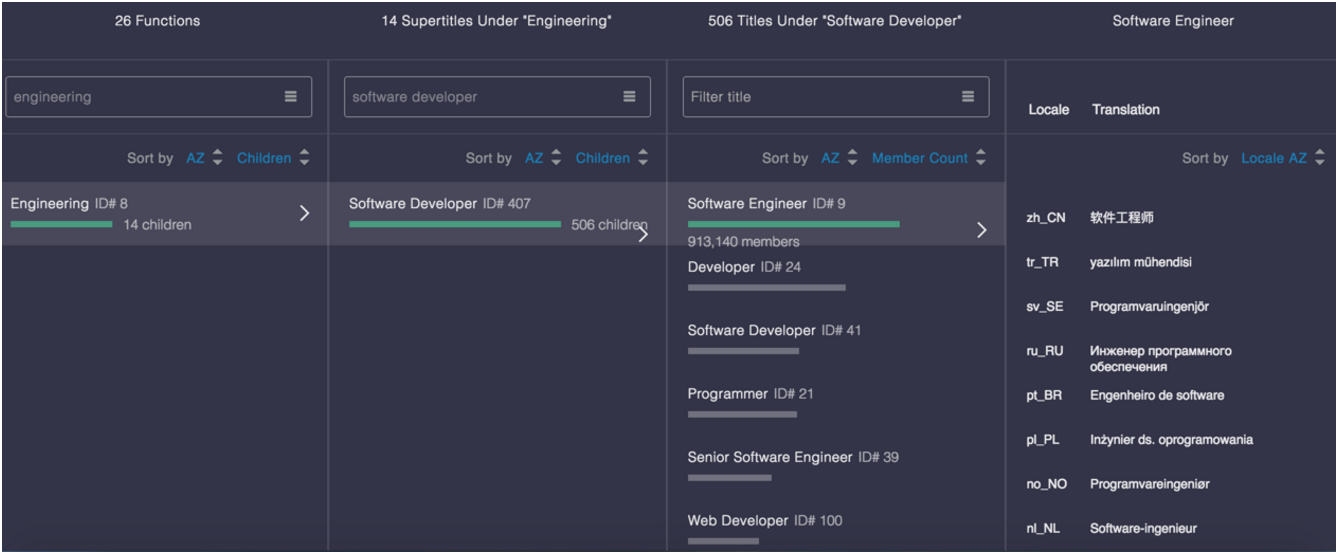
The below figure visualizes an example title entity “Software Engineer” in the title taxonomy. The title taxonomy has a hierarchical structure: similar titles such as “Programmer” and “Web Developer” are clustered into the same supertitle of “Software Developer,” and similar supertitles are clustered into the same function of “Engineering.”
Entity attributes are categorized into two parts: relationships to other entities in a taxonomy, and characteristic features not in any taxonomy. For example, a company entity has attributes that refer to other entities, such as members, skills, companies, and industries with identifiers in the corresponding taxonomies; it also has attributes such as a logo, revenue, and URL that do not refer to any other entity in any taxonomy. The former represents edges in the LinkedIn knowledge graph, which will be discussed in the next section. The latter involves feature extraction from text, data ingestion from search engine, data integration from external sources, and crowdsourcing-based methods, etc.
All entity attributes have confidence scores, either computed by a machine learning model, or assigned to be 1.0 if attributes are human-verified. The confidence scores predicted by machines are calibrated using a separate validation set, such that downstream applications can balance the tradeoff between accuracy and coverage easily by interpreting it as probability.
Inferring entity relationship
There are many valuable relationships between entities in the LinkedIn ecosystem. To name a few, the mappings from members to other entities (e.g., the skills that a member has) are crucial to ad targeting, people search, recruiter search, feed, and business and consumer analytics; the mappings from jobs to other entities (e.g., the skills that a job requires) are driving job recommendations and job search; and similarity between entities are important features in relevance models.
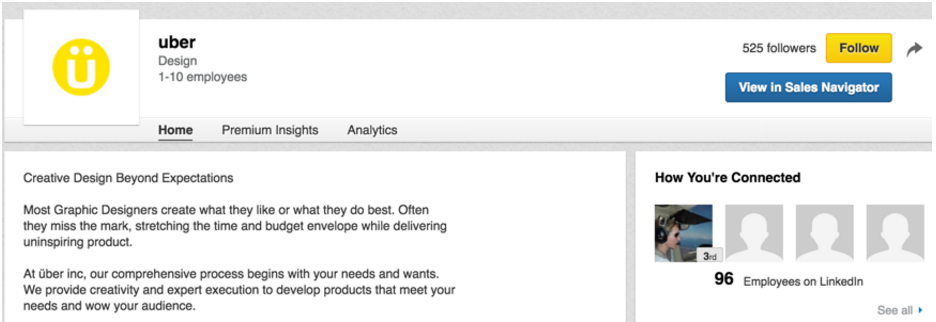
Some entity relationships are generated by members. For example, a member directly selects her company and a company administrator assigns an industry to the company, both from LinkedIn typeahead services. We call these member-generated entity relationships “explicit.” Some entity relationships are predicted by LinkedIn. For example, when a member enters “linkedin_” as her company name in the profile, we predict her true company identifier is associated with “LinkedIn.” We call these LinkedIn-predicted entity relationships “inferred.” Not all explicit relationships are trustworthy, however; one notable problem is “member’s mistake,” where members map themselves to an incorrect entity. In the below figure, a small design firm called “uber” with 1-10 employees has 96 members mapped to it, most of whom mistakenly selected the design firm “uber” from the typeahead, instead of the online transportation network company “Uber” that they actually work at.
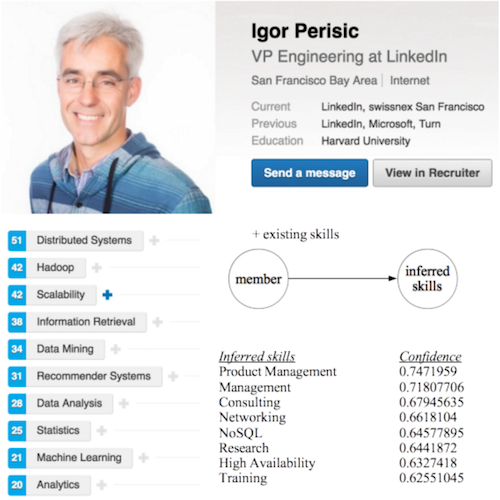
We developed a near real-time content processing framework to infer entity relationships. In total, trillions of member-generated and LinkedIn-inferred relationships co-exist in the LinkedIn knowledge graph. The below figure shows one example of inferring skills for members. Igor, VP of Data at LinkedIn, has a set of explicit skills he entered himself, such as “Distributed Systems,” “Hadoop,” etc. A machine learning model based on text features and other entity metadata features infers other skills, such as “Product Management,” “Management,” “Consulting,” etc. for him.
We train a binary classifier for each kind of entity relationship: a pair of entities belong to a given entity relationship in a binary manner (e.g., belong or not) on the basis of a set of features. Collecting high-quality training data for this supervised task is challenging. We use member-selected relationships from our typeahead service as the positive training examples. By randomly adding noise as the negative training examples, we train per-entity prediction models. This method works well for popular entities. To train a joint model covering entities in the long-tail of the distribution and to alleviate member selection errors, we leverage crowdsourcing to generate additional labeled data.
Inferred relationships are also recommended to members proactively to collect their feedback (“accept,” “decline,” or “ignore”). Accepted ones automatically become explicit relationships. All kinds of member feedback are collected as new training data, which can reinforce the next iteration of classifiers.
Data representation
Entity taxonomies and entity relationships collectively make up the standardized version of LinkedIn data in a graph structure. Equipped with this, all downstream products can speak the same language at the data level. Application teams obtain the raw knowledge graph through a set of APIs that output the entity identifiers by taking either text or other entity identifiers as the input. Various classifier results are represented in various structured formats, and served through Java libraries, REST APIs, Kafka (a high-throughput distributed messaging system) stream events, and HDFS files consistently with data version control. These data delivery mechanisms on the raw knowledge graph are useful for displaying, indexing, and filtering entities in products.
We also embed the knowledge graph into a latent space (background of this research can be found here). As a result, the latent vector of an entity encompasses its semantics in multiple entity taxonomies and multiple entity relationships (classifiers) compactly. After embedding all skills and titles into the same high-dimensional latent space using deep learning techniques, the below figure visualizes skills such as “ActionScript,” “HTML Scripting,” and “PHP” in close proximity to the title “Web Developer” after dimensionality reduction. As can be seen, the semantic proximities between entities in the original knowledge graph are still retained after the embedding.
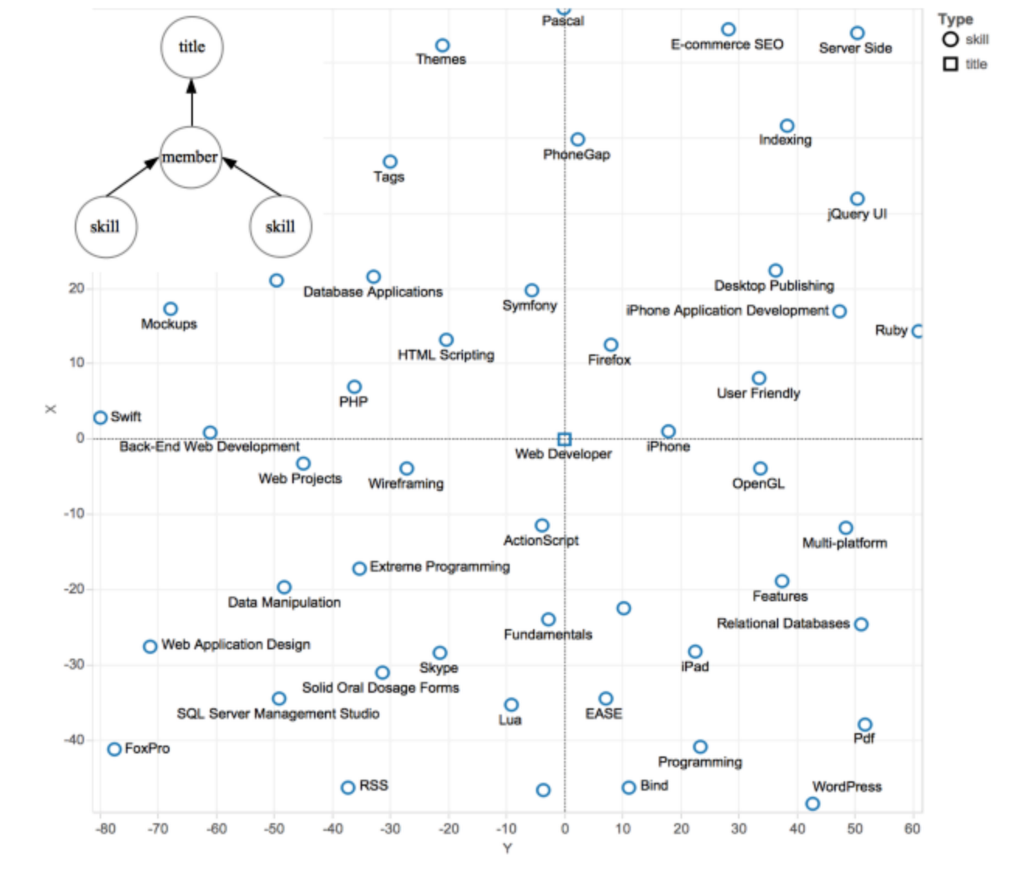
In this example, the model has a single objective, which is to predict a member’s title latent vector based on simple arithmetic operations on the member's skill latent vectors. It is particularly useful to infer the entity relationship from member to title. By optimizing the model for multiple objectives simultaneously, we can then learn latent representations more generically. Representing heterogeneous entities as vectors in the same latent space provides a concise way for using the knowledge graph as a data source from which we can extract various kinds of features to feed relevance models. This is particularly useful to relevance models, as it significantly reduce the feature engineering work on the knowledge graph.
Insights extraction from the graph
Additional knowledge can be inferred on top of the standardized knowledge graph, generating insights for business and consumer analytics. For example, by conducting OLAP to selectively aggregate graph data from different points of view, we can generate real-time insights such as the number of members who have a given skill in a given location (supply), the number of job hires requiring a given skill in that same location (demand), and finally the sophisticated skill gap after considering both supply and demand ends. We can also constrain the data analytics into a certain time range for fetching retrospective insights. The below figure lists the top ten most in-demand soft skills that can help job seekers stand out from other candidates based on data analytics on member profile updates between June 2014 and June 2015.

Insights help leaders and sales make business decisions, and increase member engagement with LinkedIn. For example, the above insights encourage members to add those soft skills to their profiles or learn them in LinkedIn online courses.
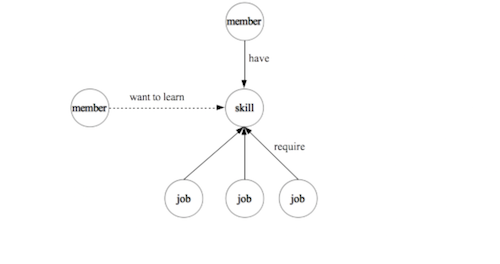
The discovery of data insights from a standardized knowledge graph is an experience-driven data mining process. It can disclose previously undiscerned relationships between entities, which is thus another way of completing the LinkedIn knowledge graph. As shown in the below figure, the above insight example defines a new type of entity relationship from member to skills (“skills you may want to learn”).
Conclusion
Building the LinkedIn knowledge graph includes node (entity) taxonomy construction, edge (entity relationship) inference, and graph representation. Aggregations on top of the graph provide additional insights, some of which can contribute back to further complete the graph. This post is just the start of sharing our experiences, and there is plenty more that we want to discuss in the future, such as applications and insights of the knowledge graph, advanced machine learning techniques in entity classification and representation, and the backend infrastructure.
Acknowledgements
Thanks to Hong Tam for providing the “uber” study case in inferred entity relationship, Uri Merhav for providing the “Web Developer” study case in data representation, Link Gan for providing the “Top 10 Most In-Demand Soft Skills” study case in insights extraction, and the entire LinkedIn Data Standardization team for building the foundations of this incredible work.