Pytorch学习 for hw3(2)Logisitic Regression_不归一化容易发散-程序员宅基地
技术标签: 机器学习 pytorch Hong _YiLi
文章目录
逻辑回归是由概率公式推导产生的,常用来做分类任务,拿手写数字辨识1-10为例:通过计算max{ P ( x = 0 ) , P ( x = 1 ) , . . . , P ( x = 9 ) P(x=0),P(x=1),...,P(x=9) P(x=0),P(x=1),...,P(x=9)},找出最大的概率值即为该x对应的类别。
1、Logisitic Regression
(1)前言
介绍一种下载数据集的方法,但是本次案例未使用到。
在安装pytorch时,有个torchvison工具包可以提供一些比较流行的数据集如MNISIT Dataset(手写数字数据),CIFAR-10(32╳32像素的像图片),但是需要在网上下载,下载方法如下:
import torchvision
train_set = torchvision.datasets.MNIST(root='D:/py文件/Hong YiLee/homework3/dataset/mnist', train=True, download=True)
test_set = torchvision.datasets.MNIST(root='D:/py文件/Hong YiLee/homework3/dataset/mnist', train=False, download=True)
root:若未下载过则标明下载地址,已经下载过则标明数据所在位置
train=True:表示提取的是training data,=False表示提取的是testing data
download=True:表示将在往网上下载,=False表示从本机提取
运行结果如下,就是速度有点慢(开了VPN也慢)

由于是分类问题所以,本次实例和上次的略有区别:现有三个输入x,对应两个分类y=0和y=1,求输入为4时,输出y为多少。
| x | y |
|---|---|
| 1.0 | 0 |
| 2.0 | 0 |
| 3.0 | 1 |
| 4.0 | ? |
所以,进而将问题简化为二分类问题即求P(y=0)、P(y=1),且P(y=1)=1-P(y=0),若P(y=0)>0.5那么y=0。由于P(y=0)可能接近0.5,那么在这种情况下分类器对于该x的类别是不确定的,应该输出“不确定”。
(2)知识点介绍:
可以将二分类问题简化为输出为[0,1]之间的回归问题。那么我们只需要将的线性回归的输出映射到[0,1]即可,而sigmiod函数恰好满足:定义域为(-∞,+∞),值域为(0,1)。当输出y>0.5则被归为1,小于0.5则被归为0。损失函数选用由概率推导出来的cross entropy(交叉熵),简称BCE(Binary Cross Entropy),最后要求和取平均值(对loss求导数的时候1/N会影响lr的大小,加上则不用将lr调的过大)。

torch.nn.BCELoss的参数详解点击链接
torch.nn.Functional的模块包含很多函数,其中有sigmoid函数,我使用的pytorch1.7.1版本已经弃用这种方法,可直接使用torch.sigmoid()
(3)完整代码:
(和Linear Regression差不多)
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
class LogisticRegressionModel(torch.nn.Module):
# 初始化
def __init__(self):
# 初始化从torch.nn.Module继承的属性
super(LogisticRegressionModel, self).__init__()
# 设置实例属性self.linear
self.linear = torch.nn.Linear(1, 1)
# 定义实例方法,添加输入x
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
criterion = torch.nn.BCELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for i in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
输出如下:
能看出随迭代次数的增加loss值在减小,最后一次的loss值为1.0836951732635498。
0 2.484407901763916
1 2.4654228687286377
2 2.44744610786438
3 2.4304330348968506
4 2.4143383502960205
5 2.399118423461914
测试对x=4的y的分类,结果y_pred =0.8407>0.5 所以分类正确
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
# y_pred = tensor([[0.8407]])
(4)查看y(是否通过考试)对x(每日的学习时间)的函数
(实际上并不是函数,是在取多个点之后的预测值绘制的图像)
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 200) # 取1-10之间等间距的200个点,并组成一个列表
x_t = torch.Tensor(x).view((200, 1)) # 将1行的列表转为200行1列的列向量
y_t = model(x_t) # 输入x,调用logistic model
y = y_t.data.numpy() # 将y_data转化为numpy数据才能进行画图
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r') # 画出分界线
plt.xlabel('Hours')
plt.ylabel('Possibility of pass')
plt.grid() # 画出背景网格线
plt.show() # 显示图
由于一使用plt.plot就出现下面的错误
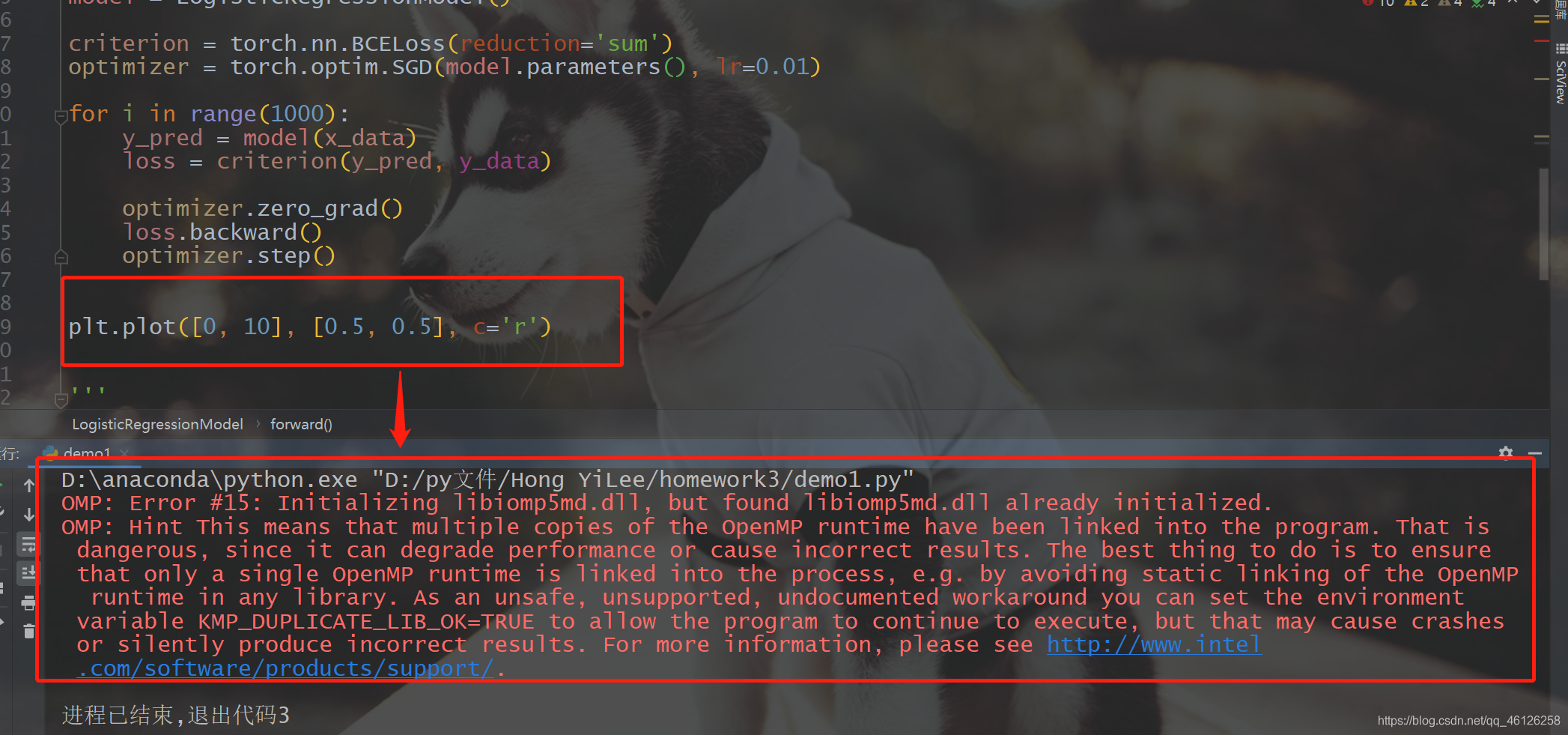
所以添加了一句,问题就解决了
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
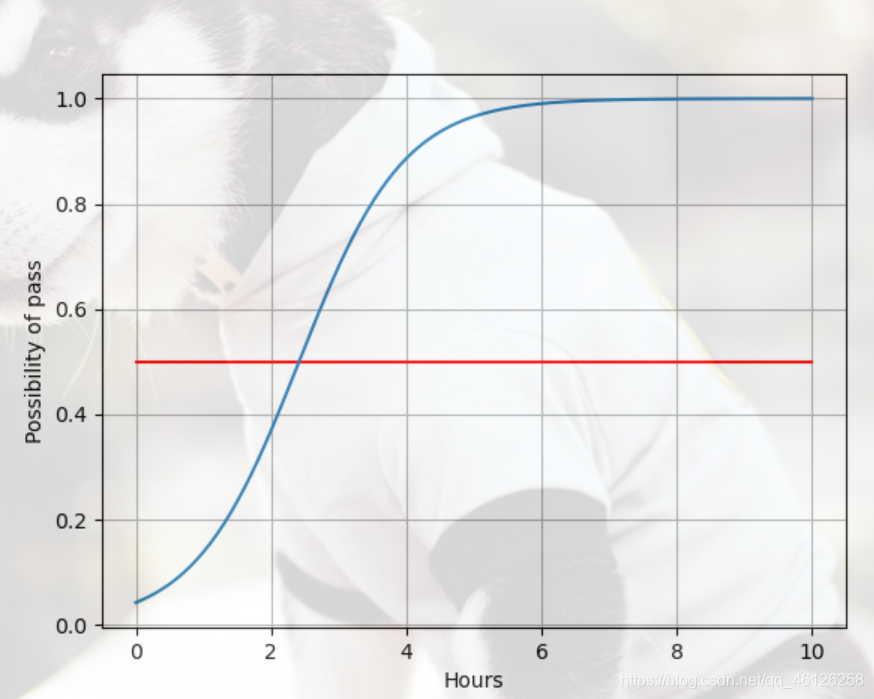
结果如下,可以看到当学习时间为两个小时多的时候就会使possibility达到0.5,也就是y的取值为1,自然当x=4时y的取值也为1.
2、多层神经网络的连接
一层的时候运算过程如下:

可以将单个函数的运算拼成矩阵相乘,进而能够使用GPU加速运算过程。torch.nn.Linear(8,1)表示输入x有8列特征,输出y有1列。

当有三层的时候,可以将矩阵乘法看成维度转换的函数,只需要改变torch.nn.Linear()的参数就可以实现两层神经网络的连接单元数如下:

(1)二分类
在二分类中我们用到糖尿病的数据集(diabetes),通过8个特征辨别其是否患有糖尿病,患病输出y=1,否则y=0。
一、数据集的准备
下载链接:https://pan.baidu.com/s/1udhg5-pvS6UsQlpawmd8-w
提取码: itm0
打开文件如下

开始分离x、y
import numpy as np
xy = np.loadtxt('E:\\自制笔记\\课外\\PyTorch深度学习实践\\diabetes.csv.gz', delimiter=',', dtype=np.float32)
x = torch.from_numpy(xy[:, :-1]) # 取所有行的前8列,并转化为tensor
y = torch.from_numpy(xy[:, [-1]]) # 取所有行的的最后一列
print(x.shape, y.shape)
二、根据继承的模块定义model类
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__() # 初始化从Module继承的方法
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.activation(self.linear3(x))
return x
model = Model()
三、设置loss和optimizer
由于size_average已经被弃用,所以使用reduction='mean’代替来求取平均值。
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
四、迭代更新
for epoch in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
输出结果:
0 0.7159094214439392
1 0.7150604128837585
2 0.7142216563224792
3 0.7133930325508118
4 0.7125746011734009
5 0.7117661237716675
最后的loss值为 0.6668325662612915,当迭代次数达到1000次时,loss值为0.6445940732955933,并趋于稳定。
五、完整代码:
import torch
import numpy as np
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__() # 初始化从Module继承的方法
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.activation(self.linear3(x))
return x
model = Model()
xy = np.loadtxt('E:\\自制笔记\\课外\\PyTorch深度学习实践\\diabetes.csv.gz', delimiter=',', dtype=np.float32)
x = torch.from_numpy(xy[:, :-1]) # 取所有行的前8列,并转化为tensor
y = torch.from_numpy(xy[:, [-1]]) # 取所有行的的最后一列
print(x.shape, y.shape)
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
(2)回归问题
下面的案例是根据sklearn的diabetes数据集来做的回归问题。已知影响糖尿病的10列特征,和对应的target,查看随训练的变化loss的变化。
一、数据集准备:
如果安装了sklearn的话,在anaconda文件夹下能找到下图的路径,里面有自带的数据集,如我的位置是D:\anaconda\Lib\site-packages\sklearn\datasets\data
查看输入x: 打开之后发现WPS和excel并不能将每一列分割(只有两列间为" , "数据才能被分割,这里的是空格所以不能被分割为单独的列)

对应的y如下:
其中最小的为25,最大的为346 ,所以先对y进行归一化处理。不进行归一化结果会发散,loss值会很大。
import torch
import numpy as np
np.random.seed(0) #当我们设置相同的seed,每次生成的随机数相同
print()
# 按照sklearn中包的位置将数据读取出来
x = np.loadtxt('D:\\anaconda\\Lib\site-packages\\sklearn\\datasets\\data\\diabetes_data.csv.gz', delimiter=' ',
dtype=np.float32)
y = np.loadtxt('D:\\anaconda\\Lib\site-packages\\sklearn\\datasets\\data\\diabetes_target.csv.gz', delimiter=' ',
dtype=np.float32)
y = y.reshape(-1, 1) #转为一列
#归一化处理
mean_y = np.mean(y, axis = 0)
std_y = np.std(y, axis = 0)
for i in range(len(y)):
if std_y[0] != 0:
y[i][0] = (y[i][0] - mean_y[0]) / std_y[0]
#创建两个tensor
x = torch.from_numpy(x)
y = torch.from_numpy(y)
# 将数据的行数打乱
def _shuffle(X, Y):
# This function shuffles two equal-length list/array, X and Y, together.
randomize = np.arange(len(X))
np.random.shuffle(randomize)
return (X[randomize], Y[randomize])
x, y = _shuffle(x, y)
二、根据继承的模块定义model类
与二分类类似,但是由于y的输出不再是单个的类别(0、1),所以最后一层不能使用激活函数限制他的值域。
class Model(torch.nn.Module):
# 初始化,并定义激活函数
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(10, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
# 最后一层不要添加激活函数,否则最后的值域会被限制
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.linear3(x)
return x
model = Model()
三、设置loss和optimizer
criterion = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
四、迭代更新
for i in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
结果如下:
0 1.1163854598999023
1 1.0310304164886475
2 1.0081417560577393
3 1.001995325088501
4 1.0003454685211182
随迭代次数增加loss变小,最后趋于稳定为0.9996225833892822
智能推荐
FTP上传下载工具类_vsftp下载工具类-程序员宅基地
文章浏览阅读419次。记录一篇将图片等静态资源上传至vsftpd服务器的工具类package com.zhouym.baiwei.utils;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.i..._vsftp下载工具类
php 得到ashx,ASP.NET-C# Post 一般处理程序(ashx)并得到返回值-程序员宅基地
文章浏览阅读166次。var postUrl = "http://xxx.com/xxp/LoginInfo.ashx";var postString = "method=CheckPW&id=4454556289&pwd=&checkword=8888&sign=";HttpWebRequest httpRequset = null;HttpWebResponse httpRespon..._ashx处理实现响应post请求示例代码
Vim使用之高亮关键字方法-程序员宅基地
文章浏览阅读3.4k次。请注意,以上命令只会影响当前打开的 Vim 编辑器窗口。如果您想要永久更改 Vim 的配置,可以将命令添加到。是您想要使用的颜色主题的名称。例如,要使用 “morning” 主题,可以输入命令。查看当前可用的颜色主题:在 Vim 中,输入命令。,然后按下 Tab 键即可查看当前可用的颜色主题。更改当前的颜色主题:在 Vim 中,输入命令。开启语法高亮:在 Vim 中,输入命令。关闭语法高亮:在 Vim 中,输入命令。
lufylegend.js的简单使用-程序员宅基地
文章浏览阅读826次。js 引入<script type="text/javascript" src="js/lufylegend/lufylegend-1.10.1.min.js"></script>html<div id="legend"></div><img src="" alt="" class="photo_img">..._lufylegend.js
MongoDB入门级保姆教程_mongodb保姆间教程-程序员宅基地
文章浏览阅读687次,点赞3次,收藏4次。MongoDB是文档数据库,旨在简化开发和扩展,本文主要介绍关键概念和基础语句并提供操作和管理上的注意事项。_mongodb保姆间教程
输入若干个正整数,判断每个数从高位到低位各位数字是否按值从小到大排列_输入一批正整数(以零或负数为结束标志),判断每个数从高位到低位的各位数字是否按-程序员宅基地
文章浏览阅读1.1w次,点赞7次,收藏16次。4-2输入若干个正整数,判断每个数从高位到低位各位数字是否按值从小到大排列,请根据题意,将程序补充完整。#include <stdio.h>int fun1(int m);int main(void){ int n; scanf("%d", &n); while (n > 0) { if(fun1(..._输入一批正整数(以零或负数为结束标志),判断每个数从高位到低位的各位数字是否按
随便推点
深度学习和机器学习的区别_机器学习与深度学习的感想-程序员宅基地
文章浏览阅读4.6w次,点赞267次,收藏741次。最近在听深度学习的课,老师提了一个基本的问题:为什么会出现深度学习?或者说传统的机器学习有什么问题。老师讲解的时候一带而过,什么维度灾难啊之类的,可能觉得这个问题太浅显了吧(|| Д)````不过我发现自己确实还不太明白,于是Google了一下,发现一篇很棒的科普文,这里翻译一下,分享给大家:翻译自文章:https://www.analyticsvidhya.com/blog/2017/04/co..._机器学习与深度学习的感想
BCGControlBar教程:使用矢量图形_mfc toolbar 有svg-程序员宅基地
文章浏览阅读421次。BCGControlBar Pro for MFC最新试用版下载请猛戳>>>BCGControlBar库提供了一种在工具栏/菜单/功能区和其他控件中使用可缩放矢量图形(SVG)的非常简单有效的方法。为什么需要使用矢量图形而不是光栅?高DPI支持是当今非常重要的应用程序功能之一:由于越来越多的客户使用高分辨率显示器,该程序应该具有DPI感知能力。许多年前,我们已经实现了..._mfc toolbar 有svg
浙大 | PTA 习题7-7 字符串替换 (15分)_例题3-7 统计英文字母和数字字符[2] 分数 15 作者 颜晖 单位 浙大城市学院 本题要-程序员宅基地
文章浏览阅读2.3k次。本题要求编写程序,将给定字符串中的大写英文字母按以下对应规则替换:原字母 对应字母 A Z B Y C X D W … … X C Y B Z A输入格式:输入在一行中给出一个不超过80个字符、并以回车结束的字符串。输出格式:输出在一行中给出替换完成后的字符串。输入样例:Only the 11 CAPItaL LeTtERS are replaced.输出样例:..._例题3-7 统计英文字母和数字字符[2] 分数 15 作者 颜晖 单位 浙大城市学院 本题要
Bioinformatics | 预测药物-药物相互作用的多模态深度学习框架_ddimdl-程序员宅基地
文章浏览阅读4.1k次,点赞4次,收藏38次。作者 | 朱玉磊审稿 | 李芬今天给大家介绍来自华中农业大学信息学院章文教授课题组在Bioinformatics上发表的一篇关于预测药物与药物相互作用事件的文章。作者提出了一个多模态深度..._ddimdl
制作一个有趣的QQ机器人_qrspeed官网-程序员宅基地
文章浏览阅读7.7k次,点赞19次,收藏72次。如何制作一个有趣的QQ机器人制作一个好玩的QQ机器人(只能手机进行操作哦)题记:这个机器人用来整蛊兄弟或者是在朋友面前装逼都是不错的选择QQ机器人简介机器人效果图机器人制作方法机器人必下软件如何制作机器人词库的编写编写词库的软件词库的编写规则给大家找了一个QR下载的官网(不想加群的兄弟姐妹看这个)结尾题记:这个机器人用来整蛊兄弟或者是在朋友面前装逼都是不错的选择)QQ机器人简介QQ机器人,根据字面意思,就是利用特定的代码,使一个QQ账号成功具备自我反应并作出应答,而这也是我今天想要教你们做的一款最_qrspeed官网
「离散数学」是一门什么样的学科_离散数学学什么-程序员宅基地
文章浏览阅读2.4k次,点赞6次,收藏13次。写这篇文章的动机是想探讨从离散数学开始入门数理逻辑的路径以及离散数学与数理逻辑之间的关系。以学习数理逻辑为目的学习离散数学,而一般的以学习计算机为目的的学习还是有相当的不同,最大的不同就是:以数理逻辑为目的的学习,应当以「证明」 — — 形式证明为目的,这其中包括了关于形式证明的理论 — — 一阶理论的句法和语义,以及关于形式证明的实践 — — 证明框架和策略。学习的中心内容有两个:「语言」 — — 「 一阶语言」;「结构」 — — 数学中关于「结构」的思想、概念、种类、实例以及「结构」和「语言」的关系。_离散数学学什么