嵌入式开发必备知识_嵌入式软件开发的知识清单-程序员宅基地
技术标签: stm32 嵌入式硬件 arm 开发语言 单片机
引言
很多应届生或嵌入式新手在有意向寻找嵌入式软件开发相关工作时,总是觉得不知道该准备些什么,感到无从下手。造成这种现象的原因主要是因为嵌入式需要具备的知识比较杂,既有编程、硬件电路、计算机原理相关的知识,也有通信、操作系统和非计算机行业相关知识。本文详细介绍嵌入式软件开发需要具备的各类知识,帮助想要从事嵌入式相关职业的人能够快速的掌握嵌入式的基本知识。全部掌握后,几乎可以确保读者可以通过市面上大都数初级嵌入式软件开发的技术面试。
以下将通过C/C++必备知识、通信必备知识、操作系统、计算机基础知识和非计算机概念几个部分具体讲解。
C/C++必备知识
include “filename.h”’和include <filename.h>有什么区别?
“filename.h”是从本项目里搜索filename.h,<filename.h> 是从标准库里搜索filename.h文件
静态/非静态、全局/局部 相关知识
问题:“静态全局变量”和“非静态全局变量”有什么区别? “静态局部变量”和“非静态局部变量”有什么区别? “静态函数”和“非静态函数”有什么区别?
静态全局变量只在本文件中定义,其他文件不能引用.
局部变量所在函数每次调用的时候都会被重新分配存储空间,函数结束后,就会回收该存储空间。静态局部变量不会,始终保持当前值。
calloc 和 malloc 有什么区别?
calloc在动态分配完内存后,将内存空间置为零。malloc不初始化,里边数据是随机的脏数据。
static
静态全局变量:在全局变量前,加上关键字static,该变量就被定义成为一个静态全局变量。静态变量在应用层面上主要是限定作用域。
静态全局变量有以下特点:
- 该变量在全局数据区分配内存
- 未经初始化的静态全局变量会被程序自动初始化为0(在函数体内声明的自动变量的值是随机的,除非它被显式初始化,而在函数体外被声明的自动变量也会被初始化为0)
- 静态全局变量在声明它的整个文件都是可见的,而在文件之外是不可见的
静态变量都在全局数据区分配内存,包括后面将要提到的静态局部变量。对于一个完整的程序,在内存中的分布情况:
| 代码区 | low address |
|---|---|
| 全局数据区堆区栈区 | high address |
一般程序把新产生的动态数据存放在堆区,函数内部的自动变量存放在栈区。自动变量一般会随着函数的退出而释放空间,静态数据(即使是函数内部的静态局部变量)也存放在全局数据区。全局数据区的数据并不会因为函数的退出而释放空间。
定义全局变量就可以实现变量在文件中的共享,但定义静态全局变量还有以下好处:
- 静态全局变量不能被其它文件所用
- 其它文件中可以定义相同名字的变量,不会发生冲突
- static在函数中的用法
当函数中定义一个static变量,除了第一次调用这个函数会定义这个变量以外,其他情况下,均不会重新定义了。下面举个例子,对比静态变量和常规变量在函数调用中的区别。
void staticFun(void)
{
static uint8_t data = 0;
data++;
printf("static function data = %d\r\n",data);
}
void NostaticFun(void)
{
uint8_t data = 0;
data++;
printf("no static function data = %d\r\n",data);
}
int main()
{
staticFun();
staticFun();
staticFun();
NostaticFun();
NostaticFun();
NostaticFun();
return 0;
}
执行此程序,主函数会先调用三次staticFun();函数,再调用三次NostaticFun();函数。最后的输出结果为:
1
2
3
1
1
1
因为每次NostaticFun中的data 都会被重新定义,而staticFun中的data不会重复定义。
const
修饰变量
用来修饰不可赋值的变量,如果一个变量在声明初始化之后不希望被修改,可以声明为const;
const修饰的变量应该进行初始化;
const修饰的变量有可能改变,部分编译器可用scanf修改;
const常用来修饰函数的形参,保证该参数在函数内部不会被修改。
修饰指针
- const修饰指针——常量指针( const int *p = &a ),指针的指向可以修改,但是指针指向的值不可以修改。
- const修饰常量——指针常量( int * const p = &a ),指针的指向不可以修改,但是指针指向的值可以修改。
- const即修饰指针,又修饰常量(const int * const p = &a ),指针的指向不可以修改,指针指向的值也不可以修改.
extren
extern表明变量或者函数是定义在其他其他文件中的。用来修饰外部变量(全局),表示该变量在其他文件中定义。首先讲一下声明与定义,
声明不等于定义,声明只是指出了变量的名字,并没有为其分配存储空间;定义指出变量名字同时为变量分配存储空间,定义包含了声明。extern是用来声明全局变量的。注意:在程序中一个变量可以声明多次,但只能定义一次。
volatile
volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,告诉编译器对该变量不做优化,都会直接从变量内存地址中读取数据,从而可以提供对特殊地址的稳定访问。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。(简洁的说就是:volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错)。
在嵌入式系统编程中,将变量声明为volatile通常用于处理硬件寄存器或在不同线程或中断服务例程(ISR)之间共享的变量。它确保编译器不会优化掉对该变量的某些操作,确保其值始终从内存中读取而不是从缓存中读取,并且对变量的写入立即对代码的其他部分可见。
c语言内存分配方式
- 从静态存储区域分配:由编译器自动分配和释放,在程序编译的时候就已经分配好内存,这块内存在程序的整个运行期间都存在,直到整个程序运行结束时才被释放,如全局变量与static变量。
- 在栈上分配
同样由编译器自动分配和释放,在函数执行时,函数内部的局部变量都可以在栈上创建,函数执行结束时,这些存储单元将被自动释放。
(需要注意的是,栈内存分配运算内置于处理器的指令集中,它的运行效率一般很高,但是分配的内存容量有限。) - 从堆上分配
也称为动态分配内存,由程序员手动完成申请和释放。程序在运行的时,由程序员使用内存分配函数(如malloc函数)来申请内存,使用完之后再由程序员自己负责使用内存释放函数(如free函数)来释放内存。
(需要注意的是,如果在堆上分配了内存空间,就必须及时释放它,否则将会导致运行的程序出现内存泄漏等错误)
变量的作用域及生命周期
1.全局变量
从静态存储区域分配,其作用域是全局作用域,也就是整个程序的生命周期内都可以使用。如果程序是由多个源文件构成的,那么全局变量只要在一个文件中定义,就可以在其他所有的文件中使用,但必须在其他文件中通过使用extern关键字来声明该全局变量。
2.全局静态变量
从静态存储区域分配,其生命周期也是与整个程序同在的,从程序开始到结束一直起作用。与全局变量不同的是,全局静态变量作用域只在定义它的一个源文件内,其他源文件不能使用。
3.局部变量
从栈上分配,其作用域只是在局部函数内,在定义该变量的函数内,只要出了该函数,该局部变量就不再起作用,也即该变量的生命周期和该函数同在。
4.局部静态变量
从静态存储区域分配,其在第一次初始化后就一直存在直到程序结束。该变量的特点是其作用域只在定义它的函数内可见,出了该函数就不可见了。
内存对齐(结构体内存大小规则)
基础知识
在 C/C++ 中,结构体/类是一种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构、联合等)的数据单元。编译器为每个成员按其自然边界(alignment)分配空间。各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。
如果一个变量的内存地址正好位于它长度的整数倍,他就被称做自然对齐。如果在 32 位的机器下,一个int类型的地址为0x00000004,那么它就是自然对齐的。同理,short 类型的地址为0x00000002,那么它就是自然对齐的。char 类型就比较 “随意” 了,因为它本身长度就是 1 个字节。自然对其的前提下:
char 偏移量为sizeof(char) 即 1 的倍数
short 偏移量为sizeof(short) 即 2 的倍数
int 偏移量为sizeof(int) 即 4 的倍数
float 偏移量为sizeof(float) 即 4 的倍数
double 偏移量为sizeof(double) 即 8 的倍数
结构体的总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍
实例解析
- 在设置结构体或类时,不考虑内存对齐问题,会浪费一些空间,例如实验一:
struct asd1{
char a;
int b;
short c;
};//12字节
struct asd2{
char a;
short b;
int c;
};//8字节
上面两个结构体拥有相同的数据成员 char、short 和 int,但由于各个成员按照它们被声明的顺序在内存中顺序存储,所以不同的声明顺序导致了结构体所占空间的不同。具体如下图:

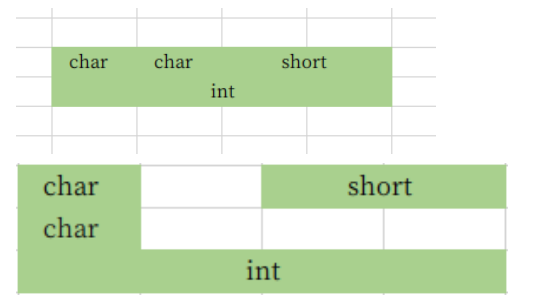
2. 看到上面的第二张图,有的人可能会有疑问,为什么 short 不是紧挨着 char 呢?其实这个原因在上面已经给出了答案——自然对齐。为此,我们可以创建结构体验证自然对齐的规则。实验很简单,在原本 short 类型变量前后添加 char 类型,看结果是怎样的。实验二:
struct asd3{
char a;
char b;
short c;
int d;
};//8字节
struct asd4{
char a;
short b;
char c
int d;
};//12字节
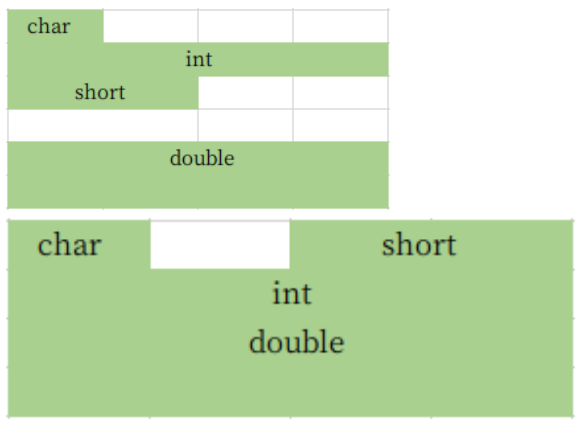
3. 当数据成员中有 double 和 long 时,情况又会有一点变化。还是以上面的结构体 asd1 和 asd2 为基础,都添加 double 型数据成员。来看看结果是什么,实验三:
struct asd1{
char a;
int b;
short c;
double d;
};//24个字节
struct asd2{
char a;
short b;
int c;
double d;
};//16个字节
只添加了一个 double,但 struct asd1 的大小从 12 变到了 24。而 struct asd2 的大小从 8 变到了 16。不需要迷惑,因为这和 double 的自然对其有关(需要注意)。原本的 asd1 占 12 个字节大小,但是 double 对齐需要是 8 的倍数,所以在 short 后面又填充了 4 个字节。此时,asd1 的占 16 个字节,再加上 double 的 8 个字节就成了 24 个字节。而 asd2 没有这个问题,它原本占 8 个字节。因为正好能对齐,所以添加 double 后占 16 个字节。具体情况如下图所示:
4. 指定对齐值
在缺省情况下,C 编译器为每一个变量或是数据单元按其自然对界条件分配空间。一般地,可以通过下面的方法来改变缺省的对界条件:
使用伪指令 #pragma pack (n),C 编译器将按照 n 个字节对齐。
使用伪指令 #pragma pack (),取消自定义字节对齐方式。
实验四:
#pragma pack(4)
struct asd5{
char a;
int b;
short c;
float d;
char e;
};//20
#pragma pack()
#pragma pack(1)
struct asd6{
char a;
int b;
short c;
float d;
char e;
};//12
#pragma pack()
使用 #pragma pack (value) 指令将结构体按相应的值进行对齐。两个结构体包含同样的成员,但是却相差 8 个字节。难道我们只需要通过简单的指令就能完成内存对齐的工作吗?其实不是的。上面的对齐结果如下:

以 32 位机器为例,CPU 取的字长是 32 位。所以上面的对齐结果会这样带来的问题是:访问未对齐的内存,处理器需要作两次内存访问。如果我要获取 int 和 float 的数据,处理器需要访问两次内存,一次获取 “前一部分” 的值,一次获取 “后一部分” 的值。这样做虽然减少了空间,但是增加访问时间的消耗。其实最理想的对齐结果应该是:

ps.使用 #pragma pack(4) 可以让前面的实验三中的 asd1 少占用 4 字节。
对其原则
对齐原则
-
数据类型自身的对齐值:对于 char 型数据,其自身对齐值为1,对于 short 型为2,对于 int,float,double 类型,其自身对齐值为 4,单位字节。
-
结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
-
指定对齐值:#pragma pack (value) 时的指定对齐值 value。
-
数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。
共用体
根据实际情况,有时需要把几种类型不同的数据,如一个整型变量、一个字符变量、一个实型变量存放在起始地址相同的同一段存储单元种。这三个变量在内存种所占的字节数不同,但都从同一个地址开始存放。这种几个类型不同的变量共同占用同一段内存的结构,称为“共用体”类型结构。共用体,也称为联合体。
union 共用体名
{
成员表列
};
共用体变量的所有成员共享同一段存储空间,这个存储空间等于共用体变量种占据内存字节数最多的成员的字节数。
‘##’连接符
##用来连接前后两个参数,把它们变成一个字符串。
例子如下:
#define main(x,y) x##y
int xy=1;
cout < < main(x,y) < < endl;
将会使编译器把
cout < < main(x,y) < < endl;
解释为
cout < < xy < < endl;
理所当然,将会在标准输出处显示’1’。
从此可以看出,x##y的效果就是将x和y连在一起了。
而#define main(x,y) x##y 则相当于把main(x,y)等价于x##y
宏定义与条件变量
#if…#else…#endif
我们在调试程序时,经常会遇到某段功能的实现,写了两种版本的程序,但调试时又不想来回切换。,这时候我们可以使用条件变量。
比如:想测试__set_FAULTMASK(1);和__disable_fault_irq();的区别,就可以使用如下方式,只需要更改#if后面是1还是0就可以选择是使用哪段程序。
#if 1
//
__set_FAULTMASK(1);
NVIC_SystemReset();
#else
__disable_irq();
delay_ms(1000);
__disable_fault_irq();
NVIC_SystemReset();
#endif
string.h 库函数(以memcpy函数为例)
C库函数是我们开发过程中必不可少的,其中面试中突出考察的大多为string.h中的库函数。
memcpy函数的用法,memcpy (void* _Dst,void const* _Src,size_t _Size)
memcpy函数是将后面地址的内容一个数据一个数据放在前面的地址,注意,是先放低位。
_Size是字节数,也就是说如果是32位数组,两个数组值就应该是_Size就应该是4。
例子:
char a[8]={
0x12,0x34,0x56,0x78,0x90,0x14,0x52,0x46 };
short b=0;
memcpy(&b,a+1,2);
printf("b=%x", b);
此段代码的作用是把0x34和0x56拼接起来送到b,输出的最终结果是:0x5634。
void 指针
void 指针可以指向任意类型的数据,就是说可以用任意类型的指针对 void 指针对 void 指针赋值。如果要将 void 指针 p 赋给其他类型的指针,则需要强制类型转换,就本例而言:a=(int *)p。在内存的分配中我们可以见到 void 指针使用:内存分配函数 malloc 函数返回的指针就是 void * 型,用户在使用这个指针的时候,要进行强制类型转换,也就是显式说明该指针指向的内存中是存放的什么类型的数据 (int )malloc(1024) 表示强制规定 malloc 返回的 void 指针指向的内存中存放的是一个个的 int 型数据。
int *Q;
void *P;
P=Q;
我们可以看到void指针类型是可以指向int *指针类型的。
指针大小
在64位系统中,不管什么样的基类型,系统指针给指针变量分配的内存空间都是8字节,在C语言中,指针变量的“基类型”仅用来指定该指针变量可以指向的变量类型,并没有其他意思。 不管基类型是什么类型的指针变量,他仍然是指针变量,所以仍然占用 8 字节。
%*c
%*c表示忽略一个字符
strstr()
此函数在嵌入式的日常开发中使用频繁,功能为:在字符串 A中查找第一次出现字符串B的位置。
C 标准库 - <string.h>
C 库函数 char *strstr(const char *haystack, const char *needle) 在字符串 haystack 中查找第一次出现字符串 needle 的位置,不包含终止符 ‘\0’。
atoi()
C 标准库 - <stdlib.h
描述
C 库函数 int atoi(const char *str) 把参数 str 所指向的字符串转换为一个整数(类型为 int 型)。
rename()
描述
C 库函数 int rename(const char *old_filename, const char *new_filename) 把 old_filename 所指向的文件名改为 new_filename。
参数
old_filename – 这是 C 字符串,包含了要被重命名/移动的文件名称。
new_filename – 这是 C 字符串,包含了文件的新名称。
通信必备知识
UART
介绍
串口(UART通用异步收发器,TTL)通讯是一种设备间的串行全双工通讯方式。由于UART是异步传输,没有传输同步时钟,为了保证数据的正确性,UART采用16倍数据波特率的时钟进行采样。
数据格式
起始位:先发出一个逻辑”0”的信号,表示传输数据的开始。
数据位:可以选择的值有5,6,7,8这四个值,可以传输这么多个值为0或者1的bit位。这个参数最好为8,因为如果此值为其他的值时当你传输的是ASCII值时一般解析肯定会出问题。理由很简单,一个ASCII字符值为8位,如果一帧的数据位为7,那么还有一位就是不确定的值,这样就会出错。
校验位:数据位加上这一位后,使得“1”的位数应为偶数(偶校验)或奇数(奇校验),以此来校验数据传送的正确性。
停止位:它是一帧数据的结束标志。可以是1bit、1.5bit、2bit的空闲电平。
空闲位:没有数据传输时线路上的电平状态。为逻辑1。
UART传输数据顺序
刚开始传输一个起始位,接着传输数据位,接着传输校验位(可不需要此位),最后传输停止位。这样一帧的数据就传输完了。接下来接着像这样一直传送。
发送数据过程
空闲状态,线路处于高电平;当收到发送指令后,拉低线路的一个数据位的时间T,接着数据按低位到高位依次发送,数据发送完毕后,接着发送奇偶校验位和停止位,一帧数据发送完成。
数据接收过程
空闲状态,线路处于高电平;当检测到线路的下降沿(高电平变为低电平)时说明线路有数据传输,按照约定的波特率从低位到高位接收数据,数据接收完毕后,接着接收并比较奇偶校验位是否正确,如果正确则通知后续设备接收数据或存入缓冲。
硬件连接
UART的硬件连接比较简单,只需要两个设备的TXD和RXD相互反接,再将GND相连即可。
IIC
介绍
I2C(IIC)属于两线式串行总线,半双工通信方式,由飞利浦公司开发用于微控制器(MCU)和外围设备(从设备)进行通信的一种总线,属于一主多从(一个主设备(Master),多个从设备(Slave))的总线结构,总线上的每个设备都有一个特定的设备地址,以区分同一I2C总线上的其他设备多个主设备,多个从设备(外围 设备)。多主机会产生总线裁决问题。当多个主机同时想占用总线时,企图启动总线传输数据,就叫做总线竞争。I2C通过总线仲裁,以决定哪台主机控制总线。
IIC总线最主要的优点是其简单性和有效性。由于接口直接在组件之上,因此IIC总线占用的空间非常小,减少了电路板的空间和芯片管脚的数量,降低了互联成本。总线的长度可高达25英尺,并且能够以10Kbps的最大传输速率支持40个组件。
IIC总线的另一个优点是,它支持多主控(multimastering), 其中任何能够进行发送和接收的设备都可以成为主总线。一个主控能够控制信号的传输和时钟频率。当然,在任何时间点上只能有一个主控。
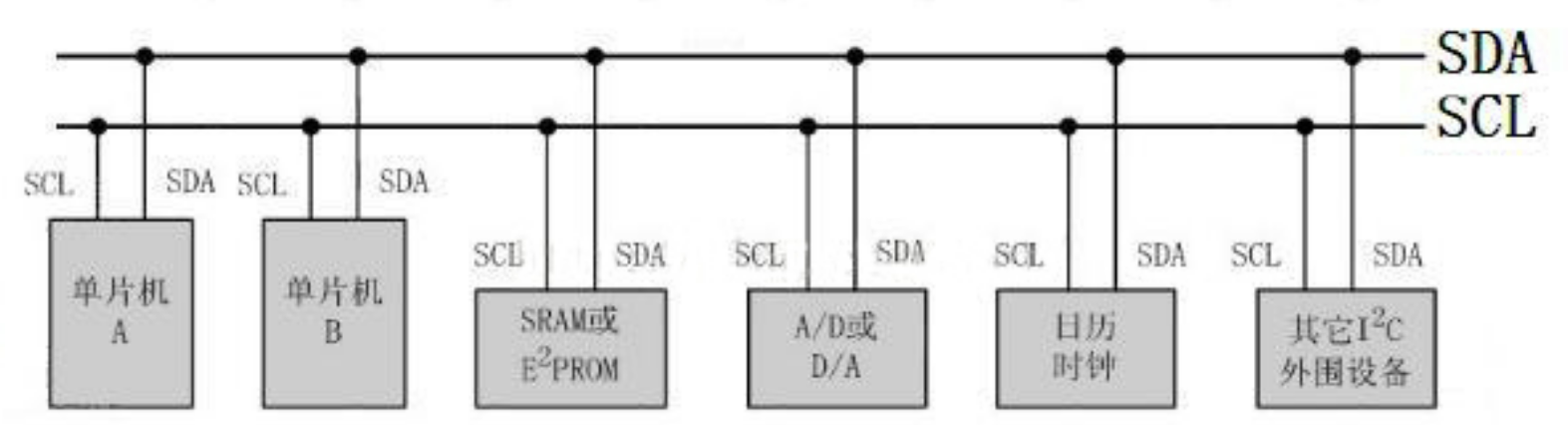
硬件
物理I2C接口有两根双向线,串行时钟线(SCL)和串行数据线(SDA)组成,可用于发送和接收数据,但是通信都是由主设备发起,从设备被动响应,实现数据的传输。上拉电阻一般在4.7k~10k之间。所有接到IIC总线设备上的串行数据SDA都接到总线的SDA上,各设备的时钟线SCL接到总线的SCL上。对于并联在一条总线上的每个IC都有唯一的地址。一般情况下,数据线SDA和时钟线SCL都是处于上拉电阻状态。因为:在总线空闲状态时,这两根线一般被上面所接的上拉电阻拉高,保持着高电平。
SPI
介绍
SPI,是一种高速的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线,节约了芯片的管脚,同时为PCB的布局上节省空间,提供方便,主要应用在 EEPROM,FLASH,实时时钟,AD转换器,还有数字信号处理器和数字信号解码器之间。
SPI主从模式
SPI分为主、从两种模式,一个SPI通讯系统需要包含一个(且只能是一个)主设备,一个或多个从设备。提供时钟的为主设备(Master),接收时钟的设备为从设备(Slave),SPI接口的读写操作,都是由主设备发起。当存在多个从设备时,通过各自的片选信号进行管理。
SPI是全双工且SPI没有定义速度限制,一般的实现通常能达到甚至超过10 Mbps。
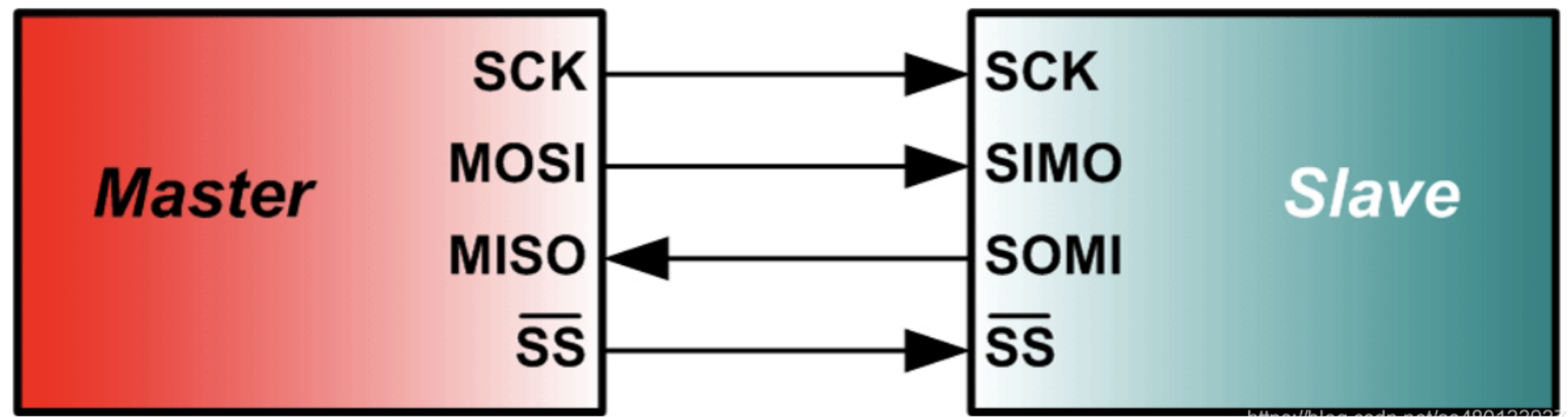
硬件
SPI接口一般使用四条信号线通信:
SDI(数据输入),SDO(数据输出),SCK(时钟),CS(片选)
MISO: 主设备输入/从设备输出引脚。该引脚在从模式下发送数据,在主模式下接收数据。
MOSI: 主设备输出/从设备输入引脚。该引脚在主模式下发送数据,在从模式下接收数据。
SCLK:串行时钟信号,由主设备产生。
CS/SS:从设备片选信号,由主设备控制。它的功能是用来作为“片选引脚”,也就是选择指定的从设备,让主设备可以单独地与特定从设备通讯,避免数据线上的冲突。
硬件上为4根线。
- SPI一对一
- 一对多

非计算机概念
电源相关
DC+:控制电源+
DC-:控制电源-
DP+:驱动电源+
DP-:驱动电源-
电机相关
RPM
电机的速度单位: 转/分。
减速比
减速比,即减速装置的传动比,是一种传动比,是指减速机构中瞬时输入速度与输出的速度的比值,用符号i表示。一般来说,减速比的表示方法是以1为分母,以:连接的輸入转速与输出转速之比。要是輸入转速为1500r/min,输出转速为25r/min,则其减速比为:i=60:1。
电机速度转换方式
一般上位机控制下位机,下位机控制电机。上位机下发的速度一般单位是m/s,而下位机对电机下发的速度,应该是RPM。
- 减速比:REDUCITON_RATIO
- Π :PI
- 轮子半径:R
- 电机旋转速度:LSpeed
- 实际线速度:Speed
LSpeed= Speed * REDUCITON_RATIO * 60 / (2 * PI* R)
程序内存分布(ROM、RAM)
一般 MCU 包含的存储空间有:片内 Flash 与片内 RAM,RAM 相当于内存,Flash 相当于硬盘。编译器会将一个程序分类为好几个部分,分别存储在 MCU 不同的存储区。
上面提到的 Program Size 包含以下几个部分:
-
Code:代码段,存放程序的代码部分;
-
RO-data:只读数据段,存放程序中定义的常量;
-
RW-data:读写数据段,存放初始化为非 0 值的全局变量;
-
ZI-data:0 数据段,存放未初始化的全局变量及初始化为 0 的变量;
编译完工程会生成一个. map 的文件,该文件说明了各个函数占用的尺寸和地址。
- RO Size 包含了 Code 及 RO-data,表示程序占用 Flash 空间的大小;
- RW Size 包含了 RW-data 及 ZI-data,表示运行时占用的 RAM 的大小;
- ROM Size 包含了 Code、RO-data 以及 RW-data,表示烧写程序所占用的 Flash 空间的大小;
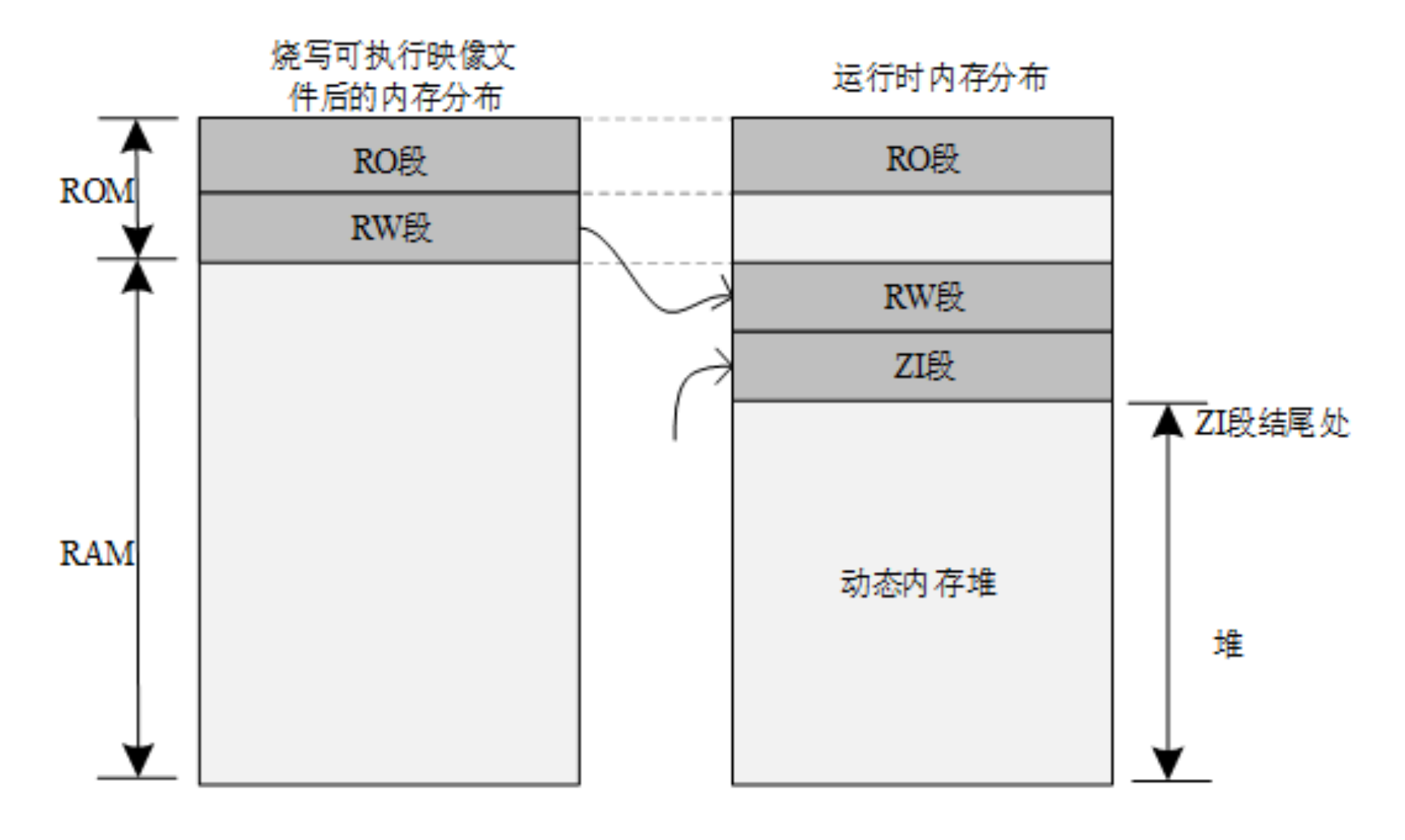
程序运行之前,需要有文件实体被烧录到 STM32 的 Flash 中,一般是 bin 或者 hex 文件,该被烧录文件称为可执行映像文件。如下图左边部分所示,是可执行映像文件烧录到 STM32 后的内存分布,它包含 RO 段和 RW 段两个部分:其中 RO 段中保存了 Code、RO-data 的数据,RW 段保存了 RW-data 的数据,由于 ZI-data 都是 0,所以未包含在映像文件中。
STM32 在上电启动之后默认从 Flash 启动,启动之后会将 RW 段中的 RW-data(初始化的全局变量)搬运到 RAM 中,但不会搬运 RO 段,即 CPU 的执行代码从 Flash 中读取,另外根据编译器给出的 ZI 地址和大小分配出 ZI 段,并将这块 RAM 区域清零。
- 其中动态内存堆为未使用的 RAM 空间,应用程序申请和释放的内存块都来自该空间。
比如:msg = (rt_uint8_t*) rt_malloc (40);
代码中的 ms 指针指向的 40字节内存空间位于动态内存堆空间中。 - 而一些全局变量则是存放于 RW 段和 ZI 段中,RW 段存放的是具有初始值的全局变量(而常量形式的全局变量则放置在 RO 段中,是只读属性的),ZI 段存放的系统未初始化的全局变量。
const static uint32_t A = 0x000000FE; uint32_t B; uint8_t C = 0;B 存放在 ZI 段中,系统启动后会自动初始化成零(由用户程序或编译器提供的一些库函数初始化成零)。C 变量则存放在 RW 段中,而 A 存放在 RO 段中。
智能推荐
2022黑龙江最新建筑八大员(材料员)模拟考试试题及答案_料账的试题-程序员宅基地
文章浏览阅读529次。百分百题库提供建筑八大员(材料员)考试试题、建筑八大员(材料员)考试预测题、建筑八大员(材料员)考试真题、建筑八大员(材料员)证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。310项目经理部应编制机械设备使用计划并报()审批。A监理单位B企业C建设单位D租赁单位答案:B311对技术开发、新技术和新工艺应用等情况进行的分析和评价属于()。A人力资源管理考核B材料管理考核C机械设备管理考核D技术管理考核答案:D312建筑垃圾和渣土._料账的试题
chatgpt赋能python:Python自动打开浏览器的技巧-程序员宅基地
文章浏览阅读614次。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。AI职场汇报智能办公文案写作效率提升教程 专注于AI+职场+办公方向。下图是课程的整体大纲下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具。_python自动打开浏览器
Linux中安装JDK-RPM_linux 安装jdk rpm-程序员宅基地
文章浏览阅读545次。Linux中安装JDK-RPM方式_linux 安装jdk rpm
net高校志愿者管理系统-73371,计算机毕业设计(上万套实战教程,赠送源码)-程序员宅基地
文章浏览阅读25次。免费领取项目源码,请关注赞收藏并私信博主,谢谢-高校志愿者管理系统主要功能模块包括页、个人资料(个人信息。修改密码)、公共管理(轮播图、系统公告)、用户管理(管理员、志愿用户)、信息管理(志愿资讯、资讯分类)、活动分类、志愿活动、报名信息、活动心得、留言反馈,采取面对对象的开发模式进行软件的开发和硬体的架设,能很好的满足实际使用的需求,完善了对应的软体架设以及程序编码的工作,采取SQL Server 作为后台数据的主要存储单元,采用Asp.Net技术进行业务系统的编码及其开发,实现了本系统的全部功能。
小米宣布用鸿蒙了吗,小米OV对于是否采用鸿蒙保持沉默,原因是中国制造需要它们...-程序员宅基地
文章浏览阅读122次。原标题:小米OV对于是否采用鸿蒙保持沉默,原因是中国制造需要它们目前华为已开始对鸿蒙系统大规模宣传,不过中国手机四强中的另外三家小米、OPPO、vivo对于是否采用鸿蒙系统保持沉默,甚至OPPO还因此而闹出了一些风波,对此柏铭科技认为这是因为中国制造当下需要小米OV几家继续将手机出口至海外市场。 2020年中国制造支持中国经济渡过了艰难的一年,这一年中国进出口贸易额保持稳步增长的势头,成为全球唯一..._小米宣布用鸿蒙系统
Kafka Eagle_kafka eagle git-程序员宅基地
文章浏览阅读1.3k次。1.Kafka Eagle实现kafka消息监控的代码细节是什么?2.Kafka owner的组成规则是什么?3.怎样使用SQL进行kafka数据预览?4.Kafka Eagle是否支持多集群监控?1.概述在《Kafka 消息监控 - Kafka Eagle》一文中,简单的介绍了 Kafka Eagle这款监控工具的作用,截图预览,以及使用详情。今天_kafka eagle git
随便推点
Eva.js是什么(互动小游戏开发)-程序员宅基地
文章浏览阅读1.1k次,点赞29次,收藏19次。Eva.js 是一个专注于开发互动游戏项目的前端游戏引擎。:Eva.js 提供开箱即用的游戏组件供开发人员立即使用。是的,它简单而优雅!:Eva.js 由高效的运行时和渲染管道 (Pixi.JS) 提供支持,这使得释放设备的全部潜力成为可能。:得益于 ECS(实体-组件-系统)架构,你可以通过高度可定制的 API 扩展您的需求。唯一的限制是你的想象力!_eva.js
OC学习笔记-Objective-C概述和特点_objective-c特点及应用领域-程序员宅基地
文章浏览阅读1k次。Objective-C概述Objective-C是一种面向对象的计算机语言,1980年代初布莱德.考斯特在其公司Stepstone发明Objective-C,该语言是基于SmallTalk-80。1988年NeXT公司发布了OC,他的开发环境和类库叫NEXTSTEP, 1994年NExt与Sun公司发布了标准的NEXTSTEP系统,取名openStep。1996_objective-c特点及应用领域
STM32学习笔记6:TIM基本介绍_stm32 tim寄存器详解-程序员宅基地
文章浏览阅读955次,点赞20次,收藏16次。TIM(Timer)定时器定时器可以对输入的时钟进行计数,并在计数值达到设定值时触发中断16位计数器、预分频器、自动重装寄存器的时基单元,在 72MHz 计数时钟下可以实现最大 59.65s 的定时,59.65s65536×65536×172MHz59.65s65536×65536×721MHz不仅具备基本的定时中断功能,而且还包含内外时钟源选择、输入捕获、输出比较、编码器接口、主从触发模式等多种功能。_stm32 tim寄存器详解
前端基础语言HTML、CSS 和 JavaScript 学习指南_艾编程学习资料-程序员宅基地
文章浏览阅读1.5k次。对于任何有兴趣学习前端 Web 开发的人来说,了解 HTML、CSS 和JavaScript 之间的区别至关重要。这三种前端语言都是您访问过的每个网站的用户界面构建块。而且,虽然每种语言都有不同的功能重点,但它们都可以共同创建令人兴奋的交互式网站,让用户保持参与。因此,您会发现学习所有三种语言都很重要。如果您有兴趣从事前端开发工作,可以通过多种方式学习这些语言——在艾编程就可以参与到学习当中来。在本文中,我们将回顾每种语言的特征、它们如何协同工作以及您可以在哪里学习它们。HTML vs C._艾编程学习资料
三维重构(10):PCL点云配准_局部点云与全局点云配准-程序员宅基地
文章浏览阅读2.8k次。点云配准主要针对点云的:不完整、旋转错位、平移错位。因此要得到完整点云就需要对局部点云进行配准。为了得到被测物体的完整数据模型,需要确定一个合适的坐标系变换,将从各个视角得到的点集合并到一个统一的坐标系下形成一个完整的数据点云,然后就可以方便地进行可视化,这就是点云数据的配准。点云配准技术通过计算机技术和统计学规律,通过计算机计算两个点云之间的错位,也就是把在不同的坐标系下的得到的点云进行坐标变..._局部点云与全局点云配准
python零基础学习书-Python零基础到进阶必读的书藉:Python学习手册pdf免费下载-程序员宅基地
文章浏览阅读273次。提取码:0oorGoogle和YouTube由于Python的高可适应性、易于维护以及适合于快速开发而采用它。如果你想要编写高质量、高效的并且易于与其他语言和工具集成的代码,《Python学习手册:第4 版》将帮助你使用Python快速实现这一点,不管你是编程新手还是Python初学者。本书是易于掌握和自学的教程,根据作者Python专家Mark Lutz的著名培训课程编写而成。《Python学习..._零基础学pythonpdf电子书