9.1、面向对象编程_选定具体的目标(比如:猫狗花草等等),进行父类和子类的抽象化建模,确定属性和方法;-程序员宅基地
文章目录
python是面向对象的编程语言
面向对象编程简介
“面向过程”(Procedure Oriented)是一种以过程为中心的编程思想。分析出解决问题所需要的步
骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。【按照过程一步一步执行】【C语言就是面向过程的语言】
面向对象的方法也是含有面向过程的思想。面向过程最重要的是模块化的思想方
法。 比如拿学生早上起来这件事说明面向过程,粗略的可以将过程拟为:
(1)起床
(2)穿衣
(3)洗脸刷牙
(4)去学校
而这4步就是一步一步地完成,它的顺序很重要,你只需要一个一个地实现就行了。
而如果是用面向对象的方法的话,可能就只抽象出一个学生的类,它包括这四个
方法,但是具体的顺序就不一定按照原来的顺序。
特点:模块化 流程化
优点:
性能比面向对象高, 因为类调用时需要实例化,开销比较大,比较消耗资源
缺点:
没有面向对象易维护、易复用、易扩展
面向对象编程
面向对象是按人们认识客观世界的系统思维方式,把构成问题事务分解成各个对象,建立对
象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
面向对象的编程语言有C++、Java、python等
特性: 抽象 封装 继承 多态
优点: 易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,
可以设计出低耦合 的系统,使系统更加灵活、更加易于维护
缺点: 性能比面向过程低
面向对象编程的三大特性
对象和类
抽象的、无法想象出实物的就是类
具体的、能描述出具体细节的就是对象,对象是对类的具体化、实例化
类(Class)是现实或思维世界中的实体在计算机中的反映,它将数据以及这些数
据上的操作封装在一起。类是创建实例的模板
对象(Object)是具有类类型的变量。对象是一个一个具体的实例。
类和对象是面向对象编程技术中的最基本的概念。
#类Class
class Cat:
#属性:一般是名词,比如年龄,性别,姓名
name='cat1'
kind='英短蓝猫'
# 方法:一般是动词,比如创建,删除,运行
def eat(self):
print('cat eat fish...')
#对象:是对类的实例化、具体化
c=Cat()
print(Cat) #__main__表示当前python文件,当前文件下的Cat类
print(c) #当前文件下的Cat类实例化的对象,所处内存空间为0x00000218CB501250

封装
对于面向对象的封装来说,其实就是使用构造方法将内容封装到对象中,然后通过
对象直接或者self间接获取被封装的内容
在使用面向对象的封装特性时,需要:
(1)将内容封装到某处
(2) 从某处调用被封装的内容
(2.1)通过对象直接调用被封装的内容: 对象.属性名
(2.2) 通过self间接调用被封装的内容: self.属性名
(2.3)通过self间接调用被封装的内容: self.方法名()
_ _ init _ _(self)构造方法是实例化对象时自动执行的方法
self 实质上是实例化的对象,python解释器会自动把对象作为参数传给self
#类Class
class Cat:
def __init__(self, name, kind): #python默认将形参设置为self,也可以将self换个名字,但是不建议
print('执行__init__(self)方法')
print('self:',self)
#封装:将self.name和name属性绑定(或封装)
self.name=name
self.kind= kind
def eat(self):
print('%s lisk eat fish...' %(self.name))
#对象:是对类的实例化、具体化
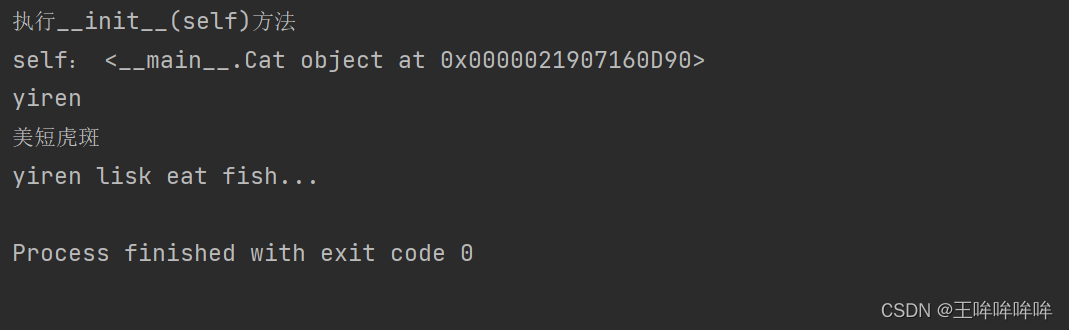
c=Cat('yiren','美短虎斑')
print(c.name) #调用封装的内容
print(c.kind)
c.eat()
class people:
def __init__(self,name,gender,age):
self.name=name
self.gender=gender
self.age=age
def shopping(self):
print(f'{
self.name},{
self.age},{
self.gender}去商场购物')
def learning(self):
print(f'{
self.name},{
self.age},{
self.gender}去学习')
def playgame(self):
print(f'{
self.name},{
self.age},{
self.gender}去玩游戏')
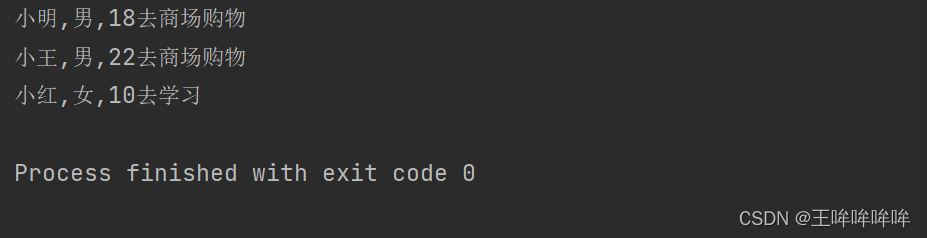
p1=people('小明',18,'男')
p2=people('小王',22,'男')
p3=people('小红',10,'女')
p1.shopping()
p2.shopping()
p3.learning()
继承
什么是继承
继承描述的是事物之间的所属关系,当我们定义一个class的时候,可以从某个现有的class
继承,新的class称为子类、扩展类(Subclass),而被继承的class称为基类、父类或超类(Baseclass、Superclass)。
如何让实现继承?
子类在继承的时候,在定义类时,小括号()中为父类的名字
继承的工作机制:
父类的属性、方法,会被继承给子类。 举例如下: 如果子类没有定义__init__方法,父类有,那
么在子类继承父类的时候这个方法就被继承了,所以只要创建对象,就默认执行了那个继承过来的
__init__方法。
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def learning(self):
print(f'{
self.name}正在学习')
class MathStudent(Student): #继承父类Student
pass
s1=MathStudent('alice','18')
print(s1.name)
print(s1.age)
s1.learning() #子类没有,但是父类有该方法
#s1.ChoiceCourse() #子类没有,而且父类也没有该方法,会报错

重写父类方法
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def learning(self):
print(f'{
self.name}正在学习')
def Choicecourse(self):
print('正在选课中'.center(50,'*'))
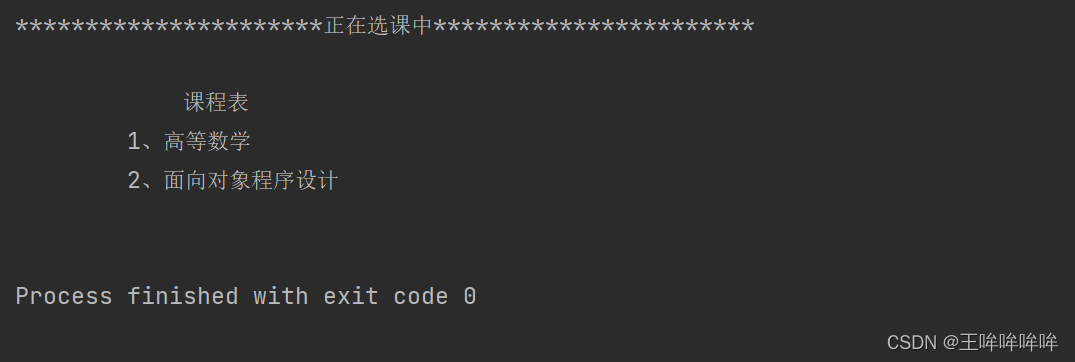
class MathStudent(Student): #继承父类Student
def Choicecourse(self):
info="""
课程表
1、高等数学
2、面向对象程序设计
"""
print(info)
s1=MathStudent('alice','18')
s1.Choicecourse()

需求:先执行父类的方法,在执行自己的个性化方法
方法一:在子类的方法中写明执行父类的方法,不建议,因为父类可能是会改变的,可能还需要修改代码
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def learning(self):
print(f'{
self.name}正在学习')
def Choicecourse(self):
print('正在选课中'.center(50,'*'))
class MathStudent(Student): #继承父类Student
def Choicecourse(self):
# 方法一:不建议
Student.Choicecourse(self)
info="""
课程表
1、高等数学
2、面向对象程序设计
"""
print(info)
s1=MathStudent('alice','18')
s1.Choicecourse()
方法二:通过super找到父类,再执行对应的方法,建议且生产环境中代码常用的方法
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def learning(self):
print(f'{
self.name}正在学习')
def Choicecourse(self):
print('正在选课中'.center(50,'*'))
class MathStudent(Student): #继承父类Student
def Choicecourse(self):
# 方法二:建议
super(MathStudent,self).Choicecourse()
info="""
课程表
1、高等数学
2、面向对象程序设计
"""
print(info)
s1=MathStudent('alice','18')
s1.Choicecourse()
多继承
多继承,即子类有多个父类,并且具有多个父类的特征。
在Python 2及以前的版本中,由任意内置类型派生出的类,都属于“新式
类”,都会获得所有“新式类”的特性;反之,即不由任意内置类型派生出的类,
则称之为“经典类”。
 python3中都是新式类。
python3中都是新式类。
新式类和经典类最明显的区别就在于继承搜索的顺序不同,即
经典类多继承搜索顺序(深度优先算法):先深入继承树左侧查找,然后再返回,开始查找右侧。
新式类多继承搜索顺序(广度优先算法):先在水平方向查找,然后再向上查找
比如有一个A类,A有两个父类分别为B和C,B的父类为D类。C的父类也为D类
A要执行一个方法,如果A没有,就会向父类B搜索,如果B也没有,那么是继续找B的父类呢?还是找A的另一个父类C呢?
对于经典类来说,会优先找父类的父类,即优先找D类。【深度优先算法】
对于新式类来说,会优先找同一层另外一个父类,即优先找C类。【广度优先算法】
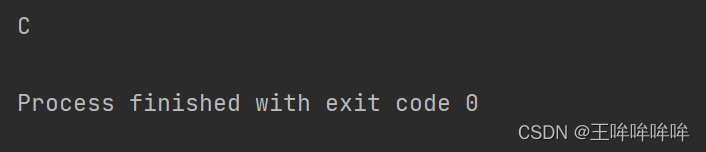
class D(object):
def hello(self):
print('D')
class C(D):
def hello(self):
print('C')
class B(D):
pass
class A(B, C):
pass
a = A()
a.hello()
 类A中没有hello方法,所以会向其父类B中搜索,B类也没有。由于python3中都是新式类。新式类采用广度优先搜索策略,所以接着会向另一个父类C中搜索。
类A中没有hello方法,所以会向其父类B中搜索,B类也没有。由于python3中都是新式类。新式类采用广度优先搜索策略,所以接着会向另一个父类C中搜索。
如果C类中也没有该方法,那么就向父类D中搜索。
私有属性和私有方法
默认情况下,属性在 Python 中都是“public”。
在 Python 中,实例的变量名如果以_ _ 开头,就变成了一个私有变量/属性
(private),实例的函数名如果以 _ _ 开头,就变成了一个私有函数/方法(private)只有内部可以访问和操作,外部(包括子类)不能访问和操作。
class Student:
"""父类Student"""
def __init__(self, name, age, score):
self.name = name
self.age = age
# 私有属性,以双下划线开头。
# 工作机制: 类的外部(包括子类)不能访问和操作,类的内部可以访问和操作。
self.__score = score
def learning(self):
print(f'{
self.name}正在学习')
def get_score(self):
return self.__score
class MathStudent(Student):
"""MathStudent的父类是Student"""
pass
# 报错原因: 子类无法继承父类的私有属性和私有方法。
s1 = MathStudent('张三', 18, 100)
# print(s1.__score) 类外部不能直接访问私有属性
score = s1.get_score()
print(score) # 100
子类无法继承父类的私有属性和私有方法。
父类的私有属性和私有方法只能在父类内部访问和操作,外部和子类都不能访问和操作。
class Student:
"""父类Student"""
def _ _init_ _(self, name, age, score):
self.name = name
self.age = age
# 私有属性,以双下划线开头。
# 工作机制: 类的外部(包括子类)不能访问和操作,类的内部可以访问和操作。
self._ _score = score
def learning(self):
print(f'{
self.name}正在学习')
def get_score(self):
self._ _modify_score()
return self._ _score
# 私有方法是以双下划线开头的方法,
#工作机制: 类的外部(包括子类)不能访问和操作,类的内部可以访问和操作。
def _ _modify_score(self):
self._ _score += 20
class MathStudent(Student):
"""MathStudent的父类是Student"""
pass
# def get_score(self):
# self._ _modify_score() # 子类无法访问父类的私有方法
# return self._ _score
s1 = MathStudent('张三', 18, 100)
score = s1.get_score()
print(score) # 120
多态
多态(Polymorphism)按字面的意思就是“多种状态”。在面向对象语言中,接口
的多种不同的实现方式即为多态。通俗来说: 同一操作作用于不同的对象,可以有不
同的解释,产生不同的执行结果
多态的好处就是,当我们需要传入更多的子类,只需要继承父类就可以了,而方法既可以直接
不重写(即使用父类的),也可以重写一个特有的。这就是多态的意思。调用方只管调用,不管
细节,而当我们新增一种的子类时,只要确保新方法编写正确,而不用管原来的代码。这就是著
名的“开闭”原则:
对扩展开放(Open for extension):允许子类重写方法函数
对修改封闭(Closed for modification):不重写,直接继承父类方法函数
class Student:
"""父类Student"""
def __init__(self, name, age):
self.name = name
self.age = age
def learning(self):
print(f'{
self.name}正在学习')
def choice_course(self):
print('正在选课中'.center(50, '*'))
class MathStudent(Student):
"""MathStudent的父类是Student"""
def choice_course(self):
super(MathStudent, self).choice_course()
info = """
课程表
1. 高等数学
2. 线性代数
3. 概率论
"""
print(info)
# 实例化
m1 = MathStudent("Alice", 8)
m1.choice_course()
s1 = Student("Alice", 8)
s1.choice_course()
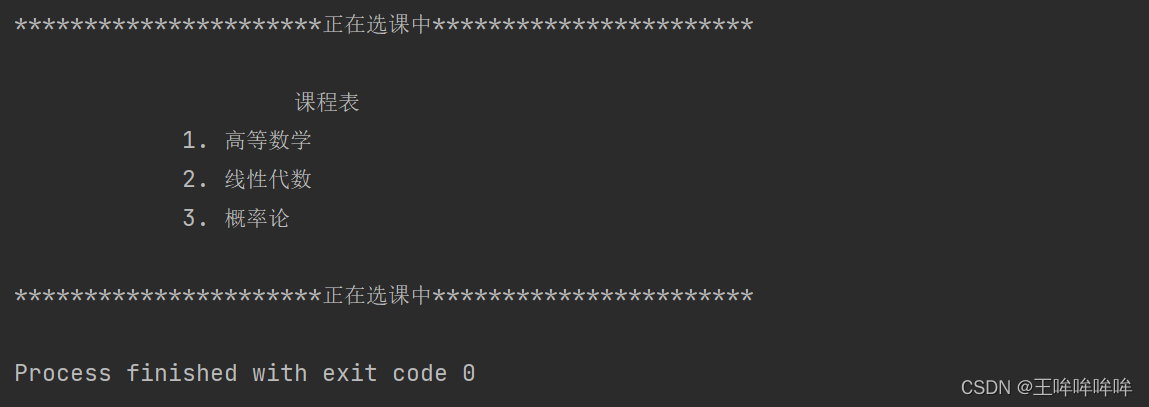 不同的对象调用同一个方法,执行结果不同。
不同的对象调用同一个方法,执行结果不同。
项目案例:栈和队列的封装
栈的封装
栈是限制在一端进行插入操作和删除操作的线性表(俗称堆栈),允许进行操作的一端称为“栈顶”,
另一固定端称为“栈底”,当栈中没有元素时称为“空栈”。向一个栈内插入元素称为是进栈,push;
从一个栈删除元素称为是出栈,pop。特点 :后进先出(LIFO)。
python的内置数据类型中没有栈,可以使用面向对象的编程封装栈。
需求:
入栈:S.push() ----- 判断栈是否为空:S.is_empty()
求栈的长度:len(S) ----- 获取栈顶元素:S.top()
出栈:S.pop()
class Stack:
def __init__(self):
self.stack = [] #基于列表封装
def push(self,value): #入栈
self.stack.append(value)
print(f'入栈元素为{
value}')
def pop(self): #出栈
if self.is_empty():
raise Exception("栈为空")
item=self.stack.pop()
print(f'出栈元素为{
item}')
return item
def is_empty(self):
return len(self.stack) == 0
def top(self):
if self.is_empty():
raise Exception("栈为空")
return self.stack[-1]
def __len__(self):
"""魔术方法,调用len(object)自动执行的方法"""
return len(self.stack)
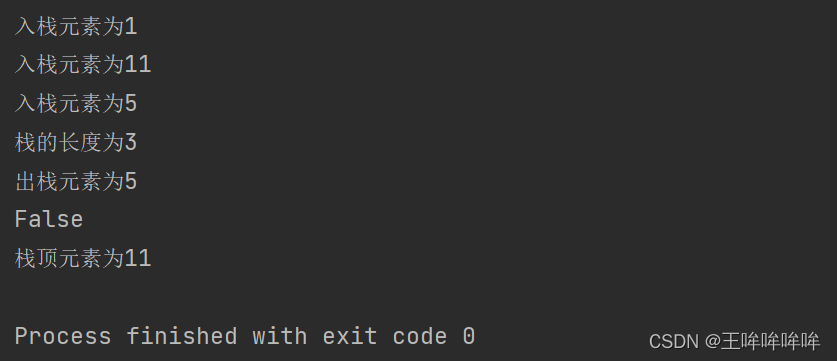
if __name__=='__main__':
stack=Stack()
stack.push(1)
stack.push(11)
stack.push(5)
print(f'栈的长度为{
len(stack)}') # 3
stack.pop()
print(stack.is_empty()) # False
print(f'栈顶元素为{
stack.top()}') # 11
队列的封装
队列是限制在一端进行插入操作和另一端删除操作的线性表,允许进行插入操作的一端称为“队尾”,
允许进行删除操作的一端称为“队头”,,当队列中没有元素时称为“空队”。特点 :先进先出(FIFO)。
需求:
入队列:Q.enqueue()
出队列:Q.dequeue()
求队列的长度:len(Q)
判断队列是否为空: Q.is_empty()
求队列的第一个元素: Q.first()
求队列的最后一个元素: Q.last()
队列的封装:
1、队列的左侧为队尾,queue[0]
2、队列的右侧为对头,queue[-1]
队列的insert函数:
用法:list.insert(index, new_item)
参数:
index:新的元素放在哪个位置(数字)
new_item:添加的新元素(成员)
class Queue:
def __init__(self):
self.queue = [] #列表的基础上封装
def enqueue(self,value):
self.queue.insert(0,value) #从对头插入元素
print(f'入队列元素为{
value}')
def dequeue(self):
if self.is_empty():
raise Exception("队列为空")
item=self.queue.pop()
print(f'出队列元素为{
item}')
return item
def is_empty(self):
return len(self.queue) == 0
def __len__(self):
return len(self.queue)
def first(self):
if self.is_empty():
raise Exception("队列为空")
return self.queue[-1]
def last(self):
if self.is_empty():
raise Exception("队列为空")
return self.queue[0]
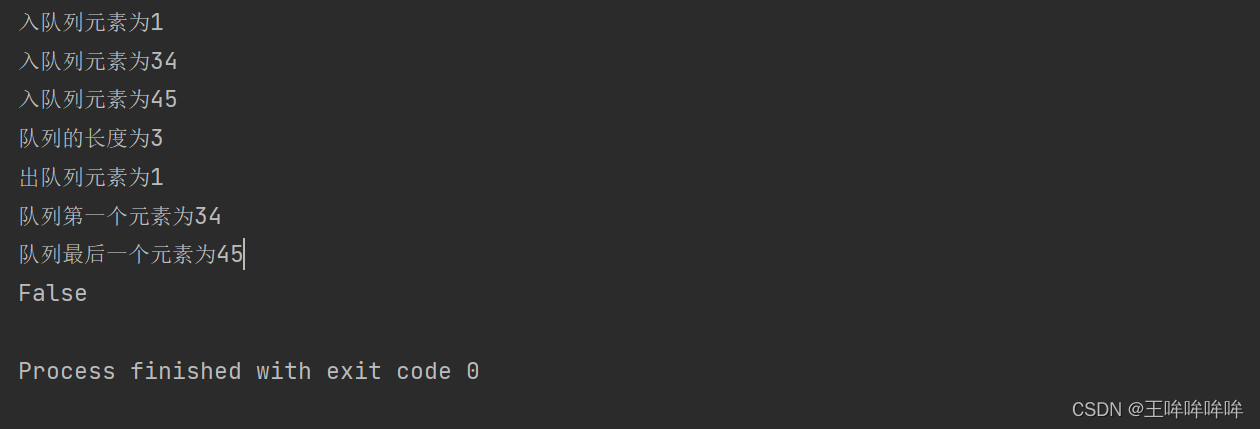
queue=Queue()
queue.enqueue(1)
queue.enqueue(34)
queue.enqueue(45)
print(f'队列的长度为{
len(queue)}')
queue.dequeue()
print(f'队列第一个元素为{
queue.first()}')
print(f'队列最后一个元素为{
queue.last()}')
print(queue.is_empty())
二叉树的封装及遍历
#二叉树的封装
# 树的结点
class Node:
def __init__(self,val=None,left=None,right=None):
self.val=val
self.left=left
self.right=right
# 二叉树
class Binarytree:
def __init__(self,root):
self.root=root
def pre_travel(self,root):
if(root!=None):
print(root.val,end=' ')
self.pre_travel(root.left)
self.pre_travel(root.right)
def in_travel(self,root):
if(root!=None):
self.in_travel(root.left)
print(root.val,end=' ')
self.in_travel(root.right)
def post_travel(self,root):
if(root!=None):
self.post_travel(root.left)
self.post_travel(root.right)
print(root.val,end=' ')
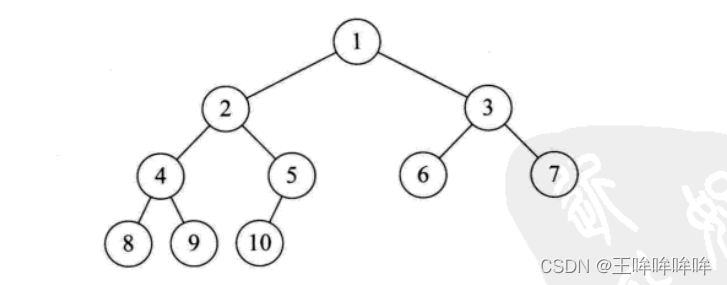
if __name__ == '__main__' :
node1=Node(1)
node2=Node(2)
node3=Node(3)
node4=Node(4)
node5=Node(5)
node6=Node(6)
node7=Node(7)
node8=Node(8)
node9=Node(9)
node10=Node(10)
node1.left=node2 #node1为根节点
node1.right=node3
node2.left=node4
node2.right=node5
node3.left=node6
node3.right=node7
node4.left=node8
node4.right=node9
node5.left=node10
bt=Binarytree(node1)
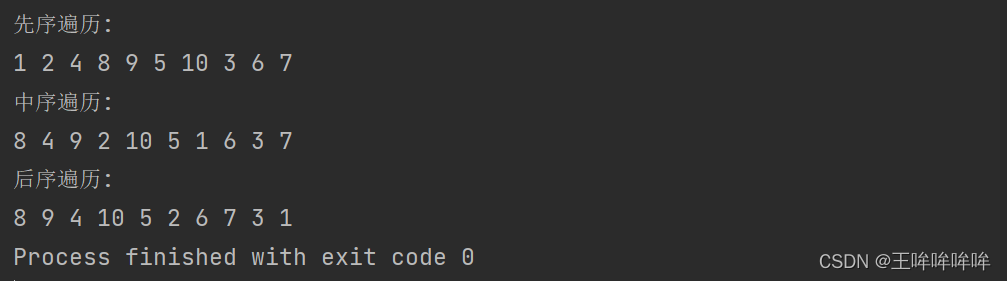
print('先序遍历:')
bt.pre_travel(node1)
print()
print('中序遍历:')
bt.in_travel(node1)
print()
print('后序遍历:')
bt.post_travel(node1)
链表的封装
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
链接:https://leetcode.cn/problems/add-two-numbers
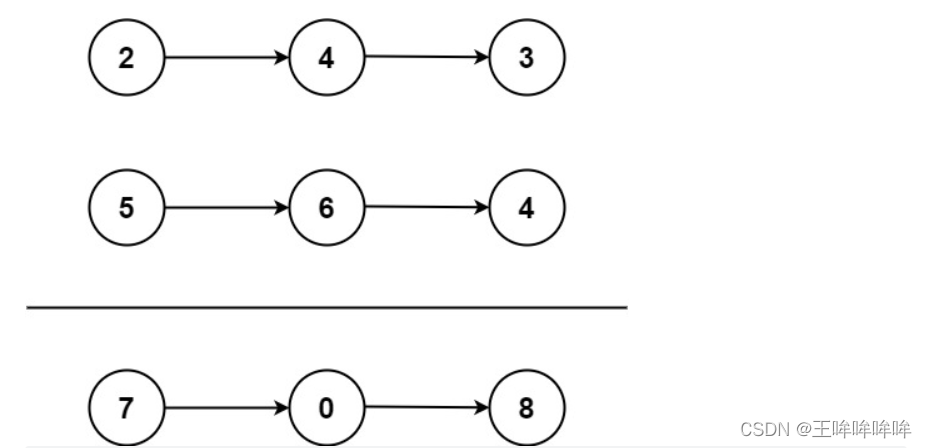 输入:l1 = [2,4,3], l2 = [5,6,4]
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
提示: 0 <= Node.val <= 9
题目数据保证列表表示的数字不含前导零
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def travel(self, head):
# 遍历链表的结点
while head:
print(head.val, end=',')
head = head.next
def create_l1():
l1 = ListNode() # l1是链表的头结点
node1 = ListNode(val=2)
node2 = ListNode(val=4)
node3 = ListNode(val=3)
l1.next = node1
node1.next = node2
node2.next = node3
# l1.travel(l1.next)
return l1.next
def create_l2():
l2 = ListNode() # l2是链表头结点
node1 = ListNode(val=5)
node2 = ListNode(val=6)
node3 = ListNode(val=4)
l2.next = node1
node1.next = node2
node2.next = node3
# l2.travel(l2.next)
return l2.next
def add_nums(l1, l2):
tem = 0
l3 = ListNode()
cur=l3 #当计算结束,l3指向链表最后一个结点,为了遍历l3链表
while (l1 or l2):
if(l1):
tem += l1.val
l1 = l1.next
if(l2):
tem += l2.val
l2 = l2.next
l3.next=ListNode(val=tem%10)
l3=l3.next
#计算进位
tem = tem // 10
#个、十、百位计算结束,看千位是否有进位
if tem==1:
l3.next=ListNode(val=1)
return cur.next
if _ _name_ _ == '_ _main_ _':
l1 = create_l1()
# print()
l2 = create_l2()
l3=add_nums(l1,l2)
l3.travel(l3)

智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象