TensorFlow:维度变换_tensorflow将shape的某两维进行调换-程序员宅基地
技术标签: tensorflow 机器学习 TensorFlow 学习
基本的维度变换包含了改变视图 reshape,插入新维度 expand_dims,删除维 squeeze,交换维度 transpose,复制数据 tile 等。
一、张量的存储和视图(View)概念
张量的视图就是我们理解张量的方式,比如shape 为[2,4,4,3]的张量A,我们从逻辑上可以理解为2 张图片,每张图片4 行4 列,每个位置有RGB 3 个通道的数据;
张量的存储体现在张量在内存上保存为一段连续的内存区域,对于同样的存储,我们可以有不同的理解方式,比如上述A,我们可以在不改变张量的存储下,将张量A 理解为2 个样本,每个样本的特征为长度48 的向量。
这就是存储与视图的关系。
在存储数据时,内存并不支持这个维度层级概念,只能以平铺方式按序写入内存,因此这种层级关系需要人为管理,也就是说,每个张量的存储顺序需要人为跟踪。
为了方便表达,我们把张量shape 中相对靠左侧的维度叫做大维度,shape 中相对靠右侧的维度叫做小维度,比如[2,4,4,3]的张量中,图片数量维度与通道数量相比,图片数量叫做大维度,通道数叫做小维度。
例如:在优先写入小维度的设定下,张量 [2,4,4,3] 的内存布局为

为了能够正确恢复出数据,必须保证张量的存储顺序与新视图的维度顺序一致,
例如根据图片数量-行-列-通道初始视图保存的张量,按照图片数量-行-列-通道( − ℎ −w − )的顺序可以获得合法数据。
如果按着图片数量-像素-通道(b − h ∗ w − c)的方式恢复视图,也能得到合法的数据。但是如果按着图片数量-通道-像素( − c − h ∗ w)的方式恢复数据,由于内存布局是按着图片数量-行-列-通道的顺序,视图维度与存储维度顺序相悖,提取的数据将是错乱的。
二、Reshape 操作
改变视图是神经网络中非常常见的操作,可以通过串联多个Reshape 操作来实现复杂
逻辑,
但是在通过Reshape 改变视图时,必须始终记住张量的存储顺序,新视图的维度顺序不能与存储顺序相悖,否则需要通过交换维度操作将存储顺序同步过来。
举个例子,对于shape 为[4,32,32,3]的图片数据,通过Reshape 操作将shape 调整为[4,1024,3],此时视图的维度顺序为 − − ,张量的存储顺序为 [, ℎ, w, ]。
在 TensorFlow 中,可以通过张量的ndim 和shape 成员属性获得张量的维度数和形
状:

通过 tf.reshape(x,new_shape),可以将张量的视图任意的合法改变
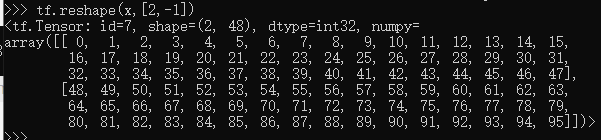
当不知道填入什么数字合适时,可以选用 -1 来替代,由python通过其他值进行推算得知具体值
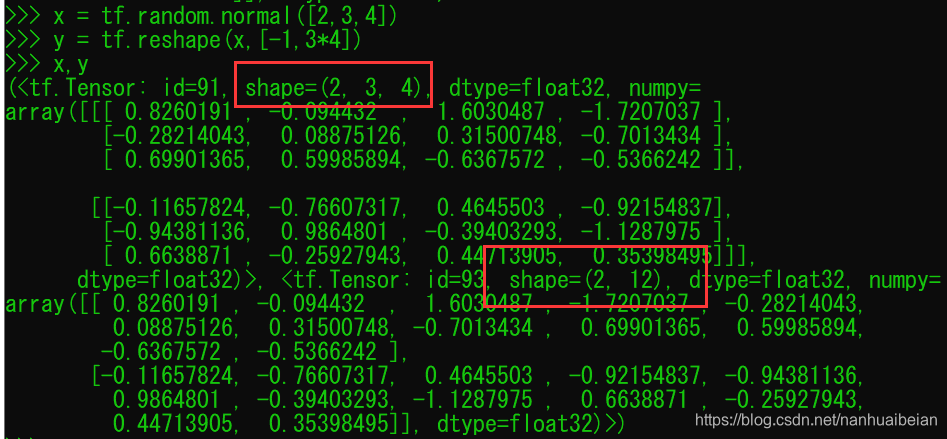
例如将shape为 [b,3,4]的输入数据转为 shape为 [b,3*4] 的数据:
三、增删维度
1. 增加维度
增加一个长度为1 的维度相当于给原有的数据增加一个新维度的概念,维度长度为1,故数据并不需要改变,仅仅是改变数据的理解方式,因此它其实可以理解为改变视图的一种特殊方式
比如:,一张28x28 灰度图片的数据保存为 shape 为[28,28]的张量,在末尾给张量增加一新维度,定义为通道数维度,此时张量的shape 变为[28,28,1]:
通过tf.expand_dims(x, axis)可在指定的axis 轴前可以插入一个新的维度:
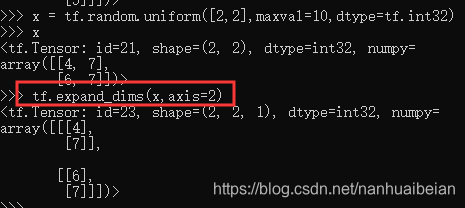
可以看到插入一个新维度后,数据的存储顺序并没有改变,仅仅改变了数据的视图。

需要注意的是,tf.expand_dims 的axis 为正时,表示在当前维度之前插入一个新维度;为负时,表示当前维度之后插入一个新的维度。以[, ℎ, w, ]张量为例,不同axis 参数的实际插入位置如图所示:

2. 删除维度
是增加维度的逆操作,与增加维度一样,删除维度只能删除长度为1 的维度,也不会改变张量的存储。
可以通过tf.squeeze(x, axis)函数,axis 参数为待删除的维度的索引号
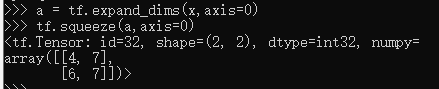
如果不指定维度参数 axis,即 tf.squeeze(x),那么他会默认删除所有长度为1的维度
四、交换维度
在实现算法逻辑时,在保持维度顺序不变的条件下,仅仅改变张量的理解方式是不够的,有时需要直接调整的存储顺序,即交换维度(Transpose)。通过交换维度,改变了张量的存储顺序,同时也改变了张量的视图。
我们以[, ℎ, w, ]转换到[, , ℎ, w]为例,介绍如何使用tf.transpose(x, perm)函数完成维度交换操作,其中 perm 表示新维度的顺序 List。
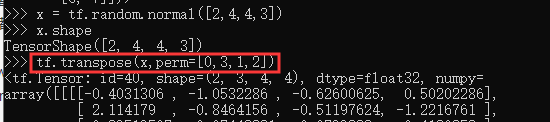
通过tf.transpose完成维度交换后,张量的存储顺序已经改变,视图也随之改变,后续的所有操作必须基于新的存续顺序进行
五、数据复制
tf.tile(x, multiples)函数完成数据在指定维度上的复制操作,multiples 分别指定了每个维度上面的复制倍数,对应位置为1 表明不复制,为2 表明新长度为原来的长度的2 倍,即数据复制一份,以此类推。

六、Broadcasting(自动扩展)
Broadcasting 也叫广播机制(自动扩展也许更合适),它是一种轻量级张量复制的手段,在逻辑上扩展张量数据的形状,但是只要在需要时才会执行实际存储复制操作。对于大部分场景,Broadcasting 机制都能通过优化手段避免实际复制数据而完成逻辑运算,从而相对于tf.tile 函数,减少了大量计算代价。
对于所有长度为1 的维度,Broadcasting 的效果和tf.tile 一样,都能在此维度上逻辑复制数据若干份,区别在于tf.tile 会创建一个新的张量,执行复制IO 操作,并保存复制后的张量数据,Broadcasting 并不会立即复制数据,它会逻辑上改变张量的形状,使得视图上变成了复制后的形Broadcasting 会通过深度学习框架的优化手段避免实际复制数据而完成逻辑运算,至于怎么实现的用户不必关系,对于用于来说,Broadcasting 和tf.tile 复制的最终效果是一样的,操作对用户透明,但是Broadcasting 机制节省了大量计算资源,建议在运算过程中尽可能地利用Broadcasting 提高计算效率。
Broadcasting 机制的核心思想是普适性,即同一份数据能普遍适合于其他位置。在验证普适性之前,需要将张量shape 靠右对齐,然后进行普适性判断:对于长度为1 的维度,默认这个数据普遍适合于当前维度的其他位置;对于不存在的维度,则在增加新维度后默认当前数据也是普适性于新维度的,从而可以扩展为更多维度数、其他长度的张量形状。
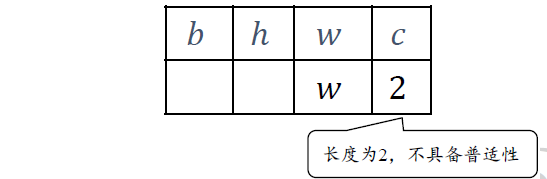
在 c 维度上,张量已经有2 个特征数据,新shape 对应维度长度为c( ≠ 2,比如c=3),那么当前维度上的这2 个特征无法普适到其他长度,故不满足普适性原则,无法应用 Broadcasting 机制,将会触发错误
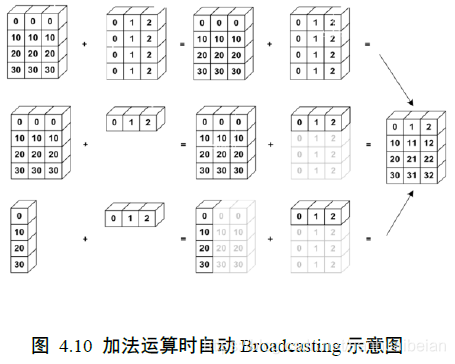
在进行张量运算时,有些运算可以在处理不同shape 的张量时,会隐式自动调用 Broadcasting 机制,如+,-,*,/等运算等,将参与运算的张量Broadcasting 成一个公共shape,再进行
智能推荐
生活垃圾数据集(YOLO版)_垃圾回收数据集-程序员宅基地
文章浏览阅读1.6k次,点赞5次,收藏20次。【有害垃圾】:电池(1 号、2 号、5 号)、过期药品或内包装等;【可回收垃圾】:易拉罐、小号矿泉水瓶;【厨余垃圾】:小土豆、切过的白萝卜、胡萝卜,尺寸为电池大小;【其他垃圾】:瓷片、鹅卵石(小土豆大小)、砖块等。文件结构|----classes.txt # 标签种类|----data-txt\ # 数据集文件集合|----images\ # 数据集图片|----labels\ # yolo标签。_垃圾回收数据集
天气系统3------微服务_cityid=101280803-程序员宅基地
文章浏览阅读272次。之前写到 通过封装的API 已经可以做到使用redis进行缓存天气信息但是这一操作每次都由客户使用时才进行更新 不友好 所以应该自己实现半小时的定时存入redis 使用quartz框架 首先添加依赖build.gradle中// Quartz compile('org.springframework.boot:spring-boot-starter-quartz'..._cityid=101280803
python wxpython 不同Frame 之间的参数传递_wxpython frame.bind-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏8次。对于使用触发事件来反应的按钮传递参数如下:可以通过lambda对function的参数传递:t.Bind(wx.EVT_BUTTON, lambda x, textctrl=t: self.input_fun(event=x, textctrl=textctrl))前提需要self.input_fun(self,event,t):传入参数而同时两个Frame之间的参数传..._wxpython frame.bind
cocos小游戏开发总结-程序员宅基地
文章浏览阅读1.9k次。最近接到一个任务要开发消消乐小游戏,当然首先就想到乐cocosCreator来作为开发工具。开发本身倒没有多少难点。消消乐的开发官网发行的书上有专门讲到。下面主要总结一下开发中遇到的问题以及解决方法屏幕适配由于设计尺寸是750*1336,如果适应高度,则在iphonX下,内容会超出屏幕宽度。按宽适应,iphon4下内容会超出屏幕高度。所以就需要根据屏幕比例来动态设置适配策略。 onLoad..._750*1336
ssm435银行贷款管理系统+vue_vue3重构信贷管理系统-程序员宅基地
文章浏览阅读745次,点赞21次,收藏21次。web项目的框架,通常更简单的数据源。21世纪的今天,随着社会的不断发展与进步,人们对于信息科学化的认识,已由低层次向高层次发展,由原来的感性认识向理性认识提高,管理工作的重要性已逐渐被人们所认识,科学化的管理,使信息存储达到准确、快速、完善,并能提高工作管理效率,促进其发展。论文主要是对银行贷款管理系统进行了介绍,包括研究的现状,还有涉及的开发背景,然后还对系统的设计目标进行了论述,还有系统的需求,以及整个的设计方案,对系统的设计以及实现,也都论述的比较细致,最后对银行贷款管理系统进行了一些具体测试。_vue3重构信贷管理系统
乌龟棋 题解-程序员宅基地
文章浏览阅读774次。题目描述原题目戳这里小明过生日的时候,爸爸送给他一副乌龟棋当作礼物。乌龟棋的棋盘是一行 NNN 个格子,每个格子上一个分数(非负整数)。棋盘第 111 格是唯一的起点,第 NNN 格是终点,游戏要求玩家控制一个乌龟棋子从起点出发走到终点。乌龟棋中 MMM 张爬行卡片,分成 444 种不同的类型( MMM 张卡片中不一定包含所有 444 种类型的卡片,见样例),每种类型的卡片上分别标有 1,2,3,41, 2, 3, 41,2,3,4 四个数字之一,表示使用这种卡片后,乌龟棋子将向前爬行相应的格子数
随便推点
python内存泄露的原因_Python服务端内存泄露的处理过程-程序员宅基地
文章浏览阅读1.5k次。吐槽内存泄露 ? 内存暴涨 ? OOM ?首先提一下我自己曾经历过多次内存泄露,到底有几次? 我自己心里悲伤的回想了下,造成线上影响的内存泄露事件有将近5次了,没上线就查出内存暴涨次数可能更多。这次不是最惨,相信也不会是最后的内存的泄露。有人说,内存泄露对于程序员来说,是个好事,也是个坏事。 怎么说? 好事在于,技术又有所长进,经验有所心得…. 毕竟不是所有程序员都写过OOM的服务…. 坏事..._python内存泄露
Sensor (draft)_draft sensor-程序员宅基地
文章浏览阅读747次。1.sensor typeTYPE_ACCELEROMETER=1 TYPE_MAGNETIC_FIELD=2 (what's value mean at x and z axis)TYPE_ORIENTATION=3TYPE_GYROSCOPE=4 TYPE_LIGHT=5(in )TYPE_PRESSURE=6TYPE_TEMPERATURE=7TYPE_PRO_draft sensor
【刘庆源码共享】稀疏线性系统求解算法MGMRES(m) 之 矩阵类定义三(C++)_gmres不构造矩阵-程序员宅基地
文章浏览阅读581次。/* * Copyright (c) 2009 湖南师范大学数计院 一心飞翔项目组 * All Right Reserved * * 文件名:matrix.cpp 定义Point、Node、Matrix类的各个方法 * 摘 要:定义矩阵类,包括矩阵的相关信息和方法 * * 作 者:刘 庆 * 修改日期:2009年7月19日21:15:12 **/
三分钟带你看完HTML5增强的【iframe元素】_iframe allow-top-navigation-程序员宅基地
文章浏览阅读1.7w次,点赞6次,收藏20次。HTML不再推荐页面中使用框架集,因此HTML5删除了<frameset>、<frame>和<noframes>这三个元素。不过HTML5还保留了<iframe>元素,该元素可以在普通的HTML页面中使用,生成一个行内框架,可以直接放在HTML页面的任意位置。除了指定id、class和style之外,还可以指定如下属性:src 指定一个UR..._iframe allow-top-navigation
Java之 Spring Cloud 微服务的链路追踪 Sleuth 和 Zipkin(第三个阶段)【三】【SpringBoot项目实现商品服务器端是调用】-程序员宅基地
文章浏览阅读785次,点赞29次,收藏12次。Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的 REST API 接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。除了面向开发的 API 接口之外,它也提供了方便的 UI 组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,
烁博科技|浅谈视频安全监控行业发展_2018年8月由于某知名视频监控厂商多款摄像机存在安全漏洞-程序员宅基地
文章浏览阅读358次。“随着天网工程的建设,中国已经建成世界上规模最大的视频监控网,摄像头总 数超过2000万个,成为世界上最安全的国家。视频图像及配套数据已经应用在反恐维稳、治安防控、侦查破案、交通行政管理、服务民生等各行业各领域。烁博科技视频安全核心能力:精准智能数据采集能力:在建设之初即以应用需求为导向,开展点位选择、设备选型等布建工作,实现前端采集设备的精细化部署。随需而动的AI数据挖掘能力:让AI所需要的算力、算法、数据、服务都在应用需求的牵引下实现合理的调度,实现解析能力的最大化。完善的数据治理能力:面_2018年8月由于某知名视频监控厂商多款摄像机存在安全漏洞