损失函数loss改进解析_改进loss-程序员宅基地
技术标签: 人脸识别
题图依然来自Coco!上篇地址:
YaqiLYU:人脸识别的LOSS(上)
Feature Normalization
- Liu Y, Li H, Wang X. Rethinking feature discrimination and polymerization for large-scale recognition [C]// NIPS workshop, 2017.
COCO(congenerous cosine) loss: sciencefans/coco_loss,归一化了权值c,归一化了特征f,并乘尺度因子 :

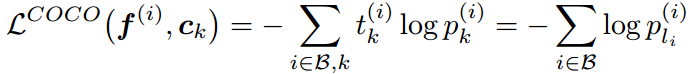
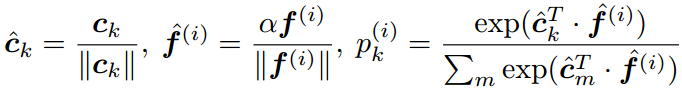

half MS-1M训练集,用coco loss训练Inception ResNet,在LFW上达到99.86%,接近满分,但要注意,同样的训练集和CNN,Softmax loss训练的结果是99.75%。
- Ranjan R, Castillo C D, Chellappa R. L2-constrained softmax loss for discriminative face verification [J]. arXiv:1703.09507, 2017.
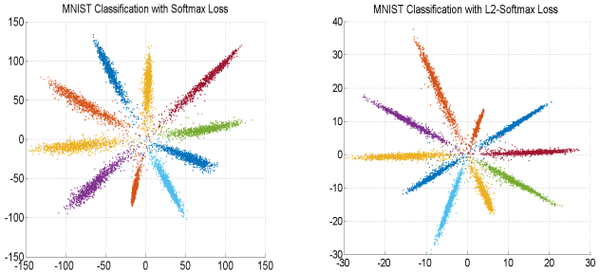

L2-Softmax: 在Softmax的w*x基础上,将特征向量x做归一化,并乘尺度因子进行放大:
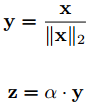
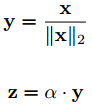
尺度因子 可以是固定值,也可以自适应训练,建议用固定值
。可以MS-Celeb-1M的子集3.7M图像作为训练集,用L2-Softmax训练ResNeXt-101在LFW上达到了99.78%,与center loss联合使用也有提升。
- Wang F, Xiang X, Cheng J, et al. NormFace: L2 Hypersphere Embedding for Face Verification [C]// ACM MM, 2017.
NormFace: happynear/NormFace,归一化了特征,同样加了尺度因子s,但这里推荐用自动学习的方法:
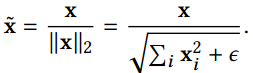
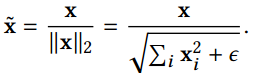

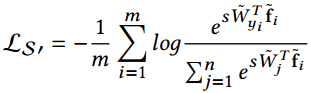
归一化后的softmax, contrastive 和center loss都用不同程度的提升,0.49M的CASIA-WebFace训练集28层ResNet,归一化前后,softmax从98.28%提升到99.16%,center loss从99.03%提升到了99.17%。
特征归一化的重要性
- 从最新方法来看,权值W和特征f(或x)归一化已经成为了标配,而且都给归一化特征乘以尺度因子s进行放大,目前主流都采用固定尺度因子s的方法(看来自适应训练没那么重要);
- 权值和特征归一化使得CNN更加集中在优化夹角上,得到的深度人脸特征更加分离;
- 特征归一化后,特征向量都固定映射到半径为1的超球上,便于理解和优化;但这样也会压缩特征表达的空间;乘尺度因子s,相当于将超球的半径放大到s,超球变大,特征表达的空间也更大(简单理解:半径越大球的表面积越大);
- 特征归一化后,人脸识别计算特征向量相似度,L2距离和cos距离意义等价,计算量也相同,我们再也不用纠结到底用L2距离还会用cos距离:
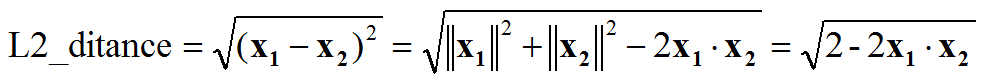
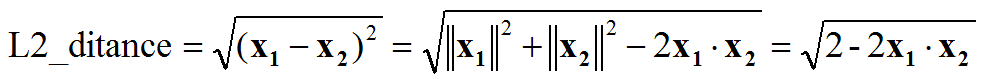

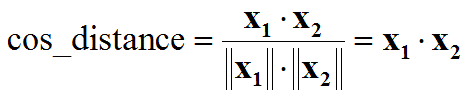
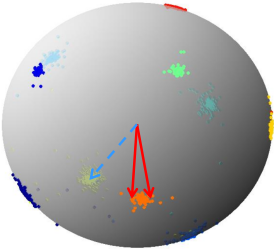
- 为什么仅特征归一化无法收敛,而必须乘固定尺度因子呢?以四分类为例分析。
- 仅特征归一化时,输出
等价于
,理想情况下,优后
是0,x2=x3=x4都输出0,此时激活值为{1, 0, 0, 0},指数函数非线性放大后输出为{e, 1, 1, 1},归一化后置信度是{47.54%, 17.49%, 17.49%, 17.49%},远远达不到收敛的要求,所以仅归一化是不能训练的。
- 归一化后乘尺度因子s,这里以s=60为例,输出
,理想情况下,优后
Additive Margin Loss
- Wang F, Liu W, Liu H, et al. Additive Margin Softmax for Face Verification [C]// ICLR 2018 (Workshop) .


AM-Softmax:happynear/AMSoftmax,在SphereFace的基础上,乘性margin改成了加性margin,即 变成了
,在权值W归一化的基础上对特征f也做了归一化,采用固定尺度因子s=30,相比SphereFace性能有提升,最重要的是训练难度大幅降低,不需要退火优化。此外,论文还做了训练集CASIA-WebFace与测试集LFW和MegaFace的重叠identity清理,LFW从Center Loss和SphereFace清理的3对增加到17对,实验证明影响较大。AM-Softmax的特点是小训练集小网络,仅20层CNN,在清理后CASIA-WebFace上训练,LFW达到了98.98%,在MegaFace上较SphereFace提升明显,有源码的好文推荐!
- Wang H, Wang Y, Zhou Z, et al. CosFace: Large Margin Cosine Loss for Deep Face Recognition [C]// CVPR, 2018.
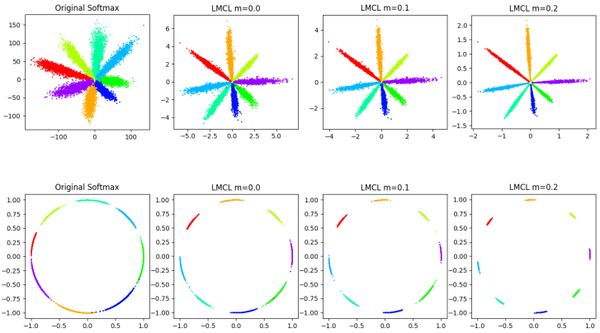
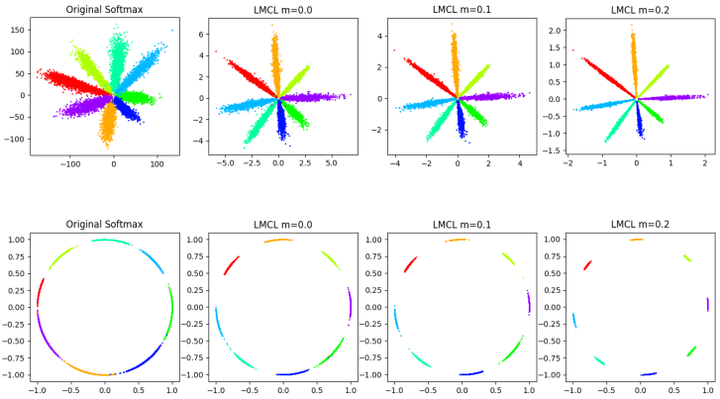
CosFace:与AM-Softmax完全一样,同样的加性margin,同样的特征归一化,工作完成比AM-Softmax早。两个训练集没有提重叠身份清理的问题,0.49M小训练集CASIA-Webface,5M腾讯自己收集的大训练集,训练64层CNN,LFW上99.73%,MegaFace上大小训练集都是SOTA。对比AM-Softmax的结果,CosFace大网络和大训练集的性能提升非常明显,没有源码。
- Jiankang Deng, Jia Guo, Stefanos Zafeiriou. ArcFace: Additive Angular Margin Loss for Deep Face Recognition [J]. arXiv:1801.07698. (Submitted to IJCV)
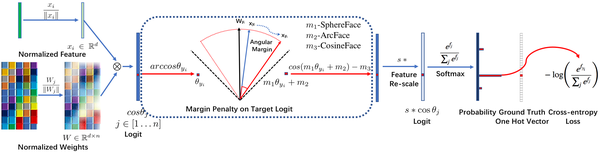
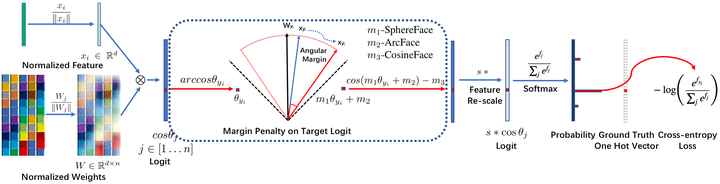
ArcFace: deepinsight/insightface,这个不是虹软的!这个不是虹软的!这个不是虹软的!仅仅是算法与虹软的人脸识别SDK重名了,没有一点关系。论文叫ArcFace,代码叫insightface,在SphereFace的基础上,同样改用加性margin但形式略有区别, 变成了
,同样也做了特征归一化,固定因子s=64。ArcFace的特点是大训练集加大网络,也做了细致的训练集和测试集清理,训练集MS-Celeb-1M从100k-10M清理到85k-3.8M,测试集MegaFace算法加人工清理后识别率提高了15%,大网络是100层CNN,在LFW上做到了99.83%,在MegaFace上large也是SOTA,目前是榜单第一名,论文篇幅较长,实验细致,强力推荐好文!
强力推荐insightface人脸识别project,基于mxnet训练速度快,包含所有sota的backbone和loss方便上手 InsightFace - 使用篇, 如何一键刷分LFW 99.80%, MegaFace 98% ,为了用这套环境,我已经转mxnet了 -_-!
不同margin的对比
目前人脸识别算法以large margin为主,这里提出并讨论两个问题:
问题一:large margin为什么能work?
- L-Softmax重构了Softmax,输出x变成
,SphereFace归一化权值W,变成
;最新AM-Softmax和ArcFace继续归一化特征乘尺度因子,变成
。所以这里我们简化问题,默认归一化权值W和特征f,即
,仅考虑
这一项变动对分类任务的影响。
- 还是讨论四分类问题,输出
。原始Softmax在输出x = {5, 1, 1, 1}时就接近收敛,训练停止,此时改用large margin softmax,第一列的
、
或
,会使输出减小,其他列保持不变,此时输出可能变成了x = {4, 1, 1, 1},网络又可以继续训练了。
- 这一过程与“从hardmax的
到softmax的
非线性放大了输出,减小训练难度,使分类问题更容易收敛”正好相反,从
- 不同loss的曲线对比,下图来自ArcFace,所有loss都是单调递减的。对比Softmax的
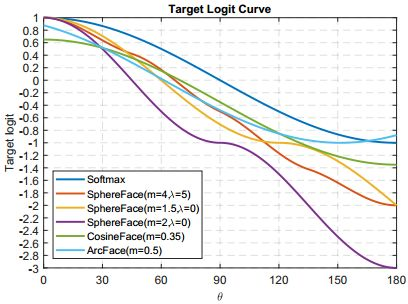
问题二:Large Margin到底优化了什么?
前面提到large margin显式约束了类间分离,看可视化结果好像也是这样,但其实这种说法是不对的。
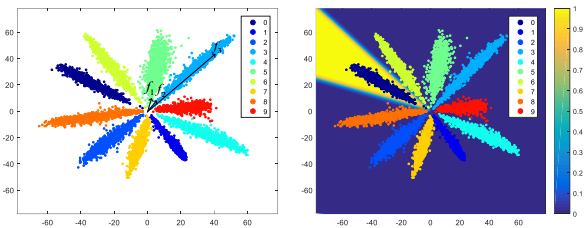
- large margin优化的核心——夹角
- 具体来看
、
或
,都减小了输出激活值,如果要达到目标置信度100%,就需要优化出比Softmax更小的夹角
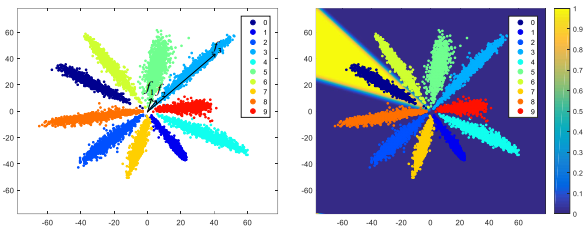
- 对特定类别来说,假如有1000张图像,经CNN特征映射后得到1000个特征向量,而权值向量W是每个类别只有一个,large margin loss要求这1000个特征向量和这1个权值向量的夹角非常小,也就是说,优化让1000个特征向量都向权值向量W的方向靠拢。
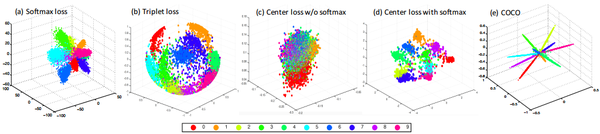
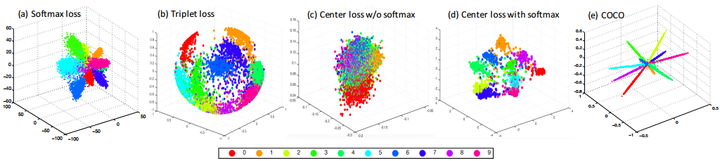
- 下图是SphereFace(m=4)在MNIST上跑出来的特征映射,不同颜色代表不同类别,每个类别的中心白线就是这个类别的权值向量可视化的结果,与前面的分析完全一致。结论就是:large magin是显式的类内夹角约束,目标是让同一类的所有特征向量都拉向该类别的权值向量。

人脸识别的SOTA
影响算法性能的因素:
- 训练集:一般训练集类别数越多,图像数量越多,训练效果越好。此外训练集的收集和标注质量,不同类别的样本数量是否均衡,都对训练有影响。
- CNN:一般CNN的容量越大,训练效果越好。CNN的模型容量参考ImageNet上的分类性能,与参数数量和运行速度并不是正比关系。
- LOSS:这部分才是前面介绍的loss相关影响,特别注意,对比某个loss的性能提升,要综合考虑训练集和CNN,不能简单的看LFW上的识别率。
最常用的两个人脸识别测试库,和以上推荐算法的性能比较,结果来自论文:
- LFW:LFW Face Database : Main,错误列表:LFW Face Database : Main,使用最多的必跑测试库,从2015年FaceNet的99.63%开始就接近饱和了,目前所有算法都在99%以上,比较意义不大。特别举两个用Softmax loss训练的例子:COCO中half MS-1M训练Inception ResNet是99.75%,ArcFace中MS1M训练ResNet100是99.7%。
- MegaFace: MegaFace,目前最大也最具挑战性的测试集,但由于这个数据集质量较差,非常容易作弊,建议以有开源代码的算法,自行训练的结果为准。问题讨论: iBUG_DeepInsight · Issue #49 · deepinsight/insightface。
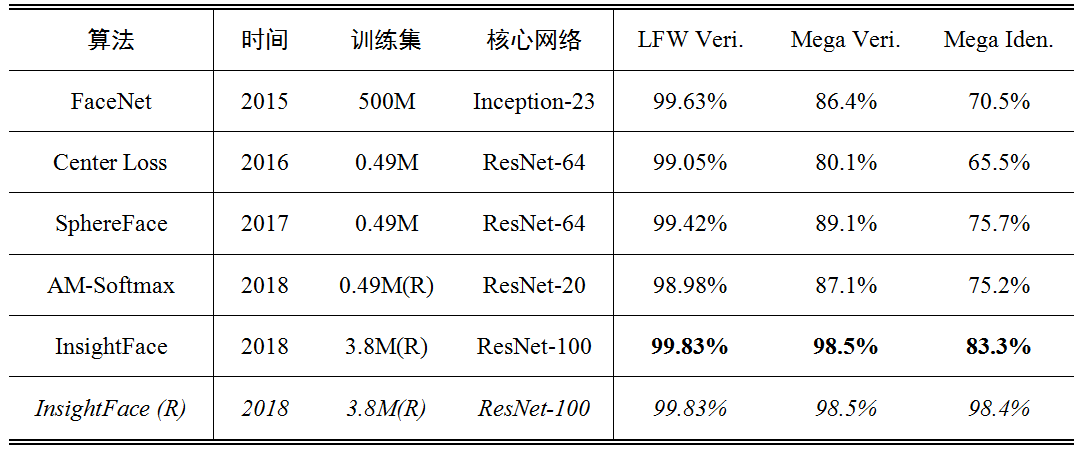
上表中AM-Softmax和InsightFace都做了更细致的训练集重叠清洗,最后一行代表InsightFace对测试集也做了清洗的结果。
END
智能推荐
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
深度神经网络在训练初期的“梯度消失”或“梯度爆炸”的问题解决:数据标准化(Data Standardization),权重初始化(Weight Initialization),Dropout正则化等_在人工神经网络研究的初始阶段,辛顿针对训练过程中常出现的梯度消失现象, 提供相-程序员宅基地
文章浏览阅读101次。1986年,深度学习(Deep Learning)火爆,它提出了一个名为“深层神经网络”(Deep Neural Networks)的新型机器学习模型。随后几年,神经网络在图像、文本等领域取得了惊艳成果。但是,随着深度学习的应用范围越来越广泛,神经网络在遇到新的任务时出现性能下降或退化的问题。这主要是由于深度神经网络在训练初期面临着“梯度消失”或“梯度爆炸”的问题。_在人工神经网络研究的初始阶段,辛顿针对训练过程中常出现的梯度消失现象, 提供相
随便推点
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf
vscode打开markdown文件 不显示图片 预览markdown文件_vscodemarkdown图片无法显示-程序员宅基地
文章浏览阅读3.2k次,点赞3次,收藏4次。vscode打开markdown文件 不显示图片 预览markdown文件_vscodemarkdown图片无法显示