有Mysql数据库的情况下为什么要用Hive数据库?-程序员宅基地
有Mysql数据库的情况下为什么要用Hive?
最近接到公司的一个需求,要求使用Hive做数据查询。当时第一反应就是What?Hive是什么鬼?一脸懵逼状。(请原谅一个刚开始实习的Java实习生见识短浅)然后发现了hive的一些问题。下面简单介绍一下Hive。
网上对于hive与mysql的区别的文章也不是很多。so只能问问公司大牛们,看看他们是怎样理解的。
由于 Hive 采用了 SQL 的查询语言 HQL,因此很容易将 Hive 理解为数据库。其实 从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。
数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
一、Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能 够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。
Hive 可以看成是从SQL到Map-Reduce的 映射器
Hive的数据放在哪儿?
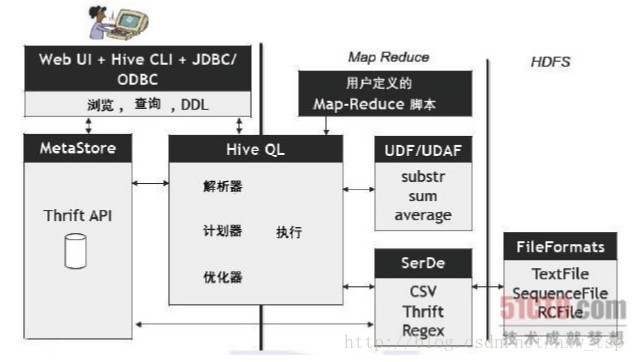
数据在HDFS的warehouse目录下,一个表对应一个子目录。
本地的/tmp目录存放日志和执行计划
hive的表分为两种,内表和外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
使用Mysql作为Hive metaStore的存储数据库
其中主要涉及到的表如下:
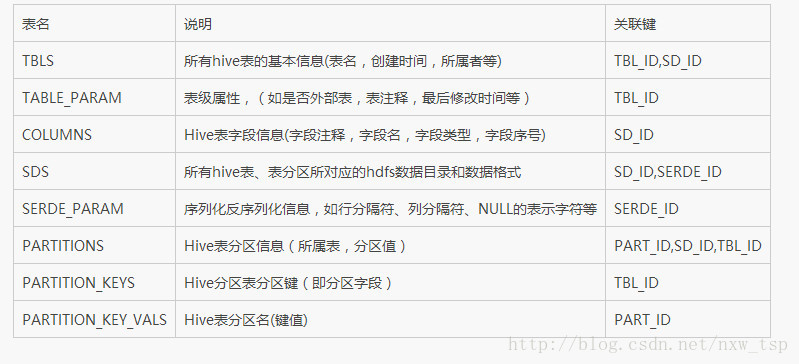
但是对于一个菜鸟来说,看完这些还是有点云里雾里。
下面来看他们的异同。
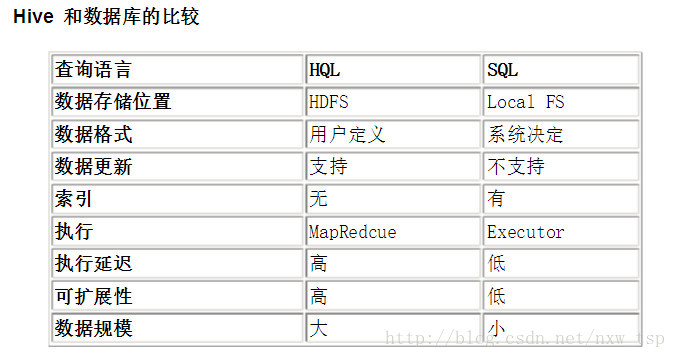
查询语言。由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
数据存储位置。Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库 则可以将数据保存在本地文件系统中。
数据格式。Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三 个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
数据更新。由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不 支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修改数据。
索引。之前已经说过,Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描, 因此也没有对数据中的某些 Key 建立索引。Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
执行。Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的(类似 select * from tbl 的查询不需要 MapReduce)。而数据库通常有自己的执行引擎。
执行延迟。之前提到,Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外 一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
可扩展性。由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是 一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的 数据;对应的,数据库可以支持的数据规模较小。
看了这些,我说为什么hive查询数据怎么这么慢呢。
最后再来一下数据库和数据仓储的区别。
> 数据库是面向事务的设计,数据仓库是面向主题设计的。 数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
> 数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。
> 数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。(维是看问题的角度,比如时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID)
以上文章部分内容来自与网络。
智能推荐
FTP命令字和返回码_ftp 登录返回230-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏13次。为了从FTP服务器下载文件,需要要实现一个简单的FTP客户端。FTP(文件传输协议) 是 TCP/IP 协议组中的应用层协议。FTP协议使用字符串格式命令字,每条命令都是一行字符串,以“\r\n”结尾。客户端发送格式是:命令+空格+参数+"\r\n"的格式服务器返回格式是以:状态码+空格+提示字符串+"\r\n"的格式,代码只要解析状态码就可以了。读写文件需要登陆服务器,特殊用..._ftp 登录返回230
centos7安装rabbitmq3.6.5_centos7 安装rabbitmq3.6.5-程序员宅基地
文章浏览阅读648次。前提:systemctl stop firewalld 关闭防火墙关闭selinux查看getenforce临时关闭setenforce 0永久关闭sed-i'/SELINUX/s/enforcing/disabled/'/etc/selinux/configselinux的三种模式enforcing:强制模式,SELinux 运作中,且已经正确的开始限制..._centos7 安装rabbitmq3.6.5
idea导入android工程,idea怎样导入Android studio 项目?-程序员宅基地
文章浏览阅读5.8k次。满意答案s55f2avsx2017.09.05采纳率:46%等级:12已帮助:5646人新版Android Studio/IntelliJ IDEA可以直接导入eclipse项目,不再推荐使用eclipse导出gradle的方式2启动Android Studio/IntelliJ IDEA,选择 import project3选择eclipse 项目4选择 create project f..._android studio 项目导入idea 看不懂安卓项目
浅谈AI大模型技术:概念、发展和应用_ai大模型应用开发-程序员宅基地
文章浏览阅读860次,点赞2次,收藏6次。AI大模型技术已经在自然语言处理、计算机视觉、多模态交互等领域取得了显著的进展和成果,同时也引发了一系列新的挑战和问题,如数据质量、计算效率、知识可解释性、安全可靠性等。城市运维涉及到多个方面,如交通管理、环境监测、公共安全、社会治理等,它们需要处理和分析大量的多模态数据,如图像、视频、语音、文本等,并根据不同的场景和需求,提供合适的决策和响应。知识搜索有多种形式,如语义搜索、对话搜索、图像搜索、视频搜索等,它们可以根据用户的输入和意图,从海量的数据源中检索出最相关的信息,并以友好的方式呈现给用户。_ai大模型应用开发
非常详细的阻抗测试基础知识_阻抗实部和虚部-程序员宅基地
文章浏览阅读8.2k次,点赞12次,收藏121次。为什么要测量阻抗呢?阻抗能代表什么?阻抗测量的注意事项... ...很多人可能会带着一系列的问题来阅读本文。不管是数字电路工程师还是射频工程师,都在关注各类器件的阻抗,本文非常值得一读。全文13000多字,认真读完大概需要2小时。一、阻抗测试基本概念阻抗定义:阻抗是元器件或电路对周期的交流信号的总的反作用。AC 交流测试信号 (幅度和频率)。包括实部和虚部。图1 阻抗的定义阻抗是评测电路、元件以及制作元件材料的重要参数。那么什么是阻抗呢?让我们先来看一下阻抗的定义。首先阻抗是一个矢量。通常,阻抗是_阻抗实部和虚部
小学生python游戏编程arcade----基本知识1_arcade语言 like-程序员宅基地
文章浏览阅读955次。前面章节分享试用了pyzero,pygame但随着想增加更丰富的游戏内容,好多还要进行自己编写类,从今天开始解绍一个新的python游戏库arcade模块。通过此次的《连连看》游戏实现,让我对swing的相关知识有了进一步的了解,对java这门语言也有了比以前更深刻的认识。java的一些基本语法,比如数据类型、运算符、程序流程控制和数组等,理解更加透彻。java最核心的核心就是面向对象思想,对于这一个概念,终于悟到了一些。_arcade语言 like
随便推点
【增强版短视频去水印源码】去水印微信小程序+去水印软件源码_去水印机要增强版-程序员宅基地
文章浏览阅读1.1k次。源码简介与安装说明:2021增强版短视频去水印源码 去水印微信小程序源码网站 去水印软件源码安装环境(需要材料):备案域名–服务器安装宝塔-安装 Nginx 或者 Apachephp5.6 以上-安装 sg11 插件小程序已自带解析接口,支持全网主流短视频平台,搭建好了就能用注:接口是公益的,那么多人用解析慢是肯定的,前段和后端源码已经打包,上传服务器之后在配置文件修改数据库密码。然后输入自己的域名,进入后台,创建小程序,输入自己的小程序配置即可安装说明:上传源码,修改data/_去水印机要增强版
verilog进阶语法-触发器原语_fdre #(.init(1'b0) // initial value of register (1-程序员宅基地
文章浏览阅读557次。1. 触发器是FPGA存储数据的基本单元2. 触发器作为时序逻辑的基本元件,官方提供了丰富的配置方式,以适应各种可能的应用场景。_fdre #(.init(1'b0) // initial value of register (1'b0 or 1'b1) ) fdce_osc (
嵌入式面试/笔试C相关总结_嵌入式面试笔试c语言知识点-程序员宅基地
文章浏览阅读560次。本该是不同编译器结果不同,但是尝试了g++ msvc都是先计算c,再计算b,最后得到a+b+c是经过赋值以后的b和c参与计算而不是6。由上表可知,将q复制到p数组可以表示为:*p++=*q++,*优先级高,先取到对应q数组的值,然后两个++都是在后面,该行运算完后执行++。在电脑端编译完后会分为text data bss三种,其中text为可执行程序,data为初始化过的ro+rw变量,bss为未初始化或初始化为0变量。_嵌入式面试笔试c语言知识点
57 Things I've Learned Founding 3 Tech Companies_mature-程序员宅基地
文章浏览阅读2.3k次。57 Things I've Learned Founding 3 Tech CompaniesJason Goldberg, Betashop | Oct. 29, 2010, 1:29 PMI’ve been founding andhelping run techn_mature
一个脚本搞定文件合并去重,大数据处理,可以合并几个G以上的文件_python 超大文本合并-程序员宅基地
文章浏览阅读1.9k次。问题:先讲下需求,有若干个文本文件(txt或者csv文件等),每行代表一条数据,现在希望能合并成 1 个文本文件,且需要去除重复行。分析:一向奉行简单原则,如无必要,绝不复杂。如果数据量不大,那么如下两条命令就可以搞定合并:cat a.txt >> new.txtcat b.txt >> new.txt……去重:cat new...._python 超大文本合并
支付宝小程序iOS端过渡页DFLoadingPageRootController分析_类似支付宝页面过度加载页-程序员宅基地
文章浏览阅读489次。这个过渡页是第一次打开小程序展示的,点击某个小程序前把手机的开发者->network link conditioner->enable & very bad network 就会在停在此页。比如《支付宝运动》这个小程序先看这个类的.h可以看到它继承于DTViewController点击左上角返回的方法- (void)back;#import "DTViewController.h"#import "APBaseLoadingV..._类似支付宝页面过度加载页