hive函数大全(数学函数,集合函数,类型转换,日期函数,条件函数,字符串函数,及侧视图)_hive 比特右移-程序员宅基地
技术标签: hive
在hive中,可以使用以下命令查看某个函数的用法:
desc function extended 函数名字;
比如查函数date_add函数的用法:
desc function extended date_add;运行结果如下:

目录
数学函数
1.log(double base,double a):返回以base为底数a的对数。返回类型为double
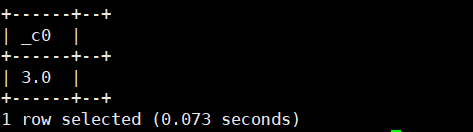
select log(2,8);运行结果如下:
2.pow(double base,double p):返回以base为底数p的幂值。返回类型为double
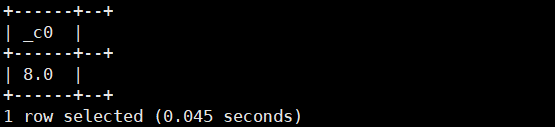
select pow(2,3);运行结果如下:
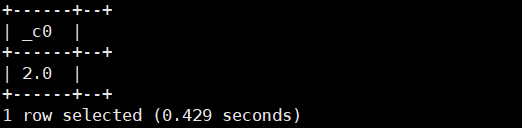
select pow(4,0.5);//相当于开方运行结果如下:
3.conv(bigint/string base,int from_base,int to_base):将数值base从from_base进制转为to_base进制string
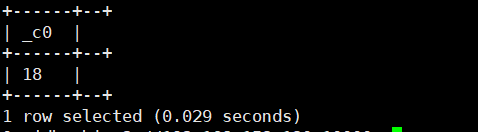
select conv('10010',2,10);(2进制转10进制)运行结果如下:
4.pmod(int/double a,int/double b):求a余b的结果。返回类型为int/double
select pmod(5,2);运行结果如下:

5.hex(string a)/unhex(string a):求字符串a的正反16进制转化(可以当成简单的加密)
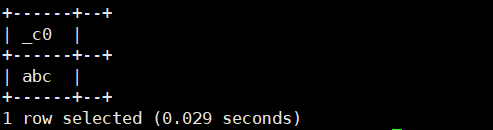
select hex('abc');运行结果如下:
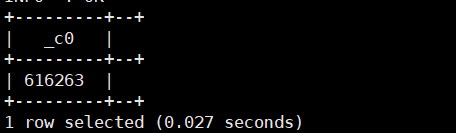
select unhex('616263');运行结果如下:
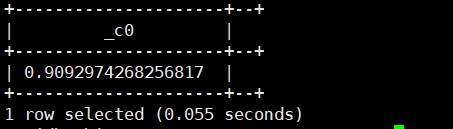
6.sin(double/decimal a):求a的正弦值。返回类型为:double
select sin(2);运行结果如下:
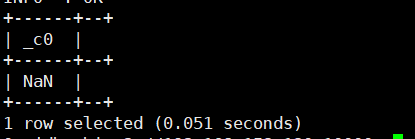
asin(double/decimal a):求a的反正弦值。返回类型为:double
select asin(2);运行结果如下:
7. cos(double/decimal a):求a的余弦值。返回类型为:double
select cos(2);运行结果如下:
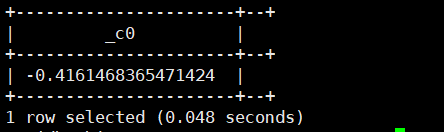
acos(double/decimal a):求a的反余弦值。返回类型为:double
select acos(2);
运行结果如下:
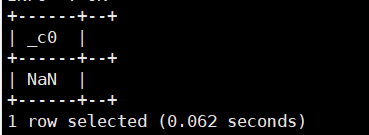
8.tan(double/decimal a) :求a的正切值。返回类型为:double
select tan(2);运行结果如下:
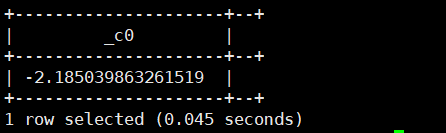
atan(double/decimal a) :求a的反正切值。返回类型为:double
select atan(2);运行结果如下:
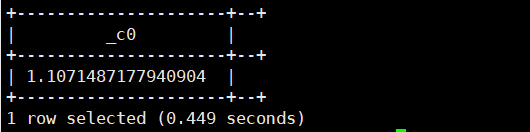
9. degree(double/decimal a):将弧度a转为角度。返回类型为:double
select degrees(2);运行结果如下:
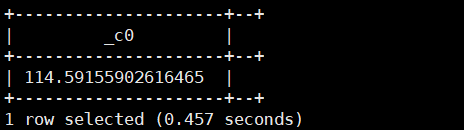
10. radians(double/decimal a):将角度a转为弧度。返回类型为:double
select radians(114.59155902616465);
运行结果如下:
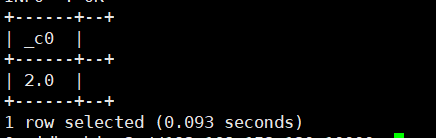
11.positive(int/double a):返回a本身。返回类型为 int/double
select positive(6);运行结果如下:
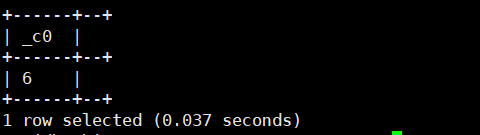
12.negative(int/double a):返回a的相反数。返回类型为 int/double
select negative(6);运行结果如下:
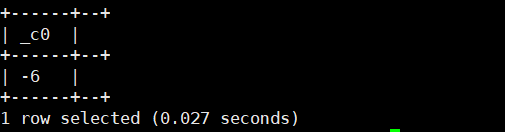
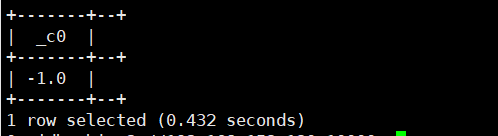
13.sign(double/decimal a):返回a的符号。返回类型为 int/double。正数返回1.0,负数返回-1.0
select sign(-6);运行结果如下:
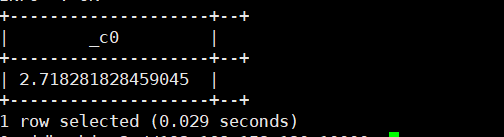
14.e():返回e的值
select e();运行结果如下:
15.pi():返回π的值
select pi();运行结果如下:

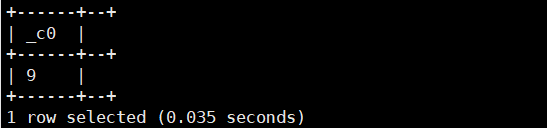
16.greatest(数1,数2,数3...) :返回最大的数(横向)
select greatest(3,6,9);运行结果如下:
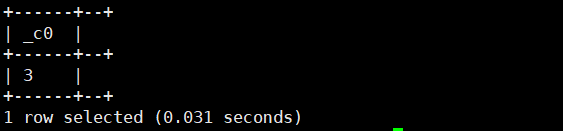
17.least(数1,数2,数3...):返回最小的数(横向)
select least(3,6,9);运行结果如下:
以下几个函数,本人的hive版本暂不支持。
18.bround(double a,int b):四舍六入五取偶
19.factorial(int a):20以内阶乘
20.shiftleft(int a,int b):位左移
21.shiftright(int a,int b):位右移
集合函数
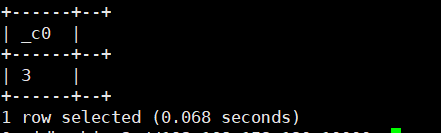
1.size(Map<k,v>/Array<T>):返回Map或者数组中元素的个数或者说返回Map或者数组的长度。返回类型为 int
select size(array(1,2,3));运行结果如下:
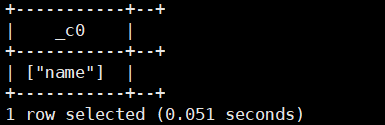
2.map_keys(Map<k,v>):返回对应的键
select map_keys(str_to_map('name:henry'));运行结果如下:
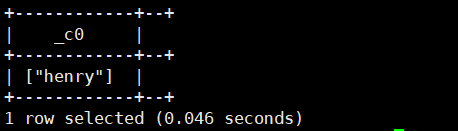
3.map_values(Map<k,v>):返回对应的值
select map_values(str_to_map('name:henry'));运行结果如下:
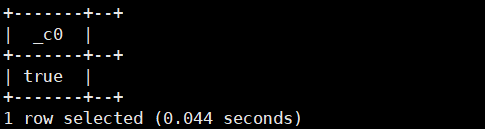
4.array_contains(Array<T>,T):如该数组Array<T>包含value返回true,否则返回false。返回类型为boolean
select array_contains(array('a','b','c'),'a');运行结果如下:
5.sort_array(Array<T>):排序并返回。返回类型为Array<T>
select sort_array(array('5','3','2'));运行结果如下:
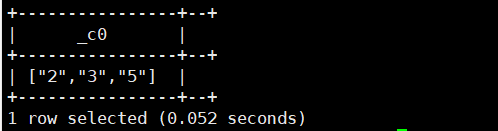
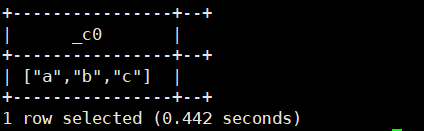
6.array(T...t):返回数组类型
select array('a','b','c');运行结果如下:
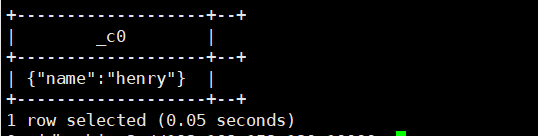
7.map(K k1,V v1...):返回map类型
select map('name','henry');运行结果如下:
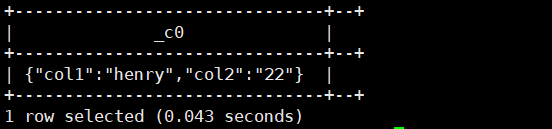
8.struct(p1,v1,p2,v2...):返回struct(结构体)类型
select struct('henry','22');运行结果如下:
类型转换
cast(expr as<type>) :将expr表达式转换成type类型
select cast(current_date() as string);
运行结果如下:
日期函数
1.from_unixtime(bigint time,string time_format):格式化时间,也可提取指定部分
select from_unixtime(12345678,'yyyy-MM-dd HH:mm:ss');运行结果如下:
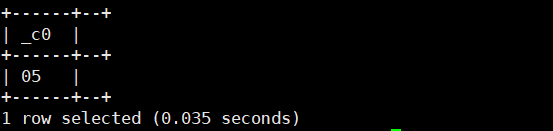
select from_unixtime(12345678,'ss');运行结果如下:
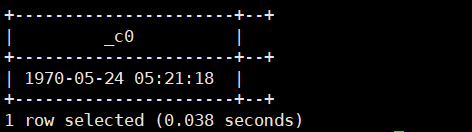
2.date_format(date/timestamp/string date,string format):返回指定的日期部分
select date_format('1970-05-24 05:21:18','MM');运行结果如下:
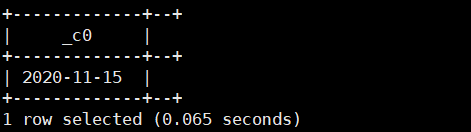
3.current_date():返回当前系统日期
select current_date();运行结果如下:
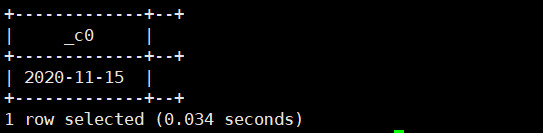
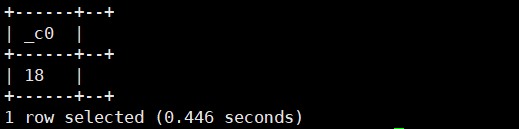
4.to_date(string timestamp):将完整的日期及时间字符串返回日期
select to_date('2020-11-11 17:46:54.982');运行结果如下:
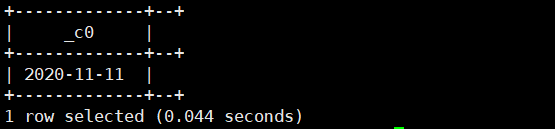
5.current_timestamp():返回当前系统日期及时间
select current_timestamp();运行结果如下:

6.unix_timestamp():获取当前系统时间长整数
select unix_timestamp();运行结果如下:
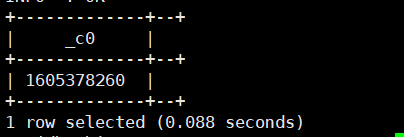
7.unix_timestamp(string datetime):将日期及时间返回一个长整数
select unix_timestamp('2020-11-11 17:46:54.982');运行结果如下:
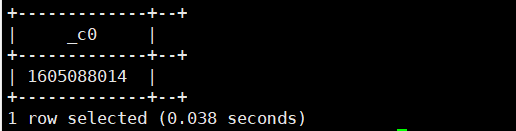
8.unix_timestamp(string datetime,string format_pattern):将日期根据指定的格式提取并转成长整数
select unix_timestamp('2020-11-11 17:46:54.982','yyyy-MM');运行结果如下:
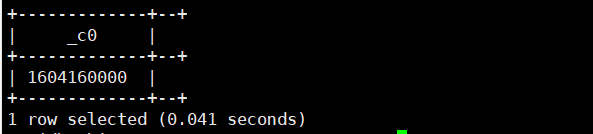
9.date_add(string date,int days):返回日期加上或减去天数的日期
select date_add(current_date(),-10);运行结果如下:

10.add_months(string date,int numberOfMonths):返回日期加上或减去月份数的日期
select add_months(current_date(),2);运行结果如下:

11.last_day(string date):该月最后一天
select last_day(current_date());运行结果如下:
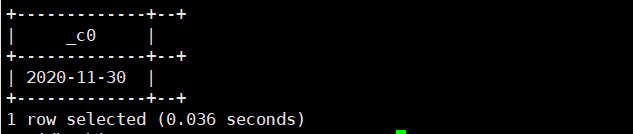
12.next_day(string date,string dayOfWeek):date之后的下一个dayOfWeek为哪一天(MO,TU,WE,TH,FR,SA,SU)
select next_day(current_date(),'TH');//(下一个周四是啥时候,写前两个字母即可)运行结果如下:

13.trunc(string date,string format):返回日期的最开始日期
select trunc(current_date(),'YY');//返回本年的第一天运行结果如下:
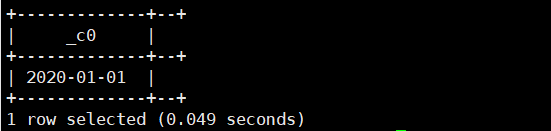
select trunc(current_date(),'MM');//返回本月第一天运行结果如下:
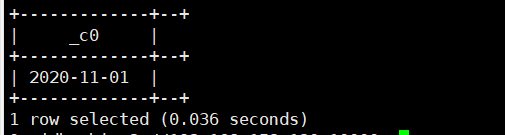
延伸一下:
返回本周的第一天
select date_add(next_day(current_date(),'SU'),-7);运行结果如下:
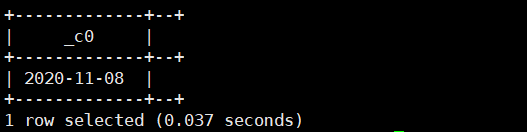
返回本季度的第一天
select concat_ws('-',cast(year(current_date())as string),cast(ceil(month(current_date())/3)*3-2 as string),'1');运行结果如下:

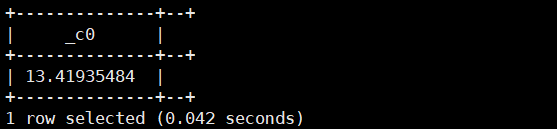
14.months_between(string datefrom,string dateto):返回两个日期相差的月份数
select months_between(current_date(),'2019-10-1');运行结果如下:
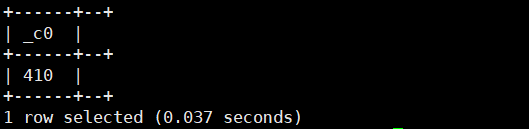
15.datediff(string datefrom,string dateto):返回两个日期相差的天数
select datediff(current_date(),'2019-10-1');运行结果如下:
条件函数
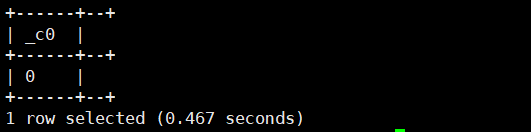
1.if(boolean,T vtrue,T vfalse):第一个参数表达式为真,则返回第二个参数,否则返回第三个参数
select if(true,0,1);运行结果如下:
2.nvl(T value,T default):若第一个值为空,则返回第二个值
select nvl(NULL,1);运行结果如下:
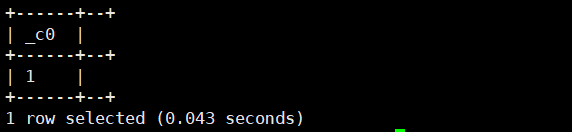
select nvl(2,3);运行结果如下:
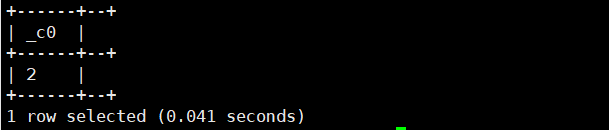
3.coalesce(a,b,...):返回第一个非空的值
select coalesce(NULL,1,2);运行结果如下:

4.case when expr1 then v1 [when expr2 then v2 …][else vn] end:case表示函数开始,end表示函数结束。
如果表达式expr1成立,则返回v1的值;如果表达式expr2成立,则返回v2的值。依次类推,最后遇到else时,返回vn的值。
5.case expr when e1 then v1 [when e2 then v2 …][else vn] end:case表示函数开始,end表示函数结束。
如果表达式expr取值为e1,则返回v1的值;如果表达式expr取值为e2,则返回v2的值,依次类推,最后遇到else,则返回vn的值
6.isnull(a):返回a是否为空值。返回类型为boolean
select isnull(1);运行结果如下:
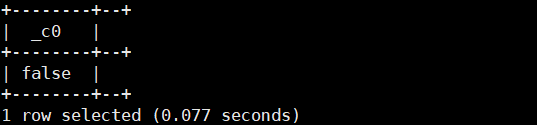
select isnull(null);运行结果如下:

7.isnotnull(a):返回a是否不为空值。返回类型为boolean
select isnotnull(null);运行结果如下:
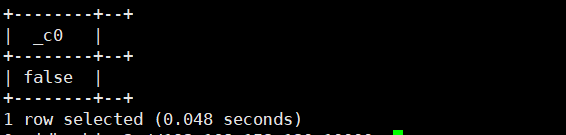
select isnotnull(2);运行结果如下:

字符串函数
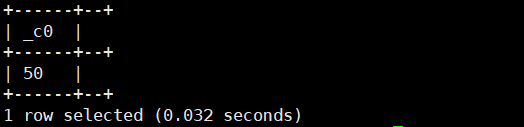
1.ascii(string a):返回字符串首字符的ASC码
select ascii('234');//返回的是2的ASC码运行结果如下:
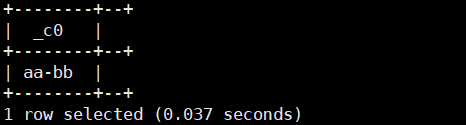
2.concat_ws(string sep,array<string>/string...array):将字符串或者数组以分隔符连接起来。返回类型为string
select concat_ws('-',array('aa','bb'));运行结果如下:
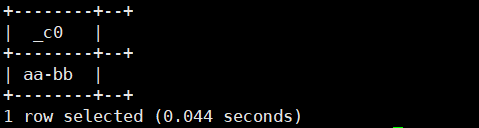
select concat_ws('-','aa','bb');运行结果如下:
3.sentences(string sentence):拆词
select sentences('hello kb10,how are you');运行结果如下:

select sentences('hello kb10!how are you');运行结果如下:

4.ngrams(array<array<string>> arr,int n,int k):按n个单词出现频次,倒序取top k
select ngrams(sentences('hello kb10!how are you'),1,2);运行结果如下:

select ngrams(sentences('hello kb10!how are you,are you'),2,2);运行结果如下:

5.context_ngrams(array<array<string>> arr,array<string>,int k):与array中指定单词之后配合出现频次,倒序取top k
select context_ngrams(sentences('hello kb10?how are you,hello word,are you ok,are we?'),array('are',null),2);运行结果如下:

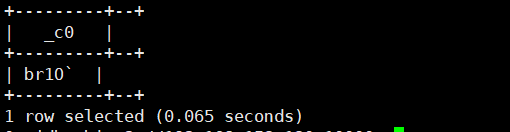
6.encode(string source,string charset):使用指定的字符集charset将字符串编码成二进制值('US-ASCII','ISO-8859-1','UTF-8','UTF-16BE','UTF-16LE','UTF-16')
select encode('我爱你','UTF-16BE');运行结果如下:
7.decode(binary,string charset)将二进制值转为原字符串
select decode(encode('我爱你','UTF-16BE'),'UTF-16BE');运行结果如下:

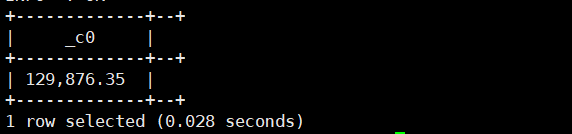
8.format_number(小数,int num):格式化保留精度
select format_number(129876.3456,2);运行结果如下:
9.get_json_object(string json,string path):提取元素,可以多层提取,解析比较复杂的语句
Object表示对象,类似于C语言中的结构体,以花括号"{}"括起来,其元素要求为键值对,key必须为String类型的,而value则可为任意类型。key和value之间以":"表示映射关系,元素之间也是以逗号分隔。
select get_json_object('{"name":"henry"}','$.name');运行结果如下:
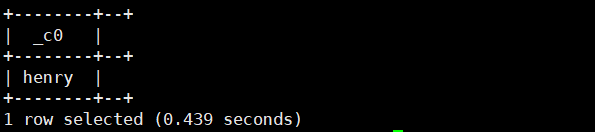
select get_json_object('{"name":"henry","info":{"city":"nj"}}','$.info.city');运行结果如下:

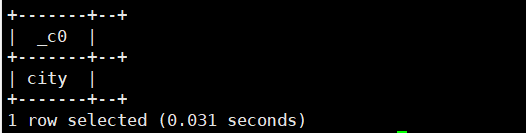
select get_json_object('{"name":"henry","info":["city","nj"]}','$.info[0]');运行结果如下:
10.in_file('文件中一行内容','虚拟机上文件位置'):返回参数1是否在参数2中存在,若存在返回true,不存在返回false
文件alisa.log中有以下内容:

select in_file('hive','/root/hadooptmp/alisa.log');运行结果如下:

11.parse_url('网址','HOST'):解析URL字符串,通过关键字可以获得url中对应的字段数据。
第二个参数可以是HOST(主机)、PATH、☆QUERY(查询)、☆REF(引用自哪里)、PROTOCOL(协议)、AUTHORITY(授权)、FILE(文件)、USERINFO
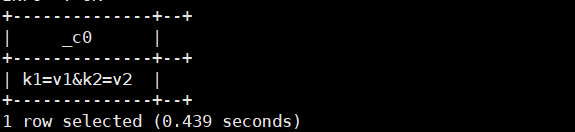
select parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1','QUERY');运行结果如下:
12.printf('%s,%d,%.nf','字符串',数字,小数....):按参数1的顺序打印出后面的参数。%s表示字符串;%d表示整数;%.nf表示保留几位小数
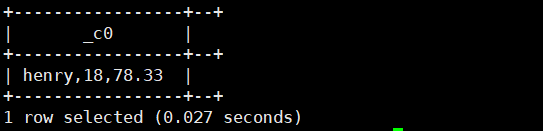
select printf('%s,%d,%.2f','henry',18,78.333);运行结果如下:
13.like '...%':%也可以是#,_
比如,有一张表如下,想要查18开头的电话号码:

select* from shop where contact.mobile like '18%';运行结果如下:

14.rlike # [] {} ? + * \d \w...(正则表达式)
select* from shop where contact.mobile rlike '18\\d{9}';运行结果如下:

15.regexp_replace('1','2','3'):将1中包含的2用3替代
select regexp_replace('you are my hero are you','you','YOU');运行结果如下:

select regexp_replace('you are my hero are you young','y\\w{2,3}','YOU');//以y开头后面有两个或三个字母的都替换成YOU运行结果如下:

16.regexp_extract('','',数字):提取元素
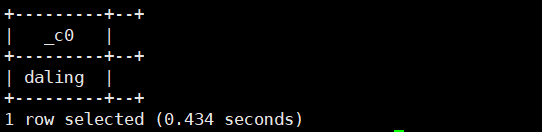
select regexp_extract('namehenryokdalingduck','name(.*?)(ok)(.*?)duck',3);运行结果如下:
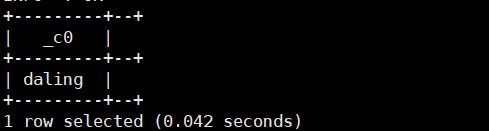
select regexp_extract('namehenryokdalingduck','name(.*?)ok(.*?)duck',2);运行结果如下:
17.split('','正则'):正则分割
例子1:
select split('[email protected]','\\.|@');运行结果如下:
例子2:
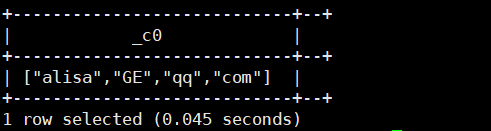
select split(regexp_replace('["henry","pola","ariel"]','\\[|\\]|"',''),',');运行结果如下:
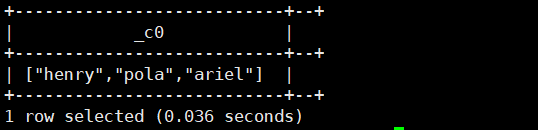
可以通过size方法查看是否分割了:
select size(split(regexp_replace('["henry","pola","ariel"]','\\[|\\]|"',''),','));运行结果如下:
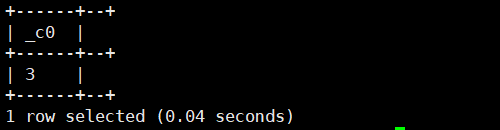
结果为3,说明已分割。
18.str_to_map('字符串')或者str_to_map('字符串','正则'):字符串转换成map形式
select str_to_map('name:henry');运行结果如下:

select str_to_map('name#henry|age#22','\\|','#');运行结果如下:

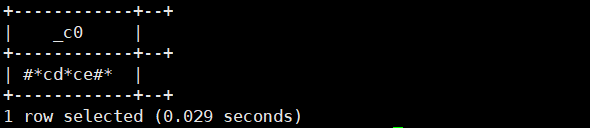
19.translate('字符串','子字符串','3'):按字符替换。将参数1字符串中包含参数2子字符串的用参数3替换
select translate('abcdbceab','ab','#*');//将a替换成#,将b替换成*运行结果如下:
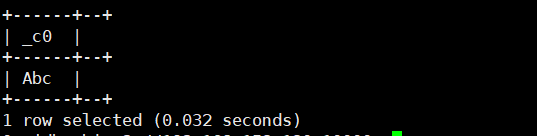
20.initcap(' '):单词首字母大写
select initcap('abc');运行结果如下:
21.substr(' ',n)或者substr(' ',n,len):截取字符串
select substr('abcdfgeabcdf',2);运行结果如下:
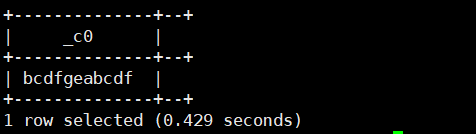
select substr('abcdfgeabcdf',2,3);运行结果如下:
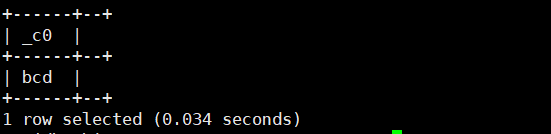
22.locate('子字符串','字符串',n):返回子字符串在字符串中,第几个子字符串的位置。位置从1开始,如果没有就会返回0
select locate('ab','abcdfab',2);运行结果如下:
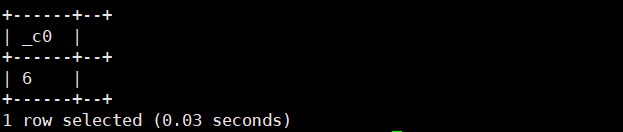
23.instr('字符串','子字符串'):返回子字符串在字符串中的位置
select instr('cdab','ab');运行结果如下:
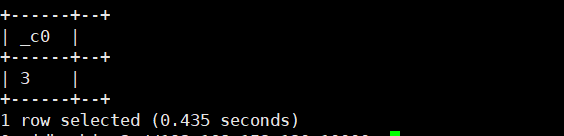
24.md5(' '):加密
select md5('abc');运行结果如下:
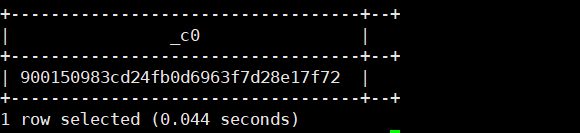
25.base64(''):将二进制格式转换成base 64位的字符串
select base64(cast('henry' as binary));运行结果如下:
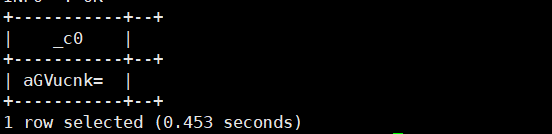
26.unbase64(' '):将64位的字符串转换二进制值
select unbase64('aGVucnk=');运行结果如下:
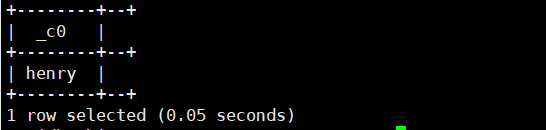
27.sha2(''/binary,长度):加密。
select sha2('henry',1);运行结果如下:

28.soundex(string src):返回字符串的soundex码。表现形式:首字母+3个数字
select soundex('hero');运行结果如下:
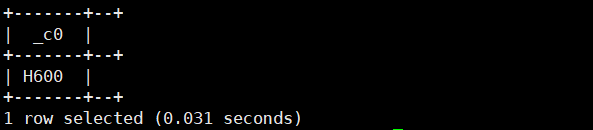
29.levenshtein(' ',' '):计算两个字符串之间的差异大小
select levenshtein('aa','a');运行结果如下:
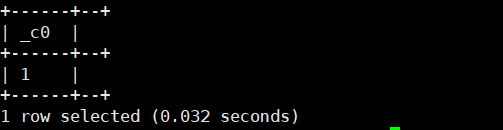
聚合函数
1.count(*):计数。统计所有行
2.count(expr):计数。统计expr。expr不能为空
3.count(distinct expr...):计数。所有表达式(列)唯一并不为空
4.sum(distinct expr...):求和。
5.avg(distinct expr...):求平均值。
6.min(col):求最小值。
7.max(col):求最大值。
8.var_pop(col):方差(离散程度)
9.var_sample(col):样本方差(变异程度)
10.studev_pop(col):标准偏差
11.studev_sample(col):样本标准偏差
12.covar_pop(col1,col2):协方差
13.covar_sample(col1,col2):样本协方差
14.corr(col1,col2):两列数值的相关系数
15.percentile(bigint col,int p):返回col的p(0~1)%分位数
16.collect_list(col):行转列(可以想象一下group_concat)。重复值不会舍去
17.collect_set(col):行转列。将重复的值舍去
表生成函数
1.explode(array<T>/Map<k,v>):展开array或者Map,对列进行多行转换
select explode(array('aa','bb','cc'));运行结果如下:

举个小例子:
有一张表,内容如下:

想要对上述的cities转多行:
select name,city from employee_id lateral view explode(cities) ct as city;运行结果如下:

想要对上述scores转多行:
select name,pos,score from employee_id lateral view explode(scores) st as pos,score;运行结果如下:

2.posexplode(array<T>):将一列数据转为多行之后,还会输出数据的下标。表现得像数组爆炸,但包括原始数组中项目的位置
select posexplode(array('aa','bb','cc'));运行结果如下:
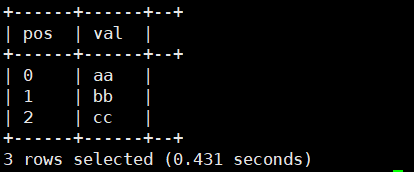
举个小例子,对cities转多行。
select name,pos,city from employee_id lateral view posexplode(cities) ct as pos,city;运行结果如下:

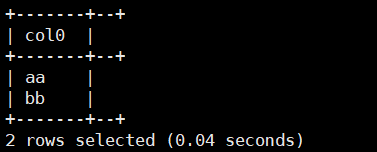
3.stack(rowNum,v1,...vm):将v1~vm拆成rownum行
select stack(2,'aa','bb');运行结果如下:
4.json_tuple(string json,string...key):对json数据格式解析 。tuple表现形式为 (key,value),要配合侧视图lateral view。tuple只能一层层提取
举个例子,有一张表jsontuple:

提取line层:
select name,hobbies,age from jsontuple lateral view json_tuple(line,'name','hobbies','age') jt as name,hobbies,age;运行结果如下:

提取name层:
select printf('%s %s',first,last)name,hobbies,age from jsontuple
lateral view json_tuple(line,'name','hobbies','age') jt as name,hobbies,age
lateral view json_tuple(name,'first','last') jt1 as first,last;运行结果如下:

提取hobbies层:
select printf('%s %s',first,last)name,age,hobby from jsontuple
lateral view json_tuple(line,'name','hobbies','age') jt as name,hobbies,age
lateral view json_tuple(name,'first','last') jt1 as first,last
lateral view explode(split(regexp_replace(hobbies,'\\[|\\]|"',''),',')) hs as hobby;运行结果如下:

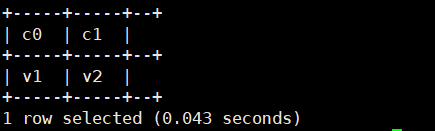
5.parse_url_tuple():通过关键字可以获得url中对应的字段数据,可以同时提取多个部分并返回
select parse_url_tuple('http://baidu.com/path1/p.php?k1=v1&k2=v2#Ref1','QUERY:k1', 'QUERY:k2');运行结果如下:
6.inline():将单列扩展成多行
select inline(array(struct('aa','bb','cc'),struct('dd','ee','ff')));运行结果如下:

窗口函数
如需控制范围需要指定...over(...rows between ??? and ???)
1.first_value(col):分组内排序后截止到当前行的第一个值
2.last_value(col):分组内排序后截止到当前行的最后一个值
3.lag(col,n,default value):窗口内往前第n行col的值
4.lead(col,n,default value):窗口内往后第n行col值
其中,n 可选,默认为1。default value 默认值,如果第n行col值为NULL,取default value
over从句
over(partition by ??? order by ??? rows|range between ??? and ???)
其中,partition by 分区,
order by 全表排序
有partition by:分区内排序,否则全局排序
rows|range between ??? and ???
有partition by:
unbounded preceding:区内第一行
unbounded following:区内最后一行
无partition by:
unbounded preceding:表内第一行
unbounded following:表内最后一行
1、使用标准的聚合函数COUNT、SUM、MIN、MAX、AVG
2、使用partition by语句,使用一个或多个原始数据类型的列
3、使用partition by语句与order by语句,使用一个或者多个数据类型的分区或者排序列
4、使用窗口规范,窗口规范支持以下格式:
(rows | range) between (unbounded | [num]) preceding and ([num] preceding | current row | (unbounded | [num]) following)
(rows | range) between current row and (current row | (unbounded | [num]) following)
(rows | range) between [num] following and (unbounded | [num]) following
5、当order by后面缺少窗口从句条件,窗口规范默认是 range between unbounded preceding and current row.
6、当order by和窗口从句都缺失, 窗口规范默认是 row between unbounded preceding and unbounded following.
7、over从句支持以下函数, 但是并不支持和窗口一起使用它们。
8、ranking函数: rank, ntile, denserank, cumedist, percentrank,lead 和 lag 函数。
分析函数
1.row_number():从1开始的行序号
2.rank():从1开始的名次(并列出现空缺) 1,2,2,4
3.dense_rank():从1开始的名次(并列不留空缺) 1,2,2,3
4.cume_dist:小于等于当前值得行数/分组内总行数
比如,统计小于等于当前薪水的人数,所占总人数的比例
5.percent_rank:分组内当前行当前行的rank值-1/分组内总行数-1
6.ntile(n):用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布
ntile不支持rows between,
比如 ntile(2) over(partition by cookieid order by createtime rows between 3 preceding and current row)
视图(view)
格式为:
create view V_NAME as
select语句
侧视图(lateral view)
侧视图出现要与表生成函数一起使用。它是一张虚拟的临时表。能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合
格式为:
select...from 表名 lateral view 函数(expr) 别名 as 属性名;
智能推荐
PHP-生成缩略图和添加水印图-学习笔记-程序员宅基地
文章浏览阅读82次。1.开始 在网站上传图片过程,经常用到缩略图功能。这里我自己写了一个图片处理的Image类,能生成缩略图,并且可以添加水印图。2.如何生成缩略图 生成缩略图,关键的是如何计算缩放比率。 这里,我根据图片等比缩放,宽高的几种常见变化,得出一个算缩放比率算法是,使用新图(即缩略图)的宽高,分别除以原图的宽高,看哪个值大,就取它作为缩放比率:...
dyld: Library not loaded: @rpath/libswiftCore.dylib ... Reason: image not found 解决-程序员宅基地
文章浏览阅读2.7k次。在室友Xcode继承一些framework时,爆出了如下错误:dyld: Library not loaded: @rpath/libswiftCore.dylib Referenced from: /private/var/containers/Bundle/Application/1761A6FE-9D6B-45F7-9F9F-922C94BF54A3/demo.app/Framewor..._library not loaded: @rpath/libswiftcore.dylib
linux gvim 快捷键tab,Linux中Vim的常用命令及快捷键-程序员宅基地
文章浏览阅读356次。光标控制命令h或^h向左移一个字符j或^j或^n向下移一行k或^p向上移一行l或空格向右移一个字符G移到文件的最后一行nG移到文件的第n行w..._gvim itab
umi4 项目使用umi-plugin-keep-alive缓存页面(react-activation)-程序员宅基地
文章浏览阅读1k次,点赞12次,收藏10次。按 name 卸载缓存状态下的 节点,name 可选类型为 String 或 RegExp,注意,仅卸载命中 的第一层内容,不会卸载 中嵌套的、未命中的。按 name 刷新缓存状态下的 节点,name 可选类型为 String 或 RegExp,注意,仅刷新命中 的第一层内容,不会刷新 中嵌套的、未命中的。按 name 卸载缓存状态下的 节点,name 可选类型为 String 或 RegExp,将卸载命中 的所有内容,包括 中嵌套的所有。true: 卸载时缓存。获取所有缓存中的节点。_umi-plugin-keep-alive
memory compiler使用流程-程序员宅基地
文章浏览阅读3k次,点赞2次,收藏25次。用了几天的memory compiler,搞清楚了它的使用流程。因为这个软件是不开源的,而且手册又很长,没有快速阅读指南,所以就花了挺多时间学习手册细节,想把其中比较主要的流程记录下来,供大家学习参考。它是一个用来综合一些IP核的软件,它里面各种各样的memory compiler,可以根据自己的选择选中一个,设置好参数之后就能生成想要的参数的memory。 因为每个memory compiler可能工艺不一样,端口数不一样,所以里面有手册告诉你这些细节的。(手册很多,每个手册几百页上下)1、首先就是要安装_memory compiler
Android 读取csv格式数据文件-程序员宅基地
文章浏览阅读5.6k次,点赞5次,收藏16次。前言什么是csv文件呢?百度百科上说 CSV是逗号分隔值文件格式,也有说是电子表格的,既然是电子表格,那么就可以用Excel打开,那为什么要在Android中来读取这个.csv格式的文件呢?因为现在主流数据格式是采用的JSON,但是另一种就是.csv格式的数据,这种数据通常由数据库直接提供,进行读取。下面来看看简单的使用吧正文首先还是先来创建一个项目,名为ReadCSV准备.csv格式的文件,点击和风APILocationList下载ZIP,保存到本地,然后解压,这个时候在你的项目文件中新建_android 读取csv
随便推点
Hive与HBase之间的区别和联系_hive hbase-程序员宅基地
文章浏览阅读2.7w次,点赞36次,收藏161次。首先要知道Hive和HBase两者的区别,我们必须要知道两者的作用和在大数据中扮演的角色概念Hive1.Hive是hadoop数据仓库管理工具,严格来说,不是数据库,本身是不存储数据和处理数据的,其依赖于HDFS存储数据,依赖于MapReducer进行数据处理。2.Hive的优点是学习成本低,可以通过类SQL语句(HSQL)快速实现简单的MR任务,不必开发专门的MR程序。3.由于Hive是依赖于MapReducer处理数据的,因此有很高的延迟性,不适用于实时数据处理(数据查询,数据插_hive hbase
【故障诊断】BP神经网络电机数据特征提取与故障诊断【含Matlab源码 2569期】_故障特征量为无编码比值的bp神经网络-程序员宅基地
文章浏览阅读402次。BP神经网络电机数据特征提取与故障诊断完整的代码,方可运行;可提供运行操作视频!适合小白!_故障特征量为无编码比值的bp神经网络
BIOS、Legacy BIOS和UEFI BIOS:你需要知道的一切-程序员宅基地
文章浏览阅读1.1k次。BIOS 是计算机历史上的一个重要组成部分。这个术语最早是在 20 世纪 70 年代作为 Gary Kildall 开发的 CP/M(微型计算机控制程序)操作系统的一部分使用的。但 BIOS 至今仍在使用。然而,成功的技术现在越来越多地用于现代计算机。Legacy BIOS 和 UEFI BIOSBIOS 的含义是什么?该术语是 Basic Input/Output System(基本输入/输出系统)的首字母缩写,它描述的是作为非易失性存储器储存在计算机主板上的固件。_legacy bios
GitLab集成gitlab-runner_gitlab-runner 16.1.2-程序员宅基地
文章浏览阅读2k次。GitLab Runner是一个开源项目,用于运行您的作业并将结果发送回GitLab。它与GitLab CI结合使用,GitLab CI是GitLab随附的用于协调作业的开源持续集成服务。。_gitlab-runner 16.1.2
缓存数据库的意义、作用与种类详解-程序员宅基地
文章浏览阅读449次,点赞7次,收藏7次。Redis、Memcached等常见的缓存数据库,以及它们各自的特点和优势,使得开发人员可以根据应用场景选择最适合的解决方案。通过合理地配置和使用缓存数据库,可以有效地改善应用程序的性能,降低数据库负载,为用户提供更流畅的体验。缓存数据库允许应用程序在需要数据时,首先从缓存中查询数据,如果数据存在,则可以避免直接访问主数据库,从而显著提高数据访问速度。主数据库通常面临大量读写请求,而缓存数据库可以分担部分读请求,减轻主数据库的负载,提高其稳定性和可靠性。缓存数据库可以作为主数据库的备份,以防止数据丢失。
手把手教你安装VSCode(附带图解步骤)_vscode安装包-程序员宅基地
文章浏览阅读3.3w次,点赞38次,收藏158次。前端开发是创建Web页面或app等前端界面呈现给用户的过程,通过HTML,CSS及JavaScript以及衍生出来的各种技术、框架、解决方案,来实现互联网产品的用户界面交互[1]。它从网页制作演变而来,名称上有很明显的时代特征。在互联网的演化进程中,网页制作是Web1.0时代的产物,,用户使用网站的行为也以浏览为主。随着互联网技术的发展和HTML5、CSS3的应用,现代网页更加美观,交互效果显著,功能更加强大。[2]..._vscode安装包