深度学习 第1讲:深度学习简介和感知机原理与实现_python 单层感知机 深度学习-程序员宅基地
而对于阅读深度学习系列文章的广大数据爱好者而言,小编希望大家能有一些机器学习基础,而且小编不会去刻意用很多通俗的语言去描述数学和计算机科学相关的术语和概念,当然小编也会尽力把主要的知识点说的够敞亮,希望大家理解。那么闲话少说,我们正式开启深度学习的学习之旅~
1
机器学习与深度学习
要是说到深度学习,恐怕不得不先提一下机器学习,解释好二者之间的关系。相信大家心中应该有自己对于机器学习概念的理解。小编这里就一句话简单概括一下:机器学习就是从历史数据中探索和训练出数据的普遍规律,将其归纳为相应的数学模型,并对未知的数据进行预测的过程。至于在这个过程中我们碰到的各种各样的问题,比如数据质量、模型评价标准、训练优化方法、过拟合等一系列关乎机器学习模型生死的问题,小编就不展开来说了,自己去补机器学习知识哈。
在机器学习中,我们有很多很多已经相当成熟了的模型和算法。(这里厘一下模型和算法的概念,小编认为,通常我们所说的像SVM之类的所谓机器学习十大算法其实不应该称之为算法,更应该称其为模型,机器学习的算法应该是在给定模型和训练策略的情况下采取的优化算法,比如梯度下降、牛顿法之类。当然,一般情况下将模型和算法混合称呼也不碍事,毕竟模型中本身就包含着计算规则的意思。)在这很多种机器学习模型中,有一种很厉害的模型,那就是人工神经网络。这种模型从早期的感知机发展而来,对任何函数都有较好的拟合性,但自上个世纪90年代一直到2012年深度学习集中爆发前夕,神经网络受制于计算资源的限制和较差的可解释性,一直处于发展的低谷阶段。之后大数据兴起,计算资源也迅速跟上,加之2012年ImageNet竞赛冠军采用的AlexNet卷积神经网络一举将图片预测的 top5 错误率降至16.4%,震惊了当时的学界和业界。从此之后,原本处于研究边缘状态的神经网络又迅速热了起来,深度学习也逐渐占据了计算机视觉的主导地位。
扯了这么多,无非就是想让大家知道,以神经网络为核心的深度学习理论是机器学习的一个领域分支,所以深度学习其本质上也必须是遵循一些机器学习的基本要义和法则的。传统的机器学习中,我们需要训练的是结构化的数值数据,比如说预测销售量、预测某人是否按时还款等等。但在深度学习中,我们的训练输入就不大是常规的数据了,它可能是一张图像、一段语言、一段对话语料或是一段视频。深度学习要做的就是我丢一张猫的图片到神经网络里,它的输出是猫或者cat这样的标签,丢进去一段语音,它输出的是你好这样的文本。所以机器学习/深度学习的核心任务就是找(训练)一个模型,它能够将我们的输入转化为正确的输出。

(图片来自台湾大学李宏毅教授的deep learning tutorial ppt)
2
感知机与神经网络
就像上面那幅图展示的一样,深度学习看起来就像是一个黑箱子,给定输入之后就出来预测结果,中间的细节很难搞清楚。在实际生产环境下,调用像 tensorflow 这样优秀的深度学习计算框架能够帮助我们快速搭建起一个深度学习项目,但在学习深度学习的过程中,小编并不建议大家一开始就上手各种深度学习框架,希望大家能和小编一道,在把基本的原理搞明白之后利用 python 或者 R 自己手动去编写模型和实现算法细节。
所以,为了学习各种结构的神经网络,我们需要从头开始。感知机作为神经网络和支持向量机的理论基础,相信任何有机器学习基础的同学都清楚其模型细节。简单而言,感知机就是一个旨在建立一个线性超平面对线性可分的数据集进行分类的线性模型。其基本结构如下所示:
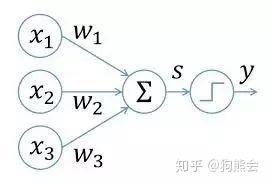
上图从左到右为感知机模型的计算执行方向,模型接受了X1、X2、X3三个输入,将输入与权值参数W进行加权求和并经过 sigmoid 函数进行激活,将激活结果作为 y 进行输出。这便是感知机执行前向计算的基本过程。这样就行了吗?当然不行。按照李航老师的统计学习三要素来打分,刚刚我们只解释了模型,对策略和算法并未解释。当我们执行完前向计算得到输出之后,模型需要根据你的输出和实际的输出按照损失函数计算当前损失,计算损失函数关于权值和偏置的梯度,然后根据梯度下降法更新权值和偏置。经过不断的迭代调整权值和偏置使得损失最小,这便是完整的单层感知机的训练过程。
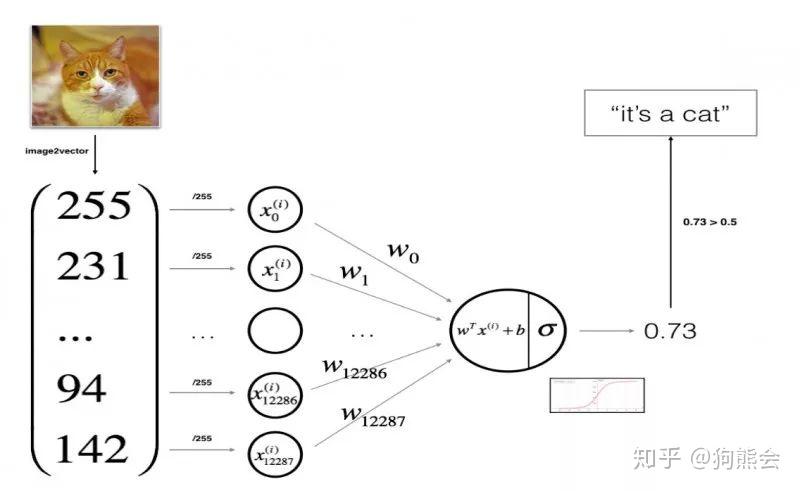
输入为图像的感知机计算过程(图片来自吴恩达老师deeplearningai作业截图)
上述的单层感知机包含两层神经元,即输入与输出神经元,可以非常容易的实现逻辑与、或和非等线性可分情形,但终归而言,这样的一层感知机的学习能力是非常有限的,对于像异或这样的非线性情形,单层感知机就搞不定了。其学习过程会呈现一定程度的振荡,权值参数 w 难以稳定下来,最终不能求得合适的解。
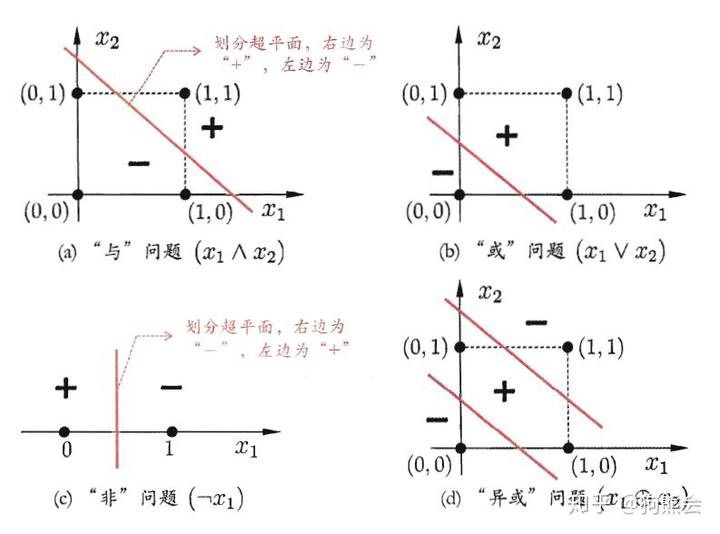
单层感知机难以解决异或问题(截图于周志华老师的《机器学习》)
对于非线性可分的情况,在感知机基础上一般有了两个解决方向,一个就是著名的支持向量机模型,旨在通过核函数映射来处理非线性的情况,这里我们不多谈,读者朋友们可以去回顾复习机器学习中有关的内容,而另一种就是神经网络模型。这里的神经网络模型也叫多层感知机(MLP: Muti-Layer Perception),与单层的感知机在结构上的区别主要在于 MLP 多了若干隐藏层,这使得神经网络对非线性的情况拟合能力大大增强。
一个单隐层的人工神经网络的结构如下图所示:
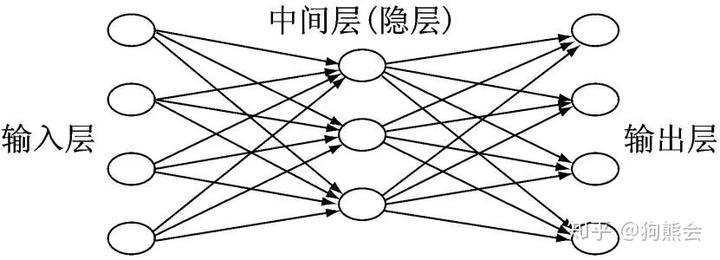
可以看到相较于两层神经元的单层感知机,多层感知机中间多了一个隐藏层,称为隐藏层的含义在于神经网络的训练过程中我们只能观察到输入和输出层的数据,对于中间的隐藏层我们是看不见的,因而在深度神经网络(DNN)中,对于中间看不见又难以进行解释的隐藏层又有个黑箱子的称呼。
含隐藏层的神经网络是如何训练的呢?跟感知机一样,神经网络的训练依然是包含前向计算和反向传播两个主要过程。当然,单层感知机没有反向传播的概念,通常是直接建立损失函数对权值和偏置参数的梯度优化。前向计算过程这里不再细述,就是权值偏置与输入的线性加权和激活操作,在隐藏层上有个嵌套的过程。这里我们重点讲一下反向传播算法(Error BackPropagation,因而也叫误差逆传播),作为神经网络的训练算法,反向传播算法可谓是目前最成功的神经网络学习算法了。我们通常说的 BP 神经网络也就是指应用反向传播算法进行训练的神经网络模型。
那反向传播算法究竟是怎样个工作机制呢?前方高能,需要大家自己补习微积分知识。因为小编实在是没有不借助公式把反向传播讲清楚的能力。假设以一个两层(即单隐层)网络为例,也就是上图中的网络结构,小编带大家详细推导一下反向传播的基本过程。
我们假设输入层为 X ,输入层与隐藏层之间的权值和偏置分别为 W1 和 b1,线性加权计算结果为 Z1 = W1*X + b1,采用 sigmoid 激活函数,隐藏层是激活输出为 a1 = σ(Z1)。而隐藏层到输出层的权值和偏置分别为 W2 和 b2,线性加权计算结果为 Z2 = W2*a1+ b2,激活输出为 a2 = σ(Z2)。所以这个两层网络的前向计算过程为 X-Z1-a1-Z2-a2。
所以反向传播的直观理解就是将上述前向计算过程反过来,但必须是梯度计算的方向反过来,假设我们这里采用交叉熵损失函数:
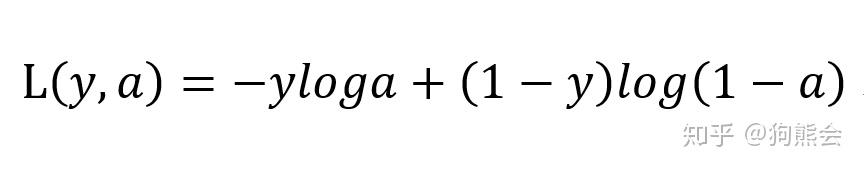
反向传播是基于梯度下降策略的,主要是以目标参数的负梯度方向对参数进行更新,所以基于损失函数对前向计算过程中各个变量进行梯度计算就是非常必要的了。将前向计算过程反过来,那基于损失函数的梯度计算顺序就是 da2-dZ2-dW2-db2-da1-dZ1-dW1-db1。一大堆微分符号!聪明如你应该可以看到我们马上要进行一波链式求导操作。我们从输出 a2 开始进行反向推导。输出层激活输出为 a2,那首先计算损失函数L(y, a) 关于 a2 的微分 da2,影响输出 a2 的是谁呢?由前向传播可知 a2 是由 Z2 经激活函数激活计算而来的,所以计算损失函数关于 Z2 的导数 dZ2 必须经由 a2 进行复合函数求导,即微积分上常说的链式求导法则。然后继续往前推,影响 Z2 的又是哪些变量呢?由前向计算 Z2 = W2*a1+ b2 可知影响 Z2 的有 W2、a1 和 b2,继续按照链式求导法则进行求导即可。最终以交叉熵损失函数为代表的两层神经网络的反向传播向量化求导计算公式如下所示:

在有了梯度计算结果之后,我们便可根据权值更新公式对权值和偏置参数进行更新了,具体计算公式如下,其中 η 为学习率,是个超参数,需要我们在训练时手动指定,当然也可以对其进行调参取得最优超参数。
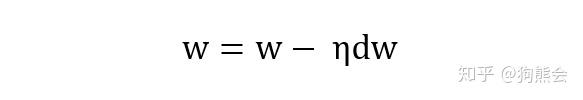
以上便是 BP 神经网络模型和算法的基本工作流程,简单而言就是前向计算得到输出,反向传播调整参数,最后以得到损失最小时的参数为最优学习参数。神经网络的基本总结流程如下图所示:

训练一个 BP 神经网络并非难事,我们有足够优秀的深度学习计算框架通过几行代码就可以搭建起一个全连接网络。但是为了学习和掌握神经网络的基本思维范式和锻炼实际的编码能力,希望大家能够利用 python 或者 R 在不调用任何算法包的情况下根据算法原理手动实现一遍神经网络模型。最后以一个神经网络可视化的动图给大家动态的展示一下神经网络的训练过程:
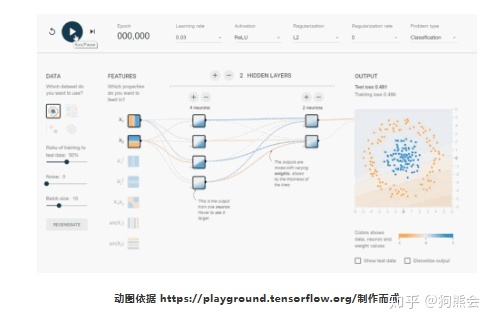
第一讲的内容到这里就结束了,在深度学习第一讲中,我们了解了深度学习和机器学习的基本关系和发展历程,对神经网络的理论基础有了更深层次的学习和掌握。咱们下期见!
每一个HTML文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML文档里, 我们都可以看到类似下面这段代码:
html{color:#000;overflow-y:scroll;overflow:-moz-scrollbars}
body,button,input,select,textarea{font-size:12px;font-family:Arial,sans-serif}
h1,h2,h3,h4,h5,h6{font-size:100%}
em{font-style:normal}
small{font-size:12px}
ol,ul{list-style:none}
a{text-decoration:none}
a:hover{text-decoration:underline}
legend{color:#000}
fieldset,img{border:0}
button,input,select,textarea{font-size:100%}
table{border-collapse:collapse;border-spacing:0}
img{-ms-interpolation-mode:bicubic}
textarea{resize:vertical}
.left{float:left}
.right{float:right}
.overflow{overflow:hidden}
.hide{display:none}
.block{display:block}
.inline{display:inline}
.error{color:red;font-size:12px}
button,label{cursor:pointer}
.clearfix:after{content:'\20';display:block;height:0;clear:both}
.clearfix{zoom:1}
.clear{clear:both;height:0;line-height:0;font-size:0;visibility:hidden;overflow:hidden}
.wordwrap{word-break:break-all;word-wrap:break-word}
.s-yahei{font-family:arial,'Microsoft Yahei','微软雅黑'}
pre.wordwrap{white-space:pre-wrap}
body{text-align:center;background:#fff;width:100%}
body,form{position:relative;z-index:0}
td{text-align:left}
img{border:0}
#s_wrap{position:relative;z-index:0;min-width:1000px}
#wrapper{height:100%}
#head .s-ps-islite{_padding-bottom:370px}
#head_wrapper.s-ps-islite{padding-bottom:370px}#head_wrapper.s-ps-islite #s_lm_wrap{bottom:298px;background:0 0!important;filter:none!important}#head_wrapper.s-ps-islite .s_form{position:relative;z-index:1}#head_wrapper.s-ps-islite .fm{position:absolute;bottom:0}#head_wrapper.s-ps-islite .s-p-top{position:absolute;bottom:40px;width:100%;height:181px}#head_wrapper.s-ps-islite #s_lg_img,#head_wrapper.s-ps-islite#s_lg_img_aging,#head_wrapper.s-ps-islite #s_lg_img_new{position:static;margin:33px auto 0 auto}.s_lm_hide{display:none!important}#head_wrapper.s-down #s_lm_wrap{display:none}.s-lite-version #m{padding-top:125px}#s_lg_img,#s_lg_img_aging,#s_lg_img_new{position:absolute;bottom:10px;left:50%;margin-left:-135px}<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><metahttp-equiv=Content-Typecontent=www.czjy.cn;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>.s-ps-sug table{width:100%;background:#fff;cursor:default}.s-ps-sug td{color:#000;font:14px arial;height:25px;line-height:25px;padding:0 8px}.s-ps-sug td b{color:#000}.s-ps-sug .mo{background:#ebebeb;cursor:pointer}.s-ps-sug .ml{background:#fff}.s-ps-sug td.sug_storage{color:#7a77c8}.s-ps-sug td.sug_storage b{color:#7a77c8}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .mo .sug_del{display:block}
.s-ps-sug .sug_ala{border-bottom:1px solid #e6e6e6}head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来。
智能推荐
AndroidStudio无代码高亮解决办法_android studio 高亮-程序员宅基地
文章浏览阅读2.8k次。AndroidStudio 升级到 4.2.2 版本后,没有代码高亮了,很蛋疼。解决办法是:点开上方的 File,先勾选 Power Save Mode 再取消就可以了。_android studio 高亮
swift4.0 valueForUndefinedKey:]: this class is not key value coding-compliant for the key unity.'_forundefinedkey swift4-程序员宅基地
文章浏览阅读1k次。使用swift4.0整合Unity出现[ valueForUndefinedKey:]: this class is not key value coding-compliant for the key unity.'在对应属性前加@objc 即可。或者调回swift3.2版本_forundefinedkey swift4
Spring Security2的COOKIE的保存时间设置_springsecurity 设置cookie失效时间-程序员宅基地
文章浏览阅读1.3k次。http auto-config="true" access-denied-page="/common/403.htm"> intercept-url pattern="/login.**" access="IS_AUTHENTICATED_ANONYMOUSLY"/> form-login login-page="/login.jsp" defau_springsecurity 设置cookie失效时间
view滑动冲突解决实战篇2(外部拦截法)_viewpage2外部拦截事件-程序员宅基地
文章浏览阅读1.1k次。继上篇内部拦截法需求还是跟上篇一样。只不过这次用外部拦截法来解决;只要在父容器添加如下代码就可以解决了滑动冲突,很简单,套模板就行 // 分别记录上次滑动的坐标(onInterceptTouchEvent) private int mLastXIntercept = 0; private int mLastYIntercept = 0; @Override public bo_viewpage2外部拦截事件
汇编 堆栈 变量存储 指针_汇编语言栈指针-程序员宅基地
文章浏览阅读2.5k次,点赞7次,收藏9次。本文章系作者原创,未经许可,不得转载。汇编 堆栈 变量存储 指针先说栈的概念,栈其实也是一种。。。。。先说内存的概念吧。。。。。额 先说计算机吧,简单来说的话,可以把计算机理解成由CPU,内存,硬盘组成,而CPU内部又包括一种叫做内部寄存器的东西,包括 数据寄存器: AX,BX,CX,DX; 段寄存器: CS,DS,ES,SS; 指针与变址寄存器SP,BP,SI,DI; ..._汇编语言栈指针
架构师之路:从码农到架构师你差了哪些_web架构师-程序员宅基地
文章浏览阅读1w次,点赞14次,收藏56次。转载自 架构师之路:从码农到架构师你差了哪些 Web应用,最常见的研发语言是Java和PHP。 后端服务,最常见的研发语言是Java和C/C++。 大数据,最常见的研发语言是Java和Python。 可以说,Java是现阶段中国互联网公司中,覆盖度最广的研发语言,掌握了Java技术体系,不管在成熟的大公司,快速发展的公司,还是创业阶段的公司,都能有立足之地。有..._web架构师
随便推点
超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门-程序员宅基地
文章浏览阅读7.3k次,点赞6次,收藏36次。超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门
python怎么输出logistic回归系数_python - Logistic回归scikit学习系数与统计模型的系数 - SO中文参考 - www.soinside.com...-程序员宅基地
文章浏览阅读1.2k次。您的代码存在一些问题。首先,您在此处显示的两个模型是not等效的:尽管您将scikit-learn LogisticRegression设置为fit_intercept=True(这是默认设置),但您并没有这样做statsmodels一;来自statsmodels docs:默认情况下不包括拦截器,用户应添加。参见statsmodels.tools.add_constant。另一个问题是,尽管您处..._sm fit(method
VS2017、VS2019配置SFML_vsllfqm-程序员宅基地
文章浏览阅读518次。一、sfml官网下载32位的版本 一样的设置,64位的版本我没有成功,用不了。二、三、四以下这些内容拷贝过去:sfml-graphics-d.libsfml-window-d.libsfml-system-d.libsfml-audio-d.lib..._vsllfqm
vc——类似与beyondcompare工具的文本比较算法源代码_byoned compare 字符串比较算法-程序员宅基地
文章浏览阅读2.7k次。由于工作需要,要做一个类似bc2的文本比较工具,用红色字体标明不同的地方,研究了半天,自己写了一个简易版的。文本比较的规则是1.先比较文本的行数,2.再比较对应行的字符串的长度3.再比较每一个字符串是否相同。具体代码如下:其中m_basestr和m_mergestr里面存放是待比较的字符串int basecount=m_basestr.GetLength(); int mergec_byoned compare 字符串比较算法
aetna java_pom.xml-程序员宅基地
文章浏览阅读79次。xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/maven-v4_0_0.xsd">org.apacheapache174.0.0org.apache.atlasapache-atlas3.0.0-SNAPSHOTMetadata Management and Data Govern..._atlas.pom
生成随机数_<math.h>随机数-程序员宅基地
文章浏览阅读1.5k次。C语言中有可以产生随机数据的函数,需要添加 stdlib. h头文件与time.h头文件。首先在main函数开头加上“ srand(unsigned)time(NULL));",这个语句将生成随机数的种子(不懂也没关系,只要记住这个语句,并且知道 srand是初始化随机种子用的即可)。然后,在需要使用随机数的地方使用 rand()函数。下面是一段生成十个随机数的代码:程序代码:#incl..._随机数