数据压缩第六周作业——DPCM预测编码_预测编码的码元效率计算-程序员宅基地
目录
1、将bmp文件转换为yuv文件(使用之前做的bmptoyuv代码)
实验要求
1、掌握DPCM编解码系统的基本原理。
2、初步掌握实验用C/C++/Python等语言编程实现DPCM编码器,并分析其压缩效率。
实验原理
DPCM(差分预测编码):利用信源相邻符号之间的相关性。早在电视原理和通信原理课上我们便已经接触了DPCM算法。在电视原理在传输视频数据时,经常将预测编码运用到帧内预测和帧间预测,由于视频两帧之间有大量相同内容,利用预测编码,先传输第一个采样点数值,再传输相邻采样点之间的差值,每次传输直接传输差值,第二个采样点=第一个采样点+差值...以此类推。由于视频之间相同内容较多,差值较小,每次传输时可用小比特表示图像,降低了对传输带宽的要求;在通信原理中,在对模拟信号进行编码传输时,也用到了DPCM算法。
(本质:建立一个新信源,将原始信源变为预测误差的信源)
简单总结DPCM算法思想为:根据模型利用以往的样本值对新样本进行预测,每次传输时,只需要传输预测值和实际值之间的差值。
DPCM算法逻辑图:(重点观察两个地方:上半部分量化、下半部分预测)
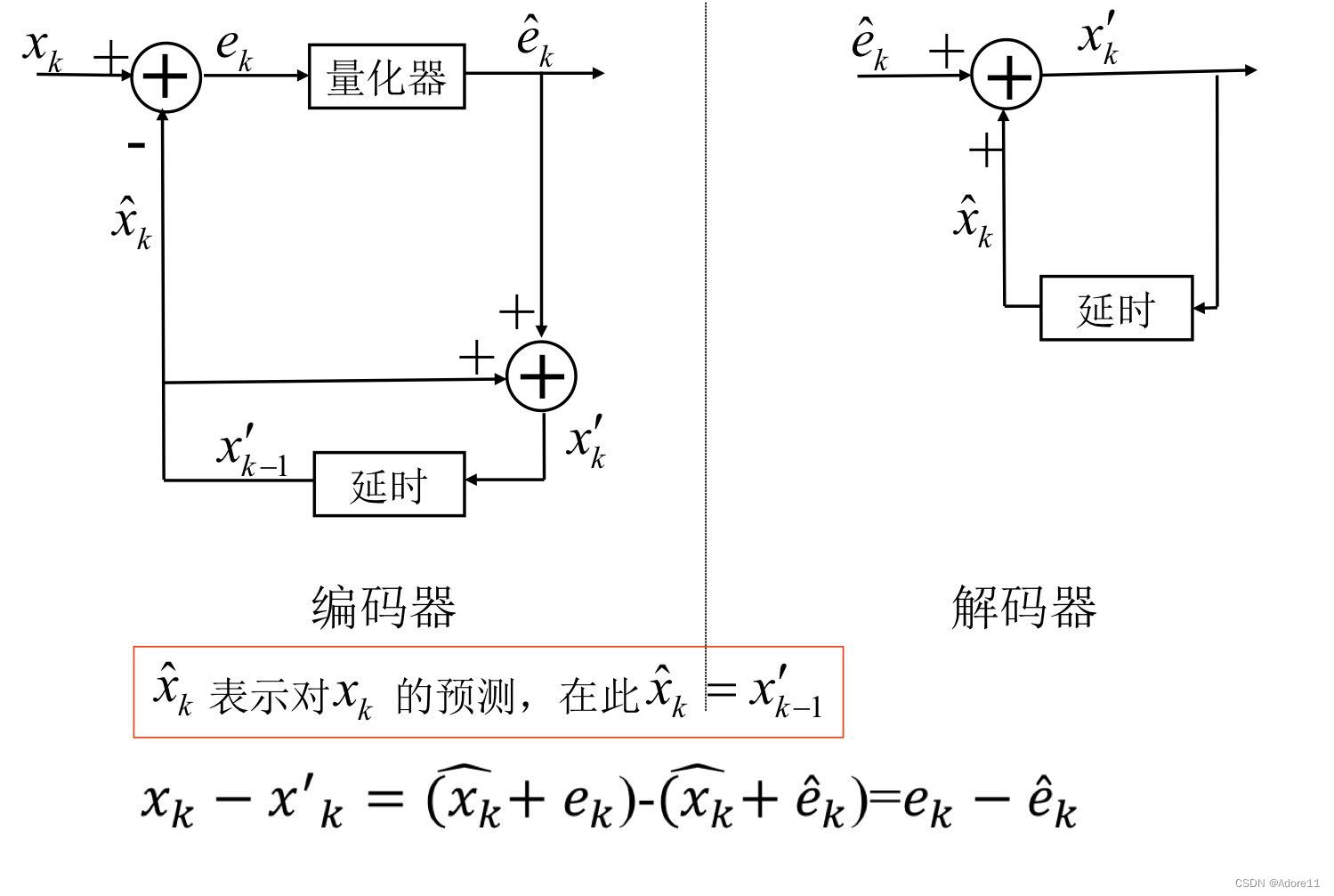
DPCM算法重点在于理解负反馈过程。注意这里的意思:

实验内容
在本次实验中,我们采用固定预测器和均匀量化器。
预测器采用左侧、上方预测均可,量化器采用8比特均匀量化,还可对预测误差进行1比特、2比特和4比特的量化设计(提高要求)。
本实验的目标是验证DPCM编码的编码效率。在DPCM编码器实现的过程中可同时输出预测误差图像和重建图像。将预测误差图像写入文件并将该文件输入Huffman编码器,得到输出码流、给出概率分布图并计算压缩比。将原始图像文件输入Huffman编码器,得到输出码流、给出概率分布图并计算压缩比。
最后比较两种系统(1.DPCM+熵编码和2.仅进行熵编码)之间的编码效率(压缩比和图像质量)。压缩质量以PSNR进行计算。
实验步骤
1.输入图片(提前将bmp文件转换为yuv文件)
2.根据给定的量化比特数进行量化和预测
3.输出预测误差图像和重建图像
4.将预测误差图像写入文件并将该文件输入Huffman编码器
5.根据输出码流画概率分布图、计算压缩比
4.度量失真程度(计算PSNR峰值信噪比)
5.对原始图像和预测误差图像进行Huffman编码
实验代码
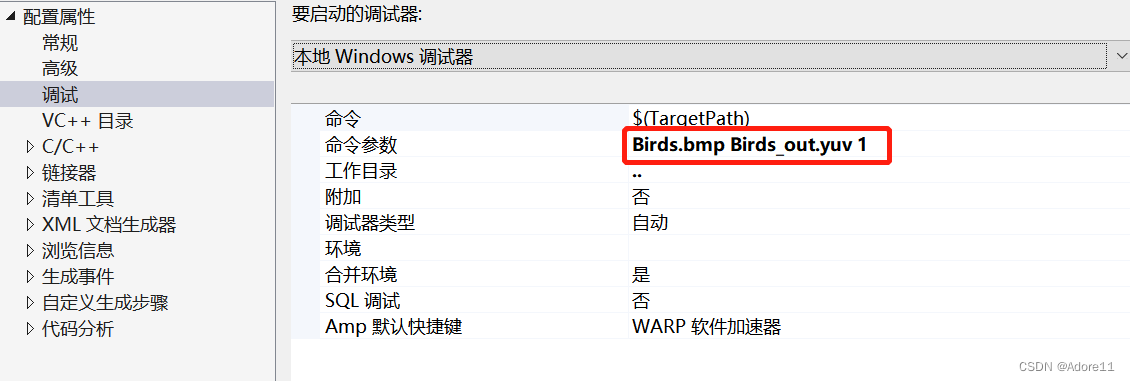
1、将bmp文件转换为yuv文件(使用之前做的bmptoyuv代码)
以Birds.bmp为例,arg[1]表示输入,arg[2]表示输出,1表示读写次数1次,输入rgb文件,输出yuv文件
2、新建项目,设置命令行参数
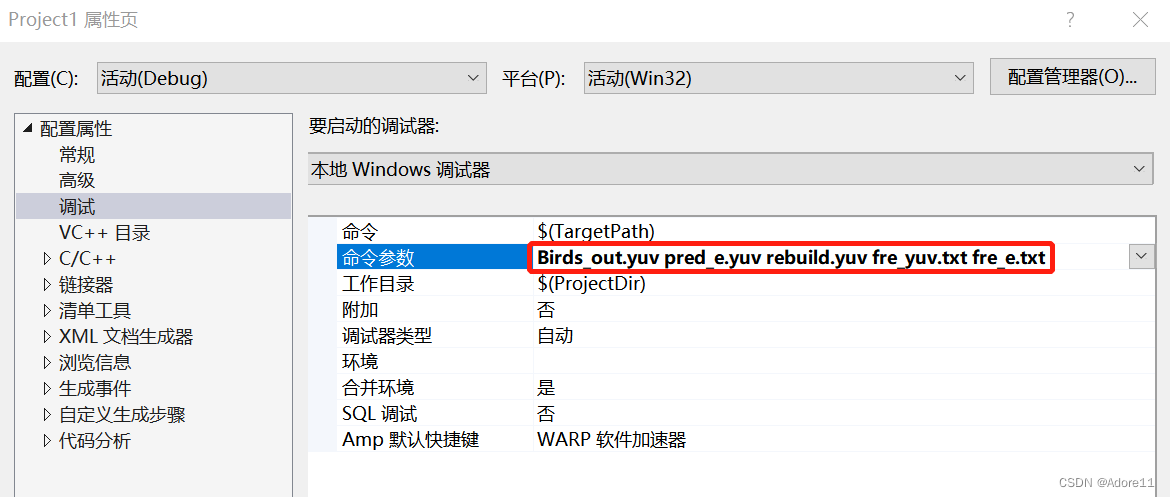
arg[1]表示输入原图,arg[2]表示预测误差,arg[3]表示重建图,arg[4]表示原图概率分布,arg[5]表示残差概率分布
3、main函数
int main(int argc, char* argv[])
{
//初始化
int height = 768;
int width = 512;
int bit = 8;
FILE* yuvname = NULL;
FILE* e_name = NULL;
FILE* rebuid_name = NULL;
FILE* freq_yuv = NULL;
FILE* freq_e = NULL;
//定义缓冲区
unsigned char* predict_buffer;
unsigned char* y_buffer;
unsigned char* u_buffer;
unsigned char* v_buffer;
unsigned char* rebuid_buffer;
y_buffer = (unsigned char*)malloc(width * height);
u_buffer = (unsigned char*)malloc(width * height / 4);
v_buffer = (unsigned char*)malloc(width * height / 4);
rebuid_buffer = (unsigned char*)malloc(width * height);
predict_buffer = (unsigned char*)malloc(width * height);
//打开文件
fopen_s(&yuvname, argv[1], "rb");
fopen_s(&e_name, argv[2], "wb");
fopen_s(&rebuid_name, argv[3], "wb");
fopen_s(&freq_yuv, argv[4], "wb");
fopen_s(&freq_e, argv[5], "wb");
if (yuvname == NULL || e_name == NULL || rebuid_name == NULL)
{
cout << "Open Error!" << endl;
return 0;
}
//读取文件
fread(y_buffer, 1, width * height, yuvname);
fread(u_buffer, 1, (width * height) / 4, yuvname);
fread(v_buffer, 1, (width * height) / 4, yuvname);
//预测差分编码
DPCM(y_buffer, predict_buffer, rebuid_buffer, width, height, bit);
//计算PSNR
PSNR(y_buffer, rebuid_buffer, height, width, bit);
//计算概率分布
int size = height * width;
int count[256] = { 0 };
int pro_y[256] = { 0 };
int pro_e[256] = { 0 };
for (int i = 0; i < size; i++) {
int color = *(y_buffer + i);// (int_buf + i)点的灰度值
count[color]++;
}
for (int j = 0; j < 256; j++)//灰度概率
{
pro_y[j] = (double(count[j]) / size);//原图的概率分布
}
for (int i = 0; i < size; i++) {
int color = *(predict_buffer + i);// (int_buf + i)点的灰度值
count[color]++;
}
for (int j = 0; j < 256; j++)//灰度概率
{
pro_e[j] = (double(count[j]) / size);//预测误差的概率分布
}
//写预测误差文件
fwrite(predict_buffer, 1, width * height, e_name);
fwrite(u_buffer, 1, (width * height) / 4, e_name);
fwrite(v_buffer, 1, (width * height) / 4, e_name);
//写预重建图像文件
fwrite(rebuid_buffer, 1, width * height, rebuid_name);
fwrite(u_buffer, 1, (width * height) / 4, rebuid_name);
fwrite(v_buffer, 1, (width * height) / 4, rebuid_name);
//写概率分布
for (int i = 0; i < 256; i++) {
fprintf(freq_yuv, "%f\n", pro_y[i]);
fprintf(freq_e, "%f\n", pro_e[i]);
}
free(y_buffer);
free(u_buffer);
free(v_buffer);
free(predict_buffer);
free(rebuid_buffer);
fclose(yuvname);
fclose(e_name);
fclose(rebuid_name);
return 0;
}4、定义DPCM函数:
采用左向预测


原始值取值范围(0,255),减去预测值(0,255),预测误差的范围为(-255,255),为保证传入的误差值为正,(预测误差+255),范围为(0,510)-->所需要的bit数为9bit。如果之后想要用4bit、16bit量化可以按照
int Quality(int error, int bit) {///量化
return (error + 255) / pow(2, (9 - bit));//这里pow就是2的(9-bit)次方
}
int FanQuality(int bit, unsigned char rebuid_buffer) {反量化
return rebuid_buffer *pow(2,(9-bit))-255;
}
void DPCM(unsigned char* y_buffer, unsigned char* predict_buffer, unsigned char* rebuid_buffer, int width, int height, int bit)
{
int error;
for (int i = 0; i < height; i++) {///行
for (int j = 0; j < width; j++) {列
if (j == 0) { //第一列以128进行预测
error = (y_buffer[i * width + j]) - 128; //误差值
predict_buffer[i * width + j] = Quality(bit, error); //量化误差值
rebuid_buffer[i * width + j] = FanQuality(bit, predict_buffer[i * width + j]) + 128; //重建值(反量化之后)
}
else { //其他列都以前一列进行预测
error = (y_buffer[i * width + j]) - rebuid_buffer[i * width + j - 1]; //误差值,左侧-右侧
predict_buffer[i * width + j] = Quality(bit, error); //量化误差值
rebuid_buffer[i * width + j] = FanQuality(bit, predict_buffer[i * width + j]) + rebuid_buffer[i * width + j - 1]; //重建值
}
}
}
}5、PSNR峰值信噪比函数
在客观评价图像质量时,我们经常会遇到峰值信噪比PSNR,计算PSNR需要提前计算MSE,这里给出下面两个的公式:
PS:这里的MAX为图像的灰度级,一般等于255。
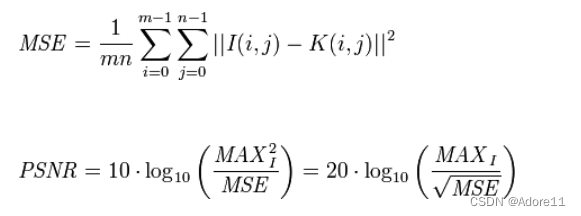
double PSNR(unsigned char* y_buffer, unsigned char* rebuid_buffer, int height, int width, int dep) {
double max = 255;
double mse = 0;
double psnr=0;
for (int i = 0; i < height; i++)
for (int j = 0; j < width; j++) {
mse += (y_buffer[i * width + j] - rebuid_buffer[i * width + j]) * (y_buffer[i * width + j] - rebuid_buffer[i * width + j]);
}
mse = mse / (double)(width * height);
psnr = 10 * log10((double)(max * max) / mse);
return psnr;
}得到PSNR结果:
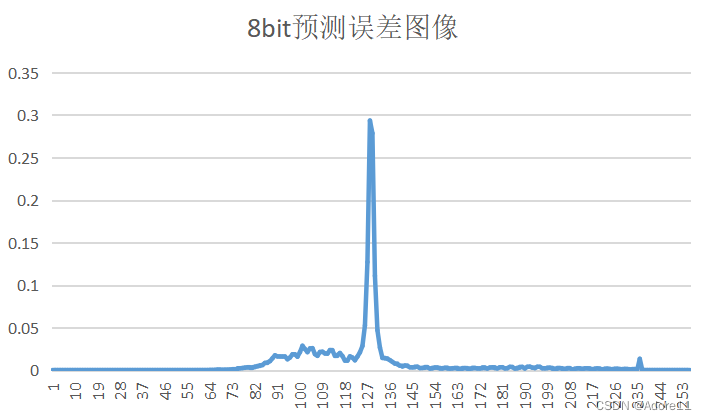
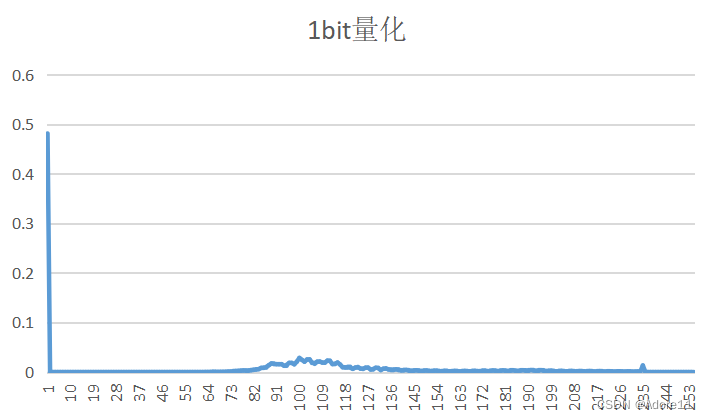
| 量化比特数 | PSNR(客观评价) | 预测误差图像 | 重建图像(主观评价) | 概率分布 |
| 8bit | 51.1408 |  |
 |
 |
| 4bit | 23.0487 |  |
 |
 |
| 2bit | 9.91007 |  |
 |
 |
| 1bit | 9.73155 |  |
 |
 |
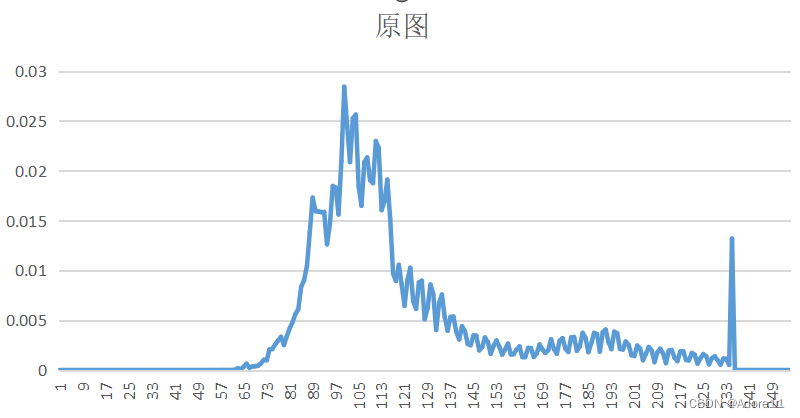
原图的概率分布计算:
#include<iostream>
#include<math.h>
using namespace std;
int main(int argc, char* argv[])
{
//初始化
int height = 768;
int width = 512;
int bit = 1;
FILE* yuvname = NULL;
FILE* out = NULL;
//定义缓冲区
unsigned char* y_buffer;
unsigned char* u_buffer;
unsigned char* v_buffer;
y_buffer = (unsigned char*)malloc(width * height);
u_buffer = (unsigned char*)malloc(width * height / 4);
v_buffer = (unsigned char*)malloc(width * height / 4);
//打开文件
fopen_s(&yuvname, argv[1], "rb");
fopen_s(&out, argv[4], "rb");
if (yuvname == NULL )
{
cout << "Open Error!" << endl;
return 0;
}
//读取文件
fread(y_buffer, 1, width * height, yuvname);
fread(u_buffer, 1, (width * height) / 4, yuvname);
fread(v_buffer, 1, (width * height) / 4, yuvname);
//计算概率分布
int size = height * width;
double count[256] = { 0 };
double pro_y[256] = { 0 };
double pro_e[256] = { 0 };
for (int i = 0; i < size; i++) {
int color = *(y_buffer + i);// (int_buf + i)点的灰度值
count[color]++;
}
for (int j = 0; j < 256; j++)//灰度概率
{
pro_y[j] = (double(count[j]) / size);//原图的概率分布
}
//写概率分布
for (int i = 0; i < 256; i++) {
fprintf(out, "%f\n", pro_y[i]);
}
free(y_buffer);
free(u_buffer);
free(v_buffer);
fclose(yuvname);
return 0;
} 
总结:
观察原图概率分布和预测误差图像概率分布,我们可以看出,原图的概率分布“范围”更广,取值相比于预测误差图像而言,分布更均匀,因此其熵也更大。
对于无失真编码而言,由于香农第一定理,信源符号平均码长的下界为信源熵,如果想达到最好的压缩效果,就希望平均码长最小;利用信源符号间的相关性,减小编码的信息冗余,将均匀分布的信源符号转换为非均匀分布,减少信源熵,提高压缩效率。
补充实验:
比较DPCM+熵编码和仅进行熵编码之间的编码效率(压缩比和图像质量)
---> 打开Huffmancode.bat,写入输入、输出,利用Huffman编码器进行熵编码,将熵编码后的结果保存在birds.txt和birds_DPCM.txt中(保存后点击.bat文件)
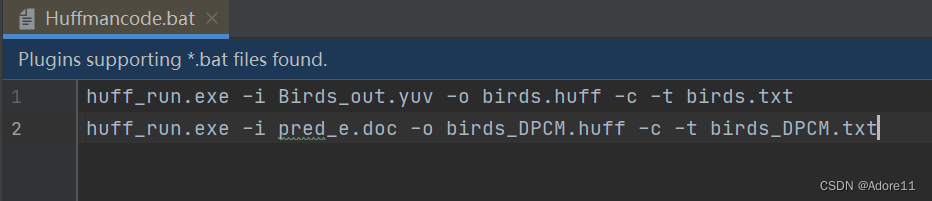
保存、运行Huffmancode.bat,得到结果

Birds_out.huff为仅进行熵编码的文件、birds_DPCM为进行DPCM+熵编码的文件,对这两个文件比较压缩比:
DPCM+8bit量化+熵编码-----压缩比: 576/340=2.1
仅进行熵编码---------压缩比:576/488=1.6
由此可见,经过熵编码后图像的压缩比更大,即系统的压缩效果更好。
Final总结:
通过本次实验我深刻理解了预测-熵编码的过程。预测尽可能利用信源符号的相关性,减小信息冗余,最大程度的减小信源符号熵。聪明的DPCM系统,通过只传误差,对误差进行编码等,提高了压缩效率。同时在编码器里引入解码器,保证编解码端同步,减少产生误差漂移。
智能推荐
JAVA毕业设计Web企业差旅在线管理系统计算机源码+lw文档+系统+调试部署+数据库_基于javaweb的差旅报销系统毕业设计-程序员宅基地
文章浏览阅读98次。JAVA毕业设计Web企业差旅在线管理系统计算机源码+lw文档+系统+调试部署+数据库。springcloud基于微服务架构的小区生活服务平台的设计与实现。jsp会议管理系统的设计与实现sqlserver。ssm+sqlserver精准扶贫项目管理系统。ssm+sqlserver音乐资源分享网站。ssm基于Web的精品课程网站的设计与实现。ssm基于JavaEE的网上图书分享系统。_基于javaweb的差旅报销系统毕业设计
ERROR: The executable **/python.exe is not functioning解决方案_error: the executable g:\workspace\pythonproject\v-程序员宅基地
文章浏览阅读2.4k次。我是从3.8.3更新到3.11.4,pycharm版本是2020.1.2,所以网上说的更改文件权限、检查路径是否有中文我统统都试过了,所以我狠心直接重装新版本的2022.3.3,一顿操作过后发现能成功创建project了也不报错。将python版本更新后,使用pycharm突然无法创建虚拟环境virtualenv失败,提示路径从C:\Users\Lenovo\AppData\Local\下的什么什么到创建的路径的下的什么什么 我这里已经解决了忘记截图保存。_error: the executable g:\workspace\pythonproject\venv\scripts\python.exe is
【计算机毕业设计】189电商平台-程序员宅基地
文章浏览阅读80次。如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统商品交易信息管理难度大,容错率低,管理人员处理数据费工费时,所以专门为解决这个难题开发了一个电商平台,可以解决许多问题。电商平台可以实现商家管理,商品订单管理,用户管理,商品管理,商品评价管理等功能。该系统采用了Mysql数据库,Java语言,Spring Boot框架等技术进行编程实现。电商平台可以提高商品交易信息管理问题的解决效率,优化商品交
js处理xml文件,成execl格式_js浏览器环境excel转xml-程序员宅基地
文章浏览阅读344次。nginx配置映射,js读取xml文件,整理成规整excel格式的字符传_js浏览器环境excel转xml
springboot整合jett实现模板excel数据导出_spring boot 导出模板数据-程序员宅基地
文章浏览阅读648次。jett是使用Excel电子表格模板快速创建Excel电子表格报告的工具。_spring boot 导出模板数据
vmstat命令详解-程序员宅基地
文章浏览阅读231次。基础命令学习目录首页原文链接:https://www.cnblogs.com/wensiyang0916/p/6514820.htmlvmstat 1 1表示每秒采集一次vmstat 2 1 2表示2秒采集一次,1表示只采集一次r 表示运行队列(就是说多少个进程真的分配到CPU) 我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值..._vmstat 1 2
随便推点
Ubuntu14.04 64位运行32位程序 ./qt-creator-linux-x86-opensource-2.6.1.bin 问题解决_error while loading shared libraries: libgobject-2-程序员宅基地
文章浏览阅读972次。./qt-creator-linux-x86-opensource-2.6.1.bin./qt-creator-linux-x86-opensource-2.6.1.bin:: error while loading shared libraries: libgobject-2.0.so.0: cannot open shared object file: No such file or ..._error while loading shared libraries: libgobject-2.0.so.0: cannot open share
基于GitLab+Docker+K8S的持续集成和交付_getlab ci kubectl kubeconfig-程序员宅基地
文章浏览阅读5.5k次。基于GitLab+Docker+K8S的持续集成和交付_getlab ci kubectl kubeconfig
EMQX5.0使用Mysql认证,和Navicat Mysql数据库连接_emqx连接mysql-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏33次。在阿里云的服务器内安装好EMQX后,接下来使EMQX和Mysql数据库连接。_emqx连接mysql
浏览器中支持硬件加速_video acceleration information-程序员宅基地
文章浏览阅读3.9k次。1 什么是硬件加速硬件加速是指,应用程序使用计算机硬件的能力,比软件实现的功能能够更有效地执行某些操作。在 Chrome/Chromium 浏览器中,硬件加速能够利用计算机的图形处理单元(GPU)来处理图形密集型任务,例如:播放视频、浏览地图、网页渲染、游戏或需要更快数学运算的任何内容。通过分离特定任务,您的 CPU 就有机会专注于处理其它事务,而 GPU 则专门负责处理图形密集型任务的进程。2 硬件加速包括哪些内容硬件加速通常包括3D图形加速和视频硬件解码加速两部分。3 支持硬件加速需要满_video acceleration information
Python安装Crypto库报错(from Crypto.Cipher import AES ModuleNotFoundError: No module named ‘Crypto‘)_from cryptodome.cipher import aes modulenotfounder-程序员宅基地
文章浏览阅读1.2k次。Python安装Crypto库报错_from cryptodome.cipher import aes modulenotfounderror: no module named 'cryp
【转载文章】 Set 命令详解 让你理解set命令_set i1-100指令的含义是将100的值赋给0-程序员宅基地
文章浏览阅读7.5k次,点赞3次,收藏15次。https://www.jb51.net/article/18973_all.htmset,E文翻译过来就是“设置”的意思,相当于数学里的“令”。如:set X=5,就是令X=5的意思。语法形式:SET [variable=[string]]SET /P variable=[promptString]SET /A expression一、SET [v..._set i1-100指令的含义是将100的值赋给0