LeNet-5、AlexNet、NIN、VGG(VGG16、VGG19)、GoogLeNet(Inception v1 v2 v3 v4)、Xception、ResNet、DenseNet_vgg16 vgg19 resnet50 以图搜图-程序员宅基地
技术标签: 人工智能
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
3.4 CNN架构
下面我们主要以一些常见的网络结构去解析,并介绍大部分的网络的特点。这里看一下卷积的发展历史图。

3.4.1 LeNet-5解析
首先我们从一个稍微早一些的卷积网络结构LeNet-5(这里稍微改了下名字),开始的目的是用来识别数字的。从前往后介绍完整的结构组成,并计算相关输入和输出。
3.3.1.1 网络结构

- 激活层默认不画网络图当中,这个网络结构当时使用的是sigmoid和Tanh函数,还没有出现Relu函数
- 将卷积、激活、池化视作一层,即使池化没有参数
3.4.1.2 参数形状总结
| shape | size | parameters | |
|---|---|---|---|
| Input | (32,32,3) | 3072 | 0 |
| Conv1(f=5,s=1) | (28,28,6) | 4704 | 450+6 |
| Pool1 | (14,14,6) | 1176 | 0 |
| Conv2(f=5,s=1) | (10,10,16) | 1600 | 2400+16 |
| Pool2 | (5,5,16) | 400 | 0 |
| FC3 | (120,1) | 120 | 48000+120 |
| FC4 | (84,1) | 84 | 10080+84 |
| Ouput:softmax | (10,1) | 10 | 840+10 |
- 中间的特征大小变化不宜过快
事实上,在过去很多年,许多机构或者学者都发布了各种各样的网络,其实去了解设计网络最好的办法就是去研究现有的网络结构或者论文。大多数网络设计出来是为了Image Net的比赛(解决ImageNet中的1000类图像分类或定位问题),后来大家在各个业务上进行使用。
3.4.2 AlexNet
2012年,Alex Krizhevsky、Ilya Sutskever在多伦多大学Geoff Hinton的实验室设计出了一个深层的卷积神经网络AlexNet,夺得了2012年ImageNet LSVRC的冠军,且准确率远超第二名(top5错误率为15.3%,第二名为26.2%),引起了很大的轰动。AlexNet可以说是具有历史意义的一个网络结构。

- 总参数量:60M=6000万,5层卷积+3层全连接
- 使用了非线性激活函数:ReLU
- 防止过拟合的方法:Dropout,数据扩充(Data augmentation)
- 批标准化层的使用
3.4.3 卷积网络结构的优化
3.4.3.1 常见结构特点
整个过程:AlexNet-->NIN-->(VGG—GoogLeNet)-->ResNet-->DenseNet
- NIN:引入1 * 1卷积
- VGG,斩获2014年分类第二(第一是GoogLeNet),定位任务第一。
- 参数量巨大,140M = 1.4亿
- 19layers
- VGG 版本
- VGG16
- VGG19

GoogleNet,2014年比赛冠军的model,这个model证明了一件事:用更多的卷积,更深的层次可以得到更好的结构。(当然,它并没有证明浅的层次不能达到这样的效果)
- 500万的参数量
- 22layers
- 引入了Inception模块
- Inception V1
- Inception V2
- Inception V3
- Inception V4

- 下面我们将针对卷积网络架构常用的一些结构进行详细分析,来探究这些结构带来的好处
3.4.4 VGG
-
特点:
- 1、VGG-16的结构非常整洁,深度较AlexNet深得多,里面包含多个conv->conv->max_pool这类的结构,VGG的卷积层都是same的卷积,即卷积过后的输出图像的尺寸与输入是一致的,它的下采样完全是由max pooling来实现。
- 2、VGG网络后接3个全连接层,filter的个数(卷积后的输出通道数)从64开始,然后没接一个pooling后其成倍的增加,128、512,VGG的注意贡献是使用小尺寸的filter,及有规则的卷积-池化操作。
-
闪光点:
-
卷积层使用更小的filter尺寸和间隔
-
与AlexNet相比,可以看出VGG-Nets的卷积核尺寸还是很小的,比如AlexNet第一层的卷积层用到的卷积核尺寸就是11*11,这是一个很大卷积核了。而反观VGG-Nets,用到的卷积核的尺寸无非都是1×1和3×3的小卷积核,可以替代大的filter尺寸。
-
3×3卷积核的优点:
- 多个3×3的卷积层比一个大尺寸filter卷基层有更多的非线性,使得判决函数更加具有判决性
- 多个3×3的卷积层比一个大尺寸的filter有更少的参数,假设卷基层的输入和输出的特征图大小相同为C,那么三个3×3的卷积层参数个数3×(3×3×C×C)=27CC;一个7×7的卷积层参数为49CC;所以可以把三个3×3的filter看成是一个7×7filter的分解(中间层有非线性的分解)
VGG-16的Keras实现(这里只做展示了解):
def VGG_16():
model = Sequential()
model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=(224,224,3),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,2),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
3.4.4 Inception 结构
首先我们要说一下在Network in Network中引入的1 x 1卷积结构的相关作用,下面我们来看1*1卷积核的优点:
3.4.4.1MLP卷积(1 x 1卷积)

- 目的:提出了一种新的深度网络结构,称为“网络中的网络”(NIN),增强接受域内局部贴片的模型判别能力。
- 做法
- 对于传统线性卷积核:采用线性滤波器,然后采用非线性激活。
- 提出MLP卷积取代传统线性卷积核
- 作用或优点:
- 1x1的卷积核操作可以实现卷积核通道数的降维和升维,实现参数的减小化
3.4.4.2 1 x 1卷积介绍

从图中,看到1 x 1卷积的过程,那么这里先假设只有3个1x1Filter,那么最终结果还是56x56x3。但是每一个FIlter的三个参数的作用
- 看作是对三个通道进行了线性组合。
我们甚至可以把这几个FIlter可以看成就是一个简单的神经元结构,每个神经元参数数量与前面的通道数量相等。
- 通常在卷积之后会加入非线性激活函数,在这里之后加入激活函数,就可以理解成一个简单的MLP网络了。
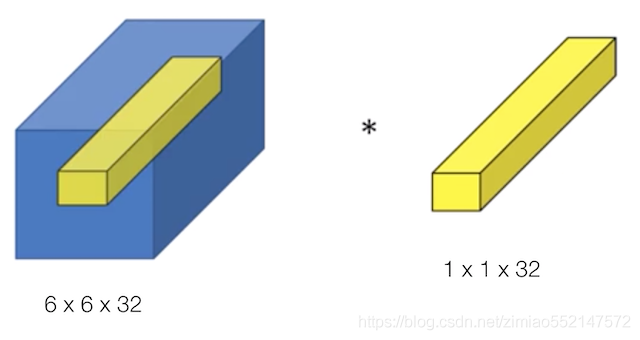
3.4.4.3 通道数变化
那么对于1x1网络对通道数的变化,其实并不是最重要的特点,因为毕竟3 x 3,5 x 5都可以带来通道数的变化,
而1x1卷积的参数并不多,我们拿下面的例子来看。
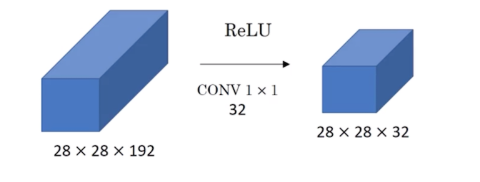
- 保持通道数不变
- 提升通道数
- 减少通道数
对于单通道输入,1×1的卷积确实不能起到降维作用,但对于多通道输入,就不不同了。假设你有256个特征输入,256个特征输出,同时假设Inception层只执行3×3的卷积。这意味着总共要进行 256×256×3×3的卷积(589000次乘积累加(MAC)运算)。这可能超出了我们的计算预算,比方说,在Google服务器上花0.5毫秒运行该层。作为替代,我们决定减少需要卷积的特征的数量,比如减少到64(256/4)个。在这种情况下,我们首先进行256到64的1×1卷积,然后在所有Inception的分支上进行64次卷积,接着再使用一个64到256的1×1卷积。
- 256×64×1×1 = 16000
- 64×64×3×3 = 36000
- 64×256×1×1 = 16000
现在的计算量大约是70000(即16000+36000+16000),相比之前的约600000,几乎减少了10倍。这就通过小卷积核实现了降维。
现在再考虑一个问题:为什么一定要用1×1卷积核,3×3不也可以吗?考虑[50,200,200]的矩阵输入,我们可以使用20个1×1的卷积核进行卷积,得到输出[20,200,200]。有人问,我用20个3×3的卷积核不是也能得到[20,200,200]的矩阵输出吗,为什么就使用1×1的卷积核?我们计算一下卷积参数就知道了,对于1×1的参数总数:20×200×200×(1×1),对于3×3的参数总数:20×200×200×(3×3),可以看出,使用1×1的参数总数仅为3×3的总数的九分之一!所以我们使用的是1×1卷积核。
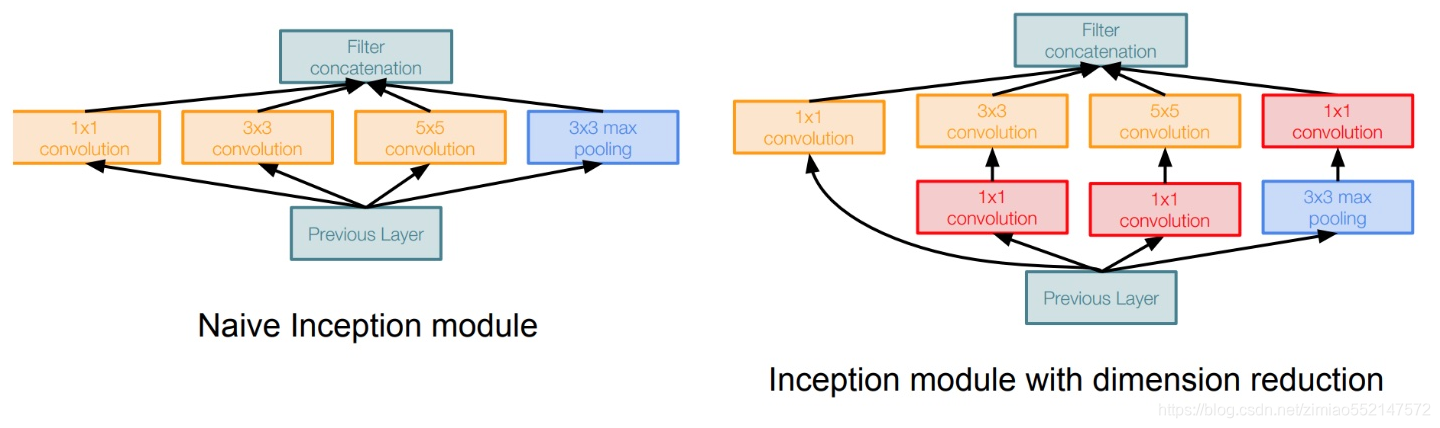
3.4.4.4 Inception层
这个结构其实还有名字叫盗梦空间结构。
-
目的:
- 代替人手工去确定到底使用1x1,3x3,5x5还是是否需要max_pooling层,由网络自动去寻找适合的结构。并且节省计算。

- 特点
- 是每一个卷积/池化最终结果的长、宽大小一致
- 特殊的池化层,需要增加padding,步长为1来使得输出大小一致,并且选择32的通道数
- 最终结果28 x 28 x 256
- 使用更少的参数,达到跟AlexNet或者VGG同样类似的输出结果
3.4.4.5 Inception v1-Pointwise Conv
Inception Module. 使用Inception Module的模块的GoogleNet不仅比Alex深,而且参数比AlexNet足足减少了12倍。
GoogleNet作者的初始想法是用多个不同类型的卷积核代替一个3x3的小卷积核(如左图),好处是可以使提取出来的特征具有多样化,并且特征之间的co-relationship不会很大,最后用把feature map都concatenate起来使网络做得很宽,然后堆叠Inception Module将网络变深。但仅仅简单这么做会使一层的计算量爆炸式增长,如下图,854M 操作:

计算量主要来自于输入前的feature map的维度256,和1x1卷积核的输出维度:192。那可否先使用1x1卷积核将输入图片的feature map维度先降低,进行信息压缩,在使用3x3卷积核进行特征提取运算?线图就只有358M操作

- 参数量对比例子:
- 直接使用
3x3的卷积核。256 维的输入直接经过一个3×3×256的卷积层,输出一个 256 维的 feature map ,那么参数量为:256×3×3×256 = 589,824 。 - 先经过
1x1的卷积核,再经过3x3卷积核,最后经过一个1x1卷积核。 256 维的输入先经过一个1×1×64的卷积层,再经过一个3x3x64的卷积层,最后经过1x1x256的卷积层,则总参数量为:256×1×1×64 + 64×3×3×64 + 64×1×1×256 = 69,632 。
- 直接使用
3.4.4.6 GoogleNet结构
其中包含了多个Inception结构。

- 特点:
- 1、Stem部分:论文指出Inception module要在网络中间使用的效果比较好,因此网络前半部分依旧使用传统的卷积层代替。
- 2、辅助函数(Axuiliary Function):从信息流动的角度看梯度消失,因为是梯度信息在BP过程中能量衰减,无法到达浅层区域,因此在中间开个口子,加个辅助损失函数直接为浅层。
- 3、Classifier部分:从VGGNet以及NIN的论文中可知,fc层具有大量层数,因此用average pooling替代fc,减少参数数量防止过拟合。在softmax前的fc之间加入dropout,p=0.7,进一步防止过拟合。
- 后面的全连接层全部替换为简单的全局平均pooling
完整结构:

- 重点2、GoogLeNet网络结构中有3个LOSS单元,这样的网络设计是为了帮助网络的收敛。在中间层加入辅助计算的LOSS单元,目的是计算损失时让低层的特征也有很好的区分能力,从而让网络更好地被训练。在论文中,这两个辅助LOSS单元的计算被乘以0.3,然后和最后的LOSS相加作为最终的损失函数来训练网络。
- 重点3、将后面的全连接层全部替换为简单的全局平均pooling,在最后参数会变的更少。而在AlexNet中最后3层的全连接层参数差不多占总参数的90%,使用大网络在宽度和深度允许GoogleNet移除全连接层,但并不会影响到结果的精度,在ImageNet中实现93.3%的精度,而且要比VGG还要快。
keras代码实现:
def Conv2d_BN(x, nb_filter,kernel_size, padding='same',strides=(1,1),name=None):
if name is not None:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter,kernel_size,padding=padding,strides=strides,activation='relu',name=conv_name)(x)
x = BatchNormalization(axis=3,name=bn_name)(x)
return x
def Inception(x,nb_filter):
branch1x1 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch3x3 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch3x3 = Conv2d_BN(branch3x3,nb_filter,(3,3), padding='same',strides=(1,1),name=None)
branch5x5 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch5x5 = Conv2d_BN(branch5x5,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branchpool = MaxPooling2D(pool_size=(3,3),strides=(1,1),padding='same')(x)
branchpool = Conv2d_BN(branchpool,nb_filter,(1,1),padding='same',strides=(1,1),name=None)
x = concatenate([branch1x1,branch3x3,branch5x5,branchpool],axis=3)
return x
def GoogLeNet():
inpt = Input(shape=(224,224,3))
#padding = 'same',填充为(步长-1)/2,还可以用ZeroPadding2D((3,3))
x = Conv2d_BN(inpt,64,(7,7),strides=(2,2),padding='same')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Conv2d_BN(x,192,(3,3),strides=(1,1),padding='same')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,64)#256
x = Inception(x,120)#480
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,128)#512
x = Inception(x,128)
x = Inception(x,128)
x = Inception(x,132)#528
x = Inception(x,208)#832
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,208)
x = Inception(x,256)#1024
x = AveragePooling2D(pool_size=(7,7),strides=(7,7),padding='same')(x)
x = Dropout(0.4)(x)
x = Dense(1000,activation='relu')(x)
x = Dense(1000,activation='softmax')(x)
model = Model(inpt,x,name='inception')
return model
3.4.4.7 Inception v2
Inception v2的论文,提出”Batch Normalization”思想:消除因conv而产生internal covariant shift, 保持数据在训练过程中的统计特性的一致性。Inception v2的结构是在卷积层与激活函数之间插入BN层:conv-bn-relu
3.4.4.8 Inception v3
-
问题:就算有了Pointwise Conv,由于 5x5 和 7x7 卷积核直接计算参数量还是非常大,训练时间还是比较长,我们还要再优化。
-
特点:Inception v3使用factorization的方法进一步对inception v2的参数数量进行优化和降低.
- Factorization:
- 1、Factorization convolutions into smaller convolution.用小的卷积核替代大的卷积核,并使用1x1卷积核预处理进行空间降维。
- Factorization:

2、Spatial Factorization into Asymmetric(不对称) Convolution:使用receptive field等效的原理,进一步将nxn的卷积核裂化成1xn和nx1的卷积核串联形式或者并联形式,进一步减少计算量。

- 提出了通用的网络设计原则
- 1、在网络的浅层部分要尽量避免representation bottlenecks(瓶颈),即: information representation(在神经网络中指的是feature map和fc层的vector)不能在某一层内进行极端压缩,否则会造成信息丢失严重的现象。最好的降维办法是将信息缓慢降维,最终达到所需要的维度。
- 2、空间信息融合可以在低维流形上进行而没有较多的信息损失
- 3x3卷积前先用1x1卷积进行降维,inception v1使用的方法。
3.4.4.9 Inception v4
Inception v4是将Inception module和residual module结合起来。引入了ResNet,使训练加速,性能提升。(后面会介绍ResNet)
3.4.4.9 Xception - Depthwise Separable Conv(深度可分离卷积)
Xception的目标是设计出易迁移、计算量小、能适应不同任务,且精度较高的模型。那么Xception与Inception-v3在结构上有什么差别呢?
- 1、InceptionV3:依据化繁为简的思想,把模块结构改造

2、依据depthwise separable convolution的思想,可以进一步把上图改造成下图.将每个channel上的空间关联分别使用一个相应的conv 3x3来单独处理呢。如此就得到了Separable conv。

什么是depthwise separable convolution(深度可分离卷积)呢?
-
1、对于112×112×64的输入做一次普通的3×3卷积,每个卷积核大小为3×3×64,也就是说,每一小步的卷积操作是同时在面上(3×3的面)和深度上(×64的深度)进行的
- 1、那如果把面上和深度上的卷积分离开来呢?这就是图3所要表达的操作。依旧以112×112×64的输入来作例子,先进入1×1卷积,每个卷积核大小为1×1×64,有没有发现,这样每一小步卷积其实相当于只在深度上(×64的深度)进行。
- 2、然后,假设1×1卷积的输出为112×112×7,我们把它分为7份,即每份是112×112×1,每份后面单独接一个3×3的卷积(如图3所示,画了7个3×3的框),此时每个卷积核为3×3×1,有没有发现,这样每一小步卷积其实相当于只在面上(3×3的面)进行。
Xception结构的表示
它就是由Inception v3直接演变而来,并且引入了Residual learning的结构

- 每个flow内部使用不同的重复模块,当然最最核心的属于中间不断分析、过滤特征的Middel flow。Entry flow主要是用来不断下采样,减小空间维度;中间则是不断学习关联关系,
总结:最后,把这7个3×3的卷积的输出叠在一起就可以了。根据Xception论文的实验结果,Xception在精度上略低于Inception-v3,但在计算量和迁移性上都好于Inception-v3。
3.4.4.11 Inception Module 总结
- inception v1被提出来;之后通过conv layer与conv layer之间的特性研究,提出BN的方法,形成Inception v2
- Inception v3中,使用factorization方法,进一步减少参数总量降低网络的冗余度,从而提高网络性能。
- inception v4:将Inception v3和residual module结合起来。
- Xception:将1x1卷积极致发挥,分离cross-channel correlation和spatial correlation
ResNet结构并分析其在计算机视觉方面取得成功的原因
Resnet通过引入残差单元来解决退化问题。
结构:
(1)通过增加 恒等快捷连接(identity shortcut connection)实现,直接跳过一个或多个层。优势是残差映射在实际中往往更容易优化。
(2)Resnet网络中短路连接shortcut的方式考虑到x的维度与F(X)维度可能不匹配情况,需进行维度匹配。通常采用两种方法解决这一问题:
zero_padding:对恒等层进行0填充的方式将维度补充完整。这种方法不会增加额外的参数
projection:在恒等层采用1x1的卷积核来增加维度。这种方法会增加额外的参数
(3)bottleneck 实现方式
使用1x1的卷积层来降维,最后一层使用1x1的卷积层来进行升维
(4)激活函数移动到残差部分可以提高模型的精度
3.4.5 ResNet-里程碑式创新
2015年何恺明推出的ResNet在ISLVRC和COCO上横扫所有选手,获得冠军。ResNet在网络结构上做了大创新,而不再是简单的堆积层数,ResNet在卷积神经网络的新思路,绝对是深度学习发展历程上里程碑式的事件。
- 问题:网络的深度提升不能通过层与层的简单堆叠来实现。由于梯度消失问题,深层网络很难训练。因为梯度反向传播到前面的层,重复相乘可能使梯度无穷小。结果就是,随着网络的层数更深,其性能趋于饱和,甚至开始迅速下降。

- 特点:
- 层数非常深,已经超过百层
- 引入残差单元来解决退化问题
引入:
对神经网络模型添加新的层,充分训练后的模型是否只可能更有效地降低训练误差?理论上,原模型解的空间只是新模型解的空间的子空间。新模型和原模型将同样有效。由于新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。然而在实践中,添加过多的层后训练误差往往不降反升。
3.4.5.1 残差网络-Residual network
-
通过增加 恒等快捷连接(identity shortcut connection)实现,直接跳过一个或多个层。
- 可以保证网络的深度在加深,但因为没有学习新的参数,网络不会发生退化的现象。
-
1、理解:假设我们希望学出的理想映射为f(x),从而作为图5.9上方激活函数的输入。左图虚线框中的部分需要直接拟合出该映射f(x),而右图虚线框中的部分则需要拟合出有关恒等映射的残差映射f(x)−x
- 1、残差映射在实际中往往更容易优化
- 2、实验中,当理想映射f(x)极接近于恒等映射时,残差映射也易于捕捉恒等映射的细微波动
- 右图也是ResNet的基础块,即残差块(residual block)。在残差块中,输入可通过跨层的数据线路更快地向前传播。

- 2、学习过程:我们只需将图中右图虚线框内上方的加权运算(最上方激活函数下的加权运算符号+)的权重和偏差参数学成0,那么f(x)即为恒等映射。
- 实际上残差不会为0, 这会使得堆积层在输入特征的基础上学习到新的特征,从而获得更好的性能。
- 3、原理:将原来需要学习的函数f(x)转换成f(x) - x文章认为,相比较于f(x)−x的优化要简单,二者的优化难度并不相同,这一想法源自图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度之间的残差问题,可以更好的获得优化效果。
1、原理数学公式解释
我们以该图来解释:




2、短路连接shortcut的方式
考虑到x的维度与F(X)维度可能不匹配情况,需进行维度匹配。这里论文中采用两种方法解决这一问题(其实是三种,但通过实验发现第三种方法会使performance急剧下降,故不采用):
- zero_padding:对恒等层进行0填充的方式将维度补充完整。这种方法不会增加额外的参数
- projection:在恒等层采用1x1的卷积核来增加维度。这种方法会增加额外的参数
3、bottleneck 实现方式

当研究50层以上的深层网络时,使用了上图所示的Bottleneck网络结构。该结构第一层使用1x1的卷积层来降维,最后一层使用1x1的卷积层来进行升维,从而保持与原来输入同维以便于恒等映射。
4、激活函数的位置
几种情况图示
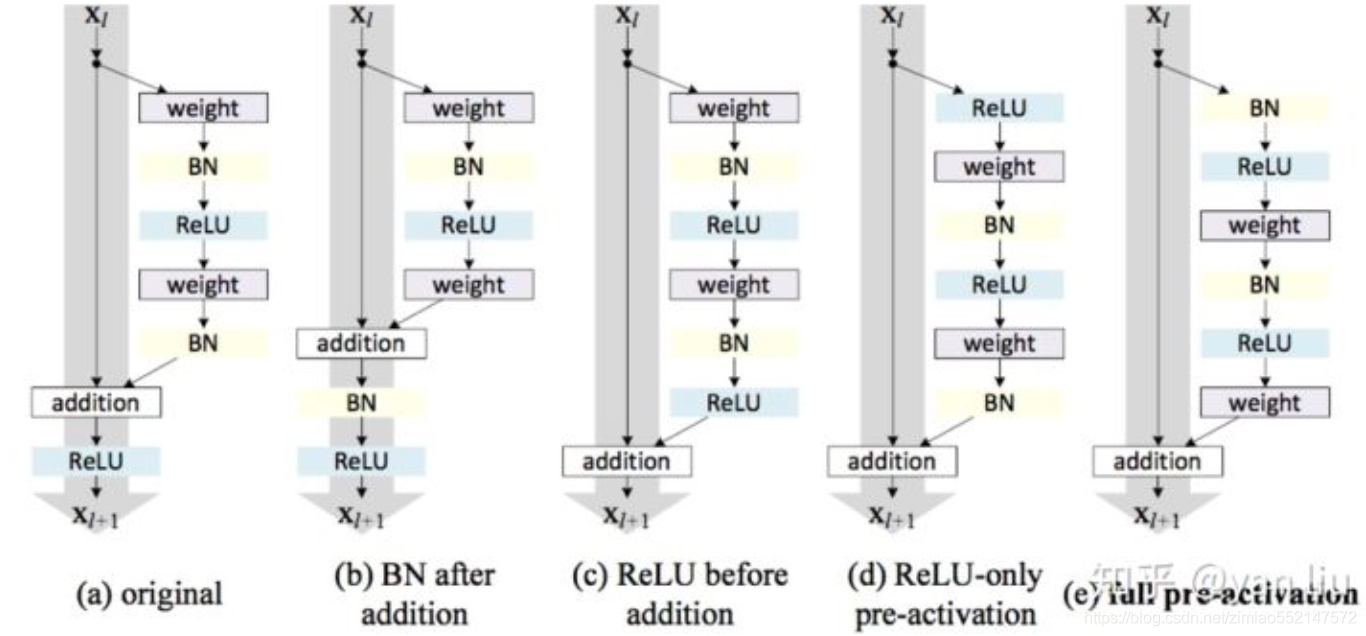

3.4.5.4 实验
-
构建了一个18层和34层的plain网络作为对比,所有层都只作简单的叠加,之后又构建了一个18层和34层的residual网络,在plain网络上加入shortcut,两个网络的参数量和计算量相同
在plain上观测到明显的退化现象,而在ResNet上没有出现退化现象,34层的网络反而比18层的更好,同时ResNet的收敛速度比plain要快。

3.4.5.3 完整结构
ResNet比起VGG19这样的网络深很多,但是运算量是少于VGG19等的。

3.4.5.4 代码实现
def Conv2D_BN(x, filters, kernel_size, strides=(1, 1), padding='same', name=None):
if name:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(filters, kernel_size, strides=strides, padding=padding, activation='relu', name=conv_name)(x)
x = BatchNormalization(name=bn_name)(x)
return x
def identity_block(input_tensor, filters, kernel_size, strides=(1, 1), is_conv_shortcuts=False):
"""
:param input_tensor:
:param filters:
:param kernel_size:
:param strides:
:param is_conv_shortcuts: 直接连接或者投影连接
:return:
"""
x = Conv2D_BN(input_tensor, filters, kernel_size, strides=strides, padding='same')
x = Conv2D_BN(x, filters, kernel_size, padding='same')
if is_conv_shortcuts:
shortcut = Conv2D_BN(input_tensor, filters, kernel_size, strides=strides, padding='same')
x = add([x, shortcut])
else:
x = add([x, input_tensor])
return x
def bottleneck_block(input_tensor, filters=(64, 64, 256), strides=(1, 1), is_conv_shortcuts=False):
"""
:param input_tensor:
:param filters:
:param strides:
:param is_conv_shortcuts: 直接连接或者投影连接
:return:
"""
filters_1, filters_2, filters_3 = filters
x = Conv2D_BN(input_tensor, filters=filters_1, kernel_size=(1, 1), strides=strides, padding='same')
x = Conv2D_BN(x, filters=filters_2, kernel_size=(3, 3))
x = Conv2D_BN(x, filters=filters_3, kernel_size=(1, 1))
if is_conv_shortcuts:
short_cut = Conv2D_BN(input_tensor, filters=filters_3, kernel_size=(1, 1), strides=strides)
x = add([x, short_cut])
else:
x = add([x, input_tensor])
return x
def ResNet34(input_shape=(224, 224, 3), n_classes=1000):
"""
:param input_shape:
:param n_classes:
:return:
"""
input_layer = Input(shape=input_shape)
x = ZeroPadding2D((3, 3))(input_layer)
# block1
x = Conv2D_BN(x, filters=64, kernel_size=(7, 7), strides=(2, 2), padding='valid')
x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(x)
# block2
x = identity_block(x, filters=64, kernel_size=(3, 3))
x = identity_block(x, filters=64, kernel_size=(3, 3))
x = identity_block(x, filters=64, kernel_size=(3, 3))
# block3
x = identity_block(x, filters=128, kernel_size=(3, 3), strides=(2, 2), is_conv_shortcuts=True)
x = identity_block(x, filters=128, kernel_size=(3, 3))
x = identity_block(x, filters=128, kernel_size=(3, 3))
x = identity_block(x, filters=128, kernel_size=(3, 3))
# block4
x = identity_block(x, filters=256, kernel_size=(3, 3), strides=(2, 2), is_conv_shortcuts=True)
x = identity_block(x, filters=256, kernel_size=(3, 3))
x = identity_block(x, filters=256, kernel_size=(3, 3))
x = identity_block(x, filters=256, kernel_size=(3, 3))
x = identity_block(x, filters=256, kernel_size=(3, 3))
x = identity_block(x, filters=256, kernel_size=(3, 3))
# block5
x = identity_block(x, filters=512, kernel_size=(3, 3), strides=(2, 2), is_conv_shortcuts=True)
x = identity_block(x, filters=512, kernel_size=(3, 3))
x = identity_block(x, filters=512, kernel_size=(3, 3))
x = AveragePooling2D(pool_size=(7, 7))(x)
x = Flatten()(x)
x = Dense(n_classes, activation='softmax')(x)
model = Model(inputs=input_layer, outputs=x)
return model
def ResNet50(input_shape=(224, 224, 3), n_classes=1000):
"""
:param input_shape:
:param n_classes:
:return:
"""
input_layer = Input(shape=input_shape)
x = ZeroPadding2D((3, 3))(input_layer)
# block1
x = Conv2D_BN(x, filters=64, kernel_size=(7, 7), strides=(2, 2), padding='valid')
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
# block2
x = bottleneck_block(x, filters=(64, 64, 256), strides=(1, 1), is_conv_shortcuts=True)
x = bottleneck_block(x, filters=(64, 64, 256))
x = bottleneck_block(x, filters=(64, 64, 256))
# block3
x = bottleneck_block(x, filters=(128, 128, 512), strides=(2, 2), is_conv_shortcuts=True)
x = bottleneck_block(x, filters=(128, 128, 512))
x = bottleneck_block(x, filters=(128, 128, 512))
x = bottleneck_block(x, filters=(128, 128, 512))
# block4
x = bottleneck_block(x, filters=(256, 256, 1024), strides=(2, 2), is_conv_shortcuts=True)
x = bottleneck_block(x, filters=(256, 256, 1024))
x = bottleneck_block(x, filters=(256, 256, 1024))
x = bottleneck_block(x, filters=(256, 256, 1024))
x = bottleneck_block(x, filters=(256, 256, 1024))
x = bottleneck_block(x, filters=(256, 256, 1024))
# block5
x = bottleneck_block(x, filters=(512, 512, 2048), strides=(2, 2), is_conv_shortcuts=True)
x = bottleneck_block(x, filters=(512, 512, 2048))
x = bottleneck_block(x, filters=(512, 512, 2048))
x = AveragePooling2D(pool_size=(7, 7))(x)
x = Flatten()(x)
x = Dense(n_classes, activation='softmax')(x)
model = Model(inputs=input_layer, outputs=x)
return model
3.4.6 DenseNet-密集连接卷积网络
DenseNet是在ResNet之后的一个分类网络,连接方式的改变,使其在各大数据集上取得比ResNet更好的效果.。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。
3.4.6.1 设计理念
我们常用的有 GoogleNet、VGGNet、ResNet 模型,但随着网络层数的加深,网络在训练过程中的前传信号和梯度信号在经过很多层之后可能会逐渐消失。
- 作者基于这个核心理念设计了一种全新的连接模式。为了最大化网络中所有层之间的信息流,作者将网络中的所有层两两都进行了连接,使得网络中每一层都接受它前面所有层的特征作为输入。


3.4.6.2 网络结构
DenseNet的网络结构主要由DenseBlock和Transition组成


3.4.6.3 DenseNet优点
-
DenseNet的优势主要体现在以下几个方面:
-
由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的“deep supervision”;
- 参数更小且计算更高效,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
- 由于特征复用,最后的分类器使用了低级特征。
-
3.4.6.4 对比
在ImageNet数据集上ResNet vs DenseNet

3.4.7 卷积神经网络学习特征可视化
我们肯定会有疑问真个深度的卷积网络到底在学习什么?可以将网络学习过程中产生的特征图可视化出来,并且对比原图来看看每一层都干了什么。



- layer1,layer2学习到的特征基本是颜色、边缘等低层特征
- layer3学习到的特征,一些纹理特征,如网格纹理
- layer4学习到的特征会稍微复杂些,比如狗的头部形状
- layer5学习到的是完整一些的,比如关键性的区分特征
3.4.8 总结
- 掌握LeNet-5 结构计算
- 了解卷积常见网络结构
- 掌握1x1卷积结构作用
- 掌握Inception结构作用
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象