k8s-高可用部署-calico插件_calico-3.9.2.yaml-程序员宅基地
技术标签: kubernetes # Kubernetes
kubernetes高可用部署参考:
Creating Highly Available Clusters with kubeadm | Kubernetes
GitHub - kubernetes-sigs/kubespray: Deploy a Production Ready Kubernetes Cluster
GitHub - wise2c-devops/breeze: Deploy a Production Ready Kubernetes Cluster with graphical interface
GitHub - cookeem/kubeadm-ha: Kubernetes high availiability deploy based on kubeadm, loadbalancer included (English/中文 for v1.15 - v1.20+)
一、拓扑选择
配置高可用(HA)Kubernetes集群,有以下两种可选的etcd拓扑:
- 集群master节点与etcd节点共存,etcd也运行在控制平面节点上
- 使用外部etcd节点,etcd节点与master在不同节点上运行
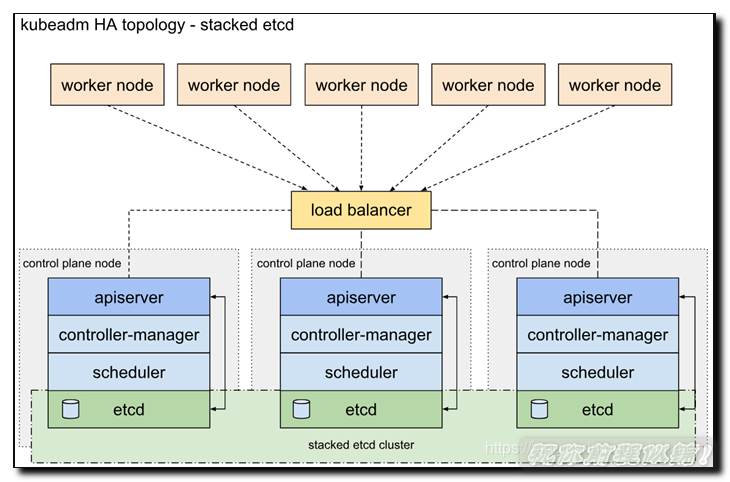
1.1 堆叠的etcd拓扑
堆叠HA集群是这样的拓扑,其中etcd提供的分布式数据存储集群与由kubeamd管理的运行master组件的集群节点堆叠部署。
每个master节点运行kube-apiserver,kube-scheduler和kube-controller-manager的一个实例。kube-apiserver使用负载平衡器暴露给工作节点。
每个master节点创建一个本地etcd成员,该etcd成员仅与本节点kube-apiserver通信。这同样适用于本地kube-controller-manager 和kube-scheduler实例。
该拓扑将master和etcd成员耦合在相同节点上。比设置具有外部etcd节点的集群更简单,并且更易于管理复制。
但是,堆叠集群存在耦合失败的风险。如果一个节点发生故障,则etcd成员和master实例都将丢失,并且冗余会受到影响。您可以通过添加更多master节点来降低此风险。
因此,您应该为HA群集运行至少三个堆叠的master节点。
这是kubeadm中的默认拓扑。使用kubeadm init和kubeadm join –experimental-control-plane命令时,在master节点上自动创建本地etcd成员。
1.2 外部etcd拓扑
具有外部etcd的HA集群是这样的拓扑,其中由etcd提供的分布式数据存储集群部署在运行master组件的节点形成的集群外部。
像堆叠ETCD拓扑结构,在外部ETCD拓扑中的每个master节点运行一个kube-apiserver,kube-scheduler和kube-controller-manager实例。并且kube-apiserver使用负载平衡器暴露给工作节点。但是,etcd成员在不同的主机上运行,每个etcd主机与kube-apiserver每个master节点进行通信。
此拓扑将master节点和etcd成员分离。因此,它提供了HA设置,其中丢失master实例或etcd成员具有较小的影响并且不像堆叠的HA拓扑那样影响集群冗余。
但是,此拓扑需要两倍于堆叠HA拓扑的主机数。具有此拓扑的HA群集至少需要三个用于master节点的主机和三个用于etcd节点的主机。

二、部署要求
使用kubeadm部署高可用性Kubernetes集群的两种不同方法:
- 使用堆叠master节点。这种方法需要较少的基础设施,etcd成员和master节点位于同一位置。
- 使用外部etcd集群。这种方法需要更多的基础设施, master节点和etcd成员是分开的。
2.1 部署要求
- 至少3个master节点
- 至少3个worker节点
- 所有节点网络全部互通(公共或私有网络)
- 所有机器都有sudo权限
- 从一个设备到系统中所有节点的SSH访问
- 所有节点安装kubeadm和kubelet,kubectl是可选的。
- 针对外部etcd集群,你需要为etcd成员额外提供3个节点
三、基本配置
3.1 节点信息:
| 主机名 | IP地址 | 角色 | CPU/MEM | 磁盘 |
|---|---|---|---|---|
| k8s-master01 | 192.168.100.235 | master | 4C8G | 100G |
| k8s-master02 | 192.168.100.236 | master | 4C8G | 100G |
| k8s-master03 | 192.168.100.237 | master | 4C8G | 100G |
| k8s-node01 | 192.168.100.238 | node | 4C8G | 100G |
| K8S VIP | 192.168.100.201 | – | – | - |
3.2 初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#配置主机名 $ hostnamectl set-hostname k8s-master01 $ hostnamectl set-hostname k8s-master02 $ hostnamectl set-hostname k8s-master03 $ hostnamectl set-hostname k8s-node01 #修改/etc/hosts $ cat >> /etc/hosts << EOF 192.168.100.235 k8s-master01 192.168.100.236 k8s-master02 192.168.100.237 k8s-master03 192.168.100.238 k8s-node01 192.168.100.201 k8s-slb EOF # 开启firewalld防火墙并允许所有流量 $ systemctl stop firewalld && systemctl disable firewalld # 关闭selinux $ sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config && setenforce 0 #关闭swap $ swapoff -a $ yes | cp /etc/fstab /etc/fstab_bak $ cat /etc/fstab_bak | grep -v swap > /etc/fstab |
3.3 配置时间同步
为了简单起见,就使用ntp进行时间同步了!
1 2 3 4 |
# 时间同步 $ yum install ntpdate -y $ ntpdate ntp.aliyun.com $ timedatectl set-timezone Asia/Shanghai |
3.4 内核升级
升级完成后,内核版本:
1 2 |
$ uname -r 4.4.248-1.el7.elrepo.x86_64 |
3.5 加载IPVS模块
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 在所有的Kubernetes节点执行以下脚本(若内核大于4.19替换nf_conntrack_ipv4为nf_conntrack): $ cat > /etc/sysconfig/modules/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack EOF #执行脚本 $ chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4 #安装相关管理工具 $ yum install ipset ipvsadm -y |
3.6 配置内核参数
1 2 3 4 5 6 7 8 |
$ cat > /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_nonlocal_bind = 1 net.ipv4.ip_forward = 1 vm.swappiness=0 EOF $ sysctl --system |
四、负载均衡
部署集群前首选需要为kube-apiserver创建负载均衡器。
注意:负载平衡器有许多中配置方式。可以根据你的集群要求选择不同的配置方案。在云环境中,您应将master节点作为负载平衡器TCP转发的后端。此负载平衡器将流量分配到其目标列表中的所有健康master节点。apiserver的运行状况检查是对kube-apiserver侦听的端口的TCP检查(默认值:6443)。
负载均衡器必须能够与apiserver端口上的所有master节点通信。它还必须允许其侦听端口上的传入流量。另外确保负载均衡器的地址始终与kubeadm的ControlPlaneEndpoint地址匹配。
haproxy/nignx+keepalived是其中可选的负载均衡方案,针对公有云环境可以直接使用运营商提供的负载均衡产品。
部署时首先将第一个master节点添加到负载均衡器并使用以下命令测试连接:
1 |
$ nc -v LOAD_BALANCER_IP PORT |
由于apiserver尚未运行,因此预计会出现连接拒绝错误。但是,超时意味着负载均衡器无法与master节点通信。如果发生超时,请重新配置负载平衡器以与master节点通信。将剩余的master节点添加到负载平衡器目标组。
4.1 安装负载均衡相关软件
1 |
$ yum install haproxy keepalived -y |
4.2 配置haproxy
所有master节点的配置相同,如下:
注意:把apiserver地址改成自己节点规划的master地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
$ vim /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server k8s-master01 192.168.100.235:6443 check
server k8s-master02 192.168.100.236:6443 check
server k8s-master03 192.168.100.237:6443 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:9999
stats auth admin:P@ssW0rd
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /admin?stats
|
4.3 配置keepalived
k8s-master01
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
$ cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
# 定义脚本
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.100.201
}
}
EOF
|
k8s-master02
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
$ cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
# 定义脚本
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.100.201
}
}
EOF
|
k8s-master03
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
$ cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
# 定义脚本
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.100.201
}
}
EOF
|
4.4 编写健康监测脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
$ vim /etc/keepalived/check-apiserver.sh
#!/bin/bash
function check_apiserver(){
for ((i=0;i<5;i++))
do
apiserver_job_id=${pgrep kube-apiserver}
if [[ ! -z ${apiserver_job_id} ]];then
return
else
sleep 2
fi
apiserver_job_id=0
done
}
# 1->running 0->stopped
check_apiserver
if [[ $apiserver_job_id -eq 0 ]];then
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
$ chmod 755 /etc/keepalived/check-apiserver.sh
|
4.5 启动haproxy和keepalived
1 2 |
$ systemctl enable --now keepalived $ systemctl enable --now haproxy |
五、安装docker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 安装依赖软件包
$ yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加Docker repository,这里改为国内阿里云yum源
$ yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce
$ yum clean all && yum makecache && yum install -y docker-ce
## 创建 /etc/docker 目录
$ mkdir /etc/docker
# 配置镜像加速
$ echo "{\"registry-mirrors\": [\"https://registry.cn-hangzhou.aliyuncs.com\"]}" >> /etc/docker/daemon.json
# 重启docker服务
$ systemctl daemon-reload && systemctl restart docker && systemctl enable docker
|
六、安装kubeadm
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#由于官方源国内无法访问,这里使用阿里云yum源进行替换: $ cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF $ yum install -y kubelet-1.18.2 kubeadm-1.18.2 kubectl-1.18.2 --disableexcludes=kubernetes $ systemctl enable kubelet && systemctl start kubelet |
七、部署k8s master、node节点
初始化参考:
kubeadm init | Kubernetes
v1beta1 package - k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta1 - pkg.go.dev
7.1 创建初始化配置文件
可以使用如下命令生成初始化配置文件:
1 |
$ kubeadm config print init-defaults > kubeadm-config.yaml |
根据实际部署环境修改信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
apiVersion: kubeadm.k8s.io/v1beta1
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.100.235
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta1
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "k8s-slb:16443"
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.14.1
networking:
dnsDomain: cluster.local
podSubnet: "10.244.0.0/16"
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
|
配置说明:
- controlPlaneEndpoint:为vip地址和haproxy监听端口16443
- imageRepository:由于国内无法访问google镜像仓库k8s.gcr.io,这里指定为阿里云镜像仓库registry.aliyuncs.com/google_containers
- podSubnet:指定的IP地址段与后续部署的网络插件相匹配,这里需要部署flannel插件,所以配置为10.244.0.0/16
- mode: ipvs:最后追加的配置为开启ipvs模式。
在集群搭建完成后可以使用如下命令查看生效的配置文件:
1 |
$ kubectl -n kube-system get cm kubeadm-config -oyaml |
7.2 初始化master01节点
这里追加tee命令将初始化日志输出到kubeadm-init.log中以备用(可选)。
k8s v1.16 之前
1 |
$ kubeadm init --config=kubeadm-config.yaml --experimental-upload-certs | tee kubeadm-init.log |
k8s v1.16 之后
1 |
$ kubeadm init --config=kubeadm-config.yaml --upload-certs | tee kubeadm-init.log |
该命令指定了初始化时需要使用的配置文件,其中添加–experimental-upload-certs或--upload-certs参数可以在后续执行加入节点时自动分发证书文件。
kubeadm init主要执行了以下操作:
- [init]:指定版本进行初始化操作
- [preflight] :初始化前的检查和下载所需要的Docker镜像文件
- [kubelet-start]:生成kubelet的配置文件”/var/lib/kubelet/config.yaml”,没有这个文件kubelet无法启动,所以初始化之前的kubelet实际上启动失败。
- [certificates]:生成Kubernetes使用的证书,存放在/etc/kubernetes/pki目录中。
- [kubeconfig] :生成 KubeConfig 文件,存放在/etc/kubernetes目录中,组件之间通信需要使用对应文件。
- [control-plane]:使用/etc/kubernetes/manifest目录下的YAML文件,安装 Master 组件。
- [etcd]:使用/etc/kubernetes/manifest/etcd.yaml安装Etcd服务。
- [wait-control-plane]:等待control-plan部署的Master组件启动。
- [apiclient]:检查Master组件服务状态。
- [uploadconfig]:更新配置
- [kubelet]:使用configMap配置kubelet。
- [patchnode]:更新CNI信息到Node上,通过注释的方式记录。
- [mark-control-plane]:为当前节点打标签,打了角色Master,和不可调度标签,这样默认就不会使用Master节点来运行Pod。
- [bootstrap-token]:生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
- [addons]:安装附加组件CoreDNS和kube-proxy
说明:无论是初始化失败或者集群已经完全搭建成功,你都可以直接执行kubeadm reset命令清理集群或节点,然后重新执行kubeadm init或kubeadm join相关操作即可。
7.3 配置kubectl
1 2 3 4 5 6 7 |
$ mkdir -p $HOME/.kube $ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config $ sudo chown $(id -u):$(id -g) $HOME/.kube/config $ yum -y install bash-completion $ source /usr/share/bash-completion/bash_completion $ source <(kubectl completion bash) $ echo "source <(kubectl completion bash)" >> ~/.bashrc |
7.4 查看当前状态
1 2 3 4 5 |
$ kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
|
7.5 安装网络插件
kubernetes支持多种网络方案,这里简单介绍常用的flannel和calico安装方法,选择其中一种方案进行部署即可。
以下操作在master01节点执行即可。
安装flannel网络插件:
由于kube-flannel.yml文件指定的镜像从coreos镜像仓库拉取,可能拉取失败,可以从dockerhub搜索相关镜像进行替换,另外可以看到yml文件中定义的网段地址段为10.244.0.0/16。
1 2 3 4 5 |
$ wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml $ cat kube-flannel.yml | grep image $ cat kube-flannel.yml | grep 10.244 $ sed -i 's#quay.io/coreos/flannel:v0.11.0-amd64#willdockerhub/flannel:v0.11.0-amd64#g' kube-flannel.yml $ kubectl apply -f kube-flannel.yml |
安装calico网络插件(可选):
安装参考:Kubernetes
1 2 3 |
$ wget https://kuboard.cn/install-script/calico/calico-3.9.2.yaml $ cat calico-3.9.2.yaml | grep 10.244 $ kubectl apply -f calico-3.9.2.yaml |
注意该yaml文件中默认CIDR为192.168.0.0/16,需要与初始化时kube-config.yaml中的配置一致,如果不同请下载该yaml修改后运行。
7.6 添加master节点
从初始化输出或kubeadm-init.log中获取命令:
1 2 3 |
$ kubeadm join k8s-slb:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:36c5f93203130cea88d162f28d54cd47f07f887c470e8a2f1b11d0ee48ef5b28 \
--control-plane --certificate-key afe2d59c138e7f0c16344c58fe4981069e21570f848f5ba50531f8f698f75302
|
执行以上命令,依次将k8s-master02和k8s-master03加入到集群中!
7.7 添加node节点
1 2 |
$ kubeadm join k8s-slb:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:36c5f93203130cea88d162f28d54cd47f07f887c470e8a2f1b11d0ee48ef5b28
|
八、集群验证
8.1 查看node节点运行情况
1 2 3 4 5 6 |
$ kubectl get node NAME STATUS ROLES AGE VERSION k8s-master01 Ready master 2m30s v1.18.2 k8s-master02 Ready master 2m34s v1.18.2 k8s-master03 Ready master 2m37s v1.18.2 k8s-node01 Ready <none> 2m49s v1.18.2 |
8.2 查看pod运行情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
$ kubectl get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-kube-controllers-7d94cd8f86-b8vzs 1/1 Running 0 8m6s 10.224.32.130 k8s-master01 <none> <none> calico-node-4rqj8 1/1 Running 0 3m47s 192.168.100.236 k8s-master02 <none> <none> calico-node-94sw6 1/1 Running 0 5m20s 192.168.100.238 k8s-node01 <none> <none> calico-node-gk7hg 1/1 Running 0 8m7s 192.168.100.235 k8s-master01 <none> <none> calico-node-vpll4 1/1 Running 0 5m8s 192.168.100.237 k8s-master03 <none> <none> coredns-7ff77c879f-97tjw 1/1 Running 0 11m 10.224.32.131 k8s-master01 <none> <none> coredns-7ff77c879f-mp98g 1/1 Running 0 11m 10.224.32.129 k8s-master01 <none> <none> etcd-k8s-master01 1/1 Running 0 11m 192.168.100.235 k8s-master01 <none> <none> etcd-k8s-master02 1/1 Running 0 3m45s 192.168.100.236 k8s-master02 <none> <none> etcd-k8s-master03 1/1 Running 0 4m41s 192.168.100.237 k8s-master03 <none> <none> kube-apiserver-k8s-master01 1/1 Running 0 11m 192.168.100.235 k8s-master01 <none> <none> kube-apiserver-k8s-master02 1/1 Running 1 3m47s 192.168.100.236 k8s-master02 <none> <none> kube-apiserver-k8s-master03 1/1 Running 0 5m7s 192.168.100.237 k8s-master03 <none> <none> kube-controller-manager-k8s-master01 1/1 Running 1 11m 192.168.100.235 k8s-master01 <none> <none> kube-controller-manager-k8s-master02 1/1 Running 0 3m47s 192.168.100.236 k8s-master02 <none> <none> kube-controller-manager-k8s-master03 1/1 Running 0 5m7s 192.168.100.237 k8s-master03 <none> <none> kube-proxy-66ntf 1/1 Running 0 5m8s 192.168.100.237 k8s-master03 <none> <none> kube-proxy-7n7nw 1/1 Running 0 11m 192.168.100.235 k8s-master01 <none> <none> kube-proxy-8qknh 1/1 Running 0 5m20s 192.168.100.238 k8s-node01 <none> <none> kube-proxy-rhqf4 1/1 Running 0 3m47s 192.168.100.236 k8s-master02 <none> <none> kube-scheduler-k8s-master01 1/1 Running 1 11m 192.168.100.235 k8s-master01 <none> <none> kube-scheduler-k8s-master02 1/1 Running 0 3m46s 192.168.100.236 k8s-master02 <none> <none> kube-scheduler-k8s-master03 1/1 Running 0 5m8s 192.168.100.237 k8s-master03 <none> <none> |
8.3 验证IPVS
查看kube-proxy日志,输出信息包含Using ipvs Proxier.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
$ kubectl logs -f kube-proxy-8qknh -n kube-system W1221 10:19:43.092405 1 feature_gate.go:235] Setting GA feature gate SupportIPVSProxyMode=true. It will be removed in a future release. W1221 10:19:43.092936 1 feature_gate.go:235] Setting GA feature gate SupportIPVSProxyMode=true. It will be removed in a future release. I1221 10:19:43.590876 1 node.go:136] Successfully retrieved node IP: 192.168.100.238 I1221 10:19:43.590973 1 server_others.go:259] Using ipvs Proxier. W1221 10:19:43.591887 1 proxier.go:429] IPVS scheduler not specified, use rr by default I1221 10:19:43.592412 1 server.go:583] Version: v1.18.2 I1221 10:19:43.593666 1 conntrack.go:100] Set sysctl 'net/netfilter/nf_conntrack_max' to 131072 I1221 10:19:43.593763 1 conntrack.go:52] Setting nf_conntrack_max to 131072 I1221 10:19:43.593944 1 conntrack.go:100] Set sysctl 'net/netfilter/nf_conntrack_tcp_timeout_established' to 86400 I1221 10:19:43.594082 1 conntrack.go:100] Set sysctl 'net/netfilter/nf_conntrack_tcp_timeout_close_wait' to 3600 I1221 10:19:43.594668 1 config.go:133] Starting endpoints config controller I1221 10:19:43.594728 1 shared_informer.go:223] Waiting for caches to sync for endpoints config I1221 10:19:43.594789 1 config.go:315] Starting service config controller I1221 10:19:43.594808 1 shared_informer.go:223] Waiting for caches to sync for service config I1221 10:19:43.695036 1 shared_informer.go:230] Caches are synced for service config I1221 10:19:43.695053 1 shared_informer.go:230] Caches are synced for endpoints config |
8.4 etcd集群验证
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl --endpoints=https://192.168.100.235:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key member list -wtable +------------------+---------+--------------+------------------------------+------------------------------+------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------+------------------------------+------------------------------+------------+ | b22d109a6211c55 | started | k8s-master02 | https://192.168.100.236:2380 | https://192.168.100.236:2379 | false | | c07cc16c40f2638 | started | k8s-master01 | https://192.168.100.235:2380 | https://192.168.100.235:2379 | false | | f122e0cdce559ffc | started | k8s-master03 | https://192.168.100.237:2380 | https://192.168.100.237:2379 | false | +------------------+---------+--------------+------------------------------+------------------------------+------------+ $ kubectl -n kube-system exec etcd-k8s-master01 -- etcdctl --endpoints=https://192.168.100.235:2379,https://192.168.100.236:2379,https://192.168.100.237:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key endpoint status https://192.168.100.235:2379, c07cc16c40f2638, 3.4.3, 3.8 MB, true, false, 15, 6776, 6776, https://192.168.100.236:2379, b22d109a6211c55, 3.4.3, 3.7 MB, false, false, 15, 6776, 6776, https://192.168.100.237:2379, f122e0cdce559ffc, 3.4.3, 3.7 MB, false, false, 15, 6776, 6776, |
8.5 验证HA
在master01上执行关机操作,建议提前在其他节点配置kubectl命令支持。
1 |
$ shutdown -h now |
在任意运行节点验证集群状态,master01节点NotReady,集群可正常访问:
1 2 3 4 5 6 |
$ kubectl get node NAME STATUS ROLES AGE VERSION k8s-master01 NotReady master 33m v1.18.2 k8s-master02 Ready master 26m v1.18.2 k8s-master03 Ready master 27m v1.18.2 k8s-node01 Ready <none> 27m v1.18.2 |
查看网卡,vip自动漂移到master02节点
1 2 3 |
$ ip a | grep 192.168
inet 192.168.100.236/24 brd 192.168.100.255 scope global eth0
inet 192.168.100.201/32 scope global eth0 |
智能推荐
软件测试流程包括哪些内容?测试方法有哪些?_测试过程管理中包含哪些过程-程序员宅基地
文章浏览阅读2.9k次,点赞8次,收藏14次。测试主要做什么?这完全都体现在测试流程中,同时测试流程是面试问题中出现频率最高的,这不仅是因为测试流程很重要,而是在面试过程中这短短的半小时到一个小时的时间,通过测试流程就可以判断出应聘者是否合适,故在测试流程中包含了测试工作的核心内容,例如需求分析,测试用例的设计,测试执行,缺陷等重要的过程。..._测试过程管理中包含哪些过程
政府数字化政务的人工智能与机器学习应用:如何提高政府工作效率-程序员宅基地
文章浏览阅读870次,点赞16次,收藏19次。1.背景介绍政府数字化政务是指政府利用数字技术、互联网、大数据、人工智能等新技术手段,对政府政务进行数字化改革,提高政府工作效率,提升政府服务质量的过程。随着人工智能(AI)和机器学习(ML)技术的快速发展,政府数字化政务中的人工智能与机器学习应用也逐渐成为政府改革的重要内容。政府数字化政务的人工智能与机器学习应用涉及多个领域,包括政策决策、政府服务、公共安全、社会治理等。在这些领域,人工...
ssm+mysql+微信小程序考研刷题平台_mysql刷题软件-程序员宅基地
文章浏览阅读219次,点赞2次,收藏4次。系统主要的用户为用户、管理员,他们的具体权限如下:用户:用户登录后可以对管理员上传的学习视频进行学习。用户可以选择题型进行练习。用户选择小程序提供的考研科目进行相关训练。用户可以进行水平测试,并且查看相关成绩用户可以进行错题集的整理管理员:管理员登录后可管理个人基本信息管理员登录后可管理个人基本信息管理员可以上传、发布考研的相关例题及其分析,并对题型进行管理管理员可以进行查看、搜索考研题目及错题情况。_mysql刷题软件
根据java代码描绘uml类图_Myeclipse8.5下JAVA代码导成UML类图-程序员宅基地
文章浏览阅读1.4k次。myelipse里有UML1和UML2两种方式,UML2功能更强大,但是两者生成过程差别不大1.建立Test工程,如下图,uml包存放uml类图package com.zz.domain;public class User {private int id;private String name;public int getId() {return id;}public void setId(int..._根据以下java代码画出类图
Flume自定义拦截器-程序员宅基地
文章浏览阅读174次。需求:一个topic包含很多个表信息,需要自动根据json字符串中的字段来写入到hive不同的表对应的路径中。发送到Kafka中的数据原本最外层原本没有pkDay和project,只有data和name。因为担心data里面会空值,所以根同事商量,让他们在最外层添加了project和pkDay字段。pkDay字段用于表的自动分区,proejct和name合起来用于自动拼接hive表的名称为 ..._flume拦截器自定义开发 kafka
java同时输入不同类型数据,Java Spring中同时访问多种不同数据库-程序员宅基地
文章浏览阅读380次。原标题:Java Spring中同时访问多种不同数据库 多样的工作要求,可以使用不同的工作方法,只要能获得结果,就不会徒劳。开发企业应用时我们常常遇到要同时访问多种不同数据库的问题,有时是必须把数据归档到某种数据仓库中,有时是要把数据变更推送到第三方数据库中。使用Spring框架时,使用单一数据库是非常容易的,但如果要同时访问多个数据库的话事件就变得复杂多了。本文以在Spring框架下开发一个Sp..._根据输入的不同连接不同的数据库
随便推点
EFT试验复位案例分析_eft电路图-程序员宅基地
文章浏览阅读3.6k次,点赞9次,收藏25次。本案例描述了晶振屏蔽以及开关电源变压器屏蔽对系统稳定工作的影响, 硬件设计时应考虑。_eft电路图
MR21更改价格_mr21 对于物料 zba89121 存在一个当前或未来标准价格-程序员宅基地
文章浏览阅读1.1k次。对于物料价格的更改,可以采取不同的手段:首先,我们来介绍MR21的方式。 需要说明的是,如果要对某一产品进行价格修改,必须满足的前提条件是: ■ 1、必须对价格生效的物料期间与对应会计期间进行开启; ■ 2、该产品在该物料期间未发生物料移动。执行MR21,例如更改物料1180051689的价格为20000元,系统提示“对于物料1180051689 存在一个当前或未来标准价格”,这是因为已经对该..._mr21 对于物料 zba89121 存在一个当前或未来标准价格
联想启天m420刷bios_联想启天M420台式机怎么装win7系统(完美解决usb)-程序员宅基地
文章浏览阅读7.4k次,点赞3次,收藏13次。[文章导读]联想启天M420是一款商用台式电脑,预装的是win10系统,用户还是喜欢win7系统,该台式机采用的intel 8代i5 8500CPU,在安装安装win7时有很多问题,在安装win7时要在BIOS中“关闭安全启动”和“开启兼容模式”,并且安装过程中usb不能使用,要采用联想win7新机型安装,且默认采用的uefi+gpt模式,要改成legacy+mbr引导,那么联想启天M420台式电..._启天m420刷bios
冗余数据一致性,到底如何保证?-程序员宅基地
文章浏览阅读2.7k次,点赞2次,收藏9次。一,为什么要冗余数据互联网数据量很大的业务场景,往往数据库需要进行水平切分来降低单库数据量。水平切分会有一个patition key,通过patition key的查询能..._保证冗余性
java 打包插件-程序员宅基地
文章浏览阅读88次。是时候闭环Java应用了 原创 2016-08-16 张开涛 你曾经因为部署/上线而痛苦吗?你曾经因为要去运维那改配置而烦恼吗?在我接触过的一些部署/上线方式中,曾碰到过以下一些问题:1、程序代码和依赖都是人工上传到服务器,不是通过工具进行部署和发布;2、目录结构没有规范,jar启动时通过-classpath任意指定;3、fat jar,把程序代码、配置文件和依赖jar都打包到一个jar中,改配置..._那么需要把上面的defaultjavatyperesolver类打包到插件中
VS2015,Microsoft Visual Studio 2005,SourceInsight4.0使用经验,Visual AssistX番茄助手的安装与基本使用9_番茄助手颜色-程序员宅基地
文章浏览阅读909次。1.得下载一个番茄插件,按alt+g才可以有函数跳转功能。2.不安装番茄插件,按F12也可以有跳转功能。3.进公司的VS工程是D:\sync\build\win路径,.sln才是打开工程的方式,一个是VS2005打开的,一个是VS2013打开的。4.公司库里的线程接口,在CmThreadManager.h 里,这个里面是我们的线程库,可以直接拿来用。CreateUserTaskThre..._番茄助手颜色