不踩坑的Python爬虫:如何在一个月内学会爬取大规模数据-程序员宅基地

Python爬虫为什么受欢迎
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。
利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:
知乎:爬取优质答案,为你筛选出各话题下最优质的内容。
淘宝、京东:抓取商品、评论及销量数据,对各种商品及用户的消费场景进行分析。
安居客、链家:抓取房产买卖及租售信息,分析房价变化趋势、做不同区域的房价分析。
拉勾网、智联:爬取各类职位信息,分析各行业人才需求情况及薪资水平。
雪球网:抓取雪球高回报用户的行为,对股票市场进行分析和预测。
爬虫是入门Python最好的方式,没有之一。Python有很多应用的方向,比如后台开发、web开发、科学计算等等,但爬虫对于初学者而言更友好,原理简单,几行代码就能实现基本的爬虫,学习的过程更加平滑,你能体会更大的成就感。
掌握基本的爬虫后,你再去学习Python数据分析、web开发甚至机器学习,都会更得心应手。因为这个过程中,Python基本语法、库的使用,以及如何查找文档你都非常熟悉了。
对于小白来说,爬虫可能是一件非常复杂、技术门槛很高的事情。比如有人认为学爬虫必须精通 Python,然后哼哧哼哧系统学习 Python 的每个知识点,很久之后发现仍然爬不了数据;有的人则认为先要掌握网页的知识,遂开始 HTML\CSS,结果入了前端的坑,瘁……
但掌握正确的方法,在短时间内做到能够爬取主流网站的数据,其实非常容易实现,但建议你从一开始就要有一个具体的目标。
在目标的驱动下,你的学习才会更加精准和高效。那些所有你认为必须的前置知识,都是可以在完成目标的过程中学到的。这里给你一条平滑的、零基础快速入门的学习路径。
1.学习 Python 包并实现基本的爬虫过程
2.了解非结构化数据的存储
3.学习scrapy,搭建工程化爬虫
4.学习数据库知识,应对大规模数据存储与提取
5.掌握各种技巧,应对特殊网站的反爬措施
6.分布式爬虫,实现大规模并发采集,提升效率
- ❶ -
学习 Python 包并实现基本的爬虫过程
大部分爬虫都是按“发送请求——获得页面——解析页面——抽取并储存内容”这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。
Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,建议从requests+Xpath 开始,requests 负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。
如果你用过 BeautifulSoup,会发现 Xpath 要省事不少,一层一层检查元素代码的工作,全都省略了。这样下来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、腾讯新闻等基本上都可以上手了。
当然如果你需要爬取异步加载的网站,可以学习浏览器抓包分析真实请求或者学习Selenium来实现自动化,这样,知乎、时光网、猫途鹰这些动态的网站也可以迎刃而解。
- ❷ -
了解非结构化数据的存储
爬回来的数据可以直接用文档形式存在本地,也可以存入数据库中。
开始数据量不大的时候,你可以直接通过 Python 的语法或 pandas 的方法将数据存为csv这样的文件。
当然你可能发现爬回来的数据并不是干净的,可能会有缺失、错误等等,你还需要对数据进行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
- ❸ -
学习 scrapy,搭建工程化的爬虫
掌握前面的技术一般量级的数据和代码基本没有问题了,但是在遇到非常复杂的情况,可能仍然会力不从心,这个时候,强大的 scrapy 框架就非常有用了。
scrapy 是一个功能非常强大的爬虫框架,它不仅能便捷地构建request,还有强大的 selector 能够方便地解析 response,然而它最让人惊喜的还是它超高的性能,让你可以将爬虫工程化、模块化。
学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。
- ❹ -
学习数据库基础,应对大规模数据存储
爬回来的数据量小的时候,你可以用文档的形式来存储,一旦数据量大了,这就有点行不通了。所以掌握一种数据库是必须的,学习目前比较主流的 MongoDB 就OK。
MongoDB 可以方便你去存储一些非结构化的数据,比如各种评论的文本,图片的链接等等。你也可以利用PyMongo,更方便地在Python中操作MongoDB。
因为这里要用到的数据库知识其实非常简单,主要是数据如何入库、如何进行提取,在需要的时候再学习就行。
- ❺ -
掌握各种技巧,应对特殊网站的反爬措施
当然,爬虫过程中也会经历一些绝望啊,比如被网站封IP、比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
遇到这些反爬虫的手段,当然还需要一些高级的技巧来应对,常规的比如访问频率控制、使用代理IP池、抓包、验证码的OCR处理等等。
往往网站在高效开发和反爬虫之间会偏向前者,这也为爬虫提供了空间,掌握这些应对反爬虫的技巧,绝大部分的网站已经难不到你了。
- ❻ -
分布式爬虫,实现大规模并发采集
爬取基本数据已经不是问题了,你的瓶颈会集中到爬取海量数据的效率。这个时候,相信你会很自然地接触到一个很厉害的名字:分布式爬虫。
分布式这个东西,听起来很恐怖,但其实就是利用多线程的原理让多个爬虫同时工作,需要你掌握 Scrapy + MongoDB + Redis 这三种工具。
Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于存储爬取的数据,Redis 则用来存储要爬取的网页队列,也就是任务队列。
所以有些东西看起来很吓人,但其实分解开来,也不过如此。当你能够写分布式的爬虫的时候,那么你可以去尝试打造一些基本的爬虫架构了,实现一些更加自动化的数据获取。
你看,这一条学习路径下来,你已然可以成为老司机了,非常的顺畅。所以在一开始的时候,尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这种简单的入手),直接开始就好。
因为爬虫这种技术,既不需要你系统地精通一门语言,也不需要多么高深的数据库技术,高效的姿势就是从实际的项目中去学习这些零散的知识点,你能保证每次学到的都是最需要的那部分。
当然唯一麻烦的是,在具体的问题中,如何找到具体需要的那部分学习资源、如何筛选和甄别,是很多初学者面临的一个大问题。
不过不用担心,我们准备了一门非常系统的爬虫课程,除了为你提供一条清晰的学习路径,我们甄选了最实用的学习资源以及庞大的主流爬虫案例库。短时间的学习,你就能够很好地掌握爬虫这个技能,获取你想得到的数据。

经过短时间的学习,不少同学都取得了从0到1的进步,能够写出自己的爬虫,爬取大规模数据。
如果你希望在短时间内学会爬虫,少走弯路
扫描下方二维码加入课程
限时优惠 ¥299(原价399)

- 高效的学习路径 -
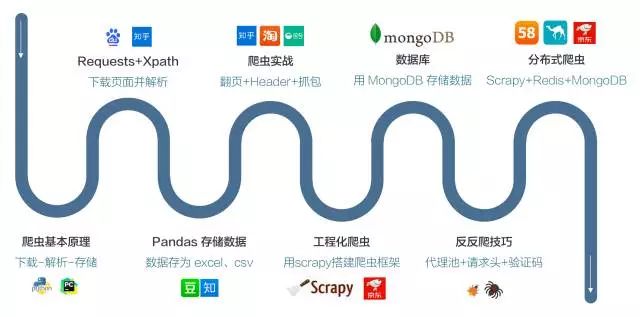
一上来就讲理论、语法、编程语言是非常不合理的,我们会直接从具体的案例入手,通过实际的操作,学习具体的知识点。我们为你规划了一条系统的学习路径,让你不再面对零散的知识点。
说点具体的,比如我们会直接用 lxml+Xpath取代 BeautifulSoup 来进行网页解析,减少你不必要的检查网页元素的操作,多种工具都能完成的,我们会给你最简单的方法,这些看似细节,但可能是很多人都会踩的坑。
《Python爬虫:入门+进阶》大纲
第一章:Python 爬虫入门
1、什么是爬虫
网址构成和翻页机制
网页源码结构及网页请求过程
爬虫的应用及基本原理
2、初识Python爬虫
Python爬虫环境搭建
创建第一个爬虫:爬取百度首页
爬虫三步骤:获取数据、解析数据、保存数据
3、使用Requests爬取豆瓣短评
Requests的安装和基本用法
用Requests 爬取豆瓣短评信息
一定要知道的爬虫协议
4、使用Xpath解析豆瓣短评
解析神器Xpath的安装及介绍
Xpath的使用:浏览器复制和手写
实战:用 Xpath 解析豆瓣短评信息
5、使用pandas保存豆瓣短评数据
pandas 的基本用法介绍
pandas文件保存、数据处理
实战:使用pandas保存豆瓣短评数据
6、浏览器抓包及headers设置(案例一:爬取知乎)
爬虫的一般思路:抓取、解析、存储
浏览器抓包获取Ajax加载的数据
设置headers 突破反爬虫限制
实战:爬取知乎用户数据
7、数据入库之MongoDB(案例二:爬取拉勾)
MongoDB及RoboMongo的安装和使用
设置等待时间和修改信息头
实战:爬取拉勾职位数据
将数据存储在MongoDB中
补充实战:爬取微博移动端数据
8、Selenium爬取动态网页(案例三:爬取淘宝)
动态网页爬取神器Selenium搭建与使用
分析淘宝商品页面动态信息
实战:用Selenium 爬取淘宝网页信息
第二章:Python爬虫之Scrapy框架
1、爬虫工程化及Scrapy框架初窥
html、css、js、数据库、http协议、前后台联动
爬虫进阶的工作流程
Scrapy组件:引擎、调度器、下载中间件、项目管道等
常用的爬虫工具:各种数据库、抓包工具等
2、Scrapy安装及基本使用
Scrapy安装
Scrapy的基本方法和属性
开始第一个Scrapy项目
3、Scrapy选择器的用法
常用选择器:css、xpath、re、pyquery
css的使用方法
xpath的使用方法
re的使用方法
pyquery的使用方法
4、Scrapy的项目管道
Item Pipeline的介绍和作用
Item Pipeline的主要函数
实战举例:将数据写入文件
实战举例:在管道里过滤数据
5、Scrapy的中间件
下载中间件和蜘蛛中间件
下载中间件的三大函数
系统默认提供的中间件
6、Scrapy的Request和Response详解
Request对象基础参数和高级参数
Request对象方法
Response对象参数和方法
Response对象方法的综合利用详解
第三章:Python爬虫进阶操作
1、网络进阶之谷歌浏览器抓包分析
http请求详细分析
网络面板结构
过滤请求的关键字方法
复制、保存和清除网络信息
查看资源发起者和依赖关系
2、数据入库之去重与数据库
数据去重
数据入库MongoDB
第四章:分布式爬虫及实训项目
1、大规模并发采集——分布式爬虫的编写
分布式爬虫介绍
Scrapy分布式爬取原理
Scrapy-Redis的使用
Scrapy分布式部署详解
2、实训项目(一)——58同城二手房监控
3、实训项目(二)——去哪儿网模拟登陆
4、实训项目(三)——京东商品数据抓取
- 每课都有学习资料 -
你可能收集了以G计的的学习资源,但保存后从来没打开过?我们已经帮你找到了最有用的那部分,并且用最简单的形式描述出来,帮助你学习,你可以把更多的时间用于练习和实践。
考虑到各种各样的问题,我们在每一节都准备了课后资料,包含四个部分:
1.课程重点笔记,详细阐述重点知识,帮助你理解和后续快速复习;
2.默认你是小白,补充所有基础知识,哪怕是软件的安装与基本操作;
3.课内外案例提供参考代码学习,让你轻松应对主流网站爬虫;
4.超多延伸知识点和更多问题的解决思路,让你有能力去解决实际中遇到的一些特殊问题。

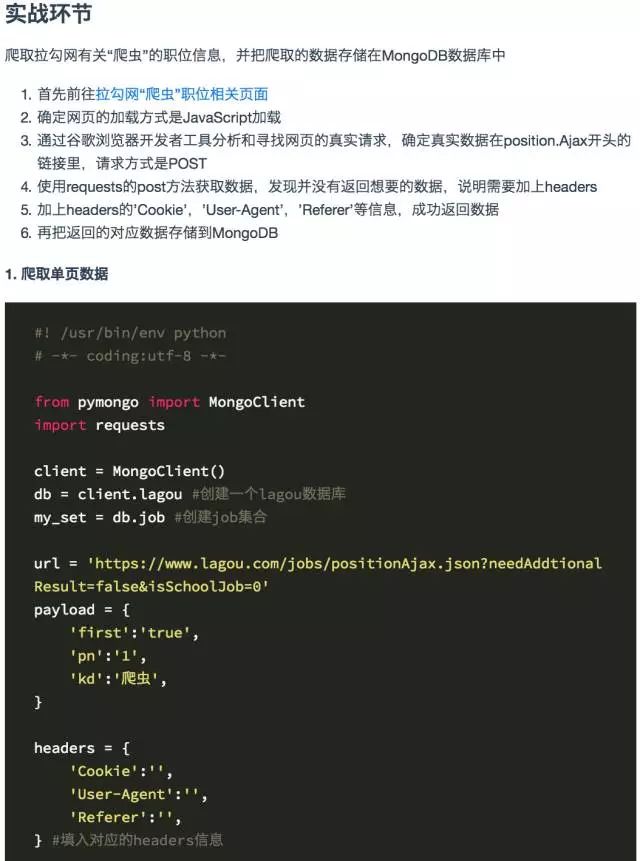
某节部分课后资料
- 超多案例,覆盖主流网站 -
课程中提供了目前最常见的网站爬虫案例:豆瓣、百度、知乎、淘宝、京东、微博……每个案例在课程视频中都有详细分析,老师带你完成每一步操作。
另外,我们还会补充比如小猪、链家、58同城、网易云音乐、微信好友等案例,提供思路与代码。
多次的模仿和练习之后,你可以很轻松地写出自己的爬虫代码,并能够轻松爬取这些主流网站的数据。

- 技能拓展:反爬虫及数据存储、处理 -
懂得基本的爬虫是远远不够的,所以我们会用实际的案例,带你了解一些网站的反爬虫措施,并且用具体的技术绕过限制。比如异步加载、IP限制、headers限制、验证码等等,这些比较常见的反爬虫手段,你都可以很好地规避。
工程化的爬虫、及分布式爬虫技术,让你有获取大规模数据的可能。除了爬虫的内容,你还将了解数据库(Mongodb)、pandas 的基本知识,帮你存储爬取的数据,同时可以对数据进行管理和清洗,你可以获得更干净的数据,以便后续的分析和处理。

用 Scrapy 爬取租房信息
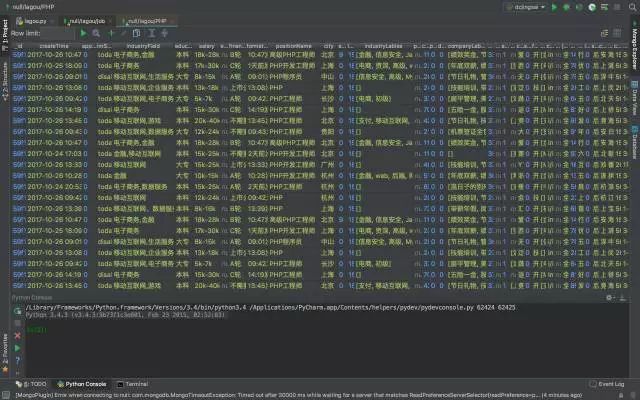
爬取拉勾招聘数据并用 MongoDB 存储
除了经验丰富、带你一步步实操的课程老师之外,DC学院还建立了提升效率的学习群,助教老师会在群里及时解答学员每一个疑问。同时,你还可以跟一群未来优秀的爬虫工程师,分享经验、代码、数据,探讨爬虫和数据分析技术。
【课程信息】
「 课程名称 」
Python 爬虫:入门+进阶
「 学习周期 」
建议每周至少学习8小时,一个月爬取大规模数据
「 上课形式 」
录播课程,可随时开始上课,反复观看
「 面向人群 」
零基础的小白,负基础的小白白
「 答疑形式 」
学习群老师随时答疑,即便是最初级的问题
「 课程资料 」
重点笔记、操作详解、参考代码、课后拓展
「 课程案例 」
爬取豆瓣短评、图书、电影数据
爬取知乎用户、回答数据
爬取淘宝、京东商品数据
爬取拉勾职位数据
爬取去哪儿旅游景点数据
爬取58同城二手房数据
公众号专属优惠,限额底价
¥299(原价¥399),限前100名
长按下方二维码,立即去抢
课程咨询、免费试看,请加入下方群聊
若群满,加Alice微信:datacastle2017

哦,对了,我们给每个按要求完成学习的同学
准备了DC学院的学习证书

每个证书编号对应一个独立身份信息
点击阅读原文立即获取爬虫技能
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf