Junit 入门使用教程_junitgenerator怎么用-程序员宅基地
1、Junit 是什么?
JUnit是一个Java语言的单元测试框架。它由Kent Beck和Erich Gamma建立,逐渐成为源于Kent Beck的sUnit的xUnit家族中最为成功的一个JUnit有它自己的JUnit扩展生态圈。多数Java的开发环境都已经集成了JUnit作为单元测试的工具。
注意:Junit 测试也是程序员测试,即所谓的白盒测试,它需要程序员知道被测试的代码如何完成功能,以及完成什么样的功能
2、Junit 能做什么?
我们知道 Junit 是一个单元测试框架,那么使用 Junit 能让我们快速的完成单元测试。
通常我们写完代码想要测试这段代码的正确性,那么必须新建一个类,然后创建一个 main() 方法,然后编写测试代码。如果需要测试的代码很多呢?那么要么就会建很多main() 方法来测试,要么将其全部写在一个 main() 方法里面。这也会大大的增加测试的复杂度,降低程序员的测试积极性。而 Junit 能很好的解决这个问题,简化单元测试,写一点测一点,在编写以后的代码中如果发现问题可以较快的追踪到问题的原因,减小回归错误的纠错难度。
3、Junit 的用法
一、首先下载 Junit jar 包,这里给两个版本的百度云下载地址:
①、Junit 4.12版本 链接:百度网盘-链接不存在 密码:hfix
②、Junit 4.8 版本 链接:百度网盘-链接不存在 密码:ma2u
二、下载完成之后,在项目中将 下载的 jar 包放进去,然后右键,Build--->Add Build Path 即可。
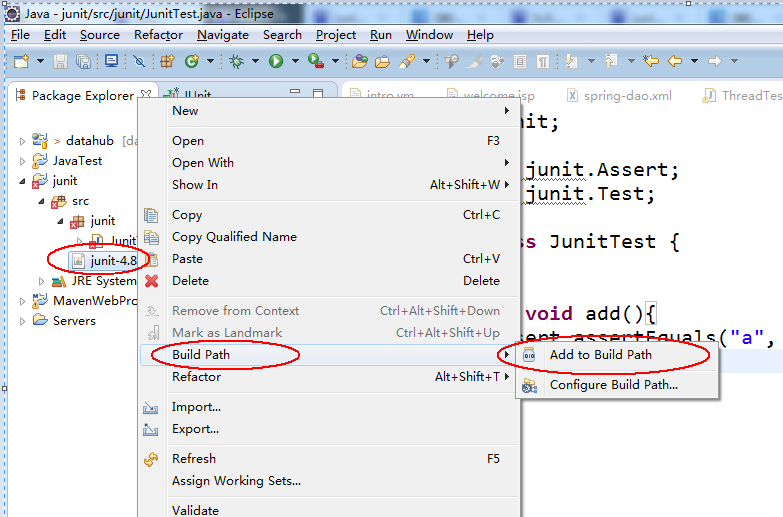
如果你是用 eclipse 开发,也可以不用下载那些jar包,eclipse内部集成了,我们只需要引入即可:
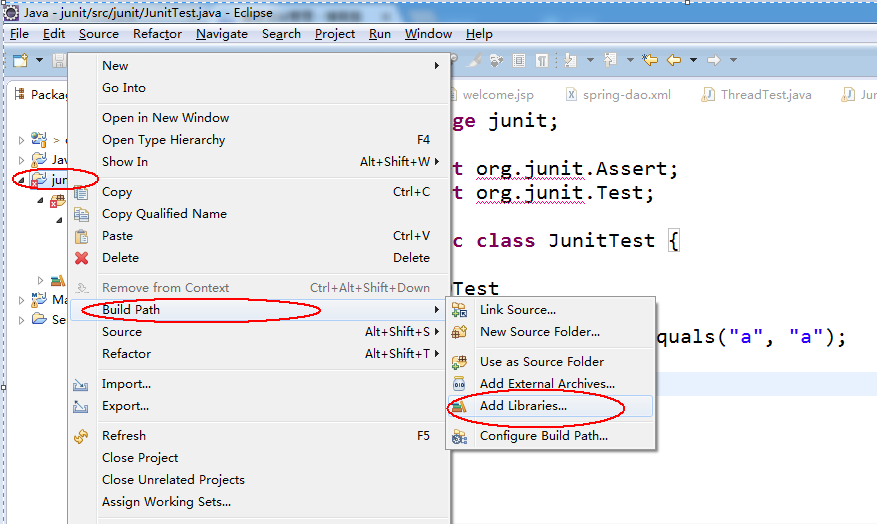
①、选中项目,右键Build--->Add Library
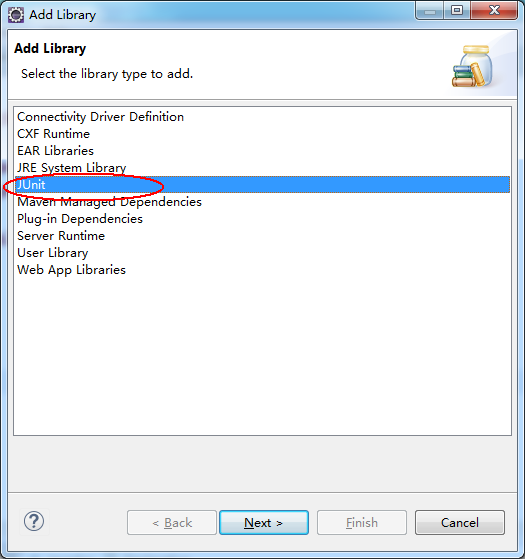
②、弹出来的界面,选中 JUnit,点击 next
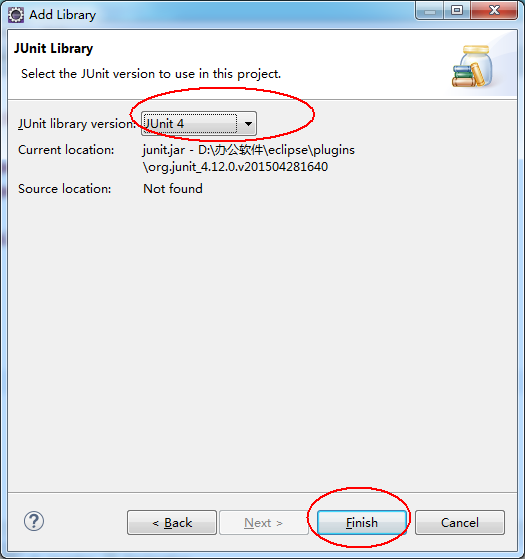
③、选中 Junit 的版本,一般我们都用 4.0 以上的。点击 Finish
三、我们先看下面这个例子,看一下 Junit 的用法
①、编写代码(需要测试的类)
public class Calculator {
/**
* 传入两个参数,求和
* @param a
* @param b
* @return
*/
public int add(int a,int b){
return a+b;
}
/**
* 传入两个参数,求差
* @param a
* @param b
* @return
*/
public int sub(int a,int b){
return a-b;
}
}
②、编写测试类
一、不用Junit
public class CalculatorTest {
public static void main(String[] args) {
Calculator c = new Calculator();
//测试 add()方法
int result = c.add(1, 2);
if(result == 3){
System.out.println("add()方法正确");
}
//测试 sub()方法
int result2 = c.sub(2, 1);
if(result2 == 1){
System.out.println("sub()方法正确");
}
}
}
那么我们可以看到,不用 Junit 只能写在 main()方法中,通过运行结果来判断测试结果是否正确。这里需要测试的只有两个方法,如果有很多方法,那么测试代码就会变得很混乱。
二、使用 Junit(看不懂 Assert.assertEquals()方法没关系,可以自己写 if()语句来判断)
public class CalculatorTest {
@Test
//测试 add()方法
public void testAdd(){
Calculator c = new Calculator();
int result = c.add(1, 2);
Assert.assertEquals(result, 3);
}
@Test
//测试 sub()方法
public void testSub(){
Calculator c = new Calculator();
int result = c.sub(2, 1);
Assert.assertEquals(result, 1);
}
}
如何运行 Junit呢?鼠标放在需要测试的方法中,右键,Run As ---->JUnit Test
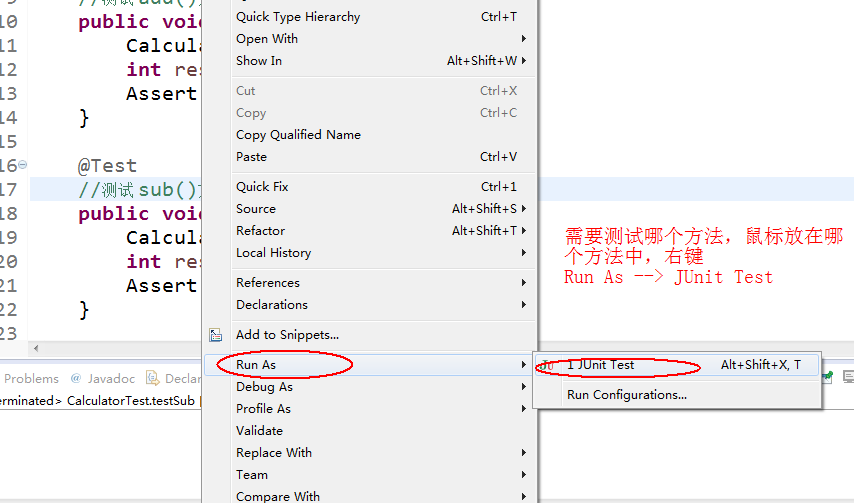
结果出现如下的绿色横条,则测试通过,红色横条,则测试失败
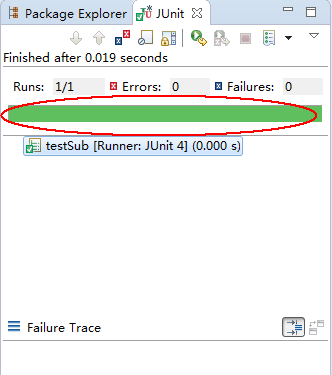
那么由上面可以看到,使用 Junit 不需要创建 main() 方法,而且每个测试方法一一对应,逻辑特别清晰。可能有读者会问,这样写代码量也并不会减少啊,那么你接着往下看:
首先介绍 Junit 的几种类似于 @Test 的注解:
1.@Test: 测试方法
a)(expected=XXException.class)如果程序的异常和XXException.class一样,则测试通过
b)(timeout=100)如果程序的执行能在100毫秒之内完成,则测试通过
2.@Ignore: 被忽略的测试方法:加上之后,暂时不运行此段代码
3.@Before: 每一个测试方法之前运行
4.@After: 每一个测试方法之后运行
5.@BeforeClass: 方法必须必须要是静态方法(static 声明),所有测试开始之前运行,注意区分before,是所有测试方法
6.@AfterClass: 方法必须要是静态方法(static 声明),所有测试结束之后运行,注意区分 @After
那么上面的例子,我们可以看到,每个 @Test 方法中都有 Calculator c = new Calculator();即类的实例化,那么我们可以将其放入到 @Before 中
public class CalculatorTest {
Calculator c = null;
@Before
public void testBeforeClass(){
c = new Calculator();
}
@Test
//测试 add()方法
public void testAdd(){
int result = c.add(1, 2);
//Assert.assertEquals(result, 3);
//等价于:
if(result == 3){
System.out.println("add()方法正确");
}
}
@Test
//测试 sub()方法
public void testSub(){
int result = c.sub(2, 1);
//Assert.assertEquals(result, 1);
//等价于:
if(result == 1){
System.out.println("sub()方法正确");
}
}
}
同理:别的注解用法我们用一个类来看:
public class JunitTest {
public JunitTest() {
System.out.println("构造函数");
}
@BeforeClass
public static void beforeClass(){
System.out.println("@BeforeClass");
}
@Before
public void befor(){
System.out.println("@Before");
}
@Test
public void test(){
System.out.println("@Test");
}
@Ignore
public void ignore(){
System.out.println("@Ignore");
}
@After
public void after(){
System.out.println("@After");
}
@AfterClass
public static void afterClass(){
System.out.println("@AfterClass");
}
}
结果为:
@BeforeClass
构造函数
@Before
@Test
@After
@AfterClass
注意:编写测试类的原则:
①测试方法上必须使用@Test进行修饰
②测试方法必须使用public void 进行修饰,不能带任何的参数
③新建一个源代码目录来存放我们的测试代码,即将测试代码和项目业务代码分开
④测试类所在的包名应该和被测试类所在的包名保持一致
⑤测试单元中的每个方法必须可以独立测试,测试方法间不能有任何的依赖
⑥测试类使用Test作为类名的后缀(不是必须)
⑦测试方法使用test作为方法名的前缀(不是必须)
智能推荐
kmeans_kmeans算法相关性分析-程序员宅基地
文章浏览阅读936次。1 kmeansK-means聚类算法也称k均值聚类算法,是集简单和经典于一身的基于距离的聚类算法。它采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为类簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。2.算法核心思想K-means聚类算法是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本_kmeans算法相关性分析
基于springboot的自习室管理系统计算机毕业设计_基于springboot的共享自习室管理系统参考文献-程序员宅基地
文章浏览阅读466次,点赞8次,收藏12次。以上是基于Spring Boot的自习室管理系统的主要功能,通过这些功能可以实现自习室座位的管理、课程的管理、学员信息的管理和行为管理等功能,为自习室提供一个高效、便捷、智能的解决方案。登录后,系统将根据用户的角色显示相应的功能菜单。通过以上各个功能模块的实现,基于Spring Boot的自习室管理系统将提供一套完善的解决方案,帮助自习室提高工作效率和服务质量,为学员提供更加便捷、舒适的学习环境。通过生成相应的报表,管理员可以更好地了解自习室的使用状况和学员的学习情况,从而做出相应的决策和管理调整。_基于springboot的共享自习室管理系统参考文献
Pytroch同一个优化器优化多个模型的参数并且保存优化后的参数_pytorch加载多个模型-程序员宅基地
文章浏览阅读4.5k次,点赞7次,收藏26次。在进行深度学习过程中会遇到几个模型进行串联,这几个模型需要使用同一个优化器,但每个模型的学习率或者动量等其他参数不一样这种情况。一种解决方法是新建一个模型将这几个模型进行串联,另一种解决方法便是往优化器里面传入这几个模型的参数。..._pytorch加载多个模型
计算机软考中级合格标准,中级软考多少分及格-程序员宅基地
文章浏览阅读1.4k次。原标题:中级软考多少分及格盛泰鼎盛 对于第一次报名软考的朋友,可能对于考试合格分数线不太了解,软考分为初、中、高三个级别,那么软考中级多少分及格呢?软考中级合格标准根据往年的软考合格分数线来看,各级别的合格标准基本上统一的。2019年上半年计算机技术与软件专业技术资格(水平)考试各级别各专业各科目合格标准均为45分(总分75分)。而2016下半年计算机技术与软件专业技术资格(水平)考试除了信息系统..._计算机程序设计员中级考试内容及合格标准
爬虫相关-程序员宅基地
文章浏览阅读50次。2019独角兽企业重金招聘Python工程师标准>>> ..._爬虫考虑安全法律因素
ASP.NET Identity 的“多重”身份验证-程序员宅基地
文章浏览阅读263次。本章主要内容有: ● 实现基于微软账户的第三方身份验证 ● 实现双因子身份验证 ● 验证码机制实现基于微软账户的第三方身份验证 在微软提供的ASP.NET MVC模板代码中,默认添加了微软、Google、twitter以及Facebook的账户登录代码(虽然被注释了),另外针对国内的一些社交账户提供了相应的组件,所有组件都可以通过Nuget包管理器安装: 从..._identity 二次登录
随便推点
C++ 敏感词屏蔽-程序员宅基地
文章浏览阅读350次。首先要解决的问题是敏感词的存储形式,这就涉及数据结构,先想想搜索屏蔽要怎么处理,比如我有一个content,我就遍历它每个字符,先看与词典中所有词第一个字符相同的,再看第二个,再看第三个.等等。那么,很明显,这就需要一种以层来存储的数据结构--树来存储敏感词汇。我首先设计了一个Node,它要存储同一级的node指针,下一级的node指针,标识词的结束,数据。最开始本来只想到用树的结构,最后发现, ...
一种隐私保护的BP神经网络的设计-程序员宅基地
文章浏览阅读167次,点赞3次,收藏7次。1. 背景介绍1.1 隐私保护的重要性在当今的数字时代,个人隐私保护已经成为一个越来越受关注的问题。随着大数据和人工智能技术的快速发展,海量的个人数据被收集和利用,这给个人隐私带来了巨大的风险。如何在利用数据的同时保护个人隐私,已经成为了一个亟待解决的挑战。
Java常用异常包_object常用方法,java常见包;常见异常-程序员宅基地
文章浏览阅读177次。1.clone方法保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。2.getClass方法final方法,获得运行时类型。3.toString方法该方法用得比较多,一般子类都有覆盖。4.finalize方法该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。5.equals方法该方法是非常重..._一般情况下,异常类存放在什么包中
队列的定义_队列又可以简称为-程序员宅基地
文章浏览阅读1.1k次。队列的定义队列简称为“对”,英文名为“Queue”。队列和堆栈一样都是特殊的线性表。和堆栈不一样的是,队列这种线性表的特殊是它限定只能在表的一端作插入运算,然后只能在表的另一端作删除运算,作插入元素的这一端为“队首”,作删除运算的这一端称为“队尾”。队列的这一特征我们又可以称它为“先进先出”。队列的这个“先进先出”就如同我们平时排队一样,讲究一个先来后到,先来的排在前面,后到的排在后面,排前面的先走,排后面的后走。队列有两种存储结构,一种是顺序排列,另一种是链式排列。如下面图的采用顺序存储结构_队列又可以简称为
数据驱动的产品研发:如何利用数据驱动提高产品安全性-程序员宅基地
文章浏览阅读867次,点赞11次,收藏20次。1.背景介绍在当今的数字时代,数据已经成为企业和组织中最宝贵的资产之一。随着数据的增长和复杂性,数据驱动的决策变得越来越重要。数据驱动的产品研发是一种新兴的方法,它利用数据来优化产品的设计、开发和运营。这种方法可以帮助企业更有效地利用数据,提高产品的安全性和质量。在这篇文章中,我们将探讨数据驱动的产品研发的核心概念、算法原理、实例和未来发展趋势。我们将涉及到以下几个方面:背景介绍核...
基础类的DSP/BIOS API调用_clk_gethtime 返回值-程序员宅基地
文章浏览阅读1.3k次。转载自:http://blog.sina.com.cn/s/blog_48b82df90100bpfj.html基础类的DSP/BIOS API调用一、时钟管理CLK(1)Uns ncounts = CLK_countspms(void) 返回每毫秒的定时器高分辨率时钟的计数值(2)LgUns currtime = CLK_gethtime(void) _clk_gethtime 返回值