深度学习-08(PaddlePaddle文本分类)_基于paddlepaddle的文本分类-程序员宅基地
深度学习-08(PaddlePaddle文本分类)
文章目录
NLP概述
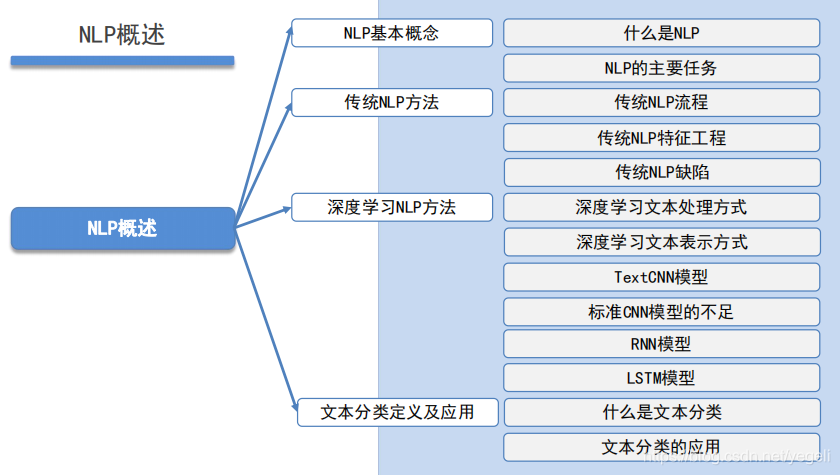
NLP基本概念
什么是NLP


NLP的主要任务




传统NLP方法
传统NLP流程

传统NLP特征工程



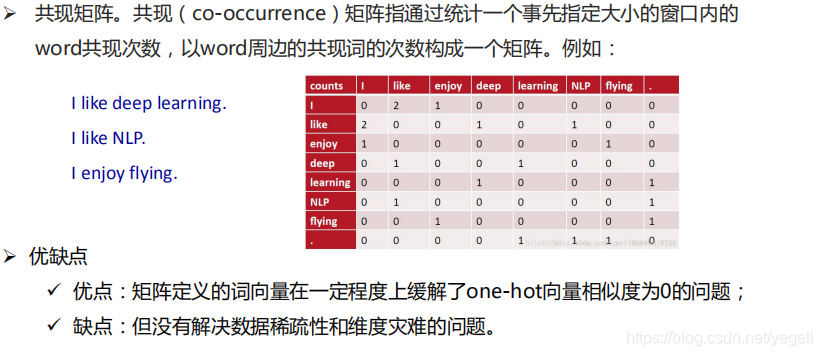

传统NLP缺陷

深度学习NLP方法
深度学习文本处理方式

深度学习文本表示方式


TextCNN模型

标准CNN模型的不足

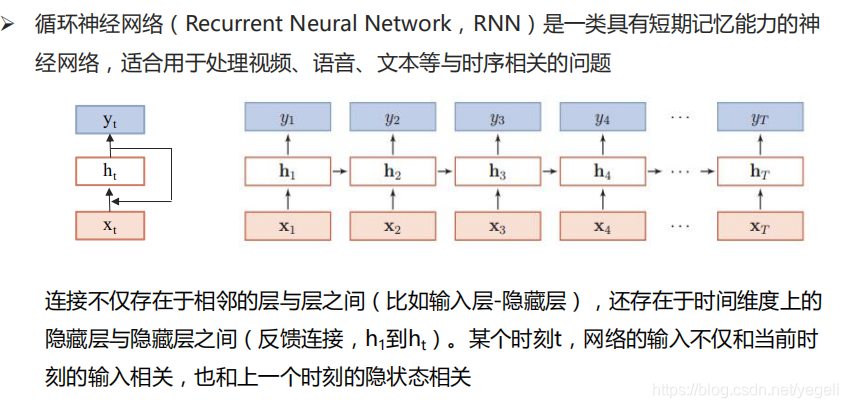
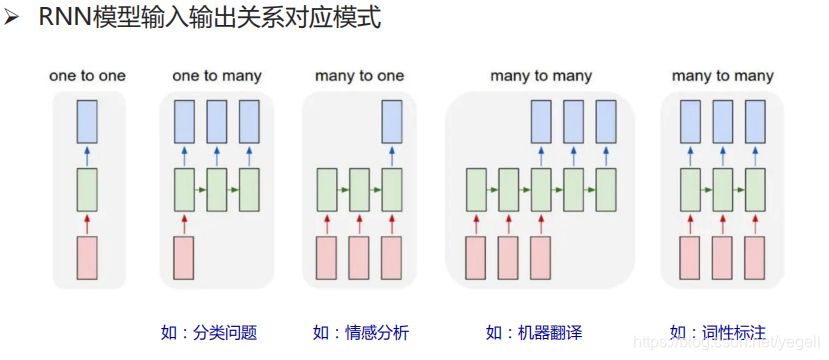
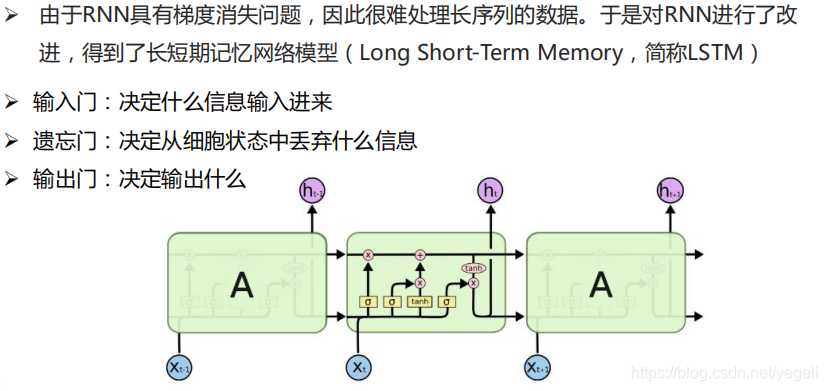
RNN模型


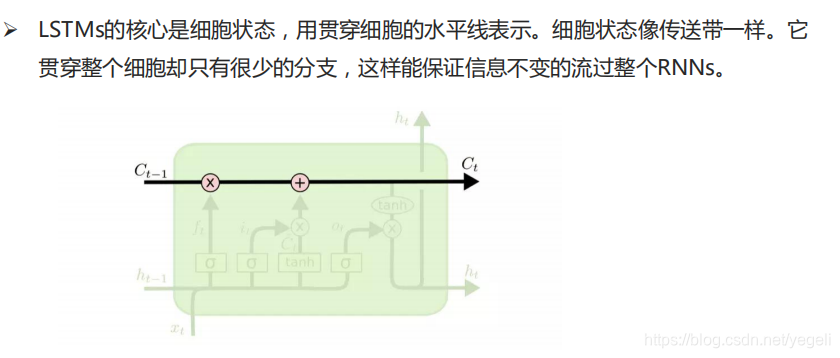
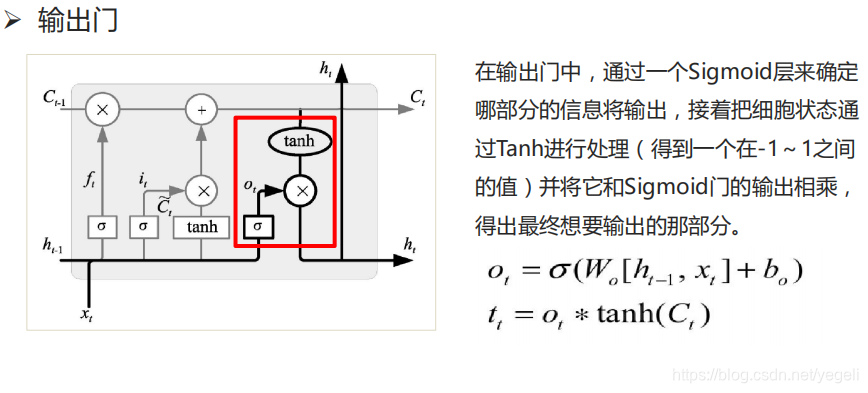
LSTM模型



文本分类定义及应用
什么是文本分类

文本分类的应用

TextCNN实现文本分类
思路及实现
案例目标

数据集介绍
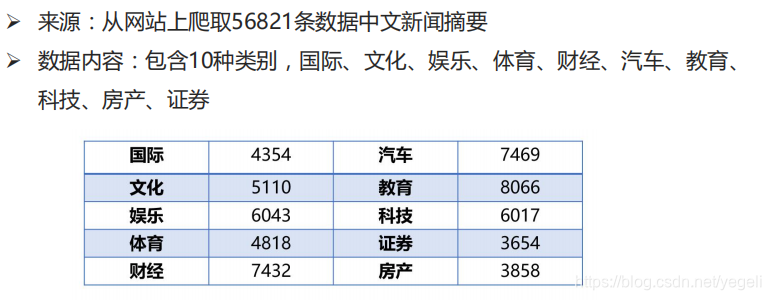
原始数据格式

网络模型介绍
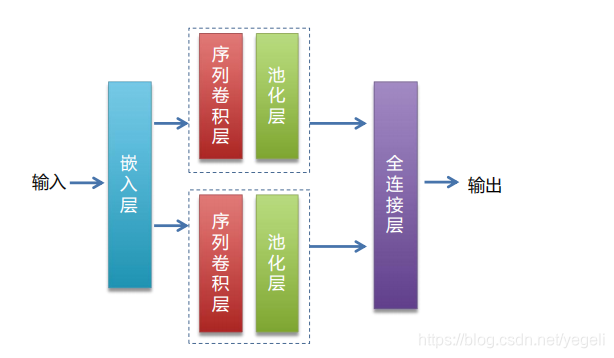
总体步骤

数据预处理
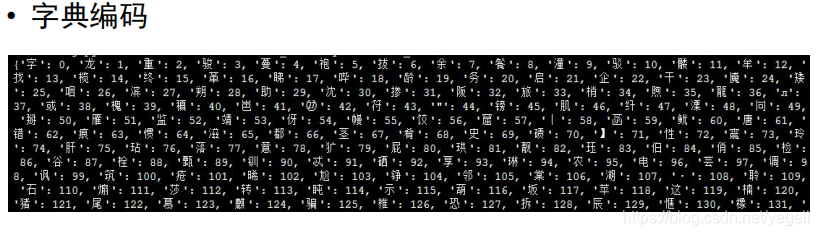
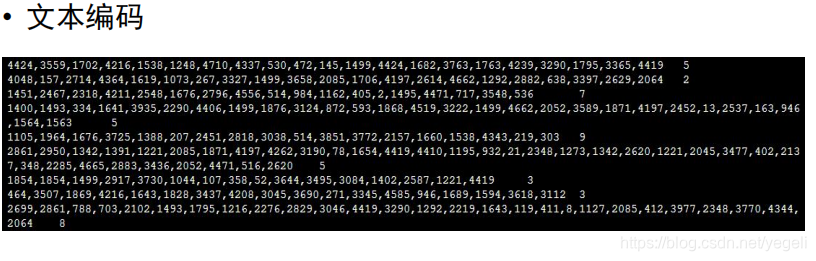
关键代码







训练过程
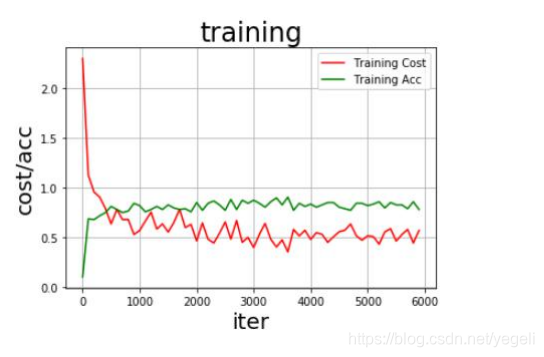
测试结果

代码
AI Studio-百度:中文资讯分类
1.数据预处理
# 中文资讯分类示例
# 任务:根据样本,训练模型,将新的文本划分到正确的类别
'''
数据来源:从网站上爬取56821条中文新闻摘要
数据类容:包含10类(国际、文化、娱乐、体育、财经、汽车、教育、科技、房产、证券)
'''
############################## 数据预处理 ##############################
import os
from multiprocessing import cpu_count
import numpy as np
import paddle
import paddle.fluid as fluid
# 定义公共变量
data_root = "data/news_classify/" # 数据集所在目录
data_file = "news_classify_data.txt" # 原始样本文件名
test_file = "test_list.txt" # 测试集文件名称
train_file = "train_list.txt" # 训练集文件名称
dict_file = "dict_txt.txt" # 编码后的字典文件
data_file_path = data_root + data_file # 样本文件完整路径
dict_file_path = data_root + dict_file # 字典文件完整路径
test_file_path = data_root + test_file # 测试集文件完整路径
train_file_path = data_root + train_file # 训练集文件完整路径
# 生成字典文件:把每个字编码成一个数字,并存入文件中
def create_dict():
dict_set = set() # 集合,去重
with open(data_file_path, "r", encoding="utf-8") as f: # 打开原始样本文件
lines = f.readlines() # 读取所有的行
# 遍历每行
for line in lines:
title = line.split("_!_")[-1].replace("\n", "") #取出标题部分,并取出换行符
for w in title: # 取出标题部分每个字
dict_set.add(w) # 将每个字存入集合进行去重
# 遍历集合,每个字分配一个编码
dict_list = []
i = 0 # 计数器
for s in dict_set:
dict_list.append([s, i]) # 将"文字,编码"键值对添加到列表中
i += 1
dict_txt = dict(dict_list) # 将列表转换为字典
end_dict = {
"<unk>": i} # 未知字符
dict_txt.update(end_dict) # 将未知字符编码添加到字典中
# 将字典保存到文件中
with open(dict_file_path, "w", encoding="utf-8") as f:
f.write(str(dict_txt)) # 将字典转换为字符串并存入文件
print("生成字典完成.")
# 对一行标题进行编码
def line_encoding(title, dict_txt, label):
new_line = "" # 返回的结果
for w in title:
if w in dict_txt: # 如果字已经在字典中
code = str(dict_txt[w]) # 取出对应的编码
else:
code = str(dict_txt["<unk>"]) # 取未知字符的编码
new_line = new_line + code + "," # 将编码追加到新的字符串后
new_line = new_line[:-1] # 去掉最后一个逗号
new_line = new_line + "\t" + label + "\n" # 拼接成一行,标题和标签用\t分隔
return new_line
# 对原始样本进行编码,对每个标题的每个字使用字典中编码的整数进行替换
# 产生编码后的句子,并且存入测试集、训练集
def create_data_list():
# 清空测试集、训练集文件
with open(test_file_path, "w") as f:
pass
with open(train_file_path, "w") as f:
pass
# 打开原始样本文件,取出标题部分,对标题进行编码
with open(dict_file_path, "r", encoding="utf-8") as f_dict:
# 读取字典文件中的第一行(只有一行),通过调用eval函数转换为字典对象
dict_txt = eval(f_dict.readlines()[0])
with open(data_file_path, "r", encoding="utf-8") as f_data:
lines = f_data.readlines()
# 取出标题并编码
i = 0
for line in lines:
words = line.replace("\n", "").split("_!_") # 拆分每行
label = words[1] # 分类
title = words[3] # 标题
new_line = line_encoding(title, dict_txt, label) # 对标题进行编码
if i % 10 == 0: # 每10笔写一笔测试集文件
with open(test_file_path, "a", encoding="utf-8") as f:
f.write(new_line)
else: # 写入训练集
with open(train_file_path, "a", encoding="utf-8") as f:
f.write(new_line)
i += 1
print("生成测试集、训练集结束.")
create_dict() # 生成字典
create_data_list() # 生成训练集、测试集
2.模型训练与评估
# 读取字典文件,并返回字典长度
def get_dict_len(dict_path):
with open(dict_path, "r", encoding="utf-8") as f:
line = eval(f.readlines()[0]) # 读取字典文件内容,并返回一个字典对象
return len(line.keys())
# 定义data_mapper,将reader读取的数据进行二次处理
# 将传入的字符串转换为整型并返回
def data_mapper(sample):
data, label = sample # 将sample元组拆分到两个变量
# 拆分句子,将每个编码转换为数字, 并存入一个列表中
val = [int(w) for w in data.split(",")]
return val, int(label) # 返回整数列表,标签(转换成整数)
# 定义reader
def train_reader(train_file_path):
def reader():
with open(train_file_path, "r") as f:
lines = f.readlines() # 读取所有的行
np.random.shuffle(lines) # 打乱所有样本
for line in lines:
data, label = line.split("\t") # 拆分样本到两个变量中
yield data, label
return paddle.reader.xmap_readers(data_mapper, # reader读取的数据进行下一步处理函数
reader, # 读取样本的reader
cpu_count(), # 线程数
1024) # 缓冲区大小
# 读取测试集reader
def test_reader(test_file_path):
def reader():
with open(test_file_path, "r") as f:
lines = f.readlines()
for line in lines:
data, label = line.split("\t")
yield data, label
return paddle.reader.xmap_readers(data_mapper,
reader,
cpu_count(),
1024)
# 定义网络
def CNN_net(data, dict_dim, class_dim=10, emb_dim=128, hid_dim=128, hid_dim2=98):
# embedding(词嵌入层):生成词向量,得到一个新的粘稠的实向量
# 以使用较少的维度,表达更丰富的信息
emb = fluid.layers.embedding(input=data, size=[dict_dim, emb_dim])
# 并列两个卷积、池化层
conv1 = fluid.nets.sequence_conv_pool(input=emb, # 输入,上一个词嵌入层的输出作为输入
num_filters=hid_dim, # 卷积核数量
filter_size=3, # 卷积核大小
act="tanh", # 激活函数
pool_type="sqrt") # 池化类型
conv2 = fluid.nets.sequence_conv_pool(input=emb, # 输入,上一个词嵌入层的输出作为输入
num_filters=hid_dim2, # 卷积核数量
filter_size=4, # 卷积核大小
act="tanh", # 激活函数
pool_type="sqrt") # 池化类型
output = fluid.layers.fc(input=[conv1, conv2], # 输入
size=class_dim, # 输出类别数量
act="softmax") # 激活函数
return output
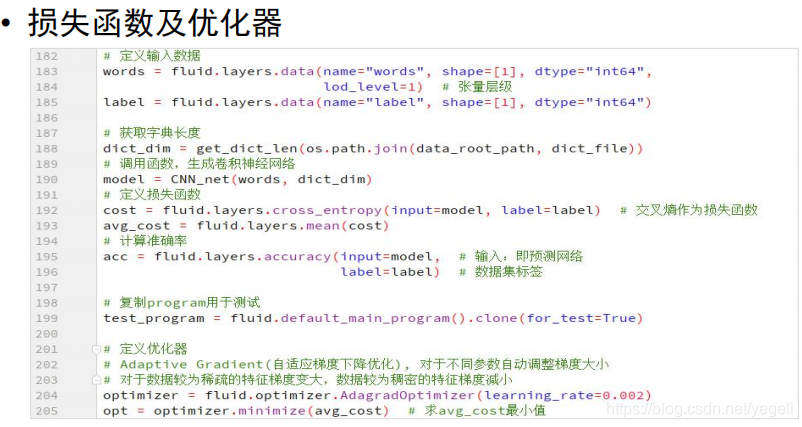
# 定义模型、训练、评估、保存
model_save_dir = "model/news_classify/" # 模型保存路径
words = fluid.layers.data(name="words", shape=[1], dtype="int64",
lod_level=1) # 张量层级
label = fluid.layers.data(name="label", shape=[1], dtype="int64")
# 获取字典长度
dict_dim = get_dict_len(dict_file_path)
# 调用函数创建CNN
model = CNN_net(words, dict_dim)
# 定义损失函数
cost = fluid.layers.cross_entropy(input=model, # 预测结果
label=label) # 真实结果
avg_cost = fluid.layers.mean(cost) # 求损失函数均值
# 准确率
acc = fluid.layers.accuracy(input=model, # 预测结果
label=label) # 真实结果
# 克隆program用于模型测试评估
# for_test如果为True,会少一些优化
test_program = fluid.default_main_program().clone(for_test=True)
# 定义优化器
optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.001)
optimizer.minimize(avg_cost)
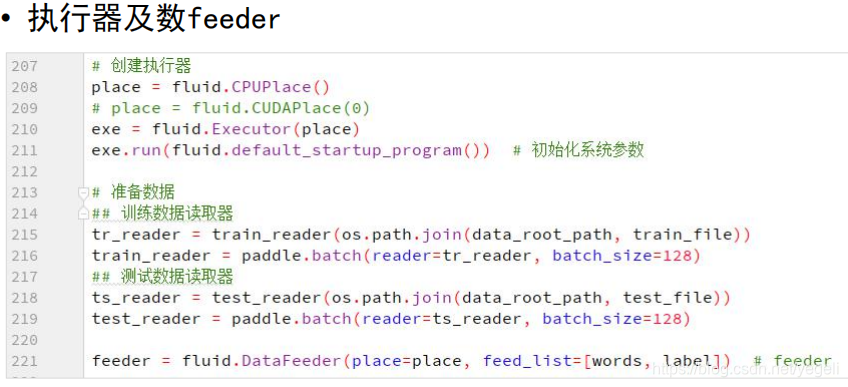
# 定义执行器
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
# 准备数据
tr_reader = train_reader(train_file_path)
batch_train_reader = paddle.batch(reader=tr_reader, batch_size=128)
ts_reader = test_reader(test_file_path)
batch_test_reader = paddle.batch(reader=ts_reader, batch_size=128)
feeder = fluid.DataFeeder(place=place, feed_list=[words, label]) # feeder
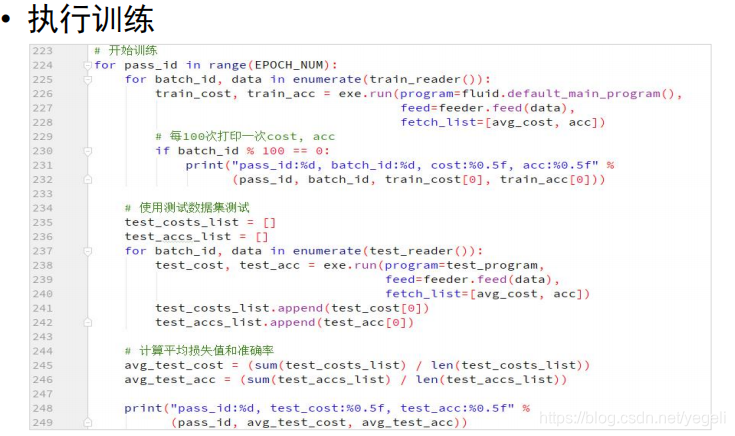
# 开始训练
for pass_id in range(20):
for batch_id, data in enumerate(batch_train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data), # 喂入数据
fetch_list=[avg_cost, acc]) # 要获取的结果
# 打印
if batch_id % 100 == 0:
print("pass_id:%d, batch_id:%d, cost:%f, acc:%f" %
(pass_id, batch_id, train_cost[0], train_acc[0]))
# 每轮次训练完成后,进行模型评估
test_costs_list = [] # 存放所有的损失值
test_accs_list = [] # 存放准确率
for batch_id, data in enumerate(batch_test_reader()): # 读取一个批次测试数据
test_cost, test_acc = exe.run(program=test_program, # 执行test_program
feed=feeder.feed(data), # 喂入测试数据
fetch_list=[avg_cost, acc]) # 要获取的结果
test_costs_list.append(test_cost[0]) # 记录损失值
test_accs_list.append(test_acc[0]) # 记录准确率
# 计算平均准确率和损失值
avg_test_cost = sum(test_costs_list) / len(test_costs_list)
avg_test_acc = sum(test_accs_list) / len(test_accs_list)
print("pass_id:%d, test_cost:%f, test_acc:%f" %
(pass_id, avg_test_cost, avg_test_acc))
# 保存模型
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir, # 模型保存路径
feeded_var_names=[words.name], # 使用模型时需传入的参数
target_vars=[model], # 预测结果
executor=exe) # 执行器
print("模型保存完成.")
3.预测
model_save_dir = "model/news_classify/"
def get_data(sentence):
# 读取字典中的内容
with open(dict_file_path, "r", encoding="utf-8") as f:
dict_txt = eval(f.readlines()[0])
keys = dict_txt.keys()
ret = [] # 编码结果
for s in sentence: # 遍历句子
if not s in keys: # 字不在字典中,取未知字符
s = "<unk>"
ret.append(int(dict_txt[s]))
return ret
# 创建执行器
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
print("加载模型")
infer_program, feeded_var_names, target_var = \
fluid.io.load_inference_model(dirname=model_save_dir, executor=exe)
# 生成测试数据
texts = []
data1 = get_data("在获得诺贝尔文学奖7年之后,莫言15日晚间在山西汾阳贾家庄如是说")
data2 = get_data("综合'今日美国'、《世界日报》等当地媒体报道,芝加哥河滨警察局表示")
data3 = get_data("中国队无缘2020年世界杯")
data4 = get_data("中国人民银行今日发布通知,降低准备金率,预计释放4000亿流动性")
data5 = get_data("10月20日,第六届世界互联网大会正式开幕")
data6 = get_data("同一户型,为什么高层比低层要贵那么多?")
data7 = get_data("揭秘A股周涨5%资金动向:追捧2类股,抛售600亿香饽饽")
data8 = get_data("宋慧乔陷入感染危机,前夫宋仲基不戴口罩露面,身处国外神态轻松")
data9 = get_data("此盆栽花很好养,花美似牡丹,三季开花,南北都能养,很值得栽培")#不属于任何一个类别
texts.append(data1)
texts.append(data2)
texts.append(data3)
texts.append(data4)
texts.append(data5)
texts.append(data6)
texts.append(data7)
texts.append(data8)
texts.append(data9)
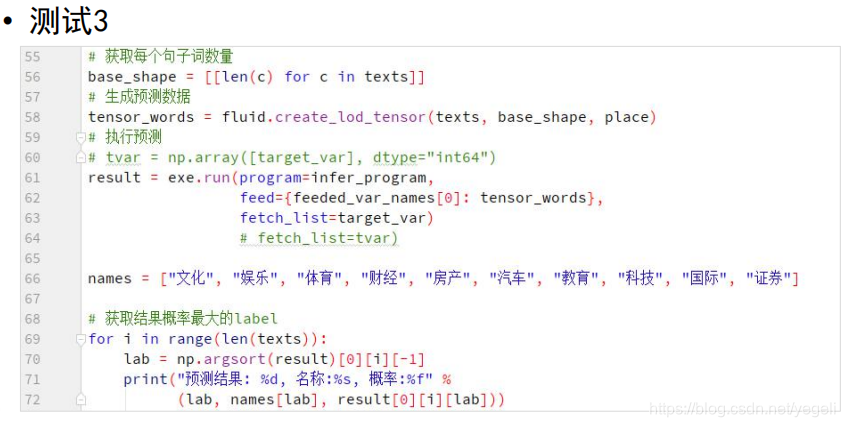
# 获取每个句子词数量
base_shape = [[len(c) for c in texts]]
# 生成数据
tensor_words = fluid.create_lod_tensor(texts, base_shape, place)
# 执行预测
result = exe.run(program=infer_program,
feed={feeded_var_names[0]: tensor_words}, # 待预测的数据
fetch_list=target_var)
# print(result)
names = ["文化", "娱乐", "体育", "财经", "房产", "汽车", "教育", "科技", "国际", "证券"]
# 获取最大值的索引
for i in range(len(texts)):
lab = np.argsort(result)[0][i][-1] # 取出最大值的元素下标
print("预测结果:%d, 名称:%s, 概率:%f" % (lab, names[lab], result[0][i][lab]))
智能推荐
qiime安装_qiime1安装包下载-程序员宅基地
文章浏览阅读1.5k次。参考网址:https://forum.qiime2.org/t/qiime2-chinese-manual/838http://qiime.org/install/install.html 安装好qiime后,脚本的运行必须在qiime环境下输入:source activate qiime1 ..._qiime1安装包下载
全网首发 | Mac版 PS2022 终于来了,支持M1芯片,五大新黑科技_ps2022macair能使用吗-程序员宅基地
文章浏览阅读850次。相信win系统的小伙伴都用了几个月的Photoshop 2022版了吧!但Mac端的学习版一直没来,很多Mac用户都直接转正版去了!用Mac的小伙伴应该都在担忧adobe 2022 国外大神还破解不,毕竟win端都已经用了好几个月了,不过该来的还是会来的。昨日,国外大神终于就带来了Mac版Photoshop 2022,现在使用Mac的小伙伴也可以一直体验了。Mac版Photoshop 2022Photoshop 2022这款神级软件可谓是人尽皆知了 ,相信大家都不陌生,是图像..._ps2022macair能使用吗
antd日期选择框中文(国际化)设置_antd日期选择框国际化-程序员宅基地
文章浏览阅读1w次。使用antd这个UI组件确实很好用,但是他属于面向国际的,所以在一些特定的组件需要使用国际化文字上的转变;可以看到提示的文字都是英文,包括鼠标停留事件也是英文的,那么在你的代码中这么写就可以了import React from 'react';import {DatePicker } from 'antd';//引入国际化设置(中文)import locale from 'antd/l..._antd日期选择框国际化
2024-02-14 串行\并行 通信 work-程序员宅基地
文章浏览阅读96次。1. 总结串行通信,并行通信,波特率,全双工,半双工,单工等通信概念。
论文解读:D-LinkNet :LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satelli-程序员宅基地
文章浏览阅读6.3k次,点赞5次,收藏51次。参考链接:北邮夺冠CVPR 2018 DeepGlobe比赛,他们是这样做卫星图像识别的论文链接:D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road ExtractionGithub地址 Python2.7 pytorc..._d-linknet
python通信工程定额_版 通信工程费用及定额套用解读-程序员宅基地
文章浏览阅读605次。通信工程费用定额套用解读一、通信工程总费用构成及内容:是按建设部财政部建标[2003]206号文件的规定做了调整。单项工程总费用由工程费、工程建设其它费、预备费和建设期利息组成。其中:*工程费由建筑安装工程费和设备、工器具购置费组成。*建筑安装工程费由直接费、间接费、利润和税金组成。*直接费由直接工程费和措施费组成。二、建筑安装工程费(见附件一)1、直接工程费:指施工过程中耗用的构成工程实体和有助..._通信工程定额的组成
随便推点
QT简介及QT环境搭建-程序员宅基地
文章浏览阅读2k次。QT简介及QT环境搭建文章目录QT简介及QT环境搭建一、QT简介1. 什么是QT?2. QT的发展史3. QT支持的平台4. QT的优点5. QT开发工具二、QT环境搭建(CentOS7)一、QT简介1. 什么是QT?Qt是一个1991年由Qt Company开发的跨平台C++图形用户界面应用程序开发框架 它既可以开发GUI程序,也可用于开发非GUI程序,比如控制台工具和服务器。Qt是面向..._qt环境
win10 设置任务栏时钟显示到秒_win10任务栏显示秒数-程序员宅基地
文章浏览阅读188次。win10 设置任务栏时钟显示到秒_win10任务栏显示秒数
.NET系统框架-程序员宅基地
文章浏览阅读124次。本书是一本讲解.NET技术的书籍,目标读者群也是在.NET框架(.NET Framework)下进行开发的程序员,因此我们无法回避的问题就是:什么是.NET框架?它包含了哪些内容?为开发程序提供了哪些支持?很多朋友对这类个问题的第一反应可能是.NET框架所提供的庞大类库及编写代码所采用的C#语言,实际上远不止这些。要描述.NET框架,自然会遇到与其相关的一系列专业的技术术语和缩写,相信大家已经..._目标框架 目标操作系统版本
基于单链表、环形队列(并发有锁)的多线程生产者消费者模型_并发环状加锁-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏11次。在这之前的我已经介绍过生产者消费者模型,不懂的可以下跳地址: http://blog.csdn.net/quinn0918/article/details/728259921、环形缓冲区缓冲区的好处,就是空间换时间和协调快慢线程。缓冲区可以用很多设计法,这里说一下环形缓冲区的几种设计方案,可以看成是几种环形缓冲区的模式。设计环形缓冲区涉及到几个点,一是超出缓冲区大小的的索引如何处理,二是如何表示缓_并发环状加锁
别光看世界杯 7月还有一场音视频技术盛宴等着你-程序员宅基地
文章浏览阅读226次。在全世界球迷的瞩目下,2018世界杯在上周激情上演,相信接下来的一个月时间里无数球迷又将守在电视前为自己喜欢的球队摇旗呐喊。当然,在移动互联网发达的今天,即使不在电视前,..._移动咪咕 张云天
PyQt5 —— 控件_pyqt5上传控件-程序员宅基地
文章浏览阅读257次。由于最近在学习pyqt5的相关知识,在网上找了几篇教程看,于是就写了这篇学习笔记。本文只是一些案例的代码以及演示,详细的讲解请看原文。原文链接:https://zetcode.com/gui/pyqt5/中文翻译:http://www.360doc.com/content/19/1022/14/12906439_868371487.shtml文章目录1、QCheckBox2、切换按钮3、滑块4、进度条5、日历6、图片7、行编辑8、QSplitter9、下拉选框1、QCheckBoxQCheck._pyqt5上传控件