Java:爬虫htmlunit_htmlunit java-程序员宅基地
为什么htmlunit与HttpClient两者都可以爬虫、网页采集、通过网页自动写入数据,我们会推荐使用htmlunit呢?
一、网页的模拟化
首先说说HtmlUnit相对于HttpClient的最明显的一个好处,HtmlUnit更好的将一个网页封装成了一个对象,如果你非要说HttpClient返回的接口HttpResponse实际上也是存储了一个对象那也可以,但是HtmlUnit不仅保存了这个网页对象,更难能可贵的是它还存有这个网页的所有基本操作甚至事件。这就是说,我们对于操作这个网页可以像在jsp中写js一样,这是非常方便的,比如:你想某个节点的上一个节点,查找所有的按钮,查找样式为“bt-style”的所有元素,对于某些元素先进行一些改造,然后再转成String,或者我直接得到这个网页之后操作这个网页,完成一次提交都是非常方便的。这意味着你如果想分析一个网页会来的非常的容易
二、网络响应的自动化处理
HtmlUnit拥有强大的响应处理机制,我们知道:常见的404是找不到资源,100等是继续,300等是跳转...我们在使用HttpClient的时候它会把响应结果告诉我们,当然,你可以自己来判断,比如说,你发现响应码是302的时候,你就在响应头去找到新的地址并自动再跳过去,发现是100的时候就再发一次请求,你如果使用HttpClient,你可以这么去做,也可以写的比较完善,但是,HtmlUnit已经较为完整的实现了这一功能,甚至说,他还包括了页面JS的自动跳转(响应码是200,但是响应的页面就是一个JS)
三、并行控制 和串行控制
既然HtmlUnit封装了那么多的底层api和hHttpClient操作,那么它有没有给我们提供自定义各种响应策略和监听整个执行过程的方法呢?,答案是肯定的。由于HtmlUnit提供的监听和控制方法比较多,我说几个大家可能接触比较少,但很有用的方法。其他的类似于:设置CSS有效,设置不抛出JS异常,设置使用SSL安全链接,诸如此类,大家通过webClient.getOptions().set***,就可以设置了,这种大家都比较熟了。
四、强大的缓存机制
为什么第一次获取一个网页可能会比较慢,但是第二次来拿就特别快呢?在HtmlUnit源码webClient类中的loadWebResponseFromWebConnection方法中我们可以看到。
以下简单介绍下如何去分析网页及涉及的代码:
其中url可以直接浏览器访问地址直接解析页面,也可以通过分析页面请求接口(开启google浏览器F12开发者模式,刷新对应页面即可查看请求数据地址 -- >> 具体数据需要通过分享查看)
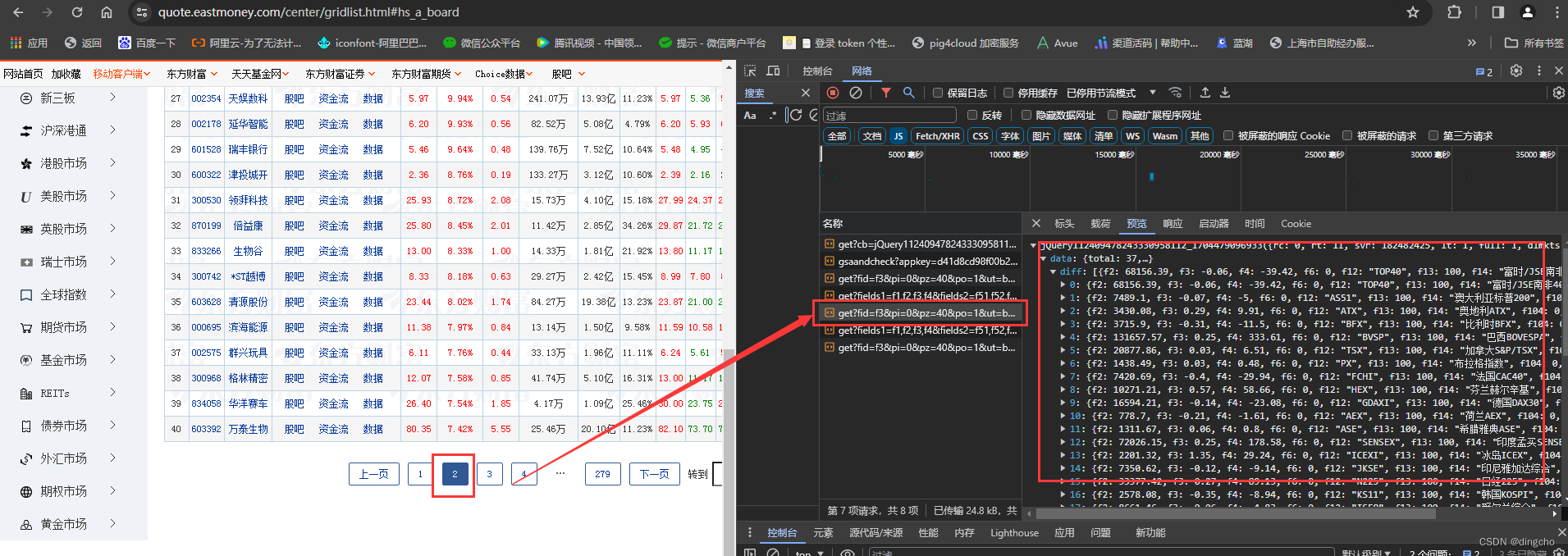 引入maven包:
引入maven包:
<htmlunit.version>2.70.0</htmlunit.version>
<junit.version>4.13.2</junit.version>
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>${htmlunit.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>@Slf4j
public class ThreadLocalClientFactory {
//单例工厂模式
private final static ThreadLocalClientFactory instance = new ThreadLocalClientFactory();
//线程的本地实例存储器,用于存储WebClient实例
private ThreadLocal<WebClient> clientThreadLocal;
public ThreadLocalClientFactory() {
clientThreadLocal = new ThreadLocal<>();
}
/**
* 获取工厂实例
*
* @return 工厂实例
*/
public static ThreadLocalClientFactory getInstance() {
return instance;
}
public WebClient crawlPageApi() {
WebClient webClient;
/**
* 如果当前线程已有WebClient实例,则直接返回该实例
* 否则重新创建一个WebClient实例并存储于当前线程的本地变量存储器
*/
if ((webClient = clientThreadLocal.get()) == null) {
webClient = new WebClient(BrowserVersion.CHROME);
clientThreadLocal.set(webClient);
log.info("为线程 [ " + Thread.currentThread().getName() + " ] 创建新的WebClient实例!");
} else {
log.info("线程 [ " + Thread.currentThread().getName() + " ] 已有WebClient实例,直接使用. . .");
}
return webClient;
}
/**
* 获取一个模拟FireFox3.6版本的WebClient实例
*
* @return 模拟FireFox3.6版本的WebClient实例
*/
public WebClient crawlPageWithAnalyseJs() {
WebClient webClient;
/**
* 如果当前线程已有WebClient实例,则直接返回该实例
* 否则重新创建一个WebClient实例并存储于当前线程的本地变量存储器
*/
if ((webClient = clientThreadLocal.get()) == null) {
webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); //需要解析js
webClient.getOptions().setThrowExceptionOnScriptError(false); //解析js出错时不抛异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(1000);
clientThreadLocal.set(webClient);
log.info("为线程 [ " + Thread.currentThread().getName() + " ] 创建新的WebClient实例!");
} else {
log.info("线程 [ " + Thread.currentThread().getName() + " ] 已有WebClient实例,直接使用. . .");
}
return webClient;
}
public WebClient crawlPageWithoutAnalyseJs(){
WebClient webClient;
/**
* 如果当前线程已有WebClient实例,则直接返回该实例
* 否则重新创建一个WebClient实例并存储于当前线程的本地变量存储器
*/
if ((webClient = clientThreadLocal.get()) == null) {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setTimeout(20000);
webClient.setJavaScriptErrorListener(new MyJSErrorListener());
webClient.setJavaScriptTimeout(5000);
clientThreadLocal.set(webClient);
log.info("为线程 [ " + Thread.currentThread().getName() + " ] 创建新的WebClient实例!");
} else {
log.info("线程 [ " + Thread.currentThread().getName() + " ] 已有WebClient实例,直接使用. . .");
}
return webClient;
}
}
有时候抓取某些网站即使设置webClient.getOptions().setThrowExceptionOnScriptError(false);
也不能关闭提示信息导致每次访问网页都会打印一大串无用信息,但是我们并不关心js报错问题,只关心拿下来页面的结果。
所以我们可以针对【DefaultJavaScriptErrorListener 】重写它里面的方法,把所有log输出语句全部删除,就可以不打印错误信息了
public class MyJSErrorListener extends DefaultJavaScriptErrorListener {
@Override
public void scriptException(HtmlPage page, ScriptException scriptException) {
}
@Override
public void timeoutError(HtmlPage page, long allowedTime, long executionTime) {
}
@Override
public void malformedScriptURL(HtmlPage page, String url, MalformedURLException malformedURLException) {
}
@Override
public void loadScriptError(HtmlPage page, URL scriptUrl, Exception exception) {
}
@Override
public void warn(String message, String sourceName, int line, String lineSource, int lineOffset) {
}
}
@Slf4j
public class SpiderUtils {
/**
* 获取http请求
*
* @param url
* @return
* @throws Exception
*/
public static String crawlPageApi(String url) throws Exception {
// WebClient webClient = PooledClientFactory.getInstance().getClient();
WebClient webClient = ThreadLocalClientFactory.getInstance().crawlPageApi();
//抓取网页
Page page = webClient.getPage(url);
//打印当前线程名称及网页标题
log.info(Thread.currentThread().getName() + " [ " + url + " ] : " + page.toString());
WebResponse response = page.getWebResponse();
String json = response.getContentAsString();
log.info(Thread.currentThread().getName() + " [ " + json + " ] : ");
return json;
}
/**
* 功能描述:抓取页面时并解析页面的js
*
* @param url
* @throws Exception
*/
public static HtmlPage crawlPageWithAnalyseJs(String url) throws Exception {
WebClient webClient = ThreadLocalClientFactory.getInstance().crawlPageWithAnalyseJs();
//抓取网页
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(1000);
//打印当前线程名称及网页标题
System.out.println(Thread.currentThread().getName() + " [ " + url + " ] : " + page.getTitleText());
return page;
}
/**
* 功能描述:抓取页面时不解析页面的js
*
* @param url
* @throws Exception
*/
public static HtmlPage crawlPageWithoutAnalyseJs(String url) throws Exception {
WebClient webClient = ThreadLocalClientFactory.getInstance().crawlPageWithAnalyseJs();
//抓取网页
HtmlPage page = webClient.getPage(url);
//打印当前线程名称及网页标题
System.out.println(Thread.currentThread().getName() + " [ " + url + " ] : " + page.getTitleText());
return page;
}
}
目前来说,只是简单运用爬虫爬取抓取对应数据进行分析,具体的爬取规则需要根据实际情况来制定,数据量过大的时候还需要考虑通过读写分离,分库分表来解决效率问题
智能推荐
EBS R12基本概念与应用基础-程序员宅基地
文章浏览阅读1.8k次。摘自: [ORACLE EBS 入门及供应链核心系统详解教程] (书籍)EBS基础功能架构(13个核心模块,业财一体化)业务运营管理,价值增值财务会计管理,价值实现应用架构Finance财务,资金流Accounting财务管理Bisuness业务,实物流核心业务,与财务高度集成;PUR、INV、制造、订单履行等间接业务,or专业业务,为核心业务提供支持;HR..._ebs r12
Java中Date和Timestamp的区别_java date timestamp区别-程序员宅基地
文章浏览阅读838次。转载:https://blog.csdn.net/ccecwg/article/details/39546307_java date timestamp区别
如何用原生js封装一个类似jq的选择器_原声js实现jq元素选择器-程序员宅基地
文章浏览阅读1.4k次。1、我们先了解一下原生js中的选择器ID选择器(在整个文档中获取id为xxx的元素)document.getElementId([ID]);类名选择器(在整个文档中或者在指定上下文中获取类名为xxx的元素)document.getElementsByClassName(' ');[context].getElementsByClassName(' ');标签名选择器(在整个文档中或者..._原声js实现jq元素选择器
Hive中partition by和distribute by区别_partition by distribute by-程序员宅基地
文章浏览阅读1.2k次,点赞3次,收藏4次。通常查询时会对整个数据库查询,而这带来了大量的开销,因此引入了partition的概念,在建表的时候通过设置partition的字段, 会根据该字段对数据分区存放,更具体的说是存放在不同的文件夹,这样通过指定设置Partition的字段条件查询时可以减少大量的开销。1)partition by [key..] order by [key..]只能在窗口函数中使用,而distribute by [key...] sort by [key...]在窗口函数和select中都可以使用。_partition by distribute by
游标(cursor )是什么?_c# cursor-程序员宅基地
文章浏览阅读7.3k次。Private SQL Area A private SQL area holds information about a parsed SQLstatement and other session-specific information for processing. When a serverprocess executes SQL or PL/SQL code, the process_c# cursor
listview使用的一些心得_listview的使用——购物商城实验心得-程序员宅基地
文章浏览阅读616次。近日在用ListView中的一些注意点,和公用代码,整理如下1.ListView.Items.Clear而不是ListView.Clear一般如果ListView是动态填充的,我们在填充之前都会先进行清理。但需要注意一下,我们是清理Items,如果去直接Clear整个ListView,就连原先定义好的列都没有了2.给ListView绑定数据ListView并不能直接_listview的使用——购物商城实验心得
随便推点
java 注解处理器的作用_深入理解Java:注解(Annotation)--注解处理器-程序员宅基地
文章浏览阅读110次。如果没有用来读取注解的方法和工作,那么注解也就不会比注释更有用处了。使用注解的过程中,很重要的一部分就是创建于使用注解处理器。Java SE5扩展了反射机制的API,以帮助程序员快速的构造自定义注解处理器。注解处理器类库(java.lang.reflect.AnnotatedElement):Java使用Annotation接口来代表程序元素前面的注解,该接口是所有Annotation类型的父接口..._java注解处理器作用
全国职业技能大赛高职组(最新职业院校技能大赛_大数据应用开发2023国赛样题解析-模块C:实时数据处理-任务二:实时指标计算)_大数据 国赛 样题-程序员宅基地
文章浏览阅读1.8k次,点赞27次,收藏28次。全国职业技能大赛高职组(最新职业院校技能大赛_大数据应用开发样题解析-模块B:数据采集-任务一:离线数据采集-程序员宅基地。_大数据 国赛 样题
ssm+mysql+微信小程序疫情防控小程序-计算机毕业设计源码73691_ssm+微信小程序-程序员宅基地
文章浏览阅读926次。本系统分为管理员和注册用户两个角色,主要有疫情新闻、疫情案例介绍、健康信息申报、行程信息申报、就医流程介绍、举报、在线留言、用户管理、信息统计等模块。用户需要先注册成为会员,成功登录后,可以查看网站发布的疫情新闻,可以查看疫情相关病例介绍,有助于疫情防范,还可以查看网站发布的重大疫情案例,了解疫情的发展状况,出行时候好做好防护,同时通过网站可以上报健康信息,以及上报行程信息,方便社区了解自己的出行情况;网站还发布了疫情状态下的就医流程,方便大家就医时候做好准备;同时网站还提供了举报功能,如果发现外来人员或_ssm+微信小程序
Linux 操作系统 022-串口/U盘/共享文件夹-程序员宅基地
文章浏览阅读296次,点赞3次,收藏9次。本节关键字:Linux、centos、串口、U盘、共享文件夹本节相关指令:echo、cat、mkdir、mount
解密C++新特性:内联函数、auto和基于范围的for循环-程序员宅基地
文章浏览阅读1.3k次,点赞45次,收藏29次。本篇主题为: 解密C++新特性:内联函数、auto关键字和基于范围的for循环。
上岸整理:2023前端面试题-vue,小程序,js,css_今年的前端面试难不难-程序员宅基地
文章浏览阅读774次,点赞4次,收藏11次。1、浏览器常见的报错信息与含义2、304与204的区别,http缓存,强缓存,协商缓存3、浏览器从输入地址到渲染,经历了什么状态?4、vue的界面渲染,经过哪些过程(生命周期)5、三次握手,四次挥手6、重排与重绘7、用css实现一个三角形8、常见的flex布局,有哪些功能9、用css实现一个水平垂直居中10、null与undefined的区别11、虚拟dom12、深拷贝与浅拷贝13、es6新增的功能15、async await 与promise。_今年的前端面试难不难