few-shot learning 小样本学习---综述_[7] wang y, yao q. few-shot learning: a survey[j].-程序员宅基地
技术标签: few shot learning 深度学习
这里写目录标题
-
基于阿里综述:
小样本学习(Few-shot Learning)综述 (出自阿里巴巴团队2019年4月)
Few-shot learning(少样本学习)入门
一文入门元学习(Meta-Learning)(附代码,MAML具体步骤) -
基于港科大综述:
Few-shot Learning: A Survey YAQING WANG1,2 , QUANMING YAO 2019
样本量极少如何机器学习?Few-Shot Learning概述
从Few-shot Learning再次认识机器学习
IBM-小样本学习(Few-shot Learning)State of the art 方法及论文讲解
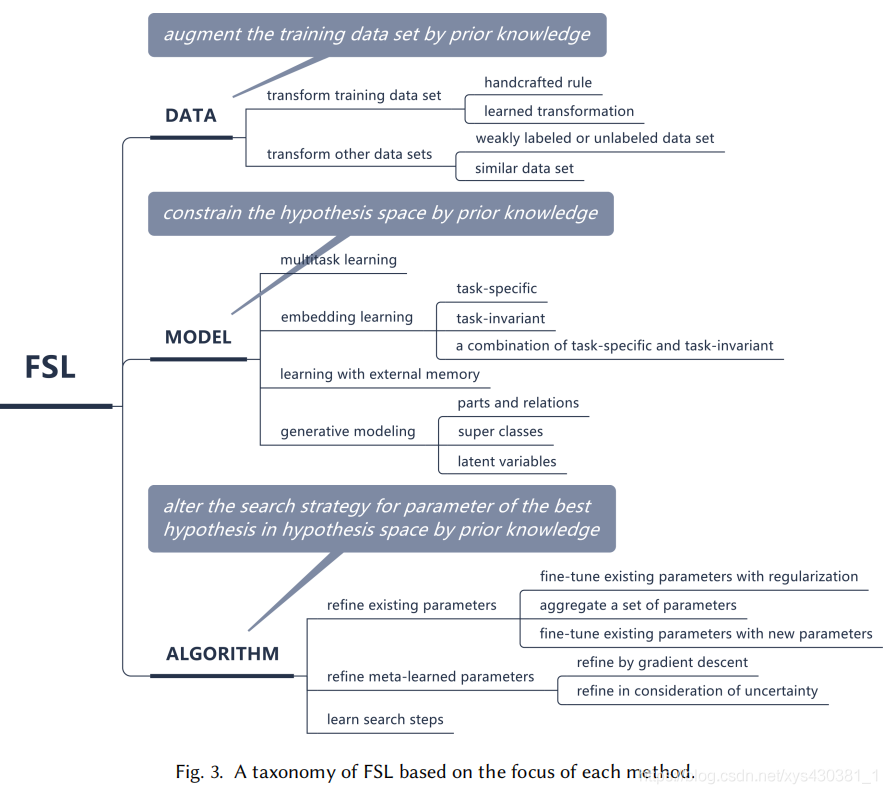
数据增广
FeLMi : Few shot Learning with hard Mixup
we propose Few shot Learning with hard Mixup (FeLMi) using manifold mixup to synthetically generate samples that helps in mitigating the data scarcity issue. Different from a naïve mixup, our approach selects the hard mixup samples using an uncertainty-based criteria.
github源码
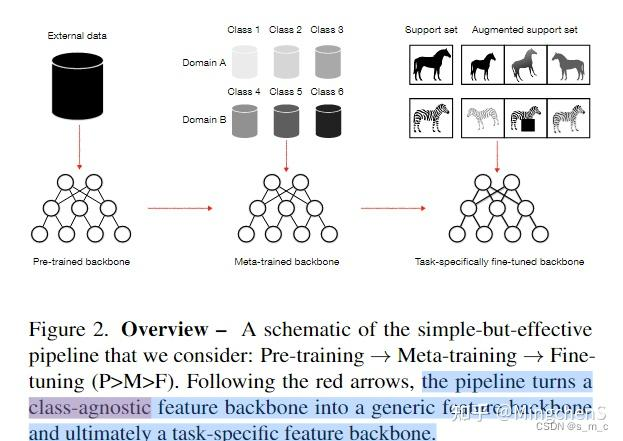
Pushing the Limits of Simple Pipelines for Few-Shot Learning: External Data and Fine-Tuning Make a Difference----CVPR 2022
论文链接
源码
小样本学习可以通过元学习和迁移学习(基于大规模外部数据预训练的自监督模型)来实现。虽然大多数FSL研究人员关注的是前者,但我们表明后者可能更有效,因为它可以使用更强大的骨干网络架构(如VisionTransformer),并且可以与简单的元学习器(如ProtoNet)相结合。
这篇工作提出了: Pre-training → Meta-training → Finetuning (P>M>F) 的小样本学习的新范式,即先在大的数据集上进行与训练,然后再小样本数据集的训练集上进行元训练,最后再在小样本数据集的测试集上利用少量样本进行微调。
同时,作者发现这种徐训练方式对小样本任务是非常奏效的,达到了sota(现在的 paper with code的排行榜依然是第一名)。
最重要的是,本文的代码尝试了十几种不同的 backbone 以及 多种不同的小样本数据集(包括单域和跨域)
自监督/弱监督
Unsupervised Few-shot Learning via Distribution Shift-based Augmentation
在ULDA中,我们系统地研究了不同增强技术的影响,并建议通过分别增强这两个集合(即移位)来加强每个少数样本任务中查询集和支持集之间的分布多样性(或差异)。通过这种方式,即使结合简单的增强技术(例如,随机裁剪、颜色抖动或旋转),我们的 ULDA 也可以产生显着的改进。
github源码
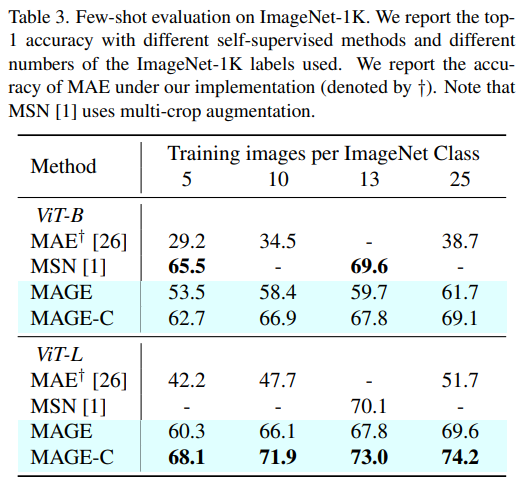
MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis—CVPR 2023
论文链接
源码
The premise of self-supervised learning is to learn representations on unlabeled data that can be effectively applied to prediction tasks with few labels [10]. Following [19], we freeze the weights of the pretrained model and train a linear classifier on top using a few labeled samples.
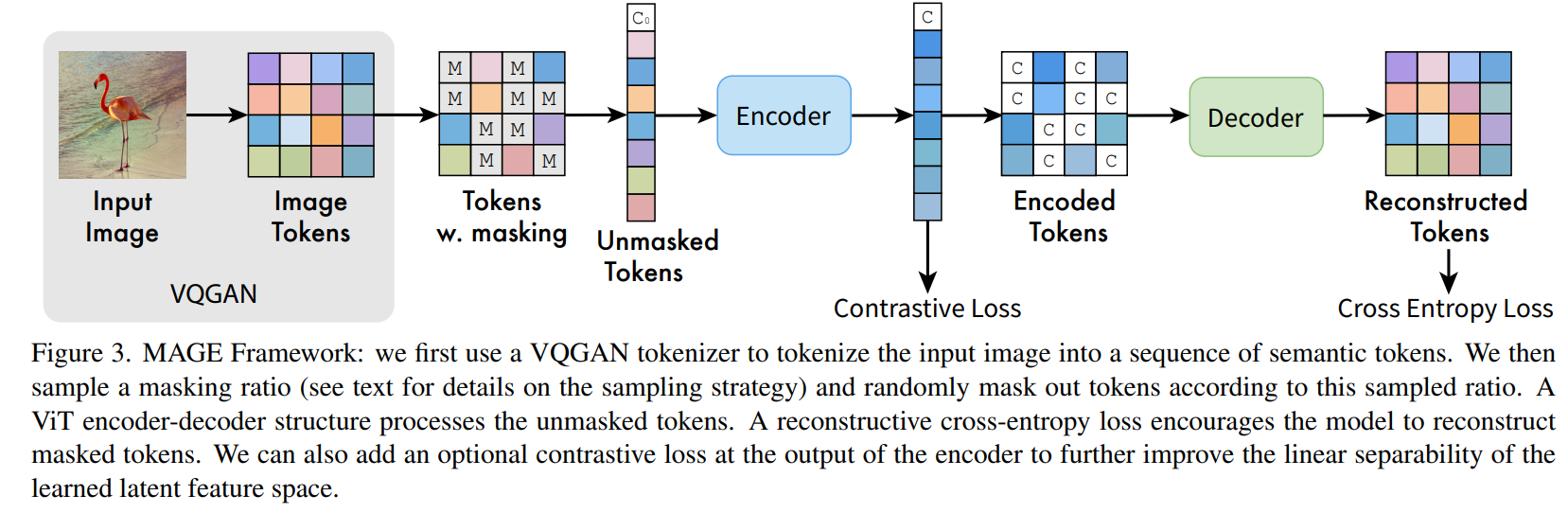

- VQGAN的作用与用法
—在整个代码中,VQGAN无需训练,都是加载已经预训练好的模型参数。
—根据源码的理解,在预训练时,利用了VQGAN的encoder对原始图像进行语义编码得到语义令牌,然后作为transformer的输入;而在transformer输出的是经变换后的语义令牌,所以在transformer之后还需要接入VQGAN的decoder,将语义令牌恢复成图像。
—预训练之后,如果用于生成任务,则还是需要在transformer之后继续使用VQGAN的decoder(只是利用预训练好的参数,无需训练),以将语义令牌恢复出图像。
—预训练之后,如果用于分类任务,则不再需要在在transformer之后继续使用VQGAN的decoder,而是在transformer之后直接接入基于MLP的分类头,进行微调训练之后即可用于推理。(因为可以直接利用transformer产生的语义令牌来进行分类)
模型
多任务学习
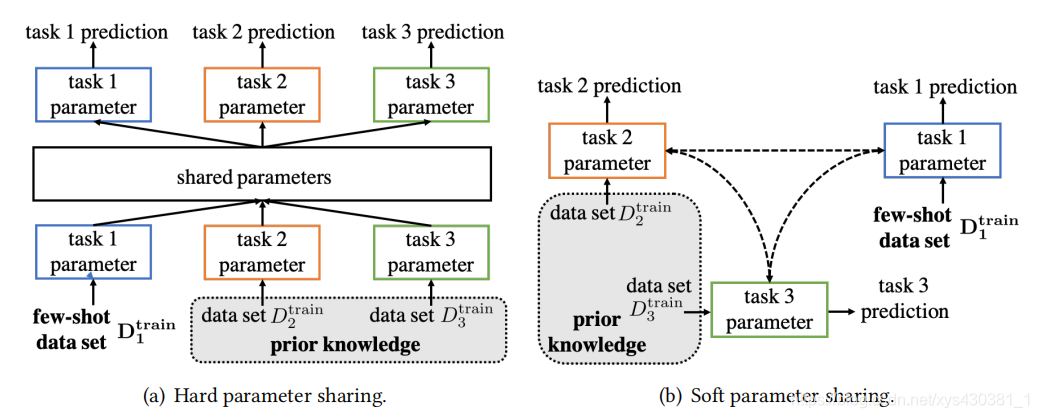
多任务学习用于few-shot的办法是:将其它数据集上训练好的参数,共享给小数据集。
Hard Parameter Sharing. This strategy explicitly shares parameter among tasks , and can additionally learn a task-specific parameter for each task to account for task specialties.
In [ Fine-grained visual categorization using meta-learning optimization with sample selection of auxiliary data], this is done by sharing the first several layers of two networks to learn the generic information, while learning a different last layer to deal with different output for each task
附录:相关论文及代码
[NIPS 2018 论文笔记] Stacked Semantics-Guided Attention Model for Fine-Grained Zero-Shot Learning
论文地址 代码地址
NIPS 2018:Zero-Shot Transfer with Deictic Object-Oriented Representation in Reinforcement Learning
NIPS 2018:Uncertainty-Aware Few-Shot Learning with Probabilistic Model-Agnostic Meta-Learning
NIPS 2018:Multitask Reinforcement Learning for Zero-shot Generalization with Subtask Dependencies
NIPS 2018:Stacked Semantics-Guided Attention Model for Fine-Grained Zero-Shot Learning
NIPS 2018:Delta-encoder: an effective sample synthesis method for few-shot object recognition
NIPS 2018:MetaGAN: An Adversarial Approach to Few-Shot Learning
NIPS 2018:One-Shot Unsupervised Cross Domain Translation
NIPS 2018:Generalized Zero-Shot Learning with Deep Calibration Network
NIPS 2018:Low-shot Learning via Covariance-Preserving Adversarial Augmentation Network
NIPS 2018:Improved few-shot learning with task conditioning and metric scaling
NIPS 2018:Adapted Deep Embeddings: A Synthesis of Methods for k-Shot Inductive Transfer Learning
ECCV2018:Y. Zhang, H. Tang, and K. Jia. 2018. Fine-grained visual categorization using meta-learning optimization with sample selection of auxiliary data.
基于度量的小样本学习
Prototype Completion with Primitive Knowledge for Few-Shot Learning(CVPR2021 源码)
Prototypical networks for few-shot learning
Prototypical networks for few-shot learning
Your Own Few-Shot Classification Model Ready in 15mn with PyTorch
对原型进行矫正的方法
- Prototype Rectification for Few-Shot Learning
缺点:矫正原型时利用了无标签的测试集数据,如果利用的是无标签的非测试集数据就更好了
— 【论文总结】Prototype Rectification for Few-Shot Learning(附翻译)
— 少样本学习新突破!创新奇智入选ECCV 2020 Oral论文
— 小样本学习中的原型修正方法
数据回放
Class-incremental experience replay for continual learning under concept drift(2021,cvpr,有源码,质心驱动的内存可检测概念漂移并保持类buffer中样本多样化)
源码:github.com/lkorycki/rsb
这篇论文的核心内容是关于一种新的持续学习(Continual Learning)方法,这种方法能够在概念漂移(Concept Drift)的情况下处理类增量学习(Class-Incremental Learning)。以下是该论文的主要要点:
问题背景:现代机器学习系统需要能够应对不断变化的数据。持续学习和数据流挖掘是处理这类场景的两个主要研究方向。持续学习关注知识的积累和避免遗忘,而数据流挖掘关注对当前数据状态的适应、检测概念漂移并快速适应变化。
研究假设:类增量持续学习可以有效扩展,同时实现:(i) 通过有效积累新类别的知识来避免灾难性遗忘;(ii) 监控以前学习过的类别的变化,并自动适应概念漂移。
动机:现有的持续学习方法假设一旦学习到的知识就应该被模型记住和存储。然而,由于现代动态数据源可能会受到概念漂移的影响,这些知识可能不再有效。
方法概述:提出了一种整体的类增量持续学习方法,基于经验重放(Experience Replay)。该方法的新颖之处在于,它允许同时避免灾难性遗忘和自动更新以前学习过的类别,如果它们受到概念漂移的影响。
主要贡献:
提出了一种统一的持续学习视角,结合了类增量学习中的灾难性遗忘避免和对先前学习类别变化的适应。
开发了一个新颖的经验重放方法,结合了聚类驱动的缓冲区以管理数据多样性,以及集群跟踪、切换和分裂,以忘记过时的信息并自动适应概念漂移,无需显式变化点检测。
讨论了一个现实且具有说明性的学习场景——持续偏好学习和推荐。由于用户可能获得新的偏好,并且他们的旧偏好可能会随时间变化,这个问题涉及到增量学习中避免灾难性遗忘和处理概念漂移的需求。
类增量经验重放:大多数基于经验重放的类增量方法专注于为静态数据存储最具代表性的实例或原型。这些方法假设观察到的类别和选择的实例的类别不会改变,因此不需要控制它们。
实验研究:通过模拟二元推荐系统,使用原始数据集的超类(0/1)来分配类别,评估了所提出的算法。实验旨在证明算法能够处理来自静态和非静态数据的类增量学习。
结论与未来工作:论文讨论了一种统一的持续学习方法,该方法桥接了避免灾难性遗忘和概念漂移下的数据流挖掘之间的差距。提出了一种基于反应性子空间缓冲区(Reactive Subspace Buffer, RSB)的经验重放方法,该方法结合了聚类驱动的记忆和适应组件,允许动态监控、重新标记和分裂现有集群。

算法是Reactive Subspace Buffer (RSB) 的实现,它是一种用于持续学习(Continual Learning)的经验重放(Experience Replay)方法,特别设计来处理概念漂移(Concept Drift)。以下是算法的详细解释:
输入参数:
cmin: 类的最小质心数。
cmax: 类的最大质心数。
bmax: 缓冲区的最大大小。
ωmax: 滑动窗口的最大大小。
输出结果:
B: 每次迭代的重放缓冲区。
算法步骤:
- 初始化:对于每个类别,确保至少有cmin个质心。如果没有,则为该类别添加新的质心、缓冲区和滑动窗口。
- 接收实例:对于每个到来的实例x及其标签y,执行以下步骤:
--- 寻找最近质心:找到实例x最近的质心Cx。
--- 更新质心:如果最近的质心Cx属于实例x的类别y,则更新质心Cx,以及它的缓冲区Bx和滑动窗口Wx。
- 概念漂移检测:如果实例x的类别与最近质心Cx的类别不一致,但实例x仍在Cx的范围内,仅更新滑动窗口Wx。
- 标签切换:如果检测到质心Cx的类别与实例x的类别不一致,并且有显著数量的实例标签与Cx当前标签不同,将Cx切换到新的多数类。
- 寻找同类别质心:如果实例x属于类别y,但最近的质心Cx不属于y,则寻找最近的同类别质心Cy,x。
- 更新或添加质心:如果实例x足够接近质心Cy,x,并且质心的数量没有达到最大值cmax,则更新Cy,x。否则,为类别y添加新的质心Cnew,以及相应的缓冲区Bnew和滑动窗口Wnew。
- 检查分裂和移除:对于每个质心C,在滑动窗口W更新后的第ns次,检查是否需要分裂成两个类别或移除微小的簇。
- 采样重放:基于质心的纯度标准,从重放缓冲区中采样实例。如果质心的纯度高于随机数r,则从其缓冲区中采样实例。
- 过采样平衡:由于采样过程可能导致采样实例的总数不确定,使用过采样来平衡选定的批次。
算法特点:
- 动态监控:通过滑动窗口跟踪当前概念。
- 标签切换:能够将质心的标签切换到新的多数类。
- 分裂机制:当簇足够“不纯”时,可以分裂成两个类别。
- 基于纯度的采样:根据簇的纯度来决定是否从其缓冲区中采样实例。
RSB算法的核心在于它能够适应概念漂移,同时避免灾难性遗忘,这使得它在持续学习环境中特别有效。通过结合聚类驱动的缓冲区和反应性组件,RSB能够在学习新类别的同时,对旧类别中的概念漂移做出反应。
为什么一个类需要多个质心?
在持续学习(Continual Learning)和数据流挖掘(Data Stream Mining)的背景下,一个类需要多个质心的原因通常与以下几个方面有关:
数据多样性:在现实世界的数据集中,一个类别(class)可能包含多种不同的模式或子空间(subspaces)。例如,在图像识别任务中,即使所有图像都属于同一个类别,它们也可能在形状、大小或方向上有所不同。使用多个质心可以帮助模型捕捉并代表这些不同的模式。
概念漂移适应性:在非静态的数据环境中,类别的分布和特征可能会随时间发生变化,这种现象称为概念漂移(Concept Drift)。多个质心可以更好地适应这种变化,因为它们允许模型在类别内部的不同子空间上进行更新和适应。
鲁棒性:多个质心可以提高模型对于噪声和异常值的鲁棒性。如果只有一个质心,那么异常值或噪声可能会对该质心的位置产生较大影响,从而影响整个类别的表示。多个质心可以通过聚合多个实例的特征来减少这种影响。
泛化能力:在机器学习中,泛化能力是指模型对未见过的数据做出准确预测的能力。通过使用多个质心来代表一个类别,可以帮助模型学习到更加泛化的特征表示,而不是仅仅记住训练数据中的特定样本。
避免过拟合:在某些情况下,如果一个类别只用一个质心来表示,模型可能会对训练数据过拟合,尤其是当类别内的变化不大时。多个质心可以促使模型学习到更加分散和泛化的特征。
灵活性和可扩展性:在类增量学习(Class-Incremental Learning)中,新类别的引入可能需要模型对现有类别的理解进行调整。多个质心提供了必要的灵活性,允许模型在新数据到来时对现有类别的表示进行更新和扩展。
在论文中提出的Reactive Subspace Buffer (RSB) 方法中,使用多个质心是为了创建一个能够同时处理新类别学习、避免灾难性遗忘以及适应概念漂移的动态学习系统。
通过这种方式,RSB 算法能够在持续学习的场景下,有效地维护和更新模型的知识库。
当缓冲区满时,新来的实例是如何将旧实例替换掉的?
在论文中提出的Reactive Subspace Buffer (RSB) 算法中,当缓冲区满时,新来的实例将替换掉旧实例的具体机制通常遵循以下原则:
先进先出 (FIFO):一种常见的替换策略是使用先进先出的原则,这意味着缓冲区中最旧的实例(通常是最先添加到缓冲区的实例)将被新的实例替换。
随机替换:在某些情况下,可能会采用随机替换策略,即从缓冲区中随机选择一个实例进行替换。
基于代表性的替换:在更复杂的方法中,替换决策可能基于实例的代表性。例如,如果新实例在特征空间中代表了之前未充分探索的区域,那么与当前缓冲区中的实例相比,它可能更具有代表性,因此可以替换掉一个不那么具有代表性的旧实例。
重要性加权:在某些经验重放方法中,每个实例可能会根据其对当前学习目标的重要性被赋予不同的权重。在缓冲区满时,可能会优先替换那些权重较低的实例。
性能驱动的替换:有时,替换决策可能基于模型性能的影响。如果替换一个实例能够提高模型在验证集上的性能,那么这样的替换可能更受青睐。
在RSB算法的上下文中,以下是新实例可能导致旧实例被替换的具体步骤:
接收新实例:算法接收一个新的实例 x 及其对应的标签 y。
找到最近质心:算法确定新实例 x 最接近的质心 Cx。
质心类别匹配:如果 x 的类别 y 与 Cx 的类别相匹配,算法将更新 Cx 及其缓冲区 Bx 和滑动窗口 Wx。
缓冲区已满:如果 Bx 已经达到最大大小 bmax,则需要替换一个旧实例。
确定替换策略:根据算法的设计,可能采用上述提到的FIFO、随机替换、基于代表性、重要性加权或性能驱动的替换策略。
执行替换:按照确定的替换策略,从缓冲区 Bx 中移除一个旧实例,并将新实例 x 添加到缓冲区中。
通过这种方式,RSB算法能够在学习新类别的同时,适应旧类别的变化,从而在持续学习环境中保持模型的性能。替换策略的选择将直接影响模型对旧知识的保留以及对新知识的吸收。
如何保证样本的多样性?
在本文提出的Reactive Subspace Buffer (RSB) 算法中,保证样本多样性的机制主要体现在以下几个方面:
聚类驱动的缓冲区:RSB算法使用聚类方法来组织数据,其中每个质心(Centroid)代表一个簇(Cluster),并且每个簇维护一个缓冲区来存储该簇的实例。这种方法有助于保持簇内样本的多样性,因为每个簇都能够独立地捕捉并维护其数据子空间的多样性。
缓冲区大小限制:通过为每个簇的缓冲区设定大小上限(bmax),算法可以确保缓冲区中的样本不是简单地按照先进先出(FIFO)原则替换,而是根据其代表性和与簇中心的距离来决定是否替换。这样可以避免缓冲区中只有非常相似的样本。
滑动窗口:每个簇的缓冲区中还包含一个滑动窗口(Wx),它用于跟踪最近的概念变化。滑动窗口有助于算法快速响应概念漂移,同时保持对最近样本的多样性。
基于纯度的采样:RSB算法在进行经验重放时,会根据每个簇的纯度(即簇内样本的一致性)来决定是否从其缓冲区中采样实例。纯度较低的簇意味着簇内存在多样性,算法可能会更倾向于从这些簇中采样实例。
质心的动态更新:当新实例到达时,如果它与最近的质心属于同一类别,算法会更新该质心及其缓冲区和滑动窗口。如果实例与当前质心类别不一致,但足够接近,算法可能只更新滑动窗口而不改变质心,这有助于维护簇的多样性。
概念漂移的适应性:RSB算法能够检测和响应概念漂移,通过切换质心的标签、分裂簇或移除过时的质心,算法可以适应数据分布的变化,从而保持样本的多样性。
过采样平衡:在从缓冲区采样实例进行经验重放时,由于采样过程可能导致某些类别的实例数量减少,RSB算法使用过采样来平衡选定的批次,这有助于保持样本的多样性。
通过上述机制,RSB算法能够在持续学习的过程中,不仅学习新的类别,而且保留对以前类别的知识,同时适应概念漂移,从而在整个学习过程中保持样本的多样性。
智能推荐
Sublime text 3搭建Python开发环境及常用插件安装_sublime python 环境搭建-程序员宅基地
文章浏览阅读4.9k次。Sublime text 3搭建Python开发环境及常用插件安装_sublime python 环境搭建
在CentOS 7上安装MySQL 8.0_centos7安装mysql8.0gpg密钥-程序员宅基地
文章浏览阅读643次。MySQL在首次安装后会执行一个安全脚本,用于设置root用户的密码以及其他安全选项。_centos7安装mysql8.0gpg密钥
echarts绘制圆角方形进度图_echarts symbolboundingdata-程序员宅基地
文章浏览阅读864次。这种场景下,可以使用两个系列,一个系列是完整的图形,当做『背景』来表达总数值,另一个系列是使用 `symbolClip` 进行剪裁过的图形,表达当前数值。_echarts symbolboundingdata
学python需要什么样的电脑,python需要什么样的电脑_python机器学习需要怎样配置的电脑-程序员宅基地
文章浏览阅读1k次,点赞18次,收藏16次。这篇文章主要介绍了学python对电脑配置要求高吗,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。_python机器学习需要怎样配置的电脑
最新OCR开源神器来了!-程序员宅基地
文章浏览阅读3.9k次。Datawhale开源开源方向:OCR开源项目01导读OCR方向的工程师,之前一定听说过PaddleOCR这个项目,其主要推荐的PP-OCR算法更是被国内外企业开发者广泛应用,短短半年..._github 2023年最新表格ocr
python 建筑建模_设计课开题 | Parameterized Complexities参数化建筑设计-程序员宅基地
文章浏览阅读317次。【竞赛+作品集,点燃你的设计理想】设计课开题啦!百川柯纳陆续推出以国际设计竞赛项目为参考的设计题目让大家参与,借此丰富履历,充实作品集。本期的设计题目为:Parameterized Complexities参数化建筑设计。喜欢参数化的小伙伴,你们兴奋吗?Parameterized Complexities 选题背景 近期不断有小伙伴在后台给我们留言,或者咨询百川柯纳顾问老师表达希望能够参加以“参数..._python 建筑平面图
随便推点
[ATF]-TEE/REE系统切换时ATF的寄存器的保存和恢复_atf-tee-程序员宅基地
文章浏览阅读1k次。ATF点滴1、设置运行时栈SP2、寄存器的保存和恢复的实现3、寄存器的保存和恢复的使用场景1、设置运行时栈SPbl31_entrypoint—>el3_entrypoint_common---->plat_set_my_stack—>platform_set_stack—>platform_get_stack动态找到该cpufunc platform_set_stackmov x9, x30 // lrbl platform_get_stackmov sp, x0r_atf-tee
PPT模板下载-程序员宅基地
文章浏览阅读134次。300多个各种类型的PPT模板下载,为您提供各种类型PPT模板、PPT图片、PPT素材、海报模板、新媒体配图等内容下载。
基于JAVA的智能小区物业管理系统【数据库设计、源码、开题报告】_智能化哪些系统需要数据库-程序员宅基地
文章浏览阅读546次。主要功能有:保安保洁管理、报修管理、房产信息管理、公告管理、管理员信息管理、业主信息管理、登录管理。_智能化哪些系统需要数据库
年度书单盘点 | 实用到爆炸,这份高性价比套系书单,越读越上头!-程序员宅基地
文章浏览阅读69次。本期年度书单,带大家盘点一下本年度图灵最受欢迎的套装图书,以前买套装书是为了凑单,如今套装书买回去不仅有一次性就能读完的酣畅感还极具收藏价值。一本好书往往要经过时间的验证,而阅读又是一种隐私,每个人的喜好大有不同,但能够集齐每个人的喜爱,这往往就是经典的诞生。今天这份书单里,有自成体系的套系书,还有一些因读者需求而产生的组成套系书。但不管哪种形式,它们都解决了读者在学习某些方面遇到的问题,也给大家...
thch30 steps/make_mfcc.sh详解-程序员宅基地
文章浏览阅读809次。这个脚本的输入参数有三个:1.data/mfcc/train 2.exp/make_mfcc/train 3.mfcc/train1.data/mfcc/train中有数据预处理后的一些文件:phone.txt spk2utt text utt2spk wav.scp word.txt2.exp/make_mfcc/train中应该是要保存程序运行的日志文件的3.mfcc/train中是提取出的特征文件1是输入目录,2,3是输出目录#!/bin/bash# Copyright 2012-2_thch30
smartclient listgrid style (加竖线、横线、背景色)_listgrid添加样式-程序员宅基地
文章浏览阅读2.5k次。如图所示:在jsp中引入: Style.css 代码:.myOtherGridCell { font-family:Verdana,Bitstream Vera Sans,sans-serif; font-size:11px; color:black; border-bottom:1px solid #a0a0a0;border-right:1px solid_listgrid添加样式