【超详细】手把手教你搭建filebeat+kafka日志监控集群_filebeat kafka-程序员宅基地
实验环境:三台centos7的虚拟机,kafka_2.12-3.0.1,apache-zookeeper-3.6.3
kafka集群最好只用三台以上;由于我电脑配置原因,就只开启了两台kafka作为集群
| 主机名 | ip |
|---|---|
| kafka01 | 192.168.1.100 |
| kafka02 | 192.168.1.101 |
| filebeat-nginx-01 | 192.168.1.102 |
前期准备:
修改三台主机的hosts文件
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.100 kafka01
192.168.1.101 kafka02
192.168.1.102 nginx-filebeat-01
192.168.30.10 manager10
192.168.30.11 node11
192.168.30.12 ndoe12
================================= zookeeper配置==============================
下载配置zookeeper
在两台kafka主机上下载zookeeper
kafka01主机:
- 新建目录zookeeper和myid文件
mkdir /tmp/zookeeper
touch /tmp/zookeeper/myid
echo 1 > /tmp/zookeeper/myid # 用于标识zookeeper
- 下载并且解压zookeeper
wget https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
tar xf apache-zookeeper-3.6.3-bin.tar.gz
cd apache-zookeeper-3.6.3 #进入zookeeper的安装目录
- 进入zookeeper的安装目录,修改配置文件
[root@manager10 apache-zookeeper-3.6.3-bin]# ls
bin conf docs lib LICENSE.txt logs NOTICE.txt README.md README_packaging.md
[root@localhost apache-zookeeper-3.6.3-bin]# cd conf/
[root@localhost conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@localhost conf]# cp zoo_sample.cfg zoo_cfg #拷贝zookeeper的配置文件
[root@localhost conf]# ls
configuration.xsl log4j.properties zoo_cfg zoo_sample.cfg
- 主要是对zoo.cfg文件进行配置,在末行添加对应的kafka映射关系。
[root@manager10 conf]# vim zoo.cfg
server.1=kafka01:2888:3888
server.2=kafka02:2888:3888
# 这里的1、2必须和之前配置的myid中的内容一致
# 2888端口是kafka中flower和leader的通信端口,简称服务端内部通信端口
# 3888端口是kafka中controller的选举端口
kafka02主机中也要配置相应的zookeeper,步骤和在kafka01的配置相似,不同点在于kafka02主机中的myid应该设置为2,而kafka01主机中的是1
最后启动两台主机中的zookeeper服务。
[root@manager10 apache-zookeeper-3.6.3-bin]# ls
bin conf docs lib LICENSE.txt logs NOTICE.txt README.md README_packaging.md
[root@manager10 apache-zookeeper-3.6.3-bin]# bin/zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /root/kafka_2.12-3.0.1/bin/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@manager10 apache-zookeeper-3.6.3-bin]#
在kafka02主机中:

在kafka01主机中:

====================================== kafka配置=======================
在两台kafka主机上下载kafka
# 使用的国内镜像
[root@manager10 ~]# wget http://mirrors.aliyun.com/apache/kafka/3.0.1/kafka_2.12-3.0.1.tgz
[root@manager10 ~]# tar xf kafka_2.12-3.0.1.tgz
[root@manager10 ~]# cd kafka_2.12-3.0.1
[root@manager10 kafka_2.12-3.0.1]# ls
bin config libs LICENSE licenses logs NOTICE site-docs
[root@manager10 kafka_2.12-3.0.1]# cd config
================================= kafka01主机 ==================
在conf目录中找到server.properties文件并修改
[root@manager10 config]# vim server.properties #修改如图配置
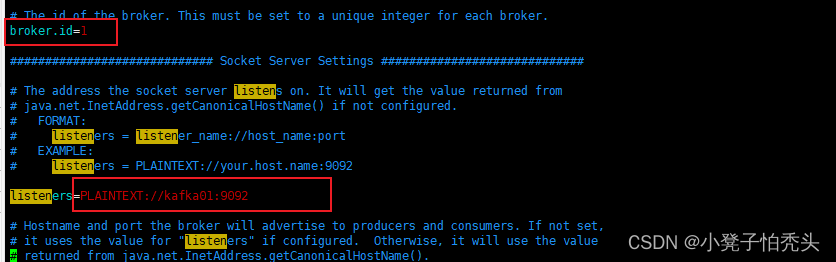
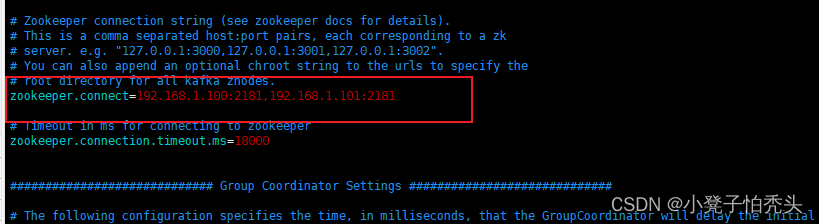
======================== kafka02主机中 ===================
[root@manager10 kafka_2.12-3.0.1]# cd config/
[root@manager10 config]# vim server.properties #修改如下图配置
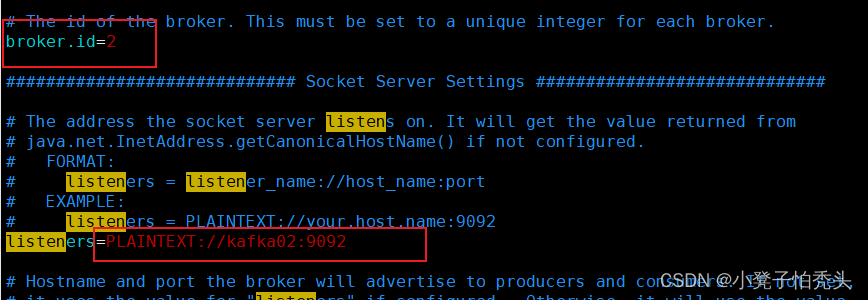
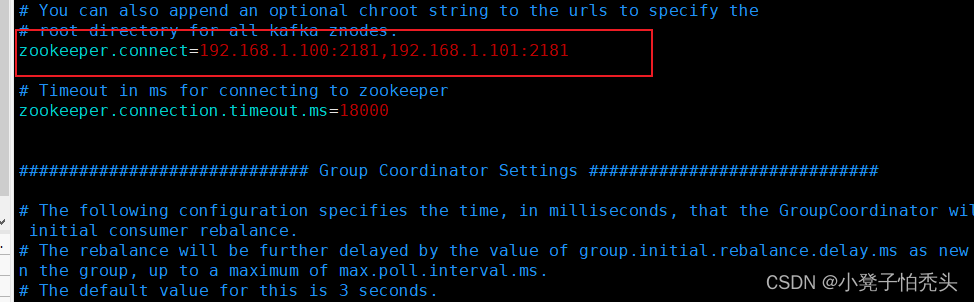
启动kafka:两台kafka都要启动
进入kafka的安装目录,找到bin文件,执行以下命令开启kafka服务
[root@manager10 kafka_2.12-3.0.1]# bin/kafka-server-start.sh -daemon config/server.properties
[root@manager10 kafka_2.12-3.0.1]# lsof -i:9092
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 9868 root 164u IPv6 57917 0t0 TCP kafka02:XmlIpcRegSvc (LISTEN)
java 9868 root 183u IPv6 57924 0t0 TCP kafka02:49542->kafka02:XmlIpcRegSvc (ESTABLISHED)
java 9868 root 184u IPv6 57925 0t0 TCP kafka02:XmlIpcRegSvc->kafka02:49542 (ESTABLISHED)
启动生产者消费者进行验证:
在kafka集群任意一台主机中创建topic:
[root@manager10 kafka_2.12-3.0.1]# bin/kafka-topics.sh --bootstrap-server 192.168.1.101:9092 --create --topic test --partitions 2 --replication-factor 1
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Created topic test.
创建生产者:
[root@manager10 kafka_2.12-3.0.1]# bin/kafka-console-producer.sh --broker-list 192.168.1.101:9092 --topic test
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
>生产了一台汽车
>
创建消费者:
[root@manager10 kafka_2.12-3.0.1]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.101:9092 --topic test --from-beginning --group default_group
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
生产了一台汽车
============================== filebeat-nginx配置在192.168.1.102主机上
关闭防火墙和selinux
[root@localhost conf]# systemctl stop firewalld
[root@localhost conf]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service
[root@localhost conf]# setenforce 0
setenforce: SELinux is disabled
[root@localhost conf]# getenforce
Disabled
下载启动nginx
yum install nginx -y
nginx #启动
访问nginx,这里之前对nginx的index.html做过修改,显示首页和您们可能不一样,可以访问就表示nginx启动成功。

filebeat配置
安装:
[root@localhost conf]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
# 编辑fb.repo文件,配置filebeat的官方下载源
[root@localhost conf]# vim /etc/yum.repos.d/fb.repo
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
安装filebeat:
[root@localhost conf]# yum install filebeat -y
# 设置开启自启
[root@localhost conf]# systemctl enable filebeat
配置:
# 查看filebeat支持哪些模块
[root@localhost conf]# filebeat modules list
# 开启支持模块
[root@localhost conf]# filebeat modules enable system nginx mysql
# 修改配置文件/etc/filebeat/filebeat.yml采集nginx的日志文件 只保存以下内容,其他内容删除
[root@localhost conf]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
# ============================kafka=======================
output.kafka:
hosts: ["192.168.1.100:9092","192.168.1.101:9092"]
topic: test
keep_alive: 10s
最后启动filebeat:
[root@localhost conf]# systemctl restart filebeat
[root@localhost conf]# ps aux|grep filebeat
root 2867 22.6 11.0 945100 109748 ? Ssl 10:44 0:01 /usr/share/filebeat/bin/filebeat --environment systemd -c /etc/filebeat/filebeat.yml --path.home /usr/share/filebeat --path.config /etc/filebeat --path.data /var/lib/filebeat --path.logs /var/log/filebeat
root 2874 0.0 0.0 112824 988 pts/0 R+ 10:44 0:00 grep --color=auto filebeat
[root@localhost conf]#
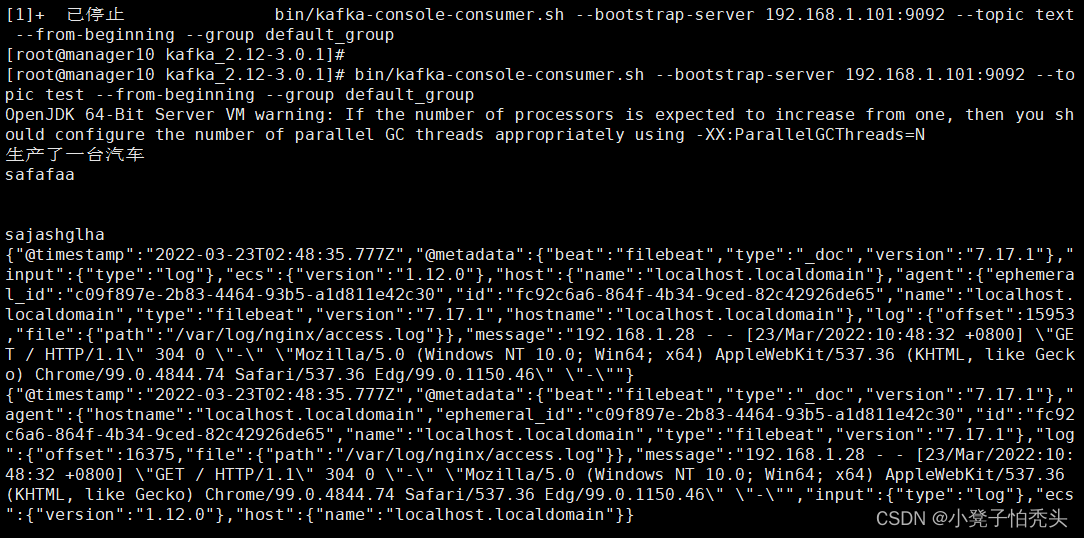
验证消费者是否可以消费到nignx日志文件,访问nginx产生日志,如下可以看到nginx日志成功推送到了kafka集群中。
智能推荐
浅谈字符数组-程序员宅基地
文章浏览阅读5.8k次,点赞25次,收藏79次。浅谈字符数组_字符数组
商业公链之区块链技术使用的常见库(十)------Go语言微服务库 "github.com/micro/go-micro”_micro.flags传递配置-程序员宅基地
文章浏览阅读2.3k次。Go语言微服务库 github.com/micro/go-micro由于Grpc存在ip和具体服务绑定,一旦服务ip改变,客户端代码也要改变,管理麻烦。同时,存在服务发现和服务间调用问题。直接使用实现了服务注册的 go-micro 框架。Micro是一套微服务构建工具库。对于微服务架构的应用,Micro提供平台层面、高度弹性的工具组件,让服务开发者们可以把复杂的分布式系统以简单的方式构建起来,..._micro.flags传递配置
java 对象转xml_Java bean与xml 互转(对象转xml、xml转对象)-程序员宅基地
文章浏览阅读318次。importorg.jdom2.Document;importorg.jdom2.Element;importorg.jdom2.input.SAXBuilder;importorg.jdom2.output.Format;importorg.jdom2.output.XMLOutputter;import java.io.*;importjava.lang.reflect.Field;impor..._java中jdom4实现bean与xml 互转(对象转xml、xml转对象)
oracle查询控制文件的位置及其文件名,oracle的控制文件(control file)-程序员宅基地
文章浏览阅读3.7k次。控制文件是一个小小的二进制文件,是oracle数据库的一部分,这个控制文件是用于记录数据库的状态和物理结构。每个数据库必须要至少一个控制文件,但是强烈的建议超过一个控制文件,每个控制文件的备份应该放在不同的磁盘上。一:控制文件包含如下信息:1:数据库名2:数据库创建的时间戳3:数据文件的名字和位置4:redo log (联机重做日志文件)的名字和位置5:当前日志的序列号6:checkpoint 信..._所有控制文件的名称和路径。
【操作系统/OS笔记07】页面置换算法,最优、FIFO、最近最久未使用、时钟_最优页面算法-程序员宅基地
文章浏览阅读1.5k次。页面置换算法,最优、FIFO、最近最久未使用、时钟、两种全局置换算法。_最优页面算法
java byte数组转image,在Java中将字节数组转换为image(blob)-程序员宅基地
文章浏览阅读1.5k次。The code for the image conversion from byte array to image i.e blob.try{Blob image_vis = rs1.getBlob(10);InputStream x=image_vis.getBinaryStream();OutputStream out=new FileOutputStream(string_op);byte..._jave byte[]转为image
随便推点
CDN静态文件部署-程序员宅基地
文章浏览阅读2.8k次。------------------------------------静态资源部署cdn分发网络的引入-----------------------------1.在获取前端页面时,我们知道是先加载静态资源,后面通过ajax请求来获取商品详情页信息来进行渲染页面的过程,任何一步没做到位都会拖累整站的QPS,TPS的响应,未将静态资源加载到cdn的情形下,TPS700左右,且平均响应时间也在300多,cdn作为前端静态资源请求的中间层节点,它充当者用户客户端访问的服务端,同时也是后端服务端的客户端,它需
计算机占cpu程序,电脑cpu占用过高怎么办 电脑进程CPU占用100%解决办法-程序员宅基地
文章浏览阅读5.6k次。很多朋友在使用电脑都出现过电脑CPU使用率高导致电脑非常卡,运行的一些程序卡主不动了。无响应的情况。那么电脑CPU占用100%使用率怎么解决呢?导致CPU使用率高的问题无非就在于两点:1.系统或软件问题;2.硬件问题解决CPU使用率过高我们就要分析为什么cpu使用率会达到100%,我们一起来分析吧!CPU使用率高的原因1.电脑运行了大型的程序,例如大型的游戏,3D网络游戏等等,这种情况通常是正常的..._电脑cpu占用过高怎么办
MT4-EA自动化交易研究笔记(2022-06-24)_mt4中,只用k线来判断行情的ea的思路-程序员宅基地
文章浏览阅读1.4k次。目录昨日交易总体情况昨日EA更新内容待解决问题/对于交易策略的思考当前在用的EA介绍已经很久没有更新日志了,趁着今天闲下来就想随便写点什么。最近一直忙着工作,期间也改进过几次ea,不过都不理想,甚至可以说越改越烂,上次说到的把仓位改成倒金字塔应该会很暴利,实际测试却没有预期的那么有效,反而弄爆了几个模拟账户,可以说非常的惨烈。最近思考的方向主要有两个,一个是能不能附加一个趋势性的ea来冲抵当前策略的浮亏,或者说想趋势震荡行情都通吃;另外一个就是思考如何解决现在这个策略进场出场都太早的问题。对前一个问题的思考_mt4中,只用k线来判断行情的ea的思路
html展开div时从左往右,从右到左不间断滚动DIV CSS代码(图例)特效-程序员宅基地
文章浏览阅读703次。完整DIV+CSS+JS不间断横向滚动代码:横向不间断滚动DIV CSS代码-CSS5.scroll_div {width:600px; height:51px;margin:0 auto; overflow: hidden; white-space: nowrap; background:#ffffff;}.scroll_div img {width:175px;height:51px;bord..._html 多个div自左向右滚动
CSP-J1 CSP-S1 初赛 第1轮 第四章 阅读程序 第7节 搜索策略 2、NOIP2013-程序员宅基地
文章浏览阅读85次。CSP-J1 CSP-S1 初赛 第1轮 第四章 阅读程序 第7节 搜索策略 2、NOIP2013
MySQL水平分表原理讲解_数据库水平分表,有哪些规则?-程序员宅基地
文章浏览阅读3.7k次,点赞5次,收藏17次。什么是水平分表?当一张表到达一定的数据量后(如500万条数据),索引的成本也随之增加,使用主键索引查找数据时也显得十分吃力,数据检索效率低。水平分表是将一个数据量大的表按照一定的规则拆分成多个结构相同的表,将数据分散到拆分出来的表中。拆分后,当我们查找某条数据时,只需要按照拆分表时的规则推断出需要查询的数据具体存在哪一张表中,到对应的表查找数据即可。下图是按照时间作为规则水平拆分表的示例:常见的水平分表方案1.按时间拆分像上图中的拆分示例,采用的是按照年份水平拆分表的方案,除此之我们还_数据库水平分表,有哪些规则?