半导体技术基础_瀚博 登临 寒武纪 昇腾-程序员宅基地
技术标签: c++ GPGPU&CUDA&FPGA&ASIC&SOC GPU,NPU,XPU,DPU,MPU 计算机软件
半导体技术基础
AI的许多数据处理涉及矩阵乘法和加法。大量并行工作的GPU提供了一种廉价的方法,但缺点是更高的功率。具有内置DSP模块和本地存储器的FPGA更节能,但它们通常更昂贵。
AI芯片该使用什么方法原理去实现,仍然众说纷纭,这是新技术的特点,探索阶段百花齐放,这也与深度学习等算法模型的研发并未成熟有关,即AI的基础理论方面仍然存在很大空白。这是指导芯片如何设计的基本前提。因此,集中在如何更好的适应已有的数据流式处理模式进行的芯片优化设计。
技术手段方面AI市场的第一颗芯片包括现成的CPU,GPU,FPGA和DSP的各种组合。虽然新设计正在由诸如英特尔、谷歌、英伟达、高通,以及IBM等公司开发,但还不清楚哪家的方法会胜出。似乎至少需要一个CPU来控制这些系统,但是当流数据并行化时,就会需要各种类型的协处理器。
人工智能,从软件层面看,其实是一种暴力计算。需要很强的计算能力来支撑。视频、3D、VR信息形式,数据量会大一两个数量级。这些都需要芯片对数据处理能力的提升。
所以,人工智能芯片核心驱动力,依然是对数据处理能力的需求,目前的芯片远远满足不了需求。尤其是一些视频、3D数据处理的场景,非要用到AI芯片不可,原来的CPU不仅成本太高,而且根本达不到要求。
以自动驾驶的视频处理为例,单靠CPU来处理汽车摄像头传来的实时视频数据,根本不可能,必须要用到针对CV场景优化之后的AI芯片。同样的场景,还有智慧城市领域的城市摄像头。
目前芯片体系所能提供的算力根本达不到要求,算力还得往上提高一两个数量级才行。
本文主要参考文献链接:
https://www.zhihu.com/question/448075048/answer/2398135680
https://mp.weixin.qq.com/s/INHq12q–FVZjZZejlADkQ
https://mp.weixin.qq.com/s/Lzi6ihofgp05s-KFceUZeA
https://mp.weixin.qq.com/s/xeSI-hB8OQb77HpS1qyduA
https://mp.weixin.qq.com/s/2bk4MH2lteRc8I-UMMEMBA
https://mp.weixin.qq.com/s/oR0d_pvr2PohpjKByZaq1Q
https://mp.weixin.qq.com/s/TcotntN4LIWHmV9ZQWB5Ow
对于中国而言,还面临一个芯片国产化的问题。AI芯片是另一个赛道,有弯道超车的可能性。中国发展AI芯片产业,可以避免被美国卡脖子,有助于中国的计算产业安全,和供应链的可靠性。
事实上,中国遭遇芯片“卡脖子”问题由来已久,高度依赖进口的传统方式使得国家在一定程度上陷入不稳定的发展中。
国产GPU全面开花
近几年大火的概念实现都离不开GPU。
3月31日,壁仞科技首款通用GPU芯片BR100系列一次点亮成功,在核心性能设计标准上,BR100系列是国内算力最大的通用GPU芯片,直接对标国际厂商近日发布的最新旗舰产品。壁仞科技BR100系列的成功点亮,标志着其成为国内极少数真正在核心性能层面达到国际顶尖水平的国产高端GPU芯片企业。
仔细翻看壁仞科技的履历,还会发现其成立两年时间,累计融资已近50亿元,成为行业内成长势头最为迅猛的“独角兽”。
显然,国产GPU赛道风潮正劲。在上一波AI芯片的创业及融资热潮后,整个芯片行业经历了一轮大洗牌。如今算力经济登上历史舞台,成为新的生产力,GPU凭借着强大的并行计算能力和良好的可编程性,逐渐成为芯片界又一火热的赛道,加上国产替代紧迫的“引力”让国内GPU企业如雨后春笋冒出。

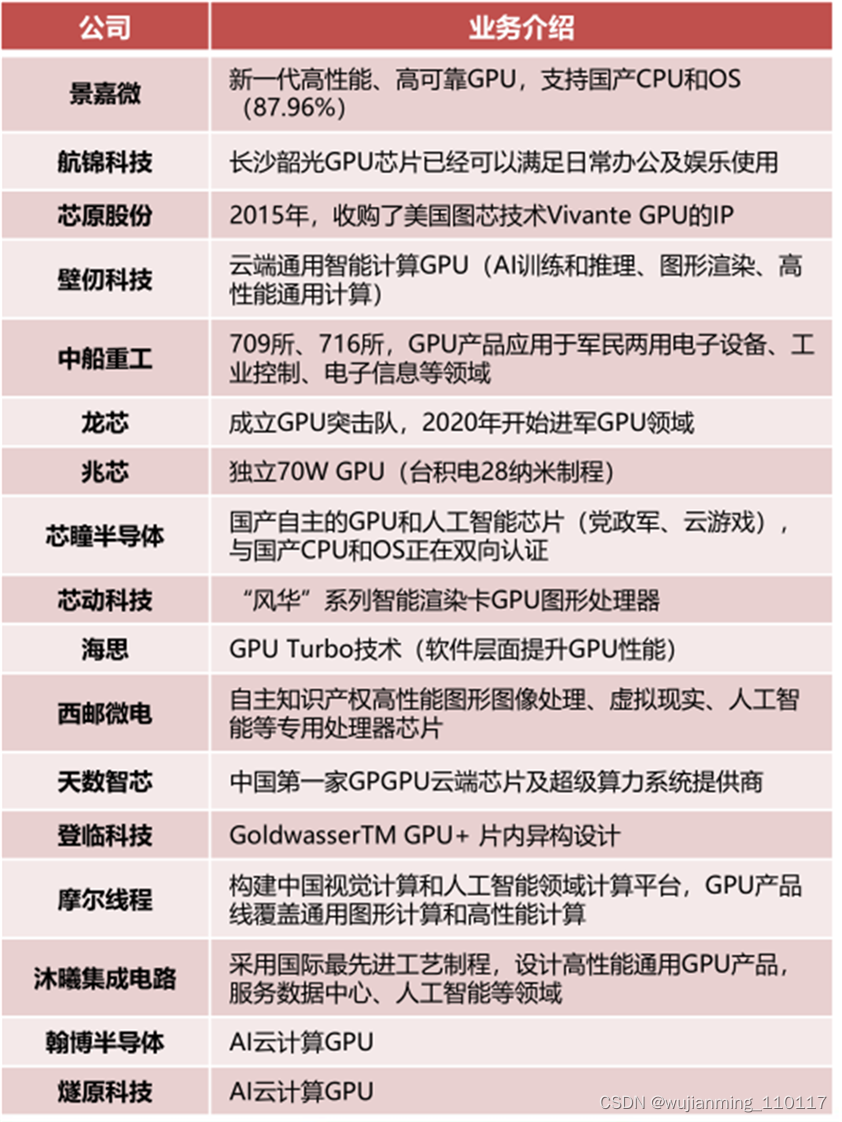
据了解,国内GPU创业公司已有近20家,既有老牌芯片企业入局,也有一批GPU新势力,这一长串名单包括摩尔线程、壁仞科技、天数智芯、沐曦集成电路、登临科技、芯动科技、砺算科技……国内GPU领域已呈现百花齐放的局面,逐渐成为了市场上投资人们追逐的热点。
GPU时代正来临
GPU的全称是Graphic Processing Unit,即图形处理器,最早由英伟达提出。最大的作用就是进行各种绘制计算机图形所需的运算,包括顶点设置、光影、像素操作等。平常在电脑上看到的视频、游戏等画面都是通过GPU的运算展现的。
相比于CPU和专用集成电路芯片(ASIC),GPU在深度学习上的性能、通用性更佳。随着市场需求的发展,GPU不止用于处理图形图像,技术原理决定了适用于大批量处理特定类型信息,并行计算能力和能效远远超过CPU,所以逐渐衍生出了通用计算GPU(GPGPU),即利用图形处理器进行非图形渲染的高性能计算。
发展至今,GPU不仅为个人电脑、服务器和移动设备进行图形处理工作,还是目前公认最好的AI加速器,在VR、自动驾驶、智能分析、图像识别、金融交易等主流云计算及边缘计算领域有着海量应用空间。当行业对算力的需求越来越大,现有的算力很难满足,制造GPU能够更好的服务用户,这便是GPU时代来临的背后逻辑。
作为图形渲染和智能计算的主要平台,GPU产业已形成较大规模。根据Verified Market Research数据统计,2020年全球GPU市场价值为254.1亿美元,2027年有望达到1853.1亿美元,年平均增速高达32.82%。
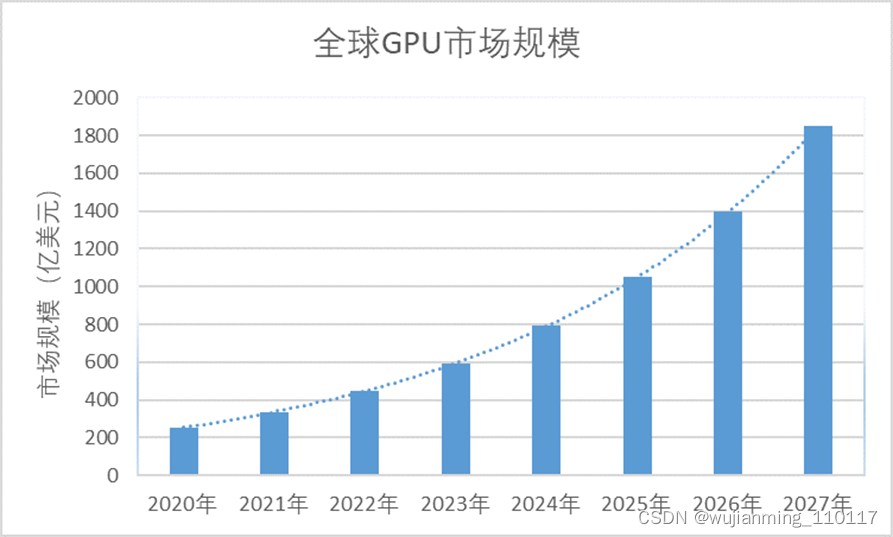
▲全球GPU规模走势预测
放眼全球,GPU呈现寡头高度垄断的格局。在GPU市场,排名前三的英伟达、AMD、英特尔的营收几乎垄断整个GPU行业的销售。在中国市场中,三大巨头也是分走了大部分“蛋糕”,2020年英伟达、AMD在中国大陆收入占比分别为23.3%、23.9%,可谓赚得盆满钵满。
相比之下,国产GPU还处于起步阶段,同时也表明国产GPU替代空间和发展潜力很大。从数据来看,2020年中国大陆的独立GPU市场规模为47.39亿美元,预计2027年中国大陆GPU市场规模将超过345.57亿美元。虽然GPU市场长期被英特尔、英伟达、AMD等厂商垄断,但由于产品价格昂贵,国内政策端对信息关键基础设施自主可控的重视,国产替代浪潮来临,国内独立GPU厂商的广阔市场空间已被打开。
源自国际芯片巨头的GPU创业者涌入
GPU市场的红火吸引着更多玩家入局。实际上,由于华人在GPU领域出类拔萃,为GPU这股新势力供给了大量人才。近年来,大批人才被中国创业机会吸引,陆续回国或离开外企,成为这批初创企业的领军人物。
这波GPU创业浪潮由壁仞科技领衔。成立仅一年多,壁仞科技吸引了启明创投、IDG资本、华登国际、珠海格力创投、松禾资本、高瓴创投、源码资本等众多VC/PE机构先后入局。截至目前,这家芯片领域“现象级”爆红企业累计融资金额已超过47亿元人民币,创下该领域融资速度及融资规模的纪录。
成立于2020年10月的摩尔线程,仅用了100天就跻身独角兽行列,一年内的时间里便拿下了3轮超20亿元的融资,身后投资方阵容豪华。值得一提的是,摩尔线程的创始人,正是前英伟达全球副总裁、中国区总经理张建中,在半导体领域赫赫有名。该公司团队其他成员还来自包括微软、英特尔、AMD、Arm等诸多芯片巨头。
GPU明星企业沐曦集成电路也是炙手可热。2021年8月,沐曦集成电路宣布完成10亿元人民币A轮融资。本轮新加入的投资者中,除了国调基金、中国互联网投资基金两个重磅国家队领投方之外,大手笔跟投的上海科创基金、智慧互联产业基金等均是市场知名的国资背景基金,国创中鼎、联想创投、复星锐正、东方富海等机构也为沐曦带来丰富的产业资源。
再看创始团队,同样是卧虎藏龙。沐曦创始人兼CEO陈维良曾在AMD担任图形研发高级总监,拥有超过18年的GPU芯片设计经验;CTO杨建曾是AMD大中华区第一位科学家,曾参与及主导数十款GPU产品量产及交付全流程;首席硬件架构师彭莉是AMD全球首位华人女科学家,历任AMD首席SoC架构师、系统架构师、GFXIP架构师等职务。
另有天数智芯、登临科技、瀚博半导体等公司先后打出CPU旗号后,投资人纷至沓来,均在数月内密集宣称获得数亿元投资,成为资本的“宠儿”。背后仍是“高配”的创业团队,天数智芯首席科学家郑金山,瀚博半导体创始人钱军、CTO张磊、副总裁杨勤富,以及燧原科技创始人赵立东、燧原科技COO张亚林等均有在AMD工作多年的资深背景。
“芯”成果接连不断国产GPU加速突围
国产GPU企业陆续获得大笔融资的背后,正说明中国GPU市场的火爆。事实上,除了资本的大力支持,国产CPU企业近几年也切实在产品上取得了一定的突破。一边是老牌厂商芯原股份、兆芯等稳扎稳打,政企市场打下江山;另一边新晋玩家摩尔线程、芯动科技等迅速崛起,依靠生态优势占领先机。

▲天数智芯的“天垓100”芯片
天数智芯于2018年正式启动GPGPU大芯片设计,国内第一家通用GPU云端芯片及超级算力系统提供商,创立之初就选择了GPGPU作为主要技术路线。2021年11月,天数智芯宣布公司全自研、国内首款云端7纳米GPGPU产品卡——“天垓100”已正式进入量产环节。这颗芯片主要应用于数据中心和服务器等领域,是国产GPU赛道从实验室走向落地的一个关键点。
在谈到国产GPU的机会点时,天数智芯相关人士表示:
“人工智能训练主流应用都采用国际厂商,国产品牌呼声强烈。同时国内市场特点是人工智能市场应用广阔,国家高度重视芯片产业发展。”
登临科技交出了阶段性的成果,首款GPU+产品已于2021年2月成功回片通过测试,开始客户送样。登临科技自主创新的GPU+,通过对高效Tensor引擎和可编程的GPGPU引擎的有机配合,采用硬件直接兼容CUDA/OpenCL,完美解决了通用性和高效率的双重难题,开辟了国内GPGPU产品商业化落地的新路径。
国内较早从事CPU研发的兆芯开始切入这个赛道。兆芯同时掌握CPU、GPU、芯片组三大核心技术,具备三大核心芯片及相关IP设计与研发的能力。早在2019年,兆芯发布了全新的用于PC的处理器KX-6000系列,KX-6000是业内第一款完整集成CPU、GPU、芯片组的SoC单芯片国产通用处理器。除了集成GPU,兆芯还计划发布一款采用台积电28nm成熟工艺制造,功耗约70W的GPU独立显卡。

另一大动作是业界“小英伟达”摩尔线程于近日正式推出采用MUSA架构的首颗全功能GPU芯片苏堤,以及基于苏堤的首款台式机显卡MTTS60、首款服务器产品MTTS2000。从创立到发布GPU,摩尔线程仅用了18个月,表现出半导体领域未曾有过的速度,这匹黑马的出现,无疑为国产GPU发展添上一把火,狠狠烧遍全世界。
现阶段,虽然国产GPU与世界巨头差距明显,但可以预见的是,随着国产GPU初代产品陆续顺利推出和落地,在一些空白的细分领域,还是有很大的“弯道超车”空间。
国产替代意愿强烈,市场应用空间广阔,大厂精英组团创业,巨额资本蜂拥而至……毋庸置疑,在中美博弈、算力经济、人工智能、“东数西算”的推波助澜下,国内GPU领域正呈现出前所未有的光景,不论是资本介入还是产品规划,国产GPU都已进入白热化阶段。
花团锦簇的背后,需要一些冷思考。相比于前些年火热的AI芯片,GPU无疑在技术上有更高的门槛,一直以来都是国内半导体产业中的弱项。国产GPU企业本身成立时间不过短短数年,虽然获得了庞大的资金涌入,但毕竟不像英伟达等国际芯片巨头那般发展许久拥有极其深厚的技术基底。新势力想要真正进入GPU市场,必须掌握核心技术,有多年的技术积累和人才资金供给。
另外,GPU芯片从最初设计到制造、流片、量产,周期通常不会低于18-24个月,需要经年累月的迭代和优化。产品“点亮”、推出只是起步,芯片的成熟需要大量的验证和出货,找到可持续的落地场景才是长期发展的关键驱动力。所以尽管热度高涨,但能拿出与国际巨头对标的量产产品、实现商业化突破的企业很少,尤其是在高端GPU领域的产品更是凤毛麟角,中国高端GPU业务从战略布局成长为核心支柱还有漫长的路要走。
但路虽远行则将至,在这趟艰难的旅程中,国产GPU已让看到了“芯”希望。大浪淘沙始见金,热炒下的GPU正迎来激烈的竞争,新晋玩家能否抗住国际芯片巨头带来的巨大压力,已获得资本青睐的企业能否交出漂亮的“成绩单”,最终谁能横枪勒马、杀出重围,成长为中国版“英伟达”?翘首以盼。
中国大芯片的黄金时代
“这个世界和这个时代变化最大、最快的其实是算力。”
毫无疑问,算力革命也影响着芯片未来方向。当前,无论是5G时代下雪崩般增长的数据量和传输速度,还是AI时代下逼近计算极限的深度学习,都对芯片提出了越来越高的算力要求。大算力芯片,这个由英伟达、英特尔等巨头执掌的赛道已然成为热门话题,中国也不例外。
虽然,相对高投入、高门槛、高试错成本的大算力芯片,中国早期一批芯片企业大多都投身于相对缺陷较少,使用相对成熟工艺技术,批量生产更容易的WiFi芯片、电源芯片等小型应用芯片,类似飞腾、华为、展锐、景嘉微和龙芯等大芯片在当时只是少数派。但随着算力革命的到来,国际竞争格局的风云变幻,越来越多的玩家摩拳擦掌,高举“国产替代”旗帜挤入赛道。
一位新秀企业的CEO曾表示,中国大芯片元年从2018年开始,到2021年是三年的开放窗口期,待到2021年年底后,创业窗口将收窄,再想入局可能为时已晚。
进入2022年,中国大芯片的玩家们也迎来了辉煌时刻。
首先爆发的AI芯片
说到大芯片,首先必提的是AI芯片。自从2017年在政府工作报告里首次提到了人工智能的重要性后,AI也逐渐成为中国的发展重心。AI的方兴未艾不仅带动了对算力更大的需求,也驱使芯片行业再度涌动起创新的热潮。
从广义上说,一般只要能够运行人工智能算法的芯片都叫作AI芯片,但AI芯片指的是针对人工智能算法做了特殊加速设计的专用芯片,即专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务仍由CPU负责)。
不完全统计,2021年超10家AI大算力芯片企业完成超15轮的融资。属地平线的大C轮融资最为惊叹,2021年上半年地平线共完成了从C2到C7共6轮融资,透露的投资额显示超25.5亿美元。百度昆仑芯片业务也在今年3月完成独立融资,并于6月独立成为一个新公司昆仑芯(北京)科技有限公司。
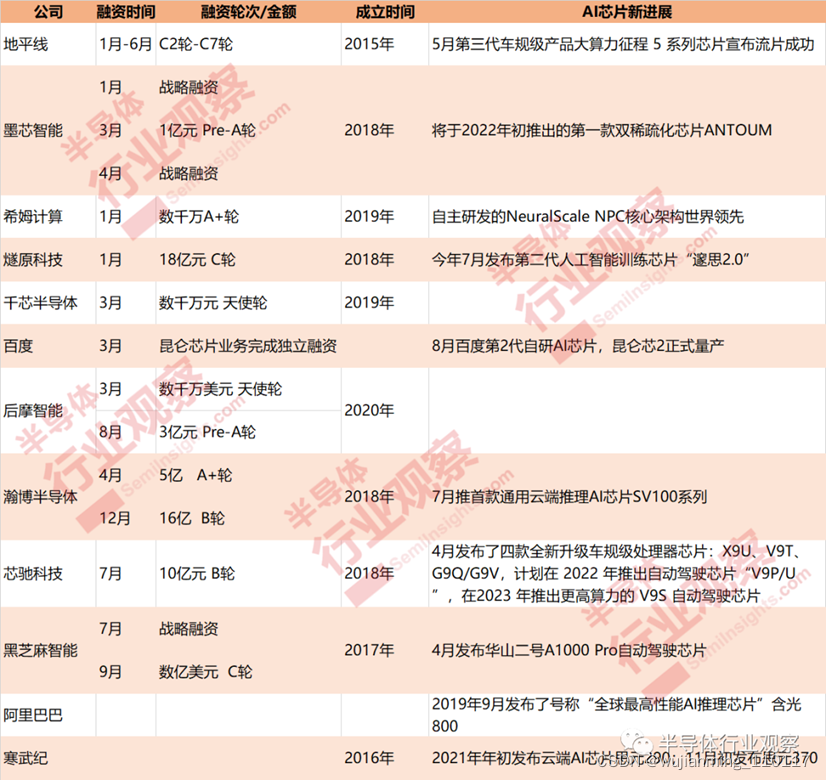
随着技术更迭,以云平台、智能汽车、机器人等人工智能领域为代表的不同领域对AI专用芯片的需求也将不断增大,人工智能市场将迎来增长期。据华经情报网数据显示,2020年,中国人工智能市场规模达151亿元,同比增长55.67%,预计到2023年其市场规模将有望达到557亿元。
在一定程度上,庞大的应用场景和市场给中国AI芯片公司带来了不小的优势,能够做到和其他国家齐头并进。中国互联网大厂大多都从AI芯片切入造芯赛道,希望从硬件层面实现自家软硬件紧密结合,满足用户的需求。百度8月宣布第2代自研AI芯片昆仑芯2正式量产,阿里早在2019年9月就已经发布了号称“全球最高性能AI推理芯片”含光800。
同时,作为AI芯片第一股的寒武纪2021年也接连发布2款云端AI芯片,分别是思元290和思元370。思元370是寒武纪首款采用chiplet(芯粒)技术的AI芯片,集成了390亿个晶体管,最大算力高达256TOPS(INT8),寒武纪第二代产品思元270算力的2倍。
此外,燧原科技、地平线、瀚博半导体、芯驰科技、黑芝麻智能等在2021年也都推出了大算力AI芯片,燧原科技发布的“邃思2.0”,被认为是中国最大AI芯片,整数精度INT8算力高达320TOPS;地平线、黑芝麻智能与寒武纪一样,推出的芯片都可运用于自动驾驶方面;芯驰科技计划在 2022 年推出自动驾驶芯片“V9P/U”,支持 L3 级自动驾驶,在2023 年推出更高算力的 V9S 自动驾驶芯片,可支持 L4/L5 级 Robotaxi;瀚博半导体主要运用于视频处理方面,其SV100单芯片INT8峰值算力超200 TOPS。
“玩不腻”的GPU
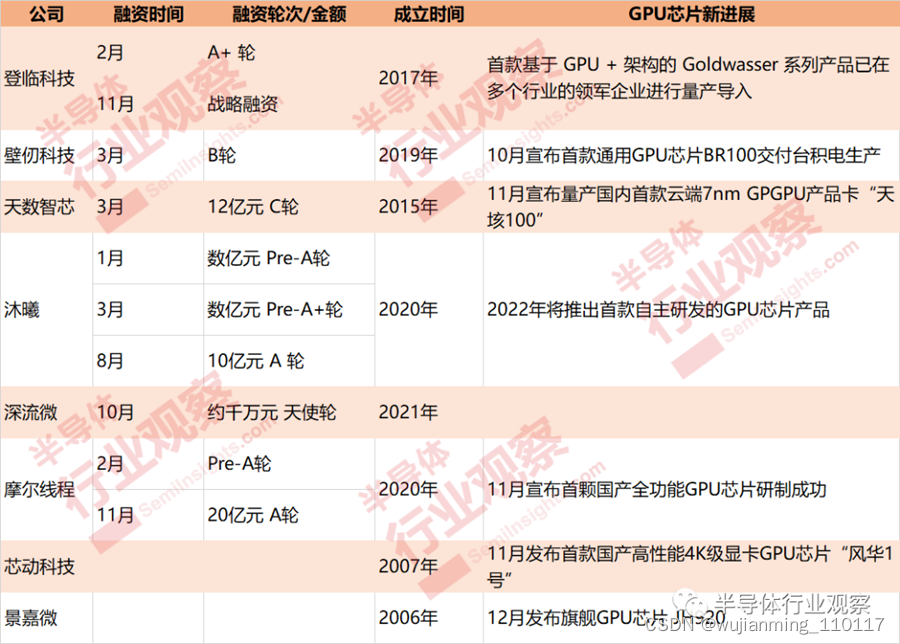
在AI方兴未艾的时候,GPU又异军突起。过去两年的GPU有多热门,相信无需赘言了,GPU企业的融资从年头贯穿到年尾,每次透露出来的融资金额都令人啧啧惊叹。
笔者根据公开信息统计,2021年超6家GPU企业共获得超10笔融资,其中登临科技、沐曦、摩尔线程在一年中都获得至少2轮的融资。从透露的投资额来看,大部分GPU企业获得的投资金额都超亿元,摩尔线程更是创造了成立仅100天就达成数十亿募资,沐曦也在成立仅一年多的时间里完成了4轮融资,壁仞科技自成立以来总融资额近50亿元,可见GPU已经成为了中国资本的“宠儿”。
GPU全称是graphics processing unit,就是图形处理器,又称显示核心、视觉处理器、显示芯片,一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
在发明之初,GPU是用来分担CPU处理图像和图形计算的压力,并承担起部分CPU的职能。但进入3D时代后,云计算、AI等技术快速发展,使得设备的图像图形处理数据大大增多,高性能计算需求打开GPU市场第二增长曲线,GPU并行计算的优势被发掘,并在高性能计算领域取代CPU成为主角。
当前,全球传统GPU格局不用多说,被英伟达、AMD、英特尔三家巨头寡头垄断,其中英伟达收入占56%、AMD占26%、英特尔占18%。中国的GPU的发展相对落后,直到2014年,GPU龙头企业景嘉微才成功研发出国内首款国产高性能、低功耗GPU芯片— JM5400。受制于GPU对CPU的依赖性,以及GPU较高的技术难度,开发GPU显然要比CPU更加困难。再加上相关人才短缺,培养一位拥有丰富经验的成熟工程师至少需要10年,这让国内GPU的发展“难上加难”。
但重重技术壁垒背后隐藏的是巨大的市场,无论是当前热门的人工智能还是自动驾驶汽车,人口老龄化可能带来的机器人落地,还是5G时代下的数字化转型,都给国产GPU带来了新机遇,据数据统计,国内GPU芯片相关生产商已近30家。中国作为全球GPU市场重要组成部分,据Verified Market Research数据显示,2020年中国大陆的独立GPU市场规模为47.39亿美元,预计2027年中国大陆GPU市场规模将超过345.57亿美元。
庞大的资本涌入曾让人们对这些成立仅数年的企业产生了怀疑,2021年,风潮正劲的国产GPU赛道玩家也接连交出了自己的答卷,从上图来看,除了今年刚成立的深流微,其余7家GPU企业都有了新动态。
天数智芯宣布量产国内首款云端7nm GPGPU产品卡“天垓100”;登临科技首款基于 GPU + 架构的 Goldwasser 系列产品已在领军企业中进行量产导入;芯动科技发布首款国产高性能4K级显卡GPU芯片“风华1号”;景嘉微发布旗舰GPU芯片 JH920;壁仞科技宣布首款通用GPU芯片BR100交付台积电生产;摩尔线程宣布首颗国产全功能GPU芯片研制成功。沐曦也曾透露2022年将推出首款自主研发的GPU芯片产品。
随着产品的推出、量产,未来国产GPU崛起势头也将越发强劲。
计算芯片“新贵”DPU
跟随GPU的脚步,DPU又称为中国大芯片的另一道风景线。其实这并不是一个新概念,亚马逊的Nitro系列更是给这个行业竖立了一个标杆。但在英伟达收购了网络解决方案厂商Mellanox并重新包装定义DPU,发布了首款产品后,DPU就背负着继CPU和GPU之后“第三颗主力芯片”的重任,宛如一匹黑马闯进了大家的视野,在国内均掀起新一波投资热潮。
根据公开信息统计,2021年芯启源、云豹智能、星云智联、大禹智芯、中科驭数、益思芯科技、云脉芯联等超7家DPU创新企业完成了超13轮融资,多笔融资金额达数亿元。芯启源、星云智联2021年完成了3轮融资,大禹智芯、中科驭数完成了2轮融资,益思芯科技、云豹智能、云脉芯联是1轮。

由于DPU市场仍处于发展初期,因此各厂商对定义众说纷纭。一般业界对DPU中的“D”有三种说法,分别是“Data”,对应的DPU被称为“数据处理器”;“Datacenter”,对应的DPU译作“数据中心处理器”;以及“Data-centric”,DPU可叫作“以数据为中心的处理器”。由NVIDIA提出的“Data Processing Unit”是目前主流的DPU定义,即是以数据为中心构造的专用处理器,采用软件定义技术路线支撑基础设施层资源虚拟化,支持存储、安全、服务质量管理等基础设施层服务。
5G时代的到来,使得网络发展速度一跃而起,网络性能正经历从10G向100G、向200G、400G甚至到800G不断快速提升的过程,原有技术架构进已无法满足网络爆发式发展的新需求,亟需一个新的专用系统来应对这新挑战。在此背景下,DPU应运而生,专注于负责数据处理功能单元,负责处理“CPU做不好,GPU做不了”的数据任务。
虽然当前DPU依旧被国际巨头占据技术和市场优势,但随着《新型数据中心发展三年行动计划(2021—2023年)》的发布,中国新型算力芯片业也迎来了发展新时期。
赛迪数据显示,得益于数据中心升级和边缘计算、新能源汽车、IoT、工业物联网等产业的发展所带来的需求增长,中国DPU产业市场规模呈现逐年增长的趋势,预计中国DPU市场将在2022-2023年迎来爆发式增长,并在 2024-2025年保持平稳。2020年中国DPU产业市场规模达3.9亿元,预计到2025年中国DPU产业市场规模将超过565.9亿元。
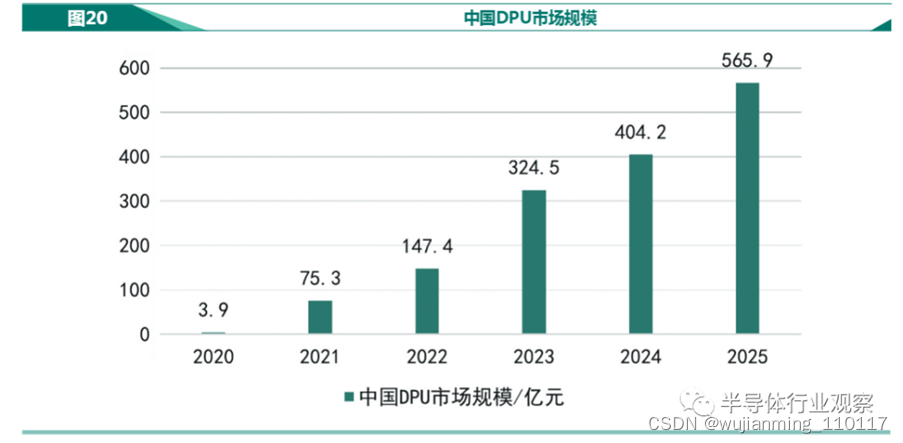
图片来源:2021年中国DPU行业发展白皮书
然而,从中国DPU市场的竞争格局来看,可谓百家争鸣。除了涌现出中科驭数、芯启源等一批创新企业外,阿里巴巴、华为在内的各大云服务商也都已经在布局自己的云端处理,追赶国内外的代际之差。2021年,国内DPU企业也已经踏上了探索商业化落地的道路。
阿里云宣布推出第四代神龙架构;中科驭数第二代DPU芯片预计2022年Q1投产流片;云豹智能发布全功能云霄DPU网卡;芯启源基于DPU的智能网卡亮相;大禹智芯第一代DPU产品Paratus V1.0亮相;益思芯科技交付DSA P4可编程vSwitch加速引擎。连2021年新成立的星云智联也表示完成初步芯片定义的工作。
就目前来看,DPU作为一个全新的、没有参考设计的系统,要做出优秀DPU产品和服务对国内DPU企业是一个不小的挑战,但依旧在为之奋斗。
从2021年整体情况来看,好赛道永远不缺资本,中国大芯片产业投资可观,玩家“输出”也强劲。无论是被巨头寡头垄断的GPU芯片,还是仍处于发展初期的DPU芯片,又或是在一定程度上可以与国外齐头并进的AI芯片,都显示出国产大芯片崛起势头正劲。
进入到2022年,国产大芯片的猛火还在持续燃烧,下一个可能爆发的点就在于Arm服务器芯片。有相关人士告诉笔者,国内现在已经有多家初创企业围绕这个领域进行布局。在今年十月,有一家名为遇贤微的初创企业就透露,准备推出采用4nm工艺的160核心Arm服务器芯片,国内几大云供应商在这个方面也跃跃欲试。除了Arm以外,采用其他架构的服务器芯片呼声现在又此起彼伏。
虽然上述赛道都热闹非凡,但需要注意的是,不管哪个赛道都只有拥有真正的技术、拿得出手的产品才能取得市场话语权,期待在未来五年能,能看到这些新秀企业带来更多的硬技术,展现真正的技术实力。
国产GPU的自主之路
1.国产GPU的发展历程
国产GPU的发展落后于国产CPU,直到2014年4月,景嘉微才成功研发出国内首款国产高性能、低功耗GPU芯片—JM5400。在国产GPU的开发中,GPU对CPU的依赖性和GPU的高研发难度,阻碍了该产业的快速发展。
首先,GPU对CPU有依赖性。GPU结构没有控制器,必须由CPU进行控制调用才能工作,否则GPU无法单独工作。所以国产CPU较国产GPU先行一步是符合芯片产业发展逻辑的。
再者,GPU技术难度很高。Moor Insights & Strategy首席分析师莫海德曾表示:“相比CPU,开发GPU要更加困难,GPU设计师、工程师和驱动程序的作者都要更少。”国内人才缺口也是国产GPU发展缓慢的重要原因之一。在芯片行业,培养一位拥有丰富经验并且能够根据市场动态及时修改芯片设计方案的成熟工程师,至少需要10年。
▲国产GPU公司及其业务简介
2.国产GPU因何走上发展快车道?
GPU作为计算机显卡的核心,承担着图像处理和输出显示的任务。随着市场需求的发展,GPU不止用于处理图形图像,技术原理决定了适用于大批量处理特定类型信息,并行计算能力和能效远远超过CPU,所以逐渐衍生出了通用计算GPU(GPGPU),即利用图形处理器进行非图形渲染的高性能计算。超算、大数据处理、人工智能等对算力要求非常高的应用场景中,算力大都采用CPU+GPGPU或搭配专用加速芯片的构建方式。
目前在集成GPU市场,英特尔、英伟达、AMD三分天下;独立GPU领域,几乎是英伟达和AMD的天下,前者市场份额甚至超出2/3。
2021年,英伟达市值首次超过英特尔,成为半导体业界的标志性事件,虽然不论营收还是利润,英特尔依然是英伟达的好几倍,但也足以说明,英伟达凭借多年来围绕GPU软硬件生态的耕耘、核心定位于数据中心+AI的方向得到了资本界的认可,进一步论证了GPU平台的潜力。
作为横跨视觉计算和人工智能计算的通用平台,GPU拥有巨大的市场空间。特别是因人工智能技术的发展,GPU作为核心算力基础,在科学计算、自动驾驶、智能分析、密码破解、图像识别、大数据、金融交易等云端计算及边缘计算领域有着海量的应用空间。正是如此,GPU发展驶入快车道。
GPU领域国产替代的市场空间超过50亿美元。除了既有的游戏市场,在工业、医疗、军事航天等方向都有进一步的发挥空间。
3.国产GPU替代的紧迫性
中国GPU市场规模和潜力非常大,庞大的整机制造能力意味着巨量的GPU采购。虽然近些年,计算机整机和智能手机产量增长都出现瓶颈,但由于这两类产品体量庞大,2019年国内智能手机出货量为3.72亿部,电子计算机整机年产量达到3.56亿台,GPU的需求量大且单品价值非常高,市场规模依然非常可观。
同时,服务器GPU伴随着整机出货的快速成长,需求量增长也较为迅速。据统计,2018年国内服务器出货量达到330.4万台,同比增长26%,其中互联网、电信、金融和服务业等行业的出货量增速也均超过20%。另外,国内在物联网、车联网、人工智能等新兴计算领域,对GPU也存在海量的需求。
据统计,近年来中国集成电路自给率不断提升,2018年为13%,预计2020年有望提升至15%,但仍然处于较低水平。根据国务院印发的《新时期促进集成电路产业和软件产业高质量发展的若干政策》等文件,中国芯片自给率要在2025年达到70%,这将产生8000亿元的国产芯片需求。中国芯片产业发展空间非常大。
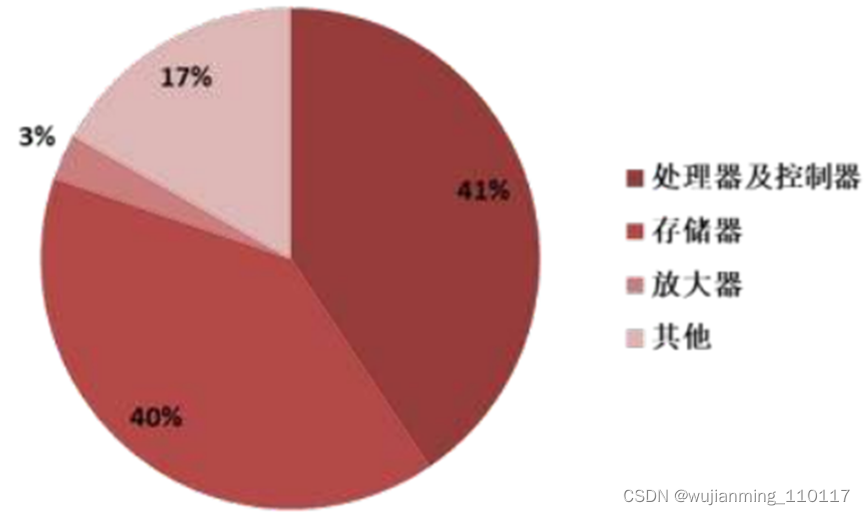
▲2019年中国大陆集成电路进口额结构

▲2012-2020年中国大陆集成电路自给率
国内GPU公司介绍
1、景嘉微:具有完全自主知识产权,打破国外GPU长期垄断
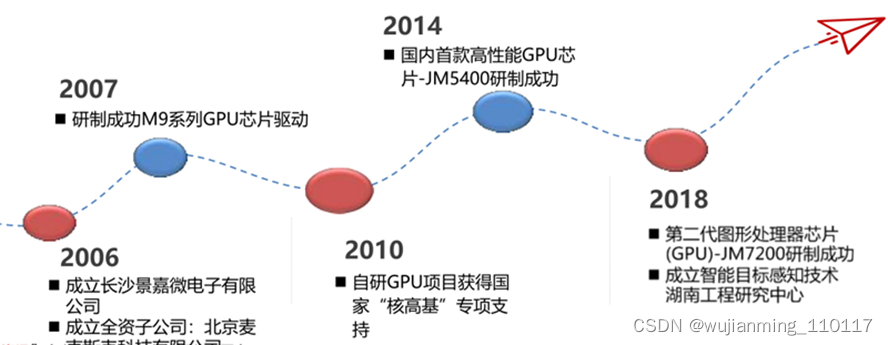
长沙景嘉微电子股份有限公司成立于2006年4月,位于长沙市高新技术开发区,公司拥有经验丰富的集成电路设计团队,是国产GPU的主要参与者,唯一自主开发并已经大规模商用的企业。
2014年4月,成功研发出国内首款国产高可靠、低功耗GPU芯片-JM5400,具有完全自主知识产权,打破了国外产品长期垄断中国GPU市场的局面,在多个国家重点项目中得到了成功的应用;
2018年8月,公司自主研发的新一代高性能、高可靠GPU芯片-JM7200流片成功,将国产GPU的技术发展提高到新的水平,可为各类信息系统提供强大的显示能力;
2019年,公司在JM7200基础上,推出了商用版本-JM7201,满足桌面系统高性能显示需求,并全面支持国产CPU和国产操作系统,推动国产计算机的生态构建和进一步完善。
▲景嘉微发展历程
景嘉微国产GPU芯片概述:
景嘉微已完成两个系列、三款GPU的量产应用,产品覆盖军用和民用两大市场。
景嘉微第一代GPU JM5400主要运用于军用市场,替代原ATI M9、M54、M72等美系GPU芯片。景嘉微第二代GPU JM7200在产品性能和工艺设计上较JM5400有较大提升,是首例进入民用市场的图形芯片。公司与国内主要CPU厂商和计算机整机厂商已建立合作关系。JM7201在JM7200的基础上对民用市场的桌面应用进行了优化,推出标准MXM和标准PCIE显卡,在保证性能的同时,降低了功耗,缩小了体积。

▲景嘉微国产GPU芯片产品线
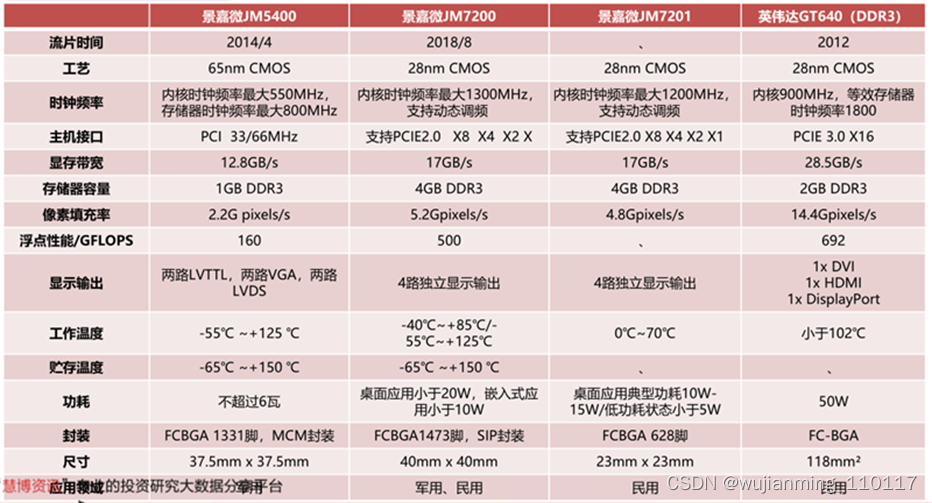
景嘉微国产GPU芯片性能详解:
景嘉微的第二代GPU JM7200系列于2018年8月流片成功,并在2019年3月获得首个订单。相较于前代JM5400,JM7200在理论性能上有翻倍的提升,同时制程也进化到了28纳米。但是JM7200在显存带宽、像素填充率、浮点性能等方面较2012年发售,采用完整版GK107核心的英伟达GT640还有相当差距。
▲各景嘉微GPU参数对比
景嘉微国产GPU后续研发:
2018年12月,景嘉微定增募集10.88亿元,用于高性能通用图形处理器和面向消费电子领域的通用类芯片研发和产业化项目。高性能通用图形处理器项目包括JM9231和JM9271两款GPU芯片,分别面向不同应用领域的中、高档系列产品。据公司2020年中报显示,下一代图形处理器研发处于后端设计阶段,研发进程一切顺利。
景嘉微JM9系列是继JM5400和JM7200局部渲染计算内核之后,首次采用统一渲染结构的GPU,增加了可编程计算模块数量。JM9231和JM9271在性能表现分别与英伟达于2016年推出的GTX1050和GTX1080相近。JM9系列的推出将使公司GPU水平与海外龙头水平缩短至5年,大幅提升公司在GPU领域的竞争力。
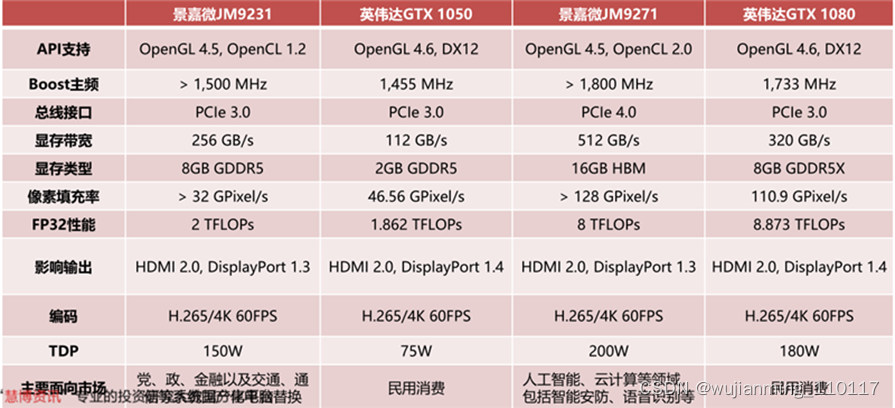
▲景嘉微后续高性能通用GPU性能参数对比
2、芯原微电子:国产GPU IP龙头
芯原微电子是依托自主半导体IP,为客户提供平台化、全方位、一站式芯片定制服务和半导体IP授权服务的企业。公司至今拥有高清视频、高清音频及语音、车载娱乐系统处理器、视频监控、物联网连接、数据中心等多种一站式芯片定制解决方案,以及5类自主可控的处理器IP,分别为图形处理器IP、神经网络处理器IP、视频处理器IP、数字信号处理器IP和图像信号处理器IP,以及1,400多个数模混合IP和射频IP,年均流片项目超过40个。主营业务的应用领域广泛包括消费电子、汽车电子、计算机及周边、工业、数据处理、物联网等,主要客户包括IDM、芯片设计公司,以及系统厂商、大型物联网公司等。
芯原在传统CMOS、先进FinFET和FD-SOI等全球主流半导体工艺节点上都具有优秀的设计能力,先进工艺制程覆盖14nm/10nm/7nm FinFET和28nm/22nm FD-SOI,并已开始进行5nm FinFET 芯片的设计研发和新一代 FD-SOI 工艺节点芯片的设计预研。
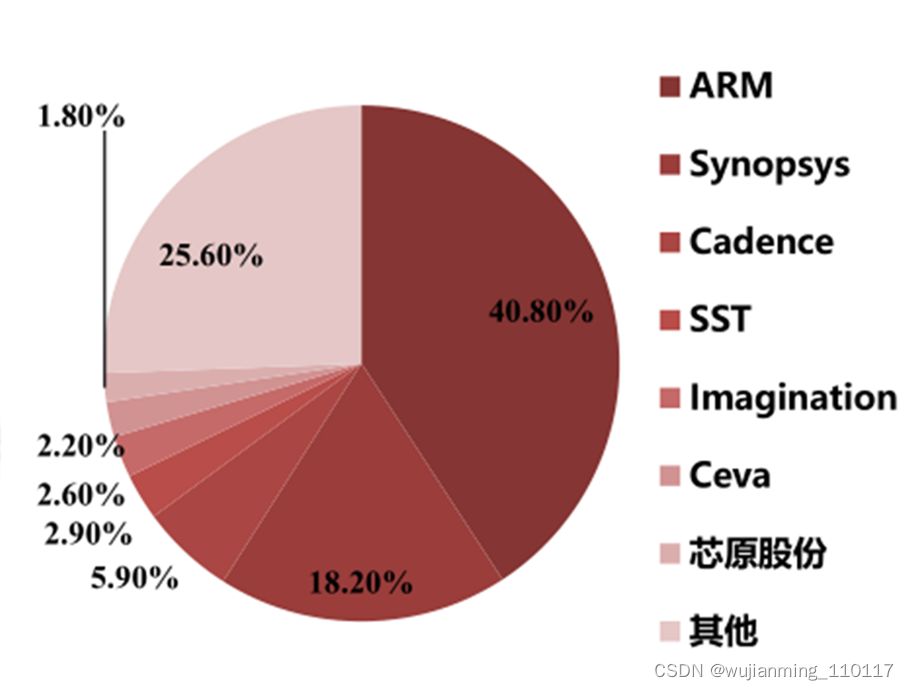
根据Ipnest统计,芯原是2019年中国大陆排名第一、全球排名第七的半导体IP授权服务供应商,全球市场占有率约为1.8%。
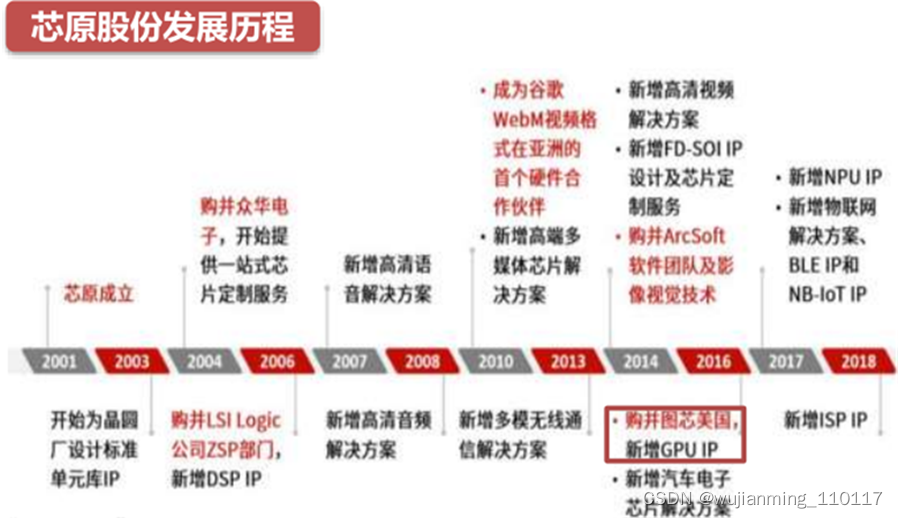
▲芯原股份发展历程
▲2019全球IP企业市占率排名
芯原GPU IP源于公司在2016年收购的美国嵌入式GPU设计商图芯技术(Vivante)。
芯原在GPU IP领域已经掌握了支持主流图形加速标准、自主可控指令集和可拓展性强,性能范围广泛等核心技术,可广泛应用于IOT、汽车电子、PC等市场。根据 IPnest 报告,芯原GPU IP(含 ISP)市场占有率排名全球前三,仅次于ARM和Imagination,2019 年全球市场占有率约为 11.8%。
目前,芯原在图形处理器技术的研发课题包括通用图形处理器运算内核的持续优化和矢量图形处理器DDR-Less技术。矢量GPU DDR-Less技术可以在不使用外部存储器DDR的基础上,实现架构清晰、分工明确、易于使用、软件控制流程简单等优点,适用于物联网、可穿戴设备和车载设备。
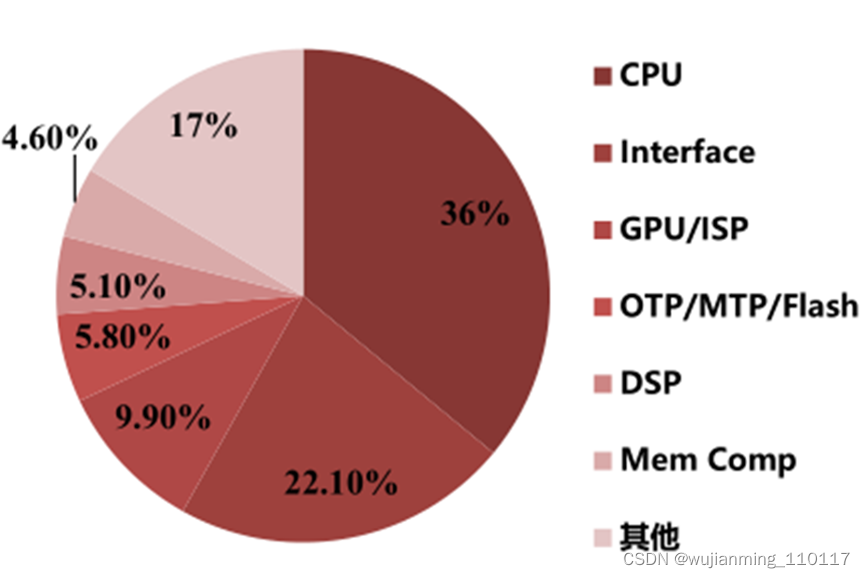
▲2019全球IP设计分类

▲芯原GPU IP的核心技术和典型应用示例
芯原可拓展Vivante GPU IP应用涵盖从低功耗的小型物联网MCU(GPU Nano IP系列)到面向汽车和计算机应用的强大SoC(GPUArcturus图形IP),可满足各种芯片尺寸和功耗预算,具有成本效益的优质图形处理器解决方案。
芯原的的图形处理器技术支持业界主流的嵌入式图形加速标准Vulkan1.0、OpenGL3.2、OpenCL1.2 EP/FP和OpenVX1.2等,具有自主可控的指令集及专用编译器,支持每秒2500亿次的浮点运算能力及128个并行着色器处理单元。
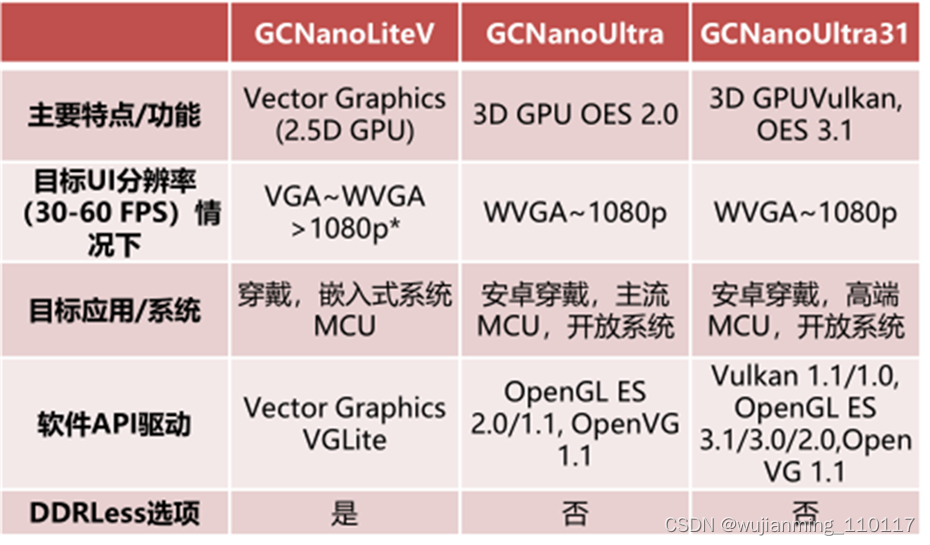
▲芯原GPU Nano IP产品线及其可应用场景
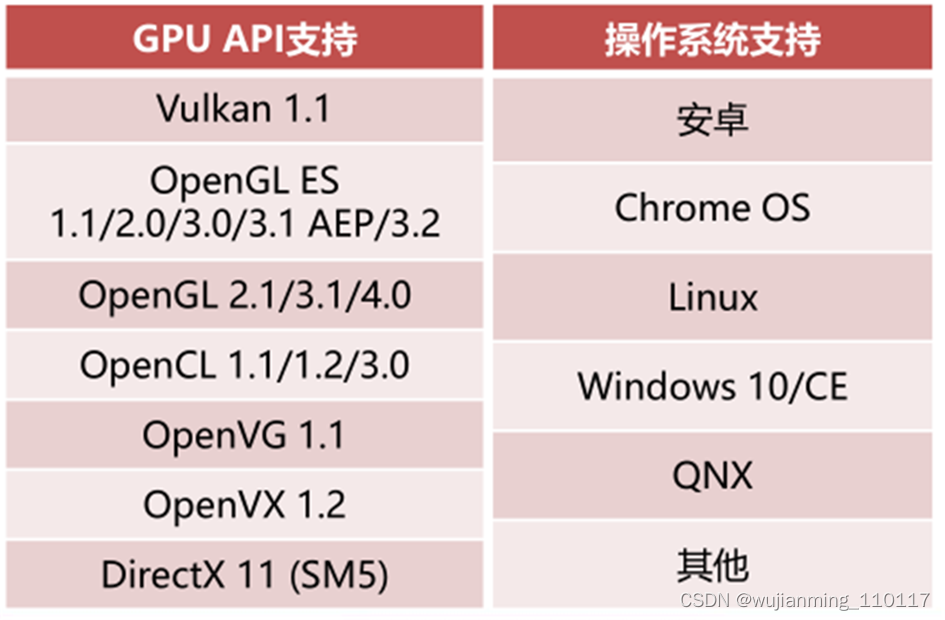
▲芯原GPU IP API和操作系统兼容性
芯原股份现有的半导体IP分为处理器IP、数模混合IP及射频IP,GPU IP隶属于处理器IP。
整体来看,2017-2019芯原得益于不断丰富的IP储备及一站式芯片定制业务的协同效应,公司半导体IP授权业务收入持续上升,GPU IP的年复合增速达13%。2019年GPU IP的营收占公司半导体IP营收的31.29%,主要由于其他类型IP收入上升,GPU IP比重相对下降。
芯原在图形处理器技术方面的研发包括高性能的通用图形处理器GC8400 IP,该IP适用于汽车电子,目前仍处IP设计验证阶段,拟达到每秒1万亿次的浮点运算能力双倍精密度,512个并行着色器处理单元 。
3、航锦科技
航锦科技是一家大型化工生产基地,公司的前身是锦西化工总厂。2017下半年,航锦科技通过收购长沙韶关和威科电子两家军工企业,挺进电子产业,形成化工+电子双主业发展模式,构建起三个支撑板块(化工、电子、金融)。
航锦科技电子板块以芯片为核心产品,围绕高端芯片与通信两大领域,覆盖高端芯片(图形处理芯片/特种FPGA/存储芯片/总线接口芯片)、北斗3芯片以及通信射频三大主要产业。坚持军民两用为发展方向,产品广泛应用于航空、航天、兵器、船舶、电子等领域,拥有广阔的市场空间。
航锦科技的GPU技术源于并购的长沙韶光。2018年,长沙韶光自主研发和合作研发的第一代及第二代图形处理芯片(GPU)获得集成电路布图设计登记证书;2019年,长沙韶光自主研发的第二代改进型图形处理芯片在自主可控设备领域的应用得到验证,并收获相关订单。
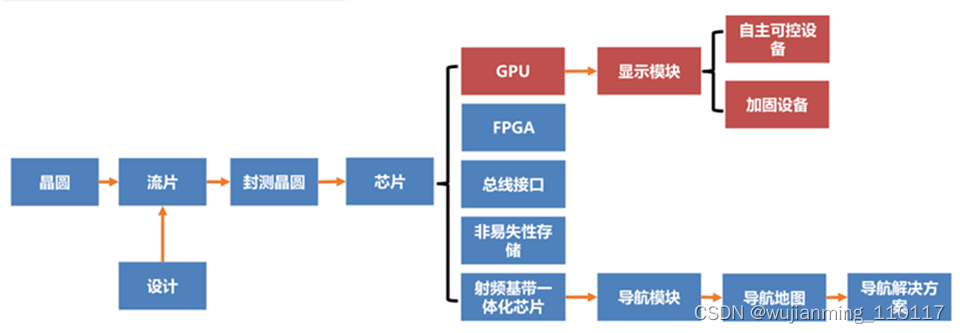
▲航锦科技自主可控芯片板块示意图
4、兆芯:同时掌握CPU、GPU、芯片组三大核心技术
上海兆芯集成电路有限公司,简称“兆芯”,由上海联合投资有限公司(上海市国资委完全出资)和中国台湾威盛电子共同成立,世界上第三家拥有X86授权的微处理器公司,总部位于上海张江,在北京、西安、武汉、深圳等地设有研发中心和分支机构。
公司同时掌握CPU、GPU、芯片组三大核心技术,具备三大核心芯片及相关IP设计与研发的能力,致力于通过技术创新与兼容主流的发展路线,推动信息产业的整体发展,并获评了“高新技术企业资质”。兆芯提供了桌面整机,服务器,工业主板,工业平台,系统级解决方案,在党政办公,交通,金融,能源,教育,网络安全方面有着广泛的应用。
兆芯KX-6000处理器:
2019Q2,兆芯发布了全新的用于PC的处理器KX-6000系列。KX-6000是业内第一款完整集成CPU、GPU、芯片组的SoC单芯片国产通用处理器。
KX-6000系列处理器采用16纳米制程,集成高性能显卡,支持DP/HDMI/VGA输出,兼容DirectX、OpenGL、OpenCL等主流API,最高可同时输出3台显示器,分辨率可达4K。
全新的KX-6000系列处理器拥有出色的兼容性和应用体验,包括Windows操作系统,日常办公应用,4K视频解码和主流游戏。

▲兆芯KX-6000系列兼容性和应用体验
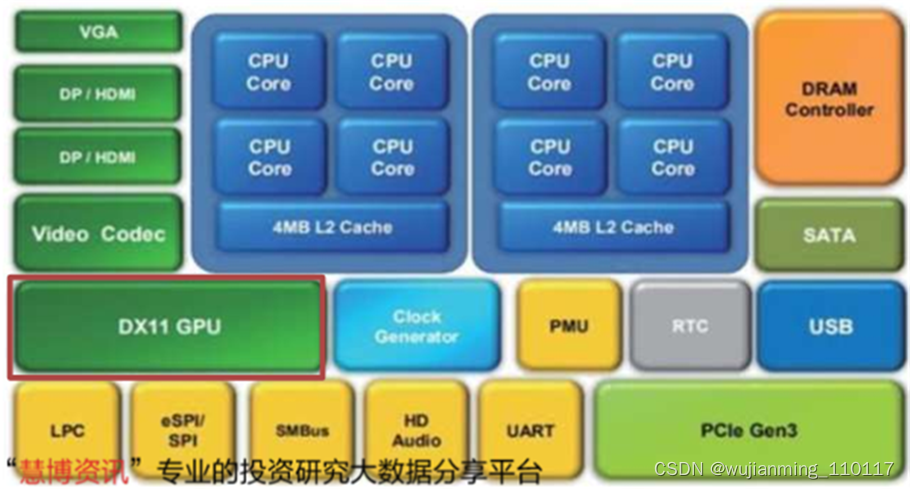
▲兆芯KX-6000处理器芯片架构
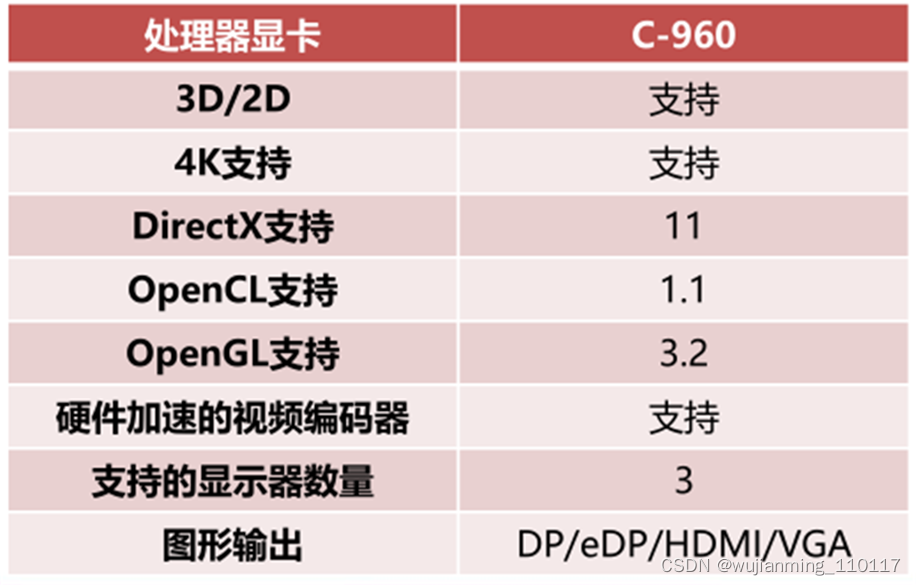
▲兆芯KX-6000处理器集成显卡参数
兆芯处理器的后续发展:
兆芯KX-6000的C-960 GPU在使用惠普兆芯图形DCH驱动的情况下,Dota 2游戏性能表现远落后英特尔酷睿i5-7400的UHD 630。未来,兆芯还会对KX系列处理器进行进一步的更新,使用全新的CPU架构,将内存从DDR4升级为DDR5,将总线从PCIe3.0升级至PCIe4.0。内存和总线的升级分别可以提高显卡的带宽和CPU与GPU间的通讯速度。
除了以上集成GPU外,兆芯还计划发布一款采用台积电28纳米工艺,TDP 70瓦的独立GPU。

▲兆芯KX6000 GPU游戏性能对比
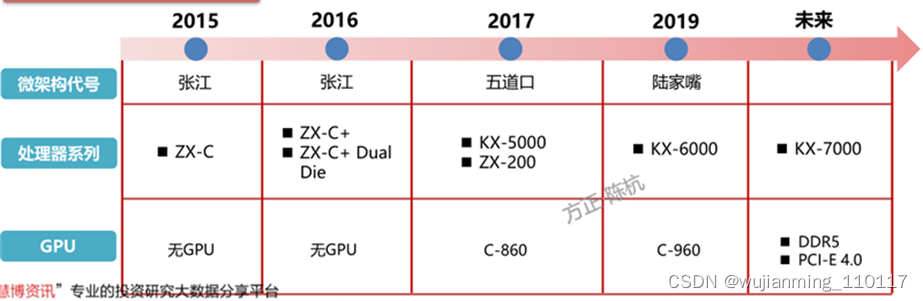
▲兆芯处理器发展路线图
5、凌久电子GPU
凌久电子创立于1983年,是中国船舶重工集团公司第七〇九研究所控股的高新技术企业。
凌久电子以嵌入式实时信号处理与高性能计算技术为基础,面向船舶、航空、航天、兵器等国防电子领域及轨道交通、海工装备、能源电力、半导体制造等民用高科技领域提供芯片级、模块级、设备级、系统级等软硬件产品;面向科研院所、部队及军校提供作定制化军事仿真服务。
凌久电子产品包括元器件类产品、基础硬件设备、基础支撑软件、应用类产品四大类。其中国产通用GPU GP101隶属于元器件类产品。
▲凌久电子平台产品
▲凌久电子元器件类产品分类
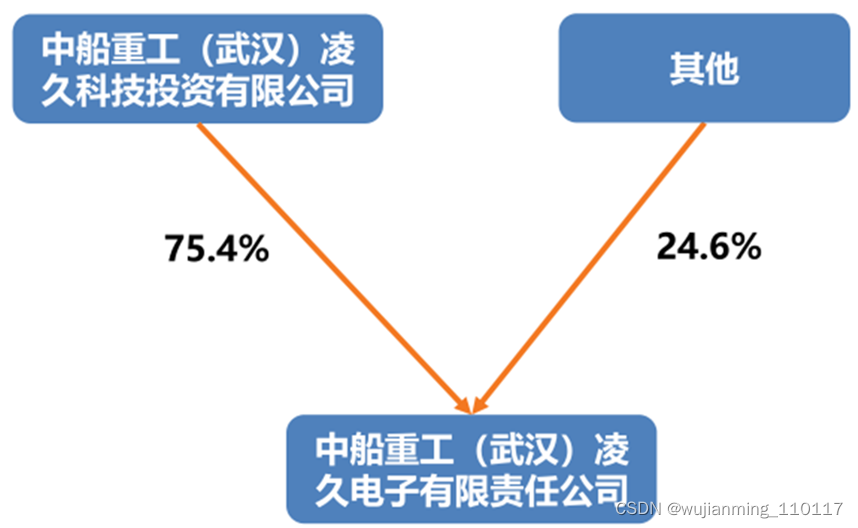
▲凌久电子股权结构
凌久电子GPU概述:
GP101是由中国船舶重工集团第709研究所控股的凌久电子研制,具备完全自主知识产权的图形处理器芯片。GP101支持2D/3D图形加速,支持二维矢量图形加速,支持4K分辨率、视频解码和硬件图层处理等功能。GP101支持VxWorks、Linux、Windows等通用操作系统,支持中标麒麟、道等国产操作系统,支持龙芯、飞腾、申威等国产处理器。
GP101实现了中国通用3D显卡零的突破,在信息安全和供货能力方便有充分的保障,可以广泛应用于军民多个领域。
6、中船重工716研究所:JARI G12 GPU
七一六所自主研发的JARI G12是2018年性能最强的国产通用图形处理器。该处理器采用混合渲染架构,兼顾数据带宽和渲染延时需求,极大地增强了芯片的灵活性和适应性;
• 提供PCIe 3.0总线,支持x86处理器和龙芯、飞腾、申威等国产处理器;支持4路数字通道和1路VGA输出,提供DP、eDP、HDMI、DVI等通用显示介面,单路数字通道最大输出分辨率为3840×2160@60fps,支持扩展、复制显示和“扩展+复制”显示模式;
• 内建视频编解码硬核,支持2路3840×2160分辨率视频的编码、解码功能;
• 支持OpenGL 4.5和OpenGL ES 3.0,满足高性能3D加速和VR显示需求;
• 支持OpenCL 2.0,满足并行计算和云计算的使用需求;
• 集成张量加速计算硬核,支持AI计算加速。该GPU支持Windows、Linux、VxWorks等主流操作系统,同时支持中标麒麟、JARI-Works、道等国内自主可控操作系统,具备健全的生态环境体系。
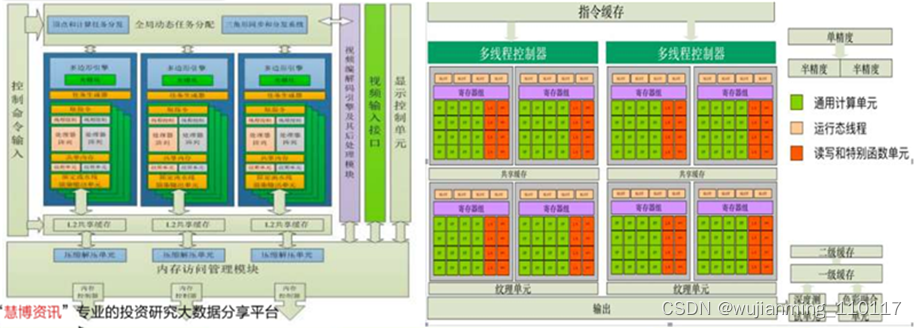
▲JARI G12架构示意图
7、芯动科技:国产IP和芯片定制先驱
芯动科技是中国一站式IP和芯片定制领军企业,提供全球6大工艺厂(台积电/三星/格芯/中芯国际/联华电子/英特尔)从130nm到5纳米全套高速混合电路IP核和ASIC定制解决方案,聚焦先进制程。
芯动科技15年来立足本土发展,所有IP和产品全自主可控,连续十年中国市场份额领先。公司客户群涵盖华为海思、中兴通讯、瑞芯微、全志、君正、AMD、Microsoft、Amazon、Microchip、Cypress等全球知名企业。
在高性能计算/多媒体&汽车电子/IoT物联网等领域,芯动解决方案具有国际先进水平,涵盖DDR5/4、LPDDR5/4、GDDR6/GDDR6X、HBM2e/3、Chiplet、HDMI2.1、32G/56G SerDes(含PCIe5/4/USB3.2/SATA/RapidIO/GMII等)、ADC/DAC、智能图像处理器GPU和多媒体处理内核等多种技术。芯动科技的芯片定制,跨工艺跨封装,涉及从需求到产品, 能端到端为客户加速从规格、设计到流片量产,及封装成型全流程。
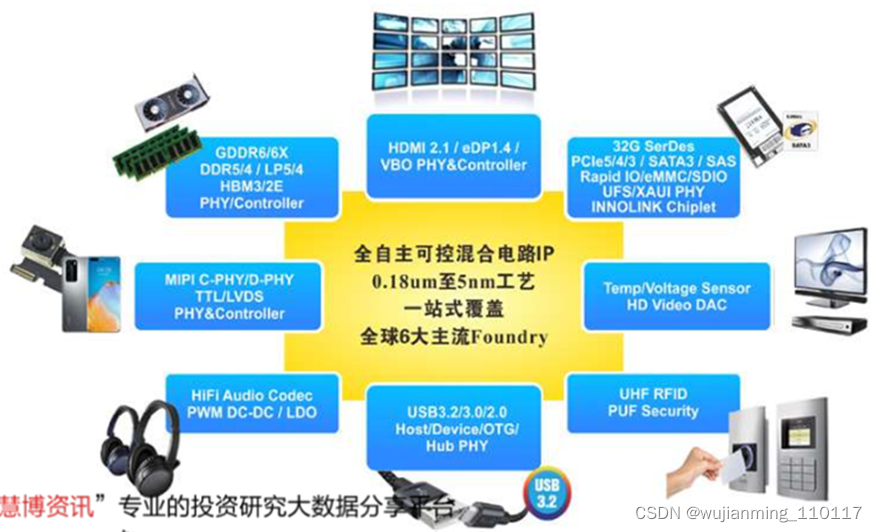
▲芯动科技一站式IP系列

▲芯动科技高性能计算平台IP
芯动科技携手Imagination,“风华”诞生:
2020年10月13日,芯动科技与Imagination达成合作。采用最前沿的多晶粒芯片(chiplet)和GDDR6高速显存等SOC创新,芯动科技将全球首发Imagination全新顶配BXT多核架构。
在信创和算力安全方面,“风华”系列GPU内置国产物理不可克隆iUnique Security PUF信息安全加密技术,提升数据安全和算力抗攻击性,支持桌面电脑和数据中心GPU计算自主可控生态。
“风华”系列GPU自带浮点和智能3D图形处理功能,全定制多级流水计算内核,兼具高性能渲染和智能AI算力,还可级联组合多颗芯片合并处理能力,灵活性强,适配国产桌面市场1080P/4K/8K高品质显示,支持VR/AR/AI,多路服务器云桌面、5G数据中心、云教育、云游戏、云办公等中国新基建5G风口下的大数据图形应用场景。
8、华为海思:GPU Turbo
GPU Turbo是一种软硬协同的图形加速技术,可以减少无用渲染次数,优化或合并渲染区域。通过算法,将相关运算放在一个或相邻的寄存器中,以此来优化图形处理效率。
GPU Turbo技术打通了EMUI操作系统以及GPU和CPU之间的处理瓶颈,在系统底层对传统的图形处理框架进行了重构,实现了软硬件协同,使得GPU图形处理整体效率得到大幅提升。
2018年6月发布了GPU Turbo 1.0,图形处理效率提高60%,同时做到更省电,保证高画质。
2018年9月发布了GPU Turbo 2.0,游戏场景下功耗下降可达13.6%,新增支持多款主流游戏,同时针对支持的游戏中关键&极限场景(如团战、载具等)进行了重点打磨与优化。
2019年4月GPU Turbo全新升级,不仅带来主流游戏接近满帧运行的酣畅体验,功耗的持续降低也带来了续航时间的提升。累计支持60款国内游戏。
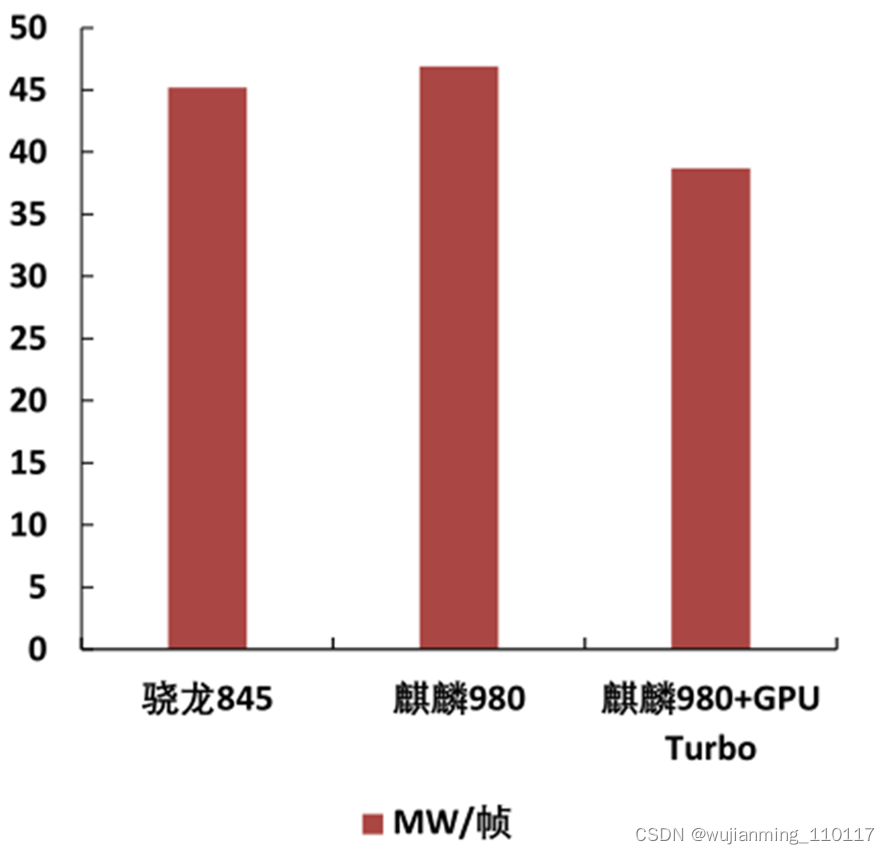
▲GPU Turbo 2.0能效对比
9、龙芯:GPU突击队
中科院计算所于2001年成立龙芯课题组,开始研制龙芯系列处理器,得到了中科院、863、973、核高基等项目大力支持,完成了十年的核心技术积累。2010年4月,中国科学院和北京市共同牵头出资入股,成立龙芯中科技术有限公司,龙芯正式从研发走向产业化。
目前,龙芯自主研发的GPU集成在7A1000桥片中。龙芯7A1000桥片是面向龙芯3号处理器的芯片组,通过HT3.0接口与处理器相连,集成GPU、显示控制器和独立显存接口,外围接口包括32路PCIE2.0、2路GMAC、3路SATA2.0、6路USB2.0和其它低速接口,可以满足桌面和服务器领域对IO接口的应用需求,并通过外接独立显卡的方式支持高性能图形应用需求。
虽然龙芯7A1000桥片的GPU性能一般,但是桥片作为CPU产业链的一环,龙芯已经实现CPU、桥片和GPU上完全自主化,打通了CPU产业链上每一个环节。
2020年,龙芯成立六支研发突击队,分别为3A5000突击队、3C5000突击队、7A2000突击队、2K2000突击队、GPU突击队、PCIE突击队。这六支突击队的目的就是要把2-3年的工作,在一年内干完!
▲龙芯7A1000
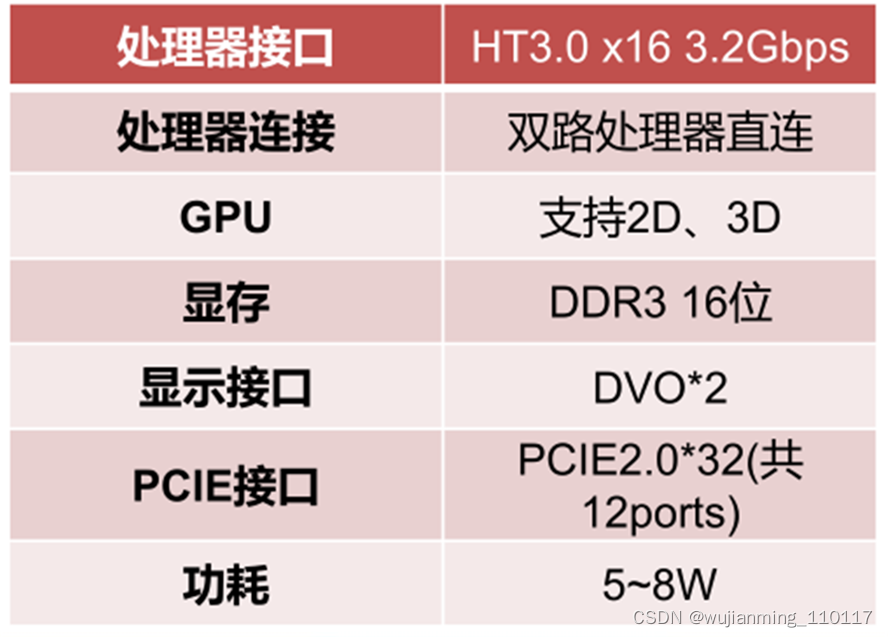
▲龙芯7A1000 GPU相关参数
10、芯瞳半导体:高性能GPU设计新星
芯瞳半导体成立于2019年,主要业务包括GPU芯片设计、异构计算平台方案、嵌入式显示系统解决方案、GPU应用部署解决方案。公司着力于研发高性能的GPU芯片,为用户提供以自研GPU芯片为核心的解决方案,致力于打造业界领先的GPU芯片设计平台,目标是成为国际一流的GPU芯片设计企业。公司创始团队在GPU领域有着超过10年的学术和工程经验,是一支软硬件全栈式支持的研发团队。
公司的GPU架构采用了业界主流的统一渲染架构,并具有高度可扩展的互联结构和计算阵列,便于芯片后续迭代升级。经过多年的积累,团队构建了芯片建模虚拟平台,通过该虚拟平台,团队可以快速地完成GPU相关软件的研发和软件生态的部署,与此同时,在该虚拟平台上快速地对芯片架构进行验证,从而缩短GPU芯片的设计验证周期,提升GPU芯片的设计效能。
公司第一代GPU芯片(GenBu01)初测已成功,已与统信、麒麟及昆仑完成适配,目前正在为小批量量产做最终测试。GenBu01主要面向的客户为需要定制嵌入式计算机产品的客户以及为国产替代领域提供信创办公PC的ODM/OEM厂商。
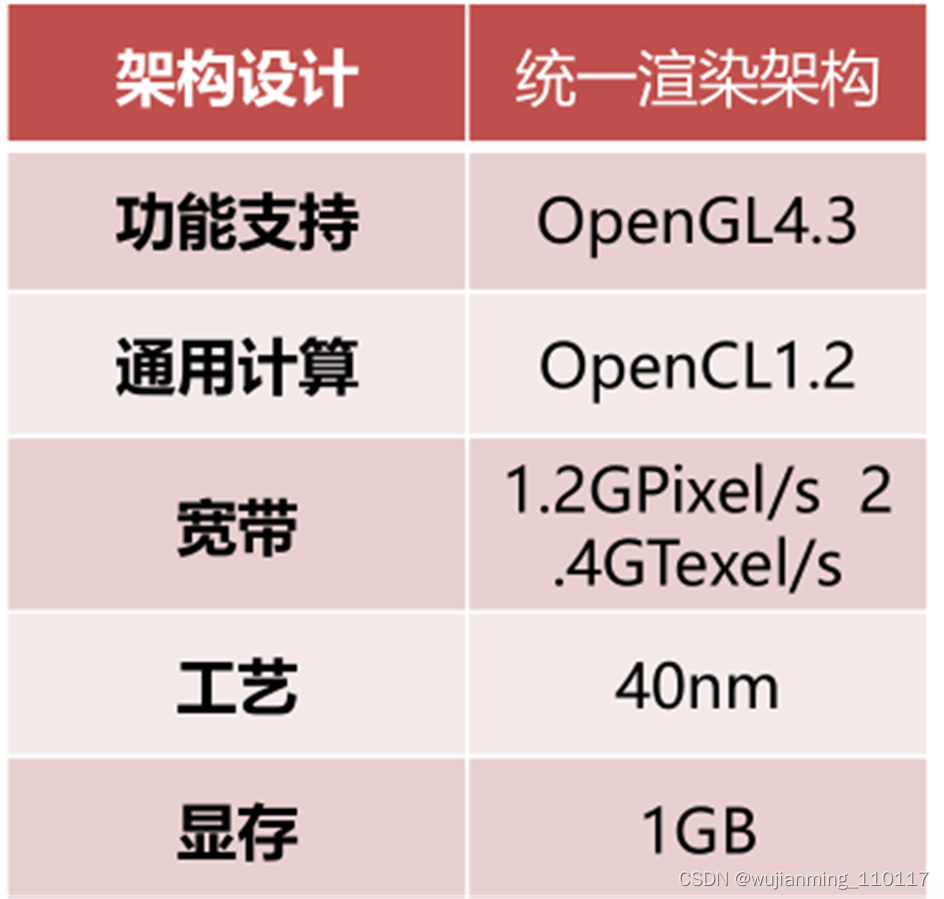
▲芯瞳GenBu01参数
11、天数智芯:国产GPGPU领跑者
天数智芯于2018年正式启动GPGPU芯片设计,是中国第一家GPGPU高端芯片及超级算力提供商。天数智芯重点打造自主可控、国际一流的通用、标准、高性能云端计算芯片GPGPU,从芯片端解决计算力问题;并推出面向5G技术需求的边缘云端推理GPGPU,提供对当前进口主流GPGPU体系的无缝兼容和市场化选择。
2021年1月15日,天数智芯成功点亮自研7纳米制程GPGPU云端训练芯片,性能达市场主流产品的两倍。该芯片量产后将广泛应用于AI训练、高性能计算(HPC)等场景,服务于教育、互联网、金融、自动驾驶、医疗、安防等各相关行业,赋能AI智能社会。
天数智芯7纳米GPGPU高端自研云端训练芯片的产品优势包括:全方位生态兼容、高性能有效算力、指令集编程架构、软硬件全栈支持、全自主知识产权。
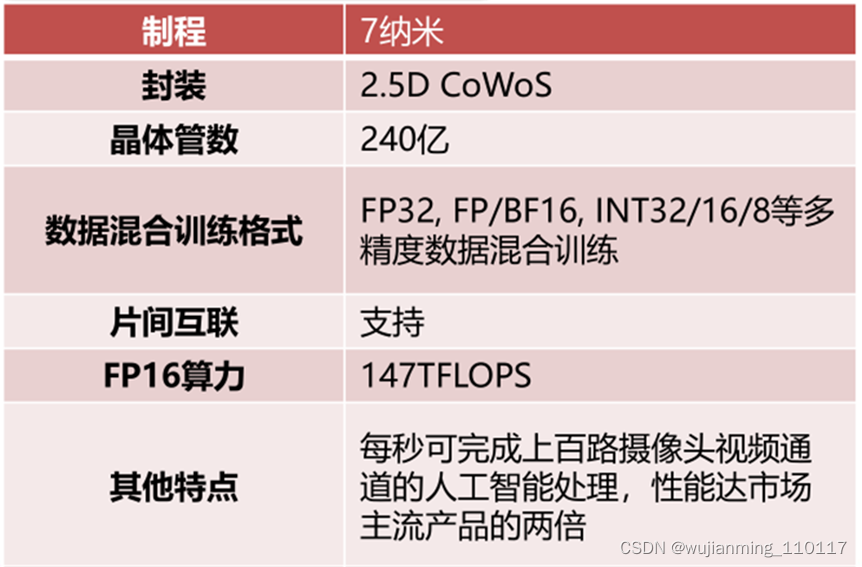
▲天数智芯GPGPU BI芯片参数
12、国产GPU新星:壁仞科技和沐曦集成电路
壁仞科技创立于2019年,团队由国内外芯片和云计算领域核心专业人员、研发人员组成,在GPU、DSA(专用加速器)和计算机体系结构等领域具有深厚的技术积累和独到的行业洞见。
壁仞科技致力于开发原创性的通用计算体系,建立高效的软硬件平台,同时在智能计算领域提供一体化的解决方案。从发展路径上,壁仞科技将首先聚焦云端通用智能计算,逐步在人工智能训练和推理、图形渲染、高性能通用计算等多个领域赶超现有解决方案,实现国产高端通用智能计算芯片的突破。
沐曦集成电路专注于设计具有完全自主知识产权,针对异构计算等各类应用的高性能通用GPU芯片。公司致力于打造国内最强商用GPU芯片,产品主要应用方向包含传统GPU及移动应用,人工智能、云计算、数据中心等高性能异构计算领域。
对于研发的方向,沐曦表示将采用业界最先进的5nm工艺技术,研发全兼容CUDA及ROCm生态的国产高性能GPU芯片,满足HPC、数据中心及AI等方面的计算需求。GPU将采用原创专利保护的可重构GPU架构,突破传统GPU芯片能效瓶颈;采用数据压缩,数据广播以及共享硬件加速单元等先进技术,大幅度优化核心算力能耗比。

▲沐曦高性能GPU研发项目
12、国产GPU新星:登临科技和摩尔线程
登临科技成立于2017年11月,是一家专注于为新兴计算领域提供高性能、高功效计算平台的高科技企业。公司的产品是以芯片为核心的系统解决方案,在所有核心IP上坚持自研路线。登临科技已完成由元禾璞华、元生资本联合领投的A+轮融资,包括北极光在内的老股东持续在本轮加码跟进。登临科技的首款GPU+(软件定义的片内异构通用人工智能处理器)产品已成功回片通过测试,开始客户送样,公司团队具备架构、系统、软件、硬件、芯片、验证等方面的综合能力。
登临科技GoldwasserTM GPU+产品在现有市场主流的GPU架构上,创新采用软硬件协同的异构设计。GPU+异构设计让产品在对客户实际业务继承在现有生态上的投入、在保证极高兼容性的同时,相比传统GPU在AI计算上性能和能效均有明显提升,大大降低了外部带宽的需求,显著降低客户总拥有成本。
摩尔线程创立于2020年10月,去年12月获得天使轮融资,今年2月22日获得Pre-A轮融资。摩尔线程致力于构建中国视觉计算和人工智能领域计算平台,研发全球领先的自主创新GPU知识产权,其GPU产品线覆盖通用图形计算和高性能计算。公司核心成员主要来自英伟达、微软、英特尔、AMD、ARM等,覆盖GPU研发设计、生产制造、市场销售、服务支持等完整架构。
13、国产GPU新星:翰博半导体
翰博半导体成立于2018年12月,立志于发展成为国际顶尖的芯片公司,立足于中国市场,填补国内市场国产芯片的空白,为智能应用提供高效算力,为人工智能创新以及应用落地赋能。
翰博半导体拥有国内外专家组成的团队。公司核心员工来自世界顶级的高科技公司,平均拥有15年以上的相关芯片,软件设计经验。
瀚博的产品注重计算机视觉及视频处理的优化,提供丰富的特性,高效的性能/功耗;适用多个人工智能领域。产品覆盖从边到云,SOC及服务器市场。
翰博半导体CEO—钱军拥有25年以上高端芯片设计经验和40多款芯片设计和量产的经验,带队设计量产业界第一颗7纳米图像处理器和AI服务器芯片,曾任AMD高管Senior Director,直接负责设计团队超过800人,全面负责GPU( 图像处理器和AI服务器)芯片设计和生产,现在市场上所有AMD Radeon图像处理器和AI服务器都是由其带队开发,包括多个系列DGPU和MI系列产品。
14、国产GPU新星:燧原科技
燧原科技成立于2018年3月,专注于人工智能领域云端算力平台,致力为人工智能产业发展提供普惠的基础设施解决方案,提供自主知识产权的高算力、高能效比、可编程的通用人工智能训练和推理产品。
燧原科技的产品技术由训练、推理、软件平台构成。其中,训练业务包含加速卡 “云燧T10” 和“云燧T11”;推理业务包含加速卡 “云燧i10”;软件平台包含“驭算”。
“云燧”系列加速卡采用自研DTU架构,支持ESL高速互联和开放生态。“云燧”芯片采用格罗方德的12nm FinFET工艺,结合 2.5D先进封装,拥有141亿晶体管和16GB HBM2显存,在FP32的算力和能效比方面领先GPU。
计算及编程平台“驭算”,由燧原自主研发,支持主流深度学习框架,并针对邃思芯片进行了针对性优化。
国产GPU发展热潮下的思考:
中国发展高端GPU有一定的紧迫性和必要性:
• 其一,在GPU当前应用最为突出的人工智能领域,已经进入大规模落地阶段,中国大部分AI芯片创业公司都在推理市场进行布局。一个重要拐点可能在2022年出现,届时云端推理市场规模将超过云端训练。
• 在国内企业喜迎推理市场大爆发之时,有一个基本点值得重视:进行推理应用的AI模型首先是在算力更强劲的云端被训练出来的。如果训练端被英伟达这样的巨头所垄断,那么下游推理的落地、创新,是否会受到限制?
• 其二,英伟达收购Arm的消息从去年开始一直受到全球范围内的关注,如果这桩交易成功,意味着一家几乎“全能型”的算力企业的诞生:无论是高端通用算力,还是移动计算、物联网,都将处于一家全面占据市场垄断地位的美国企业掌握中,对全球乃至中国市场的影响是什么?
在种种技术趋势和大国竞争的背景下,国产GPU不论是产品规划还是资本介入,都已进入白热化阶段。但越是花团锦簇,越要警惕乱花迷眼,适当的“冷”思考有益身心:
第一,没有实际产品却被资本高度重视,“高配”创业团队是当前的核心优势,摩尔线程、壁仞、沐曦……都在演绎着创始成员名字撑起高估值的创富故事。
但是长远来看,芯片技术最终还是需要经年累月的迭代和优化。巨大的研发费用和资本开支是必需,但是下游产业链长期、持续的利润支撑才是芯片跨代发展的强力驱动。芯片的成功和成熟需要大量的验证和出货,找到可持续的落地场景才是长期发展的关键驱动力。
中国在高端GPU领域缺席多年,目前如景嘉微等,正处于从军用向信创、民用市场的拓展阶段,高端GPU业务从战略布局成长为核心支柱还有漫长的征途。
第二,天数智芯、登临等宣布产品“点亮”,固然是国产GPU的一大喜事,但也需要保持清醒,“点亮”只是研发成功,最重要的还要批量生产、落地,离最终的成功还有十万八千里路。
一位业内人士表示,国产GPU要在云端训练这个英伟达处于绝对垄断的主战场进行对抗,面临的挑战非常艰巨,几大公有云厂商包括浪潮等基本都是采用英伟达的产品,服务器需要系统级的稳定性,不是光搞个加速卡就可以大规模上量的,服务器厂商不会轻易切换新硬件,因为风险太大了。
第三,在GPU领域,英伟达耕耘多年的CUDA开发者生态,也是英伟达生态的核心,很多深度学习的加速库都是基于CUDA,并且是和英伟达的硬件深度绑定的,这是创业公司难以撼动的壁垒。
国产GPU如天数智芯、登临等,在产品路线上选择兼容CUDA。在与一位GPU方向的从业者交流时,认为:“短期来看,国产GPU兼容CUDA更容易发展,毕竟写算子是人力密集型行业,用户迁移的话是需要100%迁移、整套代码都要在片上跑,如果代码量很小,需要的算子不那么多,难度就比较低。但是长期来看,还是要摆脱兼容思路,发展自有的核心技术。”不过随后打趣,“短期和长期的界定不是很好区分,有可能像凯恩斯说的‘长远来看,都死了’,先活下来是硬道理。”
GPU只是半导体产业高歌猛进的一个缩影。在与一位投资人谈起芯片领域的融资进度和规模时,不无感慨地说道,“芯片投融资今年可能会更多,以往融资还有个PPT,接下来可能有些连PPT都没有。”
先不说有没有实际产品,最重要的是未来的软件和开发者生态,这才是大规模商用的前提。国产GPU何时能够真正突围成功?
芯片设计行业,年薪百万以上已经很正常了
俗话说“兵马未动粮草先行”,在半导体产业,人才就是发展的“粮草”。

目前芯片设计行业,资深工程师(硕士毕业8-10年以上)年薪百万以上已经很正常了。
外企大厂:
6月17日,市场研究机构TrendForce集邦咨询发布了2021年第一季度全球十大IC设计公司营收排名。完整排名为:高通、英伟达、博通、联发科、AMD、联咏科技、赛灵思、瑞昱半导体、Marvell、Dialog。其中,美国占据六家,中国台湾三家,英国一家。
有行业内网友在知乎透露,IC设计外企大厂其管理岗:Director及以上,薪资股票总包一定可以达到年薪百万,甚至部分Senoir Manager都可以达到;技术岗:Principal及以上,薪资可以达到年薪百万。
大陆一线大厂:
大陆公司一线大厂包括:海思,oppo,阿里平头哥等。有网友透露,年薪百万的级别如下:
• 华为海思:土著17A及以上基本上都是破百万了,社招19C也要百万以上了;
• 阿里(平头哥):P7加股票的话可能在百万左右了,P8是肯定百万以上;
• oppo(哲库):13-3应该是在百万左右,14肯定百万+;
• 一些AI/GPU公司也给得很高,比如壁仞、沐曦、瀚博、摩尔线程、希姆科技等,技术专家角色基本上都是百万+;
• 从职级来说,到了技术专家(Principal)、总监(Director)基本上都可以达到百万年薪。
• 从年限来说,硕士毕业12年左右不少人可以拿到这样的薪酬了,优秀的毕业8年也可以达到。但主要还是得看技术方向、技术水平、公司平台等各方面因素。
芯片行业现在增长很快,因此带动大量岗位需求,
芯片设计岗位对当前待遇不满意,觉得没有发展的工程师,多出去面试面试看看外面的机会,跳槽一般都会有个25%-30%以上的涨幅,那些当前待遇低的,甚至能达到涨幅50%-100%,毕竟目前需求形势不错。
尤其是类似芯片,新能源汽车这些快速发展和扩张的行业,一定要经常的去了解行业的薪资行情,因为快速发展的行业薪资变化相对其他行业会更快,知道外部公司的情况对个人发展会很有帮助,信息就是金钱,这个这里就不展开了。
总之芯片行业是目前中国最大的一个高薪岗位增量行业了,给中国广大的理工科毕业生带来了很多机会,不过现在只是设计行业起来了,制造还不行,现在国内芯片制造的工资是台企台积电最高,包括南京和上海台积电,这是不正常的,哪个行业如果是台企工资最高,说明这个行业薪资有极大的增长空间,因为台企的分配体系是:欧美股东–台湾员工–大陆员工,希望芯片制造业的待遇也涨起来,不过这需要本土龙头企业有个带头作用。
35家国产处理器芯片(CPU/GPU/FPGA)厂商调研报告
国产CPU
国产CPU处理器主要面向PC、服务器、嵌入式系统、手机和平板、安防监控、汽车,以及视频和多媒体处理等应用市场。AspenCore分析师团队汇总了16家国产CPU芯片厂商,其中包括:
• PC/服务器CPU:北京龙芯、上海兆芯、电科申泰、天津飞腾和海光;
• 基于Arm架构的服务器CPU:天津飞腾、华为海思的鲲鹏和阿里平头哥的倚天;
• 手机AP:海思麒麟和紫光展锐虎贲;
• 平板/多媒体和视频处理SoC:全志科技、瑞芯微、北京君正、晶晨半导体
• 安防/视频处理SoC:国科微、中星微
• 嵌入式CPU:苏州国芯
POWER架构CPU:合芯科技这16家国产CPU芯片公司中,有一半已经是上市公司,最新科创板上市的有龙芯中科与国芯科技,海光信息IPO也已获上交所受理。资本市场的支持将进一步推动国产CPU在信创、工业及信息安全应用领域的发展,也有助于CPU厂商提升研发技术实力,并建设和扩展各自的生态系统。
龙芯中科的龙芯系列CPU包括面向行业应用的“龙芯1号”小CPU、面向工控和终端类应用的“龙芯2号”中CPU,以及面向桌面与服务器类应用的“龙芯3号”大CPU。2021年龙芯中科发布了完全自主指令集架构–LoongArch,基于该架构的龙芯3A5000单核性能提升50%,功耗降低30%,与国内CPU产品相比在性能上优势明显。
基于开放的龙芯生态体系,该公司与板卡、整机厂商及基础软件、应用解决方案开发商建立起紧密的合作关系,为下游企业提供基于龙芯处理器的各类开发板及软硬件模块。龙芯中科可以提供32位、64位单核、多核和不同质量等级的处理器及配套芯片,搭载的Loongnix、LoongOS两大系统软件可以适应不同的应用场景。
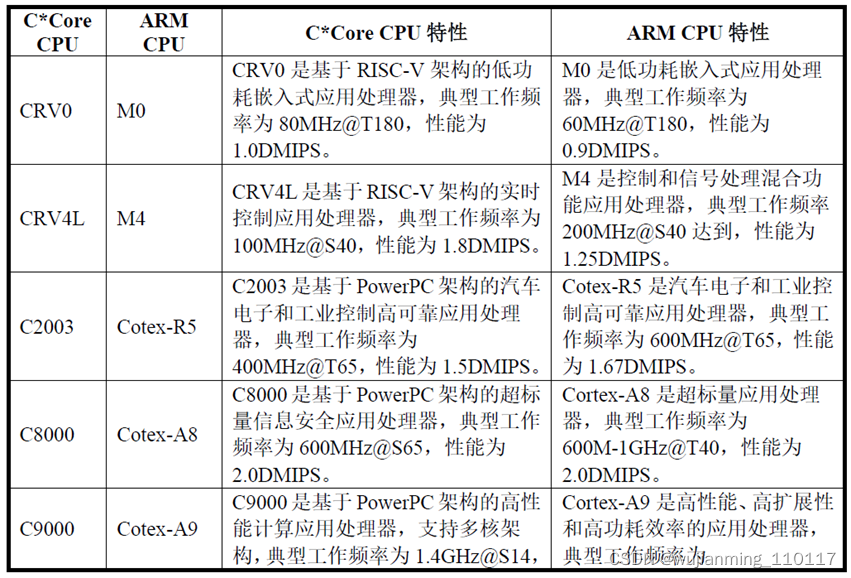
苏州国芯科技基于自主可控的嵌入式CPU 技术,以及面向信息安全、汽车电子和工业控制、边缘计算和网络通信三大关键应用领域的芯片定制服务,设计开发出一系列自主芯片及模组产品。该公司基于M*Core、PowerPC和RISC V三大指令集,提供具有自主知识产权的8大系列40余款CPU核,其主要嵌入式CPU内核与Arm内核对比如下:
国产GPU
相对于国产CPU,国产GPU发展更晚,涉及GPU处理器研发的厂商也比较少,国产GPU的性能跟英伟达、AMD和英特尔等全球领先GPU芯片还相距甚远。然而,最近几年GPU在AI应用方面的独特优势,加上资本的追捧,带动了国产GPU的创业热潮。壁仞科技、瀚博半导体和摩尔线程等GPU/AI芯片初创公司融资高达数10亿元,吸引了英伟达和AMD等国际厂商技术人才的加盟,也将推动国产GPU这一高性能芯片细分市场的竞争和发展。
AspenCore分析师团队汇总了9家国产GPU芯片厂商,其中包括:
• 图形处理/渲染GPU:景嘉微、芯动科技、芯瞳半导体、摩尔线程
• 通用计算GPU:天数智芯、登临科技、摩尔线程、壁仞科技
• AI加速GPU:天数智芯、瀚博半导体、壁仞科技、沐曦集成电路
这9家国产GPU厂商中,只有景嘉微是上市公司,芯动科技具有多年的定制芯片设计经验,其他公司都是初创型企业,但都获得了相当可观的风投融资(其中摩尔线程、壁仞科技和瀚博半导体的累积融资金额均超过20亿元)。
芯动科技于2021年底发布的“风华1号” GPU采用12nm 工艺,支持GDDR6 / GDDR6X(最大速率 19Gbps),容量可选 4GB / 8GB / 16GB,支持 HDMI2.1 / DP1.4 /VGA 多路独立输出,支持 X86、ARM、龙芯等指令集;支持 Linux、安卓、麒麟、统信UOS等操作系统;支持鲲鹏 / 安培等服务器平台。“风华1号”分为A型和B型两款,具体性能指标如下图。

天数智芯的7nm通用并行(GPGPU)云端训练芯片BI于2020年12月成功 “点亮”。基于这种全自研通用计算GPGPU芯片,天数智芯的硬件产品聚焦于云端训练及推理,通过自研指令集释放强大的可编程性与应用通用性,提供业界领先的AI算力密度与能效比。具有针对云端AI训练和HPC通用计算设计的软硬件架构;支持浮点、定点多种精度数据类型;提供超高带宽的本地存储和片间互联扩展。天数智芯可支持ResNet、Vgg、Inception、Alexnet、SSD、Mask R-CNN等通用计算机视觉相关网络模型;提供生态兼容的软件套件;支持多精度数据类型标准&混合训练,支持模型深度优化。
国产FPGA
最近赛灵思被AMD成功收购,这意味着FPGA难以成为一个有规模的独立市场,只能作为高性能计算领域的一种专用处理方式。然而,在5G、工业控制和专用细分应用领域,FPGA仍然有CPU/GPU/AI芯片无法替代的优势。国产FPGA厂商的整体技术实力跟英特尔和赛灵思等国际厂商还有相当的差距,但在中低性能的FPGA市场已经看到几家国产厂商的身影。
AspenCore分析师团队汇总了11家国产FPGA厂商,其中安路科技、紫光国微和复旦微电是上市公司,尽管FPGA业务在紫光国微和复旦微电的总营收中占比不是很大。除了传统FPGA外,还有一些厂商基于FPGA开发出特定应用的软硬件处理方案。比如,易灵思基于Quantum技术的FPGA对“功耗-性能-面积”(PPA)的优化高达4倍,其独特的设计架构可轻松扩展至百万以上逻辑单元(LE)密度,其车规级16nm FPGA针对新能源汽车中的自动驾驶、智能座舱和电气化应用。
联捷科技研发基于FPGA的数据中心图像视频等多媒体异构计算解决方案,可将性能和效能提升一个数量级,已获得美国及中国专利。联捷科技高吞吐、低时延的FPGA图像处理加速技术解决方案目前已经广泛应用于智能手机云应用、云存储和在线视频网站等市场。
最近在科创板上市的安路科技在FPGA芯片架构方面,已经开发出支持高达600K 逻辑阵列容量的PHOENIX 第一代FPGA 架构,现正开发支持1KK 以上级别逻辑容量、具有良好阵列扩展性的PHOENIX2 第二代FPGA 架构。在系统集成方面,该公司在第一代小容量FPSoC 芯片基础上,将从低功耗和高性能两个方向布局下一代FPSoC 芯片,集成CPU、FPGA和专用数据处理模块,以满足未来应用市场趋势。
在专用EDA 软件方面,安路科技的TangDynasty (TD) 软件是自主开发的FPGA集成开发环境,支持工业界标准的设计输入,包含完整的电路优化流程以及丰富的分析与调试工具,并提供良好的第三方设计验证工具接口,为所有基于安路科技FPGA产品的应用设计提供有力支持。此外,安路科技还将针对PHOENIX2 架构升级软件核心算法,面向FPSoC 芯片开发系统级软件编译工具,有效支持硬件产品的丰富产品线。
35家国产处理器芯片厂商详细信息

下面将从核心技术、主要产品、目标市场和竞争力等方面对这35家公司逐一展示。
电科申泰
• 核心技术:申威自主指令集和处理器架构
• 主要产品:32核高性能服务器处理器申威3231、8核桌面处理器831,以及嵌入式处理器TH-1
• 关键应用:大数据、云计算、人工智能、信息技术和重点行业等
• 竞争力:成立申威产业发展联盟,打造申威处理器的成熟软硬件生态体系,打通申威处理器从研发到生态到产业链的全过程,形成以申威处理器为核心的全产业化布局。
苏州国芯
• 核心技术:自主可控嵌入式CPU微架构设计技术
• 主要产品:嵌入式CPU、嵌入式CPU处理器内核C*Core、信息安全芯片、车规级安全芯片
• 关键应用:信息安全、汽车电子、工业控制、边缘计算和网络通信等应用领域
• 竞争力:公司主要产品与服务均基于自主可控的嵌入式CPU技术,可为客户提供IP授权、芯片定制服务和自主芯片及模组产品,以满足客户自主可控需求和高性能、低功耗、低成本等差异化指标需求。
合芯科技
• 核心技术:IBM POWER架构的服务器CPU设计
• 主要产品:服务器CPU、服务器系统、IP及设计服务
• 关键应用:数据库、内存计算、虚拟化等服务器应用市场
平头哥半导体
• 核心技术:基于ArmV9架构的处理器设计
• 主要产品:Arm服务器芯片倚天710、玄铁处理器IP
• 关键应用:云计算、数据中心
• 竞争力:依托阿里云计算平台,自研Arm服务器CPU基于Armv9架构,SPECrate 2017 Integer跑分超过440。
壁仞科技
• 核心技术:自主原创的GPU芯片架构
• 主要产品:BR100 GPU
• 关键应用:智慧城市、公有云、大数据分析、自动驾驶、医疗健康、生命科学、云游戏等领域。
• 竞争力:累计融资额超47亿元人民币,交付流片的通用GPU–BR100具有高算力、高通用性、高能效三大优势,完全依托壁仞科技自主原创的芯片架构,集合了诸多业界最新的芯片设计、制造与封装技术。
瀚博半导体
• 核心技术:云端推理DSA架构、视频处理技术
• 主要产品:SV100系列AI芯片和AI推理卡、GPU芯片
• 关键应用:云端与边缘AI推理应用、基于视频的AI应用
• 竞争力:继5亿元A+轮融资后,又完成16亿元B-1和B-2轮融资,已经发布SV100系列产品,图形GPU产品研发中。云端推理DSA架构芯片完胜GPU,开始应用于互联网视频处理领域。
摩尔线程
• 核心技术:3D图形计算和高性能并行计算技术
• 主要产品:全功能GPU内置3D图形计算核芯、AI训练与推理计算核芯、高性能并行计算核芯、超高清视频编解码计算核芯
• 关键应用:数字孪生、工业仿真、数字文创、智慧能源、智慧城市、智慧医疗、自动驾驶、机器人、数字人、生物计算等多个数字经济发展的重点领域。
• 竞争力:已完成A轮20亿融资,拥有完整的设计现代全功能GPU体系结构的软硬件设计团队,已经与数百个生态伙伴建立合作关系,共同推进国产GPU应用软件的联合开发、性能优化和应用创新。
芯瞳半导体
• 核心技术:业界主流的统一渲染GPU架构,具有高度可扩展的互联结构和计算阵列
• 主要产品:GenBu01 GPU
• 关键应用:嵌入式计算机产品、信创办公PC、云游戏
• 竞争力:满足国产操作系统的 2D 显示和 3D 渲染需求,目前已经与飞腾、龙芯、统信、麒麟、昆仑BIOS等国产生态厂商完成适配。
登临科技
• 核心技术:GPU+(软件定义的片内异构架构体系)
• 主要产品:Goldwasser(基于GPU+的创新AI计算加速器)
• 关键应用:高性能AI计算、智慧城市、智能安防、互联网等领域
• 竞争力:通过软件定义片内异构体系来打破传统的GPU架构实现,同时采用硬件直接兼容CUDA等主流生态,并极大提高AI计算的计算密度和效率,达到硬件性能和能效的最大化。
联捷科技
• 核心技术:基于FPGA的高性能图片处理加速技术
• 主要产品:CTAccel Image Processor (CIP) 加速器
• 关键应用:云端图片图像和视频处理
• 竞争力:研发基于FPGA的数据中心图像视频等多媒体异构计算解决方案,可将性能和效能提升一个数量级,已获得美国及中国专利。联捷科技高吞吐、低时延的FPGA图像处理加速技术解决方案目前已经广泛应用于智能手机云应用、云存储和在线视频网站等市场。
中科亿海
• 核心技术:“阵列规模/计算资源用户自定义”编译技术
• 主要产品:FPGA芯片、嵌入式可编程电路 IP核、亿灵思设计套件eLinx 2.0
• 关键应用:数据分析、信号处理、图像压缩与恢复、终端控制、信息中转等应用
• 竞争力:作为中国科学院“可编程逻辑芯片与系统”研究领域的科研与产业化团队,坚持全正向设计技术路线,研制具有高可靠性的嵌入式可编程电路 IP核、可编程逻辑芯片和EDA软件,实现可编程逻辑芯片软硬件的全面自主可控。
易灵思
• 核心技术:Quantum技术(包括可编程逻辑,路由结构,存储器和乘法器)
• 主要产品:Trion FPGA、钛金系列FPGA、Efinity IDE
• 关键应用:视频处理、工控、医疗、移动、物联网、消费电子,以及机器视觉、计算加速、边缘计算与深度学习等。
• 竞争力:与传统FPGA对比,基于Quantum技术的FPGA对“功耗-性能-面积”(PPA)的优化高达4倍,独特的设计架构可轻松扩展至百万以上逻辑单元(LE)密度。车规级16nm FPGA针对新能源汽车中的自动驾驶、智能座舱和电气化应用。
复旦微电
• 核心技术:嵌入式可编程PSoC技术
• 主要产品:千万门级FPGA 芯片、亿门级FPGA 芯片、嵌入式可编程器件PSoC
• 关键应用:5G通信、信号处理、图像处理、工业控制等应用
• 竞争力:复旦微的青龙系列嵌入式可编程PSoC 产品采用28nm 工艺制程,内嵌大容量自有eFPGA 模块,并配置有APU 和多个AI 加速引擎。
中科龙芯
• 核心技术:MIPS授权架构的CPU及生态圈、跨指令兼容的二进制翻译技术。
• 主要产品:面向行业应用的“龙芯1号”小CPU;面向工控和终端类应用的“龙芯2号”中CPU;以及面向桌面与服务器类应用的“龙芯3号”大CPU。
• 应用领域:网络安全、办公与信息化、工控及物联网等领域,并在政府、能源、金融、交通、教育等行业领域取得了广泛应用。
天津飞腾
• 核心技术:自研ARMv8架构处理器、片上并行系统(PSoC)体系结构。
• 主要产品:高性能服务器CPU(腾云S系列);高效能桌面CPU(腾锐D系列);高端嵌入式CPU(腾珑E系列)三大系列。
• 应用领域:国内政务办公、装备制造、云计算、大数据以及金融、能源和轨道交通等行业信息系统领域。
海光信息
• 核心技术:AMD授权X86指令集架构、“禅定”x86 CPU
• 主要产品:7000系列、5000系列和3000系列处理器。
• 应用领域:政府机构和商业服务器应用。
兆芯
• 核心技术: CPU、GPU、芯片组核心技术。
• 主要产品:“开先”、“开胜”两大CPU系列。
• 应用领域: 党政办公、金融、教育、医疗、交通、网络安全、能源等行业。
华为海思
• 核心技术:ARM v8架构授权、达芬奇架构NPU
• 主要产品:鲲鹏920、麒麟系列应用处理器、昇腾AI芯片。
• 应用领域:服务器、手机、智能终端。
紫光展锐
• 核心技术:5G通信、AI平台
• 主要产品:虎贲T7520/T7510/T710系列手机应用处理器、W517/307系列智能可穿戴处理器、春藤系列物联网芯片。
• 应用方案:5G、AIoT、智能语音、智能穿戴、平板电脑、工业互联网
• 目标市场:手机、可穿戴设备、工业物联网、汽车电子、功率电子。
瑞芯微
• 核心技术:ARM内核高性能应用处理器、智能语音
• 主要产品:RK35系列、RK33系列、RK32系列、RK31系列RK30系列、RK18系列、RK MCU系列、RK Power系列、RV11系列。
• 应用方案:平板电脑、流媒体应用、商业及工业应用、家居应用、智联网应用、视觉应用、车载应用。
• 目标市场:智能硬件、手机周边、平板电脑、电视机顶盒、工控等多个领域。
北京君正
• 核心技术:XBurst 系列 CPU Core (基于MIPS 指令集)、Helix/ Radix系列 VPU、Tiziano图像处理器、君正AIE 算力引擎、ISSI存储技术
• 主要产品:X2000、X1000/E、X1520、X1500、X1021系列微处理器;T40、T31、T21、T30、T20系列智能视频处理器;ISSI/Lumissil存储器。
• 应用方案:智能音频、图像识别、智能家电、智能家居、智能办公、智能视频。
• 目标市场:生物识别、教育电子、多媒体播放器、电子书、平板电脑、AIoT等领域,以及计算和通信存储市场。
全志科技
• 核心技术:智能应用处理器SoC、超高清视频编解码、高性能CPU/GPU/AI多核整合;
• 主要产品:A系列平板电脑应用处理器、F系列多媒体处理器、H系列机顶盒OTT处理器、R系列智能语音芯片、T系列车规级驾舱信息娱乐处理器、V系列视频编解码处理器、MR系列处理器。
• 应用方案:智能硬件、消费电子、工业控制、家庭娱乐、车联网方案;
• 目标市场:智能硬件、平板电脑、智能家电、车联网、机器人、虚拟现实、网络机顶盒,以及电源、无线通信模组、智能物联网等多个产品领域。
景嘉微
• 核心技术:支持国产CPU和国产操作系统的GPU
• 主要产品:JM5400、JM7200/7201 图形处理器
• 应用市场:笔记本电脑、一体机、移动工作站、刀片式主板等桌面办公和工业控制领域。
天数智芯
• 核心技术:全自研通用计算GPGPU
• 主要产品:7纳米GPGPU高端自研云端训练芯片
• 目标市场:计算机视觉、智能语音、智能推荐等AI领域;HPC通用计算。
芯动科技
• 核心技术:GDDR6高带宽显存技术、4K/8K显示的HDMI2.1技术、国产自主标准的INNOLINK Chiplet和HBM2E高性能计算平台技术
• 主要产品:智能渲染GPU图形处理器;高速32Gbps SerDes Memory ;高性能计算/高带宽储存/加密计算/AI云计算/低功耗IoT等芯片。
• 应用市场:高性能计算/多媒体&汽车电子/IoT物联网等领域;信创桌面渲染、5G数据中心、云游戏、云办公、云教育等主流新基建领域。
高云半导体
• 核心技术:GoAI机器学习平台、蓝牙FPGA系统级芯片
• 主要产品:晨熙家族GW2A系列 FPGA、小蜜蜂家族GW1N系列SoC
• 应用市场:通讯、工业控制、LED显示、汽车电子、消费电子、AI、数据中心。
上海安路
• 核心技术:全流程TD软件系统
• 主要产品:高端PHOENIX(凤凰)、中端EAGLE(猎鹰)、低端ELF(精灵)系列FPGA。
• 应用方案:LED显示屏、工业自动化、通信控制、MIPI和TCON显示等。
紫光国微
• 核心技术:Pango Design Suite FPGA开发软件技术、嵌入式FLASH、高安全加密、内嵌ECC。
• 主要产品:Titan系列FPGA、Logos系列FPGA、Compact系列CPLD;智能卡和智能终端安全芯片;半导体功率器件;超稳晶体频率器件;5G超级SIM卡。
• 应用方案:移动通信、金融支付、数字政务、公共事业、物联网与智慧生活、智能汽车、电子设备、电力与电源管理、人工智能。
• 目标市场:金融、电信、政务、汽车、工业互联、物联网等领域。
京微齐力
• 核心技术:AiPGA芯片(AI in FPGA)、异构计算HPA芯片(Heterogeneous Programmable Accelerator)、嵌入式可编程eFPGA IP核、FX伏羲EDA软件
• 主要产品:HME-R、HME-M、HME-P、HME-H系列FPGA
• 应用方案:工业控制、医疗电子、消费类电子、广播&通信、汽车电子、计算机与存储、嵌入式应用、人工智能。
• 目标市场:云端服务器、消费类智能终端以及国家通信/工业/医疗等核心基础设施。
智多晶
• 核心技术:FPGA开发软件“HqFpga”、 自主研发的FPGA架构
• 主要产品:Seagull 1000系列 CPLD、Sealion 2000 系列FPGA、Seal 5000 系列 FPGA
• 目标市场:LED驱动、视频监控、图像处理、工业控制、4G/5G通信网络、数据中心等。
成都华微电子
• 核心技术:可编程逻辑器件CPLD、FPGA硬件设计平台、可编程逻辑器件综合、映射及编程算法软件技术。
• 主要产品:数字模拟混合信号芯片、可编程逻辑器件、ADC/DAC、模拟电路及接口电路系列产品
• 应用市场:工业控制、通信和安防等。
遨格芯
• 核心技术:可编程SoC、异构(MCU)边缘计算
• 主要产品:CPLD、FPGA、MCU-SoC、AI ASIC、MCU。
• 目标市场:消费电子、工业和AIoT。
晶晨半导体
• 核心技术:超高清多媒体编解码和显示处理、人工智能、内容安全保护、系统IP等核心软硬件技术
• 主要产品:多媒体SoC芯片
• 应用方案:IP/OTT/DVB机顶盒方案、智能电视、智能影像、智能家居、智能商显。
• 目标市场:智能机顶盒、智能电视和AI音视频系统终端等,以及IPC等消费类安防市场、车载娱乐、辅助驾驶等汽车电子市场。
国科微
• 核心技术:全自主固态硬盘控制芯片、无线数据通信核心技术、AVS2超高清智能4K解码芯片
• 主要产品:直播卫星高清芯片、智能4K解码芯片、H.264/H.265高清安防芯片、高端固态存储主控芯片、北斗导航定位芯片。
• 应用方案:智能机顶盒、智能监控、存储控制、物联网
• 目标市场:卫星广播、无线通信、存储和信息安全、物联网应用领域。
中星微
• 核心技术:组织制定安全防范视频安全数字音视频编解码(SVAC)国家标准、结构化的视频码流、“数据驱动并行计算”架构
• 主要产品:“星光”数字多媒体芯片、 集成神经网络处理器(NPU)的SVAC视频编解码SoC、SVAC视频安全摄像头芯片、H.264 解压缩芯片、PC摄像头芯片
• 目标市场:信息安全、图像编码视频安全领域。
• 壁仞 500-999人 热招职位 (362)
• 沐曦 500-999人 热招职位 (190)
• 摩尔线程 100-499人 热招职位 (371)
• 瀚博半导体 100-499人 热招职位 (357)
• 登临科技 100-499人 热招职位 (173)
• 天数智芯 100-499人 热招职位 (54)
• 芯动科技 100-499人 热招职位 (28)
• 实际:
• 1、从公司规模,壁仞、沐曦超过500人,属于第一梯队。
• 2、从招聘量,摩尔线程、瀚博有超越沐曦的势头。
• 3、目前没有一家公司超过1000人。
参考链接:
https://www.zhihu.com/question/448075048/answer/2398135680
https://mp.weixin.qq.com/s/INHq12q–FVZjZZejlADkQ
https://mp.weixin.qq.com/s/Lzi6ihofgp05s-KFceUZeA
https://mp.weixin.qq.com/s/xeSI-hB8OQb77HpS1qyduA
https://mp.weixin.qq.com/s/2bk4MH2lteRc8I-UMMEMBA
https://mp.weixin.qq.com/s/oR0d_pvr2PohpjKByZaq1Q
https://mp.weixin.qq.com/s/TcotntN4LIWHmV9ZQWB5Ow
智能推荐
python色卡识别_用Python帮小姐姐选口红,人人都是李佳琦-程序员宅基地
文章浏览阅读502次。原标题:用Python帮小姐姐选口红,人人都是李佳琦 对于李佳琦,想必知道他的女生要远远多于男生,李佳琦最早由于直播向广大的网友们推荐口红,逐渐走红网络,被大家称作“口红一哥”。不可否认的是,李佳琦的直播能力确实很强,他能够抓住绝大多数人的心理,让大家喜欢看他的直播,看他直播推荐的口红适不适合自己,色号适合什么样子的妆容。为了提升效率,让自己的家人或者女友能够快速的挑选出合适自己妆容的口红色号,今..._获取口红品牌 及色号,色值api
linux awk命令NR详解,linux awk命令详解-程序员宅基地
文章浏览阅读3.6k次。简介awk命令的名称是取自三位创始人Alfred Aho 、Peter Weinberger 和 Brian Kernighan姓名的首字母,awk有自己的程序设计语言,设计简短的程序,读入文件,数据排序,处理数据,生成报表等功能。awk 通常用于文本处理和报表生成,最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。awk 通常以文件的一行为处理单位..._linux awk nr
android 网络连接失败!failed to connect to /192.168.1.186(port 8080)_failed to connect to 192.168.88.218:80-程序员宅基地
文章浏览阅读1.3w次,点赞5次,收藏2次。在网上找了一个小时,一直没有头绪,因为上个星期还是好好的,最后看到一个大神的解答,只需要将防火墙关闭就好了.原本向测试功能的,却卡在了登录上.以此记录.另外好像还有种错误是电脑与手机连接的WiFi不同,也可以看看...._failed to connect to 192.168.88.218:80
matlab 多径衰落,利用MATLAB仿真多径衰落信道.doc-程序员宅基地
文章浏览阅读1.9k次。利用MATLAB仿真多种多径衰落信道摘要:移动信道的多径传播引起的瑞利衰落,时延扩展以及伴随接收过程的多普勒频移使接受信号受到严重的衰落,阴影效应会是接受的的信号过弱而造成通信的中断:在信道中存在噪声和干扰,也会是接收信号失真而造成误码,所以通过仿真找到衰落的原因并采取一些信号处理技术来改善信号接收质量显得很重要,这里利用MATLAB对多径衰落信道的波形做一比较。一,多径衰落信道的特点关于多径衰落..._matlab多径衰落工具箱
python对json的操作及实例解析_import json灰色-程序员宅基地
文章浏览阅读1w次,点赞2次,收藏17次。Json简介:Json,全名 JavaScript Object Notation,是一种轻量级的数据交换格式。它基于 ECMAScript (w3c制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。(来自百度百科)python关于json文_import json灰色
mysql实现MHA高可用详细步骤_mysql mha超详细教程-程序员宅基地
文章浏览阅读1.1k次,点赞6次,收藏3次。一、工作原理MHA工作原理总结为以下几条:(1) 从宕机崩溃的 master 保存二进制日志事件(binlog events);(2) 识别含有最新更新的 slave ;(3) 应用差异的中继日志(relay log) 到其他 slave ;(4) 应用从 master 保存的二进制日志事件(binlog events);(5) 通过Manager控制器提升一个 slave 为新 m..._mysql mha超详细教程
随便推点
Linux环境下主从搭建心得(高手勿喷)_linux的java主从策略是什么-程序员宅基地
文章浏览阅读194次。一 java环境安装:1 安装JDK 参考链接地址:https://blog.csdn.net/qq_42815754/article/details/82968464注:有网情况下直接 yum 一键安装:yum -y list java(1)首先执行以下命令查看可安装的jdk版本(2)选择自己需要的jdk版本进行安装,比如这里安装1.8,执行以下命令:yum install -y java-1.8.0-openjdk-devel.x86_64(3)安装完之后,查看安装的jdk 版本,输入以下指令_linux的java主从策略是什么
ACM第四题_acm竞赛题 i 'm from mars-程序员宅基地
文章浏览阅读104次。定义int 类型,由while实现A,B的连续输入,输出A+B的值按Ctrl Z结束循环。#include<iostream>using namespace std;int main(){ int A,B; while(cin>>A>>B) { cout<<A+B<&_acm竞赛题 i 'm from mars
TextView.SetLinkMovementMethod后拦截所有点击事件的原因以及解决方法-程序员宅基地
文章浏览阅读5.2k次。在需要给TextView的某句话添加点击事件的时候,我们一般会使用ClickableSpan来进行富文本编辑。与此同时我们还需要配合 textView.setMovementMethod(LinkMovementMethod.getInstance());方法才能使点击处理生效。但与此同时还会有一个问题:如果我们给父布局添加一个点击事件,需要在点击非链接的时候触发(例如RectclerV..._linkmovementmethod
JAVA实现压缩解压文件_java 解压zip-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏31次。JAVA实现压缩解压文件_java 解压zip
JDK8 新特性-Map对key和value分别排序实现_java comparingbykey-程序员宅基地
文章浏览阅读1.3w次,点赞7次,收藏21次。在Java 8 中使用Stream 例子对一个 Map 进行按照keys或者values排序.1. 快速入门 在java 8中按照此步骤对map进行排序.将 Map 转换为 Stream 对其进行排序 Collect and return a new LinkedHashMap (保持顺序)Map result = map.entrySet().stream() .sort..._java comparingbykey
GDKOI2021普及Day1总结-程序员宅基地
文章浏览阅读497次。第一次参加GDKOI,考完感觉还可以,结果发现还是不行,有一些地方细节打错,有些失分严重,总结出以下几点:1.大模拟一定要注意,细节打挂就是没分,像T1就是一道大模拟题,马上切了,后面就没想着检查以下,导致有些地方挂掉了,用民间数据一测,才85分。2.十年OI一场空,不开longlonglong longlonglong见祖宗。今天的T2本来想用暴力水点分的,结果没想到longlong→intlong long\to intlonglong→int,40→040\to040→0。3.代码实现能力太差,_gdkoi