廖雪峰-Python教程-程序员宅基地
技术标签: python
Python教程:
Python简介、安装Python、第一个Python程序:
Python内置库、第三方库
命令行模式:在Windows下,执行一个.py文件
# python 文件名.py
Python交互模式:">>>"
可变对象:list
不可变对象(整数、小数、字符串、tuple):调用自身任意的方法,不会改变该对象自身的内容;但是这些方法会创建新的对象并返回
a = 'abc'
b = a.replace('a', 'A')
# 得到的结果是:a为'abc'、b为'Abc'
# print()函数
# 1. 接受多个字符串:各个字符串间自动加空格
print('hello','world','!')
格式化输出:
方式1:占位符%
# 单个占位符:
s = 'world'
print('hello, %s' %s)
# 多个占位符:
name = 'Smith'
dollars = 19
print('Hi, %s, you have $%d.' %(name, dollars))
设置小数的位数,以及是否补零:


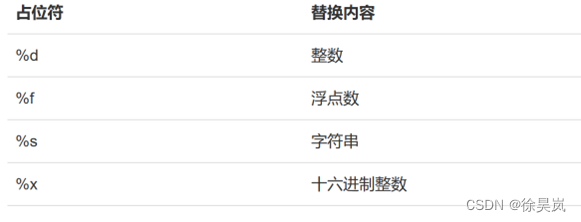
常见占位符:
方式2:format()

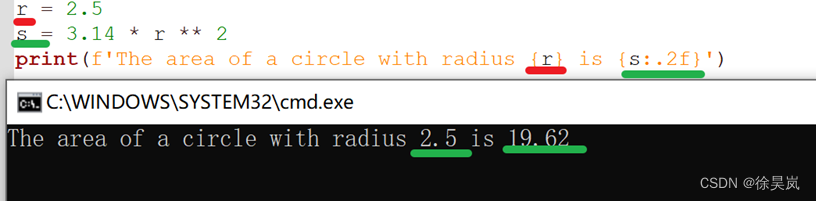
方式3:f-string
# input()函数
# 功能:输入字符串
# 参数:提示字符
# int()函数
# 功能:强转为整型
# range()函数
# 功能:生成整数序列
# list()函数
# 功能:强转为列表
缩进:1个Tab、4个空格键
注释 #
大小写敏感
Python基础:
数据类型:
整数:十进制、十六进制(0x)。当整数过大是可以用_来分隔,增加可读性。
小数:科学计数法(e替换底数10)
字符串:
# 转义字符:
'''
\n --> 换行
\t --> 制表符
\\ --> \
r'...' --> '...'不转义
%% --> %
'''
# 内部有换行:
print('''Hello
World
!
''')
布尔值(True、False):and、or、not
空值:None
变量:python是动态语言,变量本身类型不固定
# 在计算机内存中的表示:
a = '123'
b = a
'''
1. 在内存中创建了一个'123'的字符串
2. 在内存中创建了一个名为a的变量,并把它指向'123'
3. 把b也指向'123'
'''
常量:规范是全部字母大写
除法:
/ 结果为小数
// 地板除 结果为整数
取余:%
字符串编码:
ASCII编码:'A'-->65;'a'-->97;'0'-->48
GB2312编码:2字节,中文
Shift_JIS编码:日文
Euc_Kr:韩文
出现以上各种编码,会有乱码现象:
解决:Unicode字符集将各种编码统一到一套编码中
新问题:若代码中全是英文,用Unicode编码会比ASCII编码需要一倍的储存空间,在储存和传输上十分不划算
解决:Unicode可变长编码(UTF-8编码):英文字母1字节;汉字3字节;生僻字符4~6字节
可以理解ASCII编码为UTF-8编码的一个子集
计算机系统通用的字符串编码的工作方式:
计算机内存:Unicode编码
保存到硬盘或者需要传输时:UTF-8编码
Python:
内存:Unicode编码--str类型
网上传输、保存到硬盘:UTF-8--bytes类型
bytes类型:字符串前面带前缀--b;每个字符都占一个字节
Python3版本:字符串以Unicode编码,即支持多语言
# ord()函数:将字符串转为十进制整数
ord()
# chr()函数:将整数转为字符
chr()
# len()函数:得到str中有多少字符串;得到bytes有多少字节
一. 从str转换为bytes:以Unicode表示的str可以通过encode()方法,编码为指定的bytes
1. 纯英文的str可以用ASCII编码为bytes

2. 含中文的str可以用UTF-8编码为bytes

3. 但是含有中文的str不能用ASCII编码为bytes,因为超范围了
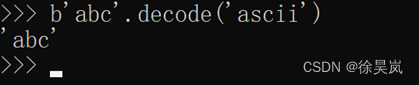
二. 从bytes转换到str:bytes可以通过decode()方法,编码为指定的str

如果bytes变量中含有无法解码的字节,则报错

忽视报错则:errors = ‘ignore’
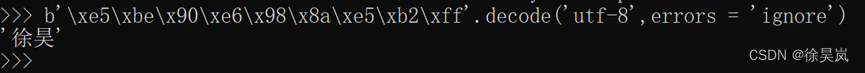
# 让Python解释器按UTF-8编码读取,在文件开头应该:
# -*- coding: utf-8 -*-
# 同时也应该让文本编辑器正在使用UTF-8编码
list:列表 [ , , , ..., ,]
获得list元素个数:len()函数
索引:[ ]
从0开始;最后一个元素的索引是-1
将某个元素值替换成其他值
追加元素到末尾 .append(元素值)方法
把元素插入指定位置 .insert(索引, 元素值)方法
删除末尾元素 .pop()方法,会返回被删元素值
删除指定位置元素 .pop(索引)方法,会返回被删元素值
list中的元素类型可以不同,其元素亦可是一个list
tuple:元组 ( , , , ..., ,)
一旦经初始化就不能修改
索引:[ ]
陷阱:定义一个只有1个元素的tuple
# 正确做法:
t = (1, )
# “可变化”例子:
t = ('a', 'b', ['A', 'B'])
t[2][0] = 'X'
t[2][1] = 'Y'
# “可变化”的实质:tuple元素可以变化,但是其指向不能发生变化
条件判断:
if 条件:
语句块1
elif 条件:
语句块2
...
else:
语句块n
'''
这里的条件可以是:
1. 判断语句
2. 数值、字符串、list、
'''
模式匹配:match语句
# 简单:
match 变量:
case 值1:
语句1
case 值2:
语句2
...
case _: # 类似default
语句n
# 复杂:
match 变量:
case x if x < 10: # 变量小于10
语句1
case 值1|值2|值3|...|值n| # 变量==值1或值2或...或值n
语句2
case _:
语句3
# 列表:
args0=['gcc']
args1=['clean']
args2=['gcc', 'hello.c', 'world.c']
match args0:
case ['gcc']:
语句1
case ['clean']:
语句2
case ['gcc', file1, *files]:
语句3
case _:
语句4
循环:
# for ... in ...:
# 依次把list或tuple中的元素迭代出来
list(range(2))
# 得到[0, 1]
# while 条件:
# break语句:提前结束循环
# continue语句:跳过这次循环,直接开始下一次循环
# break和continue语句都要配合上if条件语句
# 不要滥用break和continue语句
在这里插入代码片
结束死循环:Ctrl + c
dict:字典 {key1:value1, key2:value2, ...,keyn:valuen}
索引:字典对象[key]:得到对应的value
加入新key,及其对应的value:字典对象[key]=value
一个key只唯一对应一个value,后来的value会替代之前的
判断key是否在字典对象内:
① key in 字典对象:返回True或是False
② .get()函数
(1) 字典对象.get(key):不存在返回None
(2) 字典对象.get(key, -100):不存在返回-100
删除:字典对象.pop(key):返回key对应的value
dict和list的区别:
dict:查找和插入的速度极快,不会随着key的增加而变慢;但是需要占用大量的内存。用空间换取时间。
list:查找和插入的时间会随着元素的增加而变慢;占用空间小。
dict的key一定要是不可变对象
set:集合 { , , ..., }
有key但是无value,并且key不重复。就类似数学上无序不重复的集合
# 求交集
集合对象1 & 集合对象2
# 求并集
集合对象1 | 集合对象2
创建set:将列表list强转为set
s = set([1, 3, 2, 3])
# 会自动过滤掉list中重复的元素
增加元素:集合对象.add(key) 也会自动剔除重复的元素
删除元素:集合对象.remove(key)
set和dict的区别:
set:只有key没有value
set中也不能放入可变对象
函数:
调用函数:函数名其实就是指向一个函数对象的引用。可以把函数名赋给一个变量,相当于给这个函数起了一个别名
定义函数:def语句
def 函数名(参数列表):
...
# 可以返回一个或多个参数,如下
return 变量1, 变量2, ..., 变量n
'''
此时返回的是一个tuple元组对象:
接受方式1:只用一个变量接受
接受方式2:用n个变量接受
'''
# 也可以不返回任何变量,返回None,如下
return
空函数:
def nop():
pass
pass语句:可用来作占位符,如当下还没想好怎么写代码,就可先放一个pass语句,让代码运行不报错
函数的参数:
1. 位置参数/必选参数:
2. 默认参数:降低了函数调用的难度。默认参数必须要指向不变对象,如None,以避免出现莫名其妙的错误。
注意点:必选参数放在前面,默认参数放在后面;将变换大的参数放在前面,变化下的放在后面,做默认参数
# 定义
def fun(name, gender, age = 6, city = 'BeiJing'):
语句块
# 调用
fun('Smith', 'M')
fun('Lisa', 'F', 7)
fun('Andy', 'M', city = 'TianJin')
3. 可变参数:允许传入0个或任意个参数,这些可变参数在函数调用时,自动组装成一个tuple对象
def fun(*args):
for x in args:
print(x)
# 调用时不用传入list或者tuple
fun(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
# 如果已经有list或tuple对象,并要传入其元素
ls = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
fun(*ls)
tp = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
fun(*tp)
4. 关键字参数:允许传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装成一个dict
def fun(**kw):
print(kw)
# 调用时,不传入参数:得到{}
fun()
# 调用时传入参数(不用传入dict对象):得到{'Lisa': 19, 'Smith': 20}
fun(Lisa=19, Smith=20)
# 调用时传入参数(已经用dict对象):得到{'Andy': 22, 'Peter': 21}
dc = {
"Andy":22, "Peter":21}
fun(**dc)
5. 命名关键字参数:用来限制关键字参数名字。也可以缺省。
# 限制关键字参数只能是city和job
# 无默认参数时,要占位符*
def person(name, age, *, city, job):
print(name,age,city,job)
person("LiMing", 18, city="BeiJing", job="Engineer")
# 限制关键字参数只能是city和job,并且city缺省了
# 有默认参数时,命名关键字参数无需再要占位符*
def person(name, age, *args, city='NanJing', job):
print(name,age,args,city,job)
person("LiMing", 18, 'Outside Graduate', job="Engineer")
五类参数定义顺序:必选参数,默认参数,可变参数,命名关键字参,关键字参数
对任意函数,都可通过类似fun(*args, **kw)的形式来调用它,无论其参数是如何定义的
递归函数:
一个函数在内部调用自己本身
函数调用是通过栈这种数据结构实现的,防止栈溢出
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范