前端面试35k题库2021-@莫成尘_35k.in-程序员宅基地
技术标签: 面试 js前端面试汇总 webpack 前端 vue.js javascript
H5/C3/ES6/JS
Html5
h5、css3、es6的新属性
h5新特性:
- 拖拽释放(Drag and drop) API
- 语义化更好的内容标签(header,nav,footer,aside,article,section)
- 音频、视频API(audio,video)
- 画布(Canvas) API
- 地理(Geolocation) API
- 本地离线存储 localStorage 长期存储数据,浏览器关闭后数据不丢失;
- sessionStorage 的数据在浏览器关闭后自动删除
- 表单控件:calendar、date、time、email、url、search
- 新的技术:webworker, websocket, Geolocation
移除的元素:
-
纯表现的元素:basefont,big,center,font, s,strike,tt,u;
-
对可用性产生负面影响的元素:frame,frameset,noframes
H5的特点
-
更简洁,但是在实际开发中要注意书写规范
-
标签的语义化
-
语法更宽松
BFC
BFC(块级格式化上下文),一个创建了新的BFC的盒子是独立布局的,盒子内元素的布局不会影响盒子外面的元素,在同一个BFC中的两个相邻的盒子在垂直方向发生margin重叠的问题。
BFC是指浏览器中创建了一个独立的渲染区域,该区域内所有元素的布局不会影响到区域外元素的布局,这个渲染区域只对块级元素起作用。
触发BFC的方式(以下任意一条就可以)
- html根元素
- float属性不为none
- position不为visible,为absolute或fixed。
- display为inline-block, table-cell, table-caption, flex, inline-flex
- overflow不为visible
BFC布局与普通文档流布局区别
(注:字体加粗的触发BFC的条件都支持)
普通文档流布局规则
1. 浮动的元素是不会被父级计算高度
2. 非浮动元素会覆盖浮动元素的位置(兄弟关系的元素)。
3. 给子级添加margin-top会传递给父级
4.两个相邻元素上下margin会重叠
BFC布局规则
1.浮动的元素会被父级计算高度(高度坍塌)
(1)给父级添加浮动float
(2)给父级添加overflow:hidden; 触发了BFC(子元素浮动,父元素没有高度时使用,该方法不能和定位一起使用)
(3)给父级添加display:inline-block;
(4)给父级添加定位position:absolute/fixed;
2. 非浮动元素不会覆盖浮动元素位置
(1)非浮动元素float的值不为none
(2)非浮动元素加overflow:hidden触发了BFC。
(3)非浮动元素display:inline-block;
(4)给非浮动元素或者浮动元素添加position定位,添加的元素会覆盖在未添加的元素上面
3. 给子级添加margin-top不会传递给父级
(1)给父级添加浮动float
(2)给父级添加overflow:hidden;
(3)给子级添加display:inline-block;
(4)给父级添加定位position:absolute/fixed;
Form中的获取数据的两个方式get和post的区别?
-
get是从服务器上获取数据,post是向服务器传送数据。
-
get是把参数数据队列加到提交表单的ACTION属性所指的URL中,值和表单内各个字段一一对应,在URL中可以看到。post是通过HTTP post机制,将表单内各个字段与其内容放置在HTML HEADER内一起传送到ACTION属性所指的URL地址。用户看不到这个过程。get是显式提交,post是隐式提交。
-
对于get方式,服务器端用Request.QueryString获取变量的值,对于post方式,服务器端用Request.Form获取提交的数据。
-
get传送的数据量较小,不能大于2KB。post传送的数据量较大,一般被默认为不受限制。
-
get安全性非常低,post安全性较高。但是执行效率却比Post方法好。
什么时候使用get什么时候使用post?
-
get方式的安全性较Post方式要差些,包含机密信息的话,建议用Post数据提交方式;
-
在做数据查询时,建议用Get方式;而在做数据添加、修改或删除时,建议用Post方式;
Html中form里的action方法的get与post方法区别是什么?
get:
-
通过GET提交数据,用户名和密码将明文出现在URL上,因为登录页面有可能被浏览器缓存,GET请求请提交的数据放置在HTTP请求协议头
-
或者其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击,所以不安全
-
GET请求有长度限制
post:
-
POST数据放在body(POST提交的数据则放在实体数据),POST请求数据不能被缓存下来
-
POST请求参数不会被保存在浏览器历史或 web 服务器日志中。
-
POST请求没有长度限制
参考:form里面的action和method(post和get的方法)使用
https://www.cnblogs.com/May-day/p/5515780.html
####渐进增强和优雅降级的概念以及区别
**渐进增强 progressive enhancement:**针对低版本浏览器进行构建页面,保证最基本的功能,然后再针对高级浏览器进行效果、交互等改进和追加功能达到更好的用户体验。
**优雅降级 graceful degradation:**一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。
**区别:**优雅降级是从复杂的现状开始,并试图减少用户体验的供给,而渐进增强则是从一个非常基础的,能够起作用的版本开始,并不断扩充,以适应未来环境的需要。降级(功能衰减)意味着往回看;而渐进增强则意味着朝前看,同时保证其根基处于安全地带。
####如何处理HTML5新标签的浏览器兼容问题?
支持HTML5新标签:
IE8/IE7/IE6支持通过 document.createElement 方法产生的标签,可以利用这一特性让这些浏览器支持 HTML5 新标签,浏览器支持新标签后,还需要添加标签默认的样式(当然最好的方式是直接使用成熟的框架、使用最多的是html5shim框架):
<!--[if lt IE 9]>
<script> src="http://html5shim.googlecode.com/svn/trunk/html5.js"</script>
<![endif]-->
####如何区分HTML和HTML5
DOCTYPE声明新增的结构元素、功能元素
文档碎片
如果我们要在一个ul中添加100个li,如果不使用文档碎片,那么我们就需要使用append经常100次的追加,这会导致浏览器一直不停的渲染,是非常消耗资源的。但是如果我们使用文档碎片了,我们可以先将100个li添加到文档碎片中,然后直接把这个文档碎片追加到ul中即可。所以文档碎片其实就是一个临时的仓库。
如下代码在document.body中添加5个span:
for(var i=0;i<5;i++)
{
var op = document.createElement("span");
var oText = document.createTextNode(i);
op.appendChild(oText);
document.body.appendChild(op);
}
对于少量的更新,一条条循环插入的运行也还可以。但是,当要向document中添加大量数据(比如1w条),如果像上面的代码一样,逐条添加节点,整个过程会十分缓慢,性能极差。
也可以建一个新的节点,例如div,先将span添加到div上,然后再将div添加到body:
var oDiv = document.createElement("div");
for(var i=0;i<10000;i++)
{
var op = document.createElement("span");
var oText = document.createTextNode(i);
op.appendChild(oText);
oDiv.appendChild(op);
}
document.body.appendChild(oDiv);
但这样会在body中多添加一个div节点。用文档碎片就不会产生这种节点,引入createDocumentFragement()方法,它的作用是创建一个文档碎片,把要插入的新节点先插入它里面,然后再一次性地添加到document中。
代码如下:
//先创建文档碎片
var oFragmeng = document.createDocumentFragment();
for(var i=0;i<10000;i++)
{
var op = document.createElement("span");
var oText = document.createTextNode(i);
op.appendChild(oText);
//先附加在文档碎片中
oFragmeng.appendChild(op);
}
//最后一次性添加到document中
document.body.appendChild(oFragmeng);
浏览器内核
IE: trident内核
Firefox:gecko内核
Safari:webkit内核
Opera:以前是presto内核,Opera现已改用Google Chrome的Blink内核
Chrome:Blink(基于webkit,Google与Opera Software共同开发)
什么是viewport?
viewport是视口,在浏览器中用来显示网页的某一块区域,以合理的比例显示内容。
###CSS3
css3新特性
-
CSS3实现圆角(border-radius),盒子阴影(box-shadow),文本阴影(text-shadow)
-
渐变(gradient):线性渐变、径向渐变,旋转(transform)
-
有关制作动画的三个属性:transform、transition、animation
-
transform:translate移动、scale缩放、rotate旋转、skew倾斜
-
animation动画 keyframes关键帧
-
增加了更多的CSS选择器 多背景 rgba
-
在CSS3中唯一引入的伪元素是 ::selection.
-
媒体查询,多栏布局
-
border-color、border-image、border-radius
-
filter:blur()虚化图片
####css3的优势
- 让页面效果看起来非常炫酷,用户体验更高。
- 有利于开发和维护,还能提高网站的性能,增加网站的可访问性,可用性。
- 使网站能适配更多的设备,利于seo网站优化,提高网站的搜索排名。
css sprites如何使用
将导航背景图片,按钮背景图片等有规则的合并成一张背景图,即将多张图片合为一张整图,然后用“background-position”来实现背景图片的定位技术。
CSS元素类型
块状元素,内联元素(行内元素),内联块元素(行内块元素)
空元素有哪一些
br hr
标准盒模型和怪异盒模型
CSS中Box model是分为两种:W3C标准和IE标准盒子模型
在标准模式下,一个块的总宽度 = width + margin+padding+border
在怪异模式下,一个块的总宽度=width+margin(即width已经包含了padding和border的值)
大多数浏览器采用W3C标准模型,而IE中则采用Micreosoft自己的标准。
怪异模式是"部分浏览器在支持W3C标准的同时还保留了原来的解析模式",怪异模式主要表现在IE内核的浏览器。
当不对doctype进行定义时,会触发怪异模式。
标准盒模型和怪异盒模型的转化
怪异盒模型:box-sizing:border-box
标准盒模型:box-sizing:content-box
####列出display的值,说明他们的作用
display属性与属性值 (18个属性值)
属性值:block/inline/inline-block/none/list-item/table-header-group/table-footer-group/table
作用:块状元素和内联元素之间的转换。
-
Block块状显示:类似在元素后面添加换行符,也就是说其他元素不能在其后面并列显示。或者就是让元素竖排显示。
-
inline内联显示:在元素后面删除换行符,多个元素可以在一行内并列显示。或者就是让元素横排显示。
-
当元素设置了float属性后,就相当于该元素具备块状元素显示的特点;可以加宽高。
-
Inline-block行内块元素显示:元素的内容以块状显示,行内的其他元素显示在同一行。(只有行内块这一个元素类型支持vertical-align属性)
img,input垂直对齐方式{vertical-align:top/bottom/middle;}
-
none 此元素不会被显示。隐藏且不占位
####position的值:relative和absolute分别是相对谁进行定位的
position:定位属性,检索对象的定位方式;
定位都脱离层。
语法:position:static /absolute/relative/fixed
absoluted/relative/fixed 对定位有效,对层级属性Z-index有效。
取值:
- static:默认值,无特殊定位,对象遵循HTML原则;
- absolute:绝对定位,将对象从文档流中拖离出来,使用left/right/top/bottom等属性相对其最接近的一个并有定位设置的父元素(祖先元素|祖先元素不包含叔叔级的)进行绝对定位;如果不存在这样的父对象,则依据根元素(html)浏览器进行定位,而其层叠通过z-index属性定义,可以脱离当前的大容器,并且不占位。float脱离半层。
- relative :相对定位,该对象的文档流位置不动,将依据right,top,left,bottom(相对定位)等属性在正常文档流中偏移位置;其层叠通过z-index属性定义
一般给父层级添加relative属性值
相对于自身位置进行偏移
元素设置:margin:0 auto时:
(1)box为相对定位时(相对自身),居中
(2)box为绝对定位时(相对于根元素HTML),向左
- fixed:(固定定位)未支持,对象定位遵从绝对定位方式(absolute);但是要遵守一些规范(IE6浏览器不支持此定位);跟绝对定位一样的都是脱离文档流,不占位,并且永远相对于当前浏览器的可视窗口进行位置偏移。
absolute是不是一定需要设置相对定位
absolute不一定必须找到position单词修饰的祖先元素,如果找不到就相对浏览器进行定位。
####解释下浮动和它的工作原理
语法:float:none/left/right;
float浮动脱离半层
float:定义网页中其它文本如何环绕该元素显示
嵌套浮动元素的父级要有高度,不然会高度塌陷,解决办法,添加overflow:hidden;(注意不能与定位一起使用)
浮动的目的:就是让竖着的东西横着来
有三个取值:
left:元素活动浮动在文本左面
right:元素浮动在右面
none:默认值,不浮动。
清除浮动的方法
-
在结尾处添加空div标签clear:both;
-
万能清除浮动法(给浮动元素的父元素添加)class名.clear,哪个需要清除就给哪个元素命名为clear ;一个元素可以取多个class名,中间用空格隔开)。
:after{content:".";clear:both;display:block;height:0;overflow:hidden;visibility:hidden;}
.clear{zoom:1}
-
父级div定义height
-
父级div定义overflow:hidden
-
父级div定义overflow:auto
-
父级div也一起浮动
-
父级div定义display:table
-
结尾处加br标签clear:both
参考:几种常用的清除浮动方法
https://www.cnblogs.com/nxl0908/p/7245460.html
为何要清除浮动
浮动框不属于文档流中的普通流,当元素浮动之后,不会影响块级元素的布局,只会影响内联元素布局。此时文档流中的普通流就会表现得该浮动框不存在一样的布局模式。当包含框的高度小于浮动框的时候,此时就会出现“高度塌陷”。
####CSS3动画的实现种类
CSS3属性中有关于制作动画的三个属性:
Transition(过渡),Transform(转换),Animation(动画)
####animation和transition的区别
**相同点:**都是随着时间改变元素的属性值。
**不同点:**transition需要触发一个事件(hover事件target事件或click事件等)才会随时间改变其css属性; 而animation在不需要触发任何事件的情况下也可以显式的随着时间变化来改变元素css的属性值,从而达到一种动画的效果,css3的animation就需要明确的动画属性值。
transition触发后只能运动一次,animation可以设定运动的循环次数。
Animation–>在这个动画之前,先看Keyframes关键帧,支持animation动画的只有webkit内核的浏览器
如何让chrome支持小于12px的文字?(css3中的缩放形式)
<style>
p span{
font-size:10px;
-webkit-transform:scale(0.8);
display:block;
}
</style>
<p><span>haorooms博客测试10px</span></p>
####iframe的优缺点
优点:
-
解决加载缓慢的第三方内容如图标和广告等的加载问题
-
Security sandbox
-
并行加载脚本
缺点:
-
iframe会阻塞主页面的Onload事件
-
即时内容为空,加载也需要时间
-
没有语意
回流和重绘
-
当render tree中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建。这就称为回流。每个页面至少需要一次回流,就是在页面第一次加载的时候。
-
当render tree中的一些元素需要更新属性,而这些属性只是影响元素的外观,风格,而不会影响布局的,比如background-color。则就叫称为重绘。
注:回流必将引起重绘,而重绘不一定会引起回流
回流就相当于整个页面发生了DOM上的变化 重绘就是样式发生了改变
区别:
他们的区别很大:
回流必将引起重绘,而重绘不一定会引起回流。比如:只有颜色改变的时候就只会发生重绘而不会引起回流
当页面布局和几何属性改变时就需要回流
比如:添加或者删除可见的DOM元素,元素位置改变,元素尺寸改变——边距、填充、边框、宽度和高度,内容改变
CSS选择符
类型选择符,id选择符,class选择符,通配符,群组选择符,包含选择符,伪类选择符(伪类选择符CSS中已经定义好的选择器,不能随便取名),伪对象选择符(设置在对象后发生的内容,用来和content属性一起使用 )
CSS选择符的权重
css中用四位数字表示权重,权重的表达方式如:0,0,0,0
类型选择符的权重为0001
class选择符的权重为0010
id选择符的权重为0100
子选择符的权重为0000
属性选择符的权重为0010
伪类选择符的权重为0010
伪元素选择符的权重为0001
包含选择符的权重:为包含选择符的权重之和
群组选择符的权重:为各自的权重
内联样式的权重为1000
继承样式的权重为0000
*通配符选择器权重为0
垂直水平居中
CSS2有定位
让一个元素实现垂直水平居中:
(1)给当前元素后面添加空标签,代码不换行,必须写在一行上。
(2)给当前元素和span添加display:inline-block;转换为内联块元素。
(3)给span添加height属性,与父级同高;
(4)给当前元素和span添加vertical-align:middle;实现垂直居中。
(5)给父元素添加text-align:center;实现水平居中。
让一个图片实现垂直水平居中:
(1)给当前元素后面添加空标签,代码不换行,必须写在一行上。
(2)给span添加display:inline-block;转换为内联块元素。(图片本身就是内联块元素,不需要再转换)
(3)给span添加height属性,与父级同高;
(4)给当前元素和span添加vertical-align:middle;实现垂直居中。
(5)给父元素添加text-align:center;实现水平居中。
水平居中:text-align:center:(1)对文本有效;(2)对内联元素、内联块元素有效。
当前元素为有宽度的块元素时,可以用margin:0 auto;实现水平居中。
垂直居中:vertical-align:middle;只对内联块元素有效。
用定位让元素或图片实现垂直水平居中:
(1)给父元素定位:position:relative;
(2)给子元素加绝对定位:position:absolute;
(3)给子元素添加坐标属性:top:0;left:0;right:0;bottom:0;margin:auto;
相当于给元素提供了四个参照范围
让一个元素在当前浏览器窗口垂直水平居中:
第一种方法:(1)给元素添加固定定位:position:fixed;
(2)给元素添加坐标属性:top:0;left:0;right:0;bottom:0;margin:auto;
第二种方法:(1)给元素添加固定定位position:fixed;
(2)top:50%;left:50%;
(3)margin:-元素高度/2px 0 0 -元素宽度/2px;
中心点的移动:从左上移到中心点
c3有弹性盒布局
给父元素添加:
display:flex;
justify-content: center;
align-items: center;
利用位移(定位加位移)
父元素:
positive:relative;
子元素:
position: absolute;
top:50%;
left:50%;
transform: translate(-元素宽度/2px,-元素高度/2px);
####两种引入外部样式表link和import之间的区别
差别1:本质的差别:link属于XHTML标签,而@import完全是CSS提供的一种方式。
差别2:加载顺序的差别:当一个页面被加载的时候(就是被浏览者浏览的时候),link引用的CSS会同时被加载,而@import引用的CSS会等到页面全部被下载完再被加载。所以有时候浏览@import加载CSS的页面时开始会没有样式(就是闪烁),网速慢的时候还挺明显。
差别3:兼容性的差别:@import是CSS2.1提出的,所以老的浏览器不支持,@import只有在IE5以上的才能识别,而link标签无此问题。
差别4:使用dom(document object model文档对象模型 )控制样式时的差别:当使用javascript控制dom去改变样式的时候,只能使用link标签,因为@import不是dom可以控制的。
简述src与href的区别
src用于替换当前元素,href用于在当前文档和引用资源之间确立联系。
src是source的缩写,指向外部资源的位置,指向的内容将会嵌入到文档中当前标签所在位置;在请求src资源时会将其指向的资源下载并应用到文档内,例如js脚本,img图片和frame等元素。
<script src =”js.js”></script>
当浏览器解析到该元素时,会暂停其他资源的下载和处理,直到将该资源加载、编译、执行完毕,图片和框架等元素也如此,类似于将所指向资源嵌入当前标签内。这也是为什么将js脚本放在底部而不是头部。
href是Hypertext Reference的缩写,指向网络资源所在位置,建立和当前元素(锚点)或当前文档(链接)之间的链接,如果我们在文档中添加
<link href="common.css" rel="stylesheet"/>
那么浏览器会识别该文档为css文件,就会并行下载资源并且不会停止对当前文档的处理。这也是为什么建议使用link方式来加载css,而不是使用@import方式。
伪类选择器
1、结构性伪类选择器
①:first-child选择某个元素的第一个子元素;IE6不支持:first-child选择器
②:last-child选择某个元素的最后一个子元素;
③:nth-child()选择某个元素的一个或多个特定的子元素;
④:nth-last-child()选择某个元素的一个或多个特定的元素,从这个元素的最后一个元素开始算;
⑤:nth-of-type()选择指定类型的元素;
nth-of-type类似于:nth-child,不同的是他只计算选择指定的元素类型。
⑥:nth-last-of-type()选择指定的元素,从元素的最后一个开始计算;
⑦:first-of-type选择一个上级元素下的第一个同类元素;
⑧:last-of-type选择一个上级元素的最后一个同类元素;
⑨:only-child选择的元素是它的父元素的唯一 一个子元素;
⑩:only-of-type选择一个元素是它的上级元素的唯一一个相同类型的子元素;
伪元素选择器
::first-line ::first-letter ::before ::after
CSS3新增:::selection 用来改变浏览网页选中文本的默认效果
CSS3中主要用两个"::“和一个”:"来区分伪类和伪元素
####用CSS写一个三角形
aside{
width:1px;
height:1px;
border:50px solid #fff;
border-bottom-color:red;
}
设置宽高为0或者1像素,需要哪个方向的三角形,就给哪个方向的边框单独加颜色。
font属性的简写
说明:font的属性值应按以下次序书写(各个属性之间用空格隔开)
顺序: font-style font-weight font-size / line-height font-family
####css实现文字溢出显示省略号
-
容器宽度:width:value;
-
强制文本在一行内显示:white-space:nowrap;
-
溢出内容为隐藏:overflow:hidden;
-
溢出文本显示省略号:text-overflow:ellipsis;
圣杯布局
left:左浮动;
right:右浮动;
center:overflow:hidden;
顺序:左右中,左浮右浮。
####自适应两栏布局
html,body{height:100%;}高度写百分比时,需要声明body和html的高度为100%。
布局:一左一右,左半部分浮动,非浮动元素会覆盖浮动元素的位置。
给右半部分添加overflow:hidden;
自适应,非浮动元素不加宽度。
只适用于pc端,比较简单的布局。
CSS3兼容
各主流浏览器都定义了私有属性,以便让用户体验 CSS3 的新特性。例如,
- Webkit 类型浏览器(如 Safari、Chrome)的私有属性是以
-webkit-前缀开始, - Gecko 类型的浏览器(如 Firefox)的私有属性是以
-moz-前缀开始, - Konqueror 类型的浏览器的私有属性是以
-khtml-前缀开始, - Opera 浏览器的私有属性是以
-o-前缀开始, - 而 Internet Explorer 浏览器的私有属性是以
-ms-前缀开始(目前只有 IE 8+ 支持-ms-前缀)。
什么是Css Hack?ie6,7,8的hack分别是什么?
针对不同的浏览器写不同的CSS code的过程,就是CSS hack。
#test {
width:300px;
height:300px;
background-color:blue; /*firefox*/
background-color:red\9; /*all ie*/
background-color:yellow; /*ie8*/
+background-color:pink; /*ie7*/
_background-color:orange; /*ie6*/ }
:root #test { background-color:purple\9; } /*ie9*/
@media all and (min-width:0px){ #test {background-color:black;} } /*opera*/
@media screen and (-webkit-min-device-pixel-ratio:0){ #test {background-color:gray;} } /*chrome and safari*/
###ES6
ES6的新特性
(1)let关键字:let关键字声明变量,只要遇到大括号,就形成作用域。
(2)const:const声明的变量,一旦被声明,就没有办法被修改。
(3)箭头函数
(4)变量的解构赋值
(5)字符串模板:使用反引号`表示,使用${变量|函数}嵌入代码
(6)数组的一些方法:
- Array.from():将伪数组转成真数组。(极少数的地方会用)
- copyWithin()了解:复制指定内容覆盖指定内容(指定数组的下标6、7替换下标2及以后)
- find() 功能:查找符合条件的第一个元素。
- findIndex(); 功能:查找符合条件的第一个元素的下标。
(7)Object.assign 合并对象
(8)第七种数据类型Symbol
(9)Set和Map集合
(10)Promise对象
(11)class定义类
箭头函数中this的指向
箭头函数:箭头函数本身是没有this和arguments的,在箭头函数中引用this实际上是调用的是定义时的上一层作用域的this。 这里强调的是上一层作用域,是因为对象是不能形成独立的作用域的。
例如:
var obj = {
say: function() {
var f1 = ()=>{
console.log("1111",this);
}
f1();
}
}
var o = obj.say;
o();//f1执行时,say函数指向window,所以f1中的this指向window
obj.say();//f1执行时,say函数指向obj,所以f1中的this指向obj;
var ojb = {
pro: {
getPro: ()=>{
console.log(this);
}
}
}
obj.pro.getPro();//this指向的是window,因为箭头函数定义时,getPro的上一级是pro,是一个对象,不能形成单独的作用域,故指向window。
参考:箭头函数中的this指向
https://blog.csdn.net/sinat_36263705/article/details/79778487
ES6新增了那些关于数组的方法
-
Array.from 这个东西就是把一些集合,或者长的像数组的伪数组转换成真的数组,比如arguments,js选择器找到dom集合,还有对象模拟的数组。
var obj = {'0' : 1,length : 1} Array.from(obj / arguments / 伪数组) //返回的是一个数组Array.from还有第二个参数,是一个回调函数,功能类似map Array.from( [1, 2, 3], item => item * 2 )
-
Array.of
Array.of(1, 2, 3, 4) //把参数合并成一个数组返回,如果参数为空,则返回一个空数组 -
find/findIndex
//find 返回数组中第一个符合条件的元素, findIndex返回索引 [1, 2, 3, 4, 5].find(function(item){ return item > 3 } -
fill
数组中的每一个元素替换成指定值 let arr = [1, 2, 3, 4] arr.fill(5) //arr全变成了5 指定范围替换 arr.fill(6, 1, 3) //arr=[1,6,6,4] -
entries/keys/values
let arr=['a', 'b', 'c'] for(let key of arr.keys()){} //取键 for(let value of arr.values()){} //取值 for(let [key, value] of arr.entries()){} //都取 -
includes
var a = function(){} [1, 2, 3, 4, a].includes(a) //true
var和let的区别
let关键字声明变量,只要遇到大括号,就形成作用域。
我们把let关键字,形成的作用域,叫做块级作用域。
let命令的特性
(1)let不存在变量提升
var命令会发生”变量提升“现象,即变量可以在声明之前使用,值为undefined。
let命令不存在变量提升的行为,它所声明的变量一定要在声明后使用,否则报错。
(2)暂时性死区
只要块级作用域内存在let命令声明变量之前,该变量都是不可用的。
这在语法上,称为“暂时性死区” temporal dead zone,简称 TDZ。
(3)不允许重复声明
let不允许在相同作用域内,重复声明同一个变量。
const命令
const声明的变量不得改变值,这意味着,const一旦声明变量,就必须立即初始化,不能留到以后赋值。
const声明一个只读的常量。一旦声明,常量的值就不能改变。
const声明的常量可以更改值吗
const a = [1, 2, 3];
a.push(4);
console.log(a)// 输出[1,2,3,4]
const实际上保证的,并不是变量的值不得改动,而是变量指向的那个内存地址所保存的数据不得改动。对于简单类型的数据(数值、字符串、布尔值),值就保存在变量指向的那个内存地址,因此等同于常量。但对于复合类型的数据(主要是对象和数组),变量指向的内存地址,保存的只是一个指向实际数据的指针,const只能保证这个指针是固定的(即总是指向另一个固定的地址),至于它指向的数据结构是不是可变的,就完全不能控制了。因此,将一个对象声明为常量必须非常小心。
const foo = {};
// 为 foo 添加一个属性,可以成功
foo.prop = 123;
foo.prop // 123
// 将 foo 指向另一个对象,就会报错
foo = {}; // TypeError: "foo" is read-only
上面代码中,常量foo储存的是一个地址,这个地址指向一个对象。不可变的只是这个地址,即不能把foo指向另一个地址,但对象本身是可变的,所以依然可以为其添加新属性。
参考:let 和 const 命令
http://es6.ruanyifeng.com/#docs/let
let const var 的区别?
1、let是es6新增的声明变量的方式 ,其特点是:
(1)作用域是块级作用域(在ES6之前,js只存在函数作用域以及全局作用域)
if(1){
let a=1;
console.log(a)
}
(2)不存在变量声明提前;
console.log(b); //ReferenceError: b is not defined
let b=2;
(3) 不能重复定义
let a=1;
let a=2;
console.log(a);//Identifier 'a' has already been declared
(4)存在暂时性死区:可以这样来理解
var a=1;
if(1){
console.log(a);
let a=2;
}
① 在一个块级作用域中,变量唯一存在,一旦在块级作用域中用let声明了一个变量,那么这个变量就唯一属于这个块级作用域,不受外部变量的影响;
② 无论在块中的任何地方声明了一个变量,那么在这个块级作用域中,任何使用这个名字的变量都是指这个变量,无论外部是否有其他同名的全局变量;
③ 暂时性死区的本质就是,只要一进入当前作用域,所要使用的变量就已经存在了,但是不可获取,只有等到声明变量的那一行代码出现,才可以获取和使用该变量。
④ 暂时性死区的意义:让我们标准化代码。将所有的变量的声明放在作用域的最开始。
2、 const一般用来声明常量,且声明的常量是不允许改变的,只读属性,因此就要在声明的同时赋值。const与let一样,都是块级作用域,存在暂时性死区,不存在变量声明提前,不允许重复定义
const A=1;(重新给常量A赋值会报错 )A=3;// Uncaught TypeError: Assignment to constant variable.(错误:赋值给常量)
3、 var 是es6之前 js用来声明变量的方法,其特性是:
(1)var的作用域是函数作用域,在一个函数内利用var声明一个变量,则这个变量只在这个函数内有效
function test(){
var a=1;
console.log(a);//函数未调用 输出的是undefined 函数调用输出的是1
}
console.log(a);//ReferenceError:a is not defined
(2)存在变量声明提前(虽然变量声明提前,但变量的赋值并没有提前,因此下面的程序不会报错,但a的值为undefined)
function test(){
console.log(a);//undefined
var a=3/a=3(隐式声明)
}
参考:let,const以及var三者的区别,面试经常会问哦!
https://blog.csdn.net/lydia11111/article/details/82292208
第七种数据类型Symbol
https://www.jianshu.com/p/f40a77bbd74e
Symbol函数会生成一个唯一的值
可以理解为Symbol类型跟字符串是接近的
但每次生成唯一的值,也就是每次都不相等,
至于它等于多少,并不重要,这对于一些字典变量,比较有用
每个Symbol实例都是唯一的。因此,当你比较两个Symbol实例的时候,将总会返回false
应用场景:可以使用Symbol来作为对象属性名(key)
在这之前,我们通常定义或访问对象的属性时都是使用字符串,而现在,Symbol可同样用于对对象属性的定义和访问,当使用了Symbol作为对象的属性key后,Symbol类型的key是不能通过Object.keys()或者for…in来枚举的,它被包含在对象自身的属性名集合(property names)之中。所以,利用该特性,我们可以把一些不需要对外操作和访问的属性使用Symbol来定义。也正因为这样一个特性,当使用JSON.stringfy()将对象转换成JSON字符串的时候,Symbol属性也会被排除在输出内容之外,我们可以利用这一特点来更好的设计我们的数据对象,让"对内操作"和"对外选择性输出"变得更加优雅。
数组的解构赋值
请实现该缺少的内部代码,交换两个数的值
ES5:交换
var res = (function(x,y){
let temp = x;
x= y;
y = temp;
return {
x:x,
y:y
}
})(1,2)
console.log(res.x)
console.log(res.y)
ES6:数组解构赋值
var res = (function (x, y) {
[y,x] = [x,y]
return {
x: x,
y: y
}
})(1, 2)
console.log(res.x)
console.log(res.y)
参考:数组的扩展
http://es6.ruanyifeng.com/?search=%E6%95%B0%E7%BB%84&x=0&y=0#docs/array
ES6中构造函数内super关键字的使用
super关键字用于访问和调用一个对象的父对象上的函数,是用来继承属性的 ES6 初始化对象的属性,在构造函数中使用时,super关键字将单独出现,并且必须在使用this关键字之前使用。
##JavaScript
TypeScript
TypeScript 是 JavaScript 的一个超集,支持 ECMAScript 6 标准。
const hello : string = “Hello World!”
console.log(hello)
让js语言更加的严谨
JS里面新建函数的方法?
- 通过new
var func = new Function("参数","函数体")
var func = new Function(“num1”,“num2”,“return num1 + num2”)
var result = func(1,1)
console.log(result)//2
- 通过函数表达式
var sum = function(num1,num2){
return num1 + num2
}
var result = sum(10,20)
console.log(result)
- 通过函数声明
function sum(num1,num2){
//上面的逻辑
}
DOM流
什么是事件流
事件流:描述的就是从页面中接受事件的顺序。
分有事件冒泡与事件捕获两种。
DOM事件流的三个阶段
-
事件捕获阶段
-
处于目标阶段
-
事件冒泡阶段
参考:DOM事件流
https://www.cnblogs.com/cmyoung/p/6033879.html
阻止事件冒泡和默认行为的方法
event.preventDefault() 阻止默认行为
event.stopPropagation() 阻止冒泡
非W3C标准:
e.cancelBubble=true 阻止事件冒泡
return false 阻止默认行为
return false 代表即阻止事件冒泡,又阻止了默认行为
事件委托的实现流程
-
找到要添加事件的节点:父节点、或者祖父节点
-
把事件添加在找到的父节点上
-
通过target触发对象,找到复合条件的元素节点,进行后续操作
IE:window.event.srcElement
标准:event.targe
window.onload = function(){
var oUl = document.getElementById('ull');
var aLi = document.getElementsByTagName('li');
oUl.onmouseover = function(ev){
var event = ev||window.event; // 获取event对象
var target = ev.target || ev.srcElement; // 获取触发事件的目标对象
if(target.nodeName.toLowerCase() == 'li'){ //判断目标对象是不是li
target.style.background = 'red';
}
}
代码中加了一个标签名的判断,主要原因是如果不加判断,当你鼠标移入到父级oUL上面的时候,整个列表就会变红,这不是我们想要的结果,所以要判断一下。
target.nodeName 弹出的名字是大写的,所以需要转换大小写再比较。
事件委托的实现是利用事件冒泡的机制
事件冒泡:由里向外逐渐触发
事件捕获:由外向里逐渐触发
事件监听器
-
能够给一个事件,添加多个函数
-
精确地删除某一个事件某一个函数(通过函数名)
-
会对称重复添加的函数,自动去重
*事件监听器是用来解决传统事件绑定的问题,一般情况下(99%)用传统的事件绑定
数据类型
####Javascript的基本数据类型
Number:数字(整数,浮点数float)
Array:数组
Object:对象
布尔类型:Boolean a==b
特殊类型:Null、Undefined、NaN
console.log(1+”2"+"2") //122
console.log(“1"-'2'+'2') //-12
console.log(‘A'+"B"+"2") //ab2
console.log(“A”-"B"+2)//NaN
JavaScript创建对象的几种方式
工厂方式,构造函数方式,原型模式,混合构造函数原型模式,动态原型方式
null和undefined的区别
null == undefined //true
null !==undefined
undefined:
(1)变量被声明了,但没有赋值时,就等于undefined。
(2) 调用函数时,应该提供的参数没有提供,该参数等于undefined。
(3)对象没有赋值的属性,该属性的值为undefined。
(4)函数没有返回值时,默认返回undefined。
null是空值,解除一段关系,把对象赋值成一个空指针,避免内存泄漏,不用的DOM对象一般指向为空,例如:arr = null,不占用内存。
数据类型不同:
typeof (undefined):undefined
typeof(null):object
补充:0和null的区别
0是一个数值,是自然数,有大小
0不等于null
call和apply和bind的区别
三者都是强制改变this的指向
在说区别之前还是先总结一下三者的相似之处:
1、都是用来改变函数的this对象的指向的。
2、第一个参数都是this要指向的对象。
3、都可以利用后续参数传参。
传参数的区别:
参数形式不同,call(obj, pra, pra)后面是单个参数。apply(obj, [args])后面是数组。
Object.call(this,obj1,obj2,obj3) call需要一个一个传参
Object.apply(this,arguments) apply可以传递数组
call与apply都属于Function.prototype的一个方法,所以每个function实例都会有call/apply属性。fn.call,fn是函数,函数下面有一个call方法,fn调用。两者传递参数不同,call函数第一个参数都是要传入当前对象的对象,apply不是,apply传入的是一个参数数组,也就是将多个参数组合成为一个数组传入。Call传入则是直接的参数列表,Call方法可以将一个函数的对象上下文从初始的上下文改成由thisObj指定的新对象。

call和apply立即修改this,Bind绑定的时候不会立马去执行,当函数调用的时候bind才会执行。
参考:javascript中apply、call和bind的区别
https://www.cnblogs.com/cosiray/p/4512969.html
break和continue的区别
break 终止当前循环的
continue 跳过这次循环,直接进入下一次循环。
声明提升
程序运行之前,有一个预编译。
预编译,会将代码从头看到尾,将需要的资源(内存)准备好。
然后才开始运动。
代码运行结果
var a;
alert(typeof a);
alert(b); //报错
var c = null;
alert(typeof c)
运行结果:Undefined/报错:b is not defined
var a;
alert(typeof a);
alert(typeof b); //undefined
var c = null;
alert(typeof c)
运行结果:Undefined/undefined/object
typeof:即使你没有定义这个变量也不会报错 只会弹出undefined
alert(typeof typeof undefined) // string
运行结果:string
var bb = 1;
function aa(bb) {
bb = 2;
alert(bb);
}
aa(bb); //2
alert(bb);//1 没有更改全局变量
运行结果:2 1
var bb = 1;
function aa() {
bb = 2;
alert(bb);
}
aa(bb); //2
alert(bb);//1 没有更改全局变量
运行结果:2 2
如果外部不传入bb,相当于你又声明了一个bb,所以结果是2 2
function Foo() {
var i = 0;
return function () {
console.log(i++);
}
}
var f1 = Foo();
f2 = Foo();
f1();//0 f1执行 打印i的值 i++是后+
f1();//1 f1维护自己的i
f2();//0 f2是一个新的函数 拿到的是新的i变量
运行结果:0 1 0
已知前端页面中,有如下table。请添加用户交互效果,当用户点击该表格的某一行的时候,该行背景色设置为红色的代码。
<table id="t1">
<tr></tr>
<tr></tr>
...
<tr></tr>
</table>
用jq来实现:让当前点击的对象改变背景颜色
var trDoms = document.getElementsByTagName("tr")
for (var i = 0; i < trDoms.length; i++) {
trDoms[i].onclick = function () {
this.style.background = "red"
console.log(i)
}
}
运行结果:3 3 3
想实现打印结果为:0 1 2,应如何操作?
第一种方法:获取对应索引
var trDoms = document.getElementsByTagName("tr")
for (var i = 0; i < trDoms.length; i++) {
trDoms[i].index = i;
trDoms[i].onclick = function () {
this.style.background = "red"
console.log(this.index)
}
}
第二种方法:闭包
var trDoms = document.getElementsByTagName("tr")
for (var i = 0; i < trDoms.length; i++) {
trDoms[i].onclick = function (i) {
return function(){
console.log(i)
}
}(i)
}
第三种方法:var改成let作用域
var trDoms = document.getElementsByTagName("tr")
for (let i = 0; i < trDoms.length; i++) {
trDoms[i].onclick = function () {
console.log(i)
}
}
请问以下结果会输出什么
for (var i = 0; i < 5; i++) {
console.log(i);
}// 0 1 2 3 4
for (var i = 0; i < 5; i++) {
setTimeout(function () {
console.log(i);
}, 1000 * i);
} // 异步打印5个5
for (var i = 0; i < 5; i++) {
(function (i) {
setTimeout(function () {
console.log(i);
}, 1000 * i);
})(i);
} // 异步打印 0 1 2 3 4 (闭包写法)
for (var i = 0; i < 5; i++) {
(function () {
setTimeout(function () {
console.log(i);
}, 1000 * i);
})(i);
} // 打印5个5(function不传i,i就是全局的i)
for (var i = 0; i < 5; i++) {
setTimeout((function () {
console.log(i);
})(i), 1000 * i);
} // 0 1 2 3 4
var myObject = {
foo: "bar",
func: function () {
var self = this;
console.log("outer func:",this.foo);//bar
console.log("outer func:",self.foo);//bar
(function () {
console.log("inner func",this.foo); //undefined 即时函数中this指向window
console.log("inner func",self.foo); //bar
})();
}
}
myObject.func();
(function () {
var a = b = 1; //声明局部变量 外部访问不到局部变量
})();
console.log(typeof a); //undefined 外部访问不到内部声明的局部变量
console.log(typeof b); //number
function DateDemo() {
for (var i = 0, j = 0; i < 10, j < 6; i++ , j++) {
k = i + j;
}
return k;
}
var t = DateDemo()
console.log(t)//10:5+5
设计模式
设计模式的分类
总体来说设计模式分为三大类:
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
其实还有两类:并发型模式和线程池模式。
闭包
闭包是什么
闭包是指有权访问另一个函数作用域中变量的函数,创建闭包的最常见的方式就是在一个函数内创建另一个函数,通过另一个函数访问这个函数的局部变量,利用闭包可以突破作用链域,将函数内部的变量和方法传递到外部。
闭包的特性
- 函数内再嵌套函数
- 内部函数可以引用外层的参数和变量
- 参数和变量不会被垃圾回收机制回收
闭包的作用
闭包用的多的两个作用:读取函数内部的变量值;让这些变量值始终保存着(在内存中)。
同时需要注意的是:闭包慎用,不滥用,不乱用,由于函数内部的变量都被保存在内存中,会导致内存消耗大。
闭包的优点
-
既不声明全局变量
-
又能进行累加
-
希望一个变量常驻在内存当中,避免全局变量污染
-
可以声明私有成员
闭包的缺点
滥用闭包函数会造成内存泄露,因为闭包中引用到的包裹函数中定义的变量都永远不会被释放,所以我们应该在必要的时候,及时释放这个闭包函数。
用一个案例解释闭包的作用
执行say667()后,say667()闭包内部变量会存在,而闭包内部函数的内部变量不会存在。使得Javascript的垃圾回收机制GC不会收回say667()所占用的资源,因为say667()的内部函数的执行需要依赖say667()中的变量。这是对闭包作用的非常直白的描述。
function say667() {
// Local variable that ends up within closure
var num = 666;
var sayAlert = function() { alert(num);
}
num++;
return sayAlert;
}
var sayAlert = say667();
sayAlert() //执行结果应该弹出的667
参考:
什么是闭包(closure),为什么要用它?
https://www.cnblogs.com/lqzweb/p/6215736.html
什么是闭包?写一个简单的闭包?
答:我的理解是,闭包就是能够读取其他函数内部变量的函数。在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁.

闭包的主要应用场景
- 匿名自执行函数
- 缓存
- 封装
- 实现类和继承
参考; javascript中的闭包主要在哪些地方用到
https://zhidao.baidu.com/question/749475289979461572.html
为什么要使用匿名函数自执行函数,好处是什么
定义变量时需要加上var,否则会默认添加到全局对象的属性上,或者别的函数可能误用这些变量;或者造成全局对象过于庞大,影响访问速度(因为变量的取值是需要从原型链上遍历的), 实际中有的函数只调用一次使用自执行函数也是很好的。
我们创建了一个匿名的函数,并立即执行它,由于外部无法引用它内部的变量,因此在执行完后很快就会被释放,关键是这种机制不会污染全局对象。
哪些操作会造成内存泄漏
内存泄漏指任何对象在您不再拥有或需要它之后仍然存在。
垃圾回收器定期扫描对象,并计算引用了每个对象的其他对象的数量。如果一个对象的引用数量为 0(没有其他对象引用过该对象),或对该对象的惟一引用是循环的,那么该对象的内存即可回收。
-
setTimeout 的第一个参数使用字符串而非函数的话,会引发内存泄漏。
-
闭包
-
控制台日志
-
循环(在两个对象彼此引用且彼此保留时,就会产生一个循环)
参考:
Js内存泄漏及解决方案
https://www.cnblogs.com/carekee/articles/1733847.html
JS哪些操作会造成内存泄漏?
https://www.jianshu.com/p/763ba9562864
Javascript中的垃圾回收机制
在Javascript中,如果一个对象不再被引用,那么这个对象就会被GC回收。如果两个对象互相引用,而不再被第3者所引用,那么这两个互相引用的对象也会被回收。因为函数a被b引用,b又被a外的c引用,这就是为什么 函数a执行后不会被回收的原因。
JS 垃圾回收机制的原理
内存泄漏:不再用到的内存,没有及时释放,就叫做内存泄漏。解决内存的泄露,垃圾回收机制会定期找出那些不再用到的内存(变量),然后释放其内存。
现在各大浏览器通常采用的垃圾回收机制有两种方法:标记清除,引用计数。
-
标记清除:js中最常用的垃圾回收方式就是标记清除。当变量进入环境时,例如,在一个函数中声明一个变量,就将这个变量标记为"进入环境",从逻辑上讲,永远不能释放进入环境变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为"离开环境"。
function test(){ var a = 10; *//*被标记*"*进入环境*"* var b = "hello"; *//*被标记*"*进入环境*"* test(); *//*执行完毕后之后,*a*和*b*又被标记*"*离开环境*"*,被回收 -
引用计数:语言引擎有一张"引用表",保存了内存里面所有资源(通常是各种值)的引用次数。如果一个值的引用次数是0,就表示这个值不再用到了,因此可以将这块内存释放。如果一个值不再需要了,引用数却不为0,垃圾回收机制无法释放这块内存,从而导致内存泄漏。
const arr = [1,2,3,4]; console.log("hello world")
上面的代码中,数组[1,2,3,4]是一个值,会占用内存。变量arr是仅有的对这个值的引用,因此引用次数为1。尽管后面的代码没有用到arr,它是会持续占用内存。
如果增加一行代码,解除arr对[1,2,3,4]引用,这块内存就可以被垃圾回收机制释放了。
let arr = [1,2,3,4];
console.log("hello world");
arr = null;
上面代码中,arr重置为null,就解除了对[1,2,3,4]的引用,引用次数变成了0,内存就可以释放出来了。
因此,并不是说有了垃圾回收机制,程序员就轻松了。你还是需要关注内存占用:那些很占空间的值,一旦不再用到,你必须检查是否还存在对它们的引用。如果是的话,就必须手动解除引用
JavaScript this指针、闭包、作用域
this:指向调用上下文
闭包:内层作用域可以访问外层作用域的变量
作用域:定义一个函数就开辟了一个局部作用域,整个js执行环境有一个全局作用域
原型链
JavaScript原型,原型链 ? 有什么特点?

* 原型对象也是普通的对象,是对象一个自带隐式的 proto 属性,原型也有可能有自己的原型,如果一个原型对象的原型不为null的话,我们就称之为原型链。
* 原型链是由一些用来继承和共享属性的对象组成的(有限的)对象链。
* JavaScript的数据对象有那些属性值?
writable:这个属性的值是否可以改。
configurable:这个属性的配置是否可以删除,修改。
enumerable:这个属性是否能在for…in循环中遍历出来或在Object.keys中列举出来。
value:属性值。
* 当我们需要一个属性的时,Javascript引擎会先看当前对象中是否有这个属性, 如果没有的话,就会查找他的Prototype对象是否有这个属性。
function clone(proto) {
function Dummy() { }
Dummy.prototype = proto;
Dummy.prototype.constructor = Dummy;
return new Dummy(); //等价于Object.create(Person);
}
function object(old) {
function F() {};
F.prototype = old;
return new F();
}
var newObj = object(oldObject);
Javascript如何实现继承?
原型链继承,借用构造函数继承,组合继承,寄生式继承,寄生组合继承
数组
for-of和for-in的区别
遍历数组的时候:
for-of通过key直接拿数组里面的值
for-in通过key拿数组的索引
遍历对象的时候:
for-in通过key拿属性值
for-of不可以遍历对象
遍历对象的方法,for of为什么不能遍历对象?
for-of可以遍历的:arr/map/string,因为他们中实现了Symbol.iterator属性
for of如何遍历对象
注意:for-of目前js实现的对象有array,string,argument以及后面更高级的set,Map
当我们遍历对象的时候可以使用for-in,不过这种遍历方式会把原型上的属性和方法也给遍历出来,当然我们可以通过hasOwnProperty来过滤掉除了实例对象的数据,但是for-of在object对象上暂时没有实现,但是我们可以通过Symbol.iterator给对象添加这个属性,我们就可以使用for-of了,代码如下:
var p = {
name:'kevin',
age:2,
sex:'male'
}
Object.defineProperty(p,Symbol.iterator,{
enumberable:false,
configurable:false,
writable:false,
value:function(){
var _this = this;
var nowIndex = -1;
var key = Object.keys(_this);
return {
next:function(){
nowIndex++;
return {
value:_this[key[nowIndex]],
done:(nowIndex+1>key.length)
}
}
}
}
})
//这样的话就可以直接通过for-of来遍历对象了
for(var i of p){
console.log(i) //kevin,2,male
}
for-in遍历数组存在的问题(for-in更适合遍历对象)
var myArray = [1,2,4,5,6,7]
myArray.name = "杀马特"
Array.prototype.method = function(){
console.log("length",this.length)
}
for(var index in myArray){
console.log("myArray",myArray[index])
}
使用for in 也可以遍历数组,但是会存在以下问题:
index索引为字符串型数字,不能直接进行几何运算
遍历顺序有可能不是按照实际数组的内部顺序
使用for in会遍历数组所有的可枚举属性,包括原型。例如上栗的原型方法method和name属性 所以for in更适合遍历对象,不要使用for in遍历数组。

使用for-of遍历数组:
//for-of遍历数组
var myArray = [1, 2, 4, 5, 6, 7]
myArray.name = "杀马特"
Array.prototype.method = function () {
console.log("length", this.length)
}
for (var index of myArray) {//这里的index输出的是value而不是索引
console.log("index", index)
}

for循环和forEach循环 哪个可以停止
for循环可以通过break停止,forEach一般是没有办法终止跳出。
如何实现forEach的终止跳出?
思路1 break 不能用,不可行,执行后会报错!
var arr = ['a','b','c']
arr.forEach((item,index) => {
if(item === 'b') break
console.log(item)
})
思路2 return false 会跳出当前的遍历执行==》a,c
var arr = ['a','b','c']
arr.forEach((item,index) => {
if(item === 'b') return false
console.log(item)
})
思路3 try…catch 语句跳出异常 //a exit done
try {
arr.forEach((item,index) => {
if(item === 'b') throw new Error('exist')
console.log(item)
})
} catch (e) {
if(e.message=='exist'){
console.log(e.message)
throw e
}
} finally {
console.log('done')
}
程序最后可以终止退出循环,所以使用try…catch通过抛出异常的方式来终止程序继续执行是可行。
arr.map arr.filter arr.reduce的作用分别是?
【arr.map】
遍历数组通常使用for循环,ES5的话也可以使用forEach,ES5具有遍历数组功能的还有map、filter、some、every、reduce、reduceRight等,只不过他们的返回结果不一样。但是使用foreach遍历数组的话,使用break不能中断循环,使用return也不能返回到外层函数
arr.map循环遍历,并且将符合条件的元素放入一个新数组返回
var arr = [1,2,3]
let b = [];
//map循环遍历,并且返回一个新数组
let a = arr.map(item=>{
if(item>2){
b.push(item)
return b
}
})
console.log(b) //返回符合条件的新数据[3]
因为react中没有v-for指令,所以循环渲染的时候需要用到arr.map方法来渲染视图
【arr.filter】
arr.filter 过滤器 可以过滤掉不符合要求的元素,内部返回false就直接过滤掉了,将符合条件的数据返回,也是不影响原数组。
//过滤器
arr = arr.filter(item=>{
return item>2
})
console.log(arr) //过滤出来符合条件的数据[3]
【arr.reduce】
reduce为数组中每一个元素依次执行回调函数,不包括数组中被删除或从未被赋值的元素,接收四个参数:初始值(或者上一次回调函数的返回值),当前元素值,当前索引,调用reduce的数组。reduce方法可以搞定的东西for循环或者forEach方法有时候也可以搞定。
var newArr = [4,5,6,7]
newArr.reduce((res,currentValue,index,arr)=>{//第一个参数为一个回调函数
console.log(res,currentValue,index) //4,5,1
})
//res:默认为第一个值(4),currentValue:当前值(5),index:当前值的索引(1)
let result = newArr.reduce((res,currentValue,index,arr)=>{
console.log(res,currentValue) //第一次:4,5;第二次:9,6;第三次:15,7
return res+currentValue//第一次:9;第二次:15;第三次:22;最后结果为22
},10)//第二个参数为一个初始值,这里给它赋值为10
console.log(result)//现在res就变成了10,currentValue变成了4,依次累加,10+22 初始值+累加值
Filter、forEach、map、reduce之间的区别联系?
作用
every():对数组中的每一项运行给定函数,如果该函数对每一项都返回 true ,则返回 true。
some():对数组中的每一项运行给定函数,如果该函数对任一项返回 true ,则返回 true
filter():对数组中的每一项运行给定函数,返回该函数会返回 true 的项组成的数组。
forEach():对数组中的每一项运行给定函数。这个方法没有返回值。
map():对数组中的每一项运行给定函数,返回每次函数调用的结果组成的数组。
相同点
他们的参数都一样:
- 在每一项上运行的函数(该函数有三个参数)
- 函数第一个参数:数组项的值
- 函数第二个参数:数组项的索引
- 函数第三个参数:数组对象本身
- 运行该函数的作用域对象——影响this的值(可选)
区别
filter()、forEach()、map()、some()、every()都是对数组的每一项调用函数进行处理。
区别:
– some()、every()的返回值 :true / false
– filter()、map()的返回值 :一个新数组
– forEach()无返回值。
使用filter()、forEach()、map()、some()、every()都不改变原数组。
参考:js小记:filter()、forEach()、map()、reduce()、reduceRight()的区别
https://blog.csdn.net/b954960630/article/details/81432881
splice()
splice(index,len,[item]) 注释:该方法会改变原始数组。
//删除起始下标为1,长度为1的一个值(len设置1,如果为0,则数组不变)
var arr = ['a','b','c','d'];
arr.splice(1,1);
console.log(arr); //['a','c','d'];
//替换起始下标为1,长度为1的一个值为‘ttt’,len设置的1
var arr = ['a','b','c','d'];
arr.splice(1,1,'ttt');
console.log(arr); //['a','ttt','c','d']
var arr = ['a','b','c','d'];
arr.splice(1,0,'ttt');
console.log(arr); //['a','ttt','b','c','d'] 表示在下标为1处添加一项'ttt'
slice()
slice()方法可以基于当前数组获取指定区域元素 [start, end)
格式:数组.slice(start, end);
参数:start和end都是下标,[start, end),获取指定范围内的元素,生成新数组。(原数组是不会改变的。)
返回值:提取出来元素组成的新数组。
split()和join()的区别
join函数获取一批字符串,然后用分隔符字符串将它们连接起来,从而返回一个字符串。
split()函数获取一个字符串,然后在分隔符处将其断开,从而返回一批字符串。
但是,这两个函数之间的区别在于join可以使用任何分割字符串将多个字符串连接起来,而split()只能使用一个字符分隔符将字符串断开。
简单地说,如果你用split(),是把一串字符串(根据某个分隔符)分成若干个元素存放在一个数组里。而join是把数组中的字符串连接成一个长串,可以大体上认为是split的逆操作。
push、pop、shift、unshift
-
push()方法可以在数组的末属添加一个或多个元素 -
shift()方法把数组中的第一个元素删除 -
unshift()方法可以在数组的前端添加一个或多个元素 -
pop()方法把数组中的最后一个元素删除
参考:数组的push()、pop()、shift()和unshift()方法
https://blog.csdn.net/qwe502763576/article/details/79055682
数组的方法
解析链接www.qq.com?name=jack&age=18&id=100,获取其中的查询参数,并格式为js对象的代码:如: {name:”jack”,age:18,id:100}
var str = "www.qq.com?name=jack&age=18";
var str2 = str.substring(str.lastIndexOf(“?")+1); //索引从后往前找
var arr = str2.split(“&”);//通过&符号去切割 切割成如下形式[‘name = jack’,’age=18’,'id=100']
var json = {};
for(var i=0;i<arr.length;i++){ //循环遍历数组的长度
var newArr = arr[i].split(“=“); //拿到每一个字符串 拿到之后通过split进行切割 [‘name’,’jack’]
json[newArr[0]] = newArr[1]; // key名=value
}
考查知识点:数组截取方法/数组中字符串操作/对象的中括号会不会用
对象的、数组的、字符串的相关的使用的比较多的方法
下列代码的运行结果是:
var array1 = [1,2];
var array2 = array1; // 数组指向的是同一个地址
array1[0] = array2[1]; // 把array[1]拿出来放在array1[0]的位置变成2,2
array2.push(3);
console.log(array1);// [2,2,3]
console.log(array2);// [2,2,3]
var arr = [1,2]
arr2 = arr;//arr2和arr1指向的是同一块内存空间
arr2.push(3)
console.log(arr) //[1,2,3]
var arr = [1,2]
arr2 = arr
arr = [1,2,3] //arr 指向了新的内存空间
arr2.push(4)
console.log(arr)//[1,2,3]
console.log(arr2)//[1,2,4]
var a = {n:1}
var b = a;
a.x = a = {n:2}
console.log(a); //a赋值了一个新的地址 输出{n:2}
console.log(b); //b指向的是a原来的地址 输出{n:1,x:{n:2}}
JS数组去重
- 利用splice方法
var arr = [10, 20, 30, 40, 50, 40, 30, 20, 20, 20, 20, 10];
function norepeat(arr){
for(var i = 0; i < arr.length - 1; i++){
for(var j = i + 1; j < arr.length; j++){
if(arr[i] === arr[j]){
arr.splice(j,1);
j--
}
}
}
}
alert(arr);//10,20,30,40,50,40,30,20,20,20,20,10
norepeat(arr);
alert(arr);//10,20,30,40,50
- 倒序删除
//倒序删除
function norepeat(arr){
for(var i = arr.length -1; i > 0; i--){
for(var j = i - 1;j >= 0; j--){
if(arr[i] === arr[j]){
arr.splice(j,1);
}
}
}
}
alert(arr);//10,20,30,40,50,40,30,20,20,20,20,10
norepeat(arr);
arr.reverse();
alert(arr);//10,20,30,40,50
- 利用对象的属性不会重复这一特性,校验数组元素是否重复
function unique(arr){
var obj = {};
var result = [];
for(var i=0;i<arr.length;i++){
if(!obj[arr[i]]){
result.push(arr[i]);
obj[arr[i]] = true; //将每个数作为key,属性值值为true,当key名相同时,判断属性值是否为false,不为false则不push进数组
}
}
return result;
}
-
ES6中新增了数据类型set,set的一个最大的特点就是数据不重复。Set函数可以接受一个数组(或类数组对象)作为参数来初始化,利用该特性也能做到给数组去重。
Set集合是默认去重复的,但前提是两个添加的元素严格相等,所以5和"5"不相等,两个new出来的字符串不相等。
下面展示了一种极为精巧的数组去重的方法
var newarr = […new Set(array)];
//拓展 固定写法
alert(arr);//10,20,30,40,50,40,30,20,20,20,20,10
//下述写法的值,就是去重以后的数组。
arr = [...new Set(arr)];
alert(arr);//10,20,30,40,50
跨域
什么是跨域
由于 Javascript 同源策略的存在使得一个源中加载来自其它源中资源的行为受到了限制。即会出现跨域请求禁止。
通俗一点说就是如果存在协议、域名、端口或者子域名不同服务端,或一者为IP地址,一者为域名地址(在跨域问题上,域仅仅是通过“ url的首部 ”来识别而不会去尝试判断相同的IP地址对应着两个域或者两个域是否同属同一个IP),之中任意服务端旗下的客户端发起请求其它服务端资源的访问行动都是跨域的,而浏览器为了安全问题一般都限制了跨域访问,也就是不允许跨域请求资源。
同源策略
-
同协议
-
同域名
-
同端口号
解决跨域问题的主流方案是什么
-
Jsonp 利用script标签发起get请求不会出现跨域禁止的特点实现
-
window.name+iframe 借助中介属性window.name实现
-
html5的 postMessage 主要侧重于前端通讯,不同域下页面之间的数据传递
-
Cors需要服务器设置header:Access-Control-Allow-Origin
-
Nginx反向代理 可以不需要目标服务器配合,不过需要Nginx中转服务器,用于转发请求(服务端之间的资源请求不会有跨域限制)
参考:Nginx反向代理、CORS、JSONP等跨域请求解决方法总结
https://blog.csdn.net/diudiu5201/article/details/54808142
cors实现请求跨域
https://blog.csdn.net/badmoonc/article/details/82706246
JQuery跨域方式
- 修改ajax的请求头(尽量不要用)
改成"Access-control-Allow-Origin"
-
通过PHP文件作为中转站,进行间接跨源(爬虫)
-
JSONP跨域
JSONP原理
动态创建script标签,src属性连接接口地址,callback参数就是服务器返回给我们的数据。
缺点:jsonp只支持get请求方式,post方式不支持。
####JSONP跨域的流程
-
在资源加载进来之前定义好一个函数,这个函数接收一个参数(数据),函数里面利用这个参数做一些事情。
-
然后需要的时候通过script标签加载对应的远程文件资源。
-
当远程文件加载进来的时候,就会去执行我们前面定义好的函数,并且把数据当做这个函数中的参数传进去。
####JSONP跨域的缺点
-
它只支持GET请求而不支持POST等其它类型的HTTP请求;
-
它只支持跨域HTTP请求这种情况,不能解决不同域的两个页面之间如何进行JavaScript调用的问题
-
json文件不能用jsonp方法。
AJAX
什么是AJAX
AJAX是一种用于快速创建动态网页的技术,通过在后台与服务器进行少量数据交换,AJAX可以实现网页实现异步更新,这意味着可以在不加载整个网页的情况下,对网页的某部分进行更新。
传统的网页(不使用AJAX)如果需要更新内容,必须重载整个网页。
AJAX的原理
**思路:**先解释异步,再解释ajax如何使用
Ajax的原理简单来说通过XmlHttpRequest对象来向服务器发异步请求,从服务器获得数据,然后用javascript来操作DOM而更新页面。这其中最关键的一步就是从服务器获得请求数据。要清楚这个过程和原理,我们必须对 XMLHttpRequest有所了解。
XMLHttpRequest是ajax的核心机制,它是在IE5中首先引入的,是一种支持异步请求的技术。简单的说,也就是javascript可以及时向服务器提出请求和处理响应,而不阻塞用户。达到无刷新的效果。
AJAX的优点
AJAX不是新的编程语言,而是一种使用现有标准的新方法。
AJAX最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容。
AJAX不需要任何浏览器插件,但需要用户允许JavaScript在浏览器上运行。
AJAX的缺点
-
AJAX干掉了Back和History功能,即对浏览器机制的破坏。 在动态更新页面的情况下,用户无法回到前一个页面状态,因为浏览器仅能记忆历史记录中的静态页面。一个被完整读入的页面与一个已经被动态修改过的页面之间的差别非常微妙;用户通常会希望单击后退按钮能够取消他们的前一次操作,但是在Ajax应用程序中,这将无法实现。
-
安全问题技术同时也对IT企业带来了新的安全威胁,ajax技术就如同对企业数据建立了一个直接通道。这使得开发者在不经意间会暴露比以前更多的数据和服务器逻辑。ajax的逻辑可以对客户端的安全扫描技术隐藏起来,允许黑客从远端服务器上建立新的攻击。还有ajax也难以避免一些已知的安全弱点,诸如跨站点脚步攻击、SQL注入攻击和基于credentials的安全漏洞等。
-
对搜索引擎的支持比较弱。如果使用不当,AJAX会增大网络数据的流量,从而降低整个系统的性能。
AJAX状态码说明
1**:请求收到,继续处理
2**:操作成功收到,分析、接受
3**:完成此请求必须进一步处理
4**:请求包含一个错误语法或不能完成
5**:服务器执行一个完全有效请求失败
AJAX的流程
- 声明Ajax对象xhr,创建 XMLHttpRequest 实例
IE8以后才有如下声明的方式
var xhr = new XMLHttpRequest();
XMLHttpRequest()是AJAX的原生对象
- 一旦新建实例,就可以使用
open()方法发出 HTTP 请求。
填写请求信息,发出 HTTP 请求
第一个参数:请求方式:get/post
第二个参数:url(统一资源定位符)
第三个参数:true/false true异步,false同步
xhr.open('GET', 'http://www.example.com/page.php', true);
- 向服务器发送请求
xhr.send(),正在发送请求
- 等待数据响应,接收服务器传回的数据
xhr.onreadystatechange = function(){}
在回调函数中进行请求状态readyState的监控
当 readyState 等于 4 且状态为 200 时,表示响应内容解析完成,可以在客户端调用了。
返回的内容:
responseText:返回以文本形式存放的内容
responseXML:返回XML形式的内容
- 更新网页数据
AJAX中的GET和POST请求
get一般用来进行查询操作,url地址有长度限制,请求的参数都暴露在url地址当中,如果传递中文参数,需要自己进行编码操作,安全性较低。
post请求方式主要用来提交数据,没有数据长度的限制,提交的数据内容存在于http请求体中,数据不会暴漏在url地址中。
GET 还是 POST?
与 POST 相比,GET 更简单也更快,并且在大部分情况下都能用。
然而,在以下情况中,请使用 POST 请求:
- 无法使用缓存文件(更新服务器上的文件或数据库)
- 向服务器发送大量数据(POST 没有数据量限制)
- 发送包含未知字符的用户输入时,POST 比 GET 更稳定也更可靠
AJAX如何实现跨域
理解跨域的概念:协议、域名、端口都相同才同域,否则都是跨域。
出于安全考虑,服务器不允许ajax跨域获取数据,但是可以跨域获取文件内容,所以基于这一点,可以动态创建script标签,使用标签的src属性访问js文件的形式获取js脚本,并且这个js脚本中的内容是函数调用,该函数调用的参数是服务器返回的数据,为了获取这里的参数数据,需要事先在页面中定义回调函数,在回调函数中处理服务器返回的数据,这就是解决跨域问题的主流解决方案。
一个页面从输入URL到页面加载显示完成,这个过程中都发生了什么?
分为4个步骤:
-
当发送一个 URL 请求时,不管这个 URL 是 Web 页面的 URL 还是 Web 页面上每个资源的 URL,浏览器都会开启一个线程来处理这个请求,同时在远程 DNS 服务器上启动一个 DNS 查询。这能使浏览器获得请求对应的 IP 地址。
-
浏览器与远程 Web 服务器通过 TCP 三次握手协商来建立一个 TCP/IP 连接。该握手包括一个同步报文,一个同步-应答报文和一个应答报文,这三个报文在 浏览器和服务器之间传递。该握手首先由客户端尝试建立起通信,而后服务器应答并接受客户端的请求,最后由客户端发出该请求已经被接受的报文。
-
一旦 TCP/IP 连接建立,浏览器会通过该连接向远程服务器发送 HTTP 的 GET 请求。远程服务器找到资源并使用 HTTP 响应返回该资源,值为 200 的 HTTP 响应状态表示一个正确的响应。
-
此时,Web 服务器提供资源服务,客户端开始下载资源。
从用户输入URL,到浏览器呈现给用户页面,经过了什么过程?
用户输入URL,浏览器获取到URL
浏览器(应用层)进行DNS解析(如果输入的是IP地址,此步骤省略)
根据解析出的IP地址+端口,浏览器(应用层)发起HTTP请求,请求中携带(请求头header(也可细分为请求行和请求头)、请求体body),
header包含:
请求的方法(get、post、put…)
协议(http、https、ftp、sftp…)
目标url(具体的请求路径已经文件名)
一些必要信息(缓存、cookie之类)
body包含:
请求的内容
请求到达传输层,tcp协议为传输报文提供可靠的字节流传输服务,它通过三次握手等手段来保证传输过程中的安全可靠。通过对大块数据的分割成一个个报文段的方式提供给大量数据的便携传输。
到网络层, 网络层通过ARP寻址得到接收方的Mac地址,IP协议把在传输层被分割成一个个数据包传送接收方。
数据到达数据链路层,请求阶段完成
接收方在数据链路层收到数据包之后,层层传递到应用层,接收方应用程序就获得到请求报文。
接收方收到发送方的HTTP请求之后,进行请求文件资源(如HTML页面)的寻找并响应报文。
发送方收到响应报文后,如果报文中的状态码表示请求成功,则接受返回的资源(如HTML文件),进行页面渲染。
fetch
什么是fetch?
fetch号称是AJAX的替代品,是在ES6出现的,使用了ES6中的promise对象。Fetch是基于promise设计的。Fetch的代码结构比起ajax简单多了,参数有点像jQuery ajax。但是,一定记住fetch不是ajax的进一步封装,而是原生js,没有使用XMLHttpRequest对象。
try {
let response = await fetch(url);
let data = response.json();
console.log(data);
} catch(e) {
console.log("Oops, error", e);
}
fetch的优点
- 符合关注分离,没有将输入、输出和用事件来跟踪的状态混杂在一个对象里。
- 更好更方便的写法
fetch的优势
- 语法简洁,更加语义化
- 基于标准 Promise 实现,支持 async/await
- 同构方便,使用 isomorphic-fetch
- 更加底层,提供的API丰富(request, response)
- 脱离了XHR,是ES规范里新的实现方式
fetch的劣势
- fetch只对网络请求报错,对400,500都当做成功的请求,服务器返回 400,500 错误码时并不会 reject,只有网络错误这些导致请求不能完成时,fetch 才会被 reject。
- fetch默认不会带cookie,需要添加配置项: fetch(url, {credentials: ‘include’})
- fetch不支持abort,不支持超时控制,使用setTimeout及Promise.reject的实现的超时控制并不能阻止请求过程继续在后台运行,造成了流量的浪费
- fetch没有办法原生监测请求的进度,而XHR可以
axios
axios是什么
Axios 是一个基于 promise 的 HTTP 库,可以用在浏览器和 node.js 中,主要是用于向后台发起请求的。
axios的用途
(1)向后台发送ajax请求数据。
(2) axios可以支持高并发请求,可以同时请求多个接口。
(3) axios可以防止CSRF/XSRF(跨站请求伪造)钓鱼网站。
(4)axios提供了拦截器、catch捕获。
封装axios
Get
import axios from 'axios'
export default ({url,data})=>{
return axios.get(url,{
params:data
})
}
Post
import axios from 'axios'
import qs from 'querystring'
export default ({url,data})=>{
return axios.post(url,qs.stringify(data))
}
利用axios实现数据请求
引入axios之后就可以在实例/组件上挂载一个$http属性,用这个就可以进行数据交互了。
提供了一个get方法,执行this.$http.get().then()可以异步执行,拿到promise对象的值
axios如何防止CSRF(跨站攻击)
在a页面登录注册成功后时候跳转到b页面,b页面可以获取你的cookie信息,把你的用户信息拦截到,然后恶意向别的网站散发一些邮件或者其他的东西,当你使用axios之后,就可以防止这种攻击,a页面存储的时候往cookie添加一个唯一个key,b页面如果是别的域名是获取不到这个key的,钓鱼网站就是把b页面这个域名篡改到别的位置去了,所以它无法获取到key值,也就拿不到用户信息,这样可以防止钓鱼网站的威胁。
如何在项目中通过路由守卫来实现登录拦截?讲一个在项目中使用路由守卫的案例?
拦截器的工作流程:

第一步:路由拦截
首先在定义路由的时候就需要多添加一个自定义字段requireAuth,用于判断该路由的访问是否需要登录。如果用户已经登录,则顺利进入路由, 否则就进入登录页面。
const routes = [
{
path: '/',
name: '/',
component: Index
},
{
path: '/repository',
name: 'repository',
meta: {
requireAuth: true, // 添加该字段,表示进入这个路由是需要登录的
},
component: Repository
},
{
path: '/login',
name: 'login',
component: Login
}
];
定义完路由后,我们主要是利用vue-router提供的钩子函数beforeEach()对路由进行判断。
router.beforeEach((to, from, next) => {
if (to.meta.requireAuth) { // 判断该路由是否需要登录权限
if (store.state.token) { // 通过vuex state获取当前的token是否存在
next();
}
else {
next({
path: '/login',
query: {redirect: to.fullPath} // 将跳转的路由path作为参数,登录成功后跳转到该路由
})
}
}
else {
next();
}
})
其中,to.meta中是我们自定义的数据,其中就包括我们刚刚定义的requireAuth字段。通过这个字段来判断该路由是否需要登录权限。需要的话,同时当前应用不存在token,则跳转到登录页面,进行登录。登录成功后跳转到目标路由。
登录拦截到这里就结束了吗?并没有。这种方式只是简单的前端路由控制,并不能真正阻止用户访问需要登录权限的路由。还有一种情况便是:当前token失效了,但是token依然保存在本地。这时候你去访问需要登录权限的路由时,实际上应该让用户重新登录。
这时候就需要结合 http 拦截器 + 后端接口返回的http 状态码来判断。(具体方法见下一题目)
axios+vue如何在前端实现登录拦截?(路由拦截、http拦截)
登录流程控制中,根据本地是否存在token判断用户的登录情况,但是即使token存在,也有可能token是过期的,所以在每次的请求头中携带token,后台根据携带的token判断用户的登录情况,并返回给我们对应的状态码,而后我们可以在响应拦截器中,根据状态码进行一些统一的操作。
// 先导入vuex,因为我们要使用到里面的状态对象
// vuex的路径根据自己的路径去写
import store from '@/store/index';
// 请求拦截器axios.interceptors.request.use( //axios的一个方法,用于请求之前拦截
config => {
// 每次发送请求之前判断vuex中是否存在token
// 如果存在,则统一在http请求的header都加上token,这样后台根据token判断你的登录情况
// 即使本地存在token,也有可能token是过期的,所以在响应拦截器中要对返回状态进行判断
const token = store.state.token;
token && (config.headers.Authorization = token); (Authorization是后端自定义的名字) // 判断vuex中是否存在token,如果存在的话,则在每个http请求时header都加上token
return config; //再把这个请求发送给我们的后台
},
error => {
return Promise.error(error); //如果有错误直接返回报错的相关内容
})
如果后台传递过来的状态码是失效状态,就需要在response响应拦截器中清除本地token和清空vuex中token对象,通过commit触发mutations方法来同步更改vuex中的状态,清空token之后跳转到登录页面,让用户重新登录。
// 清除token
localStorage.removeItem('token');
store.commit('loginSuccess', null);
// 跳转登录页面,并将要浏览的页面fullPath传过去,登录成功后跳转需要访问的页面
setTimeout(() => {
router.replace({
path: '/login',
query: {
redirect: router.currentRoute.fullPath
}
});
}, 1000);
完整方法见:vue中Axios的封装和API接口的管理
https://juejin.im/post/5b55c118f265da0f6f1aa354
vue+axios 前端实现登录拦截(路由拦截、http拦截)
https://www.cnblogs.com/guoxianglei/p/7084506.html
一个axios的简单教程
https://www.jianshu.com/p/13cf01cdb81f
axios与fetch、ajax区别?
(1)fetch和axios差不多,都是基于promise的,fetch没有封装xhr(ajax的原生对象),是新的语法,默认不传cookie,也监听不到请求的进度,axios可以监听到请求的进度。
(2)axios返回一个promise对象,拿到对象之后再去.then可以拿到resolve之后的内容。
axios.get(url,{params:{}}).then(res=>{}).catch(err=>{});
axios.post(url,{}).then(res=>).catch(err=>{});
(3)ajax主要是利用callback回调函数的形式。
JQuery中的ajax:$.ajax({url,data,success(){}}) 在回调函数获取数据
axios 和 ajax 的使用方法基本一样,只有个别参数不同;
axios({
url: 'http://jsonplaceholder.typicode.com/users',
method: 'get',
responseType: 'json', // 默认的
data: {
//'a': 1,
//'b': 2,
}
}).then(function (response) {
console.log(response);
console.log(response.data);
}).catch(function (error) {
console.log(error);
})
$.ajax({
url: 'http://jsonplaceholder.typicode.com/users',
type: 'get',
dataType: 'json',
data: {
//'a': 1,
//'b': 2,
},
success: function (response) {
console.log(response);
}
})
参考:ajax和axios、fetch的区别
https://www.jianshu.com/p/8bc48f8fde75
JSON
什么是 JSON ?
- JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation)
- JSON 是轻量级的文本数据交换格式
- JSON 独立于语言:JSON 使用 Javascript语法来描述数据对象,但是 JSON 仍然独立于语言和平台。JSON 解析器和 JSON 库支持许多不同的编程语言。 目前非常多的动态(PHP,JSP,.NET)编程语言都支持JSON。
- JSON 具有自我描述性,更易理解
与 XML 相同之处
- JSON 是纯文本
- JSON 具有"自我描述性"(人类可读)
- JSON 具有层级结构(值中存在值)
- JSON 可通过 JavaScript 进行解析
- JSON 数据可使用 AJAX 进行传输
与 XML 不同之处
- 没有结束标签
- 更短
- 读写的速度更快
- 能够使用内建的 JavaScript eval() 方法进行解析
- 使用数组
- 不使用保留字
为什么使用 JSON?
对于 AJAX 应用程序来说,JSON 比 XML 更快更易使用:
使用 XML
- 读取 XML 文档
- 使用 XML DOM 来循环遍历文档
- 读取值并存储在变量中
使用 JSON
- 读取 JSON 字符串
- 用 eval() 处理 JSON 字符串
js中想要把json字符串转化为js对象的方式
-
JSON.parse()
-
eval()
假设我们有一个json字符串
var str = '{"friends":[{"name":"梅梅","age":29,"sex":"女"},' +
'{"name":"李华","age":18,"sex":"男"}]' +
'}';
使用 JSON.parse()方法来转化
var str = '{"friends":[{"name":"梅梅","age":29,"sex":"女"},' +
'{"name":"李华","age":18,"sex":"男"}]' +
'}';
JSON.parse(str);
使用 eval()方法传化:
var str = '{"friends":[{"name":"梅梅","age":29,"sex":"女"},' +
'{"name":"李华","age":18,"sex":"男"}]' +
'}';
eval('('+str+')');
注意点: 通过 eval 来转化,如果返回的字符串内容是一个数组,可以直接转化,如果返回的字符串内容是一个对象,必须在字符串的前后加上()
当字符串内容是一个数组时 ,eval()的转化方式:
var arr = '[{"name":"唐老鸭","sex":"男"},{"name":"红太狼","sex":"女"}]';
eval(arr);
JSON.parse() 和 eval() 的区别
-
eval方法不会去检查给的字符串是否符合json的格式,而JSON.parse解析不满足json格式的字符串时,会报错。
-
如果给的字符串中存在js代码eval也会一并执行,比如下面的代码段:
var str1 = '{"log":alert("我被会执行的")}';
eval("("+str1+")");
执行该代码片段,会将 alert 语句作为js代码来执行,如果我们在开发中建议使用JSON.parse来转化,这样可以避免很多隐患,比如,我们访问第三方提供的接口,返回的串中包含 window.location.href这样的内容,那么执行了就会跳转到不明网站,好危险,所以最好还是使用JSON.parse()来解析。
JSON.parse()
JSON 通常用于与服务端交换数据。
在接收服务器数据时一般是字符串。
我们可以使用 JSON.parse() 方法将数据转换为 JavaScript 对象。
JSON.parse(text[, reviver])
JSON.stringify()
JSON 通常用于与服务端交换数据。
在向服务器发送数据时一般是字符串。
我们可以使用 JSON.stringify() 方法将 JavaScript 对象转换为字符串。
JSON.stringify(value[, replacer[, space]])
Promise
同步异步函数的区别
同步:阻塞,当前程序必须等前面一个程序执行完毕以后,才能够执行。
异步:非阻塞,前一个程序是否执行完毕,不影响后面程序的执行。
promise、async、await
async函数返回的是一个 Promise 对象,可以使用 then 方法添加回调函数,async 函数内部 return 语句返回的值,会成为 then 方法回调函数的参数。当函数执行的时候,一旦遇到await就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。
await只能用在异步函数中,使用await必须要先使用async,命令后面返回的是Promise对象,运行结果可能是rejected,所以最好把await命令放在try…catch代码块中。
Promise的概念
我理解的Promise就是一套为处理异步情况的方法。先创建一个promise对象来注册一个委托,其中包括委托成功及失败后的处理函数。然后基于这种表述方式,来将promise应用到各种异步处理的情况中。
promise写法案例
var promise = getAsyncPromise('fileA.txt');
promise.then( function(result){
// 成功时的处理办法
}).catch( function(error){
// 失败时的处理办法
})
// 返回一个promise对象
promise三个状态
pending(进行中)、fulfilled(已成功)和rejected(已失败)
Promise 实际就是一个对象, 从它可以获得异步操作的消息,Promise 对象有三种状态,pending(进行中)、fulfilled(已成功)和rejected(已失败)。Promise 的状态一旦改变之后,就不会在发生任何变化,将回调函数变成了链式调用。
Promise的设计思想是,所有异步任务都返回一个Promise实例。Promise实例有一个then方法,用来指定下一步的回调函数。
总的来说,传统的回调函数写法使得代码混成一团,变得横向发展而不是向下发展。Promise就是解决这个问题,使得异步流程可以写成同步流程。
Promise构造函数
JavaScript 提供原生的Promise构造函数,用来生成 Promise 实例。
var promise = new Promise(function (resolve, reject) {
// ...
if (/* 异步操作成功 */){
resolve(value);
} else { /* 异步操作失败 */
reject(new Error());
}
});
上面代码中,Promise构造函数接受一个函数作为参数,该函数的两个参数分别是resolve和reject。它们是两个函数,由JavaScript引擎提供,不用自己实现。
resolve函数的作用是,将Promise实例的状态从"未完成"变为"成功"(即从pending变为fulfilled),在异步操作成功时调用,并将异步操作的结果,作为参数传递出去。reject函数的作用是,将Promise实例的状态从"未完成"变为"失败"(即从pending变为rejected),在异步失败时调用,并将异步操作报出的错误,作为参数传递出去。
Promise的优缺点
Promise 的优点在于,让回调函数变成了规范的链式写法,程序流程可以看得很清楚。它有一整套接口,可以实现许多强大的功能,比如同时执行多个异步操作,等到它们的状态都改变以后,再执行一个回调函数;再比如,为多个回调函数中抛出的错误,统一指定处理方法等等。
而且,Promise 还有一个传统写法没有的好处:它的状态一旦改变,无论何时查询,都能得到这个状态。这意味着,无论何时为 Promise 实例添加回调函数,该函数都能正确执行。所以,你不用担心是否错过了某个事件或信号。如果是传统写法,通过监听事件来执行回调函数,一旦错过了事件,再添加回调函数是不会执行的。
Promise 的缺点是,编写的难度比传统写法高,而且阅读代码也不是一眼可以看懂。你只会看到一堆then,必须自己在then的回调函数里面理清逻辑。
Promise的优点
promise优点主要解决回调地狱问题,使得原本的多层级的嵌套代码,变成了链式调用,让代码更清晰,减少嵌套数。
Promise的缺点
首先,无法取消Promise,一旦新建它就会立即执行,无法中途取消。其次,如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。当处于Pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)。
Promise的all方法
all方法是promise是类上自带的方法,并发读取,失败一个都失败了,时间只是一个读取的时间
第一个参数 传递的是数组,数组装的是一个个promise对象
调用后会再次返回一个promise实例
最好的写法
Promise.all([read('./name.txt'),read('./age.txt')]).then(([name,age])=>{
//data就是promise执行成功的结果类型是数组
console.log({name,age});
}).catch((err)=>{
console.log(err)
})
Promise的race方法
Promise.race ([promise1,promise2…])
当参数里的任意一个promise成功或失败后,该函数就会返回,并使用这个promise对象的值进行resolve或reject
let promise1 = ajax({method:'GET',url:'/x.json'});
let promise2 = ajax({method:'GET',url:'/y.json'});
Promise.all([promise1,promise2]).then(function(){
console.log('两个promise都执行完成了')
});
Promise.race([promise1,promise2]).then(function(){
console.log('有一个promise先执行完成了')
})
参考:简单理解Promise
https://www.jianshu.com/p/c8f9fba03df9
存储
本地存储(Local Storage )和cookies(储存在用户本地终端上的数据)之间的区别是什么?
Cookies:服务器和客户端都可以访问;大小只有4KB左右;有有效期,过期后将会删除;
本地存储:只有本地浏览器端可访问数据,服务器不能访问本地存储,直到故意通过POST或者GET的通道发送到服务器;每个域5MB;没有过期数据,它将保留直到用户从浏览器清除或者使用Javascript代码移除。
cookie 4kb 随http请求发送到服务端 后端可以帮助前端设置cookie
session 放在服务端 一般存放用户比较重要的信息
(token 令牌 token ==> cookie /localstorage) vuex
localStorage 本地存储(h5的新特性 draggable canvas svg)
5M 纯粹在本地客户端 多个标签页共享数据
sessionStorage 会话级别的存储
往本地页面中存值的方法(localStorage.setItem(key,value))
讲一下cookie、sessionstorage、localstorage
相同点:都存储在客户端
不同点:
1.存储大小
- cookie数据大小不能超过4k。
- sessionStorage和localStorage 虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大。
2.有效时间
- localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据;
- sessionStorage 数据在当前浏览器窗口关闭后自动删除。
- cookie 设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭
3.数据与服务器之间的交互方式
- cookie的数据会自动的传递到服务器,服务器端也可以写cookie到客户端
- sessionStorage和localStorage不会自动把数据发给服务器,仅在本地保存。
定义一个对象,里面包含用户名、电话,然后将其存入localStorage的代码
var json = {username:"张三",phone:17650246248}
for(var key in json){
localStorage.setItem(key,json[key]);
}
cookie和session的区别
-
保持状态:cookie保存在浏览器端,session保存在服务器端
-
使用方式:如果不在浏览器中设置过期时间,cookie被保存在内存中,生命周期随浏览器的关闭而结束,这种cookie简称会话cookie。如果在浏览器中设置了cookie的过期时间,cookie被保存在硬盘中,关闭浏览器后,cookie数据仍然存在,直到过期时间结束才消失。
-
存储内容:cookie只能保存字符串类型,以文本的方式;session通过类似与Hashtable的数据结构来保存,能支持任何类型的对象(session中可含有多个对象)
-
存储的大小:cookie:单个cookie保存的数据不能超过4kb;session大小没有限制。
-
安全性:cookie:针对cookie所存在的攻击:Cookie欺骗,Cookie截获;session的安全性大于cookie。
-
应用场景:
cookie:(1)判断用户是否登陆过网站,以便下次登录时能够实现自动登录(或者记住密码)。如果我们删除cookie,则每次登录必须从新填写登录的相关信息。
(2)保存上次登录的时间等信息。
(3)保存上次查看的页面
(4)浏览计数
session:Session用于保存每个用户的专用信息,变量的值保存在服务器端,通过SessionID来区分不同的客户。
(1)网上商城中的购物车
(2)保存用户登录信息
(3)将某些数据放入session中,供同一用户的不同页面使用
(4)防止用户非法登录
-
缺点:
cookie:
(1)大小受限
(2)用户可以操作(禁用)cookie,使功能受限
(3)安全性较低
(4)有些状态不可能保存在客户端。
(5)每次访问都要传送cookie给服务器,浪费带宽。
(6)cookie数据有路径(path)的概念,可以限制cookie只属于某个路径。
session:
(1)Session保存的东西越多,就越占用服务器内存,对于用户在线人数较多的网站,服务器的内存压力会比较大。
(2)依赖于cookie(sessionID保存在cookie),如果禁用cookie,则要使用URL重写,不安全
(3)创建Session变量有很大的随意性,可随时调用,不需要开发者做精确地处理,所以,过度使用session变量将会导致代码不可读而且不好维护。
####WebStorage
WebStorage的目的是克服由cookie所带来的一些限制,当数据需要被严格控制在客户端时,不需要持续的将数据发回服务器。
WebStorage两个主要目标:
(1)提供一种在cookie之外存储会话数据的路径。
(2)提供一种存储大量可以跨会话存在的数据的机制。
Localstroage与SessionStorage存储的区别
HTML5的WebStorage提供了两种API:localStorage(本地存储)和sessionStorage(会话存储)。
- 生命周期:localStorage:localStorage的生命周期是永久的,关闭页面或浏览器之后localStorage中的数据也不会消失。
localStorage除非主动删除数据,否则数据永远不会消失。
sessionStorage的生命周期是在仅在当前会话下有效。sessionStorage引入了一个“浏览器窗口”的概念,sessionStorage是在同源的窗口中始终存在的数据。只要这个浏览器窗口没有关闭,即使刷新页面或者进入同源另一个页面,数据依然存在。但是sessionStorage在关闭了浏览器窗口后就会被销毁。同时独立的打开同一个窗口同一个页面,sessionStorage也是不一样的。
-
存储大小:localStorage和sessionStorage的存储数据大小一般都是:5MB
-
存储位置:localStorage和sessionStorage都保存在客户端,不与服务器进行交互通信。
-
存储内容类型:localStorage和sessionStorage只能存储字符串类型,对于复杂的对象可以使用ECMAScript提供的JSON对象的stringify和parse来处理
-
获取方式:localStorage:window.localStorage;;sessionStorage:window.sessionStorage;。
-
应用场景:localStoragese:常用于长期登录(+判断用户是否已登录),适合长期保存在本地的数据。sessionStorage:敏感账号一次性登录;
WebStorage的优点
-
存储空间更大:cookie为4KB,而WebStorage是5MB;
-
节省网络流量:WebStorage不会传送到服务器,存储在本地的数据可以直接获取,也不会像cookie一样美词请求都会传送到服务器,所以减少了客户端和服务器端的交互,节省了网络流量;
-
对于那种只需要在用户浏览一组页面期间保存而关闭浏览器后就可以丢弃的数据,sessionStorage会非常方便;
-
快速显示:有的数据存储在WebStorage上,再加上浏览器本身的缓存。获取数据时可以从本地获取会比从服务器端获取快得多,所以速度更快;
-
安全性:WebStorage不会随着HTTP header发送到服务器端,所以安全性相对于cookie来说比较高一些,不会担心截获,但是仍然存在伪造问题;
-
WebStorage提供了一些方法,数据操作比cookie方便;
WebStorage的方法
setItem (key, value) —— 保存数据,以键值对的方式储存信息。
getItem (key) —— 获取数据,将键值传入,即可获取到对应的value值。
removeItem (key) —— 删除单个数据,根据键值移除对应的信息。
clear () —— 删除所有的数据
key (index) —— 获取某个索引的key
Token
token是"令牌"的意思,服务端生成一串字符串,作为客户端请求的一段标识。用户登录的时候生成一个token,并将token返回客户端,客户端将收到的token放在cookie里,下次用户向服务端发送请求的时候,服务端只需要对比token。
作用:进行身份验证,避免表单重复提交。
在ajax请求后台时token添加到哪里
在ajax请求的标头中加Token
1 function GetDateForServiceCustomer(userId) {
2 $.ajax({
3 url: 'http://*******/api/orders',
4 data: {
5 currUserId: userId,
6 type: 1
7 },
8 beforeSend: function(request) {
9 request.setRequestHeader("Authorization", token);
10 },
11 dataType: 'JSON',
12 async: false,//请求是否异步,默认为异步
13 type: 'GET',
14 success: function (list) {
15 },
16 error: function () {
17 }
18 });
19 }

参考:在ajax请求后台时在请求标头RequestHeader加token
https://www.cnblogs.com/zfdcp-028/p/6374632.html
协议
HTTPS与HTTP的一些区别
- HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
- HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
- HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
HTTP1.0和HTTP2.0有什么区别
新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
服务端推送(server push),同SPDY一样,HTTP2.0也具有server push功能。
参考:HTTP1.0、HTTP1.1 和 HTTP2.0 的区别
https://www.cnblogs.com/heluan/p/8620312.html
Websocket
WebSocket 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议。
WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在 WebSocket API 中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
在 WebSocket API 中,浏览器和服务器只需要做一个握手的动作,然后,浏览器和服务器之间就形成了一条快速通道。两者之间就直接可以数据互相传送。
现在,很多网站为了实现推送技术,所用的技术都是 Ajax 轮询。轮询是在特定的的时间间隔(如每1秒),由浏览器对服务器发出HTTP请求,然后由服务器返回最新的数据给客户端的浏览器。这种传统的模式带来很明显的缺点,即浏览器需要不断的向服务器发出请求,然而HTTP请求可能包含较长的头部,其中真正有效的数据可能只是很小的一部分,显然这样会浪费很多的带宽等资源。
HTML5 定义的 WebSocket 协议,能更好的节省服务器资源和带宽,并且能够更实时地进行通讯。
WebSocket特点
(1)建立在 TCP 协议之上,服务器端的实现比较容易。
(2)与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
(3)数据格式比较轻量,性能开销小,通信高效。
(4)可以发送文本,也可以发送二进制数据。
(5)没有同源限制,客户端可以与任意服务器通信。
(6)协议标识符是ws(如果加密,则为wss),服务器网址就是 URL。
scoket套接字编程
网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket。
如果将http比作轿车的话,那么socket就相当于发动机。
####websocket跟 socket 的区别
软件通信有七层结构,下三层结构偏向与数据通信,上三层更偏向于数据处理,中间的传输层则是连接上三层与下三层之间的桥梁,每一层都做不同的工作,上层协议依赖与下层协议。基于这个通信结构的概念。
Socket 其实并不是一个协议,是应用层与 TCP/IP 协议族通信的中间软件抽象层,它是一组接口。当两台主机通信时,让 Socket 去组织数据,以符合指定的协议。TCP 连接则更依靠于底层的 IP 协议,IP 协议的连接则依赖于链路层等更低层次。
WebSocket 则是一个典型的应用层协议。
总的来说:Socket 是传输控制层协议,WebSocket 是应用层协议。
webScoket如何兼容低浏览器
- Adobe Flash Socket
- ActiveX HTMLFile (IE)
- 基于 multipart 编码发送 XHR
- 基于长轮询的 XHR
参考:WebSocket解释及如何兼容低版本浏览器
https://www.cnblogs.com/pengc/p/8718380.html
模块化开发
模块、函数、组件分别是什么?
模块:在webpack中,通过import引入的文件叫做模块。(js/css/png)
函数:是一些功能的合集。
组件:指的是页面的某一部分。
类是什么?类被编译成什么?
类:
class Banner extends React.Component{ //es6写法
}
ES5:通过模块定义类 ES6中定义的类也被编译成这样
function Banner(){ //构造函数
}
组件化与模块化的区别,或者说怎么实现组件化开发,模块化开发
组件化:针对的是页面中的整个完整的功能模块,划分成浏览器可以识别的每个模块,例如头部Header、底部Footer、Banner。优点:代码复用、便于维护。
模块化:就是系统功能分离或独立的功能部分的方法,一般指的是单一的某个东西,例如:js、css
模块化开发的规范
(1)commonJS:自上而下同步进行 会阻塞 用在服务端
使用模块:const 变量名 = require(“包名字”)
声明模块:module.exports = {
对外的名字:函数
}
(2)AMD:异步加载文件 不会阻塞 用在浏览器端
define方法用于定义模块,RequireJS要求每个模块放在一个单独的文件里。
使用模块:require(“模块名”,function(模块对象)){
return 模块对象.函数();//回调函数
}
(3)CMD规范 中国人发明的,ECMA6来了就废弃了。
amd和cmd的区别
amd是require.js上的一个规范,cmd是sea.js的一个规范。
其实CMD与AMD规范并没什么本质的区别,区别在于他们对依赖模块的执行时机处理不同。虽然两者都是异步加载模块,但是AMD依赖前置,js可以方便知道依赖模块是谁,要依赖什么js那就先加载进来,至于你要依赖这些js来干吗得先等着,等我加载完了资源再商量;而CMD就近依赖,需要使用这个依赖模块时,我再加载进来用。
这就好比什么呢?就好像我今晚要看5集三国演义。AMD是先打开五个窗口,分别是1~5集,都缓冲着先,反正等下每集我都要看的;CMD则是先打开第一集的窗口,等到我第一集看完了,想看第二集了,就再跳转到第二集。
现在使用频率最高的,也是大家公认的好的模块化规范,是CommonJS。 后端(node.js)
require.js
实现了AMD规范的JavaScript工具库
RequireJS的基本思想是,通过define方法,将代码定义为模块;通过require方法,实现代码的模块加载。
require.js的诞生,就是为了解决这两个问题:
(1)实现了js文件的异步加载,避免网页失去响应
(2)管理模块之间的依赖性,便于代码的编写和维护
common.js
CommonJS就很简单了,一个js文件要输出去,只需使用module.export={xxx:你要输出的内容},而在另外一个js中,你要引用什么,就通过var xxxx=require(“xxxx”)引用进来就行了,这玩意并不是异步加载模块,而是同步一次性加载出来。
common.js与require.js与sea.js的区别:


####配置模块化开发
<1>在头部引入
<script scr = "js/require.js" defer async = "true" data-main = "js/main"></script>
main.js管理当前页面的js文件,每一个页面都有自己的不同名字的main.js文件.
路径以dist文件为主
在外部修改文件,不允许修改dist中的文件,gulp会自动同步修改.
<2>在main中通过require.config配置当前页面需要的模块路径
配置模块的依赖路径:
shim:{
//由于jquery-cookie是基于jquery库封装的,所以要先引入jquery再引入jquery-cookie
"jquery-cookie":['jquery'],
//声明一下,不是AMD规范的模块
"parabola":{
exports:"_"
}
}
<3>编写CSS样式/JS代码
编写JS代码:
-
先封装成函数
-
再通过对象的形式对外暴露
define(["jquery"],function($){
function slide(){
$(function(){
function show(){
console.log("hello world");
}
return{
slide:slide,
show:show
}
})
<4>在main.js中加载
//配置当前整个项目所有模块的路径
require.config({
paths:{
"slide":"slide"
},
require(["slide"],function(slide){
slide.show();
slide.slide();
})
前端构建集成工具(打包)
什么是前端集成解决方案?
FIS(Front-end Integrated Solution)是专为解决前端开发中自动化工具、性能优化、模块化框架、开发规范、代码部署、开发流程等问题的工具框架。
前端集成解决方案解决了前端哪些问题?
- 开发团队代码风格不统一,如何强制开发规范。
- 前期开发的组件库如何维护和使用
- 如何模块化前端项目
- 服务器部署前必须压缩,检查流程如何简化,流程如何完善。
你使用过哪些前端构建集成?你用过什么打包工具?
- Gulp
gulp是工具链、构建工具,可以配合各种插件做js压缩,css压缩,less编译,替代手工实现自动化工作
(1)构建工具
(2)自动化
(3)提高效率用
- webpack
webpack是文件打包工具,可以把项目的各种js文、css文件等打包合并成一个或多个文件,主要用于模块化方案,预编译模块的方案
(1)打包工具
(2)模块化识别
(3)编译模块代码方案用
webpack打包
一款模块化打包工具,webpack是基于配置的,通过配置一些选项来让webpack执行打包任务
webpack在打包的时候,依靠依赖关系图,在打包的时候要告知webpack两个概念:入口和出口
**plugins:**在webpack编译用的是loader,但是有一些loader无法完成的任务,交由插件(plugin)来完成,插件的时候需要在配置项中配置plugins选项,值是数组,可以放入多个插件使用,而一般的插件都是一个构造器,我们,我们只需在plugins数组中放入该插件的实例即可。
**loader:**在webpack中专门有一些东西用来编译文件、处理文件,这些东西就叫loader。
webpack都用过哪些loader?
url-loader 可以将css中引入的图片(背景图)、js中生成的img图片处理一下,生成到打包目录里
url-loader/file-loader 将图片转成base64
html-withimg-loader 可以将html中img标签引入的img图片打包到打包目录
css-loader 可以将引入到js中的css代码给抽离出来
style-loader 可以将抽离出来的css代码放入到style标签中
sass-loader/less-loader sass/less预编译
postcss-loader 兼容前缀
babel-loader 将es6转成es5转成大部分浏览器可以识别的语法
vue-loader 把vue组件转换成js模块
为何要转译此模块?
可以动态的渲染一些数据,对三个标签做了优化
<template> 写虚拟dom
<script> 写es6语法
<style> 默认可以用scss语法,提供了作用域
并且开发阶段提供了热加载功能
注意:webpack中loader的使用是从后往前的
webpack都用过哪些plugins?
-
html-webpack-plugin:这个插件可以选择是否依据模板来生成一个打包好的html文件,在里面可以配置、title、template、filename、minify等选项。
-
optimize-css-assets-webpack-plugin:压缩css插件
-
extract-text-webpack-plugin:样式合并
-
webpack.optimize.UglifyJsPlugin:js合并
webpack入口属性
-
entry 入口文件
-
output出口文件
Gulp打包
gulp:基于流的前端自动化构建工具,基于流的任务式工具.pipe()
gulp的特点:自动化 基于流 插件很多
Gulp 的特点:
* 自动化 - Gulp 为你的工作流而服务,自动运行那些费事费力任务。
* 平台透明 - Gulp 被集成到各种 IDE 中,并且除了 NodeJS 之外,其他如 PHP、.NET、Java 平台都可以使用 Gulp。
* 强大生态系统 - 你可以使用 npm 上 2000+ 的插件来构造你的工作流。
* 简单 - Gulp 只提供几个 API,这可以很快地学习和上手。
Gulp 原生API
在进阶Gulp时,必须熟悉API中的四个方法的使用,在这里简单概括一下,更多信息查阅API。
-
gulp.src(globs[, options])
返回符合匹配规则的虚拟文件对象流(Vinyl files)。
-
gulp.dest(path[, options])
用来指定要生成的文件的目录,目录路径为path。
-
gulp.task(name[, deps], fn)
定义一个流任务,任务名为name。
-
gulp.watch(glob[, opts], tasks)
监视文件的变化,执行操作。
Gulp插件
gulp-scss 编译css文件(注意:windows下使用 gulp-sass)
gulp-connect 来启动一个服务器
gulp-concat 合并js文件
gulp-uglify js文件压缩
gulp-rename重命名
gulp-minify-css 压缩css
gulp-babel 将es6代码转成es5
webpack和gulp有什么区别
-
gulp是基于流的构建工具:all in one的打包模式,输出一个js文件和一个css文件,优点是减少http请求,万金油方案。gulp强调的是前端开发的工作流程,我们可以通过配置一系列的task,定义task处理的事务(例如文件压缩合并、雪碧图、启动server、版本控制等),然后定义执行顺序,来让gulp执行这些task,从而构建项目的整个前端开发流程。
PS:简单说就一个Task Runner。
-
webpack是模块化管理工具:all in js,使用webpack可以对模块进行压缩、预处理、打包、按需加载等。webpack是一个前端模块化方案,更侧重模块打包,我们可以把开发中的所有资源(图片、js文件、css文件等)都看成模块,通过loader(加载器)和plugins(插件)对资源进行处理,打包成符合生产环境部署的前端资源。
PS:webpack is a module bundle
虽然都是前端自动化构建工具,但看他们的定位就知道不是对等的。
gulp严格上讲,模块化不是他强调的东西,他旨在规范前端开发流程。
webpack更是明显强调模块化开发,而那些文件压缩合并、预处理等功能,不过是他附带的功能。
webpack和gulp有什么关系
Gulp和webpack在定义和用法上来说都不冲突,可以结合来使用。
gulp应该与grunt比较,而webpack应该与browserify(网上太多资料就这么说,这么说是没有错,不过单单这样一句话并不能让人清晰明了)。
gulp与webpack上是互补的,还是可替换的,取决于你项目的需求。如果只是个vue或react的单页应用,webpack也就够用;如果webpack某些功能使用起来麻烦甚至没有(雪碧图就没有),那就可以结合gulp一起用。
Gulp应该和Grunt比较
Gulp / Grunt 是一种工具,能够优化前端工作流程。比如自动刷新页面、combo、压缩css、js、编译less等等。简单来说,就是使用Gulp/Grunt,然后配置你需要的插件,就可以把以前需要手工做的事情让它帮你做了。
devDependencies和dependencies的区别
区别是:
dependencies 程序正常运行需要的包。
devDependencies 是开发需要的包,比如 一些单元测试的包之类的。
一个node package有两种依赖,一种是dependencies一种是devDependencies,
其中前者依赖的项该是正常运行该包时所需要的依赖项,
而后者则是开发的时候需要的依赖项,像一些进行单元测试之类的包。
如果将包下载下来在包的根目录里运行npm install默认会安装两种依赖,如果只是单纯的使用这个包而不需要进行一些改动测试之类的,可以使用npm install --production,只安装dependencies而不安装devDependencies。
如果是通过以下命令进行安装npm install packagename那么只会安装。dependencies,如果想要安装devDependencies,需要输入。npm install packagename --dev。
参考文章:
gulp与webpack的区别
https://www.cnblogs.com/lovesong/p/6413546.html
前端集成解决方案(webpack、gulp)
https://blog.csdn.net/qishuixian/article/details/79453343
CSS预处理器
什么是CSS预处理器?
CSS 预处理器定义了一种新的语言,其基本思想是,用一种专门的编程语言,为 CSS 增加了一些编程的特性,将 CSS 作为目标生成文件,然后开发者就只要使用这种语言进行编码工作。
通俗的说,“CSS 预处理器用一种专门的编程语言,进行 Web 页面样式设计,然后再编译成正常的 CSS 文件,以供项目使用。CSS 预处理器为 CSS 增加一些编程的特性,无需考虑浏览器的兼容性问题”,例如你可以在 CSS 中使用变量、简单的逻辑程序、函数(如右侧代码编辑器中就使用了变量$color)等等在编程语言中的一些基本特性,可以让你的 CSS 更加简洁、适应性更强、可读性更佳,更易于代码的维护等诸多好处。
都有哪些常用的CSS预处理器?
SCSS、LESS、Stylus
####Sass预编译的特性
-
它使用自己语法并编译为可读的CSS
-
可以在更少的时间内轻松的编写CSS代码
-
是一个开源的预处理器,被解析为CSS
-
可以兼容所有的CSS版本
####为什么要用sass?
-
它是预处理语言,它为CSS提供缩进语法(它自己的语法)
-
它允许更有效的编写代码和易于维护
-
它使用可重复使用的方法,逻辑语句和一些内置的函数
-
它提供了比平面CSS好的结构格式和文档样式
####Sass和Scss有什么区别?
Sass 和 SCSS 其实是同一种东西,我们平时都称之为 Sass,两者之间不同之处有以下两点:
文件扩展名不同,Sass 是以“.sass后缀为扩展名**,而 SCSS 是以“**.scss”后缀为扩展名;
语法书写方式不同,Sass 是以严格的缩进式语法规则来书写,不带大括号({})和分号(,而 SCSS 的语法书写和我们的 CSS 语法书写方式非常类似。
####Sass语法
(1)声明变量
普通变量:$美元符号+变量名称:变量值,定义之后可以在全局范围内使用
默认变量:sass 的默认变量仅需要在值后面加上*!default 即可。sass 的默认变量一般是用来设置默认值,然后根据需求来覆盖的,覆盖的方式也很简单,只需要重新声明下变量即可
特殊变量:一般情况下,我们定义的变量都是属性值,可以直接使用,但是如果变量作为属性或者其他的特殊情况下,必须使用#{$variable}的形式进行调用。
#{$variable} 就是取值的一种特殊形式,符合特殊用法。
全局变量:全局变量——在变量的后面加上**[!global]**即可声明全局变量。
(2)sass嵌套-选择器嵌套
SASS 中的嵌套主要说的是选择器嵌套和属性嵌套两种方式,正常项目中通常使用的都是选择器嵌套方案
【注】在嵌套的过程中,如果需要用到父元素,在 SASS 中通过&符号引用父属性
(3)sass嵌套-属性嵌套
嵌套属性——不常用
所谓属性嵌套,是指某些属性拥有同样的单词开头,如:border-left,border-color
都是以 border 开头的,所以就出现了属性嵌套语法
(4)sass混合-Mixin
sass 中可以通过@mixin 声明混合,可以传递参数,参数名称以$开始,多个参数之间使用
逗号分隔,@mixin 的混合代码块由**@include** 来调用
混合能使我们重用一整段sass代码,同时也可以给其传递参数。
定义一个混合,需用到@mixin关键字,后面跟自己定义的名字,若需要传参,则在名字之后加一对单括号(),同时在里面定义参数变量。通过调用@include关键字,来调用这段混合。
(5)sass继承拓展-@extend
在 SASS 中,通过继承/扩展来减少重复代码,可以让一个选择器去继承另一个选择中所有
的样式。
继承某个样式的同时,也会继承样式的扩展。
(6)Partitials和@import
Partials 是用来定义公共样式或者组件的样式的,专门用于被其他的 scss 文件 import进行使用的,在 SCSS 文件中引入指令@import 在引入 Partials 文件时,不需要添加下划线。详细参考案例代码。
(7)sass注释
SASS 中提供了三种注释
多行注释 在编译输出的 css 文件中会保留,压缩输出格式中不会保留 --style compressed
/*
* 多行注释
*/
单行注释 在输出 css 文件时不保留
// 单行注释
强制注释 在多行注释的开头,添加感叹号!表示强制保留
/*!
* 强制注释
*/
混合样式,怎么调用,调用需不需要携带参数
无参数混合



版本控制工具
SVN优缺点(集中式版本管理控制工具)
优点:
1、 管理方便,逻辑明确,符合一般人思维习惯。
2、 易于管理,集中式服务器更能保证安全性。
3、 代码一致性非常高。
4、 适合开发人数不多的项目开发。
缺点:
1、 服务器压力太大,数据库容量暴增。
2、 如果不能连接到服务器上,基本上不可以工作,看上面第二步,如果服务器不能连接上,就不能提交,还原,对比等等。
3、 不适合开源开发(开发人数非常非常多,但是Google app engine就是用svn的)。但是一般集中式管理的有非常明确的权限管理机制(例如分支访问限制),可以实现分层管理,从而很好的解决开发人数众多的问题。
Git优缺点(分布式版本管理控制工具)
优点:
1、适合分布式开发,强调个体。
2、公共服务器压力和数据量都不会太大。
3、速度快、灵活。
4、任意两个开发者之间可以很容易的解决冲突。
5、可以离线工作。
缺点:
1、学习周期相对而言比较长。
2、不符合常规思维。
3、代码保密性差,一旦开发者把整个库克隆下来就可以完全公开所有代码和版本信息。
GIT常用命令
git add * /文件名 将想要快照的内容写入缓存区
git commit -m “当前提交的日志”
git push -u origin master 提交代码
git status 查看当前工作区提交状态
git diff 比对 暂存区和工作区版本的区别
git checkout 切换分支命令
git reset --hard 版本号 恢复到指定的版本
GIT解决冲突
Git在push时如果版本比服务器上的旧,会提示先进行pull。问题是pull时如果服务器上的版本与你本地的版本在源文件修改上有冲突,那么在解决冲突前push都会失败。用git status可以查看冲突文件。
接下来用git diff指令查看具体哪里起冲突
这里还有一些其他指令,在冲突规模比较大的时候可以很方便的确认哪里不对。
git diff --ours:看本体分支对源文件的改动
git diff --theirs:看服务器分支对源文件的改动
git diff --base:看双方对源文件的改动,base和不加base的区别就是base选项会现实双方改动中即使不冲突的部分,默认diff则只会显示冲突部分。
参考:
Git 冲突的解决方法
https://www.jianshu.com/p/9382a0e3402a
git冲突解决的方法
https://www.cnblogs.com/nicknailo/p/9044238.html
GIT和SVN的区别
最核心的区别Git是分布式的,而Svn不是分布的
Git把内容按元数据方式存储,而SVN是按文件
Git的内容的完整性要优于SVN: GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
SVN的特点是简单,只是需要一个放代码的地方时用是OK的。
Git的特点版本控制可以不依赖网络做任何事情,对分支和合并有更好的支持(当然这是开发者最关心的地方),不过想各位能更好使用它,需要花点时间尝试下
SVN和Git对比结果
-
git是分布式的scm,svn是集中式的。(最核心)
-
git是每个历史版本都存储完整的文件,便于恢复,svn是存储差异文件,历史版本不可恢复。(核心)
-
git可离线完成大部分操作,svn则不能。
-
git有着更优雅的分支和合并实现。
-
git有着更强的撤销修改和修改历史版本的能力
-
git速度更快,效率更高。
基于以上区别,git有了很明显的优势,特别在于它具有的本地仓库。
JQuery
####JQuery中获取网页元素的方法
//$的数据类型是一个函数
//alert(typeof $); //function
//$("#div1").css("background-color","red"); //id是div1
//$(".box").css("background-color","blue"); //classname是box
//$("ul .box").css("background-color","blue");//ul下的classname为box
//$("div").css("background-color","green");//div标签
//$("[name=hello]").css("background-color","orange");//name为hello
//$("div[id=div1]").css("background-color","orange");
####JQuery中的工具方法
• type() 输出当前常量/变量的数据类型
• trim() 删除字符串的首尾空格
• inArray() 查找某一个元素,在数组中的下标
• proxy() 功能类似bind,预设this
• noConflict() 给$起一个别名
• parseJSON() 功能类似JSON.parse()
• $.makeArray() 将伪数组转成数组。
JQuery插件方法
$.extend() 拓展工具方法
$.fn.extend() 拓展JQ的方法
设计思想:高内聚低耦合
谈一下Jquery中的bind、live、delegate、on的区别?
on()方法-1.9版本整合了之前的三种方式的新事件绑定机制
.on( events [, selector ] [, data ], handler(eventObject) )
- 使用.bind()方法是很浪费资源的,因为它要匹配选择器中的每一项并且挨个设置相同的事件处理程序
- 建议停止使用.live()方法,因为它已经被弃用了,由于他有很多的问题
- .delegate()方法“很划算”用来处理性能和响应动态添加元素的时候
- 新的.on()方法主要是可以实现.bind() .live() 甚至 .delegate()的功能
- 建议使用.on()方法,如果你的项目使用了1.7+的jQuery的话
参考:jQuery方法区别:click() bind() live() delegate()区别
https://www.cnblogs.com/zagelover/articles/2840762.html
关于jquery的事件委托-bind,live,delegate,on的区别
https://blog.csdn.net/qq_42164670/article/details/83450066
拖拽的三剑客
mousedown:记录被拖拽物体和鼠标按下位置相对距离
mousemove:让拖拽物体跟随鼠标去走,保持按下相对距离
mouseup:结束拖拽
Window.onload与$(document).ready(function(){})的区别是什么?
Window.onload:页面中只会出现一次,页面中所有元素都必须加载完毕才会去执行 。 $(document).ready()是JQ中的,可以执行多次 并且可以简写为:
$(function(){}) ,不需要等页面中所有元素加载,只需要dom挂载进来就可以执行回调函数。
1、执行时间上的区别:window.onload必须等到页面内(包括图片的)所有元素加载到浏览器中后才能执行。而$(document).ready(function(){})是DOM结构加载完毕后就会执行。
2、编写个数不同:window.onload不能同时写多个,如果有多个window.onload,则只有最后一个会执行,它会把前面的都覆盖掉。$(document).ready(function(){})则不同,它可以编写多个,并且每一个都会执行。
3、简写方法:window.onload没有简写的方法,$(document).ready(function(){})可以简写为$(function(){})。
另外:由于在$(document).ready()方法内注册的事件,只要DOM就绪就会被执行,因此可能此时元素的关联文件未下载完,例如与图片有关的HTML下载完毕,并且已经解析为DOM树了,但很有可能图片还未加载完毕,所以例如图片的高度和宽度这样的属性此时不一定有效。
要解决这个问题,可以使用JQuery中另一个关于页面加载的方法---load()方法。load()方法会在元素的onload事件中绑定一个处理函数。如果处理函数绑定在元素上,则会在元素的内容加载完毕后触发。如:$(window).load(function(){})=====window.onload = function(){}
Jquery中如何将数组转化为json字符串,然后再转化回来?
var arr = [{usernname:"张三",age:10}]
console.log($.parseJSON(JSON.stringify(arr)));
正则表达式
电话号码
function checkPhone(){
var phone = document.getElementById('phone').value;
if(!(/^1(3|4|5|6|7|8|9)\d{9}$/.test(phone))){
alert("手机号码有误,请重填");
return false;
}
}
邮箱号码
^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
Vue—渐进式 JavaScript 框架
Vue相关概念
Vue的诞生
Vue是一个前端js框架,由尤雨溪开发,是个人项目,目前由饿了么ued团队进行维护。Vue近几年来特别的受关注,三年前的时候angularJS霸占前端JS框架市场很长时间,接着react框架横空出世,因为它有一个特性是虚拟DOM,从性能上碾轧angularJS,这个时候,vue1.0悄悄的问世了,它的优雅,轻便也吸引了一部分用户,开始收到关注,16年中旬,VUE2.0问世,这个时候vue不管从性能上,还是从成本上都隐隐超过了react,火的一塌糊涂,这个时候,angular开发团队也开发了angular2.0版本,并且更名为angular,吸收了react、vue的优点,加上angular本身的特点,也吸引到很多用户,目前已经迭代到5.0了。
注意下Vue的诞生时间,面试官如果问你是从什么时候开始接触并且使用Vue的,你如果回答用了5、6年了那场面就十分尴尬了。
Vue渐进式框架的理解?
在声明式渲染(视图模板引擎)的基础上,我们可以通过添加组件系统(components)、客户端路由(vue-router)、大规模状态管理(vuex)来构建一个完整的框架。更重要的是,这些功能相互独立,你可以在核心功能的基础上任意选用其他的部件,不一定要全部整合在一起。可以看到,所说的“渐进式”,其实就是Vue的使用方式,同时也体现了Vue的设计的理念。
拓展:Vue2.0 中,“渐进式框架”和“自底向上增量开发的设计”这两个概念是什么?
https://www.zhihu.com/question/51907207
虚拟DOM
什么是虚拟DOM?
我们知道操作DOM的代价是昂贵的,所以vue2.0采用了虚拟DOM来代替对真实DOM的操作,最后通过某种机制来完成对真实DOM的更新,渲染视图。
所谓的虚拟DOM,其实就是用JS来模拟DOM结构,把DOM的变化操作放在JS层来做,尽量减少对DOM的操作 (个人认为主要是因为操作JS比操作DOM快了不知道多少倍,JS运行效率高)。然后对比前后两次的虚拟DOM的变化,只重新渲染变化了的部分,而没有变化的部分则不会重新渲染。
必须要注意一点的是:JS模拟的DOM结构并没有模拟所有DOM节点上的属性、方法(因为DOM节点本身的属性非常多,这也是DOM操作耗性能的一个点),而是只模拟了一部分和数据操作相关的属性和方法。
Virual DOM是用JS对象记录一个dom节点的副本,当dom发生更改时候,先用虚拟dom进行diff,算出最小差异,然后再修改真实dom。
当用传统的方式操作DOM的时候,浏览器会从构建DOM树开始从头到尾执行一遍流程,效率很低。而虚拟DOM是用javascript对象表示的,而操作javascript是很简便高效的。虚拟DOM和真正的DOM有一层映射关系,很多需要操作DOM的地方都会去操作虚拟DOM,最后统一一次更新DOM,因而可以提高性能。
虚拟DOM的缺点
- 代码更多,体积更大
- 内存占用增大
- 小量的单一的dom修改使用虚拟dom成本反而更高,不如直接修改真实dom快
VUE中虚拟dom操作流程
-
在内存中构建虚拟dom树
-
将内存中虚拟dom树渲染成真实dom结构
-
数据改变的时候,将之前的虚拟dom树结合新的数据生成新的虚拟dom树
-
将此次生成好的虚拟dom树和上一次的虚拟dom树进行一次比对(diff算法进行比对)
-
会将对比出来的差异进行重新渲染
参考:vue2.0的虚拟DOM渲染思路分析
https://www.jb51.net/article/145319.htm
v-for循环渲染为什么要设置key值?虚拟DOM与key值的关系?
(1)跟diff算法有关:如果在两个元素之间插入新元素,如果没有key的话,就需要把原位置的元素卸载了,把新元素插进来,然后依次卸载,会打乱后续元素的排列规则,如果有key值,只需要插入到对应位置即可,不会改变其他元素的走向。
(2)为了减免一些出错问题:例如在数组中,本来第一个是选中的,这时候我们再去添加新元素,如果没有key的话,那么新添加进来的元素就会被选中,加上key就是为了避免出现这样的问题。
参考:Vue 虚拟DOM与key属性
https://blog.csdn.net/weixin_42695446/article/details/84680213
虚拟DOM的Diff算法
虚拟DOM中,在DOM的状态发生变化时,虚拟DOM会进行Diff运算,来更新只需要被替换的DOM,而不是全部重绘。
在Diff算法中,只平层的比较前后两棵DOM树的节点,没有进行深度的遍历。
computed计算属性跟watch监听的区别
computed计算属性是根据现有数据生成一个新的数据,并且两者会产生关联,建立永久缓存。当无关数据变化的时候,他不会重新计算,而是直接从缓存里面取之前的值。
watch监听依赖是单个的,他每次监听只能监听一个变量的改变。
参考:浅谈VUE虚拟dom
https://blog.csdn.net/mrliber/article/details/79036828
设计模式
VUE的设计模式MVVM
vue中采用了mvvm的设计模式,是从mvc/mvp演变过来的,mvvm主要解决了mvc反馈不及时的问题,或者实现了自动同步的功能。
也就是说model层改变的时候,我们不需要手动取更改dom。而vm帮助我们实现了这个效果,改变属性后该属性对应view会自动更新,view与model之间没有必然的联系,靠vm将两者进行关联。
MVC设计模式(单向通信)
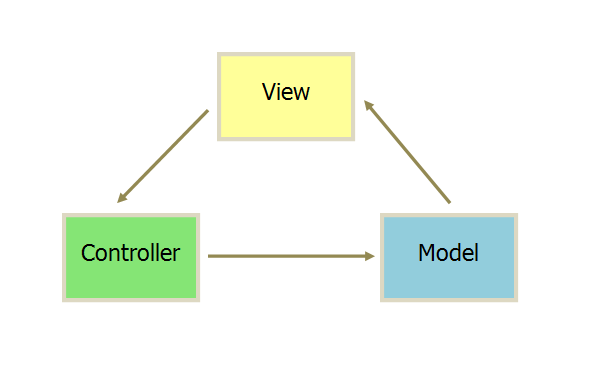
- 视图(View):用户界面。
- 控制器(Controller):业务逻辑
- 模型(Model):数据保存
- View 传送指令到 Controller
- Controller 完成业务逻辑后,要求 Model 改变状态
- Model 将新的数据发送到 View,用户得到反馈
MVP设计模式
MVP 模式将 Controller 改名为 Presenter,同时改变了通信方向。
- 各部分之间的通信,都是双向的。
- View 与 Model 不发生联系,都通过 Presenter 传递。
- View 非常薄,不部署任何业务逻辑,称为"被动视图"(Passive View),即没有任何主动性,而 Presenter非常厚,所有逻辑都部署在那里。
MVVM设计模式
MVVM 模式将 Presenter 改名为 ViewModel,基本上与 MVP 模式完全一致。
唯一的区别是,它采用双向绑定(data-binding):View的变动,自动反映在 ViewModel,反之亦然。Angular 和 Ember 都采用这种模式。
参考:MVC,MVP 和 MVVM 的图示
http://www.ruanyifeng.com/blog/2015/02/mvcmvp_mvvm.html
MVC、MVP、MVVM三种区别及适用场合
https://blog.csdn.net/victoryzn/article/details/78392128
MVVM解决了什么问题
mvvm就是为了解决mvc反馈不及时的问题
MVVM与MVC的区别
MVVM实现了View和Model的自动同步,也就是当Model属性改变时,我们不用再自己手动操作Dom元素,来改变View的显示,而是改变属性后该属性对应View层显示会自动改变(双向数据绑定原理)。
为什么model层数据更改的时候,vm就可以知道数据改变了呢?(vue的mvm框架的双向绑定原理是什么)
双向数据绑定:
当视图改变更新模型层
当模型层改变更新视图层
在Vue中,使用了双向绑定技术,就是View的变化能实时让Model发生变化,而Model的变化也能实时更新到View。Vue采用数据劫持&发布-订阅模式的方式,vue在创建vm的时候,会将数据配置在实例当中,然后通过Object.defineProperty对数据进行操作,为数据动态添加了getter与setter方法,当获取数据的时候会触发对应的getter方法,当设置数据的时候会触发对应的setter方法,从而进一步触发vm的watcher方法,然后数据更改,vm则会进一步触发视图更新操作。
参考:剖析Vue原理&实现双向绑定MVVM
https://segmentfault.com/a/1190000006599500
双向数据绑定的实现
要实现Vue中的双向数据绑定,大致可以划分三个模块:Observer、Compile、Watcher
- Observer 数据监听器
负责对数据对象的所有属性进行监听(数据劫持),监听到数据发生变化后通知订阅者。 - Compiler 指令解析器
扫描模板,并对指令进行 解析,然后绑定指定事件。 - Watcher 订阅者
关联Observer和Compile,能够订阅并收到属性变动的通知,执行指令绑定的相应操作,更新视图。
let data = {
message:"hello world!"
}
let vm = new Vue({
el:"#app",
data
});
// console.log(data);
// console.log(vm.$data);
//Object.defineProperty es5提供的 ie8不支持 原理
let _data={
}
let middle = 123;
Object.defineProperty(_data,"msg",{ //给某个对象赋了一个属性 属性中提供了get方法和set方法
get(){
return middle; 调用_data.msg相当于调用get方法 直接返回123
},
set(val){
// _data.msg = val;
middle = val; 设置完之后middle=4
}
});
console.log(_data.msg);//获取属性的时候,就会执行getter方法
_data.msg = 4;//设置属性的时候,就会执行setter方法 相当于给这个对象设置msg属性为4
console.log(_data.msg);
this.$nextTick()
用swiper时,有没有出现图片划不动的情况,原因是什么?你怎么解决的?
【VUE】swiper实例化后会出现划不动现象,产生的原因是本来这个地方是没有swiper-slide这个数据的,后续我们发送了ajax请求他才会动态生成swiperslide,banners数据立马改变了,它内部会生成新的虚拟dom和上一次虚拟dom结构作对比,然后产生新的真实dom,这个过程需要时间,但是我们立马实例化了,所以等到真实dom渲染完成后实例化早就结束了。解决方法就是,我们必须要等到因为数据改变了引发新的真实dom渲染完成后才会执行的操作,就可以避免这样的问题。
所以我们需要把实例化的过程写在this.$nextTick的回调函数中,在这个函数里面进行的操作就是等到数据更新而引发的页面当中新的虚拟dom所渲染成的真实dom真正渲染出来之后才执行,简单来说就是等到页面全部渲染完成后。
created(){
this.$http.get("/api/v2/movie/in_theaters",{
params:{
count:6
}
}).then(res=>{
console.log(res)
this.banners = res.data.subjects
//问题:异步请求 数据改变了 产生新的虚拟dom 需要与上一次虚拟dom结构对比 diff算法更新差异对比需要一定时间 数据渲染完成后直接实例化 就可能导致虚拟dom对比完成之后生成新的虚拟dom 这个实例化的代码早就执行完毕了
this.$nextTick(()=>{//这个方法的作用就是 数据更改引发新的虚拟dom更新完毕 生成真实dom后 才会进入此函数的回调函数中 所以在这个回调函数中就可以拿到因数据改变而更新生成的真实dom
new Swiper(".home-banner",{
loop:true
})
})
})
this.$nextTick() 主要作用是等数据改变引发dom重新渲染完成之后才会执行
可以在实例化配置项中进行如下配置 (自己了解一下,但是面试官一般就想让你说this.$nextTick()这个知识点)
observer:true,
observeParents:true//修改swiper子元素的话,会自动帮助我们初始化swiper
生命周期
【初始化阶段(4个)】
(1)beforeCreate
此钩子函数不能获取到数据,dom元素也没有渲染出来,此钩子函数不会用来做什么事情。
(2)created
此钩子函数,数据已经挂载了,但是dom节点还是没有渲染出来,在这个钩子函数里面,如果同步更改数据的话,不会影响运行中钩子函数的执行。可以用来发送ajax请求,也可以做一些初始化事件的相关操作。
(3)beforeMount
代表dom节点马上要被渲染出来了,但是还没有真正的渲染出来,此钩子函数跟created钩子函数基本一样,也可以做一些初始化数据的配置。
(4)mounted
是生命周期初始化阶段的最后一个钩子函数,数据已经挂载完毕了,真实dom也可以获取到了。
【运行中阶段(2个)】
(5)beforeUpdate
运行中钩子函数beforeUpdate默认是不会执行的,当数据更改的时候,才会执行。数据更新的时候,先调用beforeUpdate,然后数据更新引发视图渲染完成之后,再会执行updated。运行时beforeUpdate这个钩子函数获取的数据还是更新之前的数据(获取的是更新前的dom内容),在这个钩子函数里面,千万不能对数据进行更改,会造成死循环。
(6)updated
这个钩子函数获取的数据是更新后的数据,生成新的虚拟dom,跟上一次的虚拟dom结构进行比较,比较出来差异(diff算法)后再渲染真实dom,当数据引发dom重新渲染的时候,在updated钩子函数里面就可以获取最新的真实dom了。
【销毁阶段(2个)】
(7)beforeDestroy
切换路由的时候,组件就会被销毁了,销毁之前执行beforeDestroy。在这个钩子函数里面,我们可以做一些善后的操作,例如可以清空一下全局的定时器(created钩子函数绑定的初始化阶段的事件)、清除事件绑定。
(8)destoryed
组件销毁后执行destroyed,销毁后组件的双向数据绑定、事件监听watcher相关的都被移除掉了,但是组件的真实dom结构还是存在在页面中的。
官网这张生命周期流程图要熟练掌握,在面试官问到的时候最好能将这张图画出来,针对每个函数的功能做详细解答,整个过程至少保持在3-5分钟。如果面试官很有耐心,还想继续听你说下去,可以拓展keep-alive标签的active和deactive这两个生命周期函数,属于加分项。

###组件
####什么是组件?
WEB中的组件其实就是页面组成的一部分,好比是电脑中的每一个元件(如硬盘、键盘、鼠标),它是一个具有独立的逻辑和功能或界面,同时又能根据规定的接口规则进行相互融合,变成一个完整的应用。
页面就是由一个个类似这样的部分组成的,比如导航、列表、弹窗、下拉菜单。页面只不过是这些组件的容器,组件自由组合形成功能完整的界面,当不需要某个组件,或者想要替换某个组件时,可以随时进行替换和删除,而不影响整个应用的运行。
【注】前端组件化的核心思想就是将一个巨大复杂的东西拆分成粒度合理的小东西。
页面中能被复用的内容都被称之为组件,你所能看到的一些结构,像头部Header、Footer、Banner都可以被封装成一个组件去复用,组件就是集成了html、css、js、image的一个聚合体。
####使用组件的好处?
(1)提高开发效率
(2)方便重复使用
(3)简化调试步骤
(4)提升整个项目的可维护性
(5)便于协同开发
####组件的特性
高内聚,低耦合
为什么要封装组件?
(1)解耦
(2)提升组件复用性
组件封装的案例
<div id="demo">
<v-header></v-header>
</div>
<template id="header">
<div>
{
{msg}}<input/>
</div>
</template>
var Header = {
template:"#header",
data(){
return {
msg:"v-header的msg!!!"
}
}
};
new Vue({
el:"#demo",
components:{
"v-header":Header
}
});
组件中的data是什么类型?为什么是一个函数?
实例中的data是什么类型?
为什么实例中的data是一个对象,组件中的data是一个函数?
为了防止组件与组件之间的数据共享,让作用域独立,data是函数内部返回一个对象,让每个组件或者实例可以维护一份被返回对象的独立的拷贝。组件可以被复用,但是数据不能共享,每个组件管理自己的数据更新,不能影响其他组件的数据。
参考:data必须是一个函数(VUE官网)
https://vue.docschina.org/v2/guide/components.html#data-%E5%BF%85%E9%A1%BB%E6%98%AF%E4%B8%80%E4%B8%AA%E5%87%BD%E6%95%B0
组件的 data 选项必须是一个函数,以便每个实例都可以维护「函数返回的数据对象」的彼此独立的数据副本。
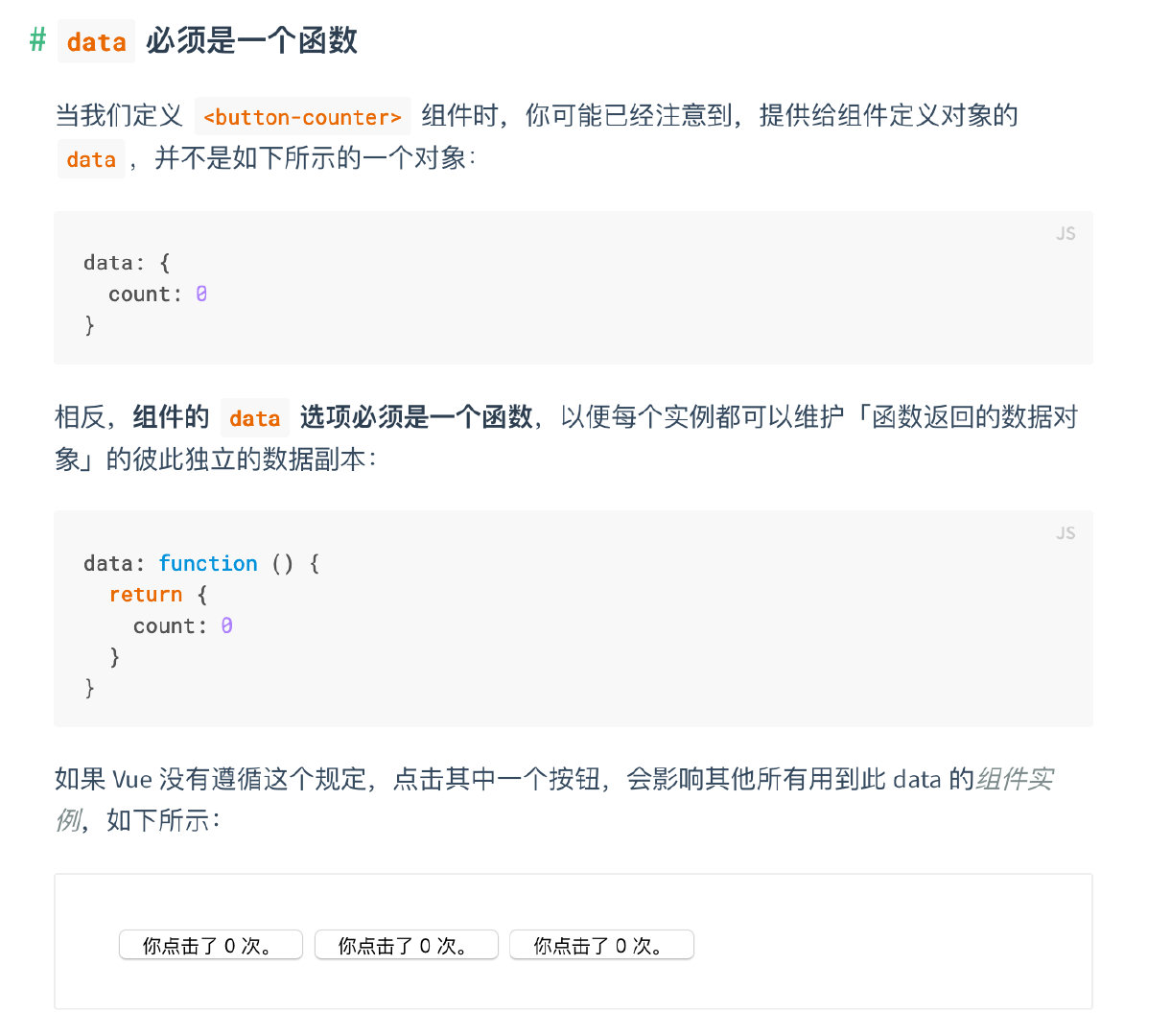
vue组件传值
父子组件通信
1、父子组件通过prop传递数据
父组件可以将一条数据传递给子组件,这条数据可以是动态的,父组件的数据更改的时候,子组件接收的也会变化
子组件被动的接收父组件的数据,子组件不要再更改这条数据了。
组件实例的作用域是孤立的,父组件不能直接使用子组件的数据,子组件也不能直接使用父组件的数据。
父组件在调用子组件的时候给子组件传递数据:
<template id="father">
<div class="father">
<p>我是父组件,这是我的fMsg:{
{fMsg}}</p>
<input type = "text" v-model = "fMsg">
<hr>
<son msg = "你好"></son>
</div>
</template>
父组件给子组件传递数据的时候,子组件需要利用props的属性来确定自己的预期数据,如果儿子没有通过props属性接受传递过来的数据,则数据会以自定义属性的方式,放在儿子最外层的根元素上面。

子组件通过props来接受父组件传递过来的数据,并且通过{ {msg}}使用
components:{
son:{
template:"<div>我是son子组件!这是父组件传递给我的msg:{
{msg}}</div>",
//接收父组件传递来的属性 msg
props:["msg"]
}
}

2、父组件通过v-bind指令传递自身变量给子组件
我们可以用 v-bind 来动态地将 prop 绑定到父组件的数据。每当父组件的数据变化时,该变化也会传导给子组件。
<template id="father">
<div class="father">
<p>我是父组件,这是我的fMsg:{
{fMsg}}</p>
<input type = "text" v-model = "fMsg">
<hr>
<!-- <son msg = "你好"></son> -->
<son :msg = "fMsg"></son>
</div>
</template>
如果如果父组件传递属性给子组件的时候键名有’-’
<son :f-msg = "fMsg"></son>
子组件接收、使用的时候写成小驼峰的模式
components:{
son:{
template:"<div>我是son子组件!这是父组件传递给我的msg:{
{fMsg}}</div>",
//接收父组件传递来的属性 msg
props:["fMsg"]
}
}
3、父子组件依靠应用类型的地址传递共享数据
单向数据流
Prop 是单向绑定的:当父组件的属性变化时,将传递给子组件,但是反过来不会。这是为了防止子组件无意间修改了父组件的状态,来避免应用的数据流变得难以理解。
<template id="father">
<div class="father">
<input type = "text" v-model = "message">
<hr>
<son :message = "message"></son>
</div>
</template>
<template id = "son">
<div>
<p>这是子组件</p>
<input type = "text" v-model = "message"></input>
</div>
</template>
另外,每次父组件更新时,子组件的所有 prop 都会更新为最新值。这意味着你不应该在子组件内部改变 prop。如果你这么做了,Vue 会在控制台给出警告。

所以如果我们想实现父子间的数据共享,依靠的就是应用类型的地址传递,应将message写成对象的形式,传递的时候将对象传递给子组件,子组件引用的时候使用对象的value值。
<template id="father">
<div class="father">
<input type = "text" v-model = "message.value">
<hr>
<!-- 传递的时候将对象传递给子组件 -->
<son :message = "message"></son>
</div>
</template>
<template id = "son">
<div>
<p>这是子组件</p>
<!-- 引用的时候使用对象的value值 -->
<input type = "text" v-model = "message.value"></input>
</div>
</template>
这时候更改父组件的value值,子组件的数据同步更改,子组件修改value值的时候也同步修改了父组件的数据。这是因为不管是子组件还是父组件,我们操作的都是同一个对象,父组件直接把引用类型的地址传递给子组件,子组件没有直接修改对象,只是更改了里面的属性值。
父组件如果将一个引用类型的动态数据传递给子组件的时候,数据会变成双向控制的,子组件改数据的时候父组件也能接收到数据变化,因为子组件改的时候不是在改数据(地址),而是在改数据里的内容,也就是说引用类型数据的地址始终没有变化,不算改父组件数据。
注意:在 JavaScript 中对象和数组是引用类型,指向同一个内存空间,如果 prop 是一个对象或数组,在子组件内部改变它会影响父组件的状态。 message:{val:""}
父 子 间 数 据 共 享 ( 双 向 控 制 ) , 基 本 不 会 使 用 , 违 背 了 单 向 数 据 流 ( 父 = 》 子 ) 父子间数据共享(双向控制),基本不会使用,违背了单向数据流(父=》子) 父子间数据共享(双向控制),基本不会使用,违背了单向数据流(父=》子)
4、viewmodel关系链
在组件间可以用过ref形成ref链,组件还拥有一个关系链($parent),通过这两种链;理论来说,任意的两个组件都可以互相访问,互相进行通信。
$parent:父组件
$children:子组件
$root:根组件

当子组件在set方法中修改父组件传递过来的值时,系统会报错,因为子组件不能修改父组件的数据。
Vue.component("bbb",{
template:"#bbb",
props:["msg"],
computed:{
/* ownMessage(){
return this.msg;
} */
ownMessage:{
get(){
return this.msg;
},
set(val){
this.msg = val //系统报错:子组件不能更改父组件传递的数据
}
}
}
})

所以这时候要使用$parent,让父组件自己更改自己的数据
set(val){
// this.msg = val //系统报错:子组件不能更改父组件传递的数据
// console.log(this)
// 相当于父组件自己更改了msg数据
this.$parent.msg = val;
}
5、父组件通过ref标记获取子组件的数据
父组件在调用子组件的时候使用ref做标记
<template id="aaa">
<div>
<button @click = "get">点击获取bbb数据</button>
<!-- 组件间不仅可以用过$root/$parent/$children来获取对应关系的组件,父组件还可以主动的通过ref为子组件做标记 -->
<bbb ref = "b"></bbb>
</div>
</template>
父组件的this属性上有$refs标记,通过refs标记拿到子组件

// 通过ref标记更改子组件的数据
// this.$refs.b.message = "哈哈"
组件间不仅可以用过$parent/children/root来获取对应关系的组件,父组件还可以主动的通过ref为子组件做标记 也可以给dom做标记,也会形成ref链,也可以交互.
<button ref="btn" @click="get">get</button>
<bbb ref="b></bbb>

注意多个子组件标记的是同一个键名,获取到的应该是一个数组
<bbb ref = "b" v-for = "(item,index) in 3" :key = "index"></bbb>

// 通过下标修改对应的数值
this.$refs.b[0].message = "哈哈"
子父组件通信
1、子组件通过父组件传递的方法来更改父组件的数据
父组件可以将更改自身数据的方法传递给子组件,子组件调用这个方法的时候,就可以给父组件传递数据,父组件被动的接收子组件的数据。
子组件声明一条自身的msg
Vue.component("son",{
template:"#son",
// 子组件接收父组件传递过来的方法
props:["change"],
data(){
return{
msg:"我是子组件"
}
}
})
父组件先声明一条自己的数据
data(){
return{
// 父组件先声明一条自己的数据
parentMsg:""
}
}
再写一个可以更改自身数据的方法
methods:{
// 写一个可以更改自身数据的方法
change(msg){
this.parentMsg = msg
}
}
将写好的change方法传递给子组件
<template id="father">
<div>
<p>这是父组件</p>
<p>子组件传递过来的值是:{
{parentMsg}}</p>
<hr>
<!-- 调用子组件的时候,将更改自身数据的方法传递给子组件 -->
<son :change = "change"></son>
</div>
</template>
子组件通过props接收父组件传递过来的change方法
props:["change"]
给p标签添加点击事件,点击即触发change方法,同时将自身的msg传递给父组件,相当于父组件的change方法被执行。
<template id="son">
<div>
<p>子组件说:{
{msg}}</p>
<p @click = "change(msg)">点击我触发父亲的change方法</p>
</div>
</template>
父组件可以在页面中渲染子组件传递过来的数据
<p>子组件传递过来的值是:{
{parentMsg}}</p>
2、通过自定义事件实现子父通信
每一个组件或者实例都会有自定义事件,和触发事件的能力,父组件给子组件绑定一个自定义事件,这个事件的处理程序却是父组件的一个方法,当子组件触发这个事件的时候,相当于父组件的方法被执行。
父组件想获取子组件的数据时,在调用子组件的时候给子组件绑定一个自定义事件change-event
<template id="father">
<div>
<p>这是父组件</p>
<p>子组件传递过来的值是:{
{parentMsg}}</p>
<hr>
<!-- 给子组件绑定一个自定义事件 -->
<son @change-event = "change"></son>
</div>
</template>
在子组件中定义一个点击事件,点击p标签执行changeWord方法
<p @click = "changeWord">点击我触发父亲的change方法</p>
在方法中编写changeWord方法,通过this.$emit来触发绑定在自己身上的自定义事件,第一个参数为事件名称change-event,第二个参数为触发这个函数的时候给他传递的数值:自身的msg。
methods:{
changeWord(){
//触发自身绑定的change事件
this.$emit("change-event",this.msg)//第一个参数为触发事件的名字,第二个参数为触发这个函数的时候给他传递的数值
}
}
一旦触发绑定在自身上的自定义事件,相当于父组件的change方法被执行。
兄弟组件通信
1、通过viewmodel关系链
定义哥哥组件,给哥哥组件添加一个点击事件,点击触发hitLittle方法
<template id = "big-brother">
<div>
<p>我是哥哥</p>
<button @click = "hitLittle">打弟弟</button>
</div>
</template>
定义弟弟组件,给弟弟组件添加一个p标签,由crying数据控制其显示与隐藏
<template id="little-brother">
<div>
<p>我是弟弟</p>
<p v-if = "crying">呜呜呜</p>
</div>
</template>
在弟弟组件的data中声明crying数据,默认为false
Vue.component("little-brother",{
template:"#little-brother",
data(){
return{
crying:false
}
}
})
在哥哥组件的methods中定义hitLittle方法,通过viewmodel关系链更改弟弟组件中的crying方法
Vue.component("big-brother",{
template:"#big-brother",
methods:{
hitLittle(){
//在兄弟组件之间的通信,可以采用关系链和ref链去使用,解决兄弟之间通信问题。
this.$parent.$children[1].crying = true;//让littel改变自身的crying状态
}
}
})
2、viewmodel关系链+ref链
在弟弟组件中添加ref标记
<little-brother ref = "little"></little-brother>
在哥哥组件的hitLittle方法中通过viewmodel和ref链配合使用更改弟弟组件中的crying数据
hitLittle(){
//在兄弟组件之间的通信,可以采用关系链和ref链去使用,解决兄弟之间通信问题。
// this.$parent.$children[1].crying = true;//让littel改变自身的crying状态
//viewmodel链和ref链配合使用
this.$parent.$refs.little.crying = true;
}
3、eventbus事件总线
创建一个空的实例
var angle = new Vue();
弟弟组件自己定义一个更改自身状态的方法
methods:{
cry(){
this.crying = true
}
}
在mounted生命周期函数中绑定一个自定义事件,第一个参数为自定义事件名,第二个函数为需要处理的函数
mounted(){
// 绑定一个自定义事件,第一个参数为自定义事件名,第二个函数为需要处理的函数
angle.$on("hit-little",this.cry)
}
在哥哥组件中触发自定义事件
hitLittle(){
//触发little-brother组件的hit-little事件
angle.$emit("hit-little")
}
keep-alive缓存
keep-alive在项目中如何应用?
当在组件之间进行切换的时候,你有时会想保持这些组件的状态,以避免反复重渲染导致的性能问题。当从a页面跳转到b页面再跳转回a页面时,可以不用再次进行数据请求,直接从缓存里面获取数据,减少性能消耗。
例如我们来展开说一说这个多标签界面:
你会注意到,如果你选择了一篇文章,切换到 Archive 标签,然后再切换回 Posts,是不会继续展示你之前选择的文章的。这是因为你每次切换新标签的时候,Vue 都创建了一个新的 currentTabComponent 实例。
重新创建动态组件的行为通常是非常有用的,但是在这个案例中,我们更希望那些标签的组件实例能够被在它们第一次被创建的时候缓存下来。为了解决这个问题,我们可以用一个 元素将其动态组件包裹起来。
keep-alive的生命周期函数
当组件在内被切换时,它的actived和deactived这两个生命周期钩子函数将会被对应执行,初始化操作放在actived里面,一旦切换组件,因为组件没有被销毁,所以它不会执行销毁阶段的钩子函数,所以移除操作需要放在deactived里面,在里面进行一些善后操作,这个时候created钩子函数只会执行一次,销毁的钩子函数一直没有执行。
keep-alive的属性
Keep-alive提供了两个属性:允许组件有条件的缓存
include:我只需要缓存哪一些组件
exclude:除了这个组件之外其他组件都会被缓存
原理:
在created的时候,将需要缓存的虚拟dom节点放到cache中,在render的时候根据name再进行取出。
keep-alive只能在组件切换的标签中进行缓存
<keep-alive include="indexCom">
<router-view/>
</keep-alive>
使用传统写法比较麻烦,我们可以在需要被缓存的页面的路由中添加keepAlive:true字段
{
path: '/',
name: 'index',
meta:{
keepAlive:true //该字段表明页面需要缓存
},
component: resolve=>require(["@/page/index"],resolve)
}
在组件切换的时候,检查下原数据上面有没有keepAlive这个属性,如果有的话就keep-alive缓存一下,没有的话就该怎么显示怎么显示。
<keep-alive>
<router-view v-if="$route.meta.keepAlive"></router-view>
</keep-alive>
<router-view v-if="!$route.meta.keepAlive"></router-view>
指令
说一下vue常用的内置指令
1、v-bind:响应并更新DOM特性;例如:v-bind:href v-bind:class v-bind:title v-bind:bb
2、v-on:用于监听DOM事件; 例如:v-on:click v-on:keyup
3、v-model:数据双向绑定;用于表单输入等;例如:
4、v-show:条件渲染指令,为DOM设置css的style属性
5、v-if:条件渲染指令,动态在DOM内添加或删除DOM元素
6、v-else:条件渲染指令,必须跟v-if成对使用
7、v-for:循环指令;例如:
-
8、v-else-if:判断多层条件,必须跟v-if成对使用;
9、v-text:更新元素的textContent;例如: 等同于 { {msg}};
10、v-html:更新元素的innerHTML;
11、v-pre:不需要表达式,跳过这个元素以及子元素的编译过程,以此来加快整个项目的编译速度;例如:{ { this will not be compiled }};
12、v-cloak:不需要表达式,这个指令保持在元素上直到关联实例结束编译;
13、v-once:不需要表达式,只渲染元素或组件一次,随后的渲染,组件/元素以及下面的子元素都当成静态页面不在渲染。
如何注册自定义指令
使用Vue.directive(id,definition)注册全局自定义指令,接收两个参数,指令ID以及定义对象。使用组件的directives选项注册局部自定义指令。
自定义指令的钩子函数
一个指令定义对象可以提供如下几个钩子函数 (均为可选):
bind:只调用一次,指令第一次绑定到元素时调用。在这里可以进行一次性的初始化设置。
inserted:被绑定元素插入父节点时调用 (仅保证父节点存在,但不一定已被插入文档中)。
update:所在组件的 VNode 更新时调用,但是可能发生在其子 VNode 更新之前。指令的值可能发生了改变,也可能没有。但是你可以通过比较更新前后的值来忽略不必要的模板更新 (详细的钩子函数参数见下)。componentUpdated:指令所在组件的 VNode 及其子 VNode 全部更新后调用。
unbind:只调用一次,指令与元素解绑时调用。
拓展:自定义指令(VUE官网)
https://cn.vuejs.org/v2/guide/custom-directive.html#ad
v-model是什么?
v-model是用于表单的据双向绑定的指令
如何自己去实现一个v-model数据绑定?
两个步骤:
-
v-bind 绑定了一个value的属性
-
v-on 把当前元素绑定到了一个事件上
<template> <div class="logs"> logs!!! <p><input type="text" v-model="msg"></p> <p>{ {msg}}</p> <hr> <p><input type="text" :value="msg2" @input="msg2 = $event.target.value"></p> <p>{ {msg2}}</p> </div> </template> <script> export default { name:"logs", data(){ return { msg:"helloworld", msg2:"" } } } </script>
v-if和v-show的区别
v-if 是“真正”的条件渲染,因为它会确保在切换过程中条件块内的事件监听器和子组件适当地被销毁和重建。 v-if 也是惰性的:如果在初始渲染时条件为假,则什么也不做——直到条件第一次变为真时,才会开始渲染条件块。 相比之下,v-show 就简单得多——不管初始条件是什么,元素总是会被渲染,并且只是简单地基于 CSS 进行切换。 一般来说,v-if 有更高的切换开销,而 v-show 有更高的初始渲染开销。因此,如果需要非常频繁地切换,则使用 v-show 较好;如果在运行时条件很少改变,则使用 v-if 较好。
路由守卫
讲一下都有哪些路由守卫?
全局前置守卫:router.beforeEach 在路由切换开始时候调用
全局后置守卫:roter.afterEach 在路由切换离开时候调用
局部路由守卫:beforeEnter 写在路由对象里
组件内的守卫:
beforeRouteEnter 路由进入到这个组件之前调用,不能获取当前组件对象 this
beforeRouteUpdate 在组件被复用时调用
beforeRouteLeave 路由离开这个组件之后调用,能获取当前组件对象 this
路由守卫中的参数都是什么意思
每个钩子方法接收三个参数:
- to: Route: 即将要进入的目标,路由对象
- from: Route: 当前导航正要离开的路由
- next: Function: 一定要调用该方法来 resolve 这个钩子。执行效果依赖 next 方法的调用参数。
- next(): 进行管道中的下一个钩子。如果全部钩子执行完了,则导航的状态就是 confirmed (确认的)。
- next(false): 中断当前的导航。如果浏览器的 URL 改变了(可能是用户手动或者浏览器后退按钮),那么 URL 地址会重置到 from 路由对应的地址。
- next(‘/’) 或者 next({ path: ‘/’ }): 跳转到一个不同的地址。当前的导航被中断,然后进行一个新的导航。
确保要调用 next 方法,否则钩子就不会被 resolved。
具体说一下每个路由守卫的功能
导航守卫(路由钩子/路由守卫/导航守卫/导航钩子/路由生命周期)
正如其名,
vue-router提供的导航守卫主要用来通过跳转或取消的方式守卫导航。有多种机会植入路由导航过程中:全局的,单个路由独享的,,或者组件级的。在某些情况下,当路由跳转前或跳转后、进入、离开某一个路由前、后,需要做某些操作,就可以使用路由钩子来监听路由的变化。
全局守卫
(1)全局前置守卫beforeEach
当一个导航触发时,全局前置守卫按照创建顺序调用。守卫是异步解析执行,此时导航在所有守卫 resolve 完之前一直处于 等待中,所以页面不会加载任何内容。

一定要在路由守卫中调用next()方法来resolve这个钩子
// 全局前置路由 router.beforeEach((to,from,next)=>{ console.log("beforeEach:全局前置守卫") // 一定要调用next()方法来resolve这个钩子 next(); })
(2)全局后置守卫afterEach
也可以注册全局后置钩子,然而和前置守卫不同的是,这些钩子不会接受
next函数也不会改变导航本身:// 全局后置钩子 router.afterEach((to,from)=>{ if (to.path === "/list/audio") { alert("已经进入list列表audio页面") } })
局部守卫
路由独享的守卫
在路由配置上直接定义beforeEnter守卫:
{ path :"/mine",component:()=>import("../views/Mine"),beforeEnter(to,from,next){ console.log("进入到mine页面了") next(); }}
组件内的守卫
最后,你可以在路由组件内直接定义以下路由导航守卫:
-
beforeRouteEnter
在进入该组件之前执行,该路由守卫中获取不到实例this,因为此时组件实例还没被创建。
beforeRouteEnter守卫 不能 访问this,因为守卫在导航确认前被调用,因此即将登场的新组件还没被创建。在Home.vue中添加beforeRouteEnter:
beforeRouteEnter(to,from,next){ console.log("beforeRouteEnter:进入组件之前",this) next() }打印this,显示undefined

不过,你可以通过传一个回调给
next来访问组件实例。在导航被确认的时候执行回调,并且把组件实例作为回调方法的参数。beforeRouteEnter (to, from, next) { next(vm => { // 通过 `vm` 访问组件实例 }) }注意
beforeRouteEnter是支持给next传递回调的唯一守卫。对于beforeRouteUpdate和beforeRouteLeave来说,this已经可用了,所以不支持传递回调,因为没有必要了。 -
beforeRouteLeave
在离开该组件之前执行,该路由守卫中可以访问组件实例"this"。
在Home.vue中添加beforeRouteLeave:
beforeRouteLeave(to,from,next){ console.log("beforeRouteLeave:离开组件之前",this) next() }此时可以打印组件实例"this"

这个离开守卫通常用来禁止用户在还未保存修改前突然离开。该导航可以通过
next(false)来取消。 -
beforeRouteUpdate(2.2 新增)
当一个组件被重复调用的时候执行该守卫
在Deatil.vue中添加beforeRouteUpdate:
beforeRouteUpdate(to,from,next){ console.log("beforeRouteUpdate") next() }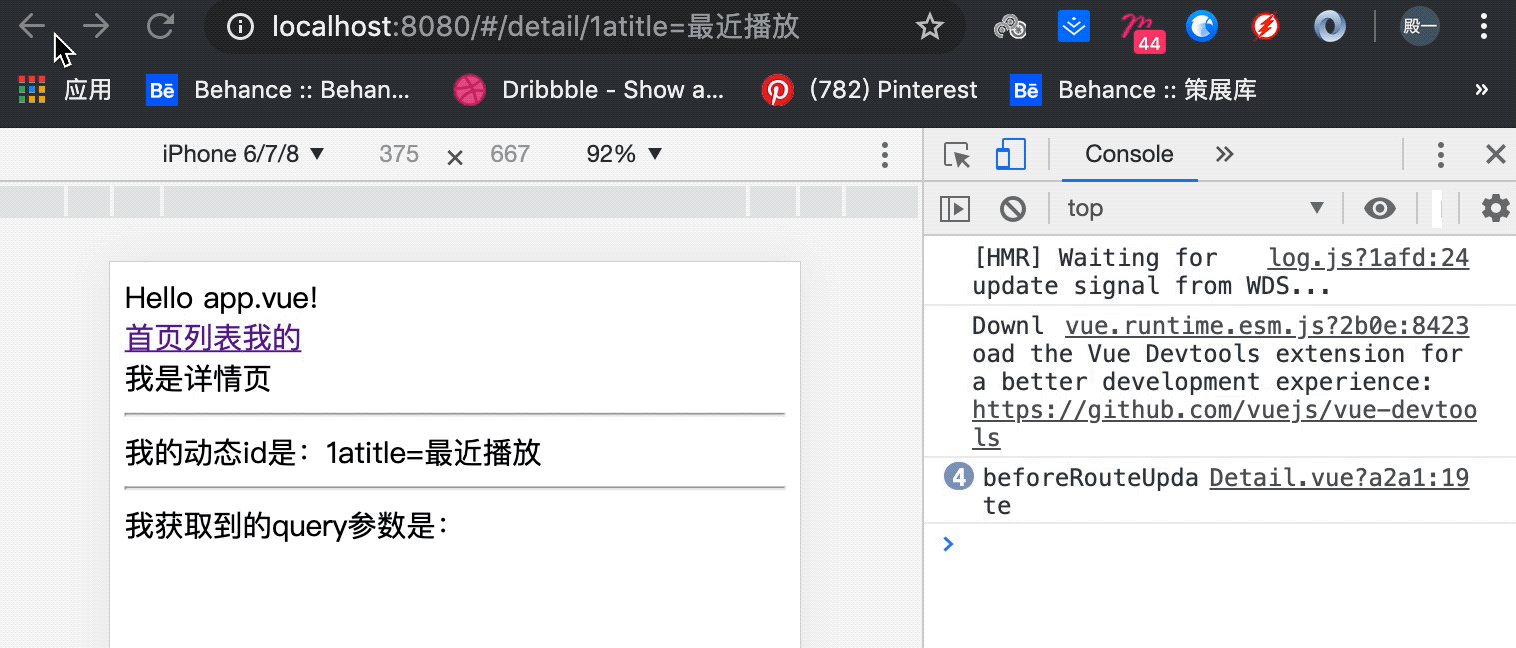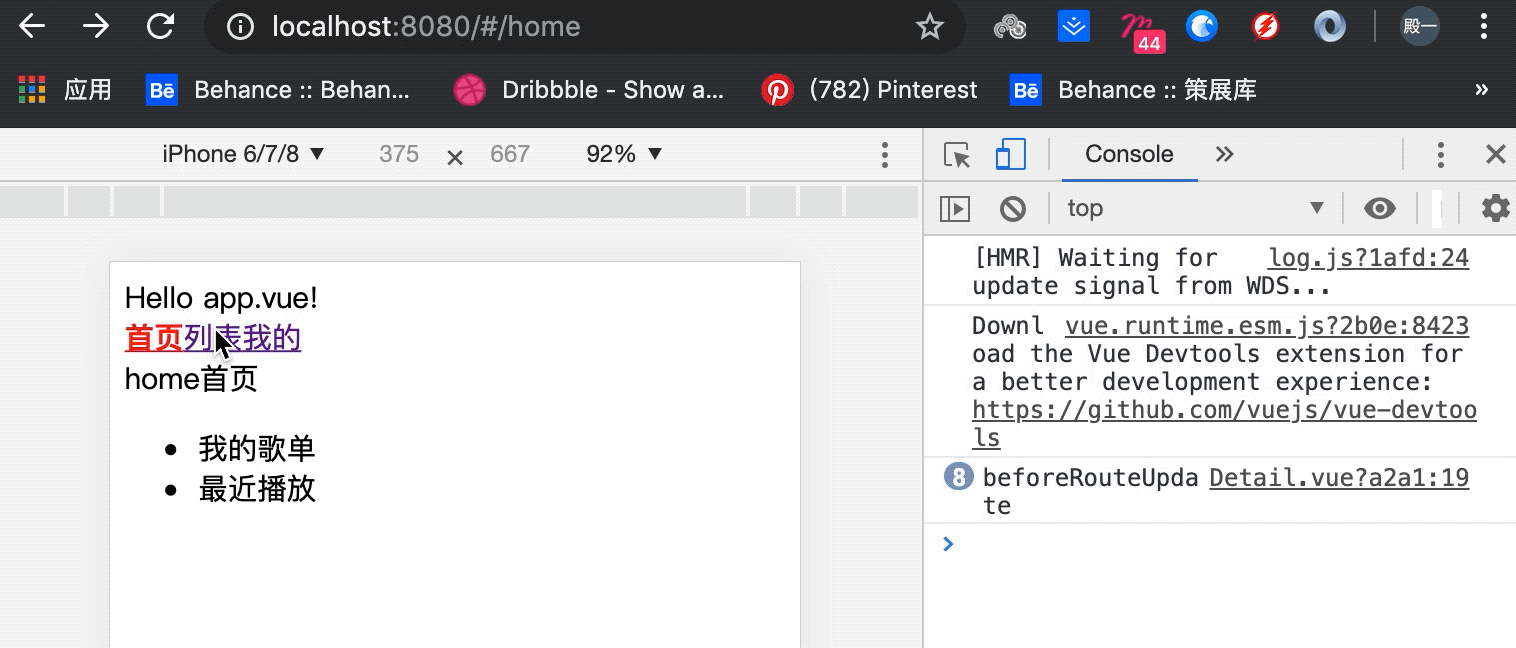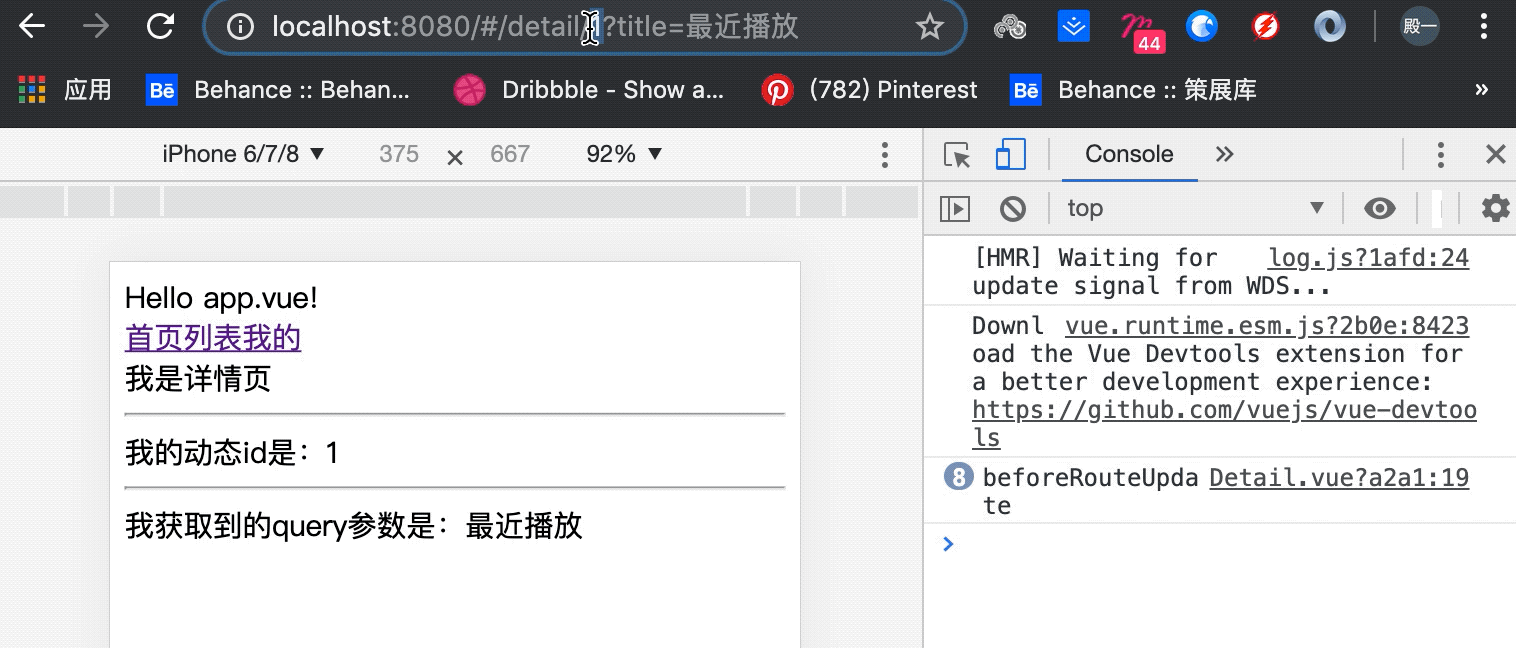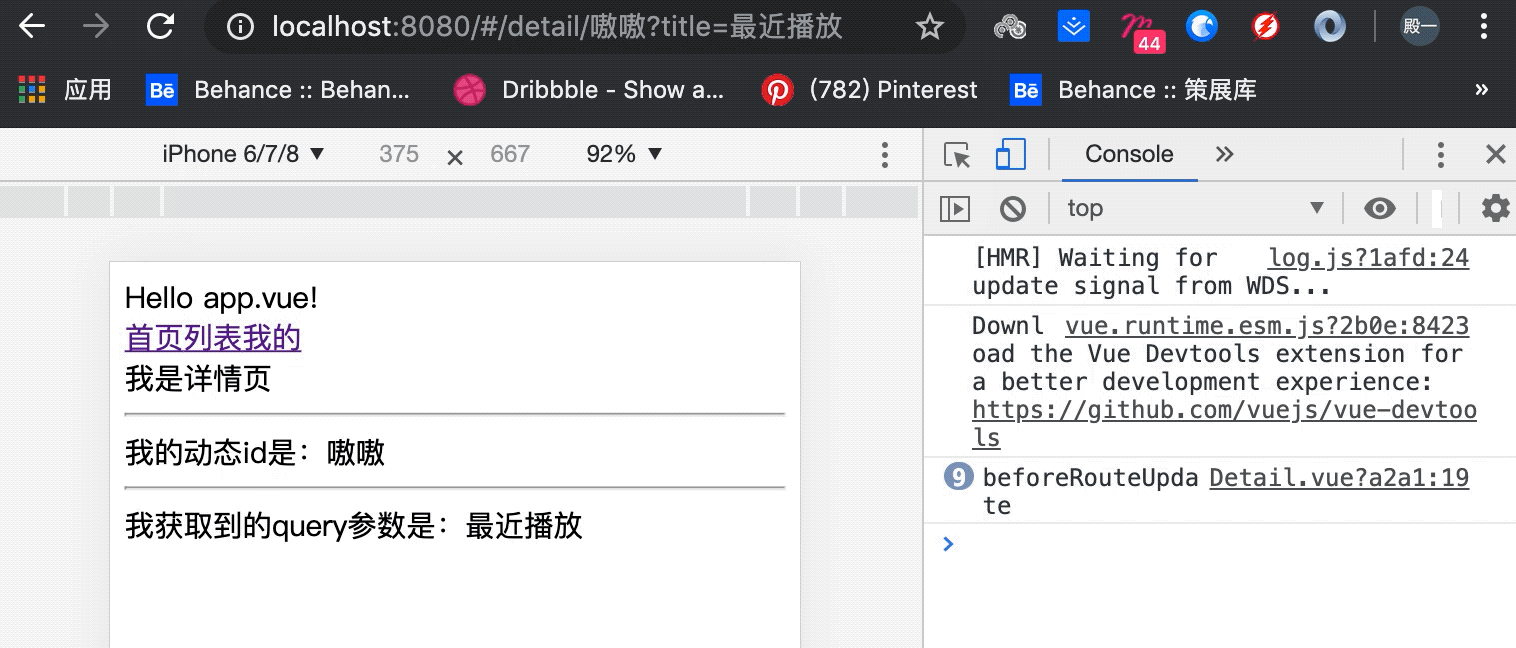
在vue项目中哪里用到过路由守卫?举一个使用到路由守卫的案例
我们想实现当路由变化的时候头部信息动态更改,我们先把内容写成这种样式:
template中:
<div class = "left"> <i :class = "['fa','fa-' + icon]"></i> <span>{ {title}}</span> </div>data中:
data(){ return{ icon:"home", title:"豆瓣首页", } },这时候就需要用到路由守卫,当路由切换的时候可以做一些业务逻辑,首先需要引入全局路由
import router from "@/router"在全局前置路由守卫router.beforeEach中,使用switch语句来匹配,根据路由name属性来设置对应的title和icon:
created(){ router.beforeEach((to,from,next)=>{ switch(to.name){ case "home": this.title = "豆瓣首页" this.icon = "home" break; case "audio": this.title = "豆瓣影音" this.icon = "audio-description" break; case "broadcast": this.title = "豆瓣广播" this.icon = "caret-square-o-left" break; case "group": this.title = "豆瓣小组" this.icon = "group" break; case "mine": this.title = "豆瓣我的" this.icon = "cog" break; default: break; } next(); }) }路由
什么是SPA单页应用?你怎么理解单页应用?
现在的应用都流行SPA(single page application),传统的项目大多使用多页面结构,需要切换内容的时候我们往往会进行单个html文件的跳转,这个时候受网络、性能影响,浏览器会出现不定时间的空白界面,用户体验不好。
单页面应用就是用户通过某些操作更改地址栏url之后,动态地进行不同模板内容的无刷新切换,用户体验好。
单页应用的优点
- 更好的用户体验,让用户在web感受natvie的速度和流畅;
- 经典MVC开发模式,前后端各负其责。
- 一套Server API,多端使用(web、移动APP等)
- 重前端,业务逻辑全部在本地操作,数据都需要通过AJAX同步、提交;
Vue切换路由的方法?vue-router的原理?
Vue中会使用官方提供的vue-router插件来使用单页面,原理就是通过检测地址栏变化后将对应的路由组件进行切换(卸载和安装)。
- 引入vue-router,如果是在脚手架中,引入VueRouter之后,需要通过Vue.use来注册插件
- 创建router路由器
- 创建路由表并配置在路由器中
- 在根实例里注入router,目的是为了让所有的组件里都能通过this.$router/route来使用路由的相关功能api
- 利用router-view来指定路由切换的位置
- 使用router-link来创建切换的工具,默认会渲染成a标签,添加to属性来设置要更改的path信息,且会根据当前路由的变化为a标签添加对应的router-link-active/router-link-exact-active(完全匹配成功)类名。
router-link标签的属性
组件支持用户在具有路由功能的应用中(点击)导航。 通过 to 属性指定目标地址,默认渲染成带有正确链接的 标签,可以通过配置 tag 属性生成别的标签。另外,当目标路由成功激活时,链接元素自动设置一个表示激活的 CSS 类名。
to
router-link的to属性,默认写的是path(路由的路径),可以通过设置一个对象,来匹配更多。
<router-link tag = "li" :to = "{name:'detail',params:{id:'1'},query:{title:'最近播放'}}">我的歌单</router-link>name
name是要跳转的路由的名字,也可以写path来指定路径,但是用path的时候就不能使用params传参,params是传路由参数,query传queryString参数。
replace
路由跳转到不同的url默认是push的过程,当用户点击浏览器后退按钮式时,则回到之前url,replace属性可以控制router-link的跳转不被记录。
依次点击首页——列表——音频——视频——我的,点击返回按钮时,依次返回之前的url。

在List.vue的标签中添加replace属性,则该标签内的跳转不会被记录
<router-link v-for = "nav in navs" :key = "nav.id" :to = "{name:nav.name}" active-class = "title" replace > { {nav.title}} </router-link>再依次点击首页——列表——音频——视频——我的,点击返回按钮时,可以看到从音频——视频之间的跳转没有被记录。

active-class
且会根据当前路由的变化为a标签添加对应的router-link-active/router-link-exact-active(完全匹配成功)类名,我们可以通过它来为标签设置不同的选中样式。
<style lang="scss"> .router-link-active{ color:blue; } .router-link-exact-active{ color:red; font-weight:900; } </style>标签切换时,选中状态的显示效果:

还可以通过的active-class属性给a标签添加指定一个activeClass名,通过设置这个class的样式,来设置标签选中时的状态,功能类似于router-link-exact-active。
<router-link v-for = "nav in navs" :key = "nav.id" :to = "nav.path" active-class = "title" > { {nav.title}} </router-link>设置.title样式
<style lang = "scss" scoped> .title{ color:aquamarine; } </style>显示效果:

tag
默认渲染成带有正确链接的a标签,可以通过配置 tag 属性生成别的标签。
<ul> <router-link tag = "li">我的歌单</router-link> <router-link tag = "li">最近播放</router-link> </ul>
路由跳转的方式
-
组件支持用户在具有路由功能的应用中(点击)导航。 通过 to 属性指定目标地址,默认渲染成带有正确链接的a标签,可以通过配置 tag 属性生成别的标签。另外,当目标路由成功激活时,链接元素自动设置一个表示激活的 CSS 类名。
-
编程式导航:this.$router.replace
This.$router.go
一级路由的实现
-
如果不是使用脚手架创建的项目,需要手动安装vue-router路由模块。
cnpm install vue-router -S -
引入vue-router,如果是在脚手架中,引入VueRouter之后,需要通过Vue.use来注册插件。
import Vue from 'vue' import Router from 'vue-router' Vue.use(Router)//让vue可以使用vue-router插件注册vue-router插件之后,this上就有了$route/router属性。

-
创建router路由器,并导出。
let router = new Router({ routes:[ ] }) export default router; -
在根实例里注入router
new Vue({ //挂载router router,//为了可以让组件使用this.$route,this.$router的一些api属性或者方法 store, render: h => h(App) }).$mount('#app')此时组件可以通过this.$router/router来使用路由相关功能的api。

-
创建router路由表
let router = new Router({ routes:[ { path:"/home",component:Home }, { path: "/list", component: List }, { path: "/mine", component: Mine } ] }) -
在App.vue中利用router-view来指定路由切换的位置
<template> <div id="app"> Hello app.vue! <!-- 显示路由组件的位置 --> <router-view></router-view> </div> </template>路由切换效果:

-
使用router-link来创建切换路由的工具
<div> <router-link to = "/home">首页</router-link> <router-link to = "/list">列表</router-link> <router-link to = "/mine">我的</router-link> </div>
会渲染成a标签,添加to属性来设置要更改的path信息

二级路由(路由嵌套)
在创建路由表的时候,可以为每一个路由对象创建children属性,值为数组,在这个里面又可以配置一些路由对象来使用多级路由,注意:一级路由path前加’/’,二级路由前不需要加’/’。
{ path :"/list",component:()=>import("../views/List"),children:[ // 二级路由前不需要加“/” { path: "audio", component: () => import("../views/Audio") }, { path: "video", component: () => import("../views/Video") } ]}二级路由组件的切换位置依然由router-view来指定(指定在父级路由组件的模板中)。
动态路由
在router路由表中配置动态路由,下面的代码就是给detail路由配置接收id的参数,多个参数继续在后面设置。
// 配置动态路由 { path:"/detail/:id",component:()=>import("../views/Detail.vue")}在页面中通过的to属性传递参数:
<ul> <router-link tag = "li" to = "/detail/1">我的歌单</router-link> <router-link tag = "li" to = "/detail/2">最近播放</router-link> </ul>在Detail.vue中打印this.$route.params.id
export default { created(){ //获取动态路由传递过来的参数 console.log(this.$route.params.id) } }在页面中通过$route.params.id渲染获取到的动态id
<template> <div class = "detail"> 我是详情页,我的动态id是:{ {$route.params.id}} </div> </template>
####一个vue组件中能有多个router-view吗?为什么
有时候想同时 (同级) 展示多个视图,而不是嵌套展示,例如创建一个布局,有
sidebar(侧导航) 和main(主内容) 两个视图,这个时候命名视图就派上用场了。你可以在界面中拥有多个单独命名的视图,而不是只有一个单独的出口。如果router-view没有设置名字,那么默认为default。<router-view class="view one"></router-view> <router-view class="view two" name="a"></router-view> <router-view class="view three" name="b"></router-view>一个视图使用一个组件渲染,因此对于同个路由,多个视图就需要多个组件。确保正确使用
components配置 (带上 s):const router = new VueRouter({ routes: [ { path: '/', components: { default: Foo, a: Bar, b: Baz } } ] })参考:命名识图(VUE官网)
https://router.vuejs.org/zh/guide/essentials/named-views.html#%E5%B5%8C%E5%A5%97%E5%91%BD%E5%90%8D%E8%A7%86%E5%9B%BE
Vue路由传参有几种方式
路由参数
在router路由表中配置动态路由,下面的代码就是给detail路由配置接收id的参数,多个参数继续在后面设置。
// 配置动态路由 { path:"/detail/:id",component:()=>import("../views/Detail.vue")}在页面中通过的to属性传递参数:
<ul> <router-link tag = "li" to = "/detail/1">我的歌单</router-link> <router-link tag = "li" to = "/detail/2">最近播放</router-link> </ul>在Detail.vue中打印this.$route.params.id
export default { created(){ //获取动态路由传递过来的参数 console.log(this.$route.params.id) } }在页面中通过$route.params.id渲染获取到的动态id
<template> <div class = "detail"> 我是详情页,我的动态id是:{ {$route.params.id}} </div> </template>queryString参数
queryString参数不需要在路由表设置接收,直接设置?后面的内容:
<ul> <router-link tag = "li" to = "/detail/1?title=我的歌单">我的歌单</router-link> <router-link tag = "li" to = "/detail/2?title=最近播放">最近播放</router-link> </ul>在路由组件中通过this.$route.query接收
export default { created(){ //获取动态路由传递过来的参数 console.log(this.$route.params.id,this.$route.query.title) } }打印结果:

页面渲染效果:

上面的参数传递也可以写成对象的形式:
<!-- 写成对象的形式 --> <router-link tag = "li" :to = "{path:'/detail/2',query:{title:'最近播放'}}">最近播放</router-link>通过prop将路由与组件解耦
在组件中接收路由参数需要this.$route.params.id,代码冗余,现在可以在路由表里配置props:true。
{ path:"/detail/:id",component:()=>import("../views/Detail.vue"),name:"detail",props:true}在路由组件中可以通过props接收id参数去使用
props:["id"],在页面中就可以通过{ {id}}的方式来使用路由传递的参数
我的动态id是:{ {id}}路由模式
为了构建SPA(单页面应用),需要引入前端路由系统,这也就是Vue-router存在的意义。前端路由的核心,就在于:改变视图的同时不会向后端发出请求。
hash和history这两个方法应用于浏览器的历史记录站,在当前已有的back、forward、go 的基础之上,它们提供了对历史记录进行修改的功能。只是当它们执行修改是,虽然改变了当前的URL,但你浏览器不会立即向后端发送请求。
hash:即地址栏URL中的#符号(此hsah 不是密码学里的散列运算)
路由有两种模式:hash、history,默认会使用hash模式

比如这个URL:http://www.baidu.com/#/hello, hash 的值为#/hello。它的特点在于:hash 虽然出现URL中,但不会被包含在HTTP请求中,对后端完全没有影响,因此改变hash不会重新加载页面。
history:利用了HTML5 History Interface 中新增的pushState() 和replaceState() 方法。(需要特定浏览器支持)
如果url里不想出现丑陋hash值(#),在new VueRouter的时候配置mode值为history来改变路由模式,本质使用H5的histroy.pushState方法来更改url,不会引起刷新。
// 默认会使用hash模式 mode:"history",
history模式,会出现404 的情况,需要后台配置。
hash模式和history模式在发生404错误时:
-
hash模式下,仅hash符号之前的内容会被包含在请求中,当用户访问https://www.baidu.com/#/home时实际请求的是:https://www.baidu.com/。因此对于后端来说,即使没有做到对路由的全覆盖,页面也不会返回404错误;

-
history模式下,前端的url必须和实际向后端发起请求的url 一致,因为我们的应用是个单页客户端应用,如果后台没有正确的配置,当用户在浏览器直接访问 https://www.baidu.com/home/detail,缺少对/home/detail的路由处理,就会返回 404错误,这就不好看了。

所以呢,你要在服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面,这个页面就是你 app 依赖的页面。
hash哈希路由的原理
window.onload = function(){ //当hash发生变化的时候, 会产生一个事件 onhashchange window.onhashchange = function(){ console.log( '你的hash改变了' ); //location对象是 javascript内置的(自带的) console.log( location ); } }上例,我们已经通过hash( 就是锚文本 ) 变化, 触发了onhashchange事件, 就可以把hash变化与内容切换对应起来,就实现了单页路由的应用!
监控hash值变化,hash一旦变化,页面内容变化,实现无刷新切换。
参考:js单页hash路由原理与应用实战
https://www.cnblogs.com/ghostwu/p/7357381.html
路由的懒加载
当打包构建应用时,JavaScript 包会变得非常大,影响页面加载。如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应组件,这样就更加高效了。结合 Vue 的异步组件和 Webpack 的代码分割功能,轻松实现路由组件的懒加载。
懒加载也叫延迟加载,即在需要的时候进行加载,随用随载。在单页应用中,如果没有应用懒加载,运用webpack打包后的文件将会异常的大,造成进入首页时,需要加载的内容过多,延时过长,会出现长时间的白屏,即使做了loading也是不利于用户体验,而运用懒加载则可以将页面进行划分,需要的时候加载页面,可以有效的分担首页所承担的加载压力,减少首页加载用时。简单的说就是:进入首页时不用一次加载过多资源,造成页面加载用时过长。
懒加载写法:
// 路由的懒加载方式 { path :"/home",component:()=>import("../views/Home")},// 当我访问/home首页时,页面才去加载Home组件,减少首页加载的时长 { path :"/list",component:()=>import("../views/List")}, { path :"/mine",component:()=>import("../views/Mine")}非按需加载则会把所有的路由组件块的js包打在一起。当业务包很大的时候建议用路由的按需加载(懒加载)。 按需加载会在页面第一次请求的时候,把相关路由组件块的js添加上。
参考:路由的懒加载(VUE官网)
https://router.vuejs.org/zh/guide/advanced/lazy-loading.html
通过正则匹配路由
// The matching uses path-to-regexp, which is the matching engine used // by express as well, so the same matching rules apply. // For detailed rules, see https://github.com/pillarjs/path-to-regexp const router = new VueRouter({ mode: 'history', base: __dirname, routes: [ { path: '/' }, // params are denoted with a colon ":" { path: '/params/:foo/:bar' }, // a param can be made optional by adding "?" { path: '/optional-params/:foo?' }, // a param can be followed by a regex pattern in parens // this route will only be matched if :id is all numbers { path: '/params-with-regex/:id(\\d+)' }, // asterisk can match anything { path: '/asterisk/*' }, // make part of th path optional by wrapping with parens and add "?" { path: '/optional-group/(foo/)?bar' } ] })官方例子github地址:https://github.com/vuejs/vue-router/blob/next/examples/route-matching/app.js
Vuex
什么是Vuex?
vuex是一个专门为vue构建的状态集管理工具,vue和react都是基于组件化开发的,项目中包含很多的组件,组件都会有组件嵌套,想让组件中的数据被其他组件也可以访问到就需要使用到Vuex。
Vuex主要解决了什么问题?
Vuex主要是为了解决多组件之间状态共享问题,它强调的是集中式管理(组件与组件之间的关系变成了组件与仓库之间的关系)把数据都放在一个仓库中管理,使用数据的时候直接从仓库中获取,如果仓库中一个数据改变了, 那么所有使用这个数据的组件都会更新。Vuex把组件与组件之间的关系解耦成组件与仓库之间的关系,方便数据维护。
Vuex的流程?Vuex的核心?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m4RwSB00-1627437898708)(https://segmentfault.com/img/bVvcIk?w=1400&h=1100)]
(1)将需要共享的状态挂载到state上:this.$store.state来调用
创建store,将状态挂载到state上,在根实例里面配置store,之后我们在组件中就可以通过this.$store.state来使用state中管理的数据,但是这样使用时,当state的数据更改的时候,vue组件并不会重新渲染,所以我们要通过计算属性computed来使用,但是当我们使用多个数据的时候这种写法比较麻烦,vuex提供了mapState辅助函数,帮助我们在组件中获取并使用vuex的store中保存的状态。
(2)我们通过getters来创建状态:通过this.$store.getters来调用
可以根据某一个状态派生出一个新状态,vuex也提供了mapGetters辅助函数来帮助我们在组件中使用getters里的状态。
(3)使用mutations来更改state:通过this.$store.commit来调用
我们不能直接在组件中更改state,而是需要使用mutations来更改,mutations也是一个纯对象,里面包含很多更改state的方法,这些方法的形参接收到state,在函数体里更改,这时,组件用到的数据也会更改,实现响应式。vuex提供了mapMutations方法来帮助我们在组件中调用mutations 的方法。
(4)使用actions来处理异步操作:this.$store.dispatch来调用
Actions类似于mutations,不同在于:Actions提交的是mutations,而不是直接变更状态。Actions可以包含任意异步操作。也就是说,如果有这样的需求:在一个异步操作处理之后,更改状态,我们在组件中应该先调用actions,来进行异步动作,然后由actions调用mutations来更改数据。在组件中通过this.$store.dispatch方法调用actions的方法,当然也可以使用mapMutations来辅助使用。
简便版流程:
组件使用数据且通过异步动作更改数据的一系列事情: 1.生成store,设置state 2.在根实例中注入store 3.组件通过计算属性或者mapState来使用状态 4.用户产生操作,调用actions的方法,然后进行异步动作 5.异步动作之后,通过commit调用mutations的方法 6.mutations方法被调用后,更改state 7.state中的数据更新之后,计算属性重新执行来更改在页面中使用的状态 8.组件状态被更改,创建新的虚拟dom 9.组件的模板更新之后重新渲染在dom中什么情况下用到vuex?
使用Vuex的情况:多组件间频繁通信
目前市场上有两种使用vuex的情况, 第一种:将需要共享、需要管理的状态放入vuex中管理,也就是说在必要时使用 第二种:将所有的数据都交由vuex管理,由vuex来承担更多的责任,组件变得更轻量级,视图层更轻项目中使用到vuex的一些场景?
(1)购物车数据共享
(2)用户登录
(3)打开窗口,出现一个表单数据,然后关闭窗口,再次打开还想出现,就使用vuexVuex的项目结构
Vuex 并不限制你的代码结构。但是,它规定了一些需要遵守的规则:
- 应用层级的状态应该集中到单个 store 对象中。
- 提交 mutation 是更改状态的唯一方法,并且这个过程是同步的。
- 异步逻辑都应该封装到 action 里面。
只要你遵守以上规则,如何组织代码随你便。如果你的 store 文件太大,只需将 action、mutation 和 getter 分割到单独的文件。
对于大型应用,我们会希望把 Vuex 相关代码分割到模块中。下面是项目结构示例:
├── index.html ├── main.js ├── api │ └── ... # 抽取出API请求 ├── components │ ├── App.vue │ └── ... └── store ├── index.js # 我们组装模块并导出 store 的地方 ├── actions.js # 根级别的 action ├── mutations.js # 根级别的 mutation └── modules ├── cart.js # 购物车模块 └── products.js # 产品模块来源:项目结构(VUE官网)
https://vuex.vuejs.org/zh/guide/structure.html#%E9%A1%B9%E7%9B%AE%E7%BB%93%E6%9E%84
vuex与local storage有什么区别
-
区别:vuex存储在内存,localstorage(本地存储)则以文件的方式存储在本地,永久保存;sessionstorage( 会话存储 ) ,临时保存。localStorage和sessionStorage只能存储字符串类型,对于复杂的对象可以使用ECMAScript提供的JSON对象的stringify和parse来处理。
-
应用场景:vuex用于组件之间的传值,localstorage,sessionstorage则主要用于不同页面之间的传值。
-
永久性:当刷新页面(这里的刷新页面指的是 --> F5刷新,属于清除内存了)时vuex存储的值会丢失,sessionstorage页面关闭后就清除掉了,localstorage不会。
注:很多同学觉得用localstorage可以代替vuex, 对于不变的数据确实可以,但是当两个组件共用一个数据源(对象或数组)时,如果其中一个组件改变了该数据源,希望另一个组件响应该变化时,localstorage,sessionstorage无法做到,原因就是区别1。
Slot插槽
vue里提供了一种将父组件的内容和子组件的模板整合的方法:内容分发,通过slot插槽来实现。
在组件标签内部写入的内容默认的会被替换掉,如果想要在组件的模板里使用这些内容,就在对应的位置写上slot标签,这个slot标签就代表着这些内容。
匿名槽口
在父组件中使用子组件的时候,在子组件标签内部写的内容,在子组件的模板中可以通过来使用
<div id = "app"> <aaa> <h3>slot槽口插入的内容</h3> </aaa> </div> <template id="aaa"> <div class = "aaa"> <slot></slot> <p>我是aaa组件</p> </div> </template>
具名槽口
父组件在子组件标签内写的多个内容我们可以给其设置slot属性来命名,在子组件的模板通过使用带有name属性的slot标签来放置对应的slot,当slot不存在的时候,slot标签内写的内容就出现。
slot上面通过name属性指定槽口名称,然后使用的时候通过slot=“槽口名称”。
<div id = "app"> <aaa> <!-- <h3>slot槽口插入的内容</h3> --> <p slot = "s1">在上面的内容</p> <p slot = "s2">在下面的内容</p> </aaa> </div> <template id="aaa"> <div class = "aaa"> <slot name = "s1"></slot> <p>我是aaa组件</p> <slot name = "s2"></slot> </div> </template>
slot插槽让我们在原有模版的基础上,定制更加多样化的组件。
作用域插槽
当我们想在父组件中访问子组件内部的一些数据时,就需要在子组件内部的元素上动态绑定一个自定义属性,将数据传递到自定义属性上,通过slot传递给父组件使用。
<slot :teacher="teacher"></slot>绑定到元素上的属性我们称之为slot props。现在,在父组件中我们可以通过slot-scope给包含所有插槽 prop 的对象命名为prop,之后就可以通过prop来使用子组件中的数据了。
<template slot-scope="prop"> 老师姓名:{ {prop.teacher.name}} 老师年龄:{ {prop.teacher.age}} </template>
v-slot
v-slot指令自 Vue 2.6.0 起被引入,提供更好的支持slot和slot-scope特性的 API 替代方案。在接下来所有的 2.x 版本中slot和slot-scope特性仍会被支持,但已经被官方废弃,且不会出现在 Vue 3 中。现在我们使用
v-slot重构上面的代码:<template v-slot:default="prop"> 老师姓名:{ {prop.teacher.name}} 老师年龄:{ {prop.teacher.age}} </template>一个不带
name的<slot>出口会带有隐含的名字“default”,使用时可以简化为v-slot="prop“。具名槽口
子组件中通过name属性给槽口设定名称
<slot name="student" :student='student'></slot>父组件中通过
v-slot:名称的方式来使用具名槽口<template v-slot:student="prop"> 学生姓名:{ {prop.student.name}} 学生年龄:{ {prop.student.age}} </template>当我们在父组件中多次调用子组件时,可以通过设置不同的样式,来设定子组件中数据的展示形式。
主流js框架对比
Vue和React的区别
(1)react销毁组件的时候,会将组件的dom结构也移除,vue则不然,在调用destory方法销毁组件的时候,组件的dom结构还是存在于页面中的,this.$destory组件结构还是存在的,只是移除了事件监听。
(2)react中没有指令
(3)在vue中,data属性是利用object.defineProperty处理过的,更改data的数据的时候会触发数据的getter和setter,但是react中没有做这样的处理,如果直接更改的话,react是无法得知的。
react更改状态:在setState中,传入一个对象,就会将组件的状态中键值对的部分更改,还可以传入一个函数,这个回调函数必须向上面方式一样的一个对象函数可以接受prevState和props。
(4)react中属性是不允许更改的,状态是允许更改的。react中组件不允许通过this.state这种方式直接更改组件的状态。自身设置的状态,可以通过setState来进行更改。
拓展:对比其他框架(Vue官网给出的详细解释)
https://vue.docschina.org/v2/guide/comparison.html
Vue和JQuery的区别
jQuery是使用选择器($)选取DOM对象,对其进行赋值、取值、事件绑定等操作,其实和原生的HTML的区别只在于可以更方便的选取和操作DOM对象,而数据和界面是在一起的。
比如需要获取label标签的内容:
$("lable").val();,它还是依赖DOM元素的值。Vue则是通过Vue对象将数据和View完全分离开来了。对数据进行操作不再需要引用相应的DOM对象,可以说数据和View是分离的,他们通过Vue对象这个vm实现相互的绑定。这就是传说中的MVVM。
-
vue适用的场景:复杂数据操作的后台页面,表单填写页面
-
jquery适用的场景:比如说一些html5的动画页面,一些需要js来操作页面样式的页面
然而二者也是可以结合起来一起使用的,vue侧重数据绑定,jquery侧重样式操作,动画效果等,则会更加高效率的完成业务需求
参考:jquery和vue对比
https://www.cnblogs.com/MR-YY/p/6898464.html
react与vue之间的相同点和不同点?
相同点:
1.都支持ssr服务器端渲染,vue:nuxt;react:next。
2.都有Virtual DOM,组件化开发,通过props参数进行父子组件数据的传递,都实现组件之间的模块化webComponent规范。
3.数据驱动视图,数据改变视图发生更改。
4.都有支持native的方案,React的React native,Vue的weex(终端的原生端端解决方案)
5.都有管理状态集工具,React有redux,Vue有自己的Vuex(自适应vue,量身定做)
不同点:
- React严格上只针对MVC的view层(用户界面的javascript库),Vue则是MVVM模式。
- virtual DOM不一样:vue会跟踪每一个组件的依赖关系,不需要重新渲染整个组件树。而对于React而言,每当应用的状态被改变时,全部组件都会重新渲染,所以react中会需要shouldComponentUpdate这个生命周期函数方法来进行控制。
- 组件写法不一样:React推荐的做法是 JSX + inline style, 也就是把HTML和CSS全都写进JavaScript了,即’all in js’;Vue推荐的做法是webpack+vue-loader的单文件组件格式,即html,css,js写在同一个文件;
- 数据绑定: vue实现了数据的双向绑定,react没有实现。
- state对象在react应用中不可变的,需要使用setState方法更新状态;在vue中,state对象不是必须的,数据由data属性在vue对象中管理。
React—用于构建用户界面的 JavaScript 库
组件
创建组件的方式
1、无状态函数式组件
创建纯展示组件,只负责根据传入的
props来展示,不涉及到要state状态的操作,是一个只带有一个render方法的组件类。2、组件是通过React.createClass创建的(ES5)
3、React.Component
在es6中直接通过class关键字来创建
组件其实就是一个构造器,每次使用组件都相当于在实例化组件
react的组件必须使用render函数来创建组件的虚拟dom结构
组件需要使用ReactDOM.render方法将其挂载在某一个节点上
组件的首字母必须大写
React.Component是以ES6的形式来创建react的组件的,是React目前极为推荐的创建有状态组件的方式,相对于React.createClass可以更好实现代码复用。将上面React.createClass的形式改为React.Component形式如下:class Greeting extends React.Component{ constructor (props) { super(props); this.state={ work_list: [] } this.Enter=this.Enter.bind(this); //绑定this } render() { return ( <div> <input type="text" ref="myWork" placeholder="What need to be done?" onKeyUp={this.Enter}/> <ul> { this.state.work_list.map(function (textValue) { return <li key={textValue}>{textValue}</li>; }) } </ul> </div> ); } Enter(event) { var works = this.state.work_list; var work = this.refs.myWork.value; if (event.keyCode == 13) { works.push(work); this.setState({work_list: works}); this.refs.myWork.value = ""; } } }关于this
React.createClass创建的组件,其每一个成员函数的this都有React自动绑定,任何时候使用,直接使用this.method即可,函数中的this会被正确设置React.Component创建的组件,其成员函数不会自动绑定this,需要手动绑定,否则this不能获取当前组件实例对象React.Component三种手动绑定this的方法
1.在构造函数中绑定
constructor(props) { super(props); this.Enter = this.Enter.bind(this); }2.使用bind绑定
<div onKeyUp={this.Enter.bind(this)}></div>3.使用arrow function绑定
<div onKeyUp={(event)=>this.Enter(event)}></div>我们在实际应用中应该选择哪种方法来创建组件呢?
- 只要有可能,尽量使用无状态组件创建形式
- 否则(如需要state、生命周期方法等),使用
React.Component这种es6形式创建组件
无状态组件与有状态的组件的区别为?
没有状态,没有生命周期,只是简单的接受 props 渲染生成 DOM 结构
无状态组件非常简单,开销很低,如果可能的话尽量使用无状态组件。
无状态的函数创建的组件是无状态组件,它是一种只负责展示的纯组件
无状态组件可以使用纯函数来实现。
const Slide = (props)=>{return (<div>.....</div>)}这就是无状态组件(函数方式定义组件) 可以简写为 const Slide = props =>(<div>......</div>)React父子组件通信
(1)this.props
(2)ref链
(3)Redux
高阶组件
高阶组件是什么?如何理解?
什么是高级组件?首先你得先了解请求ES6中的class只是语法糖,本质还是原型继承。能够更好的进行说明,我们将不会修改组件的代码。而是通过提供一些能够包裹组件的组件,
并通过一些额外的功能来增强组件。这样的组件我们称之为高阶组件(Higher-Order Component)。高阶组件(HOC)是React中对组件逻辑进行重用的高级技术。但高阶组件本身并不是React API。它只是一种模式,这种模式是由React自身的组合性质必然产生的。
说到高阶组件,就先得说到高阶函数了,高阶函数是至少满足下列条件的函数:
1、接受一个或多个函数作为输入
2、输出一个函数高阶组件定义
类比高阶函数的定义,高阶组件就是接受一个组件作为参数,在函数中对组件做一系列的处理,随后返回一个新的组件作为返回值。
高阶组件的缺点
高阶组件也有一系列的缺点,首先是被包裹组件的静态方法会消失,这其实也是很好理解的,我们将组件当做参数传入函数中,返回的已经不是原来的组件,而是一个新的组件,原来的静态方法自然就不存在了。如果需要保留,我们可以手动将原组件的方法拷贝给新的组件,或者使用hoist-non-react-statics之类的库来进行拷贝。
参考:浅谈React高阶组件
https://www.jb51.net/article/137272.htm
使用过哪些高阶组件
-
withRouter高阶组件,可以根据传入的组件生成一个新的组件,并且为新组件添加上router相关的api。
-
connect 用于连接容器组件与UI组件,connect(mapStateToProps,mapDispatchToProps)(ui组件),当状态改变的时候,容器组件内部因为通过store.subscribe可以监听状态的改变,给ui组件传入新的属性,返回容器组件(智能组件),这个函数返回什么,ui组件props上就会挂载什么,ui组件的属性上就就会有改变状态的方法了,用的话通过this.props.方法名。
虚拟dom
####React高性能的体现:虚拟DOM
在Web开发中我们总需要将变化的数据实时反应到UI上,这时就需要对DOM进行操作。而复杂或频繁的DOM操作通常是性能瓶颈产生的原因(如何进行高性能的复杂DOM操作通常是衡量一个前端开发人员技能的重要指标)。
React为此引入了虚拟DOM(Virtual DOM)的机制:在浏览器端用Javascript实现了一套DOM API。基于React进行开发时所有的DOM构造都是通过虚拟DOM进行,每当数据变化时,React都会重新构建整个DOM树,然后React将当前整个DOM树和上一次的DOM树进行对比,得到DOM结构的区别,然后仅仅将需要变化的部分进行实际的浏览器DOM更新。而且React能够批处理虚拟DOM的刷新,在一个事件循环(Event Loop)内的两次数据变化会被合并,例如你连续的先将节点内容从A-B,B-A,React会认为A变成B,然后又从B变成A UI不发生任何变化,而如果通过手动控制,这种逻辑通常是极其复杂的。
尽管每一次都需要构造完整的虚拟DOM树,但是因为虚拟DOM是内存数据,性能是极高的,部而对实际DOM进行操作的仅仅是Diff分,因而能达到提高性能的目的。这样,在保证性能的同时,开发者将不再需要关注某个数据的变化如何更新到一个或多个具体的DOM元素,而只需要关心在任意一个数据状态下,整个界面是如何Render的。
为什么虚拟dom会提升代码性能?
虚拟DOM就是JavaScript对象,就是在没有真实渲染DOM之前做的操作。
真实dom的比对变成了虚拟dom的比对(js对象的比对)
虚拟dom里面比对,涉及到diff算法。 key值 (key值相同dom可以直接进行复用)react的diff算法实现流程
1.DOM结构发生改变-----直接卸载并重新create
2.DOM结构一样-----不会卸载,但是会update变化的内容
3.所有同一层级的子节点.他们都可以通过key来区分-----同时遵循1.2两点
(其实这个key的存在与否只会影响diff算法的复杂度,换言之,你不加key的情况下,diff算法就会以暴力的方式去根据一二的策略更新,但是你加了key,diff算法会引入一些另外的操作)React会逐个对节点进行更新,转换到目标节点。而最后插入新的节点,涉及到的DOM操作非常多。diff总共就是移动、删除、增加三个操作,而如果给每个节点唯一的标识(key),那么React优先采用移动的方式,能够找到正确的位置去插入新的节点
diff算法和fiber算法的区别
diff算法是同步进行更新和比较,必须同步执行完一个操作再进行下一个操作,所耗时间比较长,JavaScript是单线程的,一旦组件开始更新,主线程就一直被React控制,这个时候如果再次执行交互操作,就会卡顿。
React Fiber重构这种方式,渲染过程采用切片的方式,每执行一会儿,就歇一会儿。如果有优先级更高的任务到来以后呢,就会先去执行,降低页面发生卡顿的可能性,使得React对动画等实时性要求较高的场景体验更好。
如何理解React中key?
keys是什么帮助 React 跟踪哪些项目已更改、添加或从列表中删除。
每个 keys 在兄弟元素之间是独一无二的。
keys 使处理列表时更加高效,因为 React 可以使用子元素上的 keys 快速知道元素是新的还是在比较树时才被移动。
keys 不仅使这个过程更有效率,而且没有 keys ,React 不知道哪个本地状态对应于移动中的哪个项目。
例如:数组循环出来三项,每一项前面有一个多选框,假设第一个多选框勾选了,然后我再动态添加新的元素,会发现新添加的元素就会被勾选了,这就是个问题!设置key值,这样的话就可以解决了。####JSX 语法
在vue中,我们使用render函数来构建组件的dom结构性能较高,因为省去了查找和编译模板的过程,但是在render中利用createElement创建结构的时候代码可读性较低,较为复杂,此时可以利用jsx语法来在render中创建dom,解决这个问题,但是前提是需要使用工具来编译jsx
JSX是一种语法,全称:javascript xml
JSX语法不是必须使用的,但是因为使用了JSX语法之后会降低我们的开发难度,故而这样的语法又被成为语法糖。
react.js中有React对象,帮助我们创建组件等功能
HTML 中所有的信息我们都可以用 JavaScript 对象来表示,但是用 JavaScript 写起来太长了,结构看起来又不清晰,用 XML的方式写起来就方便很多了。
于是 React.js 就把 JavaScript 的语法扩展了一下,让 JavaScript 语言能够支持这种直接在 JavaScript 代码里面编写类似 XML 标签结构的语法,这样写起来就方便很多了。编译的过程会把类似 XML 的 JSX 结构转换成 JavaScript 的对象结构。
在不使用JSX的时候,需要使用React.createElement来创建组件的dom结构,但是这样的写法虽然不需要编译,但是维护和开发的难度很高,且可读性很差。
所谓的 JSX 其实就是 JavaScript 对象,所以使用 React 和 JSX 的时候一定要经过编译的过程:
JSX代码 — > 使用react构造组件,bable进行编译—> JavaScript对象 —
ReactDOM.render()函数进行渲染—>真实DOM元素 —>插入页面另:
- JSX就是在js中使用的xml,但是,这里的xml不是真正的xml,只能借鉴了一些xml的语法,例如:
最外层必须有根节点、标签必须闭合
- jsx借鉴xml的语法而不是html的语法原因:xml要比html严谨,编译更方便
webpack中,是借助loader完成的jsx代码的转化,还是babel?
在vue中,借助webpack提供的vue-loader来帮助我们做一些转化,让vue代码可以在浏览器中执行。
react中没有react-loader来进行代码的转化,而是采用babel里面babel-preset-react来实现的。调用setState之后,发生了什么?
constructor(props){ super(props); this.state = { age:1 } }通过调用this.setState去更新this.state,不能直接操作this.state,请把它当成不可变的。
调用setState更新this.state,他不是马上就会生效的,他是异步的。所以不要认为调用完setState后可以立马获取到最新的值。多个顺序执行的setState不是同步的一个接着一个的执行,会加入一个异步队列,然后最后一起执行,即批处理。
setState是异步的,导致获取dom可能拿的还是之前的内容,所以我们需要在setState第二个参数(回调函数)中获取更新后的新的内容。
this.setState((prevState)=>({ age:++prevState.age }),()=>{ console.log(this.state.age) //获取更新后的最新的值 });React实现异步请求
redux中间件
通常情况下,action只是一个对象,不能包含异步操作
redux-thunk中间件
redux-thunk原理:
-可以接受一个返回函数的actionCreators,如果这个actionCreators返回的是一个函数,就执行它,如果不是,就按照原来的next(action)执行
-如果不安装redux-thunk中间件,actionCreators只能返回一个对象
-安装了redux-thunk中间件之后,actionCreators可以返回一个函数了,在这个函数里面可以写异步操作的代码
-redux中间件,创建出来的action在到达reducer之间,增强了dispatch的派发功能
####refs的作用业务场景?
通过ref对dom、组件进行标记,在组件内部通过this.refs获取到之后,进行操作
<ul ref='content'><li>国内新闻</li></ul> ... this.refs.content.style.display = this.state.isMenuShow?'block':'none'ref用于给组件做标记,例如获取图片的宽度与高度。
非受控组件,input输入框,获取输入框中的数据,可以通过ref做标记。
<input ref={el=>this.input = el}/>ref是一个函数,为什么?
避免组件之间数据相互被引用,造成内存泄漏
class Test extends React.Component{ componentDidMount(){ console.log(this.el); } render(){ //react在销毁组件的时候会帮助我们清空掉ref的相关引用,这样可以防止内存泄漏等一系列问题。 return <div ref={el=>this.el=el}></div> } }受控组件与非受控组件的区别
受控组件与非受控组件是相对于表单而言。
受控组件: 受到数据的控制。组件的变化依靠数据的变化,数据变化了,页面也会跟着变化了。输入框受到数据的控制,数据只要不变化,input框输什么都不行,一旦使用数据,从状态中直接获取。
<input value={this.state.value}/>非受控组件: 直接操作dom,不做数据的绑定。通过refs来获取dom上的内容进行相关的操作。
<input ref={el=>this.el=el}/> //不需要react组件做管理数据驱动是react核心。
实现监听滚动高度
class Test extends React.Component{ constructor(props){ super(props); this.handleWidowScroll = this.handleWidowScroll.bind(this); } handleWidowScroll(){ this.setState({ top:document.body.scrollTop }) } componentDidMount(){//绑定监听事件 window.addEventListener("scroll",this.handleWindowScroll); } componentWillUnmount(){//移除监听事件 window.removeEventListener("scroll",this.handleWindowScroll); } }####React中data为什么返回一个函数
为了防止组件与组件之间的数据共享,让作用域独立,data是函数内部返回一个对象,让每个组件或者实例可以维护一份被返回对象的独立的拷贝。
路由
react-router4的核心思想是什么?
路由也变成组件了,所以它是非常灵活的(NavLink Route)。 vue中的路由需要单独的配置 vue-router。
react-router的两种模式是什么?
hashHistory # 不需要后端服务器的配置
browserHistory / 需要后端服务器的配置 (后端人员不清楚路由重定向等相关的概念)hash路由的实现原理
通过onhashchange事件监听路由的改变,一旦路由改变,这个事件就会被执行,就可以拿到更改后的哈希值,通过更改后的哈希值就可以让我们的页面进行一个关联,一旦路由发生改变了,整个页面状态就会发生改变,但是整个页面是没有发生任何http请求的,整个页面处于一种无刷新状态。
- hash模式背后的原理是
onhashchange事件,可以在window对象上监听这个事件:
window.onhashchange = function(event) { console.log(event.oldURL, event.newURL); let hash = loaction.hash //通过location对象来获取hash地址 console.log(hash) // "#/notebooks/260827/list" 从#号开始 }因为hash发生变化的url都会被浏览器记录下来,从而你会发现浏览器的前进后退都可以用 ,这样一来,尽管浏览器没有请求服务器,但是页面状态和url一一关联起来,后来人们给它起了一个霸气的名字叫前端路由,成为了单页应用标配。
spa单页应用:根据页面地址的不同来实现组件之间的切换,整个页面处于一种无刷新状态。
history路由
随着history api的到来,前端路由开始进化了,前面的hashchange,你只能改变#后面的url片段,而history api则给了前端完全的自由
history api可以分为两大部分:切换和修改 【切换路由/修改路由】
(1)切换历史状态
包括括
back、forward、go三个方法,对应浏览器的前进,后退,跳转操作history.go(-2);//后退两次 history.go(2);//前进两次 history.back(); //后退 hsitory.forward(); //前进(2)修改历史状态
包括 了
pushState、replaceState两个方法,这两个方法接收三个参数:stateObj,title,url。两种模式的区别是什么?
在hash模式下,前端路由修改的是#中的信息,而浏览器请求时是不带它玩的,所以没有问题。但是在history下,你可以自由的修改path,当刷新时,如果服务器中没有相应的响应或者资源,会分分钟刷出一个404来,需要后端人员去做一个配置。
生命周期
react的生命周期函数
【初始化阶段】:
(1)getDefaultProps:实例化组件之后,组件的getDefaultProps钩子函数会执行
这个钩子函数的目的是为组件的实例挂载默认的属性
这个钩子函数只会执行一次,也就是说,只在第一次实例化的时候执行,创建出所有实例共享的默认属性,后面再实例化的时候,不会执行getDefaultProps,直接使用已有的共享的默认属性
理论上来说,写成函数返回对象的方式,是为了防止实例共享,但是react专门为了让实例共享,只能让这个函数只执行一次
组件间共享默认属性会减少内存空间的浪费,而且也不需要担心某一个实例更改属性后其他的实例也会更改的问题,因为组件不能自己更改属性,而且默认属性的优先级低。
(2)getInitialState:为实例挂载初始状态,且每次实例化都会执行,也就是说,每一个组件实例都拥有自己独立的状态。
(3)componentWillMount:执行componentWillMount,相当于Vue里的created+beforeMount,这里是在渲染之前最后一次更改数据的机会,在这里更改的话是不会触发render的重新执行。
(4)render:渲染dom
render()方法必须是一个纯函数,他不应该改变state,也不能直接和浏览器进行交互,应该将事件放在其他生命周期函数中。 如果shouldComponentUpdate()返回false,render()不会被调用。(5)componentDidMount:相当于Vue里的mounted,多用于操作真实dom
【运行中阶段】
当组件mount到页面中之后,就进入了运行中阶段,在这里有5个钩子函数,但是这5个函数只有在数据(属性、状态)发送改变的时候才会执行
(1)componentWillReceiveProps(nextProps,nextState)
当父组件给子组件传入的属性改变的时候,子组件的这个函数才会执行。初始化props时候不会主动执行
当执行的时候,函数接收的参数是子组件接收到的新参数,这个时候,新参数还没有同步到this.props上,多用于判断新属性和原有属性的变化后更改组件的状态。
(2)接下来就会执行shouldComponentUpdate(nextProps,nextState),这个函数的作用:当属性或状态发生改变后控制组件是否要更新,提高性能,返回true就更新,否则不更新,默认返回true。
接收nextProp、nextState,根据根据新属性状态和原属性状态作出对比、判断后控制是否更新
如果
shouldComponentUpdate()返回false,componentWillUpdate,render和componentDidUpdate不会被调用。(3)componentWillUpdate,在这里,组件马上就要重新render了,多做一些准备工作,千万千万,不要在这里修改状态,否则会死循环 相当于Vue中的beforeUpdate
(4)render,重新渲染dom
(5)componentDidUpdate,在这里,新的dom结构已经诞生了,相当于Vue里的updated
【销毁阶段】
当组件被销毁之前的一刹那,会触发componentWillUnmount,临死前的挣扎
相当于Vue里的beforeDestroy,所以说一般会做一些善后的事情,例如使定时器无效,取消网络请求或清理在
componentDidMount中创建的任何监听。
为什么Vue中有destroyed,而react却没有componentDidUnmount
Vue在调用$destroy方法的时候就会执行beforeDestroy,然后组件被销毁,这个时候组件的dom结构还存在于页面结构中,也就说如果想要对残留的dom结构进行处理必须在destroyed处理,但是react执行完componentWillUnmount之后把事件、数据、dom都全部处理掉了,所以根本不需要其他的钩子函数了
React中怎么样就算组件被销毁:
- 当父组件从渲染这个子组件变成不渲染这个子组件的时候,子组件相当于被销毁
- 调用ReactDOM.unmountComponentAtNode(node) 方法来将某节点中的组件销毁
哪个生命周期里面发送ajax?
AJAX请求应该在componentDidMount生命周期事件中。
如何避免ajax数据重新获取?
将所有的数据存储在redux中进行管理,既可以解决该问题。
为什么不把请求数据的操作写在componentWillMount中而写在componentDidMount中?
(1)此钩子函数在16版本中会被频繁调用:15.X版本用的是diff算法,不会被频繁调用,而React下一代调和算法Fiber会通过开始或停止渲染的方式优化应用性能,其会影响到comonentWillMount的触发次数,对于componentWillMount这个生命周期的调用次数就会变得不确定。React可能会多次频繁调用componentWillMount,如果我们将ajax请求放到componentWillMount函数中,那么显而易见就会被触发多次,自然也就不是好的选择。
(2)componentWillMount()将在React未来版本(官方说法 17.0)中被弃用。为了避免副作用和其他的订阅,官方都建议使用componentDidMount()代替。这个方法是用于在服务器渲染上的唯一方法。
componentWillReceiveProps调用时机?
初始化父组件第一次将数据传递给子组件的时候不会去执行,只有属性props改变的时候,子组件的钩子函数才会触发执行。
受控组件与非受控组件的区别
受控组件:受到数据控制,例如表单元素,当输入框中的内容发生改变的时候,使其更改组件。数据驱动的理念,提倡内部的一些数据最好与组件的状态进行关联。
父组件可以将自己的属性传递给子组件,子组件通过this.props调用。
非受控组件;不会受到数据(state)的控制,由DOM本身进行管理,输入框的内容发生改变了,直接通过ref进行标记,然后直接获取使用即可。
Redux
你会把数据统一放入到redux中管理,还是共享数据放在redux中管理?
把所有的数据放入到redux中管理。(props,state)
项目一旦有问题,可以直接定位问题点。
组件扩展的时候,后续涉及到传递的问题。本来的话,自己使用数据,但是后来公用,还需要考虑如何传递。redux中存储数据可以存储至少5G以上的数据。
目的就是方便数据统一,好管理。React连接Redux用到什么?
react-redux辅助工具
核心组件:Provider提供者,属性上通过store将数据派给容器组件,connect用于连接容器组件与UI组件。
引入provider,哪个地方需要用到状态和属性,就包裹一下,并且一旦有状态改变,就会监听到,并且将最新的状态返回给UI组件。
ReactDOM.render( <Provider store = {store}> <Router> <App /> </Router> </Provider>, document.getElementById('root'));connect()(UI组件) ==》返回一个容器组件
这个方法参数是state=>store.getState()
这个方法返回什么,UI组件的属性上就是有什么
当状态改变的时候,容器组件就会监听状态的变化,并且把更新后的状态通过属性的方法传递给UI组件
因为容器组件已经帮助我们实现了store.subscribe方法的订阅,这时候就不需要constructor函数和监听函数,容器组件就会自动订阅状态的变化,UI组件通过this.props来获取函数中返回的state,这时候当我们对state进行操作的时候,状态就会改变,视图重新渲染,componentWillReceiveProps这个钩子函数就会执行,实现了对状态改变的事实监听。
connect中有两个参数,一个是映射状态到组件属性(mapStateToProps),一个是映射方法到组件属性(mapDispatchToProps),最终内部返回一个容器组件帮助我们做监听操作,一旦状态更改,UI组件就会重新渲染。
connect(mapStateToProps,mapDispatchToProps)(ui组件)
容器组件内部帮你做了 store.subscribe() 状态变化 ==> 容器组件监听状态改变了 ==> 通过属性的方式给ui组件传递
把
store.getState()的状态转化为展示组件的props当我们需要挂载很多方法的时候我们可以将之简写
首先我们引入bindActionCreators
import {bindActionCreators} from "redux"然后我们使用bindActionCreators将所有操作状态的方法全部取出来绑定到UI组件的属性上,使用的时候直接通过this.props取即可。
//actionCreators很纯粹了,需要创建action然后返回action即可! //ui组件的属性上就就会有改变状态的方法了,用的话通过this.props.方法名 const mapDispatchToProps = dispatch=>{ return bindActionCreators(actionsCreators,dispatch) } connect(mapStateToProps,mapDispatchToProps)(UI组件)Redux的组成
redux有四个组成部分:
store:用来存储数据
reducer:真正的来管理数据
actionCreator:创建action,交由reducer处理
view: 用来使用数据,在这里,一般用react组件来充当

什么时候用redux?
如果你不知道是否需要 Redux,那就是不需要它
只有遇到 React 实在解决不了的问题,你才需要 Redux
简单说,如果你的UI层非常简单,没有很多互动,Redux 就是不必要的,用了反而增加复杂性。
- 用户的使用方式非常简单
- 用户之间没有协作
- 不需要与服务器大量交互,也没有使用 WebSocket
- 视图层(View)只从单一来源获取数据
需要使用redux的项目:
- 用户的使用方式复杂
- 不同身份的用户有不同的使用方式(比如普通用户和管理员)
- 多个用户之间可以协作
- 与服务器大量交互,或者使用了WebSocket
- View要从多个来源获取数据
从组件层面考虑,什么样子的需要redux:
- 某个组件的状态,需要共享
- 某个状态需要在任何地方都可以拿到
- 一个组件需要改变全局状态
- 一个组件需要改变另一个组件的状态
redux的设计思想:
-
Web 应用是一个状态机,视图与状态是一一对应的。
-
所有的状态,保存在一个对象里面(唯一数据源)。
Redux的流程
Redux的流程:
-
创建store:
从redux工具中取出createStore去生成一个store。
-
创建一个reducer,然后将其传入到createStore中辅助store的创建。
reducer是一个纯函数,接收当前状态和action,返回一个状态,返回什么,store的状态就是什么,需要注意的是,不能直接操作当前状态,而是需要返回一个新的状态。
想要给store创建默认状态其实就是给reducer一个参数创建默认值。
-
组件通过调用store.getState方法来使用store中的state,挂载在了自己的状态上。
-
组件产生用户操作,调用actionCreator的方法创建一个action,利用store.dispatch方法传递给reducer
-
reducer对action上的标示性信息做出判断后对新状态进行处理,然后返回新状态,这个时候store的数据就会发生改变, reducer返回什么状态,store.getState就可以获取什么状态。
-
我们可以在组件中,利用store.subscribe方法去订阅数据的变化,也就是可以传入一个函数,当数据变化的时候,传入的函数会执行,在这个函数中让组件去获取最新的状态。
reducer是一个纯函数?你对纯函数是怎么理解的?
reducer是state最终格式的确定。它是一个纯函数,也就是说,只要传入参数相同,返回计算得到的下一个 state 就一定相同。没有特殊情况、没有副作用,没有 API 请求、没有变量修改,单纯执行计算。 reducer对传入的action进行判断,然后返回一个通过判断后的state,这就是reducer的全部职责
Reducer 函数最重要的特征是,它是一个纯函数。也就是说,只要是同样的输入,必定得到同样的输出。
纯函数是函数式编程的概念,必须遵守以下一些约束。
不得改写参数
不能调用系统 I/O 的API
不能调用Date.now()或者Math.random()等不纯的方法,因为每次会得到不一样的结果
(1)只要是同样的输入,必定得到一个同样的输出。
(2)千万不能更改之前的状态,必须要返回一个新状态
(3)里面不能有不纯的操作,例如Math.random(),new Date(),io操作
redux中间件的原理是什么?如何理解?
通常情况下,action只是一个对象,不能包含异步操作,这导致了很多创建action的逻辑只能写在组件中,代码量较多也不便于复用,同时对该部分代码测试的时候也比较困难,组件的业务逻辑也不清晰,使用中间件了之后,可以通过actionCreator异步编写action,这样代码就会拆分到actionCreator中,可维护性大大提高,可以方便于测试、复用,同时actionCreator还集成了异步操作中不同的action派发机制,减少编码过程中的代码量。
redux中间件就是指action到达store之间。store.dispatch(action)方法将action派发给了store
并且我们的action只能是一个对象,需求的时候,就需要考虑到一些异步逻辑放在哪里去实现?
采用中间件之后,action就可以是一个函数的形式了,并且会把函数式的action转成对象,在传递给store.dispatch一个action之后,到达reducer之前,进行一些额外的操作,就需要用到middleware。你可以利用 Redux middleware 来进行日志记录、创建崩溃报告、调用异步接口或者路由等等。
换言之,redux的中间件都是对store.dispatch()的增强
redux有哪些中间件?
做异步的操作在action里面去实现!需要安装redux中间件 redux-thunk redux-saga (基于配置文件 es7 async await) redux-promise
redux-thunk原理
Redux-thunk是一个Redux中间件,位于 Action与 Strore中间,简单的说,他就是对store.dispatch进行了一次升级,他通过改造store.dispatch,可以使得store.dispatch可以接受函数作为参数。
可以看出来redux-thunk最重要的思想,就是可以接受一个返回函数的action creator。如果这个action creator 返回的是一个函数,就执行它,如果不是,就按照原来的next(action)执行。 正因为这个action creator可以返回一个函数,那么就可以在这个函数中执行一些异步的操作。
React项目相关
项目中遇到哪些问题?如何解决?
用于轮播图组件的远程数据已经请求回来了,并且也已经实例化完毕了。发现navbar能滑,但是滑不过去的现象
原因:因为我们在ComponentDidMount中请求数据,这个操作是异步操作,不会阻止后续代码,所以我们一边执行请求数据的代码一边实例化,数据还在请求中的时候,实例化已经开始执行,等数据回来的时候实例化已经早就结束了。
方法一:放入在componentDidUpdate钩子函数里面
问题:当页面中的无关数据改变的时候同样会走这个钩子函数,那就会导致它重新执行。
所以我们给Swiper的实例化起一个别名
在componentDidUpdate这个函数中if语句判断它是否存在,如果不存在再去实例化,存在的话就不需要再去执行实例化操作。
//在这个钩子函数里面 就可以获取到因数据改变导致的虚拟dom重新渲染完成的真实dom结构了 componentDidUpdate(){ if(!this.swiper)this.initSwiper() //数据可能还在请求当中,但是这个实例化操作已经完毕了。等后续数据来了,实例化提前早就结束了。 }方法二:会发现上面的方案会多写一个钩子函数,可不可以在componentDidmount里面实现此功能呢?
将实例化操作写在获取数据的回调函数里
componentDidMount(){ //请求数据 更改navs this.props.getNavs(()=>{ this.initSwiper() }) }在store/home/actionCreators文件中让getNavs接收这个回调函数,在数据请求结束后执行callback回调函数。
import {Get} from "../../modules/axios-utils" import {GET_NAV_INFO} from "./const" export default { getNavs(callback){ return dispatch=>{ Get({ url:"/sk/navs" }).then(res=>{ let navs = res.data.data.object_list dispatch({ type: GET_NAV_INFO,navs}) callback && callback() }) } } }我们跳转页面的时候它会多次请求数据,所以我们需要在componentDidMount这个钩子函数中判断redux里面navs是否存在,存在就不需要再发送请求了,这时候从别的页面再跳转回首页就不会重复请求数据,但是数据划不动,所以我们需要在函数中再次执行Swiper初始化操作。
let {navs} = this.props; if(navs){ this.initSwiper() return false; }reducer中的深拷贝与浅拷贝
我们进行改变状态操作时,componentWillReceiveProps()这个函数没有被触发,说明视图没有检测到状态的改变。这时候我们来到reducer.js这个文件中,查看执行添加操作的函数,我们通过
let new_state = {...prevState}这句代码将prevState解构出来赋值给new_stat,,我们往new_state中的todos数组push一个新内容,并没有返回新的状态,那是因为当我们对new_state这个数组进行操作的时候,会影响到之前的prevState中的todos,因为todos是个引用类型,它和new_state中的todos指向同一块内存空间,所以当我们执行push操作的时候相当于更改了之前的状态。在redux中规定,千万不能对之前的状态进行任何操作,必须要返回一个新状态,内部以此为依据来判断到底有没有新的状态产生,根据之前状态与新状态的地址比较,更改之后的地址跟之前的地址是同一个的话,就说明没有产生新状态。所以即便我们操作的是new_state中的todos,实际上我们更改的也是prevState中的todos,所以不会有新的状态产生。
所以我们要使用深拷贝,拷贝出来一份一样的数组,并且这个新数组的引用地址和之前的引用地址完全不同。
ew_state.todos = new_state.todos.slice();深拷贝浅拷贝有什么区别?
1. 浅拷贝: 将原对象或原数组的引用直接赋给新对象,新数组,新对象/数组只是原对象的一个引用。
2. 深拷贝: 创建一个新的对象和数组,将原对象的各项属性的“值”(数组的所有元素)拷贝过来,是“值”而不是“引用”
react,jquey,vue是否可以共存在一个项目中?
可以存在,互不干扰。
<div></div> <div id="react"></div> <div id="vue"></div>ReactDOM.render(,document.getElementById(“react”));
new Vue({el:"#vue",router,store});服务端渲染SSR
什么是服务端渲染? 核心在于方便seo优化
后端先调用数据库,获得数据之后,将数据和页面元素进行拼装,组合成完整的html页面,再直接返回给浏览器,以便用户浏览。 例如:http://www.cnblogs.com/cate/design
什么是客户端渲染? 分担到客户端
数据由浏览器通过ajax动态获得,再通过js将数据填充到dom元素上最终展示到网页中,这样的过程就叫做客户端渲染。 例如:https://m.maizuo.com/v5/#/films/nowPlaying
服务端渲染与客户端渲染区别?
客户端渲染不利于SEO搜索引擎优化
服务端渲染是可以被爬虫抓取到的,客户端异步渲染是很难被爬虫抓取到的
服务端渲染对SEO友好,经过服务端渲染的页面,在网络传输的时候,传输的是一个真实的页面,所以爬虫就会对这个页面中的关键数据进行分析、收录。
服务端渲染缺点就是 对服务器压力比较大
客户端渲染减轻了服务器端的渲染压力,能够实现前后端分离开发
客户端渲染缺点就是 对SEO相当的不友好主流UI开发框架
你都使用过哪些UI开发框架(类库)?
VUE:Vant、Element、Mint UI、iView
React:Ant Design
移动端:Ant Design Mobile
PC端:Bootstrap、Ant Design
混合开发:MUI
有没有用一些脚手架的搭建?,脚手架有什么作用?
Vue-cli create-react-app wepy-cli
包含基础的依赖库,只需要 npm install就可以安装,快速搭建项目。
Mint-UI用到哪些模块,怎么用,在vue里怎么注册,引入
引入:
(1)完整引入
(2)按需引入

移动端
移动端开发
编写移动端时的四个步骤
(1)添加mate声明
在编辑器中输入mate:vp按tab键
<meta charset="UTF-8"> <meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">(2)写移动端必须用怪异盒模型,box-sizing:border-box;
使用弹性盒布局:display:flex;
(3)根据设计图设置单位,rem相对于根元素。
Iphone5:宽度640px;
html:font-size:31.25vw;
31.25vw=100px=1rem;
Iphone6:宽度750px;
html:font-size:26.67vw;
26.675vw=100px=1rem;
(4)编写一屏页面:
html,body{height:100%;}
移动设备单位
ppi/dpi (每英寸所拥有像素点的数量)
dpr > 设备像素比 (物理像素、逻辑像素)
逻辑像素就是css设置的像素
物理像素就是设备显示的像素
dpr == 物理像素 / 逻辑像素
dpr 一般考虑的值 > 2或者3
如果移动端设计图的宽度为750/640 > 选择的dpr为2
如果移动端设计图的宽度为1080 > 选择的dpr为3
例:
如果设计图为640px
dpr为2
如果从ps中量出元素宽度为300px;
在css里面设置的为 300px / dpr(2) == 150px;
页面布局有哪几种方式
**固定布局:**以像素作为页面的基本单位,不管设备屏幕及浏览器宽度,只设计一套尺寸;
**可切换的固定布局:**同样以像素作为页面单位,参考主流设备尺寸,设计几套不同宽度的布局。通过识别的屏幕尺寸或浏览器宽度,选择最合适的那套宽度布局;
**弹性布局(百分比布局):**以百分比作为页面的基本单位,可以适应一定范围内所有尺寸的设备屏幕及浏览器宽度,并能完美利用有效空间展现最佳效果;
**混合布局:**同弹性布局类似,可以适应一定范围内所有尺寸的设备屏幕及浏览器宽度,并能完美利用有效空间展现最佳效果;只是混合像素、和百分比两种单位作为页面单位。
**布局响应:**对页面进行响应式的设计实现,需要对相同内容进行不同宽度的布局设计,有两种方式:pc优先(从pc端开始向下设计);
移动优先(从移动端向上设计);无论基于那种模式的设计,要兼容所有设备,布局响应时不可避免地需要对模块布局做一些变化(发生布局改变的临界点称之为断点)
####什么是响应式设计?响应式设计的基本原理是什么
响应式是指根据不同设备浏览器分辨率或尺寸来展示不同页面结构、行为、表现的设计方式。
响应式设计的基本原理是通过媒体查询检测不同的设备屏幕尺寸做处理。
####说说对于移动端页面部局你都知道哪几种布局方案,并说明其各自特点及实现的方法
移动端布局常用的有100%布局,等比缩放布局,或是混合布局。
百分比布局也称作流式布局,一般适用一些流式页面的布局;
等比缩放布局可以利用rem或vw等方式来实现;
rem
rem和em的区别
rem(font size of the root element)是指相对于根元素 (html)的字体大小的单位
em是相对于父元素
rem方法的封装
document.documentElement.style.fontSize = document.documentElement.clientWidth / 3.75 + "px" window.onresize = function(){ document.documentElement.style.fontSize = document.documentElement.clientWidth / 3.75 + "px" }px和em的区别
px和em都是长度单位,区别是:px的值是固定的,指定是多少就是多少,计算比较容易。em得值不是固定的,并且em会继承父级元素的字体大小。
浏览器的默认字体高都是16px。所以未经调整的浏览器都符合: 1em=16px。那么12px=0.75em, 10px=0.625em。
弹性盒
####Flex弹性盒布局
Flex容器:采用 Flex 布局的元素的父元素;
Flex项目:采用 Flex 布局的元素的父元素的子元素;
容器默认存在两根轴:水平的主轴(main axis)和垂直的交叉轴(cross axis)。主轴的开始位置(与边框的交叉点)叫做main start,结束位置叫做main end;交叉轴的开始位置叫做cross start,结束位置叫做cross end。
项目默认沿主轴排列。单个项目占据的主轴空间叫做main size,占据的交叉轴空间叫做cross size。
不兼容所有浏览器,不适合写pc端,主要用于移动端。
弹性元素只能影响子元素,无法影响所有的后代元素。
弹性布局属于css3只兼容高版本浏览器
Flex垂直居中
flex:弹性盒
justify-content 项目在主轴上的对齐方式
参数:center 居中/space-between 两端对齐/space-around均分对齐
align-items 项目在交叉轴上的对齐方式
参数:center 居中
flex-direction 决定主轴的方向
row X轴/column Y轴
参考:Flex 布局教程:语法篇
http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html
布局方式
媒体查询如何实现?
媒体查询 @media screen and (max-width:300px){ …} 最大宽度
Bootstrap12栅格系统
Row col col-md-4 col-md-4 col-md-4
在Bootstrap框架当中,每列基本被分为12格,要使用栅格系统需要在该
<div>标签当中设置class="container",而对于每一行则用<div class="row">包着,内部由于有12格,因此可以结合具体情况分配比例,举例:<div class="container"> <!-- 定义栅格系统 --> <div class="row"> <!-- 定义一行 --> <div class="col-md-4"> <!-- 定义了三列,每列占3格 --> <img src="timg.jpg" width="300px"> </div> <div class="col-md-4"> <img src="timg.jpg" width="300px"> </div> <div class="col-md-4"> <img src="timg.jpg" width="300px"> </div> </div> <div class="row"> <!-- 定义了4列,分别占6、3、2、1格 --> <div class="col-md-6"> <img src="timg.jpg" width="300px"> </div> <div class="col-md-3"> <img src="timg.jpg" width="300px"> </div> <div class="col-md-2"> <img src="timg.jpg" width="300px"> </div> <div class="col-md-1"> <img src="timg.jpg" width="300px"> </div> </div> </div>Grid网格布局
网格布局(Grid)是最强大的 CSS 布局方案。
它将网页划分成一个个网格,可以任意组合不同的网格,做出各种各样的布局。以前,只能通过复杂的 CSS 框架达到的效果,现在浏览器内置了。

参考:CSS Grid 网格布局教程
http://www.ruanyifeng.com/blog/2019/03/grid-layout-tutorial.html
趋势:flex和grid使布局更简单
https://www.cnblogs.com/hsprout/p/8277322.htm
混合开发&小程序
混合开发模式
我们知道混合开发的模式现在主要分为两种,H5工程师利用某些工具如DCLOUD产品、codorva+phonegap等等来开发一个外嵌native壳子的混合app。
还有就是应用比较广泛的,有native开发工程师和H5工程师一起写作开发的应用,在native的webview里嵌入H5页面,当然只是部分界面这么做,这样做的好处就是效率高,开发成本和维护成本都比较低,较为轻量,但是有一个问题不可避免的会出现,就是js和native的交互。进入域后根据不同的情况显示不同的页面(PC/MOBILE)
很多情况下,一个应用会有PC和移动端两个版本,而这两个版本因为差别大,内容多,所以不能用响应式开发但是单独开发,而域名只有一个,用户进入域后直接返回对应设备的应用,做法主要有两种: 1. 前端判断并跳转 进入一个应用或者一个空白页面后,通过navigator.userAgent来判断用户访问的设备类型,进行跳转 2. 后端判断并响应对应的应用 用户地址栏进入域的时候,服务器能接收到请求头上包含的userAgent信息,判断之后返回对应小程序开发的形式
目前小程序开发主要有三种形式:原生、wepy、mpvue,其中wepy是腾讯的开源项目;mpvue是美团开源的一个开发小程序的框架,全称mini
program vue(基于vue.js的小程序),vue开发者使用了这个框架后,开发小程序的效率将得到很大的提升。wepy与mpvue如何选择?

参考:使用mpvue开发微信小程序——原生微信小程序、mpvue、wepy对比
https://blog.csdn.net/fabulous1111/article/details/84289044
微信小程序里面各个部分是干什么的
这些文件可以分为四类,分别是以js、wxml、wxss和json结尾的文件。
以js结尾的文件,一般情况下是负责功能的,比如,点击一个按钮,按钮就会变颜色。
以wxml为后缀的文件,一般情况下负责布局,比如,把按钮放在屏幕的上方,还是放在屏幕的正中间。
以wxss为后缀的文件,是负责渲染的功能,比如,按钮是什么颜色,是正方形还是圆形。
以json为后缀的文件,这里可以暂时理解为更改屏幕上方的标题的,也就是说明页面的顶部标题。
参考:微信小程序里面各个部分是干什么的
https://www.jianshu.com/p/3863f8b75336
你经常浏览哪些技术网站
- 酷壳
- 掘金
- stackoverflow(国外)
- 思否SegmentFault
前端开发的优化问题
性能优化
简述一下你对web性能优化的方案?
1、尽量减少 HTTP 请求
2、使用浏览器缓存
3、使用压缩组件
4、图片、JS的预载入
5、将脚本放在底部
6、将样式文件放在页面顶部
7、使用外部的JS和CS
如何优化项目
(1) 减少http请求次数:CSS Sprites(雪碧图), JS、CSS源码压缩、图片大小控制合适;网页Gzip,CDN托管,data缓存 ,图片服务器。
(2) 前端模板 JS+数据,减少由于HTML标签导致的带宽浪费,前端用变量保存AJAX请求结果,每次操作本地变量,不用请求,减少请求次数
(3) 用innerHTML代替DOM操作,减少DOM操作次数,优化javascript性能。
(4) 当需要设置的样式很多时设置className而不是直接操作style。
(5) 少用全局变量、缓存DOM节点查找的结果。减少IO读取操作。
(6) 避免使用CSS Expression(css表达式)又称Dynamic properties(动态属性)。
(7) 图片预加载,将样式表放在顶部,将脚本放在底部 加上时间戳。
(8) 避免在页面的主体布局中使用table,table要等其中的内容完全下载之后才会显示出来,显示比div+css布局慢。
雅虎14条性能优化原则
1. 尽可能的减少 HTTP 的请求数 content 2. 使用 CDN(Content Delivery Network) server 3. 添加 Expires 头(或者 Cache-control ) server 4. Gzip 组件 server 5. 将 CSS 样式放在页面的上方 css 6. 将脚本移动到底部(包括内联的) javascript 7. 避免使用 CSS 中的 Expressions css 8. 将 JavaScript 和 CSS 独立成外部文件 javascript css 9. 减少 DNS 查询 content 10. 压缩 JavaScript 和 CSS (包括内联的) javascript css 11. 避免重定向 server 12. 移除重复的脚本 javascript 13. 配置实体标签(ETags) css 14. 使 AJAX 缓存 你如何对网站的文件和资源进行优化?
- 文件合并:目的是减少http请求
- 文件压缩:目的是直接减少文件下载的体积
- 使用CDN(内容分发网络来托管资源)
- 缓存的使用:并且多个域名来提供缓存
- GZIP压缩JS和CSS文件
参考:你如何对网站的文件和资源进行优化?
https://blog.csdn.net/xujie_0311/article/details/42418797
SEO优化
一个单页应用程序SEO友好吗?
单页应用实际是把视图(View)渲染从Server交给浏览器,Server只提供JSON格式数据,视图和内容都是通过本地JavaScript来组织和渲染。而搜索搜索引擎抓取的内容,需要有完整的HTML和内容,单页应用架构的站点,并不能很好的支持搜索。
参考:单页应用SEO浅谈
http://www.chinaz.com/web/2014/1209/376090.shtml
一个单页应用程序SEO友好吗?
https://baijiahao.baidu.com/s?id=1605476561507275196&wfr=spider&for=pc
网页自身SEO优化(如何让网站被搜索引擎搜索到)
- 页面主题优化
实事求是的写下自己网站的名字,网站的名字要合理,最好包含网站的主要内容。
- 页面头部优化
页面头部指的是代码中部分,具体一点就是中的“Description(描述)”和“Keywords(关键字)”两部分
- 超链接优化
(1)采用纯文本链接,少用,最好是别用Flash动画设置链接,因为搜索引擎无法识别Flash上的文字.
(2)按规范书写超链接,这个title属性,它既可以起到提示访客的作用,也可以让搜索引擎知道它要去哪里.
(3)最好别使用图片热点链接,理由和第一点差不多。
- 图片优化(alt属性,title属性)
网络爬虫对title和alt友好,网络优化时必须写。
-
为网站制作一个“网站地图”
-
PageRank(pr值,友情链接)
-
静态页面与动态页面
-
避免大“体积”的页面
-
最重要的一点!合理的代码结构
框架性能优化
react性能优化
-
使用生产环境production版本的react.js
-
重写shouldComponentUpdate来避免不必要的dom操作,一旦返回true ,组件更新操作;返回false,就不会更新,节省性能。
-
使用key来帮助React识别列表中所有子组件的最小变化
-
PureComponent 纯组件 ,自带shouldComponentUpdate,可以对props进行浅比较,不会比较对象这些东西。 发现后面的props与前面的props一样,就不会进行render了。
class Test extends React.PureComponent{ <div><Test a={10}/></div> constructor(props){ super(props); } render(){ return <div>hello...{this.props.a}</div> } }
VUE性能优化
像VUE这种单页面应用,如果没有应用懒加载,运用webpack打包后的文件将会异常的大,造成进入首页时,需要加载的内容过多,时间过长,会出现长时间的白屏,即使做了loading也是不利于用户体验,而运用懒加载则可以将页面进行划分,需要的时候加载页面,可以有效的分担首页所承担的加载压力,减少首页加载用时,简单说就是:进入首页不用一次加载过多资源造成的用时时长。
鸣谢:https://hanxueqing.github.io/Web-Front-end-Interview-Q-A/
-
智能推荐
Android Studio一个项目引入另一个项目作为依赖Libary(富文本编辑器版本)_android 如果引用一个项目作为lib-程序员宅基地
文章浏览阅读975次。文章目录一、源码,详见地址二、实践篇1、导入依赖项目2、配置添加依赖项目3、把依赖项目设置为兼容的library(错误解决)声明:本教程不收取任何费用,欢迎转载,尊重作者劳动成果,不得用于商业用途,侵权必究!!!大概是在去年12月份写了一篇这样的文章,最近参照来看发现看的有些费劲,因为当时用的Markdown编辑器所以编辑和排版都相对比较麻烦不好观看,所以决定重新写一..._android 如果引用一个项目作为lib
Quartz_quartz毕设参考文献-程序员宅基地
文章浏览阅读97次。这里是修真院后端小课堂,每篇分享文从八个方面深度解析后端知识/技能,本篇分享的是:【Quartz】【修真院Java小课堂】任务调度-Quartz开场语:大家好,我是IT修真院北京分院第32期的学员廖友,一枚正直纯洁善良的Java程序员,今天给大家分享一下,修真院官网Java任务十中的知识点——任务调度-Quartz一、背景介绍:1、任务调度概念任务调度是指基于给定时间点,给定时间间..._quartz毕设参考文献
linux系统下无法用SecureCRT及putty工具远程登录系统方法-程序员宅基地
文章浏览阅读191次。一般情况下,我们安装好了linux系统,都希望通过工具能够进行远程管理,这样可以方便许多,但是有时候却无法通过这些工具连接,主要是由于我们没有安装远程的服务,如ssh及telnet这2个服务!命令方式安装:sudo apt-get install ssh 安装telnet方法:sudo apt-get install telnet Telnet..._linux不能通过工具访问远程
The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone. You mu-程序员宅基地
文章浏览阅读174次。在做springboot连接数据库时:方案1:在项目代码-数据库连接URL后,加上 (注意大小写必须一致)?serverTimezone=UTC方案2:在mysql中设置时区,默认为SYSTEM set global time_zone='+8:00'错误原因:使用了Mysql Connector/J 6.x以上的版本,然set global time_zone='+8:0...
解决经过zuul网关,文件上传失败问题_zuul网关 file not allowed to upload!-程序员宅基地
文章浏览阅读4.1k次。在Spring Cloud Zuul中,Zuul本身有几个核心过滤器源码如下:其中 ServletDetectionFilter优先级最高 为-3 ,所以最先执行,这个核心过滤器只是做了一个判断当前请求是通过Spring的DispatcherServlet处理运行,还是通过ZuulServlet来处理运行,并把结果放回上下文中。一般般情况下,发送到API网关的外部请求都会被Spring..._zuul网关 file not allowed to upload!
使用Python 进行串口通信过程记录——PySerial安装_phthon 脱机安装串口模块-程序员宅基地
文章浏览阅读3.6k次。该文章的前提是已安装Python(楼主安装版本为64bit的3.7版本),使用PySerial模块,该模块安装前可先安装pip(推荐安装,还可以用于安装其他模块,使用方便)一、安装PIP1、下载安装包,地址为:https://pypi.org/project/pip/#files2、下载完成后将其解压到python目录下:随后,cmd进入该目录下,并进入到pip-19.0..._phthon 脱机安装串口模块
随便推点
在python moviepy中编辑后的视频没有声音的解决方案_moviepy 音频不加载-程序员宅基地
文章浏览阅读3.2k次。据说是mac下才会发生,其实不是的,和播放器的音频解码方式有关,大家在调用write_videofile函数时加上参数audio_codec="aac",改变下声道编码即可_moviepy 音频不加载
无法打开文件MSVCRTD.lib VS2017_无法打开文件“msvcrtd.lib”-程序员宅基地
文章浏览阅读1.9k次。_无法打开文件“msvcrtd.lib”
完善动态so加载库-程序员宅基地
文章浏览阅读96次。以上代码包括实验代码,都能在这里找到SillyBoy作者:Pika链接:https://juejin.cn/post/7227029203656867899来源:稀土掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。_动态so
OPENSSL之计算SHA1散列值_基于openssl实现sha1算法哈希运算-程序员宅基地
文章浏览阅读1k次。今天遇到了sha的相关函数的应用,随手收集了点有用的资料,以后在看。。。。。。。HA1散列函数是很常用的散列函数,它产生160bit(20字节)长度的散列值。今天,我就来介绍利用OpenSSL现成的API来计算数据的SHA1散列值。先来看OpenSSL的相关API声明: #include unsigned char *SHA_基于openssl实现sha1算法哈希运算
【Unity 24】Unity中的向量点乘和叉乘的应用_3d游戏中向量叉乘-程序员宅基地
文章浏览阅读4.6k次,点赞10次,收藏32次。PS:本系列笔记将会记录我此次在北京学习Unity开发的总体过程,方便后期写总结,笔记为日更。笔记内容均为 自己理解,不保证每个都对点乘求角度,叉乘求方向比如敌人再附近,点乘可以求出玩家面朝方向和敌人方向的夹角,叉乘可以得出左转还是右转更好的转向敌人Part 1 点乘:数学上的 点乘为 a * b = |a| * |b| * cos(Θ) Unity中的点乘也是如此 点乘结果为 ..._3d游戏中向量叉乘
poj 3468 A Simple Problem with Integers(线段树)(第二部分 成段更新,区间求和)-程序员宅基地
文章浏览阅读262次。题目链接:http://poj.org/problem?id=3468题目大意:给出n个数的数值Q是对区间a,b的求和C是对区间a,b内的所有数都加上c思路:成段更新,需要用到延迟标记(或者说懒惰标记),简单来说就是每次更新的时候不要更新到底,用延迟标记使得更新延迟到下次需要更新or询问到的时候#include#include#include#include#inc