后缀数组 + Hash + 二分 or Hash + 二分 + 双指针 求 LCP ---- 2017icpc 青岛 J Suffix (假题!!)_j.suffix 二分-程序员宅基地
题目大意:
就是给你n个串每个串取一个后缀,要求把串拼起来要求字典序最小!!
s u m _ l e n g t h _ o f _ n ≤ 5 e 5 sum\_length\_of\_n\leq 5e5 sum_length_of_n≤5e5
MY Slove :
-
首先我们知道对于最后一个串肯定是取最小后缀的
-
那么我们可以把最后一个串的结果接到倒数第二个串上面在求一次最小后缀就可以得倒数第二个串的结果,依次以此类推就好了。
-
但是这样我们算算复杂度:假如我们每次都把答案拼到下一个串上面求个后缀数组那么我们假设最坏就是 a + z z z z z . . . . . . a+zzzzz...... a+zzzzz......取均摊的复杂度就是 n \sqrt n n那么就是每个串长度是 n \sqrt n n,有 n \sqrt n n个串,答案最坏的情况是全部取,那么你每次都拼接的话,最后一个串要动 n \sqrt n n次,倒数第二个要动 n − 1 \sqrt n-1 n−1次…那么最坏就是 O ( n ( 1 + n ) / 2 + n ( ∑ i = 1 n i ∗ l o g ( i ∗ n ) ) ) O(\sqrt n(1+\sqrt n)/2+ \sqrt n(\sum_{i=1}^{\sqrt n}i*log(i*\sqrt n))) O(n(1+n)/2+n(∑i=1ni∗log(i∗n))) 铁定T飞了(但是实践证明 O ( n 2 ) O(n^2) O(n2)都可以过的假题)
-
我们考虑优化:
-
我们想想后面那一大坨的问题就是:后缀数组求解拼接后字符串的时间复杂度是很大的 n ( ∑ i = 1 n i ∗ l o g ( i ∗ n ) ) \sqrt n(\sum_{i=1}^{\sqrt n}i*log(i*\sqrt n)) n(∑i=1ni∗log(i∗n)) 那么我们可不可以考虑只对原来的字符求后缀数组,去虚假拼接求呢?
-
我们看看后缀排序后的后缀长什么样子:
eg:aba
a
aba
b -
通过观察我们知道要拼接的答案肯定是以最小后缀为前缀的后缀的其中一个这个贪心看肯定是这样的
我们看看这个数据就知道了
3
ababac
b
drl
ans:ababacbdrl
那么我们可以顺着这个串的所有后缀比下去,但是这个串所有后缀字符个数是 O ( n 2 ) O(n^2) O(n2)的?肯定不是这样比呀!!
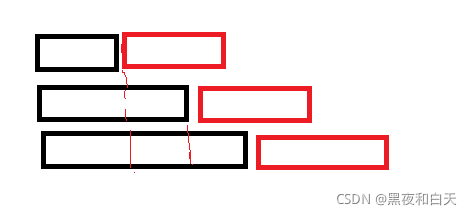
因为我们知道前面是一样的,实际上我们每次只比较后个串多出来的那部分,那部分的长度是 O ( n ) O(n) O(n)
- 但是如果前面都一样怎么办?我们就要看红色重叠的部分了,但是如果暴力比较红色部分复杂度还是将不下来!!因为最坏就是红色的长度了那么有 n n n个后缀就是 O ( n 2 ) O(n^2) O(n2)
- 因为后面是答案串我们可以对答案串进行hash,然后二分那个第一个hash值第一个hash值不一样的位置进行判断字典序!
- 我们在动态维护答案串的hash,不能正序hash,因为字符是头插入的,那么我们逆着hash
AC code
细节巨多,局难写,写了一晚上
#include <bits/stdc++.h>
#define mid ((l + r) >> 1)
#define Lson rt << 1, l , mid
#define Rson rt << 1|1, mid + 1, r
#define ms(a,al) memset(a,al,sizeof(a))
#define log2(a) log(a)/log(2)
#define _for(i,a,b) for( int i = (a); i < (b); ++i)
#define _rep(i,a,b) for( int i = (a); i <= (b); ++i)
#define for_(i,a,b) for( int i = (a); i >= (b); -- i)
#define rep_(i,a,b) for( int i = (a); i > (b); -- i)
#define lowbit(x) ((-x) & x)
#define IOS std::ios::sync_with_stdio(0); cin.tie(0); cout.tie(0)
#define INF 0x3f3f3f3f
#define LLF 0x3f3f3f3f3f3f3f3f
#define hash Hash
#define next Next
#define pb push_back
#define f first
#define s second
using namespace std;
const int N = 1e6 + 10, mod = 1e9 + 9;
const int maxn = 5e5+10;
// const long double eps = 1e-5;
const int base = 233;
typedef long long ll;
typedef unsigned long long ull;
typedef pair<int,int> PII;
typedef pair<ll,ll> PLL;
typedef pair<double,double> PDD;
template<typename T> void read(T &x) {
x = 0;char ch = getchar();ll f = 1;
while(!isdigit(ch)){
if(ch == '-')f*=-1;ch=getchar();}
while(isdigit(ch)){
x = x*10+ch-48;ch=getchar();}x*=f;
}
template<typename T, typename... Args> void read(T &first, Args& ... args) {
read(first);
read(args...);
}
//......................这里是后缀数组
// sa[l]排序是lth的后缀的开始位置
//ra[l]是起点是l的后缀排名多少
//lcp(suf(i),suf(j)) = min(H(ra[i] + 1),....H(ra[j]));
//区间最小值倍增求
// H(i)是rk[i]和rk[i-1]的lcp
//这个板子下标是从0开始,rank从1开始
//传进来的是int数组但是不能有0
struct SA {
int sa[maxn], ra[maxn], height[maxn];
int t1[maxn], t2[maxn], c[maxn];
int shift[maxn];
inline void init(const string &s) {
for(int i = 0; i < s.size(); ++ i) shift[i] = (int)(s[i]-'a'+1);
build(shift,s.size(),30);
}
void build(int *str, int n, int m) {
//字符数组,长度,字符种类
str[n] = 0;
n++;
int i, j, p, *x = t1, *y = t2;
for (i = 0; i < m; i++) c[i] = 0;//排序的桶
for (i = 0; i < n; i++) c[x[i] = str[i]]++;
for (i = 1; i < m; i++) c[i] += c[i - 1];
for (i = n - 1; i >= 0; i--) sa[--c[x[i]]] = i;
for (j = 1; j <= n; j <<= 1) {
//所有长度为1,2,4,8....的子串的排序
//长度够长的话就是所有的后缀排序
p = 0;
for (i = n - j; i < n; i++) y[p++] = i;
for (i = 0; i < n; i++) if (sa[i] >= j) y[p++] = sa[i] - j;
for (i = 0; i < m; i++) c[i] = 0;
for (i = 0; i < n; i++) c[x[y[i]]]++;
for (i = 1; i < m; i++) c[i] += c[i - 1];
for (i = n - 1; i >= 0; i--) sa[--c[x[y[i]]]] = y[i];
swap(x, y);
p = 1;
x[sa[0]] = 0;
for (i = 1; i < n; i++)
x[sa[i]] = (y[sa[i - 1]] == y[sa[i]] && y[sa[i - 1] + j] == y[sa[i] + j]) ? p - 1 : p++;
if (p >= n) break;
m = p;
}
n--;
for (int i = 0; i <= n; i++) ra[sa[i]] = i;
for (int i = 0, j = 0, k = 0; i <= n; i++) {
if (k) k--;
j = sa[ra[i] - 1];
while (str[i + k] == str[j + k]) k++;
height[ra[i]] = k;
}
st_init(height, n);
}
int lg[maxn], table[23][maxn];
void st_init(int *arr, int n) {
if (!lg[0]) {
lg[0] = -1;
for (int i = 1; i < maxn; i++)
lg[i] = lg[i / 2] + 1;
}
for (int i = 1; i <= n; ++i)
table[0][i] = arr[i];
for (int i = 1; i <= lg[n]; ++i)
for (int j = 1; j <= n; ++j)
if (j + (1 << i) - 1 <= n)
table[i][j] = min(table[i - 1][j], table[i - 1][j + (1 << (i - 1))]);
//从j开始长度是2^i次方得st表
}
int lcp(int l, int r) {
l = ra[l], r = ra[r];
if (l > r) swap(l, r);
++l;
int t = lg[r - l + 1];//区间长度
return min(table[t][l], table[t][r - (1 << t) + 1]);
}
} sa;
//............................... 这里是Hash
string s[maxn], ans;
ull pw[maxn];
vector<ull> Hash;
inline void insert(char a) {
ull last = Hash.empty() ? 0ull : Hash.back();
last = last * base + a - 'a' + 1;
Hash.push_back(last);
}
inline ull gethash(int l,int r) {
if(r < l) return 0;
return (ull)Hash[r]-(l - 1 < 0 ? 0ull : Hash[l-1])*pw[r-l+1];
}
//........................
inline void update(int i, int anspos) {
// 更新答案
for(int m = s[i].size()-ans.size()-1; m >= anspos; -- m) insert(s[i][m]), ans += s[i][m];
}
int main() {
IOS;
pw[0] = 1;
for(int i = 1; i < maxn; ++ i) pw[i] = pw[i-1] * base;
int _;
cin >> _;
while (_--) {
Hash.clear();
int n;
cin >> n;
for(int i = 1; i <= n; ++ i) cin >> s[i];
sa.init(s[n]);
ans = s[n].substr(sa.sa[1]); // 先找到最后一个串的最小后缀
for(int i = ans.size()-1; i >= 0; -- i) insert(ans[i]); // 逆着Hash
reverse(ans.begin(),ans.end()); // 将答案串反过来
for(int i = n - 1; i >= 1; -- i) {
// 枚举第i个串
if(s[i].size()==1) {
insert(s[i][0]); ans += s[i]; continue;}// 特判长度为1的串
// 对这个串建立后缀数组
sa.init(s[i]);
// 把答案串拼到新串后面
for(int j = (int)ans.size()-1; j >= 0; -- j) s[i] += ans[j];
int anspos = sa.sa[1]; //anspos = 答案后缀的开头位置
for(int k = 2; k <= s[i].size()-ans.size(); ++ k) {
// 枚举这个串的每个后缀
if(sa.lcp(sa.sa[k],sa.sa[k-1]) != s[i].size()-ans.size()-anspos) {
// 如果不是以前面后缀为前缀那就结束了后面答案不会更优
update(i,anspos);
break;
}
int eps = s[i].size() - ans.size() - sa.sa[k-1];
int is = 0;
// 只比较突出的部分
int j;
for(j = 0; j+anspos+eps < s[i].size() && j+sa.sa[k]+eps<s[i].size()-ans.size(); ++ j)
if(s[i][j+anspos+eps] < s[i][j+sa.sa[k]+eps]) {
// 如果在黑
is = 1;
update(i,anspos);
break;
} else if(s[i][j+anspos+eps] > s[i][j+sa.sa[k]+eps]) {
anspos = sa.sa[k];
if(k == s[i].size()-ans.size()) update(i,anspos);//如果到了最后一个串了可以直接更新了
is = 2;
break;
} else if(j+anspos+eps == s[i].size()-1) {
is = 1;
update(i,anspos);
break;
}
if(is == 1) break; // is == 1 表示可以确定答案了提前退出就好了
if(is == 2) continue;
//...................................二分红色部分
int l = 0, r = s[i].size()-(j+anspos+eps)-1;
//注意我是把答案串拼到了新串后面
int tmp = j+anspos+eps-(s[i].size()-ans.size());
while(l < r) {
//注意Hash是逆序存的,要从末尾开始看
if(gethash(Hash.size()-1-tmp-mid,Hash.size()-1-tmp)==gethash(Hash.size()-1-mid,Hash.size()-1)) l = mid+1;
else r = mid;
}
if(s[i][j+anspos+eps+l]>s[i][j+sa.sa[k]+eps+l]) anspos = sa.sa[k];
if(k == s[i].size()-ans.size()) update(i,anspos);//如果到了最后一个串了可以直接更新了
}
}
for(int i = ans.size()-1;~i;i--) cout << ans[i];
cout << endl;
}
return 0;
}
Solution 2
贪心从后往前看,最后一个串一定选择字典序最小的后缀,然后把这个后缀拼接到第n - 1个串,重复这个步骤就行了。
具体实现:
从后往前遍历,每次找当前串的最小后缀,这个可以对于当前下标和当前最小后缀下标二分+hash找到lcp,看lcp后一个位置的大小,然后更新最小后缀的下标(这里是关键)。然后把最小后缀拼接到前一个串即可。
理论时间复杂度跟后缀数组差不多,但后缀数组常数和编码量更大。
AC code
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
const ull base=131;
#define mod
#define maxn 605000
ull p[maxn];ull h[maxn];
ull get_hash(ull l,ull mid)
{
return h[l]-h[l-mid]*p[mid];
}
string str[maxn];char ans[maxn];
int len[maxn];
ull check(ull x,ull y)
{
ull l=1,r=y;
while(l<=r)
{
ull mid=(l+r)/2;
//cout<<"l="<<l<<" r="<<r<<" mid="<<mid<<'\n';
if(get_hash(x,mid)==get_hash(y,mid))
{
l=mid+1;
}
else r=mid-1;
}
if(l==y+1) return 0;
return ans[x-r]<ans[y-r];
}
int main()
{
ull T;
p[0]=1;
for(ull i=1;i<=maxn-100;i++)
{
p[i]=p[i-1]*base;
}
cin>>T;
while(T--)
{
ull n;
cin>>n;
for(ull i=1;i<=n;i++)
{
cin>>str[i];
len[i]=str[i].size();
}
ull id=0;
for(ull i=n;i>=1;i--)
{
//cout<<"i="<<i<<" id="<<id<<'\n';
ans[++id]=str[i][len[i]-1];
h[id]=h[id-1]*base+str[i][len[i]-1];
ull to=1;
ull t=id;
for(int j=(int)(len[i])-2;j>=0;j--)
{
//cout<<"i="<<i<<" j="<<j<<'\n';
ans[id+to]=str[i][j];
h[id+to]=h[id+to-1]*base+str[i][j];
if(check(id+to,t))
{
t=id+to;
}
to++;
}
id=t;
}
for(ull i=id;i>=1;i--) cout<<ans[i];
cout<<'\n';
}
}
/*
3
3
bbb
aaa
ccc
*/
智能推荐
解决win10/win8/8.1 64位操作系统MT65xx preloader线刷驱动无法安装_mt65驱动-程序员宅基地
文章浏览阅读1.3w次。转载自 http://www.miui.com/thread-2003672-1-1.html 当手机在刷错包或者误修改删除系统文件后会出现无法开机或者是移动定制(联通合约机)版想刷标准版,这时就会用到线刷,首先就是安装线刷驱动。 在XP和win7上线刷是比较方便的,用那个驱动自动安装版,直接就可以安装好,完成线刷。不过现在也有好多机友换成了win8/8.1系统,再使用这个_mt65驱动
SonarQube简介及客户端集成_sonar的客户端区别-程序员宅基地
文章浏览阅读1k次。SonarQube是一个代码质量管理平台,可以扫描监测代码并给出质量评价及修改建议,通过插件机制支持25+中开发语言,可以很容易与gradle\maven\jenkins等工具进行集成,是非常流行的代码质量管控平台。通CheckStyle、findbugs等工具定位不同,SonarQube定位于平台,有完善的管理机制及强大的管理页面,并通过插件支持checkstyle及findbugs等既有的流..._sonar的客户端区别
元学习系列(六):神经图灵机详细分析_神经图灵机方法改进-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏27次。神经图灵机是LSTM、GRU的改进版本,本质上依然包含一个外部记忆结构、可对记忆进行读写操作,主要针对读写操作进行了改进,或者说提出了一种新的读写操作思路。神经图灵机之所以叫这个名字是因为它通过深度学习模型模拟了图灵机,但是我觉得如果先去介绍图灵机的概念,就会搞得很混乱,所以这里主要从神经图灵机改进了LSTM的哪些方面入手进行讲解,同时,由于模型的结构比较复杂,为了让思路更清晰,这次也会分开几..._神经图灵机方法改进
【机器学习】机器学习模型迭代方法(Python)-程序员宅基地
文章浏览阅读2.8k次。一、模型迭代方法机器学习模型在实际应用的场景,通常要根据新增的数据下进行模型的迭代,常见的模型迭代方法有以下几种:1、全量数据重新训练一个模型,直接合并历史训练数据与新增的数据,模型直接离线学习全量数据,学习得到一个全新的模型。优缺点:这也是实际最为常见的模型迭代方式,通常模型效果也是最好的,但这样模型迭代比较耗时,资源耗费比较多,实时性较差,特别是在大数据场景更为困难;2、模型融合的方法,将旧模..._模型迭代
base64图片打成Zip包上传,以及服务端解压的简单实现_base64可以装换zip吗-程序员宅基地
文章浏览阅读2.3k次。1、前言上传图片一般采用异步上传的方式,但是异步上传带来不好的地方,就如果图片有改变或者删除,图片服务器端就会造成浪费。所以有时候就会和参数同步提交。笔者喜欢base64图片一起上传,但是图片过多时就会出现数据丢失等异常。因为tomcat的post请求默认是2M的长度限制。2、解决办法有两种:① 修改tomcat的servel.xml的配置文件,设置 maxPostSize=..._base64可以装换zip吗
Opencv自然场景文本识别系统(源码&教程)_opencv自然场景实时识别文字-程序员宅基地
文章浏览阅读1k次,点赞17次,收藏22次。Opencv自然场景文本识别系统(源码&教程)_opencv自然场景实时识别文字
随便推点
ESXi 快速复制虚拟机脚本_exsi6.7快速克隆centos-程序员宅基地
文章浏览阅读1.3k次。拷贝虚拟机文件时间比较长,因为虚拟机 flat 文件很大,所以要等。脚本完成后,以复制虚拟机文件夹。将以下脚本内容写入文件。_exsi6.7快速克隆centos
好友推荐—基于关系的java和spark代码实现_本关任务:使用 spark core 知识完成 " 好友推荐 " 的程序。-程序员宅基地
文章浏览阅读2k次。本文主要实现基于二度好友的推荐。数学公式参考于:http://blog.csdn.net/qq_14950717/article/details/52197565测试数据为自己随手画的关系图把图片整理成文本信息如下:a b c d e f yb c a f gc a b dd c a e h q re f h d af e a b gg h f bh e g i di j m n ..._本关任务:使用 spark core 知识完成 " 好友推荐 " 的程序。
南京大学-高级程序设计复习总结_南京大学高级程序设计-程序员宅基地
文章浏览阅读367次。南京大学高级程序设计期末复习总结,c++面向对象编程_南京大学高级程序设计
4.朴素贝叶斯分类器实现-matlab_朴素贝叶斯 matlab训练和测试输出-程序员宅基地
文章浏览阅读3.1k次,点赞2次,收藏12次。实现朴素贝叶斯分类器,并且根据李航《统计机器学习》第四章提供的数据训练与测试,结果与书中一致分别实现了朴素贝叶斯以及带有laplace平滑的朴素贝叶斯%书中例题实现朴素贝叶斯%特征1的取值集合A1=[1;2;3];%特征2的取值集合A2=[4;5;6];%S M LAValues={A1;A2};%Y的取值集合YValue=[-1;1];%数据集和T=[ 1,4,-1;..._朴素贝叶斯 matlab训练和测试输出
Markdown 文本换行_markdowntext 换行-程序员宅基地
文章浏览阅读1.6k次。Markdown 文本换行_markdowntext 换行
错误:0xC0000022 在运行 Microsoft Windows 非核心版本的计算机上,运行”slui.exe 0x2a 0xC0000022″以显示错误文本_错误: 0xc0000022 在运行 microsoft windows 非核心版本的计算机上,运行-程序员宅基地
文章浏览阅读6.7w次,点赞2次,收藏37次。win10 2016长期服务版激活错误解决方法:打开“注册表编辑器”;(Windows + R然后输入Regedit)修改SkipRearm的值为1:(在HKEY_LOCAL_MACHINE–》SOFTWARE–》Microsoft–》Windows NT–》CurrentVersion–》SoftwareProtectionPlatform里面,将SkipRearm的值修改为1)重..._错误: 0xc0000022 在运行 microsoft windows 非核心版本的计算机上,运行“slui.ex