大数据:聚类算法深度解析-程序员宅基地
文章目录
深度解析大数据聚类分析
大数据聚类分析是数据科学领域中的关键技术之一,它能够帮助我们从庞大而复杂的数据集中提取有意义的信息和模式。在这篇博文中,我们将深入探讨大数据聚类分析的概念、方法、应用和挑战。
1. 聚类分析的基本概念
1.1 什么是聚类分析?
聚类分析是一种将数据分成具有相似特征的组的技术。其目标是使组内的数据点相似度最大化,而组间的相似度最小化。这有助于发现数据中的隐藏结构和模式,为进一步的分析和决策提供基础。
在聚类分析中,我们将数据点划分为不同的簇,使得同一簇内的数据点相互之间更为相似。这种相似性是通过一定的距离度量来定义的,常见的包括欧氏距离、曼哈顿距离等。而组间的相似度最小化,则意味着不同簇之间的差异性较大。
聚类的过程类似于将一堆未标记的数据分成若干组,使得同一组内的数据点更加相似,例如下面分类结果。
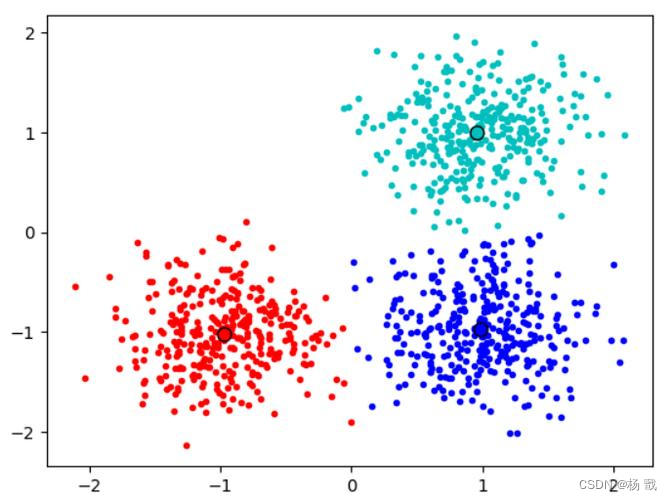
这有助于我们在没有先验标签的情况下发现数据中的潜在结构,为后续的分析和应用提供了基础。
# 伪代码:K均值算法实现聚类分析
from sklearn.cluster import KMeans
import numpy as np
# 假设有一组数据 points,其中每一行代表一个数据点的特征
points = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]])
# 假设我们要将数据分成两个簇
kmeans = KMeans(n_clusters=2)
kmeans.fit(points)
# 获取每个数据点所属的簇
labels = kmeans.labels_
# 输出结果
print("数据点所属簇:", labels)
在上述代码中,我们使用了K均值算法对一组数据进行聚类分析。该算法将数据点划分为两个簇,输出每个数据点所属的簇。这就是聚类分析的基本原理之一。
聚类分析的应用非常广泛,从市场细分到图像分割,都离不开聚类的帮助。通过深入理解聚类分析的概念和方法,我们能够更好地应用它来解决实际问题。
1.2 大数据背景下的挑战
在大数据背景下,数据量巨大、多样性高、实时性要求等因素给聚类分析带来了巨大的挑战。传统的聚类算法可能无法有效处理这些庞大的数据集,因此需要采用分布式计算和更高效的算法来应对这些挑战。
1.2.1 数据量巨大
大数据的特点之一是其庞大的数据量,传统的单机计算无法处理如此大规模的数据。对于聚类分析而言,这就要求我们使用分布式计算框架,如Apache Spark,以同时处理并行计算,提高处理效率。

1.2.2 多样性高
大数据往往涉及多种类型的数据,包括结构化数据、半结构化数据和非结构化数据。传统聚类算法可能只适用于特定类型的数据,因此需要采用更灵活的算法或者组合多种算法来处理这种多样性。
1.2.3 实时性要求
在大数据背景下,很多应用场景要求对数据进行实时的聚类分析。例如,在在线广告投放中,需要实时了解用户的兴趣以提供更精准的广告。因此,聚类算法不仅需要高效处理大规模数据,还需要具备实时性能。
为了解决这些挑战,大数据聚类分析引入了诸如流式计算、近似算法和增量式计算等技术。下面是一个简单的流式聚类的示例:
# 伪代码:流式聚类示例
from sklearn.cluster import MiniBatchKMeans
import numpy as np
# 初始化MiniBatchKMeans模型
mbk = MiniBatchKMeans(n_clusters=3, random_state=42)
# 模拟流式数据输入
streaming_data = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]])
# 逐步更新聚类模型
for i in range(len(streaming_data)):
mbk.partial_fit([streaming_data[i]])
# 获取聚类结果
labels = mbk.labels_
print("数据点所属簇:", labels)
在上述示例中,我们使用了MiniBatchKMeans模型来模拟流式数据输入,并逐步更新聚类模型。这种方式使得算法能够在数据流不断到来的情况下进行实时聚类。
通过克服大数据背景下的这些挑战,我们可以更好地应用聚类分析在复杂和庞大的数据集中发现有价值的模式和信息。
2. 大数据聚类算法
2.1 K均值算法
K均值是最常用的聚类算法之一,它通过将数据点分配到K个簇,使得簇内的数据点尽量相似。该算法迭代进行簇分配和簇中心更新,直至收敛。在大数据背景下,可以使用分布式计算框架如Apache Spark来加速计算过程。
K均值算法步骤:
- 初始化: 随机选择K个数据点作为初始簇中心。
- 分配: 将每个数据点分配到距离最近的簇中心。
- 更新: 重新计算每个簇的中心,即取簇中所有数据点的平均值。
- 重复: 重复步骤2和步骤3,直至簇中心不再发生明显变化或达到预定迭代次数。
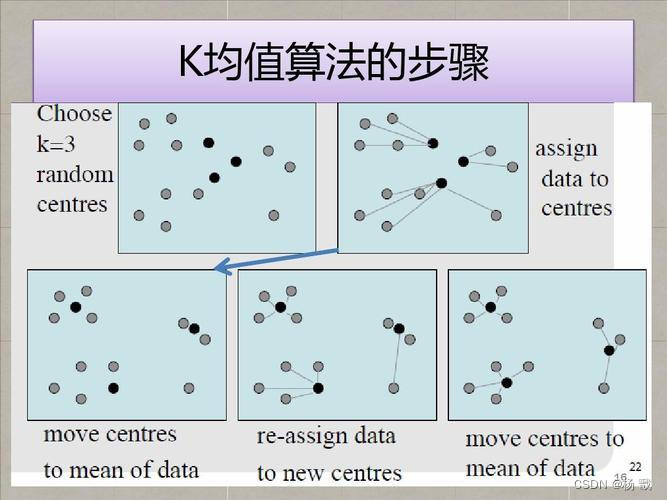
K均值算法的优点之一是其简单性和易于理解。然而,在大数据背景下,传统的K均值算法可能面临计算效率低下的问题。因此,我们可以借助分布式计算框架来提高其处理大规模数据的能力。
# 伪代码:K均值算法在Apache Spark中的实现
from pyspark.ml.clustering import KMeans
# 假设data是一个大数据集的DataFrame
kme智能推荐
18个顶级人工智能平台-程序员宅基地
文章浏览阅读1w次,点赞2次,收藏27次。来源:机器人小妹 很多时候企业拥有重复,乏味且困难的工作流程,这些流程往往会减慢生产速度并增加运营成本。为了降低生产成本,企业别无选择,只能自动化某些功能以降低生产成本。 通过数字化..._人工智能平台
electron热加载_electron-reloader-程序员宅基地
文章浏览阅读2.2k次。热加载能够在每次保存修改的代码后自动刷新 electron 应用界面,而不必每次去手动操作重新运行,这极大的提升了开发效率。安装 electron 热加载插件热加载虽然很方便,但是不是每个 electron 项目必须的,所以想要舒服的开发 electron 就只能给 electron 项目单独的安装热加载插件[electron-reloader]:// 在项目的根目录下安装 electron-reloader,国内建议使用 cnpm 代替 npmnpm install electron-relo._electron-reloader
android 11.0 去掉recovery模式UI页面的选项_android recovery 删除 部分菜单-程序员宅基地
文章浏览阅读942次。在11.0 进行定制化开发,会根据需要去掉recovery模式的一些选项 就是在device.cpp去掉一些选项就可以了。_android recovery 删除 部分菜单
mnn linux编译_mnn 编译linux-程序员宅基地
文章浏览阅读3.7k次。https://www.yuque.com/mnn/cn/cvrt_linux_mac基础依赖这些依赖是无关编译选项的基础编译依赖• cmake(3.10 以上)• protobuf (3.0 以上)• 指protobuf库以及protobuf编译器。版本号使用 protoc --version 打印出来。• 在某些Linux发行版上这两个包是分开发布的,需要手动安装• Ubuntu需要分别安装 libprotobuf-dev 以及 protobuf-compiler 两个包•..._mnn 编译linux
利用CSS3制作淡入淡出动画效果_css3入场效果淡入淡出-程序员宅基地
文章浏览阅读1.8k次。CSS3新增动画属性“@-webkit-keyframes”,从字面就可以看出其含义——关键帧,这与Flash中的含义一致。利用CSS3制作动画效果其原理与Flash一样,我们需要定义关键帧处的状态效果,由CSS3来驱动产生动画效果。下面讲解一下如何利用CSS3制作淡入淡出的动画效果。具体实例可参考刚进入本站时的淡入效果。1. 定义动画,名称为fadeIn@-webkit-keyf_css3入场效果淡入淡出
计算机软件又必须包括什么,计算机系统应包括硬件和软件两个子系统,硬件和软件又必须依次分别包括______?...-程序员宅基地
文章浏览阅读2.8k次。计算机系统应包括硬件和软件两个子系统,硬件和软件又必须依次分别包括中央处理器和系统软件。按人的要求接收和存储信息,自动进行数据处理和计算,并输出结果信息的机器系统。计算机是脑力的延伸和扩充,是近代科学的重大成就之一。计算机系统由硬件(子)系统和软件(子)系统组成。前者是借助电、磁、光、机械等原理构成的各种物理部件的有机组合,是系统赖以工作的实体。后者是各种程序和文件,用于指挥全系统按指定的要求进行..._计算机系统包括硬件系统和软件系统 软件又必须包括
随便推点
进程调度(一)——FIFO算法_进程调度fifo算法代码-程序员宅基地
文章浏览阅读7.9k次,点赞3次,收藏22次。一 定义这是最早出现的置换算法。该算法总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面予以淘汰。该算法实现简单,只需把一个进程已调入内存的页面,按先后次序链接成一个队列,并设置一个指针,称为替换指针,使它总是指向最老的页面。但该算法与进程实际运行的规律不相适应,因为在进程中,有些页面经常被访问,比如,含有全局变量、常用函数、例程等的页面,FIFO 算法并不能保证这些页面不被淘汰。这里,我_进程调度fifo算法代码
mysql rownum写法_mysql应用之类似oracle rownum写法-程序员宅基地
文章浏览阅读133次。rownum是oracle才有的写法,rownum在oracle中可以用于取第一条数据,或者批量写数据时限定批量写的数量等mysql取第一条数据写法SELECT * FROM t order by id LIMIT 1;oracle取第一条数据写法SELECT * FROM t where rownum =1 order by id;ok,上面是mysql和oracle取第一条数据的写法对比,不过..._mysql 替换@rownum的写法
eclipse安装教程_ecjelm-程序员宅基地
文章浏览阅读790次,点赞3次,收藏4次。官网下载下载链接:http://www.eclipse.org/downloads/点击Download下载完成后双击运行我选择第2个,看自己需要(我选择企业级应用,如果只是单纯学习java选第一个就行)进入下一步后选择jre和安装路径修改jvm/jre的时候也可以选择本地的(点后面的文件夹进去),但是我们没有11版本的,所以还是用他的吧选择接受安装中安装过程中如果有其他界面弹出就点accept就行..._ecjelm
Linux常用网络命令_ifconfig 删除vlan-程序员宅基地
文章浏览阅读245次。原文链接:https://linux.cn/article-7801-1.htmlifconfigping <IP地址>:发送ICMP echo消息到某个主机traceroute <IP地址>:用于跟踪IP包的路由路由:netstat -r: 打印路由表route add :添加静态路由路径routed:控制动态路由的BSD守护程序。运行RIP路由协议gat..._ifconfig 删除vlan
redux_redux redis-程序员宅基地
文章浏览阅读224次。reduxredux里要求把数据都放在公共的存储区域叫store里面,组件中尽量少放数据,假如绿色的组件要给很多灰色的组件传值,绿色的组件只需要改变store里面对应的数据就行了,接着灰色的组件会自动感知到store里的数据发生了改变,store只要有变化,灰色的组件就会自动从store里重新取数据,这样绿色组件的数据就很方便的传到其它灰色组件里了。redux就是把公用的数据放在公共的区域去存..._redux redis
linux 解压zip大文件(解决乱码问题)_linux 7za解压中文乱码-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏6次。unzip版本不支持4G以上的压缩包所以要使用p7zip:Linux一个高压缩率软件wget http://sourceforge.net/projects/p7zip/files/p7zip/9.20.1/p7zip_9.20.1_src_all.tar.bz2tar jxvf p7zip_9.20.1_src_all.tar.bz2cd p7zip_9.20.1make && make install 如果安装失败,看一下报错是不是因为没有下载gcc 和 gcc ++(p7_linux 7za解压中文乱码