单链表创建的LinkList L与LinkList *L区分的问题-程序员宅基地
在学习线性表的存储结构中,很多人在学习线性表的链式存储结构即单链表时,有人会注意函数传参LinkList L与LinkList *L的问题,如下
下面展示一些 内联代码片。
#include<stdio.h>
#include<stdlib.h>
typedef int Status;
typedef struct Node
{
ElemType data; //数据域
struct Node* Next; //指针域(指向节点的指针)
}Node;
typedef struct Node* LinkList;;
Status GetElem(LinkList L, int i, ElemType* e) //获取单链表L中的第i个元素,用e返回其值。
Status ListInsert(LinkList *L, int i, ElemType e)//向单链表第i个位置插入新元素e。
有人会发现为什么获取单链表的元素形参输入是LinkList L,而向单链表插入或者删除等操作要用到LinkList *L。
我从以下几个方面逐一递进解释:
1、对于LinkList L: L是指向定义的Node结构体的指针,因为我们前面用typedef struct Node* LinkList,就是LinkList相当于struct Node*,这里的*是跟Node的后面,LinkList是一个指向该结构体的的指针的别名,故此可以用->运算符来访问结构体成员,即L->data,而(*L)就是个Node型的结构体了,可以用点运算符访问该结构体成员,即(*L).elem;
而对于LinkList *L:L是指向定义的Node结构体指针的指针,也就是说L的内容是指向定义的Node结构体指针的地址,(*L)是指向Node结构体的指针,注意,这里的(*L)要理解好。
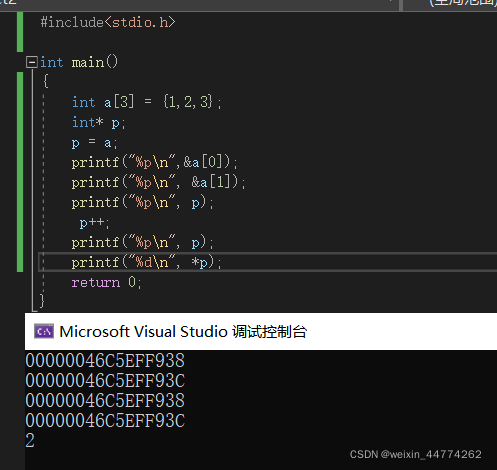
2、从上面的定义我们知道LinkList L的L是一级指针,而后面的LinkList *L是二级指针,对于一级指针我们都知道,可以通过改变的指针的值从而改变量,如
#include<stdio.h>
int main()
{
int a = 100;
int b = 200;
int* p;
p = &a;
printf("%d,",*p);
p = &b;
printf("%d\n",*p);
return 0;
}
执行结果打印出来是100,200,指针p第一次取的是整型变量a的地址,此时*p的值为100,第二次取的是整型变量b的地址,p的值为100,可以看出通过改变指针p指向的地址,对应p的值也就不同,这就是一级指针的用法。
而一级指针可以运用在线性表的顺序存储结构或者数组中,因为其逻辑上具有线性关系的数据按照前后的次序全部存储在一整块连续的内存空间中,之间不存在空隙。注意这段话:使用顺序存储结构存储的数据,第一个元素所在的地址就是这块存储空间的首地址。通过首地址,可以轻松访问到存储的所有的数据,只要首地址不丢(即我们能找到首地址)数据永远都能找着,这就是为什么我们可以使用一级指针而不用二级指针,以下代码1,2说明:
代码1
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#define MAXSIZE 20
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int Status;
typedef int ElemType;
typedef struct
{
ElemType data[MAXSIZE];
int length;
}SqList;
/******************向线性表第i个位置插入新元素e****************/
Status ListInsert(SqList* L, int i, ElemType e)
{
int k;
if (L->length == MAXSIZE)
{
return ERROR;
}
if (i<1 || i> L->length + 1)
{
return ERROR;
}
if (i <= L->length)
{
for (k = L->length - 1; k >= i - 1; k--)
{
L->data[k + 1] = L->data[k];
}
}
L->data[i - 1] = e;
L->length++;
return OK;
}
上面程序我们定义一个结构体指针*L,通过->运算符来访问结构体成员,而我们向线性表第i个位置插入的时候,后面的元素对应的地址会向后移,但是我们知道线性表的顺序存储结构或者数组中,其逻辑上具有线性关系的数据按照前后的次序全部存储在一整块连续的内存空间中,之间不存在空隙,故我们不需要指针内容发生改变,可以直接==L->data[k + 1] = L->data[k]==直接往后移。如果不理解可以看下图:
代码2
下面展示一些 内联代码片。
#include<stdio.h>
#include<stdlib.h>
#define ERROR 0
#define OK 1
typedef int ElemType;
typedef int Status;
typedef struct Node
{
ElemType data; //数据域
struct Node* Next; //指针域(指向节点的指针)
}Node;
typedef struct Node* LinkList;
Status GetElem(LinkList L, int i, ElemType* e)
{
int j;
LinkList p;
j = 1;
p = L->Next;
while (p && j < i)
{
p = p->Next;
j++;
}
if( !p|| j>i)
{
return ERROR;
}
*e = p->data;
return OK;
}
代码2是单链表的取值操作,对于单链表,其链式存储结构中,除了要存储数据元素信息外,还要存储它的后继元素的存储地址(指针)。这就是表明它的内存地址不连续。但是对于取值操作,我们只需定义一个指向定义的Node结构体的指针L。因为是取值而没对链表的内容进行操作,所以我们可以通过一级指针指向结构体,结构体内部存有指向下个结点的指针域,进而帮助我们找到其值。到了这里我们就说明了LinkList L的意义了。
3、对于 LinkList *L,L是二级指针,前面我们说L的内容是指向定义的Node结构体指针的地址,故此(*L)是指向Node结构体的指针的地址。例如寻找或者修改数组的内容我们可以通过修改一级指针的值,因为内存地址是连续的,那么我们只要找到首地址就能把这个数组表达出来。而对于单链表内存地址不连续的,我们在对单链表进行增删等操作的时候,指针的内容会发生变化的,故此我们需要二级指针来改变一级指针的内容,如下代码3:
代码3
Status ListInsert(LinkList *L, int i, ElemType e)
{
int j;
LinkList p, s;
p = *L;
j = 1;
while (p && j < i)
{
p = p->Next;
j++;
}
if (!p || j > i)
{
return ERROR;
}
s = (LinkList)malloc(sizeof(Node));
s->data = e;
s->Next = p->Next;
p->Next = s;
return OK;
}
代码3定义一个二级指针LinkList *L,其中我们发现单链表插入的两条主要程序:s->Next = p->Next; p->Next = s;其中新结点s->Next是原来的p->Next,而原来的p->Next是新的结点s,此时原来p的内容已经发生了改变,即指向第i个位置的指针内容发生了变化,故此我们使用二级指针来改变p,第二次注意(*L)是指向Node结构体的指针,通过使用二级指针单链表在函数调用后就会有一个全新的内容,总的来说有点像递归,但是使用二级指针更是方便。在如下代码4也可以看出:
代码4
void InitList(LinkList *L)
{
*L = (LinkList)malloc(sizeof(Node));
(*L)->next = NULL; //由于->的优先级高于*,故此得加括号(*L)
}
代码4可看出,初始化空链表,函数调用完毕后,L会指向一个空的链表,即会改变指针的内容,故要用*L到了。到此我们就说明了LinkList *L的意义了。
*总结一句话:如果能理解的话,就记得但凡要修改L的值的操作都要使用 L,如果不修改L的值,用Linklist L 。
智能推荐
ASP.NET Core微服务实战系列-程序员宅基地
文章浏览阅读510次。ASP.NET Core微服务实战系列 原文:ASP.NET Core微服务实战系列 希望给你3-5分钟的碎片化学习,可能是坐地铁、等公交,积少成多,水滴石穿,码字辛苦,如果你吃了蛋觉得味道不错,希望点个赞,谢谢关注。前言 这里记录的是个人奋斗和成长的地方,该篇只是一个系列目录和构想,并没有完全真正开弓。之所以有这个题目,是..._微服务 asp.net core
Hyperion高光谱数据预处理_pie软件 hyperion数据-程序员宅基地
文章浏览阅读1.6w次,点赞20次,收藏87次。Hyperion高光谱数据——影像获取+预处理最近在用Hyperion做植被分类,利用高光谱的优势,应该能得到比Landsat精度更高的结果。按照以下几项对数据准备工作总结:Hyperion数据的免费下载影像预处理的必要性利用ENVI补丁Workshop进行处理——对出现的bug进行修改最小噪声变换(MNF)改进锯齿现象Firstly–Download the Image主要在美国地质勘探_pie软件 hyperion数据
vs2010 语法错误: 缺少“;”(在标识符“PVOID64”的前面)-程序员宅基地
文章浏览阅读1.6k次。网上有很多答案,看了让人不知道在说什么,一个行之有效的解决方案是在“stdafx.h”中添加#define POINTER_64 __ptr64。已验证有效。缺点是每生成一个新项目,都要添加一次。_vs2010 语法错误: 缺少“;”(在标识符“pvoid64”的前面)
leetcode sql题目_leedcode sql-程序员宅基地
文章浏览阅读392次。1 # Write your MySQL query statement belowselect max(salary) as SecondHighestSalary from Employee where salary not in (select max(salary) from Employee )Write a SQL query to get the second hig_leedcode sql
嵌入式软件工程师笔试面试指南-ARM体系与架构_嵌入式工程师笔试面试指南-程序员宅基地
文章浏览阅读1.1w次,点赞74次,收藏324次。嵌入式软件笔试,嵌入式软件面试,程序员简历书写,Linux驱动工程师笔试,Linux驱动工程师面试,BSP工程师笔试,BSP工程师面试,应届生秋招,应届生春招,C/C++笔试题目,C/C++面试题目,C/C++程序员,BSP工程师_嵌入式工程师笔试面试指南
威佐夫博弈 hdu1527 取石子游戏_博弈 分割石子-程序员宅基地
文章浏览阅读800次。传送门:点击打开链接题意:轮流取石子。1.在一堆中取任意个数.2.在两堆中取相同个数。最后取完的人胜利,问先手是否必赢思路:威佐夫博弈博弈,满足黄金分割,且每个数字只会出现一次。具体求法见代码#include#include#include#include#include#include#include#include#include#include#include_博弈 分割石子
随便推点
java检查手机号是否被注册_【java】如何开发一个检测手机号注册过哪些网站的应用?...-程序员宅基地
文章浏览阅读707次。问题描述使用python或其它语言开发一个检测手机号注册过哪些网站的应用问题出现的环境背景及自己尝试过哪些方法在登陆一个很久没使用的网站时,原注册的手机号已弃用无法找回密码。所以希望有这么一款应用,能够在我输入手机号时列出注册过的网站,方便更换注册账号用的手机号目前的思路是,使用爬虫爬到网站中忘记密码的页面,然后输入手机号。这么做有几个问题:爬取忘记密码页面的通用规则该用什么思路去写关于验证码,我..._java 导入验证手机号是否注册某个网站
Android 插件化-程序员宅基地
文章浏览阅读3.3k次。1.插件化插件可以理解为免安装的Apk,而支持插件的app称为宿主。在Android系统中,应用是以Apk的形式存在的,应用都需要安装才能使用。实际上Android系统安装应用的方式相当简单,就是把应用Apk拷贝到系统不同的目录下,然后把so解压出来而已。常见的应用安装目录有:/system/app:系统应用/system/priv-app:系统应用/data/app:用户应用一个Apk会包含如下几个部分:classes.dex:Java代码字节码res:资源文件._android 插件化
最新阿里内推 Java 后端面试题_索引会不会使插入、删除作效率变低,怎么解决?-程序员宅基地
文章浏览阅读80次。【这里想说,因为自己也走了很多弯路过来的,所以才下定决心整理,收集过程虽不易,但想到能帮助到一部分想成为Java架构师或者是想职业提升P6-P7-P8的人,心里也是甜的!有需要的伙伴请点㊦方】↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓。数据库隔离级别,每层级别分别用什么方法实现,三级封锁协议,共享锁排它锁,mvcc 多版本并发控制协议,间隙锁。数据库表怎么设计的?_索引会不会使插入、删除作效率变低,怎么解决?
Redis实现延迟队列方法介绍-程序员宅基地
文章浏览阅读3.3k次。其中,延迟队列是 Redis 的一个重要应用场景,它被广泛应用于异步任务的调度、消息队列的实现以及秒杀、抢购等高并发场景的处理。在实现延迟队列时,我们可以使用 Redis 的有序集合来保存待执行的任务,其中元素的分值表示任务的执行时间,元素的值表示任务的内容。使用 ZADD 命令将任务添加到有序集合中,将任务的执行时间作为元素的分值,将任务的内容作为元素的值。使用 ZADD 命令将任务添加到有序集合中,将任务的执行时间作为元素的分值,将任务的内容作为元素的值。一、Redis 有序集合实现延迟队列。
Python入门实战:Python的文件操作-程序员宅基地
文章浏览阅读701次,点赞23次,收藏7次。1.背景介绍Python是一种强大的编程语言,它具有简洁的语法和易于学习。Python的文件操作是一种常用的编程技术,可以让程序员更方便地读取和写入文件。在本文中,我们将深入探讨Python的文件操作,涵盖了核心概念、算法原理、具体操作步骤、数学模型公式、代码实例以及未来发展趋势。1.1 Python的文件操作背景Python的文件操作是一种基本的编程技能,它允许程序员在程序中读取和写...
机器学习模型对比_机器学习的模型比较-程序员宅基地
文章浏览阅读1k次。1.SVM和LR(逻辑回归)1.1 相同点都是线性分类器。本质上都是求一个最佳分类超平面。都是监督学习算法。 都是判别模型。通过决策函数,判别输入特征之间的差别来进行分类。常见的判别模型有:KNN、SVM、LR。 常见的生成模型有:朴素贝叶斯,隐马尔可夫模型。1.2 不同点损失函数不同,LR的损失函数为交叉熵;svm的损失函数自带正则化,而LR需要在损失函数的基础上加上正则化。 两个模型对数据和参数的敏感程度不同。SVM算法中仅支持向量起作用,大部分样本的增减对模型无影响;而L_机器学习的模型比较