正确捕捉异常Exception和正确的日志打印_不是runtime的异常 能打印出来吗-程序员宅基地
Java异常控制机制又被称为“违例控制机制”。
捕获程序错误最理想的时机是在编译阶段,这样可以彻底避免错误的代码运行。但并非所有的错误都能在编译期间侦测到,有些问题必须在运行期间解决。
错误在运行期间发生时,我们可能不知道具体应该怎样解决,但我们清楚此时不能不管不顾地继续执行下去。此时应该做的事情是:
• 暂停程序的运行
• 指出何时、何地发生了什么样的错误
• 可能的话应处理此错误并恢复程序的执行
Java异常控制机制的作用流程:
1. 异常产生
(1).首先程序引擎需要能够获知异常的产生。Java中预置了一系列基本的异常条件,如数组下标越界、空指针、被零除等等,这些异常是由JVM自动产生的(也被称为运行时异常,见后);另一部分异常则是由Java代码(可能是JDK的代码或开发人员自己编写的代码)产生的(也被称为checked异常,见后)。
(2).异常产生即是异常对象的实例化,该对象的类型通常就说明了异常条件的类型,实例化的异常对象中还会包含对异常条件的补充说明(message),以及异常发生时的线程调用栈信息(stacktrace)。
(3).在这个环节中,JAVA完成了对错误的描述,包括错误发生的时间、错误的类型(即异常对象的Class)、对错误的描述(message)和错误发生的位置(stacktrace)。
2. 异常抛出
(1).异常抛出是JAVA程序流中的一种特殊流程,当异常产生后,JVM会停止继续执行后面的代码,并将异常对象抛出。抛出的异常对象会进入调用栈的上一层,如果异常对象没有被捕获,它会沿着调用栈的顺序逐层向上抛出,直至调用栈为空,此时该线程的运行也就彻底终止了。
(1).异常的抛出解决了当前作用域可能不具备处理异常所需的信息的问题,将异常对象在调用栈中逐级向上传递,直至有能力处理异常的作用域将其捕获。
3. 异常捕获
在异常对象逐级向上抛出的过程中,如果调用栈中某一层有捕获该类型异常的逻辑,
该异常对象便会被捕捉,异常被捕获后JVM会终止抛出异常对象的过程。
4.异常处理
当异常对象被捕获后,JVM会执行捕获后的处理逻辑(处理逻辑是由程序员编写的)。
当处理逻辑执行完成后,JVM会继续执行捕获了异常的作用域中接下来的代码
(除非异常处理逻辑中将该异常继续抛出,或异常处理逻辑中产生了新的异常)。
Exception与Error
前文所述的Java异常控制机制实际上并不仅对“异常”起作用。除了我们所说的异常(Exception)能够被产生、抛出和捕捉之外,还有另一种类型“错误(Error)”。
Java中,Throwable是所有可以被抛出并捕获的类的父类。Throwable有两大子类,分别是Exception和Error。
Java官方并没有给出Error和Exception的严格定义,而是将Error描述为“应用程序不应尝试捕捉处理的严重问题”,Exception则是“应用程序应该尝试捕捉处理的问题”。
我们从几个例子看一下:
• NoClassDefFoundError:JVM的ClassLoader在尝试加载某个类,但该类在Classpath中并不存在时会产生的错误。例如a.jar依赖b.jar中的某个类,如果我们使用编译完成的a.jar时并没有引入b.jar,编译器并不会发现问题(因为a.jar已经完成了编译,需要编译的代码中只使用了a.jar中的api,并没有直接使用b.jar),但在运行时JVM找不到b.jar中被a所依赖的类,便会发生错误。
• UnsupportedClassVersionError:当JVM尝试加载一个class但发现该class的版本并不被支持时产生的错误。例如我们使用JDK1.8开发并编译一个类,但在JDK1.7的环境中运行时,便会发生此错误
• OutOfMemoryError:当JVM内存不足,无法为一个对象分配内存时发生的错误,例如堆区内存溢出、Perm区内存溢出等。
• StackOverFlowError:当程序的递归调用过深,导致线程调用栈溢出时发生的错误。
• NoSuchFieldError/NoSuchMethodError:当JVM试图访问某个成员属性或某个方法时,发现目标不存在。一般都是由于class信息在运行时被改变导致的,多见于使用反射时。
通过上面的例子能够看出,Error一般都与程序本身的直接关系不大,更多是由于环境导致的问题。而且Error发生后通常程序都没有再继续执行下去的可能性,所以Java官方将其定义为“应用程序不应尝试捕捉处理的严重问题”。
Throw 和 throws 的区别
位置不同
- throws 用在函数上,后面跟的是异常类,可以跟多个;而 throw 用在函数内,后面跟的是异常对象。
功能不同: - throws 用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先的处理方式;throw 抛出具体的问题对象,执行到 throw,功能就已经结束了,跳转到调用者,并将具体的问题对象抛给调用者。也就是说 throw 语句独立存在时,下面不要定义其他语句,因为执行不到。
- throws 表示出现异常的一种可能性,并不一定会发生这些异常;throw 则是抛出了异常,执行 throw 则一定抛出了某种异常对象。
- 两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
Exception的分类
Java将Exception分为两类,checked异常和unchecked异常,也被称为非运行时异常和运行时(runtime)异常。
RuntimeException是Exception的一个子类,RuntimeException的子类都属于unchecked异常(也就是运行时异常),其他所有的Exception都是checked异常(也就是非运行时异常)。
这两种异常的区别从字面上即可理解,checked代表“必须被check”,而unchecked代表“无须被check”:
Java要求checked异常必须被在代码编写阶段就调用者了解,unchecked异常则不用。如果一个方法中有可能产生checked异常,则Java编译器会要求该方法定义中必须加入throws定义,明确说明该方法可能会抛出某类checked异常。如下图:
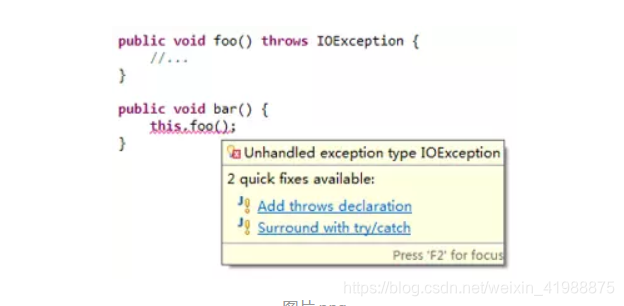
foo方法可能产生IOException(这是一种checked异常),所以bar方法在调用foo时,编译器会提示错误。此时可以在bar方法的定义行中加入throws:
public void bar() throws IOException
也可以在bar方法内将IOException捕获处理:

另一个理解checked异常与unchecked异常区别的角度是:所有由JVM自动生成的异常都是unchecked异常,反之,由java程序主动生成的异常是checked异常。
例如:
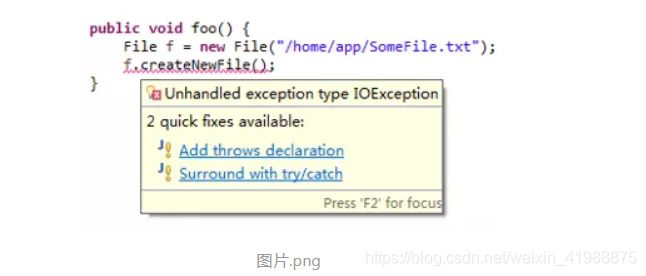
上图中f.createNewFile()方法可能会产生checked异常IOException,我们看看File类的源码:
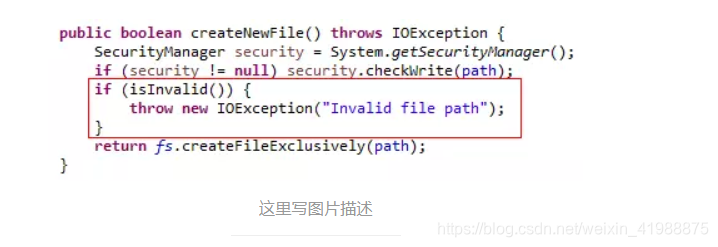
可以看到红框处,IOException异常是在代码中被主动抛出的,凡是这样在代码中主动抛出的异常,都是checked异常。
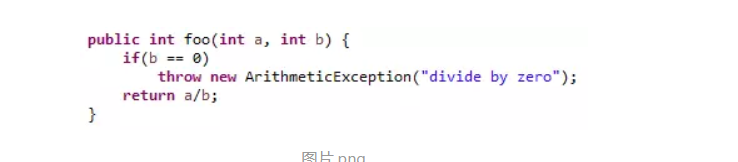
相应地,unchecked异常是JVM在运行时自动产生的,例如下图的方法,只要传入的参数b等于0,就会在运行时自动产生ArithmeticException:
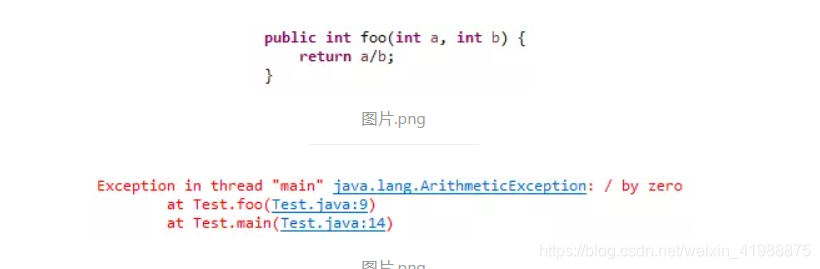
代码中永远不需要这样写:
异常处理的原则
异常处理的原则主要有三个:
• 具体明确
• 提早抛出
• 延迟捕获
具体明确:
指抛出的异常应能通过异常类名和message准确说明异常的类型和产生异常的原因。
我们通过例子来看:
代码1:

代码2:

这两段代码的处理逻辑是类似的,均是在入参input1或input2为null或空串时抛出异常,但只有第二段符合“具体明确”的标准:
首先,第二段代码通过异常类型【IllegalArgumentException】明确了异常是由于传入了不合法的参数导致的;其次,在message中说明了具体是哪个参数不合法,为什么不合法。这样不仅能够在查阅日志时快速知晓异常产生的原因,也让上层的程序能够针对IllegalArgumentException这一特定类型的异常进行有针对性的捕捉和处理。
相比之下,第一段代码中抛出的异常就不够具体明确,异常类型Exception不具有说明性质,异常message也不够明确,上层程序难以处理,阅读日志时也难以快速定位。
提早抛出:
指应尽可能早的发现并抛出异常,便于精确定位问题。
同样通过例子来看:
代码1:

代码2:
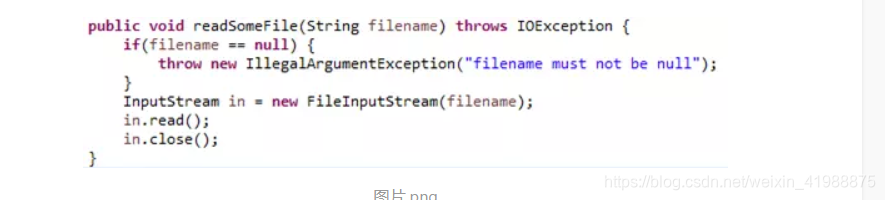
在传入的filename为null时,这两段代码都会抛出异常,第一段代码抛出的异常是:

第二段代码抛出的异常是:

第一段代码抛出的异常是在标准Java类库【InputFileStream】中抛出的,这首先就提升了问题定位的难度,不过幸好stacktrace中也打印出了前面的调用链,我们可以在标准类库的调用者身上查找问题(可以定位到Test.java的第38行)。
同时NullPointerException是Java中信息量最少的(却也是最常遭遇且让人崩溃的)异常。它压根不提我们最关心的事情:到底哪里是null。在稍微复杂一些的场景中(如一行代码中有多处都可能导致NullPointerException)会让人更加崩溃。
而相比之下第二段代码对filename提前进行了校验,并以IllegalArgumentException的形式抛出,这样在第一段代码中遇到的两个问题都可以得到解决,这便是提早抛出的好处。
延迟捕获
指异常的捕获和处理应尽可能延迟,让掌握更多信息的作用域来处理异常。
代码1:
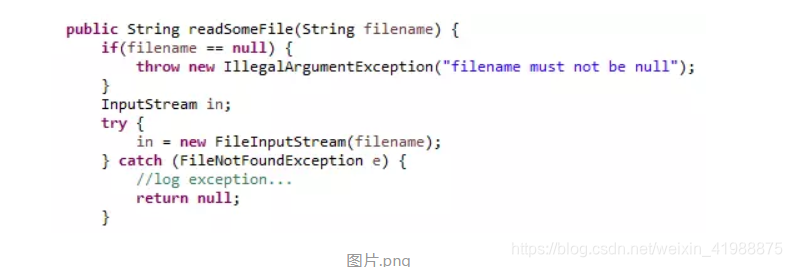
上面的代码中,readSomeFile方法将new FileInputStream处有可能产生的FileNotFoundException捕获,并将异常信息记录到了日志中。
这么做看起来似乎没什么问题,但readSomeFile这个方法有可能是一个通用的底层方法,会在各种业务场景下被调用,不同的业务场景下,发生FileNotFoundException时的处理策略可能不一样(例如某些场景要求记录异常并告警,某些场景会使用其他文件名重试),但readSomeFile方法并不知道自己所处的业务场景是什么样的,这一信息只有更上层的作用域才了解,所以在方法内部直接捕获并处理异常的做法就显得有问题了,程序将无法通过甄别业务场景来执行不同的异常处理逻辑。
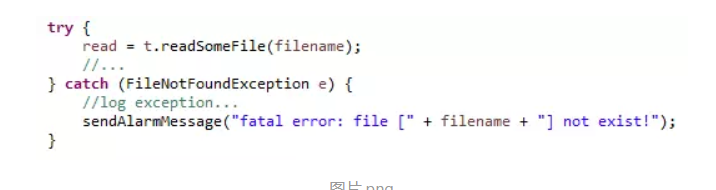
代码2:

第二段代码看起来反而更加简单了,没有对FileNotFoundException加以处理,而是直接在方法定义中将其抛出。然而在上面所述的场景下,这种处理方式反而是正确的。将异常抛出交由掌握了足够多信息的上层调用者捕获,这样就可以根据异常产生所处的具体业务流程来进行不同的处理。
例如我们可以在一个业务逻辑中这样处理:

同时在另一个业务逻辑中这样处理:
其他重要原则
- 不要让异常逃掉
- 当一个异常在整个调用栈中的任意一层都没有被捕获,这个异常就“逃掉”了。这对于任何程序来说都是一个灾难性的事件。
- 对于B/S系统,从请求处理线程中逃掉的异常很可能会被B/S框架(如Struts/SpringMVC等)捕捉到。如果没有正确配置,这些逃掉的异常很可能就被框架“吃掉”了,即框架捕获了从业务代码层抛出的异常,且没有记录或没有完整记录异常信息。这样的异常来无影去无踪,完全无迹可寻,堪称程序员的大敌。
- 某些情况下,异常会被抛到中间件或容器(Tomcat/Jboss/Weblogic/Websphere等)层(可能是没有使用B/S框架或B/S框架没有“吃掉”异常)。被中间件或容器捕获到的异常,一般情况下会被记录在中间件或容器自己的日志中(也有可能不会记),但问题在于,这种情况下,用户会看到中间件或容器提供的错误页,这些错误页基本没有用户友好型可言,而且有可能会把异常堆栈的信息直接显示在页面上,在开放性的系统中,暴露堆栈信息极有可能引发严重的安全问题。
- 而在后台进程中,如果异常逃掉了,将会导致线程的退出。如果没有守护线程及时补充异常退出的线程,那么将有可能发生整个进程因为异常而中止的灾难性后果。
- 所以说,在编程时应绝对避免异常“逃逸”的情况,对于B/S系统来说,我们可以在每个Action中都加入try-catch块,捕获所有Exception,也可以利用B/S框架的特性来实现从Action层抛出的异常的统一处理(如Struts2和SpringMVC都有的拦截器机制)。对于后台进程来说,可以利用try-catch块避免异常导致线程中止,也可以通过添加守护线程来及时补充因异常而退出的线程,同时还应使用Thread.setDefaultUncaughtExceptionHandler来确保未捕获异常的正确记录。
- 正确记录异常信息
- 即在异常的stacktrace信息完整、未缺失的基础上,确保异常的stacktrace被正确记录到日志中
错误的做法:

上面的5种处理全都是错误的,前两种将异常信息输出到了控制台而不是日志文件中。后三种错误的使用了log4j的error方法,均没有正确记录异常的stacktrace
正确的方法:

注意应使用正确的error方法,传入两个参数,参数1是对异常的附加描述,参数2是未被篡改过的异常对象
在某些情况下,可能需要在处理异常后继续抛出,让上层捕获后继续处理,在这种情况下,需要注意抛出的异常对象未被篡改。
错误的:

如果像上图这样写的话,下层的异常stacktrace会全部被吃掉。
正确的写法:

Try—catch—
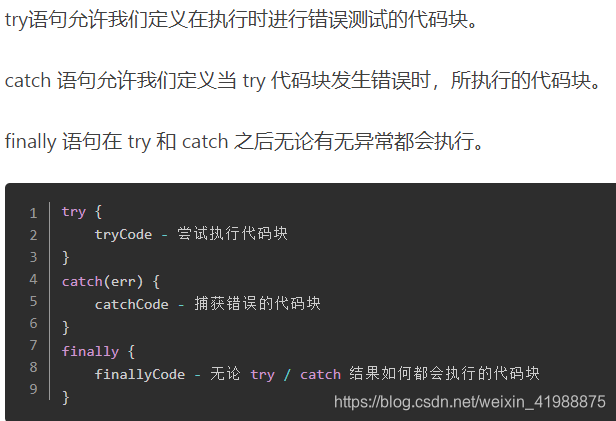
1.try中带return的情况:try{return}catch(){}finally{}
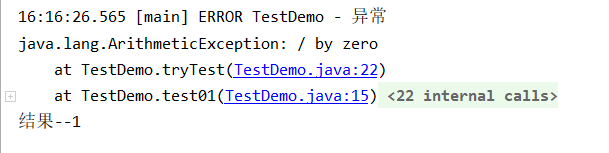
@Test
public void test01(){
System.out.println("结果--"+tryTest());
}
public int tryTest(){
int a=1;
try {
a=11;
System.out.println("try:"+a);
return a+1;
}catch (Exception e){
a=22;
}finally {
a=33;
System.out.println("finally: "+a);
}
return a;
}
try中return时返回值被保存,等finally执行完之后才能return完成;
2.catch中带return的情况:try{}catch(){return}finally{} 与try中带return一样
catch中return时返回值被保存,等finally执行完之后才能return完成;
3. finally中带return的情况:try{return}catch(){return}finally{return}
由于finally块中有return,会使程序提前退出并不执行try或catch中的return。
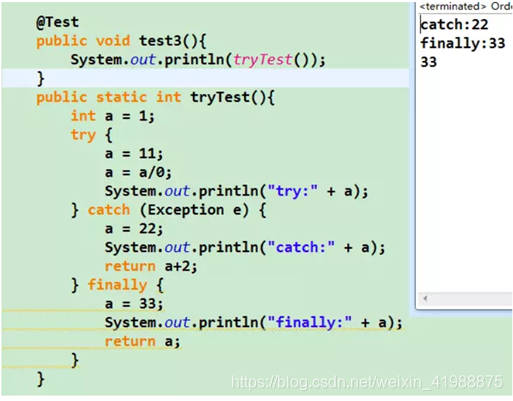
注:如果finally存在的话,任何执行try 或者catch中的return语句之前,都会先执行finally语句。如果finally中有return语句,那么程序就return了,所以finally中的return是一定会被return的,编译器把finally中的return实现为一个warning。
try-catch-finally
前文所述的异常控制流程,在JAVA程序中以try-catch-finally结构实现:

1. try块也被称为“警戒区”,try块包裹的代码在执行过程如果产生异常,或其调用栈的下层中产生了异常并被抛至本层,则会被与此try块关联的catch命令尝试捕获。若异常产生于警戒区之外,则会直接向上层抛出。
2. catch命令后的括号内指定希望捕捉的异常对象类型(可以指定多个),如果产生或被抛至此层的异常对象是catch指定的异常类型(或其子类),则异常对象会被捕捉。上例中,所有Exception对象及其子类的对象在此处均会被捕获。
3. 被捕获后,JVM会执行catch块中的代码,catch块中的代码能够访问被捕捉到的异常对象(即上例中的Exception e)。
4. catch块中的代码仍然有可能产生异常,所以也可以在catch块中插入try-catch-finally。
5. finally块为可选块,如果有,则无论是否有异常被抛出,JVM都会在try-catch块执行完成后执行finally块中的代码。
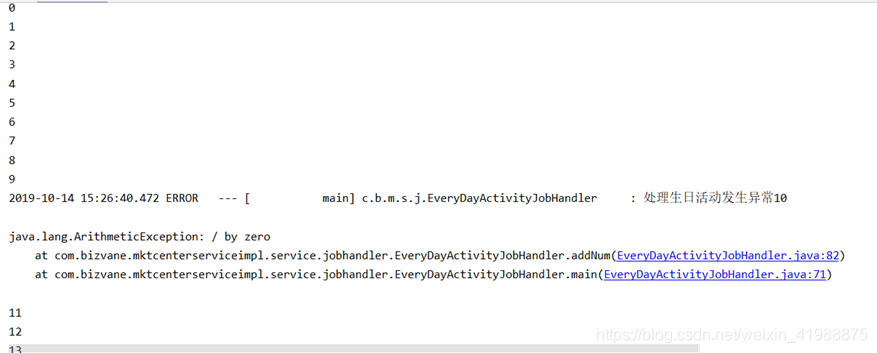
实战日志打印error:
public static void main(String[] args) {
for (int i = 0; i < 18; i++) {
try {
addNum(i);
System.out.println(i);
}catch (Exception e){
log.error("处理生日活动发生异常",e);
}
}
}
public static int addNum(int a){
int total=100+a;
if (a==10){
return 1/0;
}
return total;
}
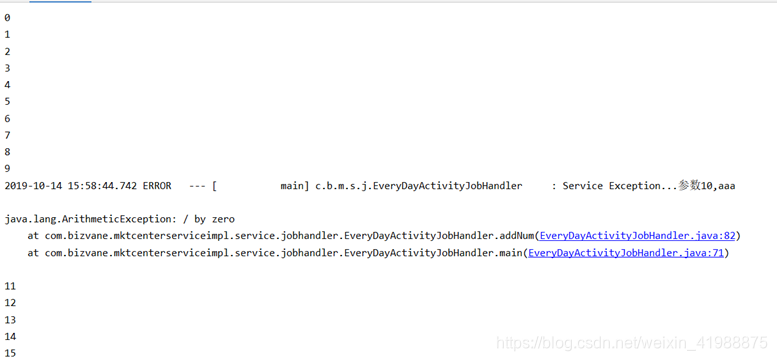
日志打印error:
public static void main(String[] args) {
for (int i = 0; i < 18; i++) {
try {
addNum(i);
System.out.println(i);
}catch (Exception e){
log.error("Service Exception...参数{}", i, e);
// log.error("Service Exception...参数{},{}", i,"aaa", e);
}
}
}
public static int addNum(int a){
int total=100+a;
if (a==10){
return 1/0;
}
return total;
}

log.error("生日活动组装条件发生异常{},{}", activityBirthday.getActivityName(),activityBirthday.getActivityCode(), e);
// log.error("Service Exception...参数{},{}", i,"aaa", e);
public static void main(String[] args) {
for (int i = 0; i < 18; i++) {
addNum(i);
System.out.println(i);
}
}
public static int addNum(int a) {
int total = 0;
try {
total = 100 + a;
if (a == 10) {
return 1 / 0;
}
return total;
} catch (Exception e) {
log.error("Service Exception...参数{}", a, e);
}
return total;
}
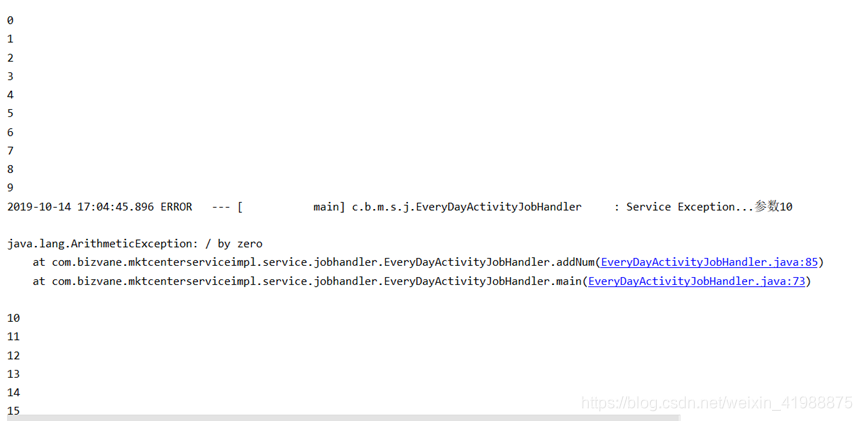
循环中try—catch--
ublic static void main(String[] args) {
for (int i = 0; i <10 ; i++) {
Student po = null;
try {
po = getPo();
System.out.println(po);
} catch (Exception e) {
log.error("Service Exception...参数{},{}", po,"aaa", e);
}
System.out.println(i+"----"+po);
}
}
public static Student getPo() {
Student student = new Student();
student.setAaa("1111");
student.setName("22222");
int i = 1 / 0;
student.setAddr("999999");
return student;
}
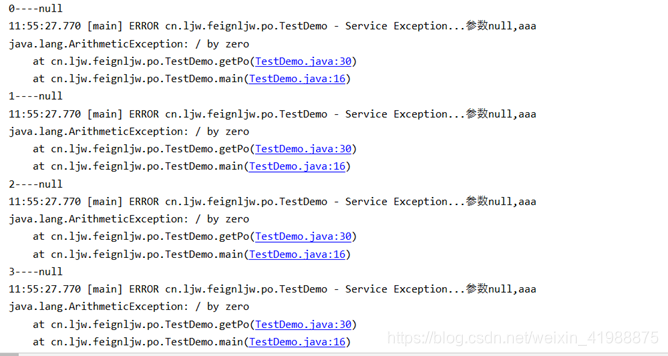
在catch中返回结果
@Slf4j
public class TestDemo {
@Test
public void test01(){
System.out.println("结果--"+tryTest());
}
public int tryTest(){
try {
int i = 1 / 0;
return 0;
}catch (Exception e){
log.error("异常",e);
return 1;
}
}
}
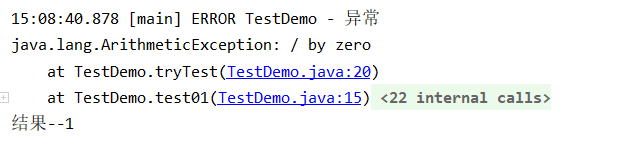
@Test
public void test01(){
System.out.println("结果--"+tryTest());
}
public int tryTest(){
int a=0;
try {
int i = 1 / 0;
a=1; //异常后改动
return a;
}catch (Exception e){
log.error("异常",e);
return a;
}
}
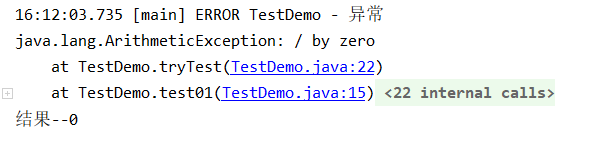
@Test
public void test01(){
System.out.println("结果--"+tryTest());
}
public int tryTest(){
int a=0;
try {
a=1; //异常前改动
int i = 1 / 0;
return a;
}catch (Exception e){
log.error("异常",e);
return a;
}
}
智能推荐
【路径规划】2D/3D RRT*算法(Matlab实现)-程序员宅基地
文章浏览阅读427次,点赞4次,收藏9次。与传统的RRT算法相比,RRT*采用增量式搜索策略,通过逐步探索状态空间并不断改善路径质量,具有较高的效率和性能。这种算法具有渐近最优性和适应复杂环境的特点,可以在不断优化树结构和重新连接的过程中,随着时间的推移收敛到全局最优解。RRT*算法的独特之处在于能够在保持搜索效率的同时,提供更接近最优解的路径规划结果,使得机器人能够在复杂的环境中更有效地规划路径并完成任务。文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。行百里者,半于九十。
Vue Router 的params和query传参的使用区别_{params:this.queryinfo}-程序员宅基地
文章浏览阅读162次。1·params传递参数(使用 name 跳转)//$router : 是路由操作对象,只写对象//$route : 路由信息对象,只读对象//操作 路由跳转this.$router.push({ name:'one', params:{ name:'pendy', age:'11' }})//读取 路由参数接收this.name = this.$route.params.name;this.age = thi_{params:this.queryinfo}
【Netty】ByteToMessageDecoder源码解析_netty 基于bytetomessagedecoder自定义起始字节和结尾字节-程序员宅基地
文章浏览阅读717次。本节我主要分析一下server端解析报文的一个过程,client当然也很重要,尤其在建立TCP连接和关闭连接需要严格控制,否则服务端会发现大量的CLOSE_WAIT(被动关闭连接),甚至大量TIME_WAIT(主动关闭连接),关于这个处理之前的文章有讲解。读了ByteToMessageDecoder的部分源码,以及它的实现JsonObjectDecoder,那么如果我们自己实现一个Decoder该如何实现,这里提供三个思路给大家,有时间再补充代码。累加器的作用是解决tcp数据包中出现半包和粘包问题。_netty 基于bytetomessagedecoder自定义起始字节和结尾字节
结构光系统标定(一)标准结构光系统_结构光标定-程序员宅基地
文章浏览阅读5.7k次,点赞12次,收藏33次。从最基本的标准结构光系统开始,尽可能详细地推导结构光系统标定的经典模型_结构光标定
java方法名是什么_什么是java的方法-程序员宅基地
文章浏览阅读3.3k次。java的方法是一段可以被重复调用的代码块。方法的声明: (推荐学习:java课程)public static 方法返回值 方法名([参数类型 变量……]){方法代码体;return 返回值;}方法的定义包括两部分:方法头和方法体。方法头可以由方法的类型,名称和名称之后的括号以及有参数的列表组成。方法体由一对括号和括号之间的内容组成。内容包括java语句及变量的声明(指局部变量)。当..._方法名是什么
如何安装Ctags 和 Taglist_tlist_exist_onlywindow-程序员宅基地
文章浏览阅读509次。参考链接 :http://blog.sina.com.cn/s/blog_684355870100jqz3.htmlCtags 下载链接:Taglist 下载链接:_tlist_exist_onlywindow
随便推点
C++(7): std::list的使用_c++ std::list-程序员宅基地
文章浏览阅读782次,点赞5次,收藏3次。std::list是 C++ 标准模板库(STL)中的一个顺序容器适配器,它提供了双向链表的数据结构。与 std::vector 不同,std::list 不存储连续的元素,因此它可以高效地在中间插入和删除元素,而不需要移动其他元素。_c++ std::list
linear-gradient的角度与百分比_lineargradient 角度-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏5次。目录一、角度二、百分比三、测试代码一、角度垂直向上方向是0度,顺时针方向选中与垂直向上形成的夹角是角度。注意,标准的语法是不支持起使方向,例如: background: linear-gradient(top, red, blue);如果要使用起使角度,家私用前缀:background: -ms-linear-gradient(top, red, blue);background: -webkit-linear-gradient(top, red, blue);background: -o_lineargradient 角度
【PostgreSQL】PostgreSQL查表的全局索引、普通索引_pgsql表索引查看-程序员宅基地
文章浏览阅读812次,点赞12次,收藏7次。【代码】【PostgreSQL】PostgreSQL查表的全局索引、普通索引。_pgsql表索引查看
人工智能与金属材料:未来的强度-程序员宅基地
文章浏览阅读827次,点赞8次,收藏12次。1.背景介绍人工智能(AI)和金属材料是两个庞大的领域,它们在现代科技中扮演着越来越重要的角色。随着计算能力的不断提高和数据处理技术的不断发展,人工智能已经成功地应用于许多领域,包括自动驾驶、语音助手、图像识别等。而金属材料则是工程材料领域的重要一环,它们的性能和可靠性对于现代工业和技术的发展具有重要意义。然而,在这两个领域之间,我们可以发现一种有趣的联系:人工智能可以帮助我们更好地理解和...
imei服务器清除id_苹果绕过ID解锁_苹果手机怎么用序列号解id解锁-程序员宅基地
文章浏览阅读1.5k次,点赞43次,收藏41次。首先搞明白什么是苹果激活锁有叫id锁,一定要把他和屏幕锁区别开来,屏幕锁就是让输入四位,六位,或者更多符号的,密码锁,这个经常使用智能手机的用户都只能,苹果的手机和安卓的有很大不同,安卓机有设置图形锁,苹果的没有这个图形锁,激活id锁很多时候是屏幕锁忘记了,刷机以后出现的的,很多人设置了屏幕锁忘记了,输入多次出现iPhone 已停用,需要连接iTunes ,这个情况下就需要连接电脑上用iTunes 刷机才可以._苹果手机怎么用序列号解id解锁
Error building SqlSession.一招解决-程序员宅基地
文章浏览阅读7.2k次,点赞9次,收藏30次。解决方法:把所有配置文件的编码格式由UTF-8全部改为UTF8 ,喜欢技术的,一起进群交流学习吧!!!_error building sqlsession.