struct c语言内存字节,C语言结构体内存的对齐知识详解-程序员宅基地
技术标签: struct c语言内存字节
前言
在前面的章节中,我们谈到了C语言中整数以及浮点数的储存
今天,我们来谈一谈一些关于结构体内存的知识。
我们先来看一个例子:
struct S1
{
char c1;
int i;
char c2;
};
大家来猜猜这个结构体S1的内存是多少?
相信会有人给出 6 的结果,他们或许是这样想的,两个 char 类型分别为一个字节,一个 int 类型又为4个字节,加起来刚好为6个
但是
结果真是如此吗?
我们来看看运行结果:
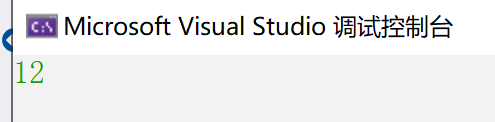
为什么呢,接下来我们就引出正文。
一.结构体内存对齐规则
首先,正如引例所示,结构体的内存并不是简简单单的将结构体各个成员的大小相加。
结构体的大小往往遵循着结构体的对齐规则:
第一个成员在与结构体变量偏移量为0的地址处。
其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
这里要注意的一点就是要解释一下这个对齐数的概念
对齐数:编译器默认的一个对齐数 与 该结构体变量成员自身大小的较小值。
注:
不是所有的编译器都有自己默认的对齐数。
在VS下其默认的对齐数为8
在linux下的默认值为4
二.怎样计算结构体的大小
在讲计算之前,我们继续来看一看上面的那个例子:
#define _CRT_SECURE_NO_WARNINGS
#include
#include
struct S1
{
char c1;
int i;
char c2;
};
int main()
{
printf("该结构体成员 c1 开始的位置为第 %d 个字节\n", offsetof(struct S1, c1));
printf("该结构体成员 i 开始的位置为第 %d 个字节\n", offsetof(struct S1, i));
printf("该结构体成员 c2 开始的位置为第 %d 个字节\n", offsetof(struct S1, c2));
printf("该结构体所占的内存空间为 %d 个字节\n", sizeof(struct S1));
return 0;
}
注:
宏 offsetof() 可以计算出结构体各成员所相对开始位置的一个偏移量。
偏移量 : 我们可以理解为把结构体变量第一个成员所储存的第一个位置置于0,以此递增
我们来看看结果:

这是为什么呢?
我们来看看上面所提到的结构体内存对齐规则:

然后我们来看示意图:

此时,关于结构体的大小,我们应该清楚了不少,接下来,我们继续来看几道例题:
struct S2
{
char c1;
char c2;
int i;
};
int main()
{
printf("%d\n", sizeof(struct S2));
return 0;
}
我们看到,S1与S2的区别仅仅只是调换了一下各成员间的顺序,那它所占的内存还是刚才的值吗:
运行结果:
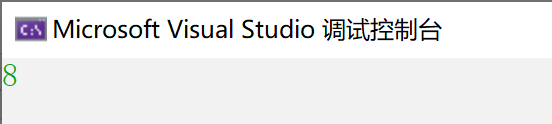
我们继续来分析一下:

趁此机会,我们再来巩固一下:
struct S3
{
double d;
char c;
int i;
};
int main()
{
printf("%d\n", sizeof(struct S3));
return 0;
}
它的结果会是多少呢?

不知道大家作对了吗?
解析:
首先 double 类型占8个字节
char 又展览接下来的一个
而 int 的对齐数为 4,所以空3个字节从12开始
而这个结构体的最大对齐数为8
所以该结构体占 2*8 = 16个字节
最后,我们再来看一道嵌套结构体的例题:
struct S3
{
double d;
char c;
int i;
};
struct S4
{
char c1;
struct S3 s3;
double d;
};
int main()
{
printf("%d\n", sizeof(struct S4));
return 0;
}
它的结果又为多少呢?

解析:
我们先来看看规则 4: 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,
结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
S3的最大对齐数为 8,它的大小为 16 个字节
首先,毋庸置疑的是 char 先放到首位
接下来因为S3的对齐数为 8,所以S3放在了以位置8开始的16个字节
最后是double,对齐数为8,所以放在了24的位置
最后,该结构体的大小为 4*8 = 32 个字节
在进行结构体所占大小的计算中,我们又可以得到一个基本编程常识:
三.设计结构体时要注意的方面
在我们进行结构体的设计中,我们可以把一些所占空间小的,来凑到一起,提高资源的利用率。
正如上文所提到的例1与例2,结构体成员完全相同,但顺序不同,两个结构体的大小也截然不同
//例1
struct S1
{
char c1;
int i;
char c2;
};
//例2
struct S2
{
char c1;
char c2;
int i;
};
int main()
{
printf("%d\n", sizeof(struct S1));//12
printf("%d\n", sizeof(struct S2));//8
return 0;
}
四.为什么存在内存对齐
对于这个原因,目前话没有一种完全正确的答案,但是:
大部分的参考资料都是如是说的:
1. 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;
某些硬件平台只能在某些地址 处取某些特定类型的数据,否则抛出硬件异常。
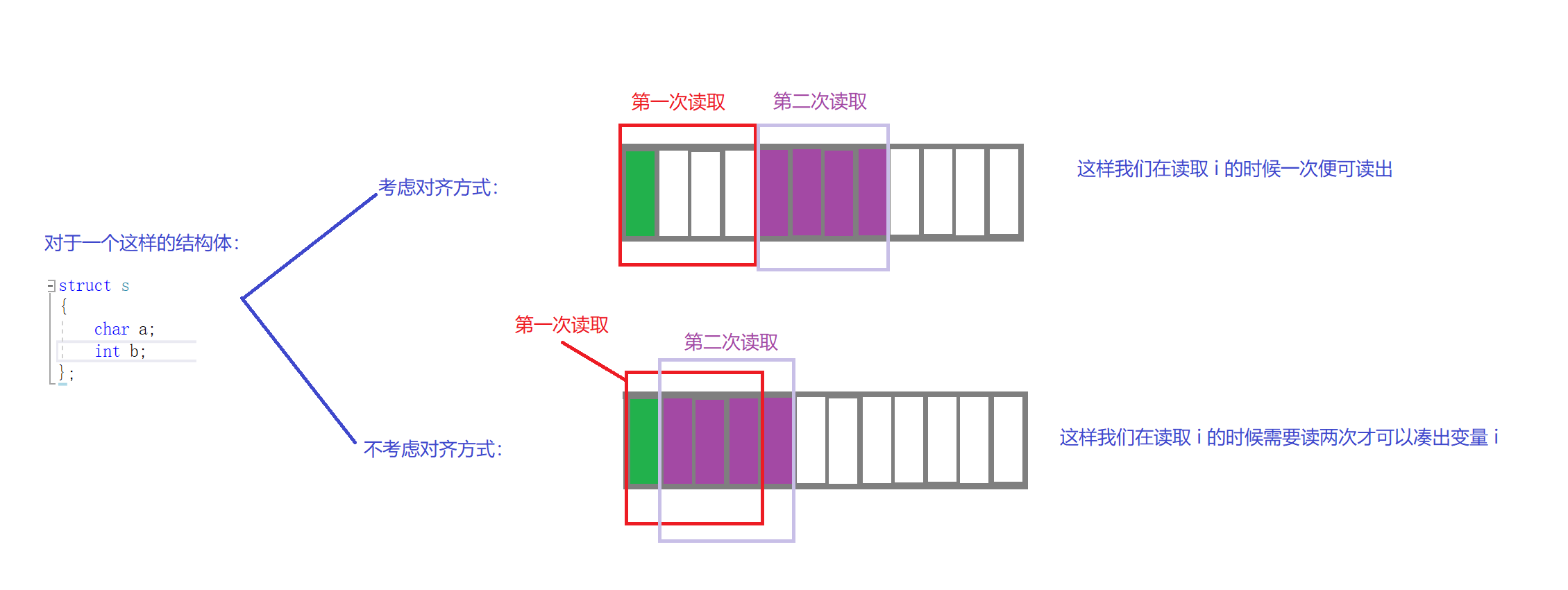
2. 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
原因在于,为了访问未对齐的内存,处理器 需要作两次内存访问;而对齐的内存访问仅需要一次访问。
对于原因而我们来看一个示意图:
五.修改默认对齐数
我们通常使用如下的预处理命令来修改编译器的默认对齐数:
#pragma pack()
如果()里面不加数字,则默认为编译器的默认对齐数
我们修改的时候,只需在()里加一个数字就行
取消的时候再添加一次#pragma pack() 即可
注:
再()里添加的数字,我们通常加的都是2的多少次方
下面来举一个实例:
#include
#pragma pack(8)//设置默认对齐数为8
struct S1
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
#pragma pack(1)//设置默认对齐数为8
struct S2
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
int main()
{
//输出的结果是什么?
printf("%d\n", sizeof(struct S1));//12
printf("%d\n", sizeof(struct S2));//6
return 0;
}
由此可见,我们也可以通过修改默认对齐数来节约 结构体使用的空间。
关于结构体内存的讲解便到此为止。
笔者水平有限,若有错误之处,还望多多指正。
总结
到此这篇关于C语言结构体内存对齐的文章就介绍到这了,更多相关C语言结构体内存对齐内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
智能推荐
yum安装及配置_安装yum-程序员宅基地
文章浏览阅读10w+次,点赞40次,收藏332次。yum是用来管理rpm的,就跟maven管理jar包相似。yum源(库)分为本地库、网络库。首先要配置yum源,可支持多个源。先查看一下挂载情况:df -h这里我们要更换光盘,并挂载:mount /dev/cdrom /mnt(如果不能成功挂载,点击一下连接即可)之后再次使用 df -h命令,就能查看到光盘的内容。下面我们cd到 /mnt下查看一下:首先关注一下Pa..._安装yum
关于STM32 CAN的过滤器/滤波器_stm32can mailbox filter-程序员宅基地
文章浏览阅读3.8k次,点赞5次,收藏12次。1.在设置CanTxMsg.StdId时注意需要将其右移一位,比如如下滤波器配置:CAN_FilterInitStructure.CAN_FilterNumber=0;CAN_FilterInitStructure.CAN_FilterMode=CAN_FilterMode_IdMask;CAN_FilterInitStructure.CAN_FilterScale=CAN_Filter..._stm32can mailbox filter
HDU 5119 Happy Matt Friends(动态规划)【状压基础类模板】_matt has n friends. they are playing a game togeth-程序员宅基地
文章浏览阅读373次。att has N friends. They are playing a game together. Each of Matt’s friends has a magic number. In the game, Matt selects some (could be zero) of his friends. If the xor (exclusive-or) sum of the selected friends’magic numbers is no less than M , Matt wi_matt has n friends. they are playing a game together.
vue3+vite+ts项目配置开发环境和生产环境 打包命令配置_vite打包配置-程序员宅基地
文章浏览阅读8.4k次,点赞6次,收藏29次。开发环境和生产环境的配置和打包方式有所不同,下面是基于vue3+vite+ts项目的开发环境和生产环境配置及打包方式的详细说明。打包完成后会在项目根目录下生成dist目录,里面包含了打包后的静态文件和index.html文件,可以直接部署到服务器上。这里配置了三个命令,分别是开发环境启动命令、开发环境打包命令和生产环境打包命令。1.3 配置.env.development。2.2 配置.env.production。1.2 配置vite.config.ts。2.1 配置vite.config.ts。_vite打包配置
(最新最详细)安装ubuntu18.04-程序员宅基地
文章浏览阅读2w次,点赞4次,收藏91次。目录1. window10中下载ubuntu镜像2. 制作U盘启动盘3. Ubuntu 分配硬盘空间1. window10中下载ubuntu镜像下载地址2. 制作U盘启动盘安装制作工具:UltraISO(点我下载),下载完成后安装插入用来做启动盘的U盘(最好是usb3.0接口,16GB或以上),并清空里面的文件打开安装好的UltraISO,点击继续试用按钮工作界面进入工作界面后,点击菜单栏文件(F),在弹出的选项卡里点击打开在弹出的文件选择对话框中找到下载好的 Ubuntu18.04._ubuntu18.04
Toad报“No valid Oracle Client found”错-程序员宅基地
文章浏览阅读203次。2019独角兽企业重金招聘Python工程师标准>>> ..._toad no valid oracle client
随便推点
分布式系列教程(11) -分布式协调工具Zookeeper(分布式锁实现)_分布式锁 的具体实现工具-程序员宅基地
文章浏览阅读553次,点赞2次,收藏2次。代码已提交至Github,有兴趣的同学可以下载来看看(git版本号:bea4d6f7ec9f7309033bcfa43316a660171ae5b6):https://github.com/ylw-github/Zookeeper-Demo本文目录结构:l____1. 知识点回顾l________1.1 多线程l________1.2 Java共享内存模型l____2. 分布式锁的解决方..._分布式锁 的具体实现工具
Nginx网站服务详解(Nginx服务的主配置文件 ——nginx.conf)-程序员宅基地
文章浏览阅读9.3k次,点赞9次,收藏51次。Nginx网站服务详解,Nginx服务的主配置文件,修改,监听,配置,密码认证,以及IP和端口虚拟主机配置方法,含图文步骤拆解讲解_nginx.conf
Java并发——Synchronized关键字和锁升级,详细分析偏向锁和轻量级锁的升级_3.轻量级锁-程序员宅基地
文章浏览阅读10w+次,点赞266次,收藏1.1k次。目录一、Synchronized使用场景二、Synchronized实现原理三、锁的优化1、锁升级2、锁粗化3、锁消除一、Synchronized使用场景Synchronized是一个同步关键字,在某些多线程场景下,如果不进行同步会导致数据不安全,而Synchronized关键字就是用于代码同步。什么情况下会数据不安全呢,要满足两个条件:一是数据共享(临界资源),二..._3.轻量级锁
排序算法-堆积树排序法(HeapSort)-程序员宅基地
文章浏览阅读731次。堆积树排序法是选择排序法的改进版,可以减少在选择排序法中的比较次数,进而减少排序时间。堆积排序法用到了二叉树的技巧,是利用堆积树来完成排序的。堆积树是一种特殊的二叉树,可分为最大堆积树和最小堆积树两种。
Hadoop调优第一篇_hadoop_namenode_opts-程序员宅基地
文章浏览阅读917次。1.hdfs核心参数——回收站设置第一步,在调优前我们需要对namenode与datanode的内存配置进行参数化设置。通过hadoop-env.sh查看namenode与datdanode的具体参数。相关参数设置如下export HDFS_NAMENODE_OPTS=”-Dhadoop.security.logger=INFO,RFAS -Xmx1024m”export HDFS_DATANODE_OPTS=”-Dhadoop.security.logger=ERROR,RFAS -Xmx10_hadoop_namenode_opts
Studio 3T for MongoDB 激活破解脚本_studio 3tjihuoma-程序员宅基地
文章浏览阅读1.9w次,点赞2次,收藏27次。Studio 3T试用期过了不能使用,网上未搜索到相对应的激活码,可以选择重置使用时间继续使用。_studio 3tjihuoma