分群思维(二)基于波士顿矩阵的产品分类_产品分群-程序员宅基地
分群思维(二)基于波士顿矩阵的产品分类
小P:小H,我们的产品现在越来越多了,有没有好分类方法帮助分类呢
小H:有啊,典型的如波士顿矩阵产品分类法
小P:我就知道你会,给我们讲讲呗~
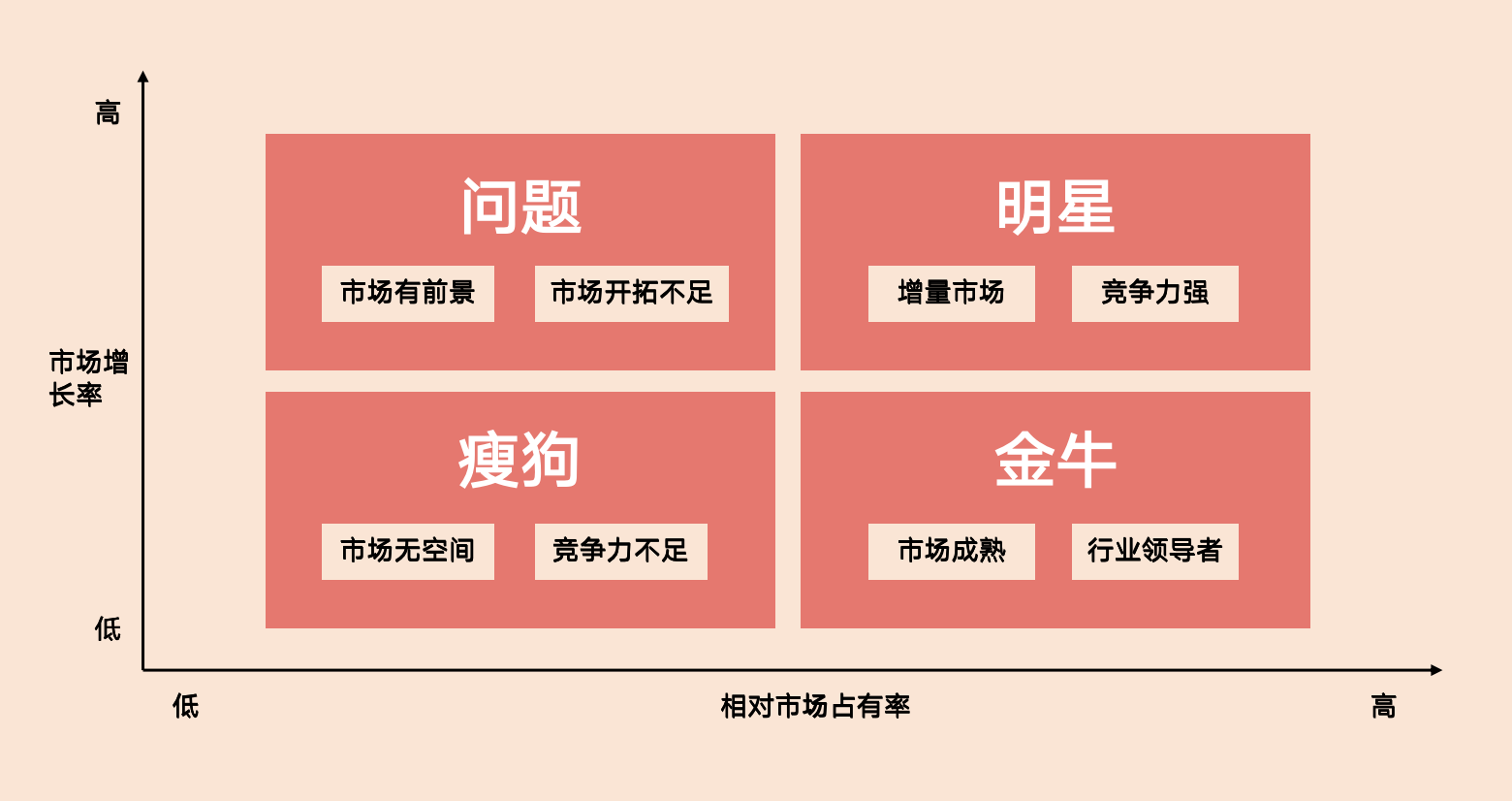
小H:波士顿矩阵将"销售增长率"和"市场占有率"作为衡量产量的重要因素,组合形成四种产品,也即著名的的波士顿产品分类。
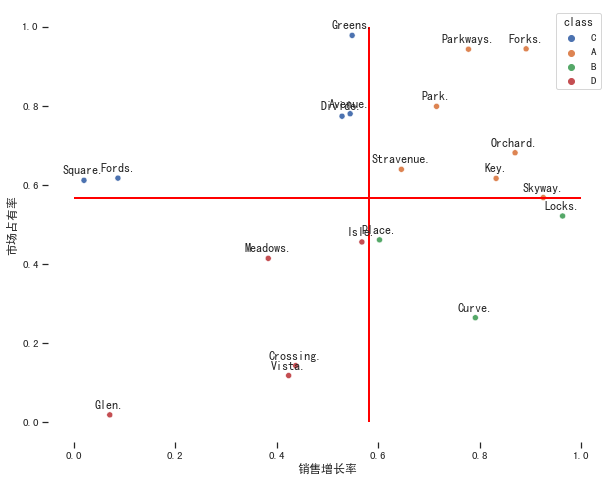
Python模拟
import faker
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import ticker
%matplotlib inline
# 初始化设置
sns.set(style="ticks")
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
def mat_class(x, y, xmean, ymean):
'''
根据特征xy生成四类,其中A类似于明星产品
'''
if x>=xmean and y>=ymean:
cl = 'A'
elif x>=xmean and y<ymean:
cl = 'B'
elif x<xmean and y>=ymean:
cl = 'C'
else:
cl = 'D'
return cl
# 生成产品随机数
f = faker.Faker()
product = [f.unique.street_suffix() for i in range(20)] # 随机生成的街道简称替代产品名称
np.random.seed(0)
sales_growth = list(np.random.rand(20))
market_share = list(np.random.rand(20))
df = pd.DataFrame({
'product':product, 'sales_growth':sales_growth, 'market_share':market_share})
sales_growth_mean = df['sales_growth'].mean()
market_share_mean = df['market_share'].mean()
df['class'] = df.apply(lambda x: mat_class(x.sales_growth, x.market_share,
sales_growth_mean, market_share_mean), axis = 1)
df.head()
| product | sales_growth | market_share | class | |
|---|---|---|---|---|
| 0 | Greens | 0.548814 | 0.978618 | C |
| 1 | Park | 0.715189 | 0.799159 | A |
| 2 | Place | 0.602763 | 0.461479 | B |
| 3 | Avenue | 0.544883 | 0.780529 | C |
| 4 | Vista | 0.423655 | 0.118274 | D |
# 为每个点添加对应的名称
plt.figure(figsize=(10, 8))
# 基础散点图
x, y = df['sales_growth'], df['market_share']
label = df['product']
sns.scatterplot(x=x, y=y, hue="class", data=df)
plt.xlabel('销售增长率'); plt.ylabel('市场占有率')
# 对散点图中的每一个点进行文字标注
for a,b,l in zip(x,y,label):
plt.text(a, b+0.01, '%s.' % l, ha='center', va='bottom',
fontsize=12)
# 添加特定分割线
plt.vlines(x=sales_growth_mean, ymin=0, ymax=1,
colors='red', linewidth=2)
plt.hlines(y=market_share_mean, xmin=0, xmax=1,
colors='red', linewidth=2)
# # 背景网格
# plt.grid(True)
# 隐去四周的边框线条
sns.despine(trim=True, left=True, bottom=True)
plt.show()
应用
一般基于波士顿矩阵分类衍生出了类似的四象限分析法,将二维指标引申至相关的两个特征。例如通过渠道规模和渠道质量对渠道进行分类;产品功能使用率和次日留存率对产品质量进行分类等。
总结
波士顿矩阵对于二维分类具有很好的指导思想,可扩展性极强
共勉~
智能推荐
hadoop在eclipse上运行实例_hadoop eclipse run as-程序员宅基地
文章浏览阅读2.8k次,点赞2次,收藏18次。上一篇博客阐述了怎么创建hadoop与eclipse的连接(因为是在GUI版上装的linux版eclipse),所以这一篇不仅介绍怎么做,而且还讲解怎么创建windows上eclipse与linux上的hadoop的连接。(11条消息) Centos7(GUI)下的hadoop与eclipse的连接并运行wordcount实例_qq_45672631的博客-程序员宅基地这里,在hadoop已经成功的前提下,我们在官网下载eclipse (这里用的是2021-06版的)java-jdk(这里用的11._hadoop eclipse run as
PHP使用gearman扩展完成异步任务总结_php5 gearman-程序员宅基地
文章浏览阅读2.2k次。PHP的gearman扩展,可以在Linux服务器上,实现PHP脚本的异步任务,甚至是分布式异步任务。在项目中一些响应慢,或者是占用时间的PHP脚本,可以用异步任务去完成,用户访问时不用等待漫长的队列任务,因为在服务器上有专门跑这些异步任务的脚本。1、安装能执行任务的job(用于执行“work”)#wget http://launchpad.net/gearmand/tru_php5 gearman
【无标题】针对MNIST数据集,构造卷积神经网络实现手写数字识别。_从网上下载或自己编程实现一个卷积神经网络并在手写字符识别数据 mnist上进行实验-程序员宅基地
文章浏览阅读1.9k次,点赞2次,收藏31次。以pytorch构建的两层卷积核,一层池化层,两层全连接层的神经网络,在Mninst数据 集上训练,准确率达到98%,而且在增加旋转的Mninst数据集上达到97%的准确率。_从网上下载或自己编程实现一个卷积神经网络并在手写字符识别数据 mnist上进行实验
IDEA专栏—IDEA导入maven工程发现Java文件颜色不对_maven颜色-程序员宅基地
文章浏览阅读1.2k次。如下图设置,File Setting中:或者在我们导入项目时,idea右下角界面会弹出提示框,询问我们是否要自动导入,选择Enable Auto-imort即可,如下图。但是这里选择仅仅是针对当前项目自动导入,所以还是乖乖在file setting中设置自动导入最为保险。_maven颜色
详解@JsonProperty、@JsonFormat 和 @DateTimeFormat 注解用法-程序员宅基地
文章浏览阅读1.4w次,点赞6次,收藏37次。详细解释 @JsonProperty、@JsonFormat 和 @DateTimeFormat 注解的用法_@jsonproperty
Linux使用docker搭建Mysql主从复制_linux 实现docker的mysql主从复制-程序员宅基地
文章浏览阅读326次。Linux使用docker搭建Mysql主从复制_linux 实现docker的mysql主从复制
随便推点
三个整数的排序_将输入的三个数放到数组中并排序-程序员宅基地
文章浏览阅读4.1k次。1. 问题描述:问题描述 输入三个数,比较其大小,并从大到小输出输入格式 一行三个整数输出格式 一行三个整数,从大到小排序样例输入33 88 77样例输出88 77 332. 方法一:可以使用Java的三目运算符进行判断得到最大值然后判断剩下来的元素的大小关系,方法二新建一个整型数组把元素存进去然后对数组进行排序然后再逆序输出即可..._将输入的三个数放到数组中并排序
剑指 Offer 14- I. 剪绳子(C++暴力+动态规划、贪心解)_c++剪绳子动态规划法-程序员宅基地
文章浏览阅读627次。一、题目剑指 Offer 14- I. 剪绳子题目描述给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]…k[m-1] 。请问 k[0]k[1]…*k[m-1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。示例1:输入: 2输出: 1解释: 2 = 1 + 1, 1 × 1 = 1示例2:输入: 10输出: 36解释: _c++剪绳子动态规划法
关于Ionic cordova 的一些基本问题_关于cordova:ionic-(仅适用于ios)仍在应用程序第一个可见模板的背景中显示闪屏中-程序员宅基地
文章浏览阅读252次。新建项目 -vx 表示指定第x个ionic版本ionic start myAwesomeApp --vx(不指定会提示使用哪个版本)ionic创建项目报错Error: read ECONNRESET at _errnoException (util.js:992:11) at TLSWrap.onread (net.js:618:25)–> 版本4.1.1 降级为3.9.1 !!!..._关于cordova:ionic-(仅适用于ios)仍在应用程序第一个可见模板的背景中显示闪屏中
光线追踪渲染实战(五):低差异序列与重要性采样,加速收敛!_软光追,bvh可视化,gpu实现,brdf,重要性采样以及差异序列-程序员宅基地
文章浏览阅读5.2k次,点赞25次,收藏26次。1. 低差异序列具有很好的空间填充性质,使用 sobol sequence 作为生成半球采样样本的随机数 2. 使用重要性采样策略对 Disney BRDF 进行采样,大大加速收敛的过程 3. 预计算 hdr 贴图的重要性采样样本,直接采样光源,对 hdr 贴图高亮处分配更多的光线 4. 使用多重重要性采样策略混合 brdf 采样和 hdr 采样,适应粗糙度和不同大小的光源,加速光线追踪的收敛_软光追,bvh可视化,gpu实现,brdf,重要性采样以及差异序列
My97DatePicker日期控件使用方法_my97datepicker设置选择今天以后-程序员宅基地
文章浏览阅读660次。-------------------------------引入JS------------------------ ------------------使用控件------------------------------- class="Wdate" size="10" readonly="readonly" style="height:15px;wi_my97datepicker设置选择今天以后
医学图像分割模型:U-Net详解及实战-程序员宅基地
文章浏览阅读6k次,点赞11次,收藏122次。2015年U-Net的出现使得原先需要数千个带注释的数据才能进行训练的深度学习神经网络大大减少了训练所需要的数据量,并且其针对神经网络在图像分割上的应用开创了先河。当时神经网络在图像分类任务上已经有了较好的成果,但在很多视觉的任务中由于输出需要进行定位,也就是每个像素需要分配一个类标签,这导致成千上万的训练图像在生物医学任务中通常难以获得,从而急需要一个神经网络,它不需要那么多的数据来进行训练却依旧有较好的效果,这就导致了U-Net的诞生。U-Net几乎是当前segmentation项目中应用最广的模型。_医学图像分割