srpg 胜利条件设定
介绍 (Introduction)
The e-sports community has been growing rapidly in the past few years, and what used to be a casual pastime has morphed into an industry projected to generate $1.8 B in revenue by 2022. While there are many video games in this ecosystem, few have been a staple of the community like League of Legends, with the game amassing over 100 million unique viewers during their 2019 World Championship.
电子竞技社区在过去几年中一直在快速增长,过去曾经是休闲娱乐,如今已演变成一个行业,预计到2022年将产生$ 1.8 B的收入。 尽管这个生态系统中有许多视频游戏,但像英雄联盟这样的社区中很少有这样的视频游戏,该游戏在2019年世界锦标赛期间吸引了超过1亿的独立观众。
Released in late 2009, League of Legends is a freemium MOBA (multiplayer online battle arena) video game created by Riot Games which generated a widespread competitive scene early on, with the first World Championship in 2011 generating around 1.6 million viewers. The game has since grown, both in popularity and gameplay, as Riot began to understand how changes could make the game more competitive and fun.
英雄联盟(League of Legends)于2009年末发布,是由Riot Games创建的免费增值MOBA(多人在线战斗竞技场)视频游戏,在早期就产生了广泛的竞争场面,2011年的第一届世界锦标赛吸引了160万观众。 此后,随着Riot开始了解变化如何使游戏更具竞争力和趣味性,游戏在受欢迎程度和游戏玩法方面都在不断发展。
The current state of the game is quite complicated, and if you’re a complete newbie, you should check out this video. To summarize, a League of Legends match poses two teams of five players, each of whom control one unique character or “champion”, and ends when one team’s Nexus, located deep in that team’s base, is destroyed. Along the way, there are many objectives that a team can achieve, such as destroying turrets, killing neutral monsters like dragon and baron for team-wide buffs, and many more. Some objectives, such as destroying at least five turrets and one inhibitor, are necessary to win the game, while others, such as getting First Blood, are helpful, but not necessary. Through this project, I would like to better understand which of these objectives are the most important to win a game of League of Legends. To that extent, the question I posed is as follows:
游戏的当前状态非常复杂,如果您是一个完全的新手,则应查看此视频 。 总而言之,英雄联盟的比赛由两队组成,每队五名球员,每人控制一个唯一的角色或“冠军”,并在摧毁一支位于该队基地深处的一支队的Nexus时结束。 在此过程中,团队可以实现许多目标,例如销毁炮塔,杀死整个团队的增益师等中立怪物,如龙和男爵,等等。 为了赢得比赛,某些目标(例如销毁至少五个炮塔和一个抑制剂)是必要的,而其他目标(例如获得“第一血统”)是有帮助的,但不是必需的。 通过这个项目,我想更好地理解其中哪些目标是赢得英雄联盟游戏最重要的目标。 就此而言,我提出的问题如下:
What objectives are the most important win conditions for a game of League of Legends?
什么目标是英雄联盟游戏最重要的获胜条件?
收集数据 (Gathering Data)
Jumping in, I first applied for an app with the Riot Developer Portal and after my app was accepted, I browsed through the APIs tab to understand the type of data I could request. Unfortunately, there wasn’t a direct way for me to pull the last X number of ranked matches from a region, so I had to figure out a way around this.
进入时,我首先向Riot Developer Portal申请了一个应用程序,当我的应用程序被接受后,我浏览了API选项卡以了解可以请求的数据类型。 不幸的是,我没有直接的方法从一个区域中获取最近的X个排名比赛,因此我不得不想办法解决这个问题。
My solution was to use a list of summoner names (usernames) to generate a list of recent matches for each player. Through a series of calls to the Riot API using the Python package Riot-Watcher, I populated a Pandas DataFrame of slightly under 10,000 rows with the most recent ranked League of Legends games played by the top 100 players in each of the five regions that make up the largest amount of the League of Legends player base. At a glance, the DataFrame looks something like this:
我的解决方案是使用召唤者名称(用户名)列表为每个玩家生成最近的比赛列表。 通过使用Python软件包Riot-Watcher对Riot API的一系列调用,我为一个熊猫行DataFrame填充了略少于10,000行的数据,其中包括五个区域中每个区域的前100名玩家所玩的最新排名的英雄联盟游戏最多的英雄联盟玩家群。 乍一看,DataFrame看起来像这样:
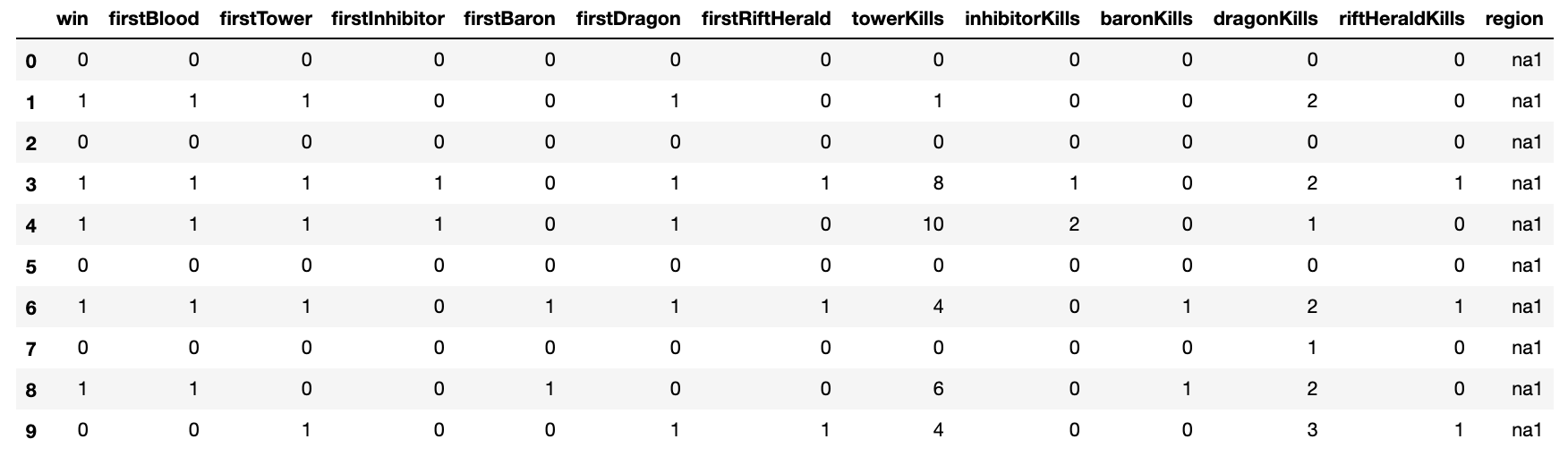
In the first seven columns, a 0 indicated ‘False’ and a 1 indicated ‘True’, while in the later columns, the data encoded in the cell indicated the number of times that event occurred. Each row contained the stats of one team in a League of Legends ranked match. For example, in the first row, the team that did not acquire any objectives first and at all lost the overall game.
在前七个列中,0表示“ False”,而1表示“ True”,而在后面的列中,在单元格中编码的数据表示事件发生的次数。 每行包含英雄联盟排名比赛中一支球队的数据。 例如,在第一行中,首先没有获得任何目标的团队根本就输掉了整个比赛。
利用热图和PCA进行探索性数据分析 (Exploratory Data Analysis with Heat Map and PCA)
I first found that around 91% of winning teams destroyed the first inhibitor, 80% killed the first baron, 70% destroyed the first tower, 63% killed the first dragon, and 59% of winning teams began the game with First Blood. Already, it seemed like the most important win condition is destroying the first inhibitor, which makes sense, as destroying a team’s inhibitor puts pressure on their base and allows the opposing team to have more map control.
我首先发现,大约91%的获胜团队摧毁了第一个阻碍者,80%杀死了第一只男爵,70%摧毁了第一座塔,63%杀死了第一只龙,59%的获胜团队开始了First Blood游戏。 似乎最重要的获胜条件是摧毁第一个抑制器,这是有道理的,因为破坏团队的抑制器会给他们的基础施加压力,并允许对方的团队拥有更多的地图控制权。
Next, I visualized the correlation across columns in my dataset:
接下来,我可视化数据集中各列之间的相关性:
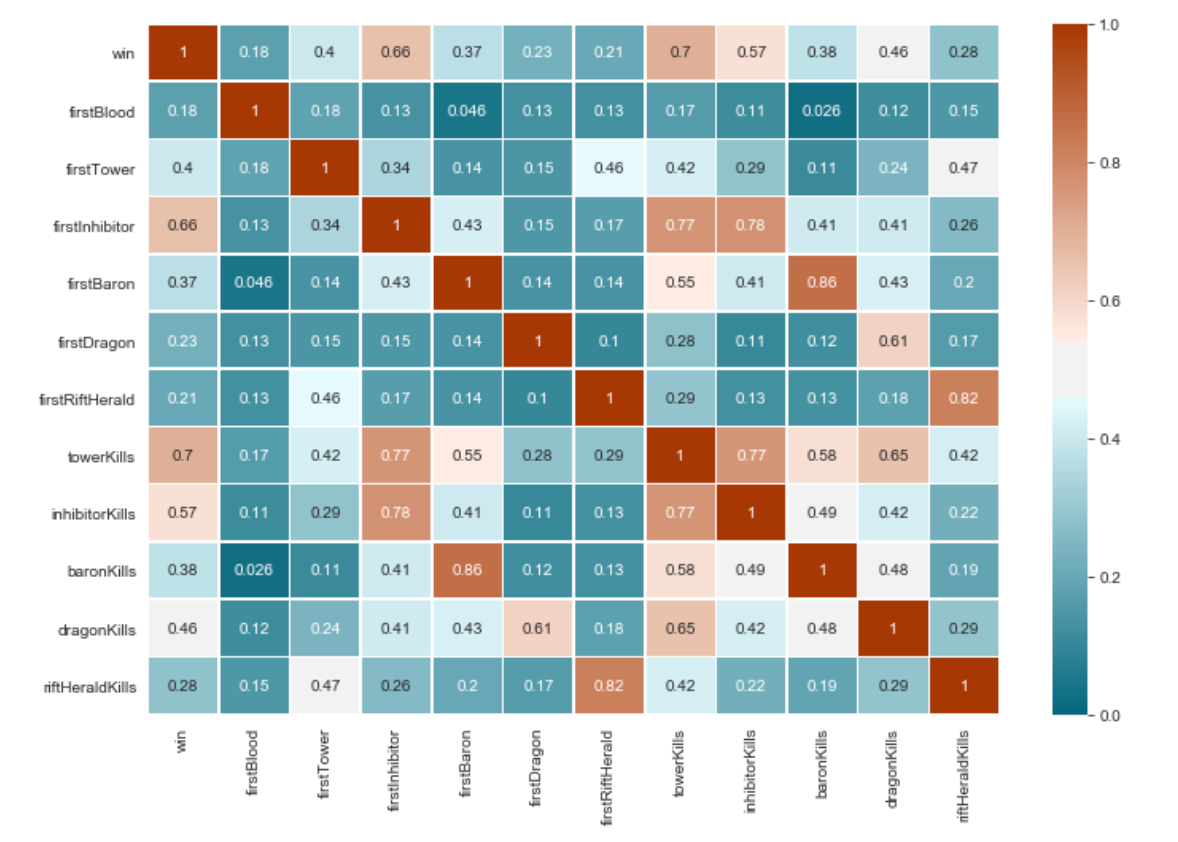
I also pulled up the same correlation heat maps for each individual region represented in my data to compare correlations across different regions, hoping to notice some differences in play styles. Generally though, the correlation matrices looked very alike each other. A possible reason for this is that my data included matches played by the best players of each region, many of whom play on a professional level. Therefore, since good gameplay practices are consistent among the competitive community, the matches represented in my data involve players who navigate each game similarly relative to lower ranked players of each region.
我还为数据中表示的每个单独区域绘制了相同的相关热图,以比较不同区域之间的相关性,希望注意到游戏风格上的一些差异。 通常,尽管相关矩阵看起来彼此非常相似。 造成这种情况的可能原因是,我的数据包括每个地区的最佳球员所打的比赛,其中许多人都是职业球员。 因此,由于良好的游戏习惯在竞争社区之间是一致的,因此我数据中所代表的比赛涉及相对于每个地区的排名较低的玩家相似地浏览每个游戏的玩家。
I was now curious to see how well the variance in the data could be explained by fewer features than the ten I would be using to predict the outcome of a game. To that extent, I performed a Principal Component Analysis to understand how many features I could simplify my data into and still preserve most of the variance:
我现在很想知道,用比我用来预测游戏结果的十个特征更少的特征可以很好地解释数据的差异。 在那种程度上,我进行了主成分分析,以了解我可以将数据简化为多少并仍然保留大部分差异的功能:
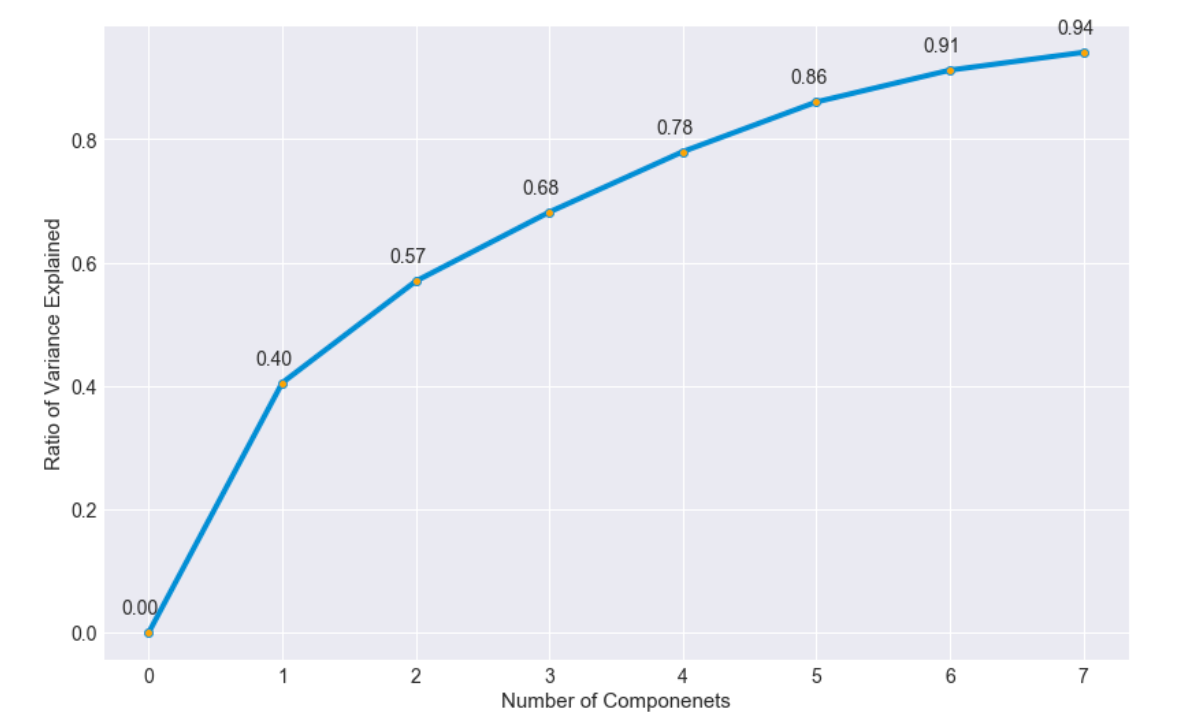
Over 80% of the variance in the ten predictor columns could be explained by half the amount of features. This was definitely interesting, and by associating each component with the original dataset’s columns, I hoped to understand which features were the most important in explaining the variance of the data, which could help me figure out which columns were most critical to whether or not a team would win.
十个预测变量列中超过80%的方差可以用特征量的一半来解释。 这绝对很有趣,并且通过将每个组件与原始数据集的列相关联,我希望了解哪些功能在解释数据差异时最重要,这可以帮助我确定哪些列对于团队会赢。
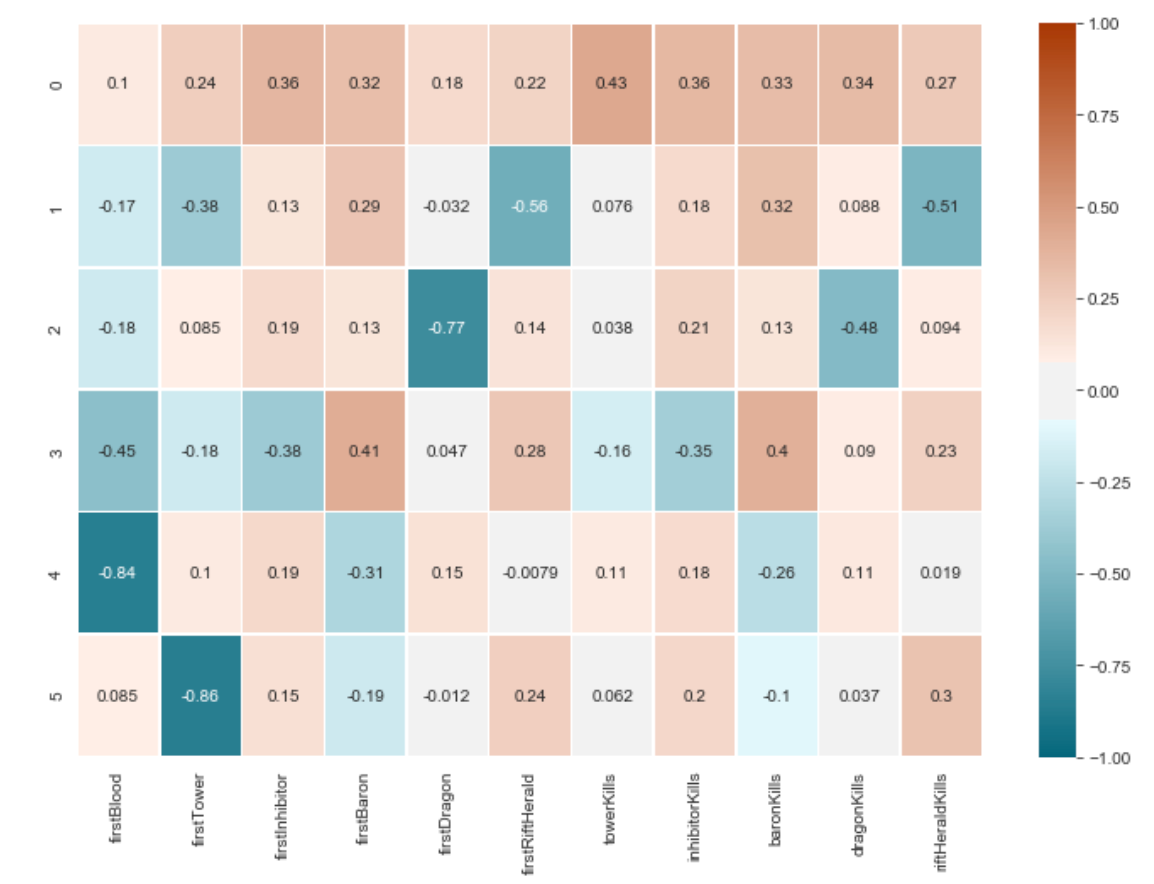
The components that were used to generate the above heat map were from a PCA object with six components, as I wanted the components to explain more than 90% of the variance in the data. It appeared that the number of tower kills, inhibitor kills, and whether or not a team destroyed the first inhibitor were the most important features in determining variance in the data, as the first component explained 40% of the variance and the three aforementioned columns were weighted the most for this component.
用于生成上述热图的组件来自具有六个组件的PCA对象,因为我希望这些组件能够解释数据中90%以上的方差。 在确定数据差异时,塔式杀伤,抑制剂杀伤的数量以及团队是否破坏了第一个抑制剂似乎是决定数据差异的最重要特征,因为第一部分解释了差异的40%,而上述三列为该组件权重最大。
To reiterate the insights I had gathered at this point:
为了重申我在这一点上收集到的见解:
- From my correlation heat map, whether or not a team destroyed the first inhibitor, how many tower kills a team had, and how many inhibitors a team had destroyed all had the highest correlation with winning. 从我的相关性热图中,一个团队是否消灭了第一个阻碍者,一个团队杀死了多少塔楼杀手以及一个团队消灭了多少个阻碍者都与获胜相关性最高。
- From my PCA analysis, whether or not a team destroyed the first inhibitor, how many tower kills a team had, and how many inhibitors a team had destroyed played the largest role in explaining the variance in the data. 根据我的PCA分析,一个团队是否销毁了第一个抑制器,一个团队杀死了多少塔楼杀手以及一个团队销毁了多少个抑制器在解释数据差异方面发挥了最大作用。
Logistic回归的数据建模 (Data Modeling with Logistic Regression)
I used a Logistic Regression model to understand the win conditions for a ranked match of League of Legends. My process was to first split my data into a set of features and a set of targets, where my features were all the columns except for the ‘win’ and ‘region’ columns, and my target was the ‘win’ column. I then split my data into a train set and a test set, ran them through a Logistic Regression model, and checked the classification report and confusion matrix to ensure a relatively strong predictive ability. When the Logistic Regression model was run on the overall dataset, the model’s precision and recall were .86 and .85 respectively.
我使用Logistic回归模型来了解英雄联盟排名比赛的获胜条件。 我的过程是首先将数据分为一组功能和一组目标,其中我的功能是除“ win”和“ region”列之外的所有列,而我的目标是“ win”列。 然后,我将数据分为训练集和测试集,并通过Logistic回归模型进行了分析,并检查了分类报告和混淆矩阵,以确保具有较强的预测能力。 在整体数据集上运行Logistic回归模型时,该模型的精度和召回率分别为0.86和.85。
From here, I performed Logistic Regression on subsets of the data that included only one region, such as matches that were only played in NA, BR, etc., and recorded the model’s coefficients in a Pandas DataFrame. This DataFrame was then visualized so I could compare the different regions:
从这里开始,我对仅包含一个区域的数据子集(例如仅在NA,BR等中进行的比赛)执行了Logistic回归,并将模型的系数记录在Pandas DataFrame中。 然后将此DataFrame可视化,因此我可以比较不同的区域:
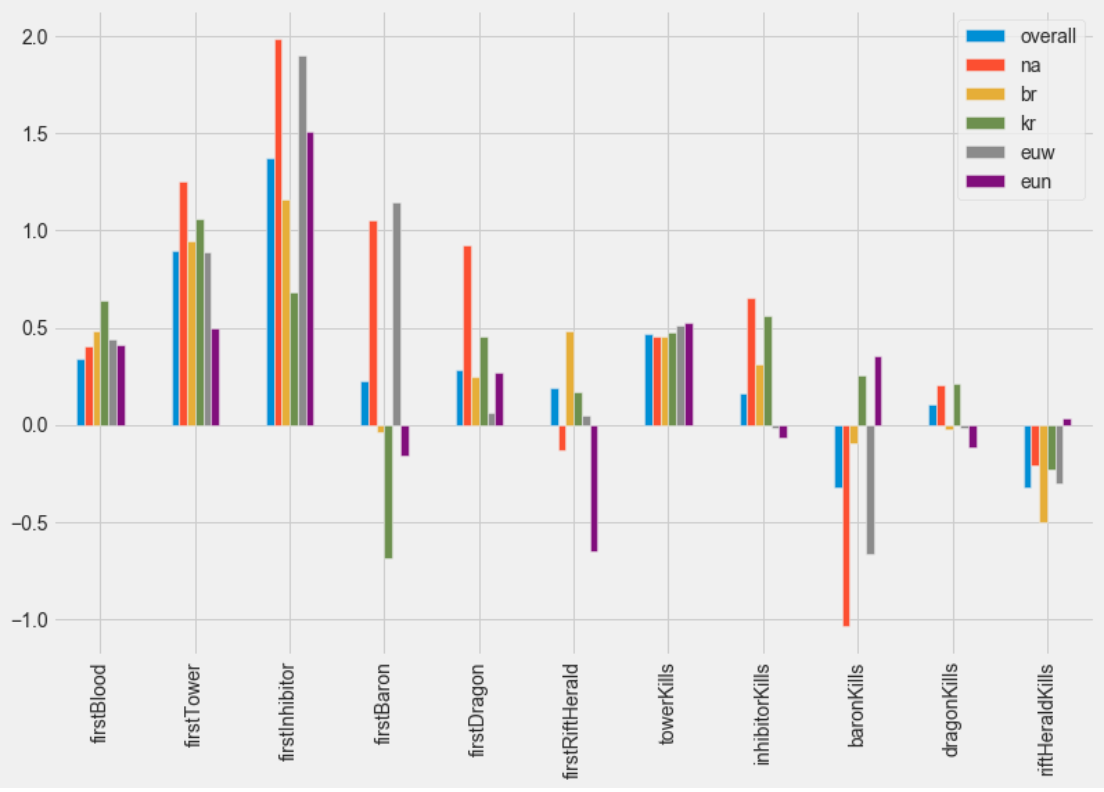
Regression coefficients describe the relationship between a predictor variable and the target variable. For example, when looking at the First Blood predictor variable above, a team getting First Blood was a moderate predictor for the outcome of the game, as a team that achieves First Blood is more likely to win. On the other hand, Rift Herald Kills were actually related in the opposite direction (except for EUNE), and teams that get more Rift Herald Kills are more likely to lose.
回归系数描述了预测变量和目标变量之间的关系。 例如,当查看上面的“第一血液”预测变量时,获得“第一血液”的团队是比赛结果的中度预测因子,因为获得“第一血液”的团队更有可能获胜。 另一方面,Rift Herald Kills实际上是相反的方向(EUNE除外),获得更多Rift Herald Kills的球队更有可能输掉比赛。
Using this analytical process, I understood which columns were more predictive of a win, helping me answer my question regarding win conditions in a game of League of Legends.
通过这种分析过程,我了解了哪些列更能预测获胜,从而帮助我回答了有关英雄联盟游戏中获胜条件的问题。
结论 (Conclusion)
As a result of my project, here are the conclusions I made:
作为我的项目的结果,以下是我得出的结论:
- In order of greatest to least, First Inhibitor, First Tower, and Tower Kills were the most important win conditions across the dataset, according to my Logistic Regression model. 根据我的逻辑回归模型,从最大到最小的顺序,First Inhibitor,First Tower和Tower Kills是整个数据集中最重要的获胜条件。
- In order from greatest to least, Tower Kills, First Inhibitor, and Inhibitor Kills were the most important win conditions across the dataset, according to my correlation heat map. 根据我的相关热图,从最大到最小的顺序,塔式杀手,第一抑制剂和抑制剂杀手是整个数据集中最重要的获胜条件。
- Although NA and EUW teams that get the first baron were more likely to win, teams in these regions were more likely to lose with increasing numbers of baron kills. 尽管获得第一名男爵的NA和EUW球队更有可能获胜,但随着男爵杀人次数的增加,这些地区的球队更有可能输掉比赛。
- The fact that teams in NA were more likely to win off a First Dragon compared to other regions perhaps indicates that games in NA were more prone to snowballing (when a team expands on a small advantage over the game to win) from dragon buffs and fights around dragon. 与其他地区相比,北美地区的球队更有可能赢得“第一龙”冠军,这可能表明北美地区的比赛更容易因打龙和打架而滚雪球(当一支球队扩大了对比赛的优势时)在龙周围。
- KR games weren’t unevenly impacted by one feature. This could indicate that KR players understand how to play from behind better than players in other regions, prompting a team to win off a combination of objectives more often than in other regions. KR游戏并不受一项功能的影响。 这可能表明KR玩家比其他地区的玩家更了解如何从背后进行比赛,这促使团队比其他地区的玩家更经常实现目标组合。
If there are any other interesting observations you think I missed out on, let us know in the comments!
如果您认为我错过了其他有趣的观察,请在评论中告诉我们!
The GitHub repository that contains my code and the dataset I put together for this analysis can be found here.
可以在此处找到包含我的代码和为分析而放在一起的数据集的GitHub存储库。
翻译自: https://towardsdatascience.com/league-of-legends-win-conditions-db139f1ed6ca
srpg 胜利条件设定