Hibernate源码分析_hibernate 源码类关系-程序员宅基地
技术标签: Java Hibernate null session callback insert hibernate sql
这段时间本人利用空闲时间解读了一下Hibernate3的源码,饶有收获,愿与大家共享。
废话不多说,首先我们先对Hibernate有一个大致的印象
l 设计模式Hibernate=监听器,实际上是回调
l Hibernate3支持拦截器
Hibernate配置方面的大原则:
l bhn.xml文件所有配置都是描述本实体,除了cascade描述级联,即如何将本实体的操作(增删查改)传递给关联方。
l inverse属性表示本实体是否拥有主动权,在一条cascade链路传递过程中,当出现inverse=false表示不再返回原cascade链路,而是从此处重新开始链路。inverse只有在非many方才有,也就是many-to-many或者one-to-many的set,List等。
下面是注明inverse=true与inverse=false的cascade链路的区别:
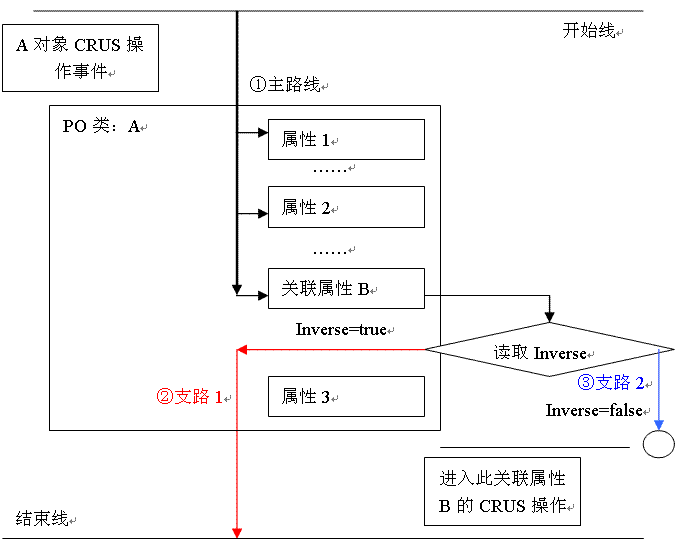
说明:若关联属性inverse=true,操作的结果将是校对A的属性所生成的sql;若关联属性inverse=false,结果将是丢弃先前A的操作,而转向对B的属性的校验所生成的sql;如果B中的属性也关联着inverse=false,则仍丢弃B继续新开启链路,直至没有关联方为inervse=false。不必担心,关联着的双方只有一方拥有inverse属性,所以不会一直传递下去。还有,丢弃了先前的操作不等于之前的对象操作无效,其效果相当于,原先的session.save(A),变成了session(A.B)而在B校对属性时总会找回A对象的。
测试用例:(暂不考虑inverse=false)
测试1:save()一个实体对象操作,预计insert发生在拥有外键方的表,拥有外键方的表是一对多中的多方。
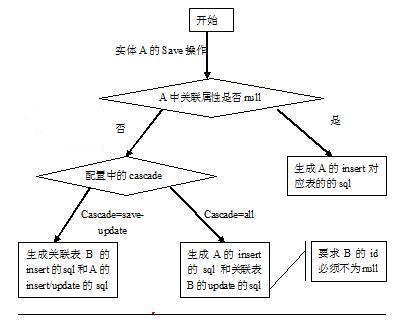
结论1:如果实体对象的外键属性为null,表示不会产生关联,可直接生成sql;如果外键属性不为空,根据配置中的cascade去做关联。如果cascade=all则生成此表的insert和关联表update的sql,也就是说此时要求关联属性的主键id不能为null;如果cascade=save-update则生成此表的insert和关联表的insert/update的sql(关键属性的主键为null为insert,否则为update)。
见下图:
举例说明:
---------PO类:A中有B类型的关联属性
class A{
private int id;
private B b;
}
class B{
private int id;
private String str;
}
---------调用处关键代码:
A a=new A();//待操作的实体对象
B b=new B();//关联属性
a.setB(b);//设置关联属性
//----
//a.setId(1);//save()操作不允许预定一个id,hibernate的Id必须使用配置中的方式生成
//a.setB(null);//关联属性为null
//----
b.setId(1);/*关联属性的主键有值。只有cascade链在B对象校验为update操作才有效,也就是说A.bhn.xml中B
*的级联设为cascade=save-update。*/
b.setId(null);/*关联属性的主键为null。支持cascade=all与cascade=save-update的操作,最终在B生成的
* 是insert操作*/
//--------
b.setStr("当前用于测试");//------数据项
//-------操作
session.save(a);
源码解读:(粗略)
Hibernate主要是事件监听模式(回调的一种实现),其核心类为Session类,Session类承载了CRUS操作和Commit操作。
补充知识点:回调的好处在于事件源对象eventSource和数据对象Object,被集中在监听器Listener里完成业务,集中的好处在于新写Listener就可以达到功能的扩展。Listener的处理方法的参数为,事件对象eventObject,事件对象包含事件源eventSource和数据对象,相当于Listener传的是两个参数,也就是说Listener得到了此数据模型中的所有数据,自然可以完成任何功能,其余部分在模型中可理解为仅是为了给Listener传参做准备。通常的运行流程是事件源先被调用方法,所以事件源的方法里完成了业务功能,所谓回调就是形式上还是调用了事件源的方法,但是业务功能的代码却在第三方的Listener类中完成,而事件源的方法里只是为了实现如何传参给Listener。这样就像是与传统编程相反由Listener去调用事件源。
案例1:Session的S查询操作
过程略:
小结:Hibernate的Select操作直接生成sql,当然通过了内存缓存才生成的sql。
案例2:Session调用CRU操作(非S操作,增删改)。
以Save()操作为例
步骤1. SessionImpl.save(obj); SessionImpl.save(null,obj);--从save(Object,Object)统一调用
步骤2. new SaveOrUpdateEvent(entityName, object, this)—创建并组装事件对象(用于Listener的参数)
步骤3. SessionImpl.fireSave(SaveOrUpdateEvent);--触发事件,即调用Listener的处理方法,目的在于传参步骤2中new出的SaveOrUpdateEvent事件对象。
代码如下:
private Serializable fireSave(SaveOrUpdateEvent event) {
errorIfClosed();
checkTransactionSynchStatus();
SaveOrUpdateEventListener[] saveEventListener =listeners.getSaveEventListeners();
for ( int i = 0; i < saveEventListener.length; i++ ) {
saveEventListener[i].onSaveOrUpdate(event);
}
return event.getResultId();
}
红色为关键代码,其中listeners为Session的EventListeners属性。
EventListeners包含有一系列的监听器,而各种监听器以数组的形式允许有多个并且按顺序调用。本例中调用的监听器种类为saveOrUpdateEventListeners,处理方法为onSaveOrUpdate()方法。实现onSaveOrUpdate(event)的类是DefaultSaveOrUpdateEventListener。所以业务实现代码应该在DefaultSaveOrUpdateEventListener.onSaveOrUpdate()中
EventListeners类中的一系列Listener []属性:
private LoadEventListener[] loadEventListeners = { new DefaultLoadEventListener() };
private SaveOrUpdateEventListener[] saveOrUpdateEventListeners = { newDefaultSaveOrUpdateEventListener() };
private MergeEventListener[] mergeEventListeners = { newDefaultMergeEventListener() };
private PersistEventListener[] persistEventListeners = { newDefaultPersistEventListener() };
private PersistEventListener[] persistOnFlushEventListeners = { newDefaultPersistOnFlushEventListener() };
private ReplicateEventListener[] replicateEventListeners = { newDefaultReplicateEventListener() };
private DeleteEventListener[] deleteEventListeners = { newDefaultDeleteEventListener() };
private AutoFlushEventListener[] autoFlushEventListeners = { newDefaultAutoFlushEventListener() };
private DirtyCheckEventListener[] dirtyCheckEventListeners = { newDefaultDirtyCheckEventListener() };
private FlushEventListener[] flushEventListeners = { newDefaultFlushEventListener() };
private EvictEventListener[] evictEventListeners = { newDefaultEvictEventListener() };
private LockEventListener[] lockEventListeners = { new DefaultLockEventListener() };
private RefreshEventListener[] refreshEventListeners = { newDefaultRefreshEventListener() };
private FlushEntityEventListener[] flushEntityEventListeners = { newDefaultFlushEntityEventListener() };
private InitializeCollectionEventListener[] initializeCollectionEventListeners =
{ new DefaultInitializeCollectionEventListener() };
步骤4. DefaultSaveOrUpdateEventListener.onSaveOrUpdate()----业务功能代码。由于方法的实现涉及内容比较多,此处暂不作详细介绍。大致功能有为了补充齐全SaveOrUpdateEvent事件对象的其他属性,可见事件对象是记录Hibernate操作过程的容器。
步骤5.根据我们提交给Hibernate的Session的CRU指令操作,重复步骤1到步骤4多次直到最后到tran.commit()操作,tran是Session开启的Transction对象,默认JDBCTransction实现,根据hibernate.cfg.xml中配置确定了在new Configuration().configure()创立的,假定JDBCTransction.commit()的实现,具体代码如下:
public void commit() throws HibernateException {
if (!begun) {
throw new TransactionException("Transaction not successfully started");
}
log.debug("commit");
if ( !transactionContext.isFlushModeNever() && callback ) {
transactionContext.managedFlush(); //if an exception occurs during flush, user must call rollback()
}
notifyLocalSynchsBeforeTransactionCompletion();
if ( callback ) {
jdbcContext.beforeTransactionCompletion( this );
}
try {
commitAndResetAutoCommit();
log.debug("committed JDBC Connection");
committed = true;
if ( callback ) {
jdbcContext.afterTransactionCompletion( true, this );
}
notifyLocalSynchsAfterTransactionCompletion( Status.STATUS_COMMITTED );
}
catch (SQLException e) {
log.error("JDBC commit failed", e);
commitFailed = true;
if ( callback ) {
jdbcContext.afterTransactionCompletion( false, this );
}
notifyLocalSynchsAfterTransactionCompletion( Status.STATUS_UNKNOWN );
throw new TransactionException("JDBC commit failed", e);
}
finally {
closeIfRequired();
}
}
其中红色部分是生成sql的方法,这里暂不展开说明,生成sql依据的是上面步骤1-4所补充完整的事件对象。
绿色部分是Hibernate3对拦截器的支持,我们都知道Hibernate3比较之前的版本的一个重要的新特性就是支持拦截器,而这一特性就体现在此处。
小结:Session的非查询操作,只有到tran.commit()才生成sql,期间所有的CRU操作的结果都存放到对应的EventObject对象,对于保存C操作和更改U操作都存放在SaveOrUpdateEvent,删除操作R存放在DeleteEvent,而后commit()完成所有EventObject生成sql的规则。
各种操作与相应的流程如下面:
| 操作/流程 |
入口 |
创建事件对象 |
触发事件 |
事件处理方法 |
| save |
SessionImpl.save() |
new SaveOrUpdateEvent() |
fireSave() |
DefaultSaveOrUpdateEventListener |
| update |
SessionImpl.update() |
new SaveOrUpdateEvent() |
fireUpdate() |
DefaultSaveOrUpdateEventListener |
| Delete |
SessionImpl.delete() |
new DeleteEvent() |
fireDelete() |
DefaultDeleteEventListener |
补充:所有业务处理监听器都在org.hibernate.event.def包下
总结:
1.save操作:commit()时,数据库执行,并增加缓存中的对象。
2.delete操作:要求含有主键,commit()时,数据库执行,并删除缓存中的对象。
如果删除执行记录数无影响,即没有找到要删除的记录,报错。
3.Select操作:直接查询数据库,更新缓存中的对象。
4.update操作:要求含有主键,commit()时,数据库执行,并更新缓存中的对象。
如果更新执行记录数无影响,即没有找到要修改的记录,报错。
使用Hibernate时需要确定表的结构,只有确定了表的结构才能确定表的执行顺序,虽然Hibernate的目地是让我们编程只关心要操作对象,但是我们要明白维护(cascade链路方向)的方向是单向的,即使我们说Hibernate支持双向关联。
-
维护方向是cascade和inverse配置出来的,Hibernate会遵循配置,去生成sql;
-
另外所谓的双向关联只不过是维护方向单向查询出所关联的对象而后在内存中进行回填。如,User:Address=1:1,双向关联的目标是查询User对象,可得到User=User.getAddress().getUser()的结果,Hibernate的实现是单向查询得到User即关联属性Address对象,而后User.getAddress().setUser(User)进行回填。
SessionImpl==EventSource 事件源
SaveOrUpdateEvent==Event事件对象
智能推荐
Failed to discover available identity versions when contacting http://controller:35357/v3. 错误解决方式_caused by newconnectionerror('<urllib3.connection.-程序员宅基地
文章浏览阅读8.3k次,点赞5次,收藏12次。作为 admin 用户,请求认证令牌,输入如下命令openstack --os-auth-url http://controller:35357/v3 --os-project-domain-name default --os-user-domain-name default --os-project-name admin --os-username admin token issue报错Failed to discover available identity versions whe._caused by newconnectionerror('
学校机房统一批量安装软件的方法来了_教室电脑 一起装软件-程序员宅基地
文章浏览阅读4.5k次。可以在桌面安装云顷还原系统软件,利用软件中的网络对拷功能部署批量对拷环境,进行电脑教室软件的批量对拷安装与增量对拷安装。_教室电脑 一起装软件
消息队列(kafka/nsq等)与任务队列(celery/ytask等)到底有什么不同?_任务队列和消息队列-程序员宅基地
文章浏览阅读3.1k次,点赞5次,收藏7次。原文链接:https://www.ikaze.cn/article/43写这篇博文的起因是,我在论坛宣传我开源的新项目YTask(go语言异步任务队列)时,有小伙伴在下面回了一句“为什么不用nsq?”。这使我想起,我在和同事介绍celery时同事说了一句“这不就是kafka吗?”。那么YTask和nsq,celery和kafka?他们之间到底有什么不同呢?下面我结合自己的理解。简单的分析一..._任务队列和消息队列
Java调KT类_java 调用kt 对象-程序员宅基地
文章浏览阅读1.5k次。1,MyUtuils.kt将被调用的文件class MyUtils { fun show(info:String){ println(info) }}fun show(info:String){ println(info)}2,Java文件调用该类,ClientJava.javapublic class ClientJava { public static void main(String[] args) { /** _java 调用kt 对象
UDP报文最大长度_最大请求报文大小-程序员宅基地
文章浏览阅读6.6k次,点赞4次,收藏4次。在进行UDP编程的时候,我们最容易想到的问题就是,一次发送多少bytes好? 当然,这个没有唯一答案,相对于不同的系统,不同的要求,其得到的答案是不一样的,我这里仅对 像ICQ一类的发送聊天消息的情况作分析,对于其他情况,你或许也能得到一点帮助: 首先,我们知道,TCP/IP通常被认为是一个四层协议系统,包括链路层,网络层,运输层,应用层. UDP属于运输层_最大请求报文大小
Windows CMD命令行程序中 无限死循环 执行一段命令_cmd装比代码无限循环-程序员宅基地
文章浏览阅读10w+次,点赞14次,收藏18次。代码如下:for /l %a in (0,0,1) do echo hello,world粘贴在cmd命令行窗口中,回车即可无限死循环输出hello,world。如果需要停止,可以按ctrl+c中断。解析通用形式:for /l %variable IN (start,step,end) DO command [command-parameters] 该集表示以增量形式从start到end的一个数字序列。具体到第一段代码,如果是 (0,0,1) 就是从0开始,每次增_cmd装比代码无限循环
随便推点
vue.js知识点-transition的钩子函数应用(实例展示)_transition 钩子-程序员宅基地
文章浏览阅读1.6k次。本小结通过transition的钩子函数实现小球半场动画头条-静敏的编程秘诀-vue教程合集知识点1:入场、出厂方法beforeEnter表示动画入场之前,此时,动画尚未开始,可以在beforeEnter中设置元素开始动画之前的起始样式enter表示动画开始之后的样式,这里可是设置小球完成动画之后的,结束状态enter(el,done)el:动画钩子函数的第一个参数:el,..._transition 钩子
MyBatis 多表映射及动态语句
主要梳理mybatis多表及动态使用
Qt 多线程基础及线程使用方式-程序员宅基地
文章浏览阅读2.9w次,点赞98次,收藏777次。文章目录Qt 多线程操作2.线程类QThread3.多线程使用:方式一4.多线程使用:方式二5.Qt 线程池的使用Qt 多线程操作应用程序在某些情况下需要处理比较复杂的逻辑, 如果只有一个线程去处理,就会导致窗口卡顿,无法处理用户的相关操作。这种情况下就需要使用多线程,其中一个线程处理窗口事件,其他线程进行逻辑运算,多个线程各司其职,不仅可以提高用户体验还可以提升程序的执行效率。Qt中使用多线程需要注意:Qt的默认线程为窗口线程(主线程):负责窗口事件处理或窗口控件数据的更新;子线程负责后台的业_qt 多线程
GQA分组注意力机制
【代码】GQA分组注意力机制。
android 耗电分析与性能优化-程序员宅基地
文章浏览阅读218次。1.官方的建议1.1 电池续航时间优化(Optimizing Battery Life)参考文章:优化电池使用时间已有中文的详细说明,此处做简要说明:(1)监控电池电量和充电状态(Monitoring the Battery Level and Charging State)通过系统广播,获取充电状态和电池电量的变化来调整数据更新等操作;如在充电时,更新数据及应用,在低电量时,减少更新频..._com.tencent.mm:exdevice
pytorch基础 神经网络构建-程序员宅基地
文章浏览阅读818次,点赞14次,收藏9次。计算e1=2.718,e5=148.413,e3=20.086,e1+e5+e3=171.217。“人/B 们/E 常/S 说/S 生/B 活/E 是/S 一/S 部/S 教/B 科/M 书/E ”给一段文字做分词标注,标注每个字对应的标号。图中是双向的三层 RNNs,堆叠多层的RNN网络,可以增加模型的参数,提高模型的拟合。双向的 RNN 是同时考虑“过去”和“未来”的信息,输入(黑色点)沿着黑色的实线箭。比如标签0将表示为([1,0,0,0,0,0,0,0,0,0]),标签3将表示为。