文本生成解码策略 Beam Search, top_k, temperature_`temperature` (=0) has to be a strictly positive f-程序员宅基地
技术标签: 人工智能
一、从Greedy Search到Beam Search
Greedy search是指在每个t时刻选择下一个词时,根据 wt=argmaxwP(w|w1:t−1)选择概率最高的词。
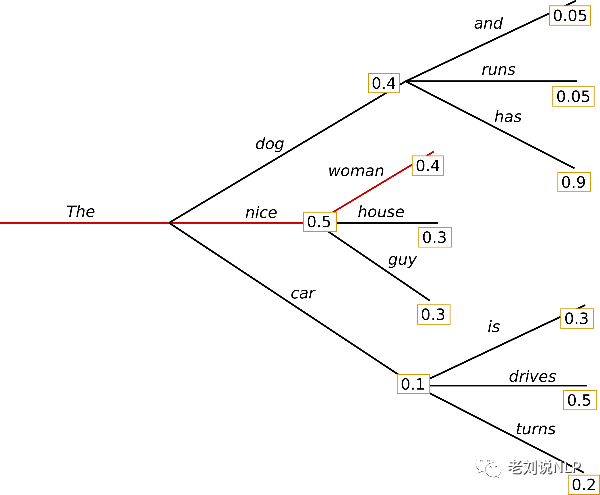
以上图为例:
从单词“The”开始,算法在选择下一个词时,贪心的选择了概率最高的“nice”,进而,最终的生成词序列为(“The”,“nice”,“woman”),总概率为0.5×0.4=0.2
文章《https://blog.csdn.net/jarodyv/article/details/128994176》中列举了一个有趣的例子:
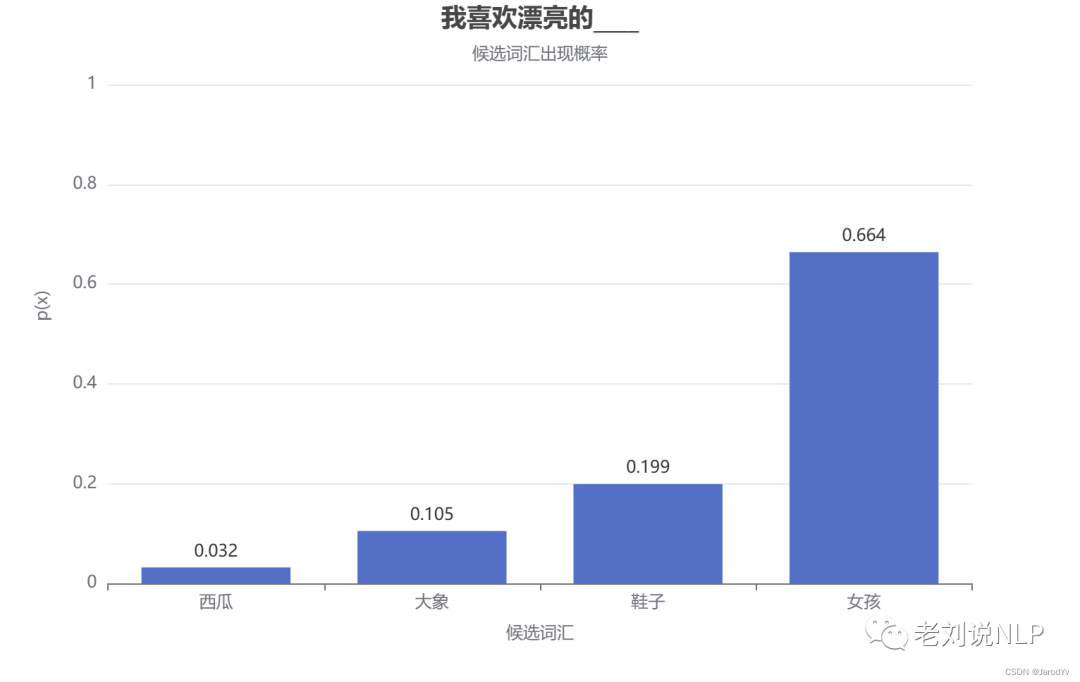
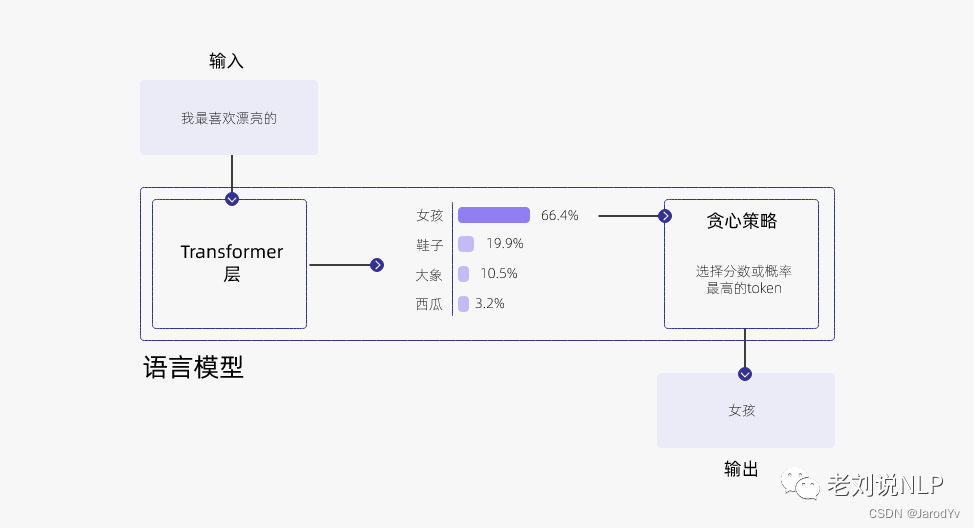
假设训练了一个描述个人生活喜好的模型,想让它来补全“我喜欢漂亮的___”这个句子。一般语言模型会按照下图的流程来工作:

模型会查看所有可能的单词,并根据其概率分布从中采样,以预测下一个词。
假设模型的词汇量不大,只有:“大象”、“西瓜”、“鞋子”和“女孩”。通过下图的词汇概率可以发现,“女孩”的选中概率最高(p=0.664),“西瓜”的选中概率最低(p=0.032)。
上面的例子中,很明显“女孩”最可能被选中,这就是 “贪心策略”,永远选择分数或概率最大的token,
Greedy Search存在的一个最大的问题在于,只考虑了当前的高概率词,忽略了在当前低概率词后面的高概率词,还是这个例子,词“has”在词“dog”后面,条件概率高达0.9,但词“dog”的条件概率只排第二,所以greedy search错过了词序列“The”、“dog”、“has”。
具体实现:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
因此,为了避免错过隐藏的高概率词,Beam Search通过参数num_beams的配置,可以在每个时刻,记录概率最高的前num_beams个路径,在下一个时刻可以有多个基础路径同时搜索。
以num_beams=2为例,我们看下原理图:
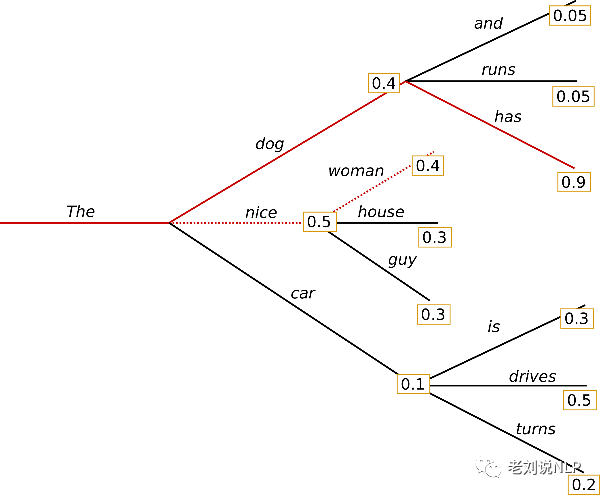
可以看到:
在t=1时,最大概率的路径是(“The”、“nice”),beam search同时也会记录概率排第二的路径(“The”、“dog”)。
在t=2时,beam search也会发现路径(“The”、“dog”、“has”)有0.36的概率超过了路径(“The”、“nice”、“women”)的概率0.2。
因此,两条路径中,找到了概率最高的路径,得到了更为合理的答案。
beam search生成的词序列比greedy search生成的词序列的综合概率更高,但是也不能保证是概率最高的词序列。
具体实现:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
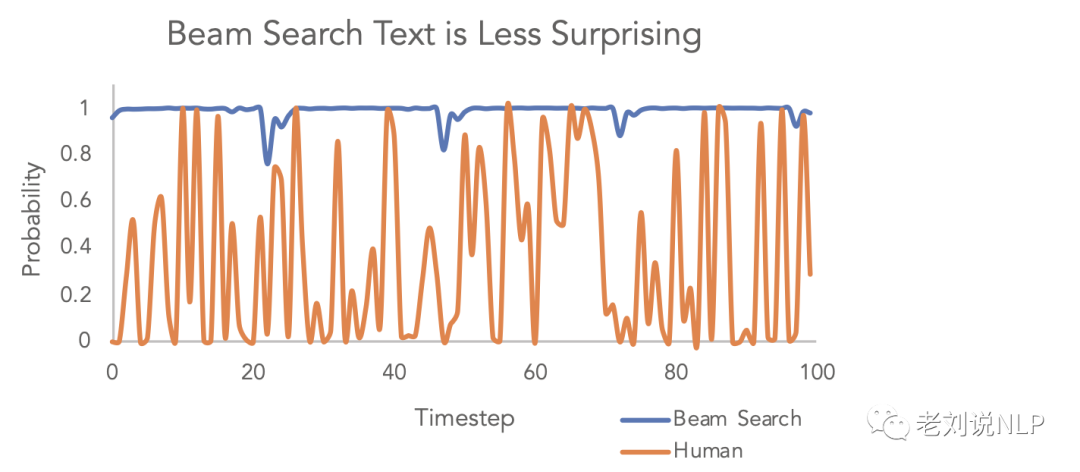
不过,在开放领域生成任务的很多时候,beam search都不是最好的解码方式:
首先,beam search在做像是翻译和摘要这类可以大致预测生成长度的场景中表现还可以Murray et al. (2018)、Yang et al. (2018)。但是在像是对话和故事生成这类开放生成领域效果就差得多了。
其次,我们已经看到beam search经常会生成重复内容,在故事生成中,我们很难决定要不要n-gram惩罚,因为我们很难确定强制不要重复还是有重复会更好。
最后,就是文首所提到的,高水平的人类语言不会按照下一个词条件概率最高的方式排列,所以就需要在此基础上优化采样方式。
二、从Beamsearch到Top-k固定采样
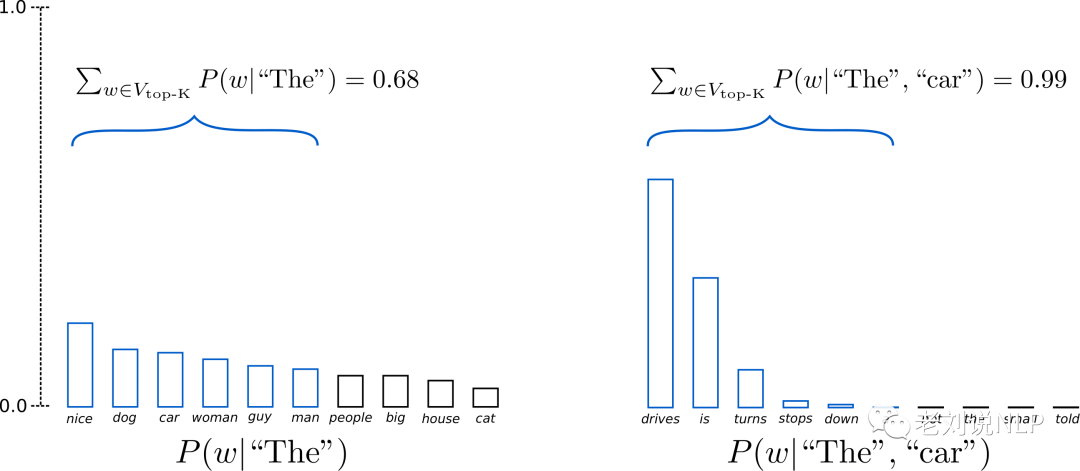
Beam Search每次会选择在Beam中最大概率的词汇,Top-k采样是对前面“贪心策略”的优化,它从排名前k的token种进行抽样,允许其他分数或概率较高的token也有机会被选中,以达到有一定机率不选最大概率的词,其核心思想在于:在解码的每个时间步从前k个概率最大的词中按它们的概率进行采样。
所以,我们称之为静态采样,如下图所示:
当K=6时,限制候选池是概率最高的前6个词,这6个词的集合被定义为Vtop−K。在第一轮他们占据全部概率的约2/3,而第二轮前6个词几乎占据了所有的概率。所以,我们避免了在第二轮生成奇怪的词,如(“not”、“the”、“small”、“told”、)。
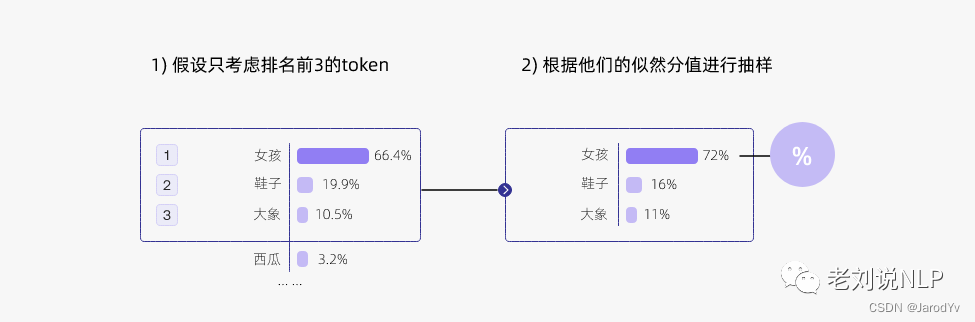
又如下图示例中,我们首先筛选似然值前三的token,然后根据似然值重新计算采样概率,通过调整k的大小,即可控制采样列表的大小。“贪心策略”其实就是k=1的top-k采样:
但Top-k采样有个很大的问题,Top-K sampling不会根据下一个词的概率分布 ,动态调整候选池的大小。当条件概率非常集中的时候,会更倾向于选择top-k中的词,而当条件概率非常分散的时候,就不能选中top-k以外的词,这其实也是我们进行LDA话题聚类,kmeans聚类中经常遇到的问题。有选大了可能会采样出长尾词,导致语句不通顺,选小了又退化成了Beam Search:

下面是具体实现:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# activate beam search and early_stopping
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# set top_k to 10
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=10
)
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
三、从Top-k固定采样到Top-p(Nucleus Sampling)动态采样
Top-k有一个缺陷,那就是“k值取多少是最优的”非常难确定。于是出现了动态设置token候选列表大小策略——即核采样(Nucleus Sampling)。
Nucleus Sampling,也称Top-p,在每个时间步,解码词的概率分布满足80/20原则或者说长尾分布,头部的几个词的出现概率已经占据了绝大部分概率空间,把这部分核心词叫做nucleus。
基于这样的观察,提出nucleus sampling,即给定一个概率阈值p,从解码词候选集中选择一个最小集Vp,使得它们出现的概率和大于等于p。然后再对Vp做一次re-scaling,本时间步仅从Vp集合中解码。
具体的,与限定在前K个词的采样不同的是,Top-p sampling会根据累计概率超过概率p时,从候选集选择个数最少的子集。通过这种方式,子集的大小可以动态的根据概率分布调整。
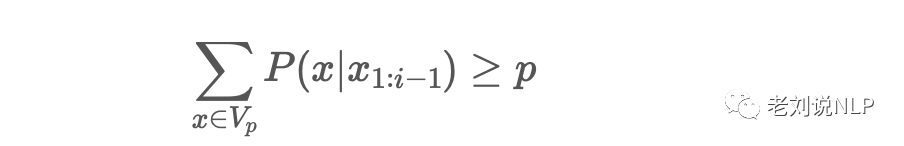
这样的好处在于在不同时间步,随着解码词的概率分布不同,候选词集合的大小会动态变化,不像top-k sampling是一个固定的窗口大小。由于解码词还是从头部候选集中筛选,这样的动态调整可以使生成的句子在满足多样性的同时又保持通顺。
如下图所示,当p=0.92时,top-p sampling选择了累计概率超过92%的最少个数的子集,记为Vtop−p。在t=1中,子集包含了9个最可能的词,在t-2时,子集为前3个词,累计概率就超过92%。
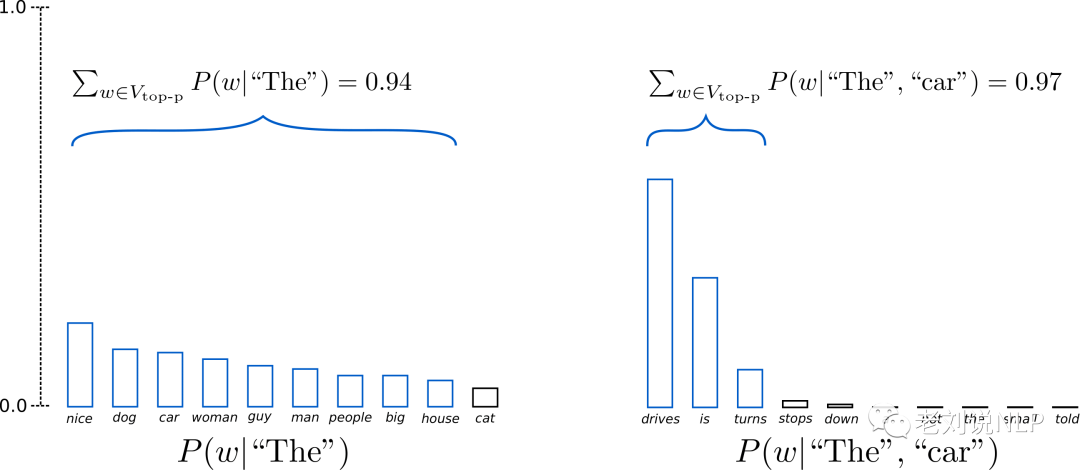
这也就说明,在条件概率分布分散,下一个词不易预测时,候选子集范围更大;在条件概率分布集中,下一个词容易预测时,候选子集范围更小。
下图更形象的展示了top-p值为0.9的Top-p采样效果:
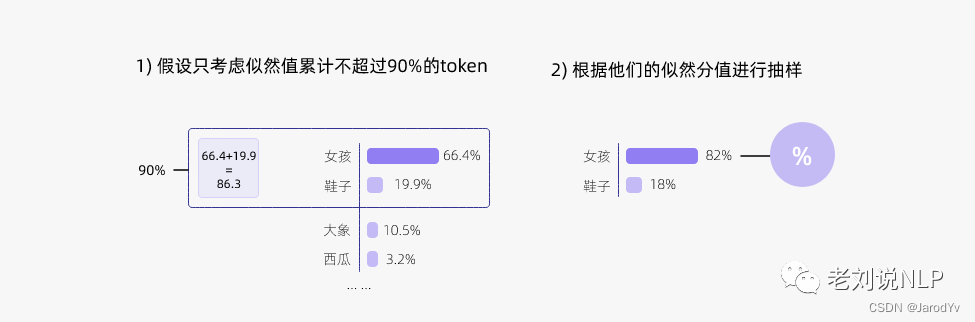
在top-p中,根据达到某个阈值的可能性得分之和动态选择候选名单的大小,top-p值通常设置为比较高的值,目的是限制低概率token的长尾。我们可以同时使用top-k和top-p。如果k和p同时启用,则p在k之后起作用。
下面是具体实现:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=3
)
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
四、从动态采样到概率侧重缩放:temperature温度采样
上面所说的topk, top_p都是在动态选择不同词的范围,但并没有更改实际词出现的概率,那么,是否可以在出现上概率上也进行调节呢?例如,将高频和低频之间的概率拉大或者减少,也能够对多样性提供一些思路。
因此,temperature温度采样方式被踢出,
在概率模型中,logits扮演着能量的角色,可以通过将logits除以温度来实现温度采样,然后将其输入Softmax并获得采样概率,就是直接re-scale原有的解码词分布:
越低的温度(<1)使模型会对高频的选择更为偏向,而高于1的温度,则会缩小高频词和低频词之间的差距。
温度采样中的温度与玻尔兹曼分布有关,其公式如下所示:
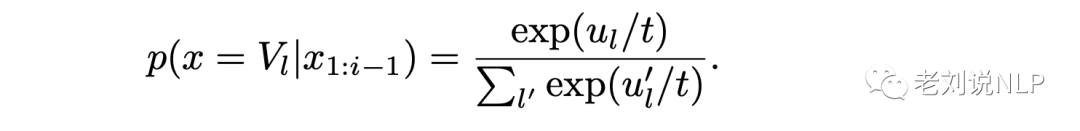
很相似,本质上就是在Softmax函数上添加了温度(T)这个参数。Logits根据我们的温度值进行缩放,然后传递到Softmax函数以计算新的概率分布。
其中t是一个超参数,取值范围[0,1),t的取值不同,解码词的概率分布也就更平缓或更两极分化。一定程度上也能通过设置不同的t达到与top-k sampling一样的效果。
下面是huggingface上的具体实现:
class TemperatureLogitsWarper(LogitsWarper):
r"""
:class:`transformers.LogitsWarper` for temperature (exponential scaling output probability distribution).
Args:
temperature (:obj:`float`):
The value used to module the logits distribution.
"""
def __init__(self, temperature: float):
if not isinstance(temperature, float) or not (temperature > 0):
raise ValueError(f"`temperature` has to be a strictly positive float, but is {temperature}")
self.temperature = temperature
[DOCS] def __call__(self, input_ids: torch.Tensor, scores: torch.Tensor) -> torch.Tensor:
scores = scores / self.temperature
return scores
同样的,我们以文章《https://blog.csdn.net/jarodyv/article/details/128994176》中举出的形象例子来理解下,
在“我喜欢漂亮的___”这个例子中,初始温度T=1,可以观察在出T取不同值的情况下,概率发生的变化:
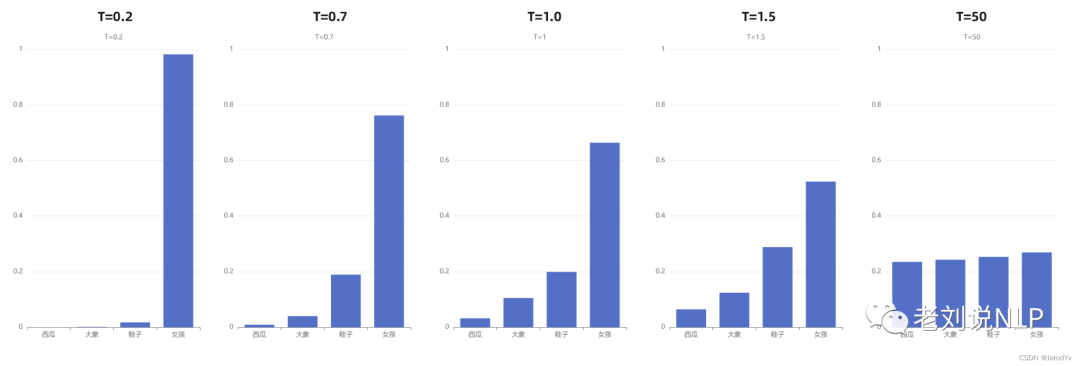
通过上图我们可以清晰地看到,随着温度的降低,模型愈来愈越倾向选择”女孩“;另一方面,随着温度的升高,分布变得越来越均匀。当T=50时,选择”西瓜“的概率已经与选择”女孩“的概率相差无几了。

下面是使用huggingface的具体例子
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=3,
temperature=1.5,
)
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
针对重复生成问题的ngrams重复惩罚机制
生成成模型在实际的运行过程中,总会出现一些重复的例子,这是高频词选择的结果。为了解决重复问题,一个简单的方法是用n-grams惩罚,来自论文Paulus et al. (2017)和Klein et al. (2017)。
其基本思想在于:通常的n-grams惩罚通过配置下一个词重复出现n-gram的概率为0,来保证没有n-gram出现两次,实现原理如下所示:
def calc_banned_ngram_tokens(prev_input_ids: Tensor, num_hypos: int, no_repeat_ngram_size: int, cur_len: int) -> None:
"""Copied from fairseq for no_repeat_ngram in beam_search"""
if cur_len + 1 < no_repeat_ngram_size:
# return no banned tokens if we haven't generated no_repeat_ngram_size tokens yet
return [[] for _ in range(num_hypos)]
generated_ngrams = [{} for _ in range(num_hypos)]
for idx in range(num_hypos):
gen_tokens = prev_input_ids[idx].tolist()
generated_ngram = generated_ngrams[idx]
for ngram in zip(*[gen_tokens[i:] for i in range(no_repeat_ngram_size)]):
prev_ngram_tuple = tuple(ngram[:-1])
generated_ngram[prev_ngram_tuple] = generated_ngram.get(prev_ngram_tuple, []) + [ngram[-1]]
def _get_generated_ngrams(hypo_idx):
# Before decoding the next token, prevent decoding of ngrams that have already appeared
start_idx = cur_len + 1 - no_repeat_ngram_size
ngram_idx = tuple(prev_input_ids[hypo_idx, start_idx:cur_len].tolist())
return generated_ngrams[hypo_idx].get(ngram_idx, [])
banned_tokens = [_get_generated_ngrams(hypo_idx) for hypo_idx in range(num_hypos)]
return banned_tokens
例如, 配置 no_repeat_ngram_size = 2时,可以使用huggingface加以实现:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
六、针对重复生成问题的RepetitionPenalty重复惩罚
除了grams重复惩罚志气,还可以通过惩罚因子将出现过词的概率变小或者强制不使用重复词来解决。
其核心思想在于:对于之前出现过的词语,在后续预测的过程中,通过引入惩罚因子降低其出现的概率。
惩罚因子来自于同样广为流传的《CTRL: A Conditional Transformer Language Model for Controllable Generation》。
scores为cur-step的词表分布[batch,seq,vocab_size],指的是候选词汇集中每个词汇的概率值,input_ids为输入decoder的文本序列[batch,seq],则score则是获取当前已经生成文本序列的token概率,减少已经出现的token的概率, 将减少后的概率重分配到原始的cur-step词表分布中。
class RepetitionPenaltyLogitsProcessor(LogitsProcessor):
r"""
:class:`transformers.LogitsProcessor` enforcing an exponential penalty on repeated sequences.
Args:
repetition_penalty (:obj:`float`):
The parameter for repetition penalty. 1.0 means no penalty. See `this paper
<https://arxiv.org/pdf/1909.05858.pdf>`__ for more details.
"""
def __init__(self, penalty: float):
if not isinstance(penalty, float) or not (penalty > 0):
raise ValueError(f"`penalty` has to be a strictly positive float, but is {penalty}")
self.penalty = penalty
[DOCS] def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
score = torch.gather(scores, 1, input_ids)
# if score < 0 then repetition penalty has to be multiplied to reduce the previous token probability
score = torch.where(score < 0, score * self.penalty, score / self.penalty)
scores.scatter_(1, input_ids, score)
return scores
其中,torch.gather(input,dim,index),input表示输入张量的值,dim表示输入张量的维度,index表示在维度上的具体索引。
torch.where()函数的作用是按照一定的规则合并两个tensor类型,例如,torch.where(a>0, a, b)表示满足条件返回a,否则返回b。
标准化的说,torch.where()函数的作用是按照一定的规则合并两个tensor类型。torch.where(condition,a,b)其中 输入参数condition:条件限制,如果满足条件,则选择a,否则选择b作为输出。注意:a和b是tensor.
>>> import torch
>>> a=torch.randn(3,5)
>>> a
tensor([[ 0.8416, 1.6152, -0.8635, -0.2283, -0.0522],
[-1.1139, 0.4552, 1.5567, 0.8376, 0.1232],
[-0.7011, 0.7474, -2.5362, 0.0333, -0.0081]])
>>> b=torch.ones(3, 5)
>>> b
tensor([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
>>> torch.where(a>0, a, b)
tensor([[0.8416, 1.6152, 1.0000, 1.0000, 1.0000],
[1.0000, 0.4552, 1.5567, 0.8376, 0.1232],
[1.0000, 0.7474, 1.0000, 0.0333, 1.0000]])
下面的score计算公式表述,如果score<0,那么score变成score * self.penalty,如果大与0,则变成score / self.penalty,目的是让其得分更小。
score = torch.where(score < 0, score * self.penalty, score / self.penalty)
同样的,我们可以使用huggingface对其进行实现:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
repetition_penalty=2,
early_stopping=True
)
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
七、看针对多样性生成中huggingface中还有那些实现策略
当然,为了保证多样性生成,还有很多其他参数控制策略,包括长度、badwords等,下面总结了其中的22个参数及其释义,其中加粗的可以重点看看。
1、temperature (float, optional, defaults to 1.0): 用于调节下一个标记概率的值。
2、top_k (int, optional, defaults to 50): 用于top-k过滤的最高概率词汇标记的数量。
3、top_p (float, optional, defaults to 1.0) : 如果设置为float < 1,则只保留概率加起来达到top_p或更高的最小的最有可能的词汇集合进行生成。
4、typical_p (float, optional, defaults to 1.0): 局部典型性衡量在已经生成的部分文本的情况下,预测下一个目标标记的条件概率与预测下一个随机标记的预期条件概率的相似程度。如果设置为float < 1,则保留最小的、概率相加为typical_p或更高的局部典型标记的集合,用于生成。
5、epsilon_cutoff (float, optional, defaults to 0.0):如果设置为严格介于0和1之间的float,只有条件概率大于epsilon_cutoff的标记会被采样。在论文中,建议的值在3e-4到9e-4之间,取决于模型的大小。
6、eta_cutoff (float, optional, defaults to 0.0): Eta采样是局部典型采样和ε采样的混合体。如果设置为严格介于0和1之间的浮点数,只有当一个标记大于eta_cutoff或sqrt(eta_cutoff) * exp(-entropy(softmax(next_token_logits)))时,才会考虑它。后者是预期的下一个令牌概率,以sqrt(eta_cutoff)为尺度。在论文中,建议值从3e-4到2e-3不等,取决于模型的大小。更多细节见截断抽样作为语言模型去平滑。
7、diversity_penalty (float, optional, defaults to 0.0): 如果一个beam路径得分在某一特定时间产生了与其他组的任何beam路径相同的标记,这个值将从beam的分数中减去。请注意,多样性惩罚只有在分组beam搜索被启用时才有效。
8、repetition_penalty (float, optional, defaults to 1.0) :重复性惩罚的参数。1.0意味着没有惩罚。
9、encoder_repetition_penalty (float, optional, defaults to 1.0):对不在原始输入中的序列进行指数式惩罚。1.0意味着没有惩罚。
10、length_penalty (float, optional, defaults to 1.0):对长度的指数惩罚,用于beam search。它作为指数被应用于序列的长度,反过来又被用来划分序列的分数。由于分数是序列的对数可能性(即负数),length_penalty > 0.0会促进更长的序列,而length_penalty < 0.0会鼓励更短的序列。
11、no_repeat_ngram_size (int, optional, defaults to 0):如果设置为int > 0,所有该大小的ngrams只能出现一次。
12、bad_words_ids(List[List[int]], optional): 不允许生成的token id的列表。为了获得不应该出现在生成的文本中的词的标记ID,使用tokenizer(bad_words, add_prefix_space=True, add_special_tokens=False).input_ids,这个能用于敏感词过滤。
13、force_words_ids(List[List[int]] or List[List[List[int]]], optional):必须生成的标记ID的列表。如果给定的是List[List[int]],这将被视为一个必须包含的简单单词列表,与bad_words_ids相反。如果给定的是List[List[List[int]]],这将触发一个disjunctive约束,即可以允许每个词的不同形式。
14、renormalize_logits (bool, optional, defaults to False) :在应用所有的logits处理器或warpers(包括自定义的)之后,是否要重新规范化logits。强烈建议将此标志设置为 "True",因为搜索算法假定分数对数是正常化的,但一些对数处理器或翘曲器会破坏正常化。
15、constraints (List[Constraint], optional): 可以添加到生成中的自定义约束,以确保输出将包含使用Constraint对象所定义的某些令牌,并尽可能以最合理的方式进行。
16、forced_bos_token_id (int, optional, defaults to model.config.forced_bos_token_id):强制作为解码器_start_token_id之后第一个生成的令牌的id。对于像mBART这样的多语言模型非常有用,在这种情况下,第一个生成的标记需要是目标语言的标记。
17、forced_eos_token_id (Union[int, List[int]], optional, defaults to model.config.forced_eos_token_id) :当达到max_length时,强制作为最后生成的令牌的id。可以选择使用一个列表来设置多个序列结束的标记。
18、remove_invalid_values (bool, optional, defaults to model.config.remove_invalid_values) - 是否删除模型的可能nan和inf输出,以防止生成方法崩溃。注意,使用remove_invalid_values会减慢生成速度。
19、exponential_decay_length_penalty (tuple(int, float), optional): 这个Tuple在生成一定数量的标记后,增加一个指数级增长的长度惩罚。该元组应包括: (start_index, decay_factor),其中start_index表示惩罚开始的位置,decay_factor表示指数衰减的系数。
20、suppress_tokens (List[int], optional) :一个在生成时将被抑制的标记的列表。SupressTokens的logit处理器将把它们的log probs设置为-inf,这样它们就不会被采样了。
21、begin_suppress_tokens (List[int], optional): 一个将在生成之初被抑制的标记的列表。SupressBeginTokens日志处理器将把它们的日志probs设置为-inf,这样它们就不会被采样了。
22、forced_decoder_ids (List[List[int]], optional) :一对整数的列表,表示从生成索引到标记索引的映射,在采样前将被强制。例如,[[1, 123]]意味着第二个生成的标记将总是一个索引为123的标记。
总结
本文主要从原理、源码实现等几个方面,依次介绍从Greedy Search到Beam Search、从Beamsearch到Top-k固定采样、从Top-k固定采样到Top-p(Nucleus Sampling)动态采样、从动态采样到概率侧重缩放:temperature温度采样、针对重复生成问题的ngrams重复惩罚机制、针对重复生成问题的RepetitionPenalty重复惩罚、看针对多样性生成中huggingface中还有那些实现策略等7个方向的内容。
从中我们可以看到,其本质上都是在干预预训练模型在解码过程中下一次词的预测概率选择问题,从选择范围、缩放概率、重复惩罚、根据实际场景选择特定的词语等多个方面入手。不过,在实际的过程中,具体还需要我们进行实践,增强的理解。
原文:
https://huggingface.co/blog/how-to-generate
其他文章:
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法