Java 多线程:彻底搞懂线程池_java线程池-程序员宅基地
熟悉 Java 多线程编程的同学都知道,当我们线程创建过多时,容易引发内存溢出,因此我们就有必要使用线程池的技术了。
目录
5.2 定时线程池(ScheduledThreadPool )
5.4 单线程化线程池(SingleThreadExecutor)
1 线程池的优势
总体来说,线程池有如下的优势:
(1)降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
(2)提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
(3)提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
2 线程池的使用
线程池的真正实现类是 ThreadPoolExecutor,其构造方法有如下4种:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}可以看到,其需要如下几个参数:
- corePoolSize(必需):核心线程数。默认情况下,核心线程会一直存活,但是当将 allowCoreThreadTimeout 设置为 true 时,核心线程也会超时回收。
- maximumPoolSize(必需):线程池所能容纳的最大线程数。当活跃线程数达到该数值后,后续的新任务将会阻塞。
- keepAliveTime(必需):线程闲置超时时长。如果超过该时长,非核心线程就会被回收。如果将 allowCoreThreadTimeout 设置为 true 时,核心线程也会超时回收。
- unit(必需):指定 keepAliveTime 参数的时间单位。常用的有:TimeUnit.MILLISECONDS(毫秒)、TimeUnit.SECONDS(秒)、TimeUnit.MINUTES(分)。
- workQueue(必需):任务队列。通过线程池的 execute() 方法提交的 Runnable 对象将存储在该参数中。其采用阻塞队列实现。
- threadFactory(可选):线程工厂。用于指定为线程池创建新线程的方式。
- handler(可选):拒绝策略。当达到最大线程数时需要执行的饱和策略。
线程池的使用流程如下:
// 创建线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(CORE_POOL_SIZE,
MAXIMUM_POOL_SIZE,
KEEP_ALIVE,
TimeUnit.SECONDS,
sPoolWorkQueue,
sThreadFactory);
// 向线程池提交任务
threadPool.execute(new Runnable() {
@Override
public void run() {
... // 线程执行的任务
}
});
// 关闭线程池
threadPool.shutdown(); // 设置线程池的状态为SHUTDOWN,然后中断所有没有正在执行任务的线程
threadPool.shutdownNow(); // 设置线程池的状态为 STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表3 线程池的工作原理
下面来描述一下线程池工作的原理,同时对上面的参数有一个更深的了解。其工作原理流程图如下:
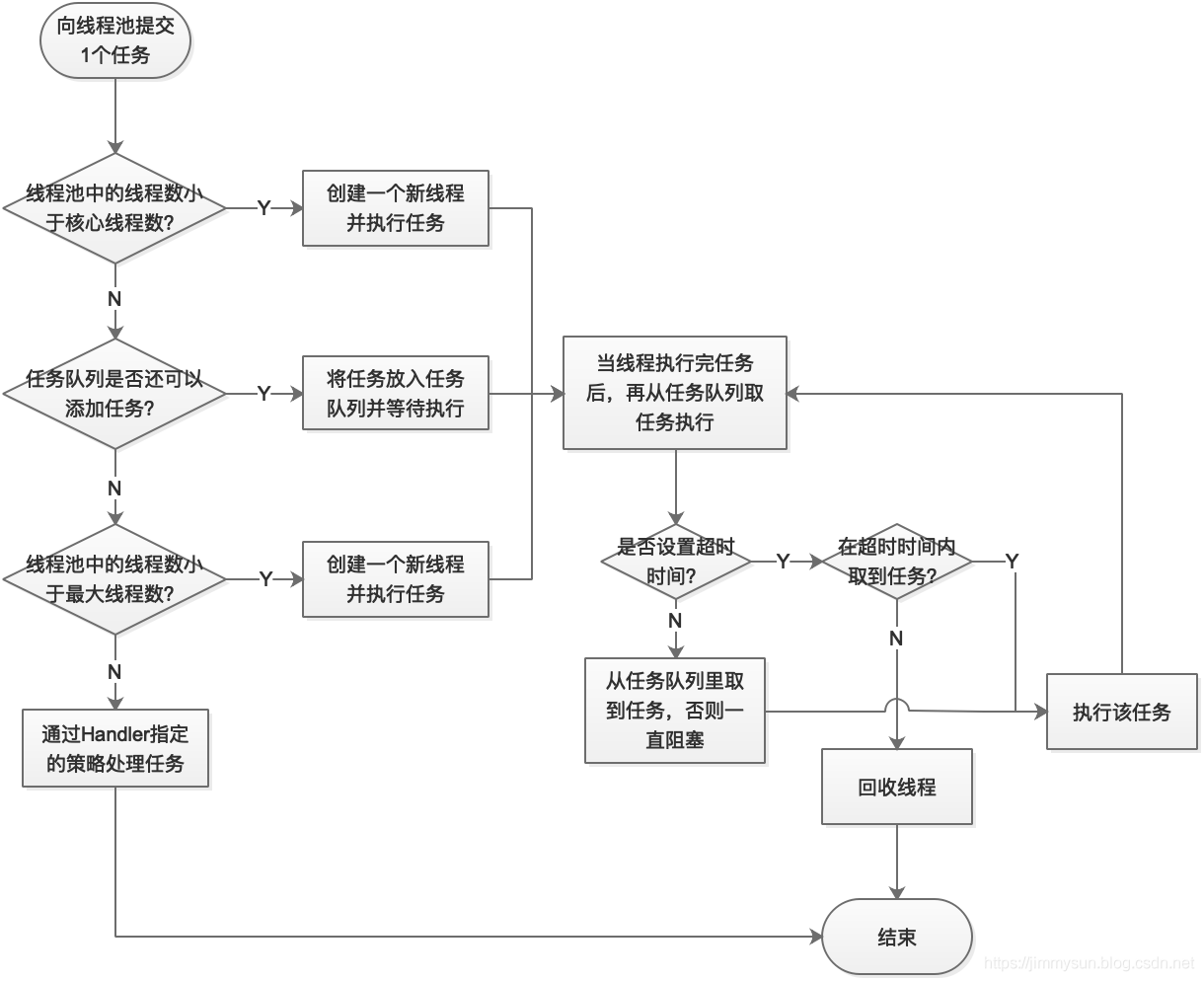
通过上图,相信大家已经对所有参数有个了解了。下面再对任务队列、线程工厂和拒绝策略做更多的说明。
4 线程池的参数
4.1 任务队列(workQueue)
任务队列是基于阻塞队列实现的,即采用生产者消费者模式,在 Java 中需要实现 BlockingQueue 接口。但 Java 已经为我们提供了 7 种阻塞队列的实现:
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列(数组结构可配合指针实现一个环形队列)。
- LinkedBlockingQueue: 一个由链表结构组成的有界阻塞队列,在未指明容量时,容量默认为 Integer.MAX_VALUE。
- PriorityBlockingQueue: 一个支持优先级排序的无界阻塞队列,对元素没有要求,可以实现 Comparable 接口也可以提供 Comparator 来对队列中的元素进行比较。跟时间没有任何关系,仅仅是按照优先级取任务。
- DelayQueue:类似于PriorityBlockingQueue,是二叉堆实现的无界优先级阻塞队列。要求元素都实现 Delayed 接口,通过执行时延从队列中提取任务,时间没到任务取不出来。
- SynchronousQueue: 一个不存储元素的阻塞队列,消费者线程调用 take() 方法的时候就会发生阻塞,直到有一个生产者线程生产了一个元素,消费者线程就可以拿到这个元素并返回;生产者线程调用 put() 方法的时候也会发生阻塞,直到有一个消费者线程消费了一个元素,生产者才会返回。
- LinkedBlockingDeque: 使用双向队列实现的有界双端阻塞队列。双端意味着可以像普通队列一样 FIFO(先进先出),也可以像栈一样 FILO(先进后出)。
- LinkedTransferQueue: 它是ConcurrentLinkedQueue、LinkedBlockingQueue 和 SynchronousQueue 的结合体,但是把它用在 ThreadPoolExecutor 中,和 LinkedBlockingQueue 行为一致,但是是无界的阻塞队列。
注意有界队列和无界队列的区别:如果使用有界队列,当队列饱和时并超过最大线程数时就会执行拒绝策略;而如果使用无界队列,因为任务队列永远都可以添加任务,所以设置 maximumPoolSize 没有任何意义。
4.2 线程工厂(threadFactory)
线程工厂指定创建线程的方式,需要实现 ThreadFactory 接口,并实现 newThread(Runnable r) 方法。该参数可以不用指定,Executors 框架已经为我们实现了一个默认的线程工厂:
/**
* The default thread factory.
*/
private static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}4.3 拒绝策略(handler)
当线程池的线程数达到最大线程数时,需要执行拒绝策略。拒绝策略需要实现 RejectedExecutionHandler 接口,并实现 rejectedExecution(Runnable r, ThreadPoolExecutor executor) 方法。不过 Executors 框架已经为我们实现了 4 种拒绝策略:
- AbortPolicy(默认):丢弃任务并抛出 RejectedExecutionException 异常。
- CallerRunsPolicy:由调用线程处理该任务。
- DiscardPolicy:丢弃任务,但是不抛出异常。可以配合这种模式进行自定义的处理方式。
- DiscardOldestPolicy:丢弃队列最早的未处理任务,然后重新尝试执行任务。
5 功能线程池
嫌上面使用线程池的方法太麻烦?其实Executors已经为我们封装好了 4 种常见的功能线程池,如下:
- 定长线程池(FixedThreadPool)
- 定时线程池(ScheduledThreadPool )
- 可缓存线程池(CachedThreadPool)
- 单线程化线程池(SingleThreadExecutor)
5.1 定长线程池(FixedThreadPool)
创建方法的源码:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}- 特点:只有核心线程,线程数量固定,执行完立即回收,任务队列为链表结构的有界队列。
- 应用场景:控制线程最大并发数。
使用示例:
// 1. 创建定长线程池对象 & 设置线程池线程数量固定为3
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
// 2. 创建好Runnable类线程对象 & 需执行的任务
Runnable task =new Runnable(){
public void run() {
System.out.println("执行任务啦");
}
};
// 3. 向线程池提交任务
fixedThreadPool.execute(task);5.2 定时线程池(ScheduledThreadPool )
创建方法的源码:
private static final long DEFAULT_KEEPALIVE_MILLIS = 10L;
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue(), threadFactory);
}- 特点:核心线程数量固定,非核心线程数量无限,执行完闲置 10ms 后回收,任务队列为延时阻塞队列。
- 应用场景:执行定时或周期性的任务。
使用示例:
// 1. 创建 定时线程池对象 & 设置线程池线程数量固定为5
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
// 2. 创建好Runnable类线程对象 & 需执行的任务
Runnable task =new Runnable(){
public void run() {
System.out.println("执行任务啦");
}
};
// 3. 向线程池提交任务
scheduledThreadPool.schedule(task, 1, TimeUnit.SECONDS); // 延迟1s后执行任务
scheduledThreadPool.scheduleAtFixedRate(task,10,1000,TimeUnit.MILLISECONDS);// 延迟10ms后、每隔1000ms执行任务5.3 可缓存线程池(CachedThreadPool)
创建方法的源码:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}- 特点:无核心线程,非核心线程数量无限,执行完闲置 60s 后回收,任务队列为不存储元素的阻塞队列。
- 应用场景:执行大量、耗时少的任务。
使用示例:
// 1. 创建可缓存线程池对象
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
// 2. 创建好Runnable类线程对象 & 需执行的任务
Runnable task =new Runnable(){
public void run() {
System.out.println("执行任务啦");
}
};
// 3. 向线程池提交任务
cachedThreadPool.execute(task);5.4 单线程化线程池(SingleThreadExecutor)
创建方法的源码:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}- 特点:只有 1 个核心线程,无非核心线程,执行完立即回收,任务队列为链表结构的有界队列。
- 应用场景:不适合并发但可能引起 IO 阻塞性及影响 UI 线程响应的操作,如数据库操作、文件操作等。
使用示例:
// 1. 创建单线程化线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
// 2. 创建好Runnable类线程对象 & 需执行的任务
Runnable task =new Runnable(){
public void run() {
System.out.println("执行任务啦");
}
};
// 3. 向线程池提交任务
singleThreadExecutor.execute(task);5.5 对比
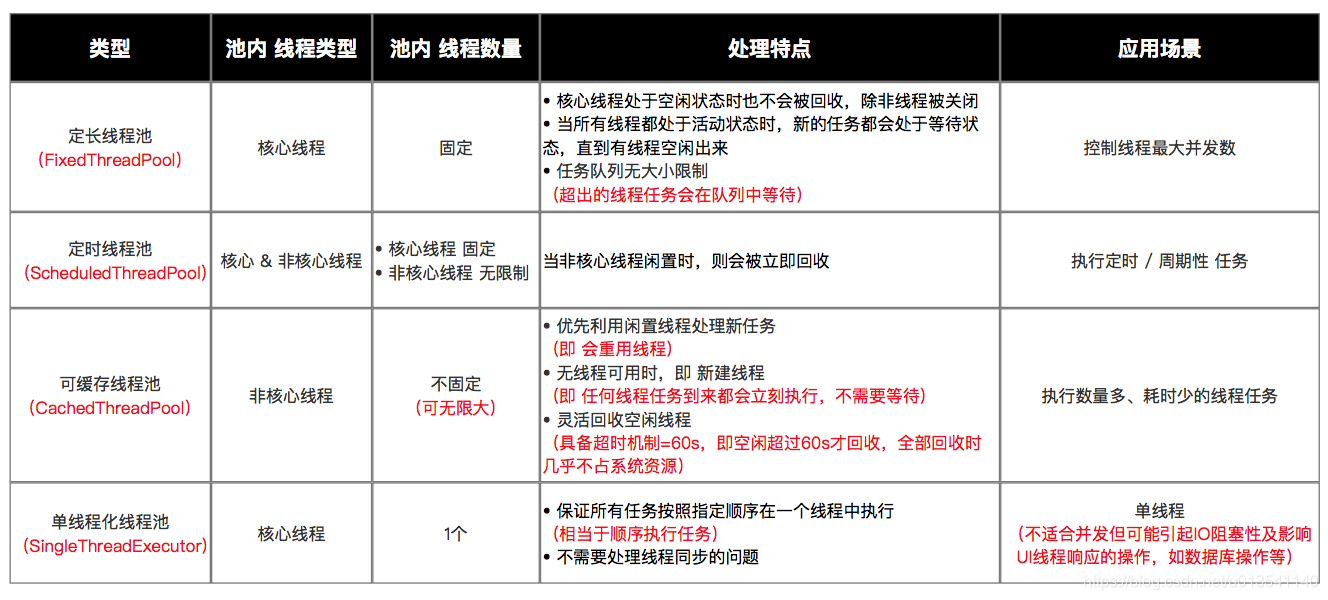
6 总结
Executors 的 4 个功能线程池虽然方便,但现在已经不建议使用了,而是建议直接通过使用 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
其实 Executors 的 4 个功能线程有如下弊端:
- FixedThreadPool 和 SingleThreadExecutor:主要问题是堆积的请求处理队列均采用 LinkedBlockingQueue,可能会耗费非常大的内存,甚至 OOM。
- CachedThreadPool 和 ScheduledThreadPool:主要问题是线程数最大数是 Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至 OOM。
参考
智能推荐
ultralytics/yolov3训练预测自己数据集的配置过程_yolov3.pt-程序员宅基地
文章浏览阅读6.7k次,点赞11次,收藏78次。此时查看文件,发现需要yolov3.pt(默认参数),但该文件并没有随git该目录时一起下载,github博主提供了这些文件的下载路径,4. 运行detect.py, 在runs文件夹的detect文件夹中能看到整体测试集的预测结果,这边的exp也是每一次预测的历史记录。yolov3的一些资料可见博主的博客。该文件夹中存在多个exp关键字的文件夹,其每一次训练,exp后面的索引都会增1,以记录你的训练历史。运行,在anno文件夹下,会看到对应每一个xml文件,都会生成一个对应的txt文件。_yolov3.pt
实践作业:经典机器学习案例——淡水资源监测-程序员宅基地
文章浏览阅读848次,点赞22次,收藏13次。通过提供的淡水资源质量数据集,对数据首先进行数据探索、数据预处理、利用机器学习建立模型,并进行欺诈数据的检测。1、数据探索:查看数据集规模、数据类型、缺失值情况以及统计性描述。2、数据预处理:处理缺失值、平衡数据样本3、利用机器学习建立模型:支持向量机分类、集成学习。
python相关函数_Python【十七】:自相关函数的实现-程序员宅基地
文章浏览阅读1k次。# -*- coding: cp936 -*-"""This is a Simple Code for compute the specific value of autocorrelation functionCompute Fomular: R(k) = E[(Xi - e)(X(i+k) - e)] / V, as E is Expection function,e is Expection..._python 自相关函数
关于使用Spring Initializr快速构建项目遇到的问题_用spring initializr创建的项目不能运行-程序员宅基地
文章浏览阅读146次。如果你的项目构建之后不能启动,在项目上会出现一个红色的J.1.可以先把关于git的目录删除,如下2.如果还不行,在项目结构中将java和test包设置为蓝色的方块3.如果有运行显示maven有问题的可以将pom.xml设置为添加一个maven项目..._用spring initializr创建的项目不能运行
python初始化字典值为列表,需注意避免赋值其中一个但其他值也变化_字典里面的值修改之后,其他会跟着变么-程序员宅基地
文章浏览阅读5.2k次,点赞2次,收藏4次。初始化字典的第一反应是使用dict.fromkeys(),如果value值是int之类的简单值类型没什么问题,但用list初始化则不然。场景是为dict初始化value值为空的list,可以分别对不同key值对应的value独立操作。使用dict.fromkeys()初始化得到的字典改动一个value其他的value值也会跟随变化,这是因为后者每个key对应的value值都指向了同一个列表..._字典里面的值修改之后,其他会跟着变么
nodejs如何动态生成html页面,nodejs 简单实现动态html的方法-程序员宅基地
文章浏览阅读2.6k次。动态替换html内容1.实现的功能及原理实现了将,用户表单的数据,与html相结合,将用户输入的数据,显示到html对应的位置。原理:通过正则表达式,替换html中的模板数据 如用户名{name},可以通过拿到用户提交的name的值value,通过replace(正则表达式,value)的方式替换掉原模板数据,并输出到客户端。2.主要用到的方法和模块2.1文件操作模块 var fs=require..._nodejs动态生成页面
随便推点
Cadence Virtuoso打印版图,高分辨率无底色,可直接用于论文中_virtuoso print-程序员宅基地
文章浏览阅读6.6k次,点赞8次,收藏43次。这里写自定义目录标题前言具体步骤配置Cadence打印机在virtuoso打印转换格式前言在virtuoso画完版图之后,背景是纯黑色的,如果直接截图放在论文里会显得很丑,这里介绍一种打印的方式,导出高分辨率,无底色,很漂亮的图片具体步骤配置Cadence打印机在终端terminal执行下述命令plotconfigure会弹出下面的窗口,上边显示了已经安装的打印机(第一次打开是空的,因为还没有安装),下半部分显示的是打印机的列表,双击即可添加到上边的已安装列表,然后在上边选中刚刚添加的打印机_virtuoso print
[Mac软件]实用的屏幕录像工具:Apeaksoft Screen Recorder Mac v2.2.6-程序员宅基地
文章浏览阅读366次,点赞8次,收藏9次。它可以帮助用户轻松地在计算机上录制任何视频、音频和屏幕截图,无论是在线电影、广播、游戏、视频教程还是网络摄像头视频,都可以轻松应对。此外,Apeaksoft Screen Recorder还提供了丰富的编辑功能,如文本框、箭头、选择等,让用户可以在录制过程中对内容进行实时评论和标注,提高视频的可读性和观赏性。总之,Apeaksoft Screen Recorder是一款功能强大、操作简单的Mac屏幕录制工具,无论您是想要录制在线电影、广播、游戏、视频教程还是网络摄像头视频,都可以为您提供满意的解决方案。
windows nginx安装与部署_windows nginx 能安装在系统盘吗-程序员宅基地
文章浏览阅读592次。最近在研究nginx部署,在网上找了些小例子学习,过程中遇到些问题,故总结下来分享给大家,首先要在网上下载nginx,地址为http://nginx.org,下一个windows版本,并解压到一个盘符在,这里放在c盘根目录下。然后其命令窗口,进到此目录下,运行nginx,操作如下:如果正确运行,则在任务管理器会看到如下两个进程:如果没有则说明出了问题,可以查看nginx目录下的logs目录下的er..._windows nginx 能安装在系统盘吗
Spark大数据处理机器学习算法解析案例实战_spark数据处理分析实例-程序员宅基地
文章浏览阅读851次。作者:禅与计算机程序设计艺术 1.简介Apache Spark是一个开源的集群计算框架,用于快速处理大规模数据集(Big Data)。Spark可以运行在Hadoop之上,提供高吞吐量的数据处理能力;并且其可扩展性让它能够同时处理多个节点的集群资源。Spark是一款开源的分布式计算系统,具有高容错性_spark数据处理分析实例
Babel从入门到插件开发-程序员宅基地
文章浏览阅读198次。最近的技术项目里大量用到了需要修改源文件代码的需求,也就理所当然的用到了Babel及其插件开发。这一系列专题我们介绍下Babel相关的知识及使用。对于刚开始接触代码编译转换的同学,单纯的介绍Babel相关的概念只是会当时都能看懂,但是到了自己去实现一个需求的时候就又会变得不知所措,所以我们再介绍中穿插一些例子。大概分为以下几块:0、..._babel type 构建三元表达式
vim替换操作_vim替换字符-程序员宅基地
文章浏览阅读399次,点赞8次,收藏9次。若option字段有c,如gc,则会出现如下提示:”replace with foo(y/n/a/q/l/^E/^Y)?,其中range和option字段都可以缺省不填。vim替换字符串的这些选项可以组合使用。Vim替换字符串命令的基本语法是。_vim替换字符