Python爬虫【一】爬取移动版“微博辟谣”账号内容(API接口)_微博半年可见爬虫-程序员宅基地
技术标签: 爬虫 python 微博 数据采集 爬取微博内容(学习用)
专题系列导引
爬虫课题描述可见:
课题解决方法:
微博移动版爬虫
微博PC网页版爬虫
Python爬虫【二】爬取PC网页版“微博辟谣”账号内容(selenium同步单线程)
Python爬虫【三】爬取PC网页版“微博辟谣”账号内容(selenium单页面内多线程爬取内容)
Python爬虫【四】爬取PC网页版“微博辟谣”账号内容(selenium多线程异步处理多页面)
前言
本文我们针对3G4G移动版微博网站(URL: https://m.weibo.cn),爬取"微博辟谣"的数据
一. 分析
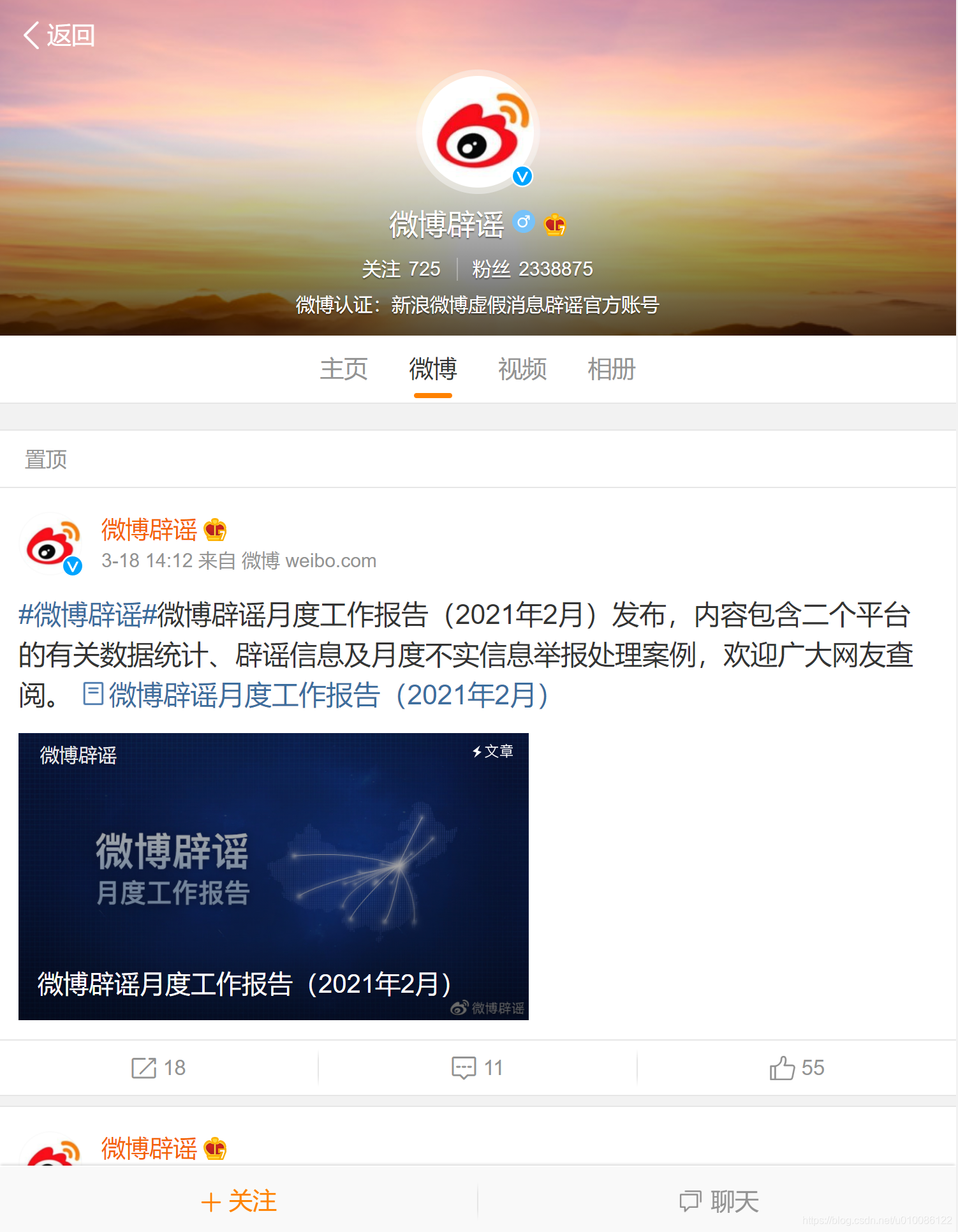
微博辟谣的URL地址:
https://m.weibo.cn/u/1866405545?uid=1866405545&t=0&luicode=10000011&lfid=100103
微博页面效果:
爬取思路
首先对微博辟谣网页访问和翻页时进行数据抓包,发现调用了如下接口:

接口返回数据集:
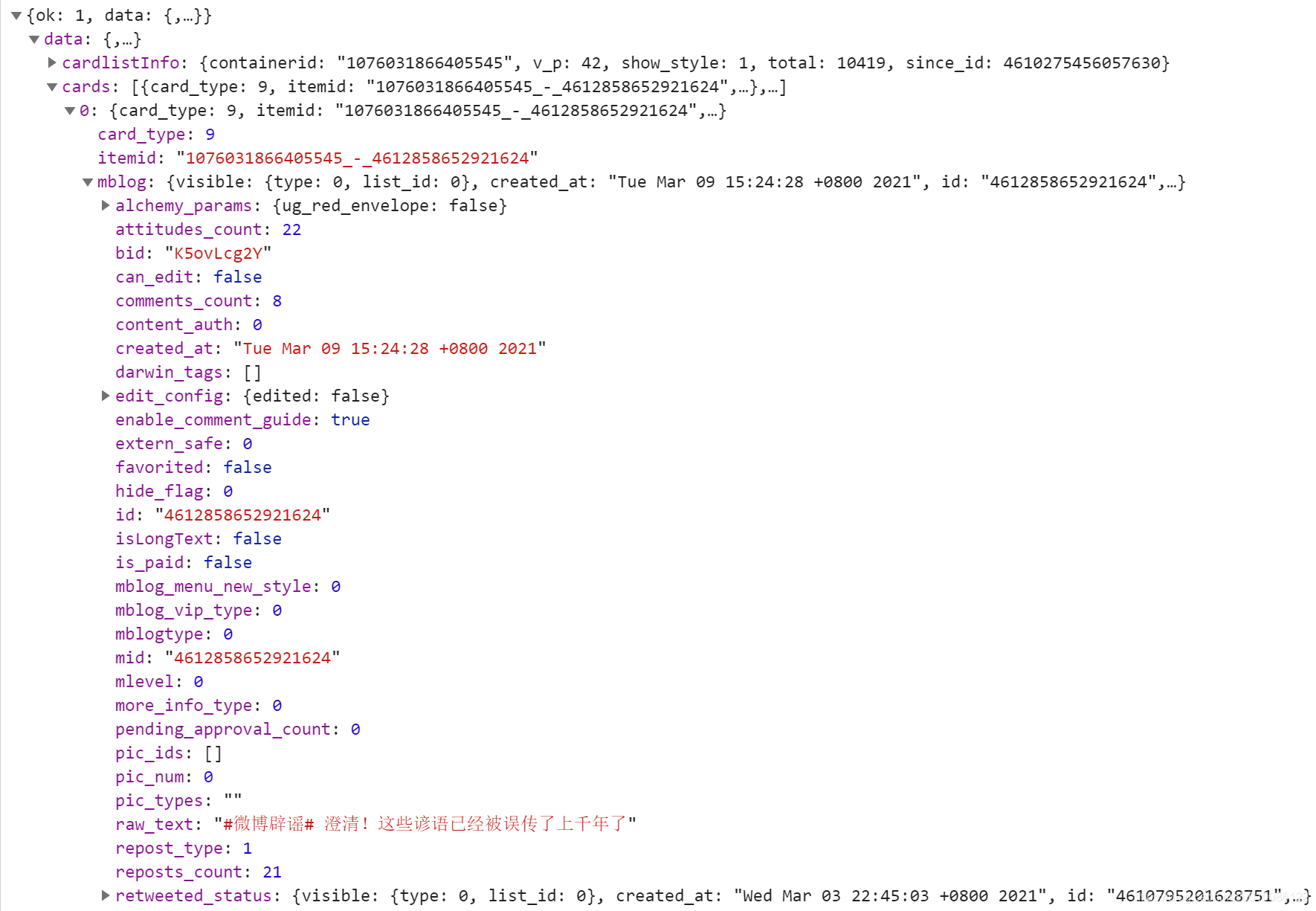
因此总结特点如下:
- 移动版网站页面是通过js访问API接口、再渲染到html元素的方式来加载内容的。因此我们可以不管html页面展示如何,而采用直接调用后台API接口来提取数据
- API接口中通过添加入参page=?的方式来实现不同页面数据内容的获取;新版API(2021年11月)换用了since_id=?作为入参,但也保留了page参数,两者都可实现分批按页查询的功能。since_id参数说明如下:每次API请求,返回的结果中都会保留下一页查询需要的since_id值;当翻页时,下一次API调用传入的since_id即为此since_id。所以我们可以通过更换此参数不断的实现分页爬取
二. 处理流程
整个微博移动版的爬取流程,可总结为以下四步:
1. 创建用来保存数据的DataFrame对象:excel_df
2. 从第一页开始,访问当前页面的API接口,获取微博数据并提取相关字段,存入df中
3. 不断的向后请求每一页的API接口,重复上面的提取数据和存df操作,直到最后一页
4. 将整个excel_df数据写入excel中
三. 代码实现
1. 项目结构
Python爬虫工程使用requests模块请求API接口。因为整体功能比较简单,所以使用面向过程的设计模式,用函数调用串联整个业务。
工程结构如下:
- 创建
m_crawler.py模块,定义爬取流程所需要的几个函数以上处理模块,放在名为
m包中
- 因为DataFrame数据写excel比较基础,所以我们将它设计为一个工具方法。定义一个
util.py模块,将工具方法都写入此模块中- 项目中URL、写入地址、表头等配置变量比较多,因此将他们写入
property.py文件以上两个公共模块,放在名为
common的包中
- 在项目下创建一个
名为excel的文件夹,将最终的导出结果文件存于其中main.py作为整个项目的启动入口
最终项目结构如下图:

2. main.py
main.py为程序入口,启动工程时首先从这里开始执行。因为我们的串联类为CrawlHandle,并且需要Crawler做为入参,因此main.py中代码设计如下:
if __name__ == '__main__':
# 移动版微博爬取
m_crawler.crawler_m_weibo_write_excel()
3. m_crawler.py模块
1. crawler_m_weibo_write_excel()函数
def crawler_m_weibo_write_excel()为爬取处理主函数,根据上面的设计,功能是串联整个爬取的流程,设计如下:
def crawler_m_weibo_write_excel():
"""
主方法:从m移动端微博中读取数据,整理并存入指定excel
:return:
"""
# 定义空df,以装载处理完的数据
excel_df = DataFrame(columns=EXCEL_COLUMNS)
try:
# 无线循环不断向后翻页查询,直到查至微博最后一页
# 发现问题:移动版微博设置了只能拉取2000条数据,超过200条数据,since_id不会再返回;入参用page传参也是如此。此问题已在页面上尝试,m微博确实只能下拉2000条数据
page = 1 # 页面计数
while True:
# 1. 爬取微博数据
json_cards = get_weibo_info_by_page(page)
# 爬不到时退出爬取循环
if len(json_cards) == 0:
print("已爬取到微博最后一页,退出爬虫循环...")
break
# 2. 解析页面返回的json数据 整理为特定格式的list并返回
parse_json_list = list(parse_result_2_list(json_cards))
print("爬取第 %s 页,爬取有效微博数: %s" % (page, len(parse_json_list)))
# 3. 将此轮爬取的微博数据添加到df数据表末端
excel_df = excel_df.append(parse_json_list)
# 页数加1
page += 1
# 最好让程序睡眠一段时间,防止微博服务器认为在恶意爬取,封禁IP
time.sleep(0.5)
except Exception as e:
print("爬虫程序报错,可能出现问题,请检查!", e)
# 4. 爬取完所有数据后,进行写文档操作
util.write_excel(excel_df, M_WB_EXCEL_PATH)
那么接下来的重点就是补充完这五部分的方法代码细节,定义相关的类或者方法
2. get_weibo_info_by_page()函数
上面调用的"分页抓取微博数据"功能,封装了函数def get_weibo_info_by_page(),编写如下:
def get_weibo_info_by_page(page):
"""
分页抓取微博数据
:return:
"""
# 拼接接口入参
m_wb_request_params['page'] = page
# 拼装完整的请求URL
url = M_WB_URL + urlencode(m_wb_request_params)
# print("请求URL: %s" % url)
try:
# get请求接口,返回结果为json结构数据
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 打印返回值,用于调试
# print("请求得到的response==%s" % response.text)
# 转json
response_json = response.json()
# 取json中的cards, 为array_list
cards = response_json.get('data').get('cards')
# print("提取到的cards属性:%s" % cards)
return cards
except requests.ConnectionError as e:
print('爬取错误', e.args)
3. parse_result_2_list()函数
将API请求的结果json提取必要的字段,封装入df的逻辑,封装为函数def parse_result_2_list():
def parse_result_2_list(json_cards):
"""
解析页面返回的json数据 整理为特定格式的list并返回
:return:
"""
# 循环所有cards,依次处理
for card in json_cards:
# card_type == 9 为微博正文内容,取出分析
if card.get('card_type') == 9:
# 取mblog
mblog = card.get('mblog')
# “微博辟谣”账号发微博时输入的文字内容
# wb_text = mblog.get('raw_text') # 老方法,2021年已不可用
# 新方法
bs = BeautifulSoup(mblog.get('text'), "html.parser")
wb_text = bs.get_text()
# 剔除月度工作报告信息
if '月度工作报告' in wb_text:
# 剔除月度工作报告,可打印日志分析剔除结果,以防有误判删除掉有用信息
print("剔除月度报告: %s" % mblog.get('raw_text'))
continue
# card转换整理后的json结果
etl_json = {
}
# "微博辟谣"此条微博的id
wb_id = mblog.get("id")
# 微博名,这里为“微博辟谣”
wb_name = mblog.get('user').get("screen_name")
# “微博辟谣”账号发微博时微博时间
wb_time = util.parse_time(mblog.get('created_at'))
# 本微博转发数,若为文章“转发”,则说明还没人转,设为0
wb_repost_count = mblog.get('reposts_count')
# set值
etl_json['WB_id'] = wb_id
etl_json['WB_name'] = wb_name
etl_json['WB_text'] = wb_text
etl_json['WB_time'] = wb_time
etl_json['WB_repost_count'] = wb_repost_count
# mblog中若有属性 retweeted_status 说明是转发
if mblog.get('retweeted_status'):
weibo_info = mblog.get('retweeted_status')
""" 当出现特殊情况无法爬取内容时的处理办法,目前处理办法是:忽略此条微博,跳过 """
# 被设为不可见,因此无法爬取(包括原作者设为自己可见、半年内可见等情况)
if weibo_info['visible']['type'] != 0 or weibo_info['visible']['list_id'] != 0:
print("以下博客已被设为不可见,不可爬取:%s" % weibo_info)
continue
# 微博账号被删除z包括自己注销、被查封注销等情况)
if 'deleted' in weibo_info:
print("以下博客已被删除,不可爬取:%s" % weibo_info)
continue
# 原微博的id
wb_id_org = weibo_info.get("id")
# 原微博号名称
wb_name_org = weibo_info.get('user').get("screen_name")
# 原账号发微博时微博时间
wb_time_org = util.parse_time(weibo_info.get('created_at'))
# 原微博转发数
wb_repost_count_org = weibo_info.get('reposts_count')
etl_json['WB_id_org'] = wb_id_org
etl_json['WB_name_org'] = wb_name_org
etl_json['WB_time_org'] = wb_time_org
etl_json['WB_repost_count_org'] = wb_repost_count_org
etl_json['type'] = "转发"
etl_json['weibo_name'] = wb_name_org
etl_json['time'] = wb_time_org
etl_json['repost_count'] = wb_repost_count_org
# 原微博发微时输入的文字内容
wb_text_org = weibo_info.get('raw_text')
# 如果文章没有全部展开,则再次提取微博数据
if ">全文<" in weibo_info.get("text"):
wb_long_text_org = util.get_weibo_long_text(wb_id_org)
# etl_json['wb_long_text_org'] = wb_long_text_org
# 替换文本
if wb_long_text_org is not None or wb_long_text_org != "":
wb_text_org = wb_long_text_org
etl_json['WB_text_org'] = wb_text_org
etl_json['text'] = wb_text_org
else:
etl_json['type'] = "原创"
etl_json['weibo_name'] = wb_name
etl_json['text'] = wb_text
etl_json['time'] = wb_time
etl_json['repost_count'] = wb_repost_count
yield etl_json
因为每个API接口会请求多条微博数据,因此入参是个list; 函数中用yield关键字返回一个迭代,但我们需要的是类型为list的结果,所以调用时,直接用list()做转换,就可得到此函数迭代执行后的结果list。
4. util.py模块
此模块为工具模块,用到的方法有
def get_weibo_long_text(id):
"""
通过id获取微博长文本
:return:
"""
# 拼装完整的请求URL
url = M_WB_LONG_TEXT_URL % id
# print("长文本请求URL: %s" % url)
try:
# get请求接口,返回结果为json结构数据
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 打印返回值,用于调试
# print("长文本请求得到的response: %s" % response.text)
# 转json
response_json = response.json()
# 提取长文本
long_text = response_json.get('data').get('longTextContent')
# print("提取到的long_text:%s" % long_text)
# 将长文本用bs4转换为纯文字
html_soup = BeautifulSoup(long_text)
text = html_soup.get_text()
if text:
pass
else:
print("!调用接口查询长文本出错! URL = %s ,response= %s" % (url, response.text))
return text
except Exception as e:
print('爬取长文本错误')
traceback.print_exc()
def write_excel(excel_df, excel_path):
"""
将结果写入Excel
:param excel_df:
:param excel_path:
:return:
"""
print("开始写入Excel文档:文档名称 %s" % excel_path)
excel_df.to_excel(excel_path, index=False)
# 如果只想要前四列,则用下面的语句:
# excel_df[excel_columns[:4]].to_excel(excel_path, index=False)
print("写入Excel文档成功!")
主要是用来请求全文,还有些Excel的工具方法
结束
以上整个爬虫项目编写完毕,只有配置变量和用到的工具方法没有贴出,具体实现可见源代码
四. 爬虫执行
1. 执行过程
当程序执行后,可以看到依次爬取每页微博数据,一页中有25条数据,会空过已删除、不可见、月报告的微博

2. 执行结果
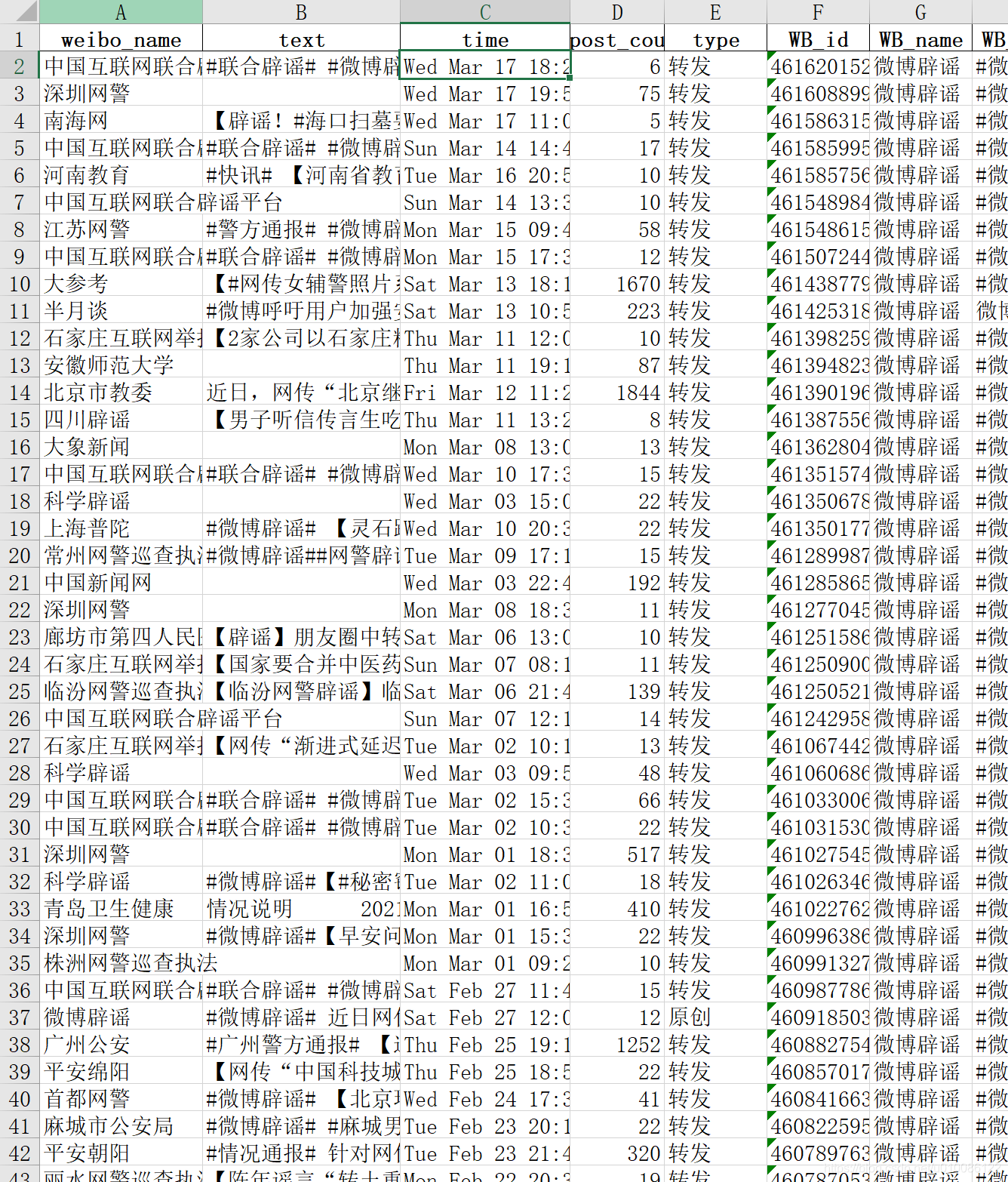
最后爬取存入excel的结果如下,前四列即为课题要求的结果。
日期笔者在2020年12月时为yyyy-MM-dd的格式,2021年3月19日重试时,返回结果改为了日期字符串,这里可以用日期转换工具类做转换,format日期值,博主此处省略
五. 问题总结
- 为了防止过快访问被微博服务器检测到恶意爬取,最好每次调用完成处理后,等待1s左右的时间(如果能用ip池做代理绕开服务器爬取检测更好)
- 移动版微博API设置了只能拉取2000条数据(前80页)。超过2000条数据,since_id不会再返回;接口入参用page传参也是如此,因此数据不全问题无法回避。
- 上述问题的解决办法只能更改数据爬取渠道,使用爬取PC网页版来完成全量数据爬取目标。在后面的【二】【三】【四】中即可看到实现方式
- 因为爬取移动版微博是调用API接口,所以速度快,稳定性好,可靠性高。每页微博25条数据大概平均用时6秒,总共80页数据用时480秒,约8分钟。折合到微博辟谣45*240条的总量(通过PC版统计),估计全量爬取用时大约0.7小时
- 微博API接口和页面格式、字段、日期表示一直有变化,博主程序满足当前(2021年3月)的微博设计情况;若有变化读者需要根据实际情况进行改造
执行程序
项目工程编译了windows版本执行程序:微博数据采集python+selenium执行程序:WBCrawler.exe
-
执行项目前,需要下载selenium对应的浏览器驱动程序(driver.exe),并放在本机环境变量路径中,否则会报错。安装操作具体可见博客专题中的指导【二】
-
执行程序时,会在系统用户默认路径下,创建一个虚拟的python环境(我的路径是C:\Users\Albert\AppData\Local\Temp_MEI124882\),因此启动项目所需时间较长(约20秒后屏幕才有反应,打出提示),请耐心等待;也正因如此,执行电脑本身环境是可以无需安装python和selenium依赖包的;同时最后爬取保存的excel也在此文件夹下。
-
本项目采用cmd交互方式执行,因此等到屏幕显示:
选择爬取方式: 1. 移动版微博爬取 2. PC网页版微博爬取(单线程) 3. PC网页版微博爬取(页面内多线程) 4. PC网页版微博爬取(多线程异步处理多页面)
后,用键盘输入1~4,敲回车执行
- 此exe编译时,工程代码内编写的最终excel记录保存地址为:相对工程根路径下的excel文件夹;因此当本exe执行到最后保存数据时,会因为此excel文件夹路径不存在而报错。若在工程中将保存地址改为绝对路径(例如D:\excel\),再编译生成exe执行,则最终爬取数据可以正确保存
项目工程
工程参见:微博数据采集python+selenium工程:WBCrawler.zip
本专题内对源码粘贴和分析已经比较全面和清楚了,可以满足读者基本的学习要求。源码资源为抛砖引玉,也只是多了配置文件和一些工具方法而已,仅为赶时间速成的同学提供完整的项目案例。大家按需选择
智能推荐
ffmpeg音视频处理流程核心技术_视频效果演示系统的核心技术-程序员宅基地
文章浏览阅读712次。视频播放器原理 什么是ffmpeg? ffmpeg 音视频编/解码 流程图 ffmpeg 常用 struct AVFormatContext AVStream AVCodecContext AVCodec AVPacket AVFrame ffmpeg 常用Api av_register_all() avformat_alloc_output_context2() avio_open()..._视频效果演示系统的核心技术
Java List集合多种情况处理方法_java list reduce-程序员宅基地
文章浏览阅读449次。Java List集合多种情况处理方法:List集合交集、并集、差集、去重、与数组互转、删除、排序等操作_java list reduce
【UML】软件需求说明书_uml需求文档访客管家-程序员宅基地
文章浏览阅读2.3k次,点赞77次,收藏80次。需求:指人对客观事务需要的表现,体现为愿望、意向和兴趣,因而成为行动的一种直接原因。软件需求(IEEE软件工程标准词汇表):(1)用户解决问题或达到目标所需的条件或能力。(2)系统或系统部件要满足合同、标准、规范或者其他正式规定文档所需具有条 件或能力。(3)对(1)或(2)中的一个条件或一种能力的一种文档化表述。用例:定义 1 用例是对一个活动者使用一个系统的一项功能时进行交互过程中的一个文字描述序列。_uml需求文档访客管家
linux笔记-根文件系统及文件管理命令详解_根文件系统文本登陆-程序员宅基地
文章浏览阅读574次。第三章、Linux根文件系统及文件管理命令详解02_03_Linux根文件系统详解文件系统:rootfs: 根文件系统 FHS:Filesystem Hierarchy Standard(文件系统目录标准)的缩写,多数Linux版本采用这种文件组织形式,类似于Windows操作系统中c盘的文件目录,FHS采用树形结构组织文件。FHS定_根文件系统文本登陆
马克 · 扎克伯格期望的元宇宙到底会是什么样子?_马克扎克伯格博客-程序员宅基地
文章浏览阅读358次。马克 · 扎克伯格期望的元宇宙到底会是什么样子?_马克扎克伯格博客
使用Python开发游戏运行脚本(二)实现模拟点击_大漠窗口绑定成功按键-程序员宅基地
文章浏览阅读1.4w次,点赞8次,收藏78次。本文接上一篇文章 使用Python开发游戏运行脚本(一)成功调用大漠插件上一篇我们已经简单实现了python调用大漠插件并输出版本号的功能,接下来我们要做的就是通过大漠插件模拟鼠标点击和键盘文字输入。 由于近年来最热门的游戏基本都是手游,所以我们也会以手游为例来进行游戏脚本的开发。大漠插件是一款针对Windows平台的鼠标键盘模拟+图文查找库,这样我们要想实现手游脚本开发的第一步,就是下载Android模拟器,然后在对安卓模拟器进行鼠标和键盘的模拟,以此来实现自动化游戏脚本。一、Android模拟器的_大漠窗口绑定成功按键
随便推点
Canvas实现黑客帝国字符雨_canvas画字符雨-程序员宅基地
文章浏览阅读1k次。 利用Canvas的fillText(),隔一定时间在画布上作画<!DOCTYPE html><head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width,initial-scale=1.0"> &_canvas画字符雨
微信公众号跳转微信小程序,自定义微信跳转标签_opentaglist-程序员宅基地
文章浏览阅读1.1k次。微信公众号跳转微信小程序,自定义微信跳转标签_opentaglist
数据恢复技术与LVM数据恢复方法_vgreduce --removemissing恢复-程序员宅基地
文章浏览阅读4.3k次。数据恢复技术与LVM数据恢复方法 1摘要 随着计算机网络应用的发展,数据存储的安全性变的越来越重要。在常见的基于RAID和LVM的环境下面,当出现硬盘故障或者错误操作导致数据丢失的情况下,采用适当的数据恢复策略可以在很大程度上提供数据恢复的成功概率。本文研究了几种情况下的数据恢复技术和方法,为数据恢复和数据安全的预防提供了指导。 2数据恢复需求 2.1Linux IO存储栈 图(1)Linux IO 存储..._vgreduce --removemissing恢复
程序员如何年薪百万?深度学习必读书籍!_年薪百万的程序员看什么书-程序员宅基地
文章浏览阅读307次。深度学习程序员想年薪百万,基础必须打牢,所以推荐重点书籍Deep Learning花书Deep Learning with PythonDeep Learning for Computer Vision with PythonScikit-Learn与TensorFLow机器学习实用指南深度学习实践Tensorflow机器学习指南..._年薪百万的程序员看什么书
Window系统下C/C++程序毫秒和微秒级程序运行时间的获取方法_large_integer nfreq, t1, t2;-程序员宅基地
文章浏览阅读1.3k次。一、使用clock()函数,获取毫秒级(ms)时间[1]#include <time.h>//clock()头文件clock_t start = clock();{statement section}//测试代码段clock_t end = clock();printf("the running time is :%fs\n", (double)(end -s..._large_integer nfreq, t1, t2;
IntelliJ IDEA 使用教程-- 从入门到上瘾(配套视频教程)_idea使用视频教程-程序员宅基地
文章浏览阅读6.8k次,点赞3次,收藏31次。 前言: 至于用哪个开发工具本文暂且不做任何讨论, 今天着重讲解IntelliJ IDEA这款开发工具的使用 前言:IntelliJ IDEA如果说IntelliJ IDEA是一款现代化智能开发工具的话,Eclipse则称得上是石器时代的东西了。其实笔者也是一枚从Eclipse转IDEA的探索者,随着近期的不断开发实践和调试,逐步..._idea使用视频教程