数据结构复习过程中的笔记_顺序队列满了会怎么样-程序员宅基地
知识点盲区
主要为在做题过程中发现的知识点盲区,自己的找到的坑,逐步一点一点慢慢的填上
0.1 队列
顺序队列空:frontrear
顺序队列满:frontrear,会出现假溢出情况
因为顺序队列是按照头出尾进的操作方式存储元素,当元素存满队列,从队头出队元素到队列非空,在执行入队列操作时,队列实际上是没有满,还有大量的空闲元素,但是已经满足rear==frot的条件,我们把这种现象叫做假溢出,为了解决这种问题引出了循环队列的概念。
初始时:front=rear=0
循环队列入队:rear=(rear+1)%MAXSIZE
循环队列出队:front=(front+1)%MAXSIZE
循环队列长度:(rear-front+MAXSIZE)%MAXSIZE
循环队列队空:frontrear
循环队列队满:
(1)牺牲一个单元来区分队空或队满,入队列时候少用一个队列单元
队满:(rear+1)%MAXSIZEfront
队空:front=rear
元素个数:(rear-front+MAXSIZE)%MAXSIZE
(2)增加一个元素表示数据成员个数,
队满:sizeMAXSIZE,frontrear
队空:size0,frontrear
(3)增加tag数据成员,区分队空还是满
tag0时,若因删除导致frontrear,则为空
tag1时,若因插入导致frontrear,则为满
0.2 链队列
不带头结点的队列front指向第一个元素,rear指向最后一个元素,当队列空时rear=front=null
带头结点的队列front指向头结点,rear指向最后一个元素,当队列空时,rear、front都指向头结点
void InitQueue(LinkQueue *Q)
{
Q.front = Q.rear = (LinkNode*)malloc(sizeof(LinkNode));
Q.front->next = NULL;
}
bool IsEmpty(LinkQueue Q)
{
if(Q.front == Q.rear)
return true;
else
return false;
}
void EnQueue(LinkQueue &Q,ElemType x)
{
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));
s->data = x;
s->next = NULL;
Q.rear->next = s;
Q.rear = s;
}
void DeQueue(LinkQueue &Q,ElemType &x)
{
if(Q.front == Q.rear)
return false;
x = p->data;
Q.front->next = p->next;//指向出队元素的后一个
if(Q.rear == p)
Q.rear = Q.front;
free(p);
return true;
}
0.3 双端队列
双端队列是指两端都可以进行插入和删除操作的队列
输出受限的双端队,允许在一端进行插入和删除,另外一端只允许插入
输入受限的双端队,允许在一端进行插入和删除,另外一端值允许删除
1、线性表的基本操作
线性表的操作都是从第i个位置,而不是下标,
插入元素需要后移动n-i+1
删除元素需要移动n-i
查找元素i
2、已知邻接矩阵,计算i结点的入度,删除所有i结点出发的狐头
邻接矩阵行是出度,列是入度
删除i结点出发的边,将邻接矩阵中i行的元素都置为0即可删除边
有向图的邻接矩阵i行是出度,j列是入度,度是顶点入度和出度之和
无向图的邻接矩阵i行或j列为某个结点的度,
3、二叉排序树的中序遍历是递增序列
(1)非空二叉树上的叶子结点数等于度为2的结点数加1:n0=n2+1
(2)非空二叉树上第k层至多有2^(k-1)个结点
(3)高度为h的二叉树至多有2^h-1个结点
(4)高度为log2n+1
1)当i>i时,结点i的双亲结点编号为i/2,当i为偶数时,双亲为n/2,是左孩子,当i为奇数时,双亲为(i-1)/2,是右孩子
2)当2i<=n时,结点i的左孩子编号为2i,否则无左孩子
3)当2i+1<=n时,结点i的右海子编号为2i+1,否则无右孩子
4、拓扑排序的作用
判断有向图是否有环路,求有向图的最长路径
5、数据结构的逻辑结构
三对角矩阵
前n-1行有:3(n-2)+2=3i-4个元素
第n行aij元素前有多少个元素:(j-i)+1
第
6、广义表转化为树
根据广义表构建二叉树
7、排序的插入次数
最好情况下,序列已经有序,每次选取递增序列进行比较,不需要移动元素,时间复杂度为O(n)
最坏情况下,序列逆序,每次都要比较,每次都要移动,比较2+3+…+n次,移动i+1次,哨兵操作两次,移动元素i-1次
稳定性,由于每次插入元素从事从后向前先比较在移动,所以不会发生位置变化
折半插入的比较次数
折半插入仅仅减少了比较次数O(nlog2n),时间复杂度还是O(n2)
冒泡排序
最好情况下,序列有序,第一趟检测到有序后flag为false则表明没有元素交换,从而直接退出,比较n-1次,移动0次,时间复杂度为O(n)
最坏情况下,序列逆序,进行n-1趟排序,第i趟排序进行n-i次比较,每次比较后移动3次交换元素Swap函数,
进行n-1趟比较,比较n-i次,移动3(n-i)次,时间复杂度为O(n2)
稳定性,当i>j时且A[i] == A[j]时不会发生交换,稳定排序,产生的序列是全局有序的
快速排序
最好情况下,元素基本逆序,递归树平衡,时间复杂度O(n2),空间复杂度O(log2n)
最坏情况下,元素在两个取于分别是n-1个和0个元素,元素基本有序,时间复杂度O(n2),空间复杂度O(n)
稳定性,在划分过程中,若区间内有小于基准的值,则在交换过程中相对位置会发生变化
排序后不会产生有序子序列,但是每趟排序后基准元素会被放在最终位置
选择排序
最好情况下,序列有序,比较n趟,比较i次(找最小元素),共n(n-1)/2次
最坏情况下,序列无序,比较n趟,比较i次,共n(n-1)/2次,因此时间复杂度始终为O(N2)
稳定性,在第i趟找最小元素后,可能会导致相同关键字元素的相对位置发生改变,因此是不稳定算法
堆排序
调整时间与树高有关,在n个元素的堆中,比较次数不超过4n,比较的时间复杂度为O(n)
建堆的时间为O(n),调整n-1次,每次O(h),h为树高,故时间复杂度为O(nlog2n)
适合于关键字特大的情况,不稳定,因为构建堆的过程中可能会交换相对位置
归并排序
算法思想,按照2,4,8,16,…,的间隔不断将多个有序子列表进行合并排序。
最好情况下,每趟的时间复杂度为O(n),需要进行log2n趟,故时间复杂度为O(nlog2n)
基数排序
将插入的记录按照插入顺序连接起来。
空间效率,一趟排序需要辅助空间为r(r个队列),O,r个关键字,d表示数字最大的位数
时间效率,基数需要进行d趟分配和收集,一趟分配需要O(n),一趟收集需要O,一趟的时间复杂复杂度为O(n+r),时间复杂度为O(d(n+r))。
8、堆的性质,建立,调整,插入
大根堆、小根堆:堆顶的元素都比双亲大或小,是完全二叉树
堆的建立,根据序列按照层序填充,插入的元素在最后
堆的调整,堆[n/2]-1个结点不断调整
9、哈夫曼树的性质
10、哈夫曼树的叶子结点的个数
11、二分查找的判定树的高度
log2n+1
12`、满二叉树
除了叶子结点外,每个结点的度都为2,左孩子结点为n/2,右孩子结点为2i+1
12、完全二叉树的性质
(1)i<n/2,则结点i为分支结点,否则为叶子结点
(2)叶子结点只可能在最大的两层数先,对于最大层次中的叶子结点,都依次排到该层的最左边
(3)若有度为1的结点,则只可能有1个,且该结点只有左孩子,没有右孩子
(4)按照层序编号,一旦出现某结点为叶子结点或只有左孩子,则编号大于i的结点均为叶子结点
(5)n为奇数时,每个分支结点都有左孩子和有孩子,n为偶数时编号最大的分支结点(n/2)只有左孩子,没有右孩子
13、冒泡排序的比较次数
冒泡排序
最好情况下,序列有序,第一趟检测到有序后flag为false则表明没有元素交换,从而直接退出,比较n-1次,移动0次,时间复杂度为O(n)
最坏情况下,序列逆序,进行n-1趟排序,第i趟排序进行n-i次比较,每次比较后移动3次交换元素Swap函数,
进行n-1趟比较,比较n-i次,移动3(n-i)次,时间复杂度为O(n2)
稳定性,当i>j时且A[i] == A[j]时不会发生交换,稳定排序,产生的序列是全局有序的
14、二分查找的平均查找长度
二叉排序树为平衡二叉树则高度为O(log2n),若为单只树(变成了链表)则为O(n)
二叉排序树生成树不唯一,当序列不同时树不同,二分查找的树唯一
15、三维数组的存储地址
16、关键路径的相关概念理解
AOE网特性:
(1)只有在某顶点所代表的事件发生后,从该顶点出发的各有向边代表的活动才能开始。
(2)只有在进入某顶点的各个有向边所代表的活动都结束时,该顶点所代表的事件才能发生
(3)AOE网中仅有一个入度为0的顶点,称为源点,表示整个工程的开始,仅仅有一个出度为0的点,称为汇点
从源点到汇点的路径中,具有最大长度的路径称为关键路径,关键路径上的活动称为关键活动。
完成整个工程的最短路径就是关键路径的长度,即关键路径上活动花费开销和,因为关键活动影响了工程的事件,若关键活动不按时完成,则会影响工程的完成时间
关键活动相关概念
1)事件最早发生事件ve
从前往后取最大,决定了所有v开始活动的最早时间,max
2)事件最晚发生事件vl
从后往前取最小,决定了所有v开始活动最迟发生时间,min
3)活动最早开始时间e
该弧 起点 表示的事件,最早发生时间,<k,j>表示边i,e(i)=ve(k)
4)活动最迟开始时间l
该弧 终点 表示的事件,最迟发生时间与该活动所需要时间的差,<k,j>表示边i,l(i)=vl(j)-weight(i)
5)最迟开始时间和最早开始时间差d
16.1、最短路径相关概念
单源最短路径:dijkstra,不适用带有负值的图,因为最短路径长度加上这条负值的俄结果可能小于a原先确定的最短路径长度,则无法进行更新。
时间复杂度:邻接矩阵,为O(v^2)
16.2、拓扑排序
有向图的无环图的排序
(1)每个顶点只出现一次
(2)若顶点A在序列中排在顶点B前面,则在图中不存在顶点B到顶点A的路径
拓扑排序是对有向无环图的一种排序,使得若存在一条边从顶点A到顶点B的路径,在排序中顶点B出现在顶点A的后面
bool Topological(Graph G)
{
InitStack(s);
for(int i = 0;i < G.vexnum;i++)
{
if(indegree[i] == 0)//将所有入度为0的结点入栈
push(s,i);
}
int count = 0;
while(!IsEmpty(s))//DFS思想
{
pop(s,i);//出栈
print[count++] = i;//访问
for(p = G.vertices[i].firstarc;p >= 0;p = p ->nextarc)//所有指向i的顶点入度减1,如果减完后的顶点度为0则入栈。
{
v = p->adjvex;
if(!(--indegree[v]))//入度为0则入栈
{
push(s,v);
}
}
}
if(count < G.vexnum)
return false;
else
return true;
}
bool Topo(Graph G)
{
InitStack(s);
for(i = 0;i < G.vexnum;i++)
{
if(indegree[i] == 0)
{
push(s,i);
}
}
int count = 0;
while(!IsEmpty(s))
{
pop(s,i);
print[count++] = i;
for(w = FirstNeighbor;w >= 0;w = NextNeighbor(G,w,v))
{
if(!(--indegree[v]))
push(s,v);
}
}
if(count < G.vexnum)
return false;
else
return true;
}
17、二叉树空链域的问题
n个结点的二叉链表中有n+1个空链域,n个结点有2n域,除了根结点外每个结点都被指向故有n-1个被占用
空=2n-(n-1)=n+1个
18、顺序查找的查找长度
查找成功:每个元素的比较次数n-i+1次,共n个元素,每个元素查找概率为1/n,(1+2+…+n)1/n,ASL=(n+1)/2
查找失败:每个元素比较次数为n+1次,ASL=n+1
有序表的顺序查找
n个结点,有n+1个查找失败的结点,n+1空指针域
除了第一个结点以外每个结点都有指针值指向该结点2n-(n-1)=2n-n+1=n+1个空指针域
查找成功:每个元素比较n-i+1次,共n个元素,每个元素查找概率为1/n,(1+2+…+n)1/n,ASL=(n+1)/2
查找失败:查找失败次数等于父圆形结点所在层数,最后一层有2个查找失败结点
每个查找失败的概率为1/(n+1),(1+2+…+n+n)/n+1=n/2 + n/(n+1)

**18.2、折半查找 **
int Binary_Search(SeqList L,ElemType key)
{
int low = 0,high = L.len-1,mid;
while(low <= high)
{
mid=(low+high)/2;
if(L.elem[mid] == key)
return mid;
else if(L.elem[mid] > key)
high = mid - 1;
else
low = mid + 1;
}
return -1;
}
n个元素,判定树有n个圆形结点和n+1个非圆形结点,是一棵平衡二叉树
查找成功:查找长度为根结点到目的结点路径上结点个数,也就是层高
查找失败:查找失败为根结点到目的结点上父亲结点个数,也就是层高
查找成功平均查找长度ASL=1/n(11+22+…+h2^h-1)=n+1/n log2(n+1) = log2(n+1) - 1=树高(多种表示方法)
时间复杂度为O(log2n)
查找成功平均查找长度ASL=(园形结点个数层数)/方形结点个数
查找失败平均查找长度ASL=(方形结点个数*层数)/方形结点个数
18.3、分块查找
分块查找:块内无序,块间有序
第一块中的最大关键字小于第二块中所有关键字,
第二块中的最大关键字小于第三块中所有关键字。。
索引表,索引表中有每个元素块中的最大关键字和各个块的第一个元素地址,索引表有序排列
平均查找长度ASL=L1+Ls
将长度为n的查找表均匀的分成b块(索引表),每块s的元素(块内),此时b和s相当于n
块内和索引在表中都采用顺序查找: ASL=L1+l2=(b+1)/2 + (s+1)/2
快内采用顺序查找、索引表采用折半查找:ASL=L1+Ls = log2(b+1) + (s+1)/2
19、三元组相关概念
20、k叉树的性质
树的基本性质:
(1)树中结点数等于所有结点度数之和+1
(2)度为m的树中第i层上最多有m^(i-1)个结点
(3)高度为h的m叉树中最多有(m^k - 1)/(m-1)个结点
(4)具有n个结点的m叉树最小高度为logm(n(m-1))+1
总结点数=n0+n1+n2+…+nm
总分支数=0n0+1n1+2n2+mnm(度为m的结点引出m条分支)
总结点数=总分支数+1
20、哈夫曼树
哈夫曼树中只有度为0和度为2的结点
度为m的哈夫曼树只有度0和m的结点,设度为m的结点有nm个,度为0的结点有n0个,结点总数为n,n=n0+nm
n个结点的哈夫曼树有n-1条分支,mn = n-1=nm+n0-1,整理得(m-1)nm=n0-1,nm=(n-1)/(m-1)
特点
(1)初始结点都为叶子结点,权值越小根根结点的路径月长
(2)构造过程中新建了n-1个结点(双分支结点),哈夫曼树结点总数为n+n-1=2n-1
(3)每次构造都选择两个树作为新的结点,因此不存在度为1的结点,只有度为0和2的结点
21、散列表的性质,k如何取值
散列函数可能会把两个或两个以上的不同关键字映射到同一地址,称这种情况为冲突,这些发生冲突的不同关键字称为同义词,这些冲突不可避免。
散列函数的构造
(1)散列函数定义域必须包括需要存储的关键字,值域的范围
(2)散列函数计算出来的地址应该能等概率、均匀的分布在整个地址空间,从而减少冲突
常见的散列函数:
(1)直接定址法:适合关键字分布基本连续的情况
(2)除留余数法:散列表的长度为m,取一个不大于m但接近或等于m的质数
(3)数字分析法
(4)平方折中法
处理冲突的方法
(1)开放地址法
1)线形探测
平均查找长度
ASL成功 =(比较次数*关键字个数)/总关键字个数
ASL失败 =(查找失败次数 * 关键字个数)/p的查找个数,地址的范围为p的取值范围
2)平方探测
3)在散列法
4)伪随即法
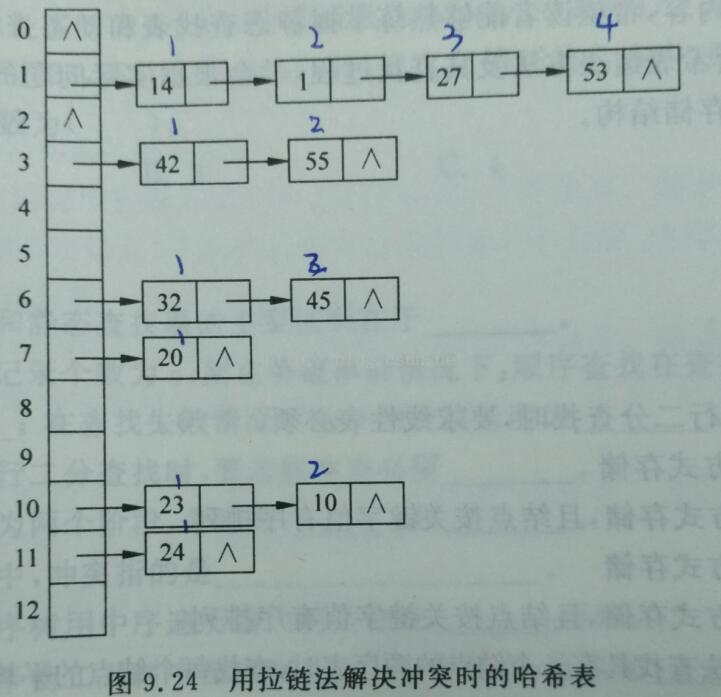
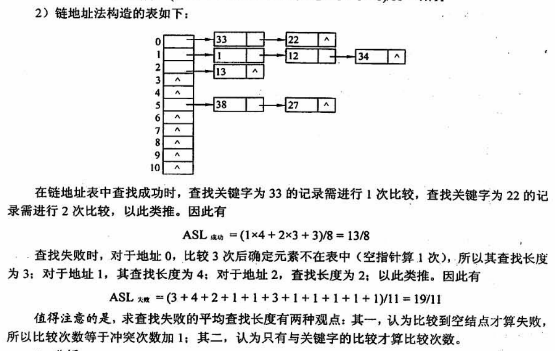
(2)拉链法
平均查找长度
ASL成功 =(关键字的位置*关键字的个数)/总关键字个数
ASL失败 =(查找失败次数 * 关键字个数)/p的查找个数(表长吗,答不是),地址的范围为p的取值范围
对于每一个同义词进行查找,
装填因子a=表中记录n/三列表长度m,
平均查找长度依赖于装填因子,不直接依赖于m和n,装填因子越大,表示记录越满,发生冲突可能性越大
https://blog.csdn.net/u011080472/article/details/51177412
22、各种排序的性质,时间复杂度,与初始序列是否有关
23、图的十字链表法、三元组、多重链表的画法
邻接表
以某个结点为起点,每个结点依次指向与其相连的顶点
#typedef MaxVerterNum 100
typedef struct ArcNode//边表结点
{
int adjvex;//邻接点域
struct ArcNode *next;//指针域
}ArcNode;
typedef struct VNode//顶点表结点
{
VertexType data;//数据域
ArcNode *first;//边表头指针
}VNode,AdjList[MaxVertexNum];
typedef struct
{
AdjList vertices;//邻接表
int vexnum,arcnum;
}ALGraph;//图
邻接表特点
(1)若图G为无向图,需要的空间为O(V+2E),因为不区分方向,只要有相邻的边就表示出来,若G为有向图,需要空间为O(V+E)。
(2)给定一定的点,很容易找到所有的边,为O(n),但是要找到顶点之间是否存在边,邻接表为O(n^2)
(3)有向图的邻接矩阵,出度为邻接表的结点个数,求入度需要遍历整个表。无向图,为顶点的个数
十字链表法
弧结点:[tailvex][headvex][hlink][tlnik][infor]
taillvex:尾弧结点
headvex:头弧结点
hlink:指向头相同的下一条边
tlink:指向尾相同的下一条边
顶点结点:[data][firstin][firstout]
firstin:第一条入度边
firstout:第一条出度边
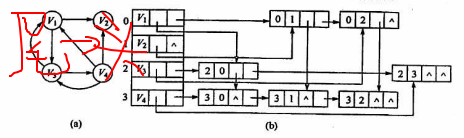
可以方便的求出度和入度信息,但是删除麻烦
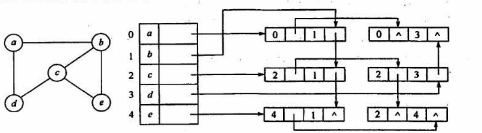
邻接多重表
边表:[mark][ivex][ilink][jvex][info]
ilink:指向下一条依附于ivex的边,相同尾巴
jlink:指向下一条依附于顶点jvex的边,相同头
24、数据结构相关的基础概念
25、树和二叉树的区别、性质
26、二叉树的平衡调整
二叉树调整笔记
27、二叉线索树
中序线索化创建
1、如果左子树为空,建立前驱线索
2、如果pre不为空且pre的右孩子为NULL,建立前驱结点的后继线索
pre标记刚刚访问过的结点
void InTread(ThreadTree &p,ThreadTree &pre)
{
if(p != NULL)
{
InThread(p->lchild,pre);
if(p->lchild == NULL)
{
p->lchild = pre;
p->ltag = 1;
}
else
{
p->ltag = 0;
}
if(pre != NULL && pre->rchild == NULL)
{
pre->rchild = p;
pre->rtag=1;
}
else
{
p->rtag=0;
}
pre = p;
InThread(p->rchild,pre);
}
}
void preTread(ThreadTree &p,ThreadTree &pre)
{
if(p != NULL)
{
if(p->lchild != NULL)
{
p->lchild = pre;
p->ltag = 1;
}
else
{
p->ltag=0;
}
if(pre != NULL && pre->rchild == NULL)
{
pre->rchild=p;
pre->rtag = 1
}
else
{
pre->ltag = 0;
}
pre = p;
}
}
ThreadNode *FirstNode(ThreadNode *p)
{
while(p->ltag == 0)
p = p->lchild;
return p;
}
ThreadNode *NextNode(ThreadNode )
{
if(p->rtag == 0)//如果p右子树没有线索,则找右子树中的第一个结点就是他的后继
return FistNode(p->rchild);
else
return p->child;
}
void Inorder(ThreadNode *T)
{
for(ThreadNode *p = FistNode(T);p != NULL;p = NextNode(p))
visit(p);
}
BDAEC
DBEACG
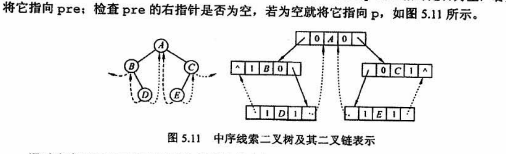
中序线索二叉树
1、查找p的前驱:查找左线索,若无左线索,结点的前驱是遍历左子树访问的最后一个结点
2、查找p的后继,查找右线索,若无右线索,结点的后继是遍历右子树访问的第一个结点。
29、树与二叉树、森林的转换
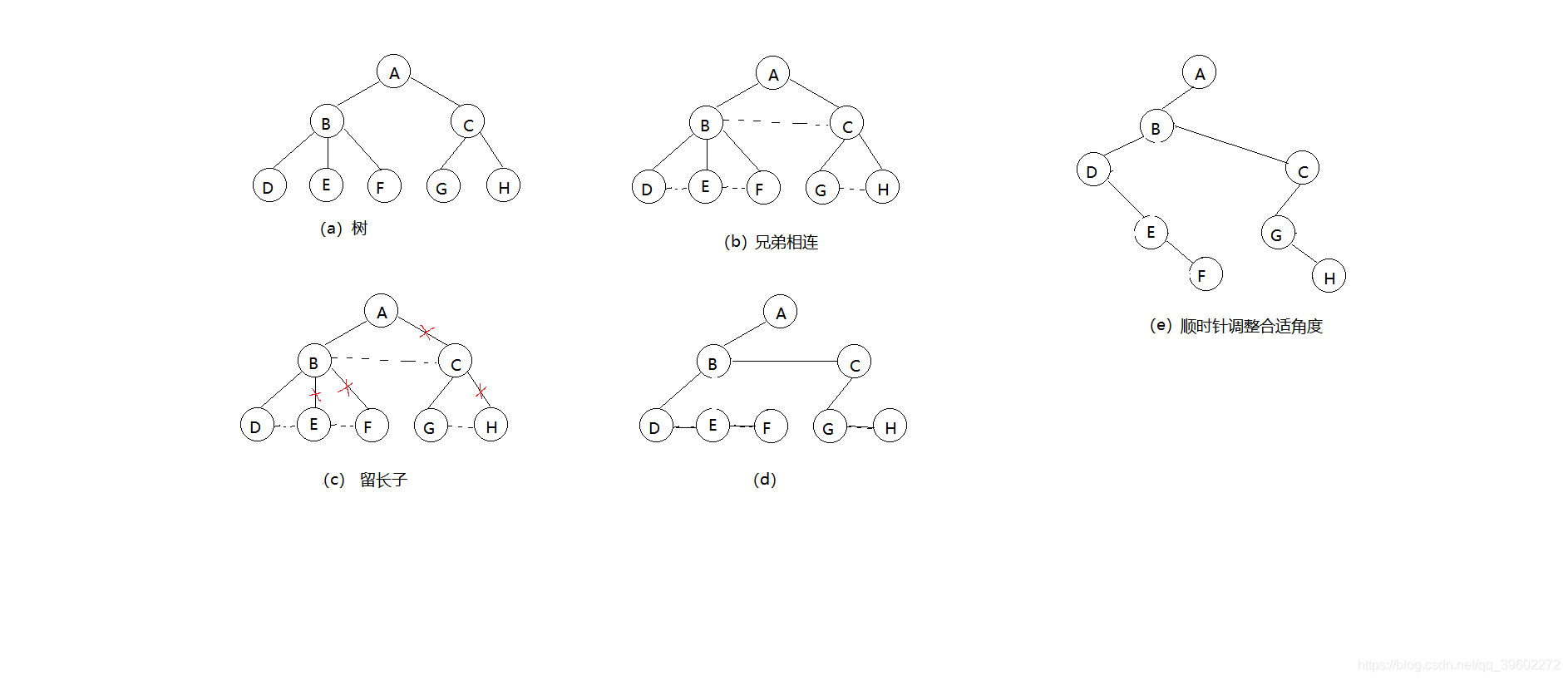
(1)树转二叉树
兄弟相连,留长子
1)加线,在所有兄弟结点之间加线
2)去线,树中的每个结点,只保留与它与第一个孩子结点的连线,删除与其他孩子结点之间的连线
3)层次调整
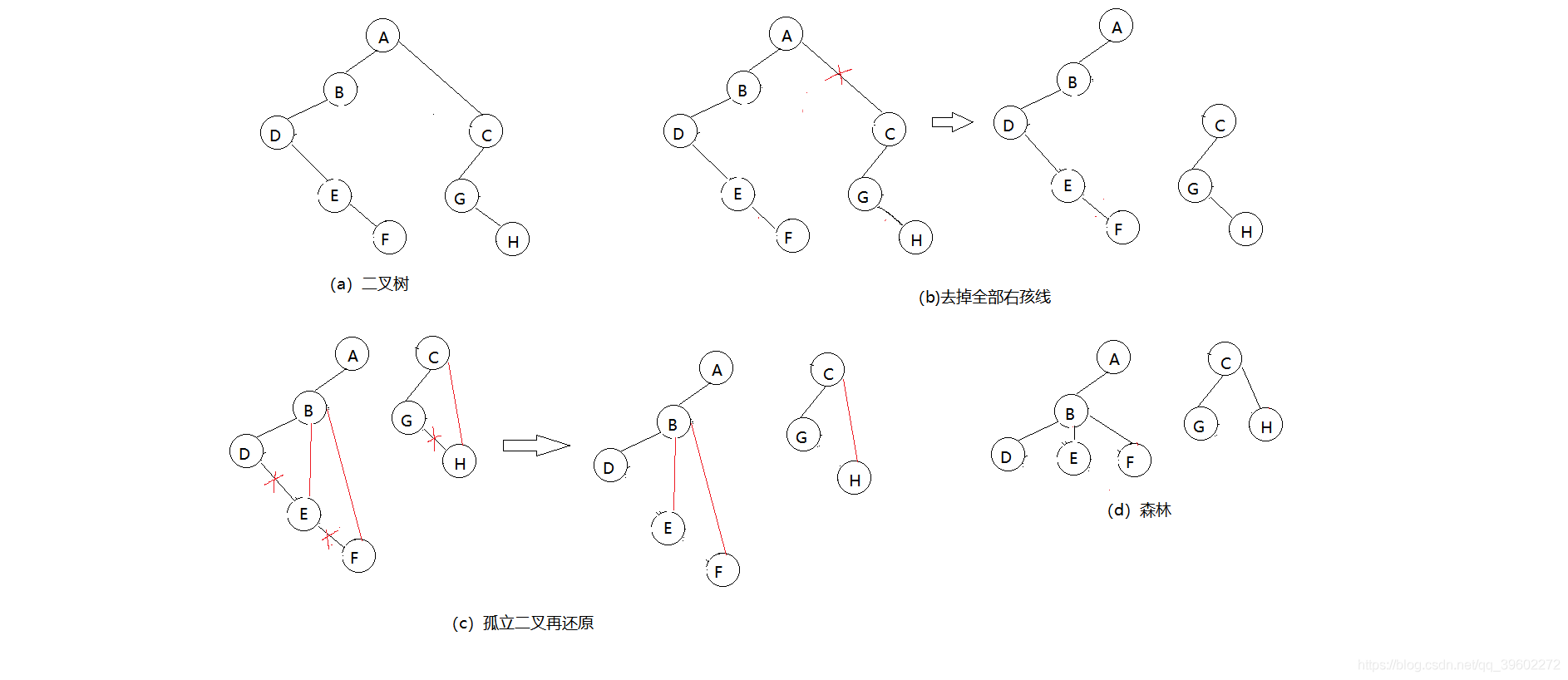
(2)森林转为二叉树
去掉全部右孩线,孤立二叉在还原
1)把每棵树转为二叉树
2)第一棵树不动,从第二棵树开始,依次把根结点作为前一棵二叉树的根结点的右孩子,连接起来
(3)二叉树转树
左孩右右连双亲,去掉原来右孩线
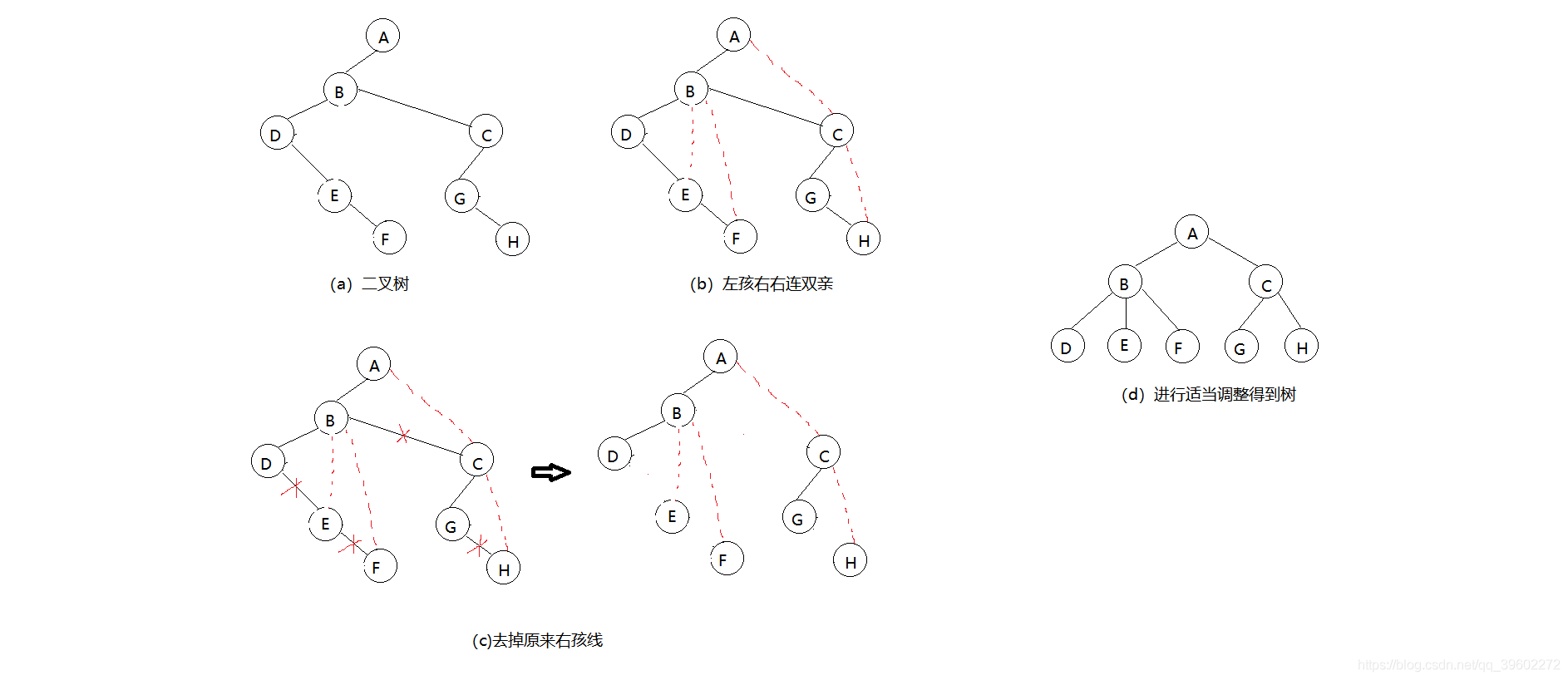
(4)森林转为二叉树
树变二叉根相连
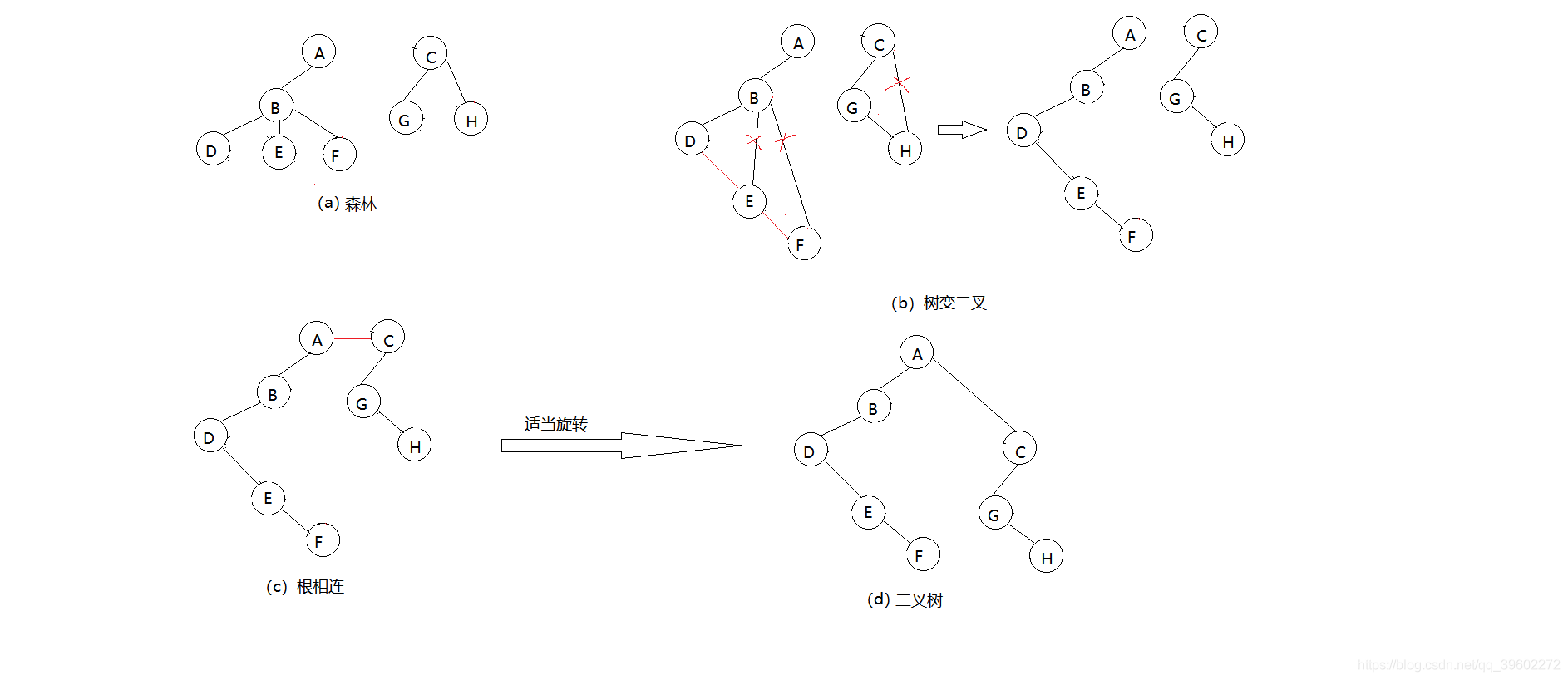
二叉树、森林的转换
30、二叉排序树的删除
(1)若被删除的结点z是叶子结点,则直接删除
(2)若被删除的结点z只有一颗左子树或者右子树,则让z的子树称为z父结点的子树,代替z的位置
(3)若被删除的结点z有左右两棵子树,则令z的直接后继代替z,然后从二叉排序树中删除这个直接后继或者直接前驱,变成了第一二情况
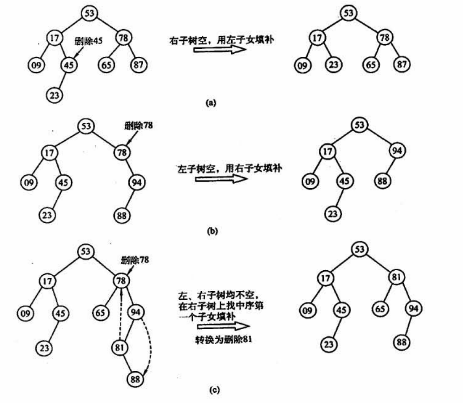
31、二叉排序树平均查找长度
二叉排序树查找效率取决于树的高度,若二叉排序树为平衡二叉树则高度为O(log2n),若为单只树(变成了链表)则为O(n)
二叉排序树生成树不唯一,当序列不同时树不同,二分查找的树唯一
32、图的边、顶点、度
简单路径:路径中,顶点不重复出现的路径称为简单路径。
简单回路:除第一个顶点和最后一个顶点外,其余顶点不重复出现的回路称为简单回路。
完全图,无向图有n(n-1)/2条边,任意两个顶点之间都存在边,有向图有n(n-1)条边,任意两个顶点之间都存在方向相反的弧
无向图,n个顶点有n-1条边,构成一个完全图,则为最小连通图,若多余n-1则为回路
有向图,n个顶点至少n条边,构成一个环路
若一个图有n个顶点,并且有大于n-1条边,则一定有环
33、BFS相关
BFS类似树的层序遍历
生成树不唯一
采用邻接表存储,每个顶点均被搜索入队一次,时间复杂度为O(V),在搜索邻接顶点时每条边至少被访问一次,时间复杂度为O(E),总的时间复杂度为O(V+E)
采用邻接矩阵存储,查找每个顶点的邻接点需要O(V),故需要O(V^2)
bool BFSTraverse(Graph G)
{
for(i = 0;i < G.vexnum;++i)
{
visited[i] = False;
}
InitQueue(Q);
for(i = 0;i < G.vexnum;++i)
{
if(!visited[i])
{
BFS(G,i);
}
}
}
void BFS(Graph G,int v)
{
visit(v);//访问v
visited[v] = True;//数组置为1
EnQueue(Q,v);//入队列
while(!IsEmpty(Q))//如果队列不空
{
DeQueue(Q,v);//出队列
for(w = FirstNeighbor(G,v);w >= 0;w = NextNeighbor(G,v,w))//查找v相邻的边
{
if(!visited[i])//如果不空
{
visit(w);//访问
visited[w] = True;
EnQueue(Q,w);//入队
}
}
}
}
//BFS求单源最短路径
void BFS_MIN_Distance(Graph G,int u)
{
for(i = 0;i < G.vexnum;++i)
{
d[i] = #;
}
EnQueue(Q,u);
while(!Isempty(Q))
{
DeQueue(Q,u);
for(w = FirstNeighbor(G,u);w >= 0;w = NextNeighbor(G,u,w))
{
if(!visited[w])
{
visited[w] = True;
d[w] = d[u]+1;//如果有路径则+1
EnQueue(Q,w);
}
}
}
}
33、DFS
DFS类似于树的先序遍历
DFS生成树和生成森林不唯一
void BFSTravers(Graph G)
{
for(v = 0;v < G.vexnum;++v)
{
visit[v] = FAlse;
}
for(v = 0;v < G.vexnum;++v)
{
if(!visited[v])
DFS((G,v);
}
}
void DFS(Graph G,int v)
{
visit(v);
visited[v] = True;
for(w = FirstNeighbor(G,v);w >= 0;w = NextNeighbor(G,v,w))
{
if(!visited[w])
(
DFS(G,w);
)
}
}
void DFS1(Graph G,int v)
{
InitStack(S);
visit(v);
visited[v] = True;
push(S,v);
while(!IsEmpty(S))
{
pop(S,v);//出栈以后访问
visit(v);
for(w = FirstNeighbor(G,v);w >= 0;w = Neighbor(G,v,w))
{
if(!visited[w])
{
push(S,w);
visited[w] = True;//每次进栈都要置为1
}
}
}
}
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数