NLP 使用Word2vec实现文本分类_word2vec 使用-程序员宅基地
本文为[365天深度学习训练营学习记录博客
参考文章:365天深度学习训练营
原作者:[K同学啊 | 接辅导、项目定制]\n 文章来源:[K同学的学习圈子](https://www.yuque.com/mingtian-fkmxf/zxwb45)
一、加载数据

import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
import pandas as pd
# 加载自定义中文数据
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
print(train_data)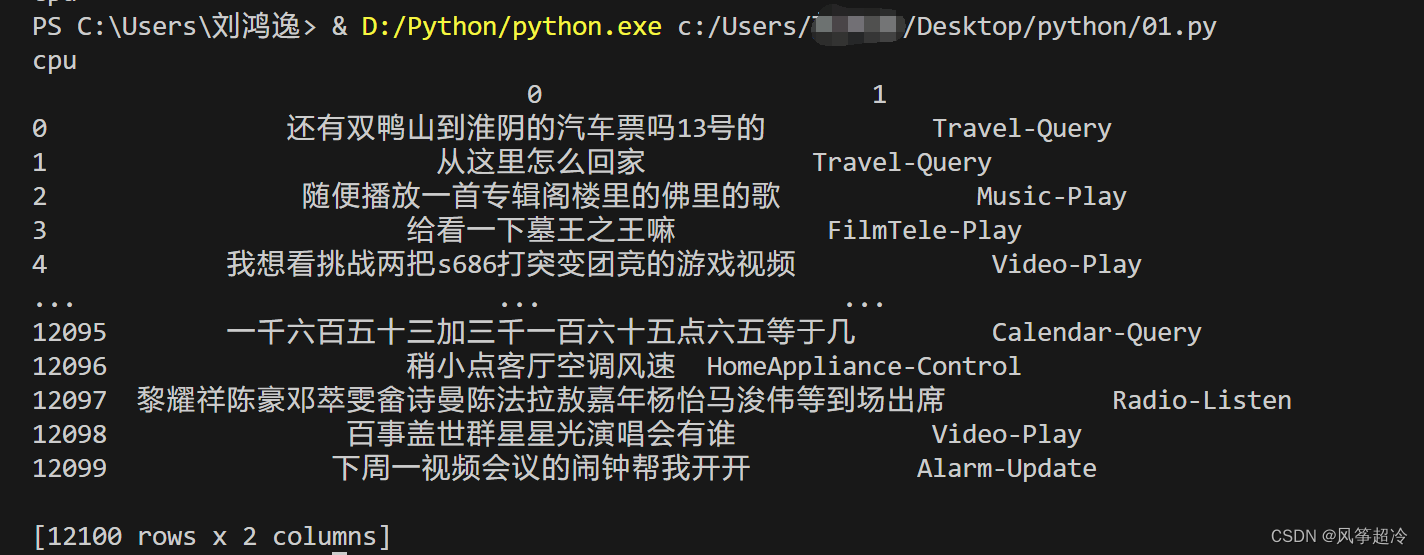
二、构造数据迭代器
# 构造数据集迭代器
def coustom_data_iter(texts, labels):
for x, y in zip(texts, labels):
yield x, y
x = train_data[0].values[:]
#多类标签的one-hot展开
y = train_data[1].values[:]
print(x,"\n",y)yield x, y:使用 yield 关键字,将每次迭代得到的 (x, y) 元组作为迭代器的输出。yield 的作用类似于 return,但不同之处在于它会暂停函数的执行,并将结果发送给调用方,但函数的状态会被保留,以便下次调用时从上次离开的地方继续执行。

三、构建词典
from gensim.models.word2vec import Word2Vec
import numpy as np
# 训练 Word2Vec 浅层神经网络模型
w2v = Word2Vec(vector_size=100, #是指特征向量的维度,默认为100。
min_count=3) #可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5。
w2v.build_vocab(x)
w2v.train(x,
total_examples=w2v.corpus_count,
epochs=20)
Word2Vec可以直接训练模型,一步到位。这里分了三步
-
Word2Vec(vector_size=100, min_count=3): 创建了一个Word2Vec对象,设置了词向量的维度为100,同时设置了词频最小值为3,即只有在训练语料中出现次数不少于3次的词才会被考虑。 -
w2v.build_vocab(x): 使用 build_vocab 方法根据输入的文本数据 x 构建词典。build_vocab 方法会统计输入文本中每个词汇出现的次数,并按照词频从高到低的顺序将词汇加入词典中。 -
w2v.train(x, total_examples=w2v.corpus_count, epochs=20): 训练Word2Vec模型,其中:
x是训练数据。total_examples=w2v.corpus_count:total_examples 参数指定了训练时使用的文本数量,这里使用的是 w2v.corpus_count 属性,表示输入文本的数量epochs=20指定了训练的轮数,每轮对整个数据集进行一次训练。
# 将文本转化为向量
def average_vec(text):
vec = np.zeros(100).reshape((1, 100))
for word in text:
try:
vec += w2v.wv[word].reshape((1, 100))
except KeyError:
continue
return vec
# 将词向量保存为 Ndarray
x_vec = np.concatenate([average_vec(z) for z in x])
# 保存 Word2Vec 模型及词向量
w2v.save('w2v_model.pkl')这段代码逐步完成了将文本转化为词向量的过程,并保存了Word2Vec模型及词向量。
-
average_vec(text): 这个函数接受一个文本列表作为输入,并返回一个平均词向量。它首先创建了一个形状为(1, 100)的全零NumPy数组vec,用于存储文本的词向量的累加和。然后,它遍历文本中的每个词,尝试从已经训练好的Word2Vec模型中获取词向量,如果词在模型中存在,则将其词向量加到vec中。如果词不在模型中(KeyError异常),则跳过该词。最后,返回词向量的平均值。 -
x_vec = np.concatenate([average_vec(z) for z in x]): 这一行代码使用列表推导式,对数据集中的每个文本z调用average_vec函数,得到文本的词向量表示。然后,使用np.concatenate函数将这些词向量连接成一个大的NumPy数组x_vec。这个数组的形状是(样本数, 100),其中样本数是数据集中文本的数量。 -
w2v.save('w2v_model.pkl'): 这一行代码保存了训练好的Word2Vec模型及词向量。w2v.save()方法将整个Word2Vec模型保存到文件中。
train_iter = coustom_data_iter(x_vec, y)
print(len(x),len(x_vec))-
train_iter = coustom_data_iter(x_vec, y): 这行代码创建了一个名为train_iter的迭代器,用于迭代训练数据。它调用了一个名为coustom_data_iter的函数,该函数接受两个参数x_vec和y,分别表示训练样本的特征和标签。在这个上下文中,x_vec是一个NumPy数组,包含了训练样本的特征向量表示,y是一个数组,包含了训练样本的标签。该迭代器将用于训练模型。 -
print(len(x),len(x_vec)): 这行代码打印了训练数据的长度,即x的长度和x_vec的长度。在这里,len(x)表示训练样本的数量,len(x_vec)表示每个样本的特征向量的长度(通常表示特征的维度)。这行代码的目的是用于验证数据的准备是否正确,以及特征向量的维度是否与预期一致。
![]()
label_name = list(set(train_data[1].values[:]))
print(label_name)
四、生成数据批次和迭代器
text_pipeline = lambda x: average_vec(x)
label_pipeline = lambda x: label_name.index(x)
print(text_pipeline("你在干嘛"))
print(label_pipeline("Travel-Query"))-
text_pipeline = lambda x: average_vec(x): 这一行定义了一个名为text_pipeline的匿名函数(lambda函数),它接受一个参数x(文本数据)。在函数体内部,它调用了前面定义的average_vec函数,将文本数据x转换为词向量的平均值。 -
label_pipeline = lambda x: label_name.index(x): 这一行定义了另一个匿名函数label_pipeline,它接受一个参数x,该参数表示标签数据。在函数体内部,它调用了index方法来查找标签在label_name列表中的索引,并返回该索引值。 -
print(text_pipeline("你在干嘛")): 这行代码调用了text_pipeline函数,将字符串 "你在干嘛" 作为参数传递给函数。函数会将这个文本转换为词向量的平均值,并打印出来。 -
print(label_pipeline("Travel-Query")): 这行代码调用了label_pipeline函数,将字符串 "Travel-Query" 作为参数传递给函数。函数会在label_name列表中查找 "Travel-Query" 的索引,并打印出来。

from torch.utils.data import DataLoader
def collate_batch(batch):
label_list, text_list= [], []
for (_text, _label) in batch:
# 标签列表
label_list.append(label_pipeline(_label))
# 文本列表
processed_text = torch.tensor(text_pipeline(_text), dtype=torch.float32)
text_list.append(processed_text)
label_list = torch.tensor(label_list, dtype=torch.int64)
text_list = torch.cat(text_list)
return text_list.to(device),label_list.to(device)
# 数据加载器,调用示例
dataloader = DataLoader(train_iter,
batch_size=8,
shuffle =False,
collate_fn=collate_batch)-
text_pipeline = lambda x: average_vec(x): 这行代码创建了一个名为text_pipeline的匿名函数,该函数接受一个参数x,表示文本数据。在这里,text_pipeline函数被定义为average_vec(x),即调用之前定义的average_vec函数,用来将文本转换为向量表示。 -
label_pipeline = lambda x: label_name.index(x): 这行代码创建了一个名为label_pipeline的匿名函数,该函数接受一个参数x,表示标签数据。在这里,label_pipeline函数被定义为label_name.index(x),即查找x在label_name列表中的索引,返回其索引值作为标签的表示。 -
collate_batch(batch): 这是一个自定义的函数,用于处理一个批次(batch)的数据。它接受一个批次的数据作为输入,并对数据进行处理,最后返回处理后的文本和标签列表。 -
在
collate_batch函数中:- 首先,创建了两个空列表
label_list和text_list,用于存储标签和文本数据。 - 然后,对批次中的每个样本进行遍历,提取样本的文本和标签。
- 对于标签部分,调用了
label_pipeline函数将标签转换为模型可接受的格式,并添加到label_list中。 - 对于文本部分,调用了
text_pipeline函数将文本转换为向量表示,并转换为 PyTorch 张量格式,并添加到text_list中。 - 最后,将
label_list转换为 PyTorch 整数张量格式,将text_list进行拼接并转换为 PyTorch 浮点数张量格式,并返回这两个张量。
- 首先,创建了两个空列表
-
dataloader = DataLoader(train_iter, batch_size=8, shuffle=False, collate_fn=collate_batch): 这行代码创建了一个 PyTorch 的数据加载器DataLoader,用于加载训练数据。其中参数说明如下:train_iter是之前定义的用于迭代训练数据的迭代器。batch_size=8指定了每个批次的样本数量为 8。shuffle=False表示不对数据进行洗牌,即不打乱样本的顺序。collate_fn=collate_batch指定了数据加载器在每个批次加载数据时调用的数据处理函数为collate_batch函数,用于处理每个批次的数据。
五、构建模型
from torch import nn
class TextClassificationModel(nn.Module):
def __init__(self, num_class):
super(TextClassificationModel, self).__init__()
self.fc = nn.Linear(100, num_class)
def forward(self, text):
return self.fc(text)
num_class = len(label_name)
vocab_size = 100000
em_size = 12
model = TextClassificationModel(num_class).to(device)
import time
def train(dataloader):
model.train() # 切换为训练模式
total_acc, train_loss, total_count = 0, 0, 0
log_interval = 50
start_time = time.time()
for idx, (text,label) in enumerate(dataloader):
predicted_label = model(text)
optimizer.zero_grad() # grad属性归零
loss = criterion(predicted_label, label) # 计算网络输出和真实值之间的差距,label为真实值
loss.backward() # 反向传播
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪
optimizer.step() # 每一步自动更新
# 记录acc与loss
total_acc += (predicted_label.argmax(1) == label).sum().item()
train_loss += loss.item()
total_count += label.size(0)
if idx % log_interval == 0 and idx > 0:
elapsed = time.time() - start_time
print('| epoch {:1d} | {:4d}/{:4d} batches '
'| train_acc {:4.3f} train_loss {:4.5f}'.format(epoch, idx,len(dataloader),
total_acc/total_count, train_loss/total_count))
total_acc, train_loss, total_count = 0, 0, 0
start_time = time.time()
def evaluate(dataloader):
model.eval() # 切换为测试模式
total_acc, train_loss, total_count = 0, 0, 0
with torch.no_grad():
for idx, (text,label) in enumerate(dataloader):
predicted_label = model(text)
loss = criterion(predicted_label, label) # 计算loss值
# 记录测试数据
total_acc += (predicted_label.argmax(1) == label).sum().item()
train_loss += loss.item()
total_count += label.size(0)
return total_acc/total_count, train_loss/total_count六、训练模型
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 超参数
EPOCHS = 10 # epoch
LR = 5 # 学习率
BATCH_SIZE = 64 # batch size for training
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None
# 构建数据集
train_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)
split_train_, split_valid_ = random_split(train_dataset,
[int(len(train_dataset)*0.8),int(len(train_dataset)*0.2)])
train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
for epoch in range(1, EPOCHS + 1):
epoch_start_time = time.time()
train(train_dataloader)
val_acc, val_loss = evaluate(valid_dataloader)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
if total_accu is not None and total_accu > val_acc:
scheduler.step()
else:
total_accu = val_acc
print('-' * 69)
print('| epoch {:1d} | time: {:4.2f}s | '
'valid_acc {:4.3f} valid_loss {:4.3f} | lr {:4.6f}'.format(epoch,
time.time() - epoch_start_time,
val_acc,val_loss,lr))
print('-' * 69)
test_acc, test_loss = evaluate(valid_dataloader)
print('模型准确率为:{:5.4f}'.format(test_acc))| epoch 1 | 50/ 152 batches | train_acc 0.732 train_loss 0.02655
| epoch 1 | 100/ 152 batches | train_acc 0.822 train_loss 0.01889
| epoch 1 | 150/ 152 batches | train_acc 0.838 train_loss 0.01798
---------------------------------------------------------------------
| epoch 1 | time: 0.93s | valid_acc 0.812 valid_loss 0.019 | lr 5.000000
---------------------------------------------------------------------
| epoch 2 | 50/ 152 batches | train_acc 0.840 train_loss 0.01745
| epoch 2 | 100/ 152 batches | train_acc 0.843 train_loss 0.01807
| epoch 2 | 150/ 152 batches | train_acc 0.843 train_loss 0.01846
---------------------------------------------------------------------
| epoch 2 | time: 1.01s | valid_acc 0.854 valid_loss 0.020 | lr 5.000000
---------------------------------------------------------------------
| epoch 3 | 50/ 152 batches | train_acc 0.850 train_loss 0.01770
| epoch 3 | 100/ 152 batches | train_acc 0.850 train_loss 0.01675
| epoch 3 | 150/ 152 batches | train_acc 0.859 train_loss 0.01565
---------------------------------------------------------------------
| epoch 3 | time: 0.98s | valid_acc 0.836 valid_loss 0.023 | lr 5.000000
---------------------------------------------------------------------
| epoch 4 | 50/ 152 batches | train_acc 0.898 train_loss 0.00972
| epoch 4 | 100/ 152 batches | train_acc 0.892 train_loss 0.00936
| epoch 4 | 150/ 152 batches | train_acc 0.900 train_loss 0.00948
---------------------------------------------------------------------
| epoch 4 | time: 0.91s | valid_acc 0.879 valid_loss 0.011 | lr 0.500000
---------------------------------------------------------------------
| epoch 5 | 50/ 152 batches | train_acc 0.911 train_loss 0.00679
| epoch 5 | 100/ 152 batches | train_acc 0.899 train_loss 0.00786
| epoch 5 | 150/ 152 batches | train_acc 0.903 train_loss 0.00752
---------------------------------------------------------------------
| epoch 5 | time: 0.91s | valid_acc 0.879 valid_loss 0.010 | lr 0.500000
---------------------------------------------------------------------
| epoch 6 | 50/ 152 batches | train_acc 0.905 train_loss 0.00692
| epoch 6 | 100/ 152 batches | train_acc 0.915 train_loss 0.00595
| epoch 6 | 150/ 152 batches | train_acc 0.910 train_loss 0.00615
---------------------------------------------------------------------
| epoch 6 | time: 0.90s | valid_acc 0.880 valid_loss 0.010 | lr 0.050000
---------------------------------------------------------------------
| epoch 7 | 50/ 152 batches | train_acc 0.907 train_loss 0.00615
| epoch 7 | 100/ 152 batches | train_acc 0.911 train_loss 0.00602
| epoch 7 | 150/ 152 batches | train_acc 0.908 train_loss 0.00632
---------------------------------------------------------------------
| epoch 7 | time: 0.92s | valid_acc 0.881 valid_loss 0.009 | lr 0.050000
---------------------------------------------------------------------
| epoch 8 | 50/ 152 batches | train_acc 0.903 train_loss 0.00656
| epoch 8 | 100/ 152 batches | train_acc 0.915 train_loss 0.00582
| epoch 8 | 150/ 152 batches | train_acc 0.912 train_loss 0.00578
---------------------------------------------------------------------
| epoch 8 | time: 0.93s | valid_acc 0.881 valid_loss 0.009 | lr 0.050000
---------------------------------------------------------------------
| epoch 9 | 50/ 152 batches | train_acc 0.903 train_loss 0.00653
| epoch 9 | 100/ 152 batches | train_acc 0.913 train_loss 0.00595
| epoch 9 | 150/ 152 batches | train_acc 0.914 train_loss 0.00549
---------------------------------------------------------------------
| epoch 9 | time: 0.93s | valid_acc 0.877 valid_loss 0.009 | lr 0.050000
---------------------------------------------------------------------
| epoch 10 | 50/ 152 batches | train_acc 0.911 train_loss 0.00565
| epoch 10 | 100/ 152 batches | train_acc 0.908 train_loss 0.00584
| epoch 10 | 150/ 152 batches | train_acc 0.909 train_loss 0.00604
---------------------------------------------------------------------
| epoch 10 | time: 0.91s | valid_acc 0.878 valid_loss 0.009 | lr 0.005000
---------------------------------------------------------------------
模型准确率为:0.8781七、测试指定数据
def predict(text, text_pipeline):
with torch.no_grad():
text = torch.tensor(text_pipeline(text), dtype=torch.float32)
print(text.shape)
output = model(text)
return output.argmax(1).item()
# ex_text_str = "随便播放一首专辑阁楼里的佛里的歌"
ex_text_str = "还有双鸭山到淮阴的汽车票吗13号的"
model = model.to("cpu")
print("该文本的类别是:%s" %label_name[predict(ex_text_str, text_pipeline)])
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象