搞清楚Java值传递还是引用传递-程序员宅基地
技术标签: 死磕面试系列 java android 开发语言

作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人
个人主页:Leo的博客
当前专栏:每天一个知识点
特色专栏: MySQL学习
本文内容:搞清楚Java值传递还是引用传递
个人知识库: [Leo知识库]https://gaoziman.gitee.io/blogs/),欢迎大家访问
1.基本数据类型和引用数据类型的不同
所谓数据类型,是编程语言中对内存的一种抽象表达方式,我们知道程序是由代码文件和静态资源组成,在程序被运行前,这些代码存在在硬盘里,程序开始运行,这些代码会被转成计算机能识别的内容放到内存中被执行。
因此
数据类型实质上是用来定义编程语言中相同类型的数据的存储形式,也就是决定了如何将代表这些值的位存储到计算机的内存中。
所以,数据在内存中的存储,是根据数据类型来划定存储形式和存储位置的。
那么Java的数据类型有哪些?
1.1 基本数据类型
Java中的基本数据类型包括以下几种:
- 整数类型:
- byte(字节型):占用1个字节,取值范围为-128到127。
- short(短整型):占用2个字节,取值范围为-32768到32767。
- int(整型):占用4个字节,取值范围为-2147483648到2147483647。
- long(长整型):占用8个字节,取值范围为-9223372036854775808到9223372036854775807。
- 浮点类型:
- float(单精度浮点型):占用4个字节,表示小数,取值范围为正负3.40282347e+38F。
- double(双精度浮点型):占用8个字节,表示小数,取值范围为正负1.79769313486231570e+308。
- 字符类型:
- char(字符型):占用2个字节,表示单个字符,取值范围为0到65535,采用Unicode编码。
- 布尔类型:
- boolean(布尔型):占用1个字节,表示true或false。
也可以通过下面这个表格来感受一下
| 数据类型 | 默认值 | 大小 | 取值范围 | 举例 |
|---|---|---|---|---|
| boolean | false | 1 比特 | true / false | boolean b = true |
| char | ‘\u0000’ | 2 字节 | 0 - 2^16-1 | char c = ‘c’; |
| byte | 0 | 1 字节 | -2^7 - 2^7-1 | byte b = 10; |
| short | 0 | 2 字节 | -2^15 - 2^15-1 | short s = 10; |
| int | 0 | 4 字节 | -2^31 - 2^31-1 | int i = 10; |
| long | 0L | 8 字节 | -2^63 - 2^63-1 | long l = 10l; |
| float | 0.0f | 4 字节 | -2^31 - 2^31-1 | float f = 10.0f; |
| double | 0.0 | 8 字节 | -2^63 - 2^63-1 | double d = 10.0d; |
1.2 引用数据类型
引用类型:引用也叫句柄,引用类型,是编程语言中定义的在句柄中存放着实际内容所在地址的地址值的一种数据形式。它主要包括:
Java中的引用数据类型包括以下几种:
- 类(Class):Java中的类是一种引用类型,它是用来描述对象的模板,可以创建多个实例。类定义了对象的属性和方法,可以通过实例化类的方式创建对象,并调用对象的方法。
- 接口(Interface):Java中的接口是一种抽象类型,它定义了一组方法的签名,但没有具体的实现。接口被用来定义通用的行为,可以被多个类实现,从而实现多态性。
- 数组(Array):Java中的数组是一种引用类型,它是由相同类型的元素构成的集合。数组用于存储一组数据,可以按照下标访问每个元素,数组的长度是固定的。
- 枚举(Enum):Java中的枚举是一种特殊的类,用于定义一组固定的常量。枚举常量在使用时可以直接引用,不需要进行实例化。
- 注解(Annotation):Java中的注解是一种特殊的接口类型,用于给程序中的元素(如类、方法、字段等)添加额外的信息。注解可以帮助编译器或其他工具生成代码或文档,也可以用于运行时的处理。
除此之外,Java中还有一些预定义的类,如String、Integer、Double等,它们也属于引用类型。这些类提供了常见的操作和方法,可以方便地处理字符串、数字等数据。
有了数据类型,JVM对程序数据的管理就规范化了,不同的数据类型,它的存储形式和位置是不一样的,要想知道JVM是怎么存储各种类型的数据,就得先了解JVM的内存划分以及每部分的职能。
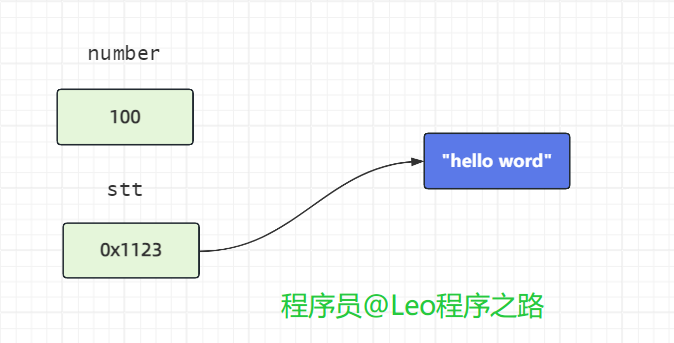
如图所示,number是基本数据类型,值就直接保存在变量中。而str是引用数据类型,变量中保存的只是实际对象的地址。一般称这种变量为引用,引用指向实际对象,实际对象中保存着内容。
2.赋值运算符(=)的作用
number = 20;
str = “Leo”;
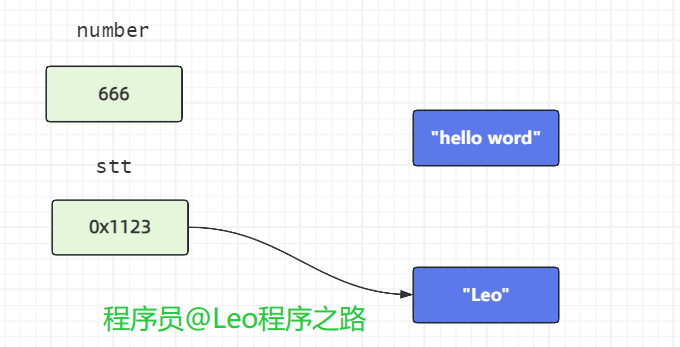
对于基本类型 number ,赋值运算符会直接改变变量的值,原来的值被覆盖掉。如上图直接改为666
对于引用类型 str,赋值运算符会改变引用中所保存的地址,原来的地址被覆盖掉。但是原来的对象不会被改变(重要)。
如上图所示,hello 字符串对象没有被改变。(没有被任何引用所指向的对象是垃圾,会被垃圾回收器回收)
3.形参与实参
- 形参:方法被调用时需要传递进来的参数,如:print(int a)中的a,它只有在print被调用期间a才有意义,也就是会被分配内存空间,在方法print执行完成后,a就会被销毁释放空间,也就是不存在了
- 实参:方法被调用时是传入的实际值,它在方法被调用前就已经被初始化并且在方法被调用时传入。
举个简单的例子
public static void print(int a){
a=60; // 方法的参数a就是形参
System.out.println(a);
}
public static void main(String[] args) {
int a=10;//实参
print(a);
}
int a=60;中的a在被调用之前就已经创建并初始化,在调用print()方法时,他被当做参数传入,所以这个a是实参。
而print(int a)中的a只有在print被调用时它的生命周期才开始,而在print调用结束之后,它也随之被JVM释放掉,,所以这个a是形参。
4.JVM内存的划分及职能
Java语言本身是不能操作内存的,它的一切都是交给JVM来管理和控制的,因此Java内存区域的划分也就是JVM的区域划分,在说JVM的内存划分之前,我们先来看一下Java程序的执行过程,如下图:
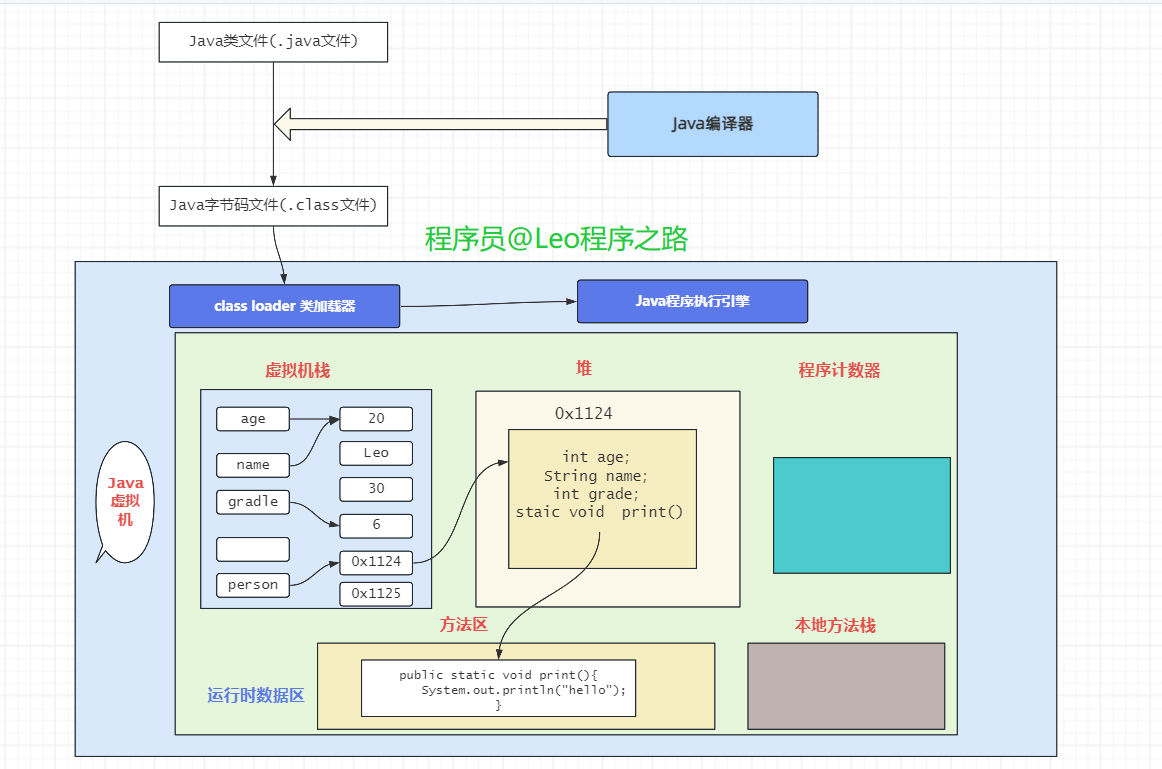
可以看出来Java代码被编译器编译成字节码之后,JVM开辟一片内存空间(也叫运行时数据区),通过类加载器加到到运行时数据区来存储程序执行期间需要用到的数据和相关信息,在这个数据区中,它由以下几部分组成:
- 虚拟机栈
- 堆区
- 程序计数器
- 方法区
- 本地方法栈
4.1 虚拟机栈
虚拟机栈是Java方法执行的内存模型,栈中存放着栈帧,每个栈帧分别对应一个被调用的方法,方法的调用过程对应栈帧在虚拟机中入栈到出栈的过程。
栈是线程私有的,也就是线程之间的栈是隔离的;当程序中某个线程开始执行一个方法时就会相应的创建一个栈帧并且入栈(位于栈顶),在方法结束后,栈帧出栈。
下图表示了一个Java栈的模型以及栈帧的组成:
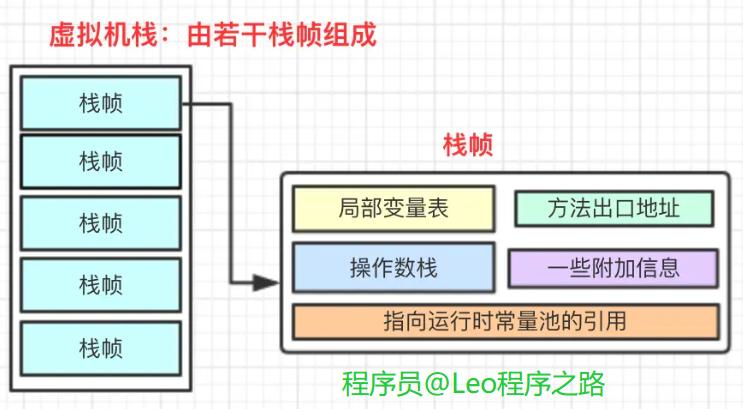
栈帧:是用于支持虚拟机进行方法调用和方法执行的数据结构,它是虚拟机运行时数据区中的虚拟机栈的栈元素。
每个栈帧中包括:
- 局部变量表:用来存储方法中的局部变量(非静态变量、函数形参)。当变量为基本数据类型时,直接存储值,当变量为引用类型时,存储的是指向具体对象的引用。
- 操作数栈:Java虚拟机的解释执行引擎被称为"基于栈的执行引擎",其中所指的栈就是指操作数栈。
- 指向运行时常量池的引用:存储程序执行时可能用到常量的引用。
- 方法返回地址:存储方法执行完成后的返回地址。
4.2 堆区
堆区 是一个在JVM启动时创建的内存部分,主要用于存储Java对象实例—基本上,几乎所有的对象实例和数组都在这块区域分配。堆内存是所有线程共享的一部分内存,其大小可在JVM启动时设置,并且随着程序的运行可动态扩展或收缩(在JVM允许的范围内)。这也是Java垃圾收集器执行垃圾回收的主要区域,因此,理解堆内存对于把握Java内存管理和垃圾收集策略是非常重要的。
堆内存结构
而在JVM规范中,并没有严格规定堆的具体结构,具体实现取决于JVM的供应商。然而,一般来说,现在大多数的JVM实现都采用了分代内存管理的概念,将堆内存细分为以下几个部分:
- 年轻代 (Young Generation): 这部分内存是新创建的对象分配空间的地方。年轻代进一步细分为一个"Eden空间"和两个"幸存区(Survivor spaces)",默认比例为8:1:1。大多数对象首先在Eden空间分配,经过几次垃圾收集后,存活下来的对象将会被移到幸存区。
- 老年代 (Old Generation): 当对象在年轻代中经历了足够多的垃圾回收周期之后仍然存活,会被移动到老年代。这部分存放的是应用中生命周期长的对象。老年代的空间通常比年轻代大,所需的垃圾收集频率低于年轻代。
- 永久代/元空间 (Permanent Generation/Metaspace): 这部分内存主要用于存储JVM加载的类信息、常量池、静态变量等。在JDK 1.7及以前的版本中,这部分被称为永久代,但在JDK 1.8及以上版本中,永久代被移除,相应的数据移至本地内存中的元空间。
堆内存管理和垃圾回收
垃圾收集 是自动内存管理的一部分,JVM的垃圾收集器负责识别堆中不再被引用的对象并清除它们,以便释放空间给新对象使用。不同的垃圾收集器(如Serial GC, Parallel GC, CMS, G1 GC等)有不同的策略来执行这一任务。
由于堆是多线程共享的,对堆内存的操作通常要考虑并发控制和内存分配策略。随着垃圾收集器技术的进步,现代JVM可以高效地管理堆内存,并最小化应用程序暂停时间。
调优和监控
堆内存的大小和垃圾收集的行为可能会显著影响Java程序的性能。因此,开发者经常需要根据应用程序的需求来调优JVM的堆设置,以获得最佳性能。JVM提供了诸如-Xms和-Xmx这样的启动参数来控制堆内存的初始大小和最大大小。
此外,可以使用监控和剖析工具(例如jConsole, VisualVM, JProfiler等)来监控堆内存的使用情况,帮助识别内存泄露。
4.3 程序计数器
程序计数器(Program Counter Register) 是一个较小但非常重要的组成部分。程序计数器是一个非常小的内存空间,它为每个线程保留一个计数值,用于指示线程正在执行的字节码的行号。这意味着每个线程都有自己的程序计数器,这是线程私有的内存。
功能和重要性
- 线程隔离: 由于每个线程都有自己的程序计数器,这使得在多线程环境中,计算机可以轻松地恢复上下文切换后的执行位置。每当线程恢复执行时,程序计数器会指向线程应该执行的字节码指令。
- 指示当前执行的指令: 程序计数器存储着指向当前线程正在执行的字节码指令的地址。如果执行的是非本地方法(即Java方法),那么这个计数器记录的是正在执行的字节码指令的地址;如果执行的是本地方法(即非Java代码),程序计数器的值则为空(Undefined)。
- 协助异常处理和线程恢复: 在出现异常或线程切换时,程序计数器保留着重要信息,使得JVM能够准确地知道程序的执行到哪一点,并相应地进行处理。
内存分配
程序计数器的内存占用非常小,但它是运行程序所必需的。每个线程都有一个程序计数器,但其内存分配相比于堆或方法区来说是微不足道的。然而,它对于线程的顺利执行是必不可少的。
与垃圾回收的关系
与堆或方法区不同,程序计数器的内存分配和回收是与线程的创建和结束紧密相关的。它不涉及传统意义上的垃圾回收,因为每个程序计数器只服务于一个线程,当线程结束时,程序计数器自然就被回收了。
总结
总的来说,程序计数器是JVM中非常关键的组成部分,它确保线程执行的正确性和高效性,尽管它的大小非常小,但在JVM的多线程操作中起着不可或缺的作用。由于它是线程私有的,程序计数器是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域。
4.4 方法区
方法区是一块所有线程共享的内存逻辑区域,在JVM中只有一个方法区,用来存储一些线程可共享的内容,它是线程安全的,多个线程同时访问方法区中同一个内容时,只能有一个线程装载该数据,其它线程只能等待。
方法区可存储的内容有:类的全路径名、类的直接超类的权全限定名、类的访问修饰符、类的类型(类或接口)、类的直接接口全限定名的有序列表、常量池(字段,方法信息,静态变量,类型引用(class))等。
4.5 本地方法栈
本地方法栈(Native Method Stack)是用于支持Java程序中本地方法(即非Java代码)执行的一个区域。当Java程序调用本地方法,如使用Java Native Interface(JNI)调用C或C++等语言写的代码时,这些方法的执行是在本地方法栈中进行的。它与Java方法栈在功能上类似,但专门用于本地方法的执行。
功能和重要性
- 支持本地方法执行: 本地方法栈为JVM执行本地方法提供了空间。这些方法不是用Java编写的,而是用其他语言(如C或C++)实现的,并通过JNI与Java代码交互。
- 线程隔离: 与程序计数器和Java虚拟机栈一样,本地方法栈也是线程私有的。每个线程在调用本地方法时都会使用自己的本地方法栈。
- 内存管理: 本地方法栈可能会因为本地方法调用的深度过大而发生溢出,这种情况下会抛出
StackOverflowError或者在无法获得足够内存时抛出OutOfMemoryError。
与Java栈的区别
虽然本地方法栈和Java虚拟机栈在概念上相似,但它们的主要区别在于:
- 使用的语言和方法类型:Java虚拟机栈用于Java方法的调用,而本地方法栈用于本地方法的调用。
- 管理和优化:由于本地方法一般直接运行在底层操作系统上,其栈的管理和优化往往依赖于操作系统和硬件,而不是JVM。
内存分配和回收
本地方法栈的内存分配也是线程私有的,它的大小可以在JVM启动时设置,甚至可能被设置为动态扩展。当线程结束时,其本地方法栈也会被回收。
应用场景和注意事项
- 应用场景:本地方法栈主要用于执行那些需要接近底层系统或具有特殊性能要求的操作,例如硬件级别的操作、系统调用或传统的库函数调用。
- 注意事项:使用本地方法栈意味着牺牲了Java的平台无关性和安全性。因此,需要谨慎使用本地方法,并确保相关代码的安全和可靠。
总结
总的来说,本地方法栈是JVM用于支持本地方法执行的重要组成部分。它为Java程序提供了与非Java语言编写的代码交互的能力,但这也带来了额外的复杂性和潜在的安全风险。了解本地方法栈的工作原理对于编写和调试涉及JNI的Java应用程序是很重要的
5.数据如何在内存中存储?
在Java中,数据存储主要发生在JVM(Java虚拟机)的几个主要内存区域:堆(Heap)、栈(Stack)、方法区(Method Area)和程序计数器(Program Counter Register)。每个区域都有其特定的用途和存储类型的数据。
1. 堆(Heap)
- 对象实例存储: Java中的对象实例都是在堆内存中分配的。这包括类实例(Object)和数组。
- 共享资源: 堆是所有线程共享的一部分内存。
- 垃圾回收: 垃圾收集主要在堆内存中进行,它负责清理不再被任何对象引用的内存。
- 动态分配: 堆的大小可以动态调整,可以在JVM启动时指定初始大小和最大大小。
2. 栈(Stack)
- 局部变量存储: 每个线程都有自己的栈,用于存储基本类型的局部变量(如int, long, double等)以及对象引用。
- 方法调用: 栈帧(Stack Frame)存储了方法调用的局部变量、操作数栈、方法返回值等信息。每个方法调用创建一个新的栈帧。
- 快速访问: 栈内存比堆内存访问速度快,但大小有限制。
3. 方法区(Method Area)
- 类结构: 存储每个类的结构信息,如运行时常量池(Runtime Constant Pool)、字段和方法数据、构造函数和普通方法的代码。
- 静态变量: 包括所有静态变量的数据。
- 实现细节: 在JDK 1.8之前,这部分被称为永久代(PermGen)。在JDK 1.8及以后,被替换为元空间(Metaspace)。
4. 程序计数器
- 线程执行追踪: 每个线程都有自己的程序计数器,用于跟踪线程正在执行的指令地址。
数据存储的其他要点:
- 引用类型和基本类型: 基本类型(如int, float)通常存储在栈上,而引用类型(如对象、数组)存储在堆上。
- 内存管理: Java内存管理是自动的,由垃圾收集器处理不再被使用的对象。
- 并发和多线程: Java中每个线程都有自己的栈,但堆是在所有线程之间共享的。
1.基本数据类型的局部变量
定义基本数据类型的局部变量以及数据都是直接存储在内存中的栈上,也就是前面说到的**“虚拟机栈”**,数据本身的值就是存储在栈空间里面。

如上图,在方法内定义的变量直接存储在栈中,如
int age=20;
String name="Leo";
int grade=6;
当我们写int age=20;,其实是分为两步的:
int age;//定义变量
age= 20;//赋值
首先JVM创建一个名为age的变量,存于局部变量表中,然后去栈中查找是否存在有字面量值为20的内容,如果有就直接把age指向这个地址,如果没有,JVM会在栈中开辟一块空间来存储“20”这个内容,并且把age指向这个地址。因此我们可以知道:
我们声明并初始化基本数据类型的局部变量时,变量名以及字面量值都是存储在栈中,而且是真实的内容。
我们再来看String name = “Leo”,按照刚才的思路:字面量为"Leo"的内容在栈中已经存在,因此name是直接指向这个地址的。由此可见:栈中的数据在当前线程下是共享的。
那么如果再执行下面的代码呢?
name="hhh";
当代码中重新给weight变量进行赋值时,JVM会去栈中寻找字面量为"hhh"的内容,发现没有,就会开辟一块内存空间存储"hhhh"这个内容,并且把name指向这个地址。由此可知:
基本数据类型的数据本身是不会改变的,当局部变量重新赋值时,并不是在内存中改变字面量内容,而是重新在栈中寻找已存在的相同的数据,若栈中不存在,则重新开辟内存存新数据,并且把要重新赋值的局部变量的引用指向新数据所在地址。
2.基本数据类型的成员变量
成员变量:顾名思义,就是在类体中定义的变量。
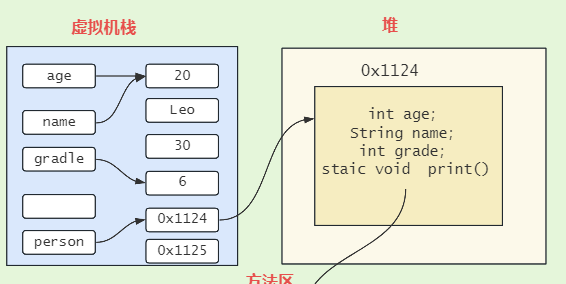
我们看per的地址指向的是堆内存中的一块区域,我们来还原一下代码:
public class Person{
private int age;
private String name;
private int grade;
//篇幅较长,省略setter getter方法
static void print(){
System.out.println("print....");
};
}
//调用
Person per=new Person();
同样是局部变量的age、name、grade却被存储到了堆中为person对象开辟的一块空间中。因此可知:基本数据类型的成员变量名和值都存储于堆中,其生命周期和对象的是一致的。
3.基本数据类型的静态变量
前面提到方法区用来存储一些共享数据,因此基本数据类型的静态变量名以及值存储于方法区的运行时常量池中,静态变量随类加载而加载,随类消失而消失
4.引用数据类型的存储
堆是用来存储对象本身和数组,而引用存放的是实际内容的地址值,因此通过上面的程序运行图,也可以看出,当我们定义一个对象时
Person person = new Person();
实际上,它也是有两个过程:
Person person;//定义变量
person=new Person();//赋值
在执行Person per;时,JVM先在虚拟机栈中的变量表中开辟一块内存存放per变量,在执行person=new Person()时,JVM会创建一个Person类的实例对象并在堆中开辟一块内存存储这个实例,同时把实例的地址值赋值给per变量。因此可见:
对于引用数据类型的对象/数组,变量名存在栈中,变量值存储的是对象的地址,并不是对象的实际内容。
6.值传递和引用传递
有了上述知识的铺垫,下面我们来进入我们的主题。
6.1 值传递
值传递: 在方法被调用时,实参通过形参把它的内容副本传入方法内部,此时形参接收到的内容是实参值的一个拷贝,因此在方法内对形参的任何操作,都仅仅是对这个副本的操作,不影响原始值的内容。
接下来我们看一个例子:
package com.Leo.exer.demo;
/**
* @author : Leo
* @version 1.0
* @date 2023-11-22 14:38
* @description :
*/
public class ValueTest {
public static void main(String[] args) {
int age1 = 25;
String name1 = "hhhh";
print(age1,name1);
System.out.println("方法执行后的age:"+ age1 );
System.out.println("方法执行后的name:"+ name1);
}
private static void print(int age, String name) {
System.out.println("传入的age:"+ age );
System.out.println("传入的的name:"+ name);
age = 88;
name = "Leo";
System.out.println("方法内进行修改的age:"+ age );
System.out.println("方法内进行修改的name:"+ name);
}
}
执行结果:
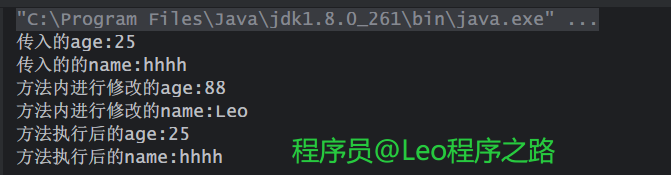
从上面的打印结果可以看到:
age1和name1作为实参传入print()之后,无论在方法内做了什么操作,最终age1和那么1都没变化。
这是为什么呢,我们接着通过内存图进行分析
首先程序运行时,调用mian()方法,此时JVM为main()方法往虚拟机栈中压入一个栈帧,即为当前栈帧,用来存放main()中的局部变量表(包括参数)、操作栈、方法出口等信息,如age1和name1都是mian()方法中的局部变量,因此可以断定,age1和name1是躺着mian方法所在的栈帧中.
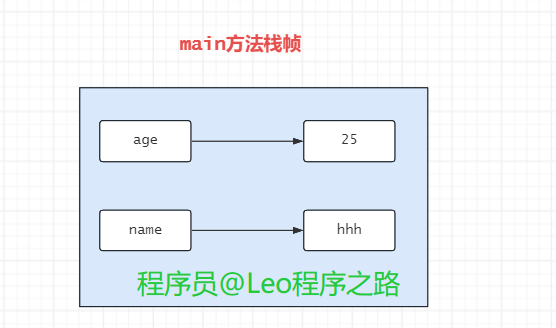
而当执行到print()方法时,JVM也为其往虚拟机栈中压入一个栈,即为当前栈帧,用来存放print()中的局部变量等信息,因此age和name是躺着print方法所在的栈帧中,而他们的值是从age1和name1的值copy了一份副本而得,如图:

因而可以age1和age、name1和name对应的内容是不一致的,所以当在方法内重新赋值时,实际流程如图:

也就是说,age和name的改动,只是改变了当前栈帧(print方法所在栈帧)里的内容,当方法执行结束之后,这些局部变量都会被销毁,main方法所在栈帧重新回到栈顶,成为当前栈帧,再次输出a和w时,依然是初始化时的内容。
因此:值传递传递的是真实内容的一个副本,对副本的操作不影响原内容,也就是形参怎么变化,不会影响实参对应的内容。
6.2 引用传递
引用传递: 引用也就是指向真实内容的地址值,在方法调用时,实参的地址通过方法调用被传递给相应的形参,在方法体内,形参和实参指向通愉快内存地址,对形参的操作会影响的真实内容。
我们先简单创建一个Person对象
public class Person {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
package com.Leo.exer.demo;
/**
* @author : Leo
* @version 1.0
* @date 2023-11-22 14:54
* @description :
*/
public class PersonTest {
public static void main(String[] args) {
Person person = new Person();
person.setName("我是Leo哥");
person.setAge(45);
print(person);
System.out.println("方法执行后的name:"+person.getName());
}
public static void print(Person person){
System.out.println("传入的person的name:"+ person.getName());
person.setName("我是张三");
System.out.println("方法内重新赋值后的name:"+ person.getName());
}
}
打印结果:
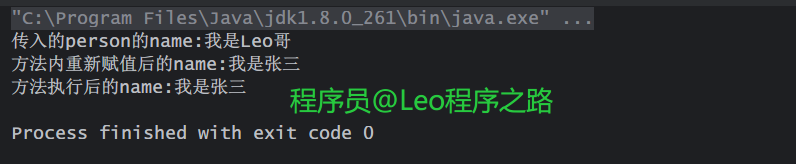
可以看出,person经过print()方法的执行之后,内容发生了改变,这印证了上面所说的**“引用传递”**,对形参的操作,改变了实际对象的内容。
那么这个真的就是我们前面所说的引用传递嘛,不是说Java只有值传递嘛,这是怎么回事呢?
其实这个例子只是一个巧合,我们只需要在我们代码上多加一行代码就可以了
public static void print(Person person){
System.out.println("传入的person的name:"+ person.getName());
person = new Person(); // 加上这一行代码
person.setName("我是张三");
System.out.println("方法内重新赋值后的name:"+ person.getName());
}
执行结果:

为什么这次的输出和上次的不一样了呢?
我们再次通过内存模型进行分析
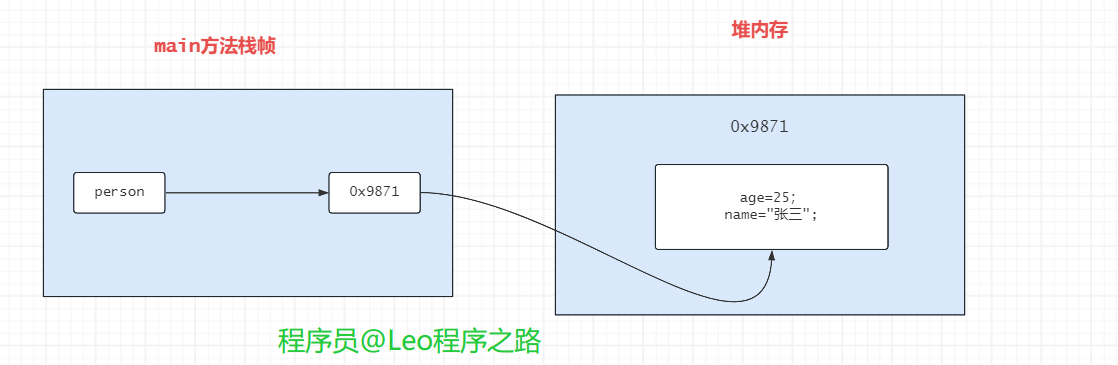
上面讲到JVM内存模型可以知道,对象和数组是存储在Java堆区的,而且堆区是共享的,因此程序执行到main()方法中的下列代码时,此时的内存图为:
Person person = new Person();
person.setName("我是Leo哥");
person.setAge(25);
print(person);
当执行到print()方法时,因方法内有这么一行代码:
person = new Person();
JVM需要在堆内另外开辟一块内存来存储new Person(),假如地址为xo7751,那此时形参person指向了这个地址,假如真的是引用传递,那么由上面讲到:引用传递中形参实参指向同一个对象,形参的操作会改变实参对象的改变。
可以推出:实参也应该指向了新创建的person对象的地址,所以在执行print()结束之后,最终输出的应该是后面创建的对象内容。
然而实际上,最终的输出结果却跟我们推测的不一样,最终输出的仍然是一开始创建的对象的内容。
由此可见:引用传递,在Java中并不存在。
无论是基本类型和是引用类型,在实参传入形参时,都是值传递,也就是说传递的都是一个副本,而不是内容本身。
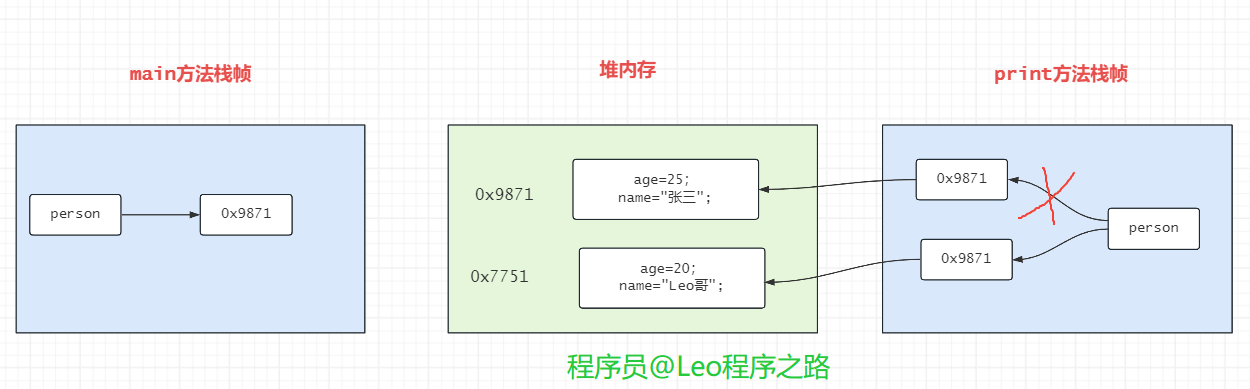
方法内的形参person和实参person并无实质关联,它只是由person处拷贝了一份指向对象的地址,此时:
person和person都是指向同一个对象。
因此在第一个例子中,对形参p的操作,会影响到实参对应的对象内容。而在第二个例子中,当执行到new Person()之后,JVM在堆内开辟一块空间存储新对象,并且把person改成指向新对象的地址,此时:
person依旧是指向旧的对象,person指向新对象的地址。
7.总结
经过上述分析,Java参数传递中,不管传递的是基本数据类型还是引用类型,都是值传递。
当传递基本数据类型,比如原始类型(int、long、char等)、包装类型(Integer、Long、String等),实参和形参都是存储在不同的栈帧内,修改形参的栈帧数据,不会影响实参的数据。
当传参的引用类型,形参和实参指向同一个地址的时候,修改形参地址的内容,会影响到实参。当形参和实参指向不同的地址的时候,修改形参地址的内容,并不会影响到实参。
8.文末推荐福利
项目管理新模式:一本专注于帮助项目经理在AI时代实现晋级、提高效率的图书。书中介绍了如何使用 ChatGPT 来完成项目管理的各个环节,并通过实战案例展示了 ChatGPT在实际项目管理中的应用方法。

内容简介
本书是一本致力于揭示人工智能如何颠覆和重塑项目管理,并以ChatGPT为核心工具推动项目管理创新的实用指南。本书通过 13 章的系统探讨,带领读者踏上项目管理卓越之路。
第 1 章人工智能颠覆与重塑项目管理,首先揭示了人工智能对项目管理的深刻影响和带来的机遇与挑战,为读者构建了认知框架。紧接着,第 2 章至第 13 章依次介绍了使用ChatGPT编写各种文档、在项目启动中的应用、帮助组建高效团队、辅助项目沟通管理、项目计划与管理、项目成本管理、项目时间管理、项目质量管理、项目风险管理、采购计划与采购流程、项目绩效管理,以及辅助进行项目总结等各方面的内容。
本书注重理论与实践的结合,每章都以具体案例、实用技巧和最佳实践为基础,帮助读者深入了解ChatGPT的应用场景,掌握在项目管理中实际运用的方法和策略。无论您是初入职场的新手项目经理还是经验丰富的专业人士,本书都将成为您的导航指南,帮助您在人工智能时代展现卓越的项目管理和创新能力,并在日常工作中取得更加优 异的成果。
购买链接
当当:http://product.dangdang.com/29621634.html
京东:https://item.jd.com/14129232.html
参与方式
关注我的博客:关注我的博客,所有新鲜的博客文章和活动信息都不会错过。
添加博主wx:添加Leocisyam,如果添加不了,请私信博主。
参与方式:关注公众号程序员Leo或者文末扫码关注,回复抽奖,即可参与抽奖。
公布结果:2023年11月25日晚,我会亲自抽取2️⃣名幸运读者,并在微信私信通知,请大家注意查收哈。
智能推荐
稀疏编码的数学基础与理论分析-程序员宅基地
文章浏览阅读290次,点赞8次,收藏10次。1.背景介绍稀疏编码是一种用于处理稀疏数据的编码技术,其主要应用于信息传输、存储和处理等领域。稀疏数据是指数据中大部分元素为零或近似于零的数据,例如文本、图像、音频、视频等。稀疏编码的核心思想是将稀疏数据表示为非零元素和它们对应的位置信息,从而减少存储空间和计算复杂度。稀疏编码的研究起源于1990年代,随着大数据时代的到来,稀疏编码技术的应用范围和影响力不断扩大。目前,稀疏编码已经成为计算...
EasyGBS国标流媒体服务器GB28181国标方案安装使用文档-程序员宅基地
文章浏览阅读217次。EasyGBS - GB28181 国标方案安装使用文档下载安装包下载,正式使用需商业授权, 功能一致在线演示在线API架构图EasySIPCMSSIP 中心信令服务, 单节点, 自带一个 Redis Server, 随 EasySIPCMS 自启动, 不需要手动运行EasySIPSMSSIP 流媒体服务, 根..._easygbs-windows-2.6.0-23042316使用文档
【Web】记录巅峰极客2023 BabyURL题目复现——Jackson原生链_原生jackson 反序列化链子-程序员宅基地
文章浏览阅读1.2k次,点赞27次,收藏7次。2023巅峰极客 BabyURL之前AliyunCTF Bypassit I这题考查了这样一条链子:其实就是Jackson的原生反序列化利用今天复现的这题也是大同小异,一起来整一下。_原生jackson 反序列化链子
一文搞懂SpringCloud,详解干货,做好笔记_spring cloud-程序员宅基地
文章浏览阅读734次,点赞9次,收藏7次。微服务架构简单的说就是将单体应用进一步拆分,拆分成更小的服务,每个服务都是一个可以独立运行的项目。这么多小服务,如何管理他们?(服务治理 注册中心[服务注册 发现 剔除])这么多小服务,他们之间如何通讯?这么多小服务,客户端怎么访问他们?(网关)这么多小服务,一旦出现问题了,应该如何自处理?(容错)这么多小服务,一旦出现问题了,应该如何排错?(链路追踪)对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一个问题提供了相应的组件来解决它们。_spring cloud
Js实现图片点击切换与轮播-程序员宅基地
文章浏览阅读5.9k次,点赞6次,收藏20次。Js实现图片点击切换与轮播图片点击切换<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title></title> <script type="text/ja..._点击图片进行轮播图切换
tensorflow-gpu版本安装教程(过程详细)_tensorflow gpu版本安装-程序员宅基地
文章浏览阅读10w+次,点赞245次,收藏1.5k次。在开始安装前,如果你的电脑装过tensorflow,请先把他们卸载干净,包括依赖的包(tensorflow-estimator、tensorboard、tensorflow、keras-applications、keras-preprocessing),不然后续安装了tensorflow-gpu可能会出现找不到cuda的问题。cuda、cudnn。..._tensorflow gpu版本安装
随便推点
物联网时代 权限滥用漏洞的攻击及防御-程序员宅基地
文章浏览阅读243次。0x00 简介权限滥用漏洞一般归类于逻辑问题,是指服务端功能开放过多或权限限制不严格,导致攻击者可以通过直接或间接调用的方式达到攻击效果。随着物联网时代的到来,这种漏洞已经屡见不鲜,各种漏洞组合利用也是千奇百怪、五花八门,这里总结漏洞是为了更好地应对和预防,如有不妥之处还请业内人士多多指教。0x01 背景2014年4月,在比特币飞涨的时代某网站曾经..._使用物联网漏洞的使用者
Visual Odometry and Depth Calculation--Epipolar Geometry--Direct Method--PnP_normalized plane coordinates-程序员宅基地
文章浏览阅读786次。A. Epipolar geometry and triangulationThe epipolar geometry mainly adopts the feature point method, such as SIFT, SURF and ORB, etc. to obtain the feature points corresponding to two frames of images. As shown in Figure 1, let the first image be and th_normalized plane coordinates
开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先抽取关系)_语义角色增强的关系抽取-程序员宅基地
文章浏览阅读708次,点赞2次,收藏3次。开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先关系再实体)一.第二代开放信息抽取系统背景 第一代开放信息抽取系统(Open Information Extraction, OIE, learning-based, 自学习, 先抽取实体)通常抽取大量冗余信息,为了消除这些冗余信息,诞生了第二代开放信息抽取系统。二.第二代开放信息抽取系统历史第二代开放信息抽取系统着眼于解决第一代系统的三大问题: 大量非信息性提取(即省略关键信息的提取)、_语义角色增强的关系抽取
10个顶尖响应式HTML5网页_html欢迎页面-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏51次。快速完成网页设计,10个顶尖响应式HTML5网页模板助你一臂之力为了寻找一个优质的网页模板,网页设计师和开发者往往可能会花上大半天的时间。不过幸运的是,现在的网页设计师和开发人员已经开始共享HTML5,Bootstrap和CSS3中的免费网页模板资源。鉴于网站模板的灵活性和强大的功能,现在广大设计师和开发者对html5网站的实际需求日益增长。为了造福大众,Mockplus的小伙伴整理了2018年最..._html欢迎页面
计算机二级 考试科目,2018全国计算机等级考试调整,一、二级都增加了考试科目...-程序员宅基地
文章浏览阅读282次。原标题:2018全国计算机等级考试调整,一、二级都增加了考试科目全国计算机等级考试将于9月15-17日举行。在备考的最后冲刺阶段,小编为大家整理了今年新公布的全国计算机等级考试调整方案,希望对备考的小伙伴有所帮助,快随小编往下看吧!从2018年3月开始,全国计算机等级考试实施2018版考试大纲,并按新体系开考各个考试级别。具体调整内容如下:一、考试级别及科目1.一级新增“网络安全素质教育”科目(代..._计算机二级增报科目什么意思
conan简单使用_apt install conan-程序员宅基地
文章浏览阅读240次。conan简单使用。_apt install conan