【吴恩达深度学习】Deep Neural Network for Image Classification: Application-程序员宅基地
技术标签: 人工智能,机器学习,深度学习 算法 深度学习 人工智能
Deep Neural Network for Image Classification: Application
When you finish this, you will have finished the last programming assignment of Week 4, and also the last programming assignment of this course!
You will use the functions you’d implemented in the previous assignment to build a deep network, and apply it to cat vs non-cat classification. Hopefully, you will see an improvement in accuracy relative to your previous logistic regression implementation.
After this assignment you will be able to:
- Build and apply a deep neural network to supervised learning.
Let’s get started!
1 - Packages
Let’s first import all the packages that you will need during this assignment.
- numpy is the fundamental package for scientific computing with Python.
- matplotlib is a library to plot graphs in Python.
- h5py is a common package to interact with a dataset that is stored on an H5 file.
- PIL and scipy are used here to test your model with your own picture at the end.
- dnn_app_utils provides the functions implemented in the “Building your Deep Neural Network: Step by Step” assignment to this notebook.
- np.random.seed(1) is used to keep all the random function calls consistent. It will help us grade your work.
import time
import numpy as np
import h5py
import matplotlib.pyplot as plt
import scipy
from PIL import Image
from scipy import ndimage
from dnn_app_utils_v2 import *
%matplotlib inline
plt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
%load_ext autoreload
%autoreload 2
np.random.seed(1)
2 - Dataset
You will use the same “Cat vs non-Cat” dataset as in “Logistic Regression as a Neural Network” (Assignment 2). The model you had built had 70% test accuracy on classifying cats vs non-cats images. Hopefully, your new model will perform a better!
Problem Statement: You are given a dataset (“data.h5”) containing:
- a training set of m_train images labelled as cat (1) or non-cat (0)
- a test set of m_test images labelled as cat and non-cat
- each image is of shape (num_px, num_px, 3) where 3 is for the 3 channels (RGB).
Let’s get more familiar with the dataset. Load the data by running the cell below.
train_x_orig, train_y, test_x_orig, test_y, classes = load_data()
The following code will show you an image in the dataset. Feel free to change the index and re-run the cell multiple times to see other images.
# Example of a picture
index = 7
plt.imshow(train_x_orig[index])
print ("y = " + str(train_y[0,index]) + ". It's a " + classes[train_y[0,index]].decode("utf-8") + " picture.")
# Explore your dataset
m_train = train_x_orig.shape[0]
num_px = train_x_orig.shape[1]
m_test = test_x_orig.shape[0]
print ("Number of training examples: " + str(m_train))
print ("Number of testing examples: " + str(m_test))
print ("Each image is of size: (" + str(num_px) + ", " + str(num_px) + ", 3)")
print ("train_x_orig shape: " + str(train_x_orig.shape))
print ("train_y shape: " + str(train_y.shape))
print ("test_x_orig shape: " + str(test_x_orig.shape))
print ("test_y shape: " + str(test_y.shape))
As usual, you reshape and standardize the images before feeding them to the network. The code is given in the cell below.
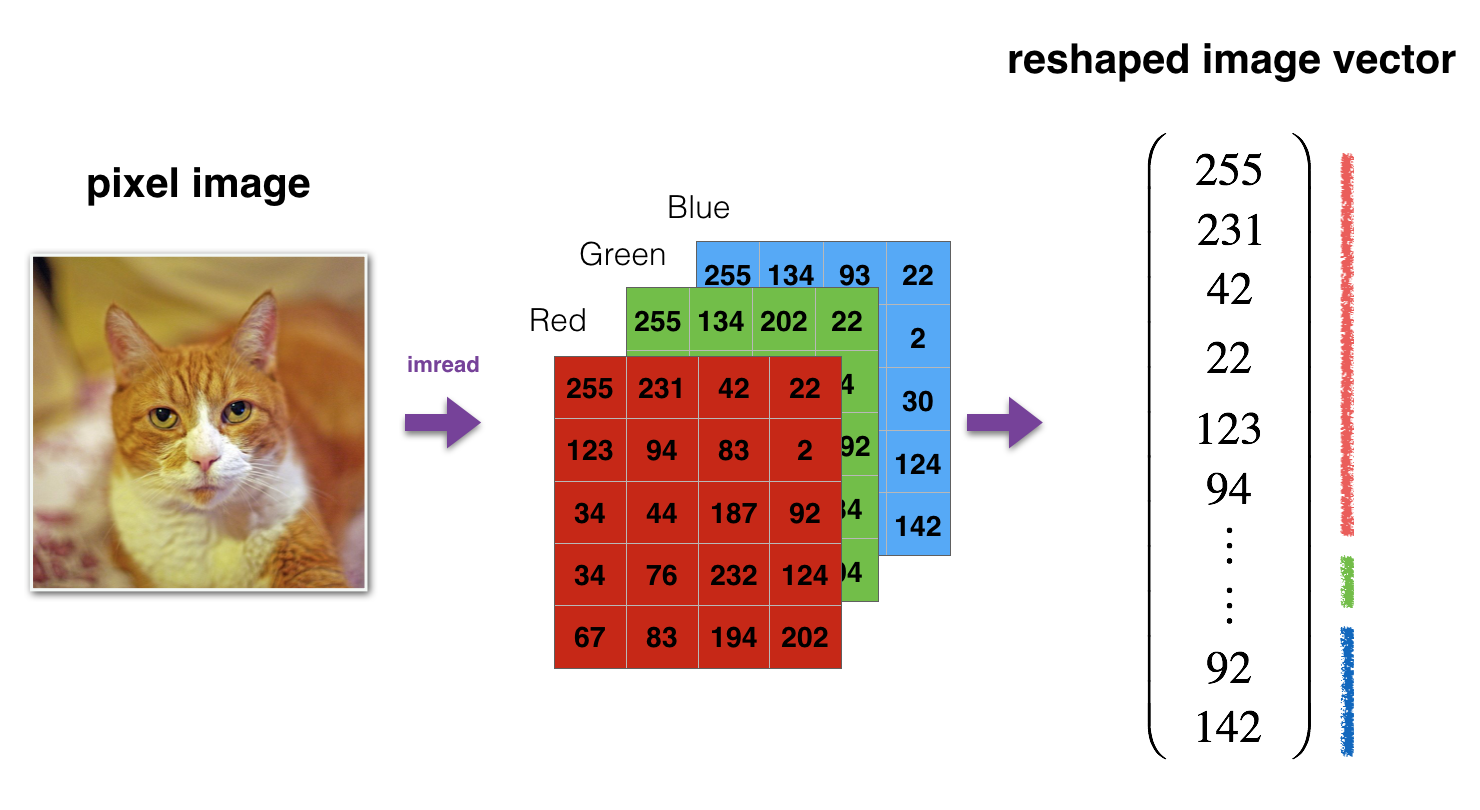
# Reshape the training and test examples
train_x_flatten = train_x_orig.reshape(train_x_orig.shape[0], -1).T # The "-1" makes reshape flatten the remaining dimensions
test_x_flatten = test_x_orig.reshape(test_x_orig.shape[0], -1).T
# Standardize data to have feature values between 0 and 1.
train_x = train_x_flatten/255.
test_x = test_x_flatten/255.
print ("train_x's shape: " + str(train_x.shape))
print ("test_x's shape: " + str(test_x.shape))
12 , 288 12,288 12,288 equals 64 × 64 × 3 64 \times 64 \times 3 64×64×3 which is the size of one reshaped image vector.
3 - Architecture of your model
Now that you are familiar with the dataset, it is time to build a deep neural network to distinguish cat images from non-cat images.
You will build two different models:
- A 2-layer neural network
- An L-layer deep neural network
You will then compare the performance of these models, and also try out different values for L L L.
Let’s look at the two architectures.
3.1 - 2-layer neural network
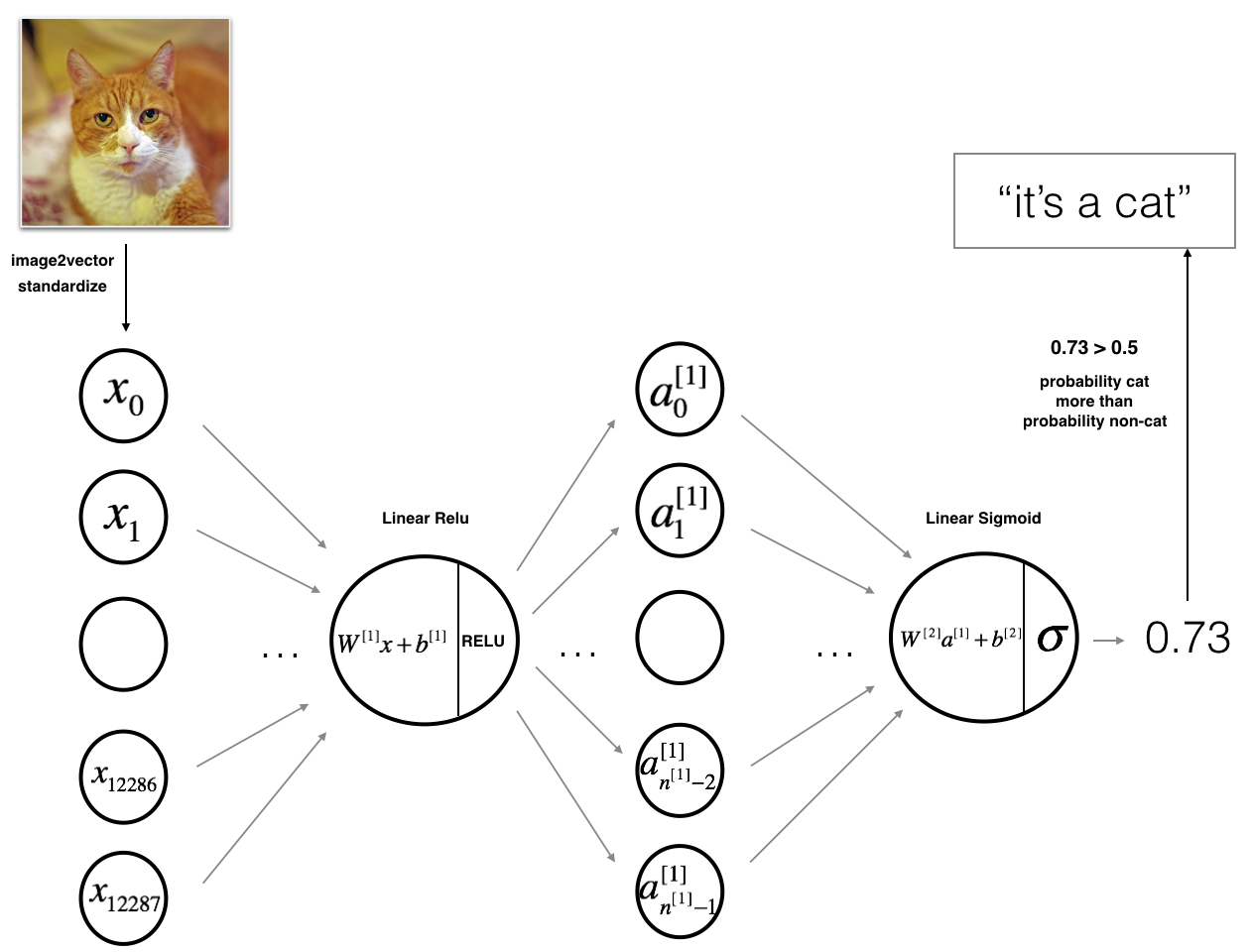
The model can be summarized as: ***INPUT -> LINEAR -> RELU -> LINEAR -> SIGMOID -> OUTPUT***.
Detailed Architecture of figure 2:
- The input is a (64,64,3) image which is flattened to a vector of size ( 12288 , 1 ) (12288,1) (12288,1).
- The corresponding vector: [ x 0 , x 1 , . . . , x 12287 ] T [x_0,x_1,...,x_{12287}]^T [x0,x1,...,x12287]T is then multiplied by the weight matrix W [ 1 ] W^{[1]} W[1] of size ( n [ 1 ] , 12288 ) (n^{[1]}, 12288) (n[1],12288).
- You then add a bias term and take its relu to get the following vector: [ a 0 [ 1 ] , a 1 [ 1 ] , . . . , a n [ 1 ] − 1 [ 1 ] ] T [a_0^{[1]}, a_1^{[1]},..., a_{n^{[1]}-1}^{[1]}]^T [a0[1],a1[1],...,an[1]−1[1]]T.
- You then repeat the same process.
- You multiply the resulting vector by W [ 2 ] W^{[2]} W[2] and add your intercept (bias).
- Finally, you take the sigmoid of the result. If it is greater than 0.5, you classify it to be a cat.
3.2 - L-layer deep neural network
It is hard to represent an L-layer deep neural network with the above representation. However, here is a simplified network representation:
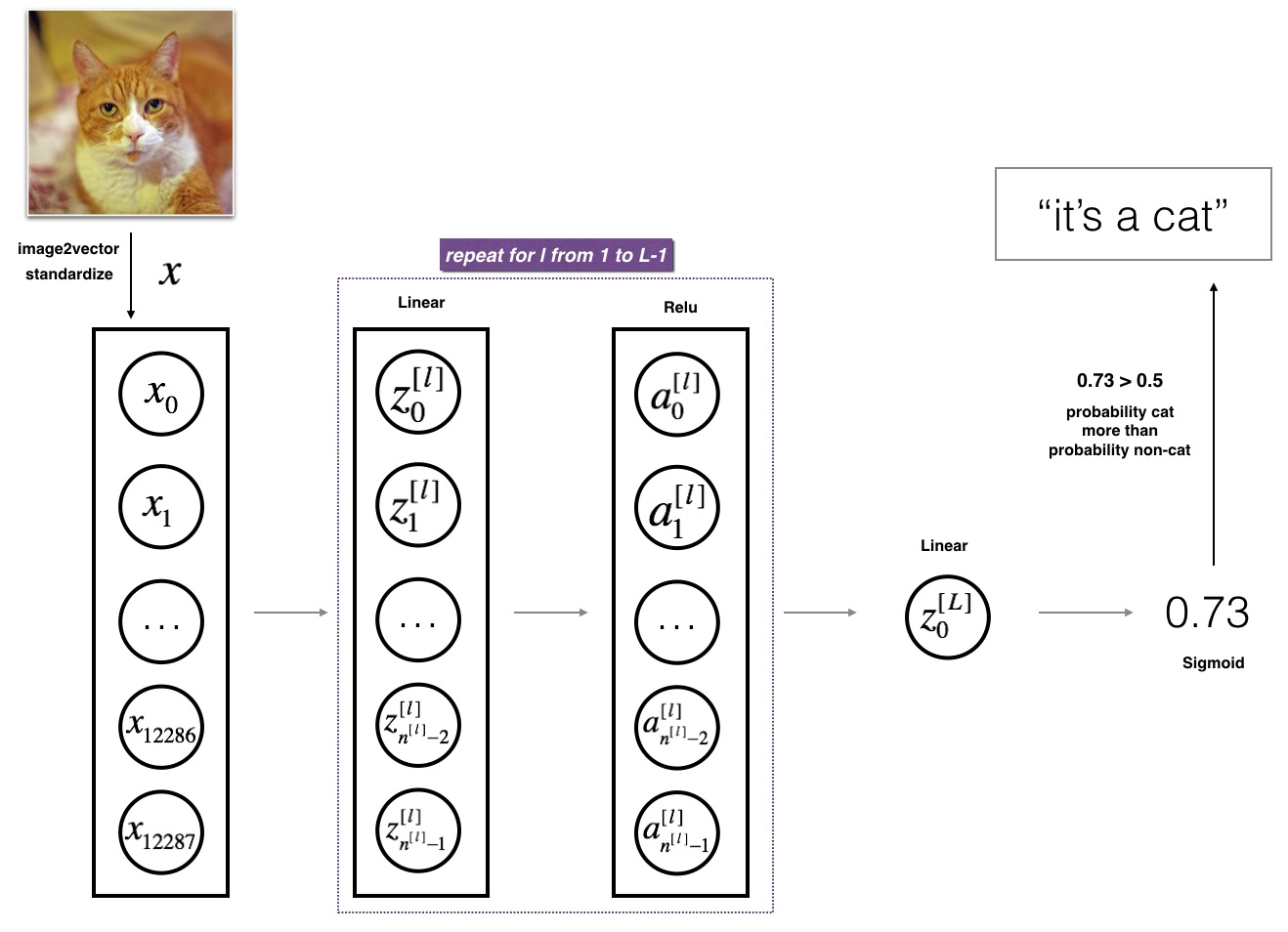
The model can be summarized as: ***[LINEAR -> RELU] $\times$ (L-1) -> LINEAR -> SIGMOID***
Detailed Architecture of figure 3:
- The input is a (64,64,3) image which is flattened to a vector of size (12288,1).
- The corresponding vector: [ x 0 , x 1 , . . . , x 12287 ] T [x_0,x_1,...,x_{12287}]^T [x0,x1,...,x12287]T is then multiplied by the weight matrix W [ 1 ] W^{[1]} W[1] and then you add the intercept b [ 1 ] b^{[1]} b[1]. The result is called the linear unit.
- Next, you take the relu of the linear unit. This process could be repeated several times for each ( W [ l ] , b [ l ] ) (W^{[l]}, b^{[l]}) (W[l],b[l]) depending on the model architecture.
- Finally, you take the sigmoid of the final linear unit. If it is greater than 0.5, you classify it to be a cat.
3.3 - General methodology
As usual you will follow the Deep Learning methodology to build the model:
1. Initialize parameters / Define hyperparameters
2. Loop for num_iterations:
a. Forward propagation
b. Compute cost function
c. Backward propagation
d. Update parameters (using parameters, and grads from backprop)
4. Use trained parameters to predict labels
Let’s now implement those two models!
4 - Two-layer neural network
Question: Use the helper functions you have implemented in the previous assignment to build a 2-layer neural network with the following structure: LINEAR -> RELU -> LINEAR -> SIGMOID. The functions you may need and their inputs are:
def initialize_parameters(n_x, n_h, n_y):
...
return parameters
def linear_activation_forward(A_prev, W, b, activation):
...
return A, cache
def compute_cost(AL, Y):
...
return cost
def linear_activation_backward(dA, cache, activation):
...
return dA_prev, dW, db
def update_parameters(parameters, grads, learning_rate):
...
return parameters
### CONSTANTS DEFINING THE MODEL ####
n_x = 12288 # num_px * num_px * 3
n_h = 7
n_y = 1
layers_dims = (n_x, n_h, n_y)
# GRADED FUNCTION: two_layer_model
def two_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):
"""
Implements a two-layer neural network: LINEAR->RELU->LINEAR->SIGMOID.
Arguments:
X -- input data, of shape (n_x, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
layers_dims -- dimensions of the layers (n_x, n_h, n_y)
num_iterations -- number of iterations of the optimization loop
learning_rate -- learning rate of the gradient descent update rule
print_cost -- If set to True, this will print the cost every 100 iterations
Returns:
parameters -- a dictionary containing W1, W2, b1, and b2
"""
np.random.seed(1)
grads = {
}
costs = [] # to keep track of the cost
m = X.shape[1] # number of examples
(n_x, n_h, n_y) = layers_dims
# Initialize parameters dictionary, by calling one of the functions you'd previously implemented
### START CODE HERE ### (≈ 1 line of code)
parameters=initialize_parameters(n_x,n_h,n_y)
### END CODE HERE ###
# Get W1, b1, W2 and b2 from the dictionary parameters.
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> SIGMOID. Inputs: "X, W1, b1". Output: "A1, cache1, A2, cache2".
### START CODE HERE ### (≈ 2 lines of code)
A1,cache1=linear_activation_forward(X,W1,b1,activation="relu")
A2,cache2=linear_activation_forward(A1,W2,b2,activation="sigmoid")
### END CODE HERE ###
# Compute cost
### START CODE HERE ### (≈ 1 line of code)
cost=compute_cost(A2,Y)
### END CODE HERE ###
# Initializing backward propagation
dA2 = - (np.divide(Y, A2) - np.divide(1 - Y, 1 - A2))
# Backward propagation. Inputs: "dA2, cache2, cache1". Outputs: "dA1, dW2, db2; also dA0 (not used), dW1, db1".
### START CODE HERE ### (≈ 2 lines of code)
dA1,dW2,db2=linear_activation_backward(dA2,cache2,activation="sigmoid")
dA0,dW1,db1=linear_activation_backward(dA1,cache1,activation="relu")
### END CODE HERE ###
# Set grads['dWl'] to dW1, grads['db1'] to db1, grads['dW2'] to dW2, grads['db2'] to db2
grads['dW1'] = dW1
grads['db1'] = db1
grads['dW2'] = dW2
grads['db2'] = db2
# Update parameters.
### START CODE HERE ### (approx. 1 line of code)
parameters=update_parameters(parameters,grads,learning_rate)
### END CODE HERE ###
# Retrieve W1, b1, W2, b2 from parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# Print the cost every 100 training example
if print_cost and i % 100 == 0:
print("Cost after iteration {}: {}".format(i, np.squeeze(cost)))
if print_cost and i % 100 == 0:
costs.append(cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
Run the cell below to train your parameters. See if your model runs. The cost should be decreasing. It may take up to 5 minutes to run 2500 iterations. Check if the “Cost after iteration 0” matches the expected output below, if not click on the square () on the upper bar of the notebook to stop the cell and try to find your error.
parameters = two_layer_model(train_x, train_y, layers_dims = (n_x, n_h, n_y), num_iterations = 2500, print_cost=True)
Expected Output:
| **Cost after iteration 0** | 0.6930497356599888 |
| **Cost after iteration 100** | 0.6464320953428849 |
| **...** | ... |
| **Cost after iteration 2400** | 0.048554785628770206 |
Good thing you built a vectorized implementation! Otherwise it might have taken 10 times longer to train this.
Now, you can use the trained parameters to classify images from the dataset. To see your predictions on the training and test sets, run the cell below.
predictions_train = predict(train_x, train_y, parameters)
Expected Output:
| **Accuracy** | 0.9999999999999998 |
predictions_test = predict(test_x, test_y, parameters)
Expected Output:
| **Accuracy** | 0.72 |
Note: You may notice that running the model on fewer iterations (say 1500) gives better accuracy on the test set. This is called “early stopping” and we will talk about it in the next course. Early stopping is a way to prevent overfitting.
Congratulations! It seems that your 2-layer neural network has better performance (72%) than the logistic regression implementation (70%, assignment week 2). Let’s see if you can do even better with an L L L-layer model.
5 - L-layer Neural Network
Question: Use the helper functions you have implemented previously to build an L L L-layer neural network with the following structure: [LINEAR -> RELU] × \times ×(L-1) -> LINEAR -> SIGMOID. The functions you may need and their inputs are:
def initialize_parameters_deep(layer_dims):
...
return parameters
def L_model_forward(X, parameters):
...
return AL, caches
def compute_cost(AL, Y):
...
return cost
def L_model_backward(AL, Y, caches):
...
return grads
def update_parameters(parameters, grads, learning_rate):
...
return parameters
### CONSTANTS ###
layers_dims = [12288, 20, 7, 5, 1] # 5-layer model
# GRADED FUNCTION: L_layer_model
def L_layer_model(X, Y, layers_dims, learning_rate = 0.0075, num_iterations = 3000, print_cost=False):#lr was 0.009
"""
Implements a L-layer neural network: [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID.
Arguments:
X -- data, numpy array of shape (number of examples, num_px * num_px * 3)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples)
layers_dims -- list containing the input size and each layer size, of length (number of layers + 1).
learning_rate -- learning rate of the gradient descent update rule
num_iterations -- number of iterations of the optimization loop
print_cost -- if True, it prints the cost every 100 steps
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
np.random.seed(1)
costs = [] # keep track of cost
# Parameters initialization.
### START CODE HERE ###
parameters=initialize_parameters_deep(layers_dims)
### END CODE HERE ###
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: [LINEAR -> RELU]*(L-1) -> LINEAR -> SIGMOID.
### START CODE HERE ### (≈ 1 line of code)
AL,caches=L_model_forward(X,parameters)
### END CODE HERE ###
# Compute cost.
### START CODE HERE ### (≈ 1 line of code)
cost=compute_cost(AL,Y)
### END CODE HERE ###
# Backward propagation.
### START CODE HERE ### (≈ 1 line of code)
grads=L_model_backward(AL,Y,caches)
### END CODE HERE ###
# Update parameters.
### START CODE HERE ### (≈ 1 line of code)
parameters=update_parameters(parameters,grads,learning_rate)
### END CODE HERE ###
# Print the cost every 100 training example
if print_cost and i % 100 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
if print_cost and i % 100 == 0:
costs.append(cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
You will now train the model as a 5-layer neural network.
Run the cell below to train your model. The cost should decrease on every iteration. It may take up to 5 minutes to run 2500 iterations. Check if the “Cost after iteration 0” matches the expected output below, if not click on the square () on the upper bar of the notebook to stop the cell and try to find your error.
parameters = L_layer_model(train_x, train_y, layers_dims, num_iterations = 2500, print_cost = True)
Expected Output:
| **Cost after iteration 0** | 0.771749 |
| **Cost after iteration 100** | 0.672053 |
| **...** | ... |
| **Cost after iteration 2400** | 0.092878 |
pred_train = predict(train_x, train_y, parameters)
| **Train Accuracy** | 0.985645933014 |
pred_test = predict(test_x, test_y, parameters)
Expected Output:
| **Test Accuracy** | 0.8 |
This is good performance for this task. Nice job!
Though in the next course on “Improving deep neural networks” you will learn how to obtain even higher accuracy by systematically searching for better hyperparameters (learning_rate, layers_dims, num_iterations, and others you’ll also learn in the next course).
6) Results Analysis
First, let’s take a look at some images the L-layer model labeled incorrectly. This will show a few mislabeled images.
print_mislabeled_images(classes, test_x, test_y, pred_test)
A few type of images the model tends to do poorly on include:
- Cat body in an unusual position
- Cat appears against a background of a similar color
- Unusual cat color and species
- Camera Angle
- Brightness of the picture
- Scale variation (cat is very large or small in image)
7) Test with your own image (optional/ungraded exercise)
Congratulations on finishing this assignment. You can use your own image and see the output of your model. To do that:
1. Click on “File” in the upper bar of this notebook, then click “Open” to go on your Coursera Hub.
2. Add your image to this Jupyter Notebook’s directory, in the “images” folder
3. Change your image’s name in the following code
4. Run the code and check if the algorithm is right (1 = cat, 0 = non-cat)!
## START CODE HERE ##
## END CODE HERE ##
fname = "images/" + my_image
image = np.array(plt.imread(fname))
my_image = scipy.misc.imresize(image, size=(num_px,num_px)).reshape((num_px*num_px*3,1))
my_predicted_image = predict(my_image, my_label_y, parameters)
plt.imshow(image)
print ("y = " + str(np.squeeze(my_predicted_image)) + ", your L-layer model predicts a \"" + classes[int(np.squeeze(my_predicted_image)),].decode("utf-8") + "\" picture.")
智能推荐
【Unity API】3---GameObject_unity new gameobject()参数-程序员宅基地
文章浏览阅读425次。1.创建游戏物体的三种方法 public GameObject prefab; // Use this for initialization void Start () { //1.第一种创建方法 GameObject go = new GameObject("Cube"); //2.第二种 ,可以实例化特效或者角色等等 ..._unity new gameobject()参数
python知识图谱问答系统代码_医疗知识图谱问答系统探究(一)-程序员宅基地
文章浏览阅读522次。这是 阿拉灯神丁Vicky 的第 23 篇文章1、项目背景为通过项目实战增加对知识图谱的认识,几乎找了所有网上的开源项目及视频实战教程。果然,功夫不负有心人,找到了中科院软件所刘焕勇老师在github上的开源项目,基于知识图谱的医药领域问答项目QABasedOnMedicaKnowledgeGraph。用了两个晚上搭建了两套,Mac版与Windows版,哈哈,运行成功!!!从无到有搭建一个以疾病为..._chat_graph.py
hdu 3986 Harry Potter and the Final Battle(最短路+枚举删边)_3986 harry potter and the final battle 枚举+最短路(删掉任意-程序员宅基地
文章浏览阅读899次。Harry Potter and the Final BattleTime Limit: 5000/3000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submission(s): 1741 Accepted Submission(s): 487Problem Descript_3986 harry potter and the final battle 枚举+最短路(删掉任意一条边的最长最短
python开发节目程序_python获取央视节目信息-程序员宅基地
文章浏览阅读342次。# -*- coding: utf-8 -*-#---------------------------------------# 程序:cctv节目表抓取# 作者:lqf# 日期:2013-08-09# 语言:Python 2.7# 功能:抓取央视的节目列表信息#---------------------------------------import stringimport..._python获取电视直播节目单
如何用C语言实现OOP-程序员宅基地
文章浏览阅读1.6k次,点赞5次,收藏18次。我们知道面向对象的三大特性分别是:封装、继承、多态。很多语言例如:C++ 和 Java 等都是面向对象的编程语言,而我们通常说 C 是面向过程的语言,那么是否可以用 C 实现简单的面向对象..._c语言如何实现oop编程
Spark特征工程-one-hot 和 multi-hot_spark df one-hot-程序员宅基地
文章浏览阅读1k次。one-hot , multi-hot_spark df one-hot
随便推点
嵌入式系统的事件驱动型编程技术_[论文阅读笔记]区块链系统中智能合约技术综述...-程序员宅基地
文章浏览阅读276次。区块链系统中智能合约技术综述范吉立 李晓华 聂铁铮 于戈《计算机科学》2019年8月14页,56个参考文献框架1 引言2 区块链中的智能合约语言2.1 智能合约语言2.2 比特币脚本语言图2.3 以太坊灵完备型语言2.3.1 Solidity语言2.3.2 Serpent语言2.4 可验证型语言Pact2.5 超级账本智能合约语言2.6 开发语言的对比3 区块链中智能合约的实现技术3.1 嵌..._嵌入式事件驱动编程
python嵌入式开发实战_Python和PyQT来开发嵌入式ARM界面如何实现-程序员宅基地
文章浏览阅读386次。Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发1)。 简介随着Python在互联网人工智能领域的流行,大家也慢慢感受到Python开发的便利,本文就基于嵌入式ARM平台,介绍使用Python配合PyQT5模块来开发图形化应用程序。本文所演示的ARM平台..._qt for python可以写入嵌入式设备吗
python rabbitmq 多任务类型_rabbitmq常用的三种exchange类型和python库pika接入rabbitmq-程序员宅基地
文章浏览阅读108次。现在很多开源软件都提供了对应的web管理界面,rabbitmq也不例外,rabbitmq提供了一个web插件。当rabbit-server启动之后,即在浏览器中通过http://localhost:15672/地址访问页面,提供一个比命令rabbitmqctl更友好的学习rabbitmq的方式。可以简单方便的通过配置rabbitmq,并可以向exchange和queue中发消息来验证自己的理解。如..._python rabbitmq exchange_bind
关于达梦数据库数据迁移工具的使用方法(DTS)_达梦迁移工具使用方法-程序员宅基地
文章浏览阅读5.1k次。达梦DTS工具的使用,适用于简单的数据迁移_达梦迁移工具使用方法
java上传文件到文件夹判断文件夹是否存在,不存在则创建_java nas 上传文件夹不存在-程序员宅基地
文章浏览阅读4.2k次。// 判断文件夹是否存在 public static void judeDirExists(File file) { if (file.exists()) { if (file.isDirectory()) { System.out.println("dir exists"); } else {_java nas 上传文件夹不存在
前后端通信安全RSA+AES混合加密_aes前端加密安全吗-程序员宅基地
文章浏览阅读3.4k次。前后端安全通信一直是头疼的问题,如何保证前后端安全通信?读完这偏文章教你学会前后端安全通信。_aes前端加密安全吗