深度学习模型部署(五)onnx模型以及相应工具_onnx模型dpu-程序员宅基地
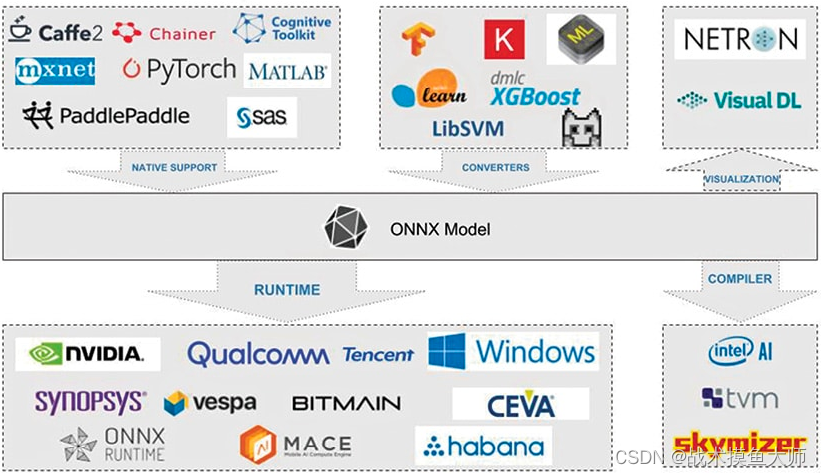
ONNX概念
onnx不仅仅一种模型参数存储的格式,还是一套完整的用于描述计算函数的编程语言,它的作用就是定义计算图,他本身无法进行。
这个概念和Verilog有点像,一个是硬件描述语言,一个是模型描述语言。
onnx模型或者说计算图,是由这几部分组成:
- input,output:输入输出
- node:节点,即算子,算子的固定参数保存在attribute中
- initializer:初始化器,用于加载函数
此外onnx还允许在模型中添加一些元数据,用于记录作者,模型版本等信息,类似于注释一样。onnx模型中的元数据有:
- doc_string:人类可读的文档,可以用markdown
- domain:不知道干啥用的,反正存个模型名字
- metadata_props:是个字典类型的,不知道干啥使的
- model_author:模型的作者
- model_license:模型的版权协议
- model_version:模型版本
- producer_name:训练模型的框架
- producer_version:训练框架的版本
- training_info:训练信息
Onnx存储方式是使用protobuf来存储,protobuf是Protocol Buffers的简称,它是Google公司开发的一种数据描述语言,很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。它的定位类似于xml和json这种。
Onnx支持的operator
Onnx将支持的operator存储到两个domain中,一个domain是ai.onnx,存储了大量深度学习常用operator,另一个是ai.onnx.ml,存储了树模型以及一些机器学习中的operator。
Onnx支持的数据类型
基本上主流的数据类型都支持,例如fp32,fp16,int4,int8,int16等.Onnx中支持的数据类型:
0: onnx.TensorProto.UNDEFINED
1: onnx.TensorProto.FLOAT
2: onnx.TensorProto.UINT8
3: onnx.TensorProto.INT8
4: onnx.TensorProto.UINT16
5: onnx.TensorProto.INT16
6: onnx.TensorProto.INT32
7: onnx.TensorProto.INT64
8: onnx.TensorProto.STRING
9: onnx.TensorProto.BOOL
10: onnx.TensorProto.FLOAT16
11: onnx.TensorProto.DOUBLE
12: onnx.TensorProto.UINT32
13: onnx.TensorProto.UINT64
14: onnx.TensorProto.COMPLEX64
15: onnx.TensorProto.COMPLEX128
16: onnx.TensorProto.BFLOAT16
17: onnx.TensorProto.FLOAT8E4M3FN
18: onnx.TensorProto.FLOAT8E4M3FNUZ
19: onnx.TensorProto.FLOAT8E5M2
20: onnx.TensorProto.FLOAT8E5M2FNUZ
21: onnx.TensorProto.UINT4
22: onnx.TensorProto.INT4
ONNX是强类型的语言,不支持数据类型之间的隐式转换,想要转换必须添加显式转换。
ONNX支持2维的稀疏张量,类型为SparseTensorProto
稀疏向量是指0比较多的向量,可以用特殊的方式来存储以减少空间占用。
opset version
ONNX的算子库是不断更新的,opset version就是算子库版本,onnx版本和opset的版本是对应的,每次算子库版本更新都会引入新的算子。模型本身也要指定一个算子版本来表示模型所依赖的算子的版本。例如6,7,13,14版本的算子库对Add算子进行了更新,如果模型指定的算子库版本是15,那么Add算子将使用14版本的实现。
Onnx控制流
ONNX支持控制流算子例如if,但是这样会降低性能,最好避免控制流算子。
if算子
根据条件决定执行哪个子图,但是子图的输出shape和num必须是一样的,子图的输出将作为if算子的输出。
下面是一个简单的模型的搭建过程,手搓模型就是这么搓的。
import onnx
import numpy as np
# Given a bool scalar input cond.
# return constant tensor x if cond is True, otherwise return constant tensor y.
cond = onnx.helper.make_tensor_value_info( # 创建输入
"cond", onnx.TensorProto.BOOL, []
)
then_out = onnx.helper.make_tensor_value_info( # 创建then输出
"then_out", onnx.TensorProto.FLOAT, [5]
)
else_out = onnx.helper.make_tensor_value_info( # 创建else输出
"else_out", onnx.TensorProto.FLOAT, [5]
)
x = np.array([1, 2, 3, 4, 5]).astype(np.float32) # 创建then输出的值
y = np.array([5, 4, 3, 2, 1]).astype(np.float32) # 创建else输出的值
then_const_node = onnx.helper.make_node( # 创建then输出的节点
"Constant",
inputs=[],
outputs=["then_out"],
value=onnx.numpy_helper.from_array(x),
)
else_const_node = onnx.helper.make_node( # 创建else输出的节点
"Constant",
inputs=[],
outputs=["else_out"],
value=onnx.numpy_helper.from_array(y),
)
then_body = onnx.helper.make_graph( # 创建then的子图
[then_const_node], "then_body", [], [then_out]
)
else_body = onnx.helper.make_graph( # 创建else的子图
[else_const_node], "else_body", [], [else_out]
)
if_node = onnx.helper.make_node( # 创建if节点
"If",
inputs=["cond"],
outputs=["res"],
then_branch=then_body,
else_branch=else_body,
)
res = onnx.helper.make_tensor_value_info("res", onnx.TensorProto.FLOAT, [5]) # 创建输出,这个输出是if节点的输出
graph = onnx.helper.make_graph( # 创建主图
[if_node], "test_if", [cond], [res]
)
onnx.save_model( # 保存模型
onnx.helper.make_model(graph, opset_imports=[onnx.helper.make_opsetid("", 11)]),
"if.onnx",
)
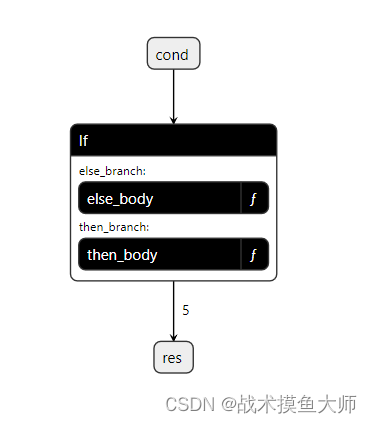
模型结构图
Scan循环算子
scan算子有一个全局变量,只需要开始时输入进行初始化,还有一个输入,每次循环都输入,这两个是并在一个输入里面的,scan的输出也是,一个输出是全局变量最后的值,另一个输出是每次循环的输出结合到一起,比如:全局变量是N维度,每次输入是M维,每次输出也是M维,循环k次,那么scan的输入就是:[N,kM],输出是:[N,kM]。
# Given an input sequence [x1, ..., xN], sum up its elements using a scan
# returning the final state (x1+x2+...+xN) as well the scan_output
# [x1, x1+x2, ..., x1+x2+...+xN]
#
# create graph to represent scan body
import numpy as np
import onnx
sum_in = onnx.helper.make_tensor_value_info(
"sum_in", onnx.TensorProto.FLOAT, [2]
)
next = onnx.helper.make_tensor_value_info("next", onnx.TensorProto.FLOAT, [2])
sum_out = onnx.helper.make_tensor_value_info(
"sum_out", onnx.TensorProto.FLOAT, [2]
)
scan_out = onnx.helper.make_tensor_value_info(
"scan_out", onnx.TensorProto.FLOAT, [2]
)
add_node = onnx.helper.make_node(
"Add", inputs=["sum_in", "next"], outputs=["sum_out"]
)
id_node = onnx.helper.make_node(
"Identity", inputs=["sum_out"], outputs=["scan_out"]
)
scan_body = onnx.helper.make_graph(
[add_node, id_node], "scan_body", [sum_in, next], [sum_out, scan_out]
)
# create scan op node
node = onnx.helper.make_node(
"Scan",
inputs=["initial", "x"],
outputs=["y", "z"],
num_scan_inputs=1,
body=scan_body,
)
# create inputs for sequence-length 3, inner dimension 2
initial = np.array([0, 0]).astype(np.float32).reshape((2,))
x = np.array([1, 2, 3, 4, 5, 6]).astype(np.float32).reshape((3, 2))
# final state computed = [1 + 3 + 5, 2 + 4 + 6]
y = np.array([9, 12]).astype(np.float32).reshape((2,))
# scan-output computed
z = np.array([1, 2, 4, 6, 9, 12]).astype(np.float32).reshape((3, 2))
# create graph
initial_info = onnx.helper.make_tensor_value_info(
"initial", onnx.TensorProto.FLOAT, initial.shape
)
x_info = onnx.helper.make_tensor_value_info("x", onnx.TensorProto.FLOAT, x.shape)
y_info = onnx.helper.make_tensor_value_info("y", onnx.TensorProto.FLOAT, y.shape)
z_info = onnx.helper.make_tensor_value_info("z", onnx.TensorProto.FLOAT, z.shape)
graph = onnx.helper.make_graph(
[node], "test_scan", [initial_info, x_info], [y_info, z_info]
)
# create model
model = onnx.helper.make_model(graph, opset_imports=[onnx.helper.make_opsetid("", 11)])
# save model
onnx.save_model(model, "scan.onnx")
#inference
import onnxruntime as rt
sess = rt.InferenceSession("scan.onnx")
res = sess.run(None, {
"initial": initial, "x": x})
print(res)
LOOP算子
就常见的循环,跟scan差不多,不过没有全局变量,输入也是每次循环输入一个,输出是每个循环的输出结合到一起,结合方式有两种:一种是结合成一个大的tensor,另一种是多个tensor结合成一个sequence,前者要求每个循环的输出的shape必须可以相互兼容才能结合。
扩展算子
ONNX允许自定义算子,这部分内容比较多,后面再写blog专门讲
Function
我的理解是:有的模型中的层是多个算子结合到一起形成的,比如yolo中的C3,这种不需要再自定义算子,可以把几个需要的算子结合到一起形成一个Function。官方说这样做的好处是:可以减小代码量,可以给推理引擎额外信息,推理引擎可以用这些信息做优化,比如为一些Function进行底层实现。
官方文档原文:Functions are one way to extend ONNX specifications. Some model requires the same combination of operators. This can be avoided by creating a function itself defined with existing ONNX operators. Once defined, a function behaves like any other operators. It has inputs, outputs and attributes.
There are two advantages of using functions. The first one is to have a shorter code and easier to read. The second one is that any onnxruntime can leverage that information to run predictions faster. The runtime could have a specific implementation for a function not relying on the implementation of the existing operators
类型推理
Onnx可以推理出模型的输出的数据类型以及大小,但是对于有自定义算子的模型不可以。
工具
- netron:可视化工具,自行百度下载
- onnx2py.py:根据onnx模型反生成一个py文件,这个py脚本可以生成这个模型,用于让用户修改模型,例如想要修改一个模型,可以先生成“可以生成这个模型的脚本”,然后再修改这个脚本,再用这个修改过的脚本生成模型。
- onnx-graphsurgeon:TensorRT做的一个工具,可以用于修改onnx模型,名字翻译过来就是图手术刀
如果觉得有帮助,点赞收藏+关注!thanks!
智能推荐
JAVA 中的 Random() 函数_random true-程序员宅基地
文章浏览阅读182次。Java 中存在着两种 Random 函数用来产生随机数 , 分别是 java.lang.Math.random() 和 java.util.Random() , 下面分开介绍java.lang.Math.random()调用这个 Math.Random() 函数能够返回带正号的 double 值 , 该值大于等于 0.0 且小于 1.0 , 即取值范围是 [0.0,1.0) 的左闭右开区间 ..._random true
股票质押式回购 非担保交收 结算备付金 B股转H股_非担保交易-程序员宅基地
文章浏览阅读2.5k次。 股票质押式回购股票质押式回购交易(简称“股票质押回购”)是指符合条件的资金融入方(简称“融入方”)以所持有的股票或其他证券质押,向符合条件的资金融出方(简称“融出方”)融入资金,并约定在未来返还资金、解除质押的交易。股票质押回购的回购期限不超过3 年,回购到期日遇非交易日顺延等情形除外。业务流程如下: 1、融入方、融出方、证券公司各方签署《股票质押回购交易业务协议》;2、证券..._非担保交易
反激变换器衍生拓扑对比分析_非对称反激-程序员宅基地
文章浏览阅读747次,点赞15次,收藏17次。在非对称反激变换器中,上管导通时,变压器和谐振电容同时储存能量,当能量从原边向次级传输时,原边串联的谐振电容和变压器储存的能量,同时向输出负载传输,因此,变压器得到利用的利用,变压器的尺寸可以显著的减小。(1)有源箝位反激变换器的变压器需要储存输出所需的所有能量,由于输入电压通常在一定的范围内变化,因此变压器无法工作在最优的状态,变压器也无法进行最优化的设计。、有源箝位反激变换器中,当负载降低到某一值时,系统会退出有源箝位的工作方式,效率会降低,同时会对次级整流管产生高的电压应力。_非对称反激
WIFI 认证 测试_11n认证用例-程序员宅基地
文章浏览阅读7.3k次。IEEE 802.11a/b/g双频带WorldRadio设计已经完成Wi-Fi多媒体(WMM,Wi-Fi multimedia)的Wi-Fi认证。 WMM通过控制网络音频、视频与数据的优先传送次序与缩短延迟时间提供给无线多媒体应用卓越的服务品质(QoS, Quality of Service),这个认证程序同时也可以确保取得WMM 认证的产品具有互通性,将有助于Wi-Fi 技术在消费_11n认证用例
32.Python从入门到精通—Python错误输出重定向和程序终止 字符串正则匹配 访问 互联网 日期和时间-程序员宅基地
文章浏览阅读5.4k次,点赞28次,收藏24次。接下来使用re模块中的findall函数进行匹配,它会返回一个列表,其中包含了所有符合模式的子串。最后输出匹配结果,可以看到输出的结果是一个列表,其中包含了所有匹配到的单词。除了findall函数之外,re模块还提供了其他一些函数,用于进行字符串正则匹配,例如search函数、match函数、sub函数等等。除了这些基本操作之外,datetime模块还提供了许多其他的日期和时间操作,例如时区转换、日期和时间的加减、日期和时间的比较等等。在上面的代码中,如果程序遇到异常,它将打印错误信息并以状态码1退出。
【送书福利-第二十五期】《AI时代系列书籍》-程序员宅基地
文章浏览阅读4.4w次,点赞37次,收藏35次。【送书福利-第二十五期】《AI时代系列书籍》
随便推点
Eclipse中运行JSP程序(J2ee第三天学习记录)_eel3 shij-程序员宅基地
文章浏览阅读5.3k次,点赞8次,收藏27次。之前写的jsp学习记录,感觉没什么干货,大家随便看看吧_eel3 shij
约瑟夫问题的几种解法_yue se fu ying shi li yu ruan shi li-程序员宅基地
文章浏览阅读2.5k次。问题来历据说著名犹太历史学家 Josephus有过以下的故事:在罗马人占领乔塔帕特后,39 个犹太人与Josephus及他的朋友躲到一个洞中,39个犹太人决定宁愿死也不要被敌人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,由第1个人开始报数,每报数到第3人该人就必须自杀,然后再由下一个重新报数,直到所有人都自杀身亡为止。然而Josephus 和他的朋友并不想遵从。首先从一个人开始,越过k-2个_yue se fu ying shi li yu ruan shi li
win10安装pyskl配置环境,软件安装等mmdet(1)_pyskl 环境配置-程序员宅基地
文章浏览阅读658次。上周对骨骼识别的GitHub进行仿真,初步有了进展,现在对其进行复盘,首先软件是基于python语言为基础的,第一步就是安装python,对于版本是有要求的,这里先展示一下pyskl的下载库的版本要求。这个你可以试一下先pip下载cpython,cython,pip下载pycocotools ,但是一般还是有问题,所以先下载这个pycocotools的包,这是包的下载。10.mmdet=2.23.0这个是问题出的最多的地方,先是下载mmdet的whl文件,然后也放在跟mmcv-full的那个地方上面。_pyskl 环境配置
adobe dreamweaver cs5序列号_dwcs5序列号-程序员宅基地
文章浏览阅读5.2k次。Adobe Dreamweaver CS5序列号如下:1192-1973-6217-2477-6088-1657(我用的是这个)1192-1013-2621-8434-6884-01751192-1482-6532-1529-0926-55701192-1384-9698-0251-8971-98021192-1678-5764-4289-1578-82661192-1337-9219..._dwcs5序列号
超详细Anaconda安装教程-程序员宅基地
文章浏览阅读10w+次,点赞488次,收藏2.2k次。超详细最新Anaconda安装教程_anaconda安装教程
C语言中的3种注释方法_c语言注释-程序员宅基地
文章浏览阅读1.5w次,点赞5次,收藏30次。在用C语言编程时,常用的注释方式有如下几种: (1)单行注释 // … (2)多行注释 /* … */ (3)条件编译注释 #if 0…#endif_c语言注释