【Python爬虫必备—>Scrapy框架快速入门篇——上】_scrpy框架教学-程序员宅基地
技术标签: 爬虫框架 万字博文 快速入门 原力计划 Scrapy框架从入门到实战 scrapy
- 相信不少小伙伴们在经历过我的上几篇关于爬虫技术的万字博文的轮番轰炸后,已经可以独立开发出属于自己的爬虫项目!!!——爬虫之路,已然开启!
第一篇之爬虫入坑文;一篇万字博文带你入坑爬虫这条不归路(你还在犹豫什么&抓紧上车)
第二篇之爬虫库requests库详解。两万字博文教你python爬虫requests库,看完还不会我把我女朋友都给你
第三篇之解析库Beautiful Soup库详解。Python万字博文教你玩透Beautiful Soup库【️建议收藏系列️】
第四篇之Selenium详解。【️爬虫必备->Selenium从黑铁到王者️】初篇——万字博文详解(建议收藏)
- 但是 前几日有很多粉丝私聊我反馈说:"自己爬虫基础库已经学差不多了,实战也做了不少,但是好多自己接的爬虫单或者老板都要求使用scrapy框架来爬取数据,自己没有接触过scrapy框架不知道如何下手!"
其实我已经有一个scrapy一条龙教学的分栏,也有不少人订阅并且反响不错,【Scrapy框架详解】。但是呢?我又想了想,确实少了篇总结性的文章——来从总体上介绍Scrapy框架。
-
所以应粉丝们要求,本博主花了假期周六周日两天时间,肝出本文(共分上中下三篇),目的在于带领想要学习scrapy的同学走近scrapy的世界!并在文末附带一整套scrapy框架学习路线,如果你能认认真真看完这三篇文章,在心里对scrapy有个印象,然后潜心研究文末整套学习路线,那么,scrapy框架对你来说——手到擒来!!!
-
我会尽量把技术文写的通俗易懂/生动有趣,保证每一个想要学习知识&&认认真真读完本文的读者们能够有所获,有所得。当然,如果你读完感觉本文写的还可以,真正学习到了东西,希望给我个「 赞 」 和 「 收藏 」,这个对我很重要,谢谢了!
第一部分:走近scrapy!
0.简介及安装
1️⃣简介:
scrapy设计目的:用于爬取网络数据,提取结构性数据的框架,其中,scrapy使用了Twisted异步网络框架,大大加快了下载速度!
2️⃣安装:
直接pip安装(一句命令&&一步到位):
pip install scrapy
1.scrapy项目开发流程:
- 创建项目:scrapy startproject mySpider
- 生成一个爬虫:scrapy genspider baidu baidu.com
- 提取数据:根据网站结构在spider中实现数据采集相关内容
- 保存数据:使用pipeline进行数据后续处理和保存
2.scrapy框架运行流程:
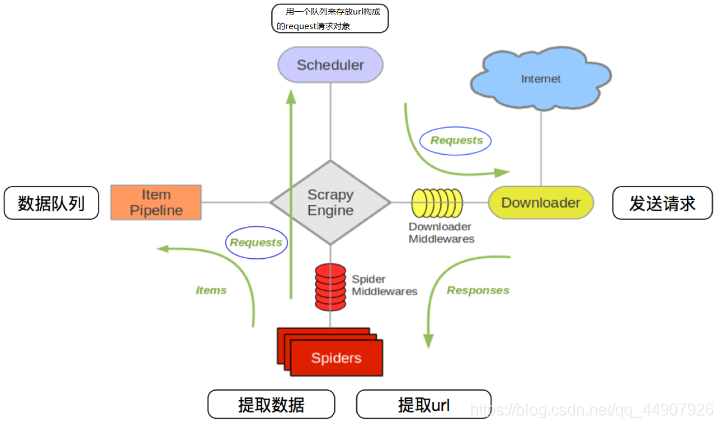

原理描述:
- 爬虫中起始url构造的url对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件–>下载器
- 下载器发送请求,获取response响应—>下载中间件—>引擎–>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象—>爬虫中间件—>引擎—>调度器,重复步骤2
- 爬虫提取数据—>引擎—>管道处理和保存数据
| 注意:爬虫中间件和下载中间件只是运行的逻辑的位置不同,作用是重复的:如替换UA等! |
拓展——scrapy中三个内置对象:
三个内置对象:(scrapy框架中只有三种数据类型)
request请求对象:由url,method,post_data,headers等构成;
response响应对象:由url,body,status,headers等构成;
item数据对象:本质是一个字典。
第二部分:创建&&运行你的第一个scrapy项目!
1.创建项目:
创建scrapy项目的命令:scrapy startproject <项目名字>
示例:
scrapy startproject myspider
生成的目录和文件结果如下:

2.爬虫文件的创建:
在项目根路径下执行:
scrapy genspider <爬虫名字> <允许爬取的域名>
示例:
cd myspider
scrapy genspider itcast itcast.cn
讲解:
- 爬虫名字:作为爬虫运行时的参数;
- 允许爬的域名:为对于爬虫设置的爬取范围,设置之后用于过滤要爬取的url,如果爬取的url与允许的域名不同,则被过滤掉。
3.运行scrapy爬虫:
命令:在项目目录下执行:
scrapy crawl <爬虫名字>
示例:
scrapy crawl itcast
不过,在运行之前,我们先要编写itcast.py爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
# 爬虫运行时的参数
name = 'itcast'
# 检查允许爬的域名
allowed_domains = ['itcast.cn']
# 1.修改设置起始的url
start_urls = ['见评论区']
# 数据提取的方法:接收下载中间件传过来的response,定义对于网站相关的操作
def parse(self, response):
# 获取所有的教师节点
t_list = response.xpath('//div[@class="li_txt"]')
print(t_list)
# 遍历教师节点列表
tea_dist = {
}
for teacher in t_list:
# xpath方法返回的是选择器对象列表 extract()方法可以提取到selector对象中data对应的数据。
tea_dist['name'] = teacher.xpath('./h3/text()').extract_first()
tea_dist['title'] = teacher.xpath('./h4/text()').extract_first()
tea_dist['desc'] = teacher.xpath('./p/text()').extract_first()
yield teacher
然后再运行,会发现已经可以正常运行!
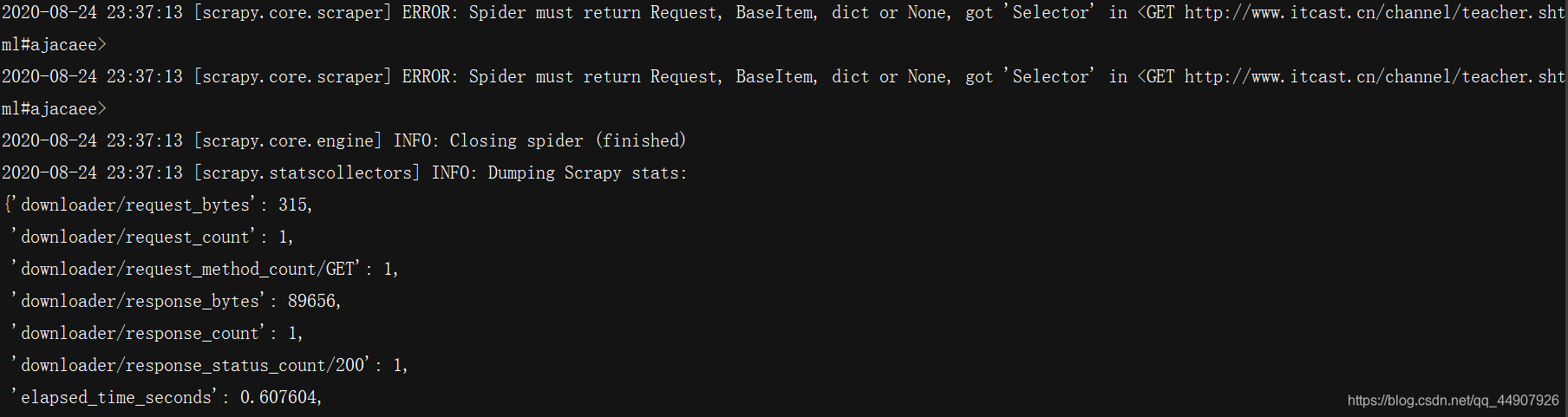
4.明确了爬虫所爬取数据之后,使用管道进行数据持久化操作:
修改itcast.py爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
from ..items import UbuntuItem
class ItcastSpider(scrapy.Spider):
# 爬虫运行时的参数
name = 'itcast'
# 检查允许爬的域名
allowed_domains = ['itcast.cn']
# 1.修改设置起始的url
start_urls = ['见评论区']
# 数据提取的方法:接收下载中间件传过来的response,定义对于网站相关的操作
def parse(self, response):
# 获取所有的教师节点
t_list = response.xpath('//div[@class="li_txt"]')
print(t_list)
# 遍历教师节点列表
item = UbuntuItem()
for teacher in t_list:
# xpath方法返回的是选择器对象列表 extract()方法可以提取到selector对象中data对应的数据。
item['name'] = teacher.xpath('./h3/text()').extract_first()
item['title'] = teacher.xpath('./h4/text()').extract_first()
item['desc'] = teacher.xpath('./p/text()').extract_first()
yield item
注意:
- scrapy.Spider爬虫类中必须有名为parse的解析;
- 如果网站结构层次比较复杂,也可以自定义其他解析函数;
- 在解析函数中提取的url地址如果要发送请求,则必须属于allowed_domains范围内,但是start_urls中的url地址不受这个限制;
- 启动爬虫的时候注意启动的位置,是在项目路径下启动;
- parse()函数中使用yield返回数据,注意:解析函数中的yield能够传递的对象只能是:BaseItem, Request, dict, None。
小知识点1——定位元素以及提取数据、属性值的方法:
(解析并获取scrapy爬虫中的数据: 利用xpath规则字符串进行定位和提取)
- response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法;
- 额外方法extract():返回一个包含有字符串的列表;
- 额外方法extract_first():返回列表中的第一个字符串,列表为空没有返回None。
小知识点2——response响应对象的常用属性:
- response.url:当前响应的url地址
- response.request.url:当前响应对应的请求的url地址
- response.headers:响应头
- response.requests.headers:当前响应的请求头
- response.body:响应体,也就是html代码,byte类型
- response.status:响应状态码
5.管道保存数据
在pipelines.py文件中定义对数据的操作!
- 定义一个管道类;
- 重写管道类的process_item方法;
- process_item方法处理完item之后必须返回给引擎。
️初级篇:
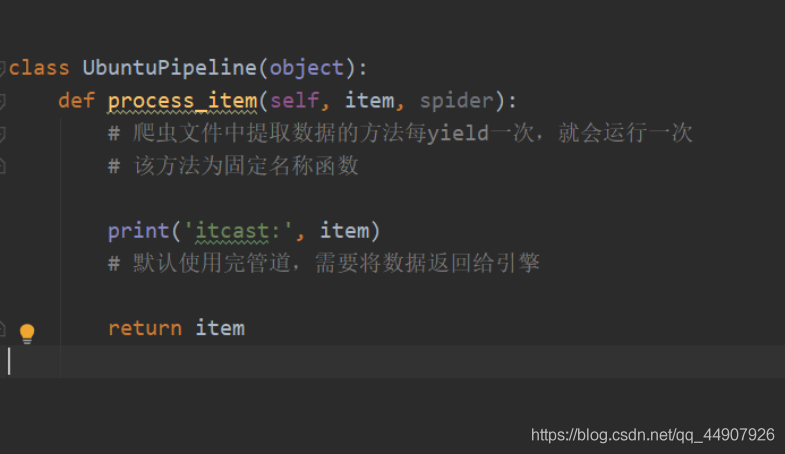
️进阶篇:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
class UbuntuPipeline(object):
def __init__(self):
self.file = open('itcast.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 将item对象强制转为字典,该操作只能在scrapy中使用
item = dict(item)
# 爬虫文件中提取数据的方法每yield一次,就会运行一次
# 该方法为固定名称函数
# 默认使用完管道,需要将数据返回给引擎
# 1.将字典数据序列化
'''ensure_ascii=False 将unicode类型转化为str类型,默认为True'''
json_data = json.dumps(item, ensure_ascii=False, indent=2) + ',\n'
# 2.将数据写入文件
self.file.write(json_data)
return item
def __del__(self):
self.file.close()
6.settings.py配置启用管道:
在settings文件中,解封代码,说明如下:
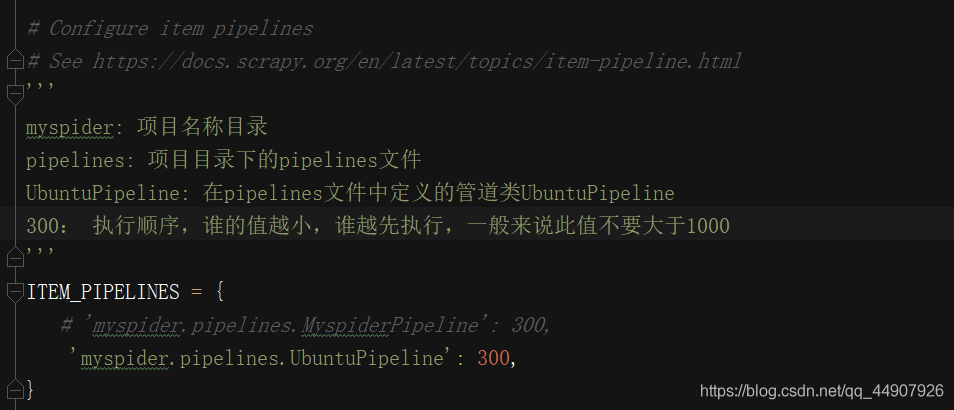
7.scrapy数据建模与请求:
(通常在做项目的过程中,在items.py中进行数据建模!)
(1)为什么建模?
- 定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查,值不相同会报错;
- 配合注释一起可以清晰的知道要抓取哪些字段,没有定义的字段不能抓取,在目标字段少的时候可以使用字典代替;
- 使用scrapy的一些特定组件需要Item做支持,如scrapy的ImagesPipeline管道类。
(2)本项目中实操:
在items.py文件中操作:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class UbuntuItem(scrapy.Item):
# 讲师名字
name = scrapy.Field()
# 讲师职称
title = scrapy.Field()
# 讲师座右铭
desc = scrapy.Field()
注意:
- from …items import UbuntuItem这一行代码中 注意item的正确导入路径,忽略pycharm标记的错误;
- python中的导入路径要诀:从哪里开始运行,就从哪里开始导入。
8.设置user-agent:
# settings.py文件中找到如下代码解封,并加入UA:
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36',
}
9.到目前为止,一个入门级别的scrapy爬虫已经OK了,基操都使用了!
如何run呢?
现在cd到项目目录下,输入
scrapy crawl itcast
即可运行scrapy!
10.开发流程总结:
-
创建项目:
scrapy startproject 项目名 -
明确目标:
在items.py文件中进行建模! -
创建爬虫:
创建爬虫:
scrapy genspider 爬虫名 允许的域名
完成爬虫:
修改start_urls; 检查修改allowed_domains; 编写解析方法! -
保存数据:
在pipelines.py文件中定义对数据处理的管道
在settings.py文件中注册启用管道
结语:
通过上面的学习,你已经可以独立创建一个scrapy项目并使用此框架进行简单的爬虫项目编写。但是!任何一种功夫都不是一下就能学好学会学精的!所以跟着本专栏,只要你跟着潜心学完,那么!恭喜你!你已经是名优秀的scrapy框架使用者了!!!
第三部分——In The End!

| 从现在做起,坚持下去,一天进步一小点,不久的将来,你会感谢曾经努力的你! |
智能推荐
class和struct的区别-程序员宅基地
文章浏览阅读101次。4.class可以有⽆参的构造函数,struct不可以,必须是有参的构造函数,⽽且在有参的构造函数必须初始。2.Struct适⽤于作为经常使⽤的⼀些数据组合成的新类型,表示诸如点、矩形等主要⽤来存储数据的轻量。1.Class⽐较适合⼤的和复杂的数据,表现抽象和多级别的对象层次时。2.class允许继承、被继承,struct不允许,只能继承接⼝。3.Struct有性能优势,Class有⾯向对象的扩展优势。3.class可以初始化变量,struct不可以。1.class是引⽤类型,struct是值类型。
android使用json后闪退,应用闪退问题:从json信息的解析开始就会闪退-程序员宅基地
文章浏览阅读586次。想实现的功能是点击顶部按钮之后按关键字进行搜索,已经可以从服务器收到反馈的json信息,但从json信息的解析开始就会闪退,加载listview也不知道行不行public abstract class loadlistview{public ListView plv;public String js;public int listlength;public int listvisit;public..._rton转json为什么会闪退
如何使用wordnet词典,得到英文句子的同义句_get_synonyms wordnet-程序员宅基地
文章浏览阅读219次。如何使用wordnet词典,得到英文句子的同义句_get_synonyms wordnet
系统项目报表导出功能开发_积木报表 多线程-程序员宅基地
文章浏览阅读521次。系统项目报表导出 导出任务队列表 + 定时扫描 + 多线程_积木报表 多线程
ajax 如何从服务器上获取数据?_ajax 获取http数据-程序员宅基地
文章浏览阅读1.1k次,点赞9次,收藏9次。使用AJAX技术的好处之一是它能够提供更好的用户体验,因为它允许在不重新加载整个页面的情况下更新网页的某一部分。另外,AJAX还使得开发人员能够创建更复杂、更动态的Web应用程序,因为它们可以在后台与服务器进行通信,而不需要打断用户的浏览体验。在Web开发中,AJAX(Asynchronous JavaScript and XML)是一种常用的技术,用于在不重新加载整个页面的情况下,从服务器获取数据并更新网页的某一部分。使用AJAX,你可以创建异步请求,从而提供更快的响应和更好的用户体验。_ajax 获取http数据
Linux图形终端与字符终端-程序员宅基地
文章浏览阅读2.8k次。登录退出、修改密码、关机重启_字符终端
随便推点
Python与Arduino绘制超声波雷达扫描_超声波扫描建模 python库-程序员宅基地
文章浏览阅读3.8k次,点赞3次,收藏51次。前段时间看到一位发烧友制作的超声波雷达扫描神器,用到了Arduino和Processing,可惜啊,我不会Processing更看不懂人家的程序,咋办呢?嘿嘿,所以我就换了个思路解决,因为我会一点Python啊,那就动手吧!在做这个案例之前先要搞明白一个问题:怎么将Arduino通过超声波检测到的距离反馈到Python端?这个嘛,我首先想到了串行通信接口。没错!就是串口。只要Arduino将数据发送给COM口,然后Python能从COM口读取到这个数据就可以啦!我先写了一个测试程序试了一下,OK!搞定_超声波扫描建模 python库
凯撒加密方法介绍及实例说明-程序员宅基地
文章浏览阅读4.2k次。端—端加密指信息由发送端自动加密,并且由TCP/IP进行数据包封装,然后作为不可阅读和不可识别的数据穿过互联网,当这些信息到达目的地,将被自动重组、解密,而成为可读的数据。不可逆加密算法的特征是加密过程中不需要使用密钥,输入明文后由系统直接经过加密算法处理成密文,这种加密后的数据是无法被解密的,只有重新输入明文,并再次经过同样不可逆的加密算法处理,得到相同的加密密文并被系统重新识别后,才能真正解密。2.使用时,加密者查找明文字母表中需要加密的消息中的每一个字母所在位置,并且写下密文字母表中对应的字母。_凯撒加密
工控协议--cip--协议解析基本记录_cip协议embedded_service_error-程序员宅基地
文章浏览阅读5.7k次。CIP报文解析常用到的几个字段:普通类型服务类型:[0x00], CIP对象:[0x02 Message Router], ioi segments:[XX]PCCC(带cmd和func)服务类型:[0x00], CIP对象:[0x02 Message Router], cmd:[0x101], fnc:[0x101]..._cip协议embedded_service_error
如何在vs2019及以后版本(如vs2022)上添加 添加ActiveX控件中的MFC类_vs添加mfc库-程序员宅基地
文章浏览阅读2.4k次,点赞9次,收藏13次。有时候我们在MFC项目开发过程中,需要用到一些微软已经提供的功能,如VC++使用EXCEL功能,这时候我们就能直接通过VS2019到如EXCEL.EXE方式,生成对应的OLE头文件,然后直接使用功能,那么,我们上篇文章中介绍了vs2017及以前的版本如何来添加。但由于微软某些方面考虑,这种方式已被放弃。从上图中可以看出,这一功能,在从vs2017版本15.9开始,后续版本已经删除了此功能。那么我们如果仍需要此功能,我们如何在新版本中添加呢。_vs添加mfc库
frame_size (1536) was not respected for a non-last frame_frame_size (1024) was not respected for a non-last-程序员宅基地
文章浏览阅读785次。用ac3编码,执行编码函数时报错入如下:[ac3 @ 0x7fed7800f200] frame_size (1536) was not respected for anon-last frame (avcodec_encode_audio2)用ac3编码时每次送入编码器的音频采样数应该是1536个采样,不然就会报上述错误。这个数字并非刻意固定,而是跟ac3内部的编码算法原理相关。全网找不到,国内音视频之路还有很长的路,音视频人一起加油吧~......_frame_size (1024) was not respected for a non-last frame
Android移动应用开发入门_在安卓移动应用开发中要在活动类文件中声迷你一个复选框变量-程序员宅基地
文章浏览阅读230次,点赞2次,收藏2次。创建Android应用程序一个项目里面可以有很多模块,而每一个模块就对应了一个应用程序。项目结构介绍_在安卓移动应用开发中要在活动类文件中声迷你一个复选框变量