使用python编写网络爬虫_设计一个爬虫父类basespyder,包含基本网络连接和html数据获取方法-程序员宅基地
使用python编写网络爬虫
前言
此篇文章是本人编写爬虫获取数据的心得体会,涉及到数据收集、数据预处理。对于数据存储、数据处理与分析、数据展示/数据可视化、数据应用部分请关注我的新文章。仅适用于新手python、爬虫入门。
特别说明:
**1、本篇内容仅供个人学习交流用,禁止作为商业用途。【转载请注明出处】 https://blog.csdn.net/qq_44092306/
2、本篇文章只是介绍爬虫的思路,对于引用的模块不做详细解释,模块详细解释请大家查阅其他资料。谢谢!
1、为何使用爬虫
简单的说,使用爬虫的目的就是为了降低工作量。举个例子,当我们需要获取一些信息的时候,这些信息存在于不同的网页上面,而且数据量巨大,单纯的靠人工去记录则会浪费很多时间和精力。这时,我们就可以使用爬虫作为工具去获取这些数据集,大大减少了机械性工作的时间。在大数据中,数据的获取往往离不开爬虫。
2、编写爬虫的知识要求
- python基础知识:语法规则、控制语句、数据结构(字典、元组、列表)、函数 、模块
- HTML基础、CSS基础、http、https协议
- 会灵活的字符串处理、数据结构的处理
3、确定爬虫使用的工具库
本人使用的python版本为3
from bs4 import BeautifulSoup
import requests
import lxml
4、确定要获取的数据集
资源定位:获取贝壳网中的二手房房源信息
说明: 我们在选择目标网址的时候,尽量选择正规,用户使用量多的网站,虽然会遇到一些反爬措施。小网站尽量不要爬,因为小网站的网页格式有些并不是固定的,当我们写了爬虫代码后,运行起来会发现不能够通用,从而使爬取复杂化。
要获取的数据集: 房源标题、楼盘名称、简介、价格 (其他数据项也可获取,这几项只是作为例子)
4.1 分析Url地址变化

通过浏览网页发现,底部有分页导航栏,点击下一页时,url变化为
https://jn.ke.com/ershoufang/pg2/
因此,首页为https://jn.ke.com/ershoufang/pg1/。至此url变化分析完毕。
分析URL地址变化的目的是: 通过request.get()方法循环这些url,获取到HTML页面元素
4.2 获取目标数据集所在的HTML区域
在目标网页上面点击F12进入开发者模式,我们只想取得房源信息,因此其他HTML均为无用数据,无需获取。我们所做的是尽量将目标区域缩小到最小范围。
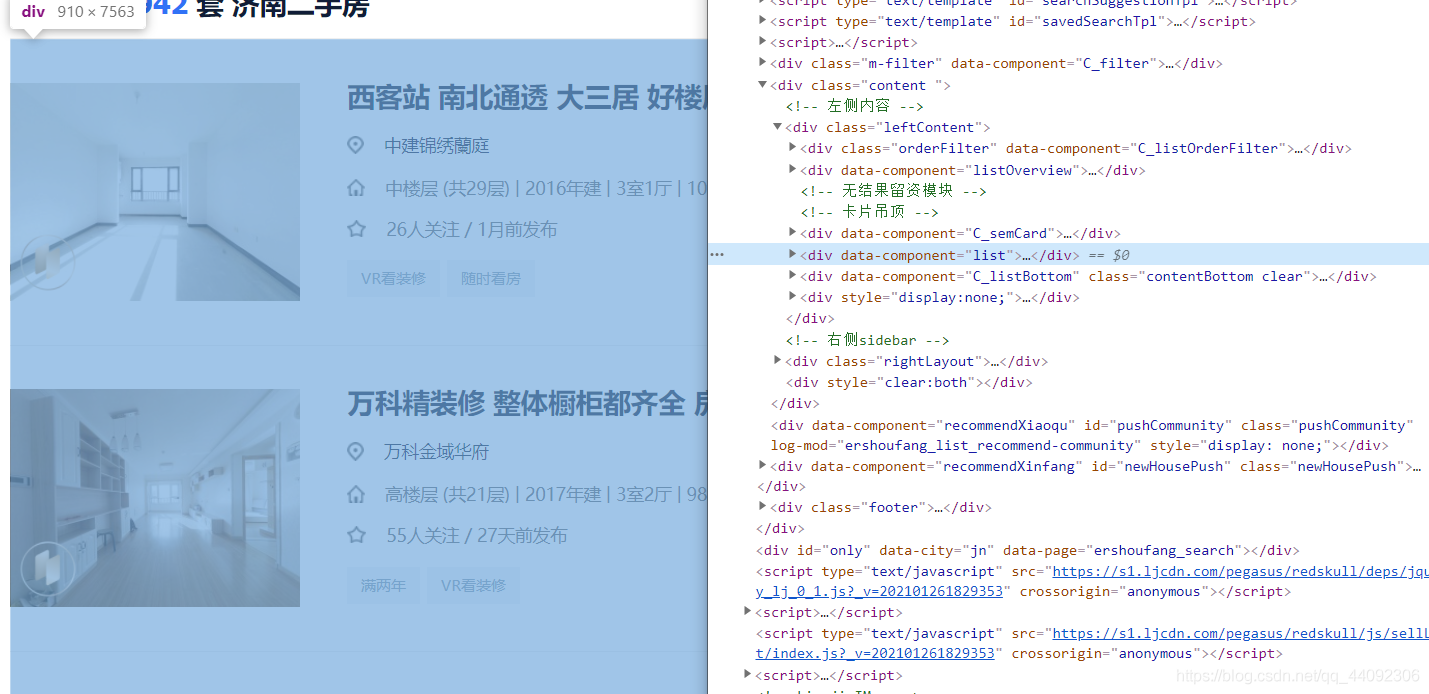
通过分析,房源列表项所在区域均在<div data-componet=‘‘list’’>标签中,通过浏览发现,还可以继续缩小区域 。最终,目标区域缩小到
5、开始爬取页面
5.1 模拟浏览器
因为大部分的网站都有反爬取机制,所以我们需要让程序去模拟浏览器,通过设置代理和请求头,以及时间间隔,这几种方法可以避免大多数的网站把我们的请求挂掉。
# 请求头
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0Win64x64) AppleWebKit / 537.36(XHTML, likeGecko) Chrome '
'/ 11.1.1111.111Safari / 111.11'
}
# 设置代理 http-协议类型 101.4.136.34-代理ip 82-代理端口
proxy = {
'http': 'http://101.4.136.34:82'}
r = requests.get(url, headers=headers, proxies=proxy)
r.encoding = 'gbk' #设置编码格式
context = r.text
# 第一个参数表示被解析的html内容,第二个参数表示使用的解析器
soup = BeautifulSoup(context, 'lxml')
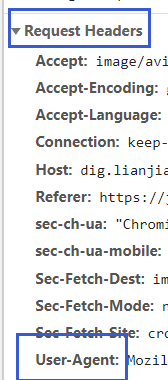
请求头通过需要F12查看

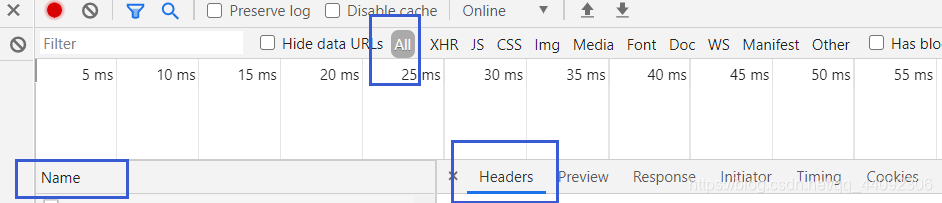
选择Name中的一项,查看Headers,找到如下内容复制到代码里面即可
soup即为我们解析后的HTML网页,大家可以试着print(soup)看看是什么。
就是一个对应URL的HTML文档
5.2 获取目标HTML区域中的数据
通过前面的步骤,我们将数据集范围区域缩小到了<div class=‘‘info clear’’>标签中。现在我们可以获取到里面的内容了。
- 获取一页中所有的<div class=‘‘info clear’’>项
info_clear_all = soup.find_all('div', _class='info clear')
- 遍历info_clear_all
- 在迭代器的遍历范围内找到目标数据所在区域
- 获取目标数据区域的具体内容
具体代码如下:
from webbrowser import Mozilla
from bs4 import BeautifulSoup
import requests
import lxml
import random
import time
url = 'https://jn.ke.com/ershoufang/'
def getSoup(Url):
# 设置请求头
headers = {
# headers中的内容为您浏览器的具体信息,请参考上述补充
}
# 设置代理 http-协议类型 101.4.136.34-代理ip 82-代理端口
proxy = {
'http': 'http://101.4.136.34:82'}
r = requests.get(Url, headers=headers, proxies=proxy)
# 获取网页的编码格式
encode = r.encoding
# 获取HTML网页
context = r.text
# 解析网页
soup = BeautifulSoup(context, 'lxml')
return soup
def getContext():
soup = getSoup(url)
# 获取<div class='info clear'></div>所有标签项
info_clear_all = soup.find_all('div', class_='info clear')
for a in info_clear_all:
# 获取标题
label_a_title = a.find('a', class_='VIEWDATA CLICKDATA maidian-detail') # 获取标题所在的a标签
title = label_a_title.attrs['title'] # 获取标题
print('标题:'+title)
# 获取楼盘名称
positionInfo = a.find('div', class_='positionInfo') # 缩小楼盘名称所在范围
label_a = positionInfo.find('a') # 获取<a>标签
building_name = label_a.text # 获取楼盘名称
print('楼盘名称:' + building_name)
# 获取楼盘简介
houseInfo = a.find('div', class_='houseInfo') # 获取简介所在的div范围
introduce = houseInfo.text.replace(' ', '').strip().replace('\n', '') # 获取简介
print('楼盘简介:'+introduce)
# 获取楼盘价格
totalPrice = a.find('div', class_='totalPrice') # 获取楼盘价格所在div范围
price = totalPrice.text # 获取楼盘价格
print('楼盘价格:'+price+'\n')
if __name__ == "__main__":
getContext()
运行结果
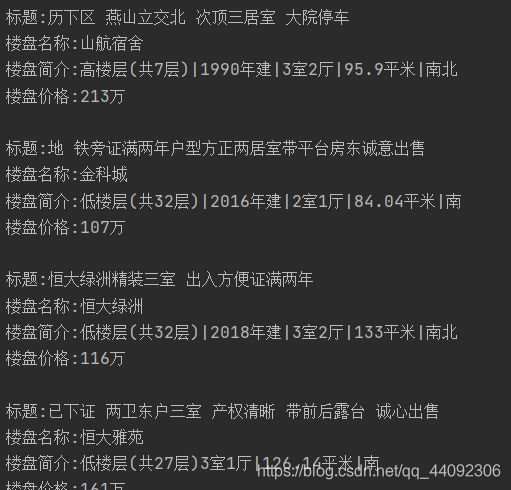
智能推荐
实体店小程序有哪些功能?_线下门店小程序功能-程序员宅基地
文章浏览阅读58次。综上所述,实体店做小程序需要考虑的功能有展示店铺信息、产品信息、关联公众号文章等。同时还可以添加在线客服、优惠活动、订单管理、用户评价等功能,提高用户购物体验和店铺的销售量。4. 用户评价:在小程序中设置用户评价功能,让用户对商品和服务进行评价,提高店铺的口碑。2. 产品信息:在小程序中展示店铺的产品信息,包括商品的图片、描述、价格等信息。可以通过分类和搜索功能,帮助用户快速找到心仪的商品。3. 关联公众号文章:如果实体店已经有了公众号,可以将公众号文章关联到小程序中,方便用户在小程序中阅读和分享。_线下门店小程序功能
1day漏洞包含POC-金和OA jc6 viewConTemplate.action存在FreeMarker模板注入漏洞-程序员宅基地
文章浏览阅读612次,点赞5次,收藏16次。金和JCS协同管理应用软件采用了精确管理模型的最新指导思路,充分融入现代企业的管理科学精髓,通过结合最新的信息化技术,从而更高效的帮助客户开展业务、管理企业,提高效率。JCS除了显著的“集团化应用”的特色外,还具有灵活易用的“信息门户应用”功能,可以根据个人需求,定制灵活的个性化工作台,全面体现了金和JCS以人为本、管理精确的理念。其接口存在命令执行漏洞,可能导致服务器被攻击者接管。
Linux学习——uboot入门_linux uboot-程序员宅基地
文章浏览阅读3.1k次,点赞4次,收藏34次。uboot是一个裸机程序,是一个,用于启动Linux 或者其他其他系统。uboot主要工作是初始化DDR,因为Linux是运行在DDR里的,Linux镜像(Zimage /ulmage)+设备树(.dtb)存放在SD、EMMC、NAND、SPI Flash等外置存储器中。Uboot需要将Linux镜像从外置Flash拷贝到DDR中,linux系统才能运行。_linux uboot
解决Windows中mfc110u.dll文件丢失问题-程序员宅基地
文章浏览阅读2.8k次。或者将文件复制到Windows系统目录,这个需要注意电脑的系统是32位还是64位,如果是32位的系统,那就将本站下载32位的dll文件放到“C:/Windows/System32”这个文件夹里面,如果是64位的系统,那就将本站下载的32位dll文件放到“C:/Windows/SysWOW64”这个文件夹里面,本站下载的64位文件放到“C:/Windows/System32”这个文件夹里面.二、扫描完成,扫描结果分成三部分,包括1,待修复的丢失文件。1、从下面列表下载mfc110u.dll文件。_mfc110u.dll
爬虫中常见的反爬手段和解决方法-程序员宅基地
文章浏览阅读9.6k次,点赞25次,收藏113次。了解反爬的三个方向 了解常见基于身份识别进行反爬 了解常见基于爬虫行为进行反爬 了解常见基于数据加密进行反爬一、反爬的三个方向基于身份识别进行反爬 基于爬虫行为进行反爬 基于数据加密进行反爬二、常见基于身份识别进行反爬1. 通过headers字段来反爬headers中有很多字段,这些字段都有可能会被对方服务器拿过来判断是否为爬虫1.1 通过headers中的user-agent字段进行反爬反爬原理:爬虫默认情况下没有user-agent,而是使用模块默认设置 解决.._反爬
基于TX2的全向四轮小车搭建(一)_搭载了tx2的无人车-程序员宅基地
文章浏览阅读1.6k次,点赞3次,收藏28次。全向四轮小车搭建(一) - 硬件清单全向四轮小车实物图小车硬件清单小车功能说明全向四轮小车实物图全向四轮小车是一类差分式自主移动小车,该小车基于Jetson TX2 作为主控板,以树莓派3b+作为从机控制电机转速,四个直流电机由两个电机驱动板驱动。这一系列介绍本人从零开始搭建该小车的过程,记录下该过程中走过的弯路和一些个人心得,作为学习记录。小车硬件清单名称数目单价Jetson TX2 主控板1¥3299树莓派3b+1¥499树莓派3电机扩展版1¥20_搭载了tx2的无人车
随便推点
SQL Server中怎么给表添加注释_sqlserver创建表添加备注-程序员宅基地
文章浏览阅读3.8k次。在 SQL Server 中,可以使用 sp_addextendedproperty 存储过程为表添加注释。此时,就添加完毕了。打开 SQL Server Management Studio,连接到相应的数据库。在“名称”列中输入“MS_Description”,在“值”列中输入表的注释。在“对象资源管理器”中,展开数据库,找到要添加注释的表。在“属性”窗口中,选择“扩展属性”选项卡。在“扩展属性”列表中,点击“添加”按钮。. 点击“确定”按钮保存注释。右键单击该表,选择“属性”。_sqlserver创建表添加备注
2016 ACM/ICPC亚洲区大连站-重现赛题解-程序员宅基地
文章浏览阅读319次。The 2016 ACM-ICPC Asia Dalian Regional Contest [Cloned]【A - Wrestling Match】【题目大意】有一个球队,队员有好坏之分,给你总人数n,m个对立关系,x个已知的好队员和y个已知的坏队员,问你能否将所有人分为两组,一组好一组坏【解题思路】二分图染色裸题【AC代码】#include <bits/stdc++.h&...
Ubuntu下搭建Redis主从集群_ubuntu22 redis 主从-程序员宅基地
文章浏览阅读870次。共包含三个节点,一个主节点,两个从节点。这里我们会在同一台虚拟机中开启3个redis实例,模拟主从集群,信息如下。_ubuntu22 redis 主从
quartus仿真文件的编写_reg eachvect-程序员宅基地
文章浏览阅读8k次,点赞5次,收藏56次。步骤与实现1.verilog代码写完之后,进行语法错误检查和全编译,编译成功之后,需要进行仿真文件的编写,在已有的模板上进行修改。(接上一篇如何获取仿真文件模板)2.修改主要是进行输入信号的赋值,仿真文件内容组成如下:(以按键点亮自己的led灯仿真文件代码编译为例看内容组成)3.二选一选择器就是,三个输入,一个输出,当选通信号为低电平,选择输入2=输出,当选通信号为高电平,选择输入1=输出。二选一选择器verilog代码如下:module choose(input wire [0:0] in__reg eachvect
编程环境和软件工具安装手册_服务器编程环境安装手册-程序员宅基地
文章浏览阅读160次。Linux 服务器软件安装_服务器编程环境安装手册
Python编写简单的学生管理系统_test_student.py-程序员宅基地
文章浏览阅读1w次,点赞9次,收藏47次。Python编写简单的学生管理系统一共两个文件,其中一个定义函数,另一个是主程序,调用函数,运行程序CMS.py'''编写“学生信息管理系统”,要求如下:必须使用自定义函数,完成对程序的模块化学生信息至少包含:姓名、年龄、学号,除此以外可以适当添加必须完成的功能:添加、删除、修改、查询、退出'''# 定义一个列表用来存储多个学生信息stuList = []# 定义系统..._test_student.py