UNIX环境高级编程_标准io创建空头文件-程序员宅基地
一、标准io操作
io操作是所有一切实现的基础,input and output
stdio:FILE 类型贯穿始终
fopen() //打开文件
fopen(3)
fopen - stream open functions
#include <stdio.h>
FILE *fopen(const char *path, const char *mode);
fopen() 函数将文件打开,通过这个函数我们可以告诉操作系统我们要操作的是哪个文件,以及用什么样的方式操作这个文件。
参数列表:
path:要操作的文件路径。
mode:文件的打开方式,这个打开方式一共分为6种。
r:以只读的方式打开文件,并且文件位置指针会被定位到文件首。如果要打开的文件不存在则报错。
r+:以读写的方式打开文件,并且文件位置指针会被定位到文件首。如果要打开的文件不存在则报错。
w:以只写的方式打开文件,如果文件不存在则创建,如果文件已存在则被截断为 0 字节,并且文件位置指针会被定位到文件首。
w+:以读写的方式打开文件,如果文件不存在则创建,如果文件已存在则被截断为 0 字节,并且文件位置指针会被定位到文件首。
a:以追加的方式打开文件,如果文件不存在则创建,且文件位置指针会被定位到文件最后一个有效字符的后面(EOF,end of the file)。
a+:以读和追加的方式打开文件,如果文件不存在则创建,且读文件位置指针会被初始化到文件首,但是总是写入到最后一个有效字符的后面(EOF,end of the file)。
返回值:
FILE 是一个由标准库定义的结构体,不要企图通过手动修改结构体里的内容来实现文件的操作,一定要通过标准库函数来操作文件。
这个函数返回一个 FILE 类型的指针,它作为我们打开文件的凭据,后面所有对这个文件的操作都需要使用这个指针,而且使用之后一定不要忘记调用 fclose(3) 函数释放资源。
如果该函数返回了一个指向 NULL 的指针,则表示文件打开失败了,可以通过 errno 获取到具体失败的原因。
fclose(3);//关闭文件
fclose - close a stream
#include <stdio.h>
int fclose(FILE *fp);
这个函数是与 fopen(3) 函数对应的,当我们使用完一个文件之后,需要调用 fclose(3) 函数释放相关的资源,否则会造成内存泄漏。当一个 FILE 指针被 fclose(3) 函数成功释放后,这个指针所指向的内容将不能再次被使用,如果需要再次打开文件还需要调用 fopen(3) 函数。
参数列表:
fp:fopen(3) 函数的返回值作为参数传入即可。
ulimit -a 查看打开文件的最大个数
创建文件默认权限
文件创建权限为 0666 & ~umask umask (unask存在就是限制文件权限问题)
error
它是标准 C 中定义的一个整形值,用来表示上次发生的错误。
通常系统调用会给我们我返回一个整形值来表示是否出现了错误,当出现了错误的时候会设置 errno,通过 errno 我们就可以得知出现了什么错误了。
标准库已经为我们准备好专门的转换函数了:perror(3) 和 strerror(3)
perror(3)
会自动读取 errno 帮我们转换成对应的文字描述,并且将它们输出到标准错误流中。它的参数是一个字符串,用来让我们自定义一些错误消息给用户看,它的输出格式就是 我们给传递的参数:errno 转换的描述文字。
strerror(3)
函数也会将 errno 转换为文字,不过它不会自动读取 errno 当前的值,需要我们把 errno 传递给它。它也不会帮我们输出到标准输出中,而是将转换完的字符串返回给我们。
如果大家是开发一个前台应用,一般可以使用 perror(3) 函数直接将错误输出给用户。
如果大家开发的是后台应用(如守护进程等),那么一般先使用 strerrno(3) 函数将 errno 转换为字符串,然后再把这个字符串传给日志系统记录下来。
大家在使用 errno 这个全局变量的时候要导入 errno.h 头文件:
#include <errno.h>
在使用 strerror(3) 函数时不要忘记导入 string.h 头文件,否则会报段错误!
fgetc
int fgetc(FILE *stream) 从指定的流 stream 获取下一个字符(一个无符号字符),并把位置标识符往前移动。
int fgetc(FILE *stream)
参数
stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要在上面执行操作的流。
返回值
该函数以无符号 char 强制转换为 int 的形式返回读取的字符,如果到达文件末尾或发生读错误,则返回 EOF。
fputc
int fputc(int char, FILE *stream)
参数
char -- 这是要被写入的字符。该字符以其对应的 int 值进行传递。
stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要被写入字符的流。
返回值
如果没有发生错误,则返回被写入的字符。如果发生错误,则返回 EOF,并设置错误标识符。
利用 fputc 和fgetc实现mycp例子
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
FILE *fps,*fpd;
char ch;
if (argc < 3)
{
fprintf(stderr,"Using:%s <src_file> <dis_file>\n",argv[0]);
exit(1);
}
fps = fopen(argv[1],"r");
if(fps == NULL)
{
perror("fopens()");
exit(1);
}
fpd = fopen(argv[2],"w");
if(fpd == NULL)
{
fclose(fps);
perror("fopend()");
exit(1);
}
while(1)
{
ch = fgetc(fps);
if(ch == EOF)
break;
fputc(ch, fpd);
}
fclose(fpd);
fclose(fps);
}
fgets(3)
#include <string.h>
```c
fgets - input of strings
#include <stdio.h>
int fgetc(FILE *stream);
char *fgets(char *s, int size, FILE *stream);
从输入流 stream 中读取一个字符串回填到 s 所指向的空间。
这里出现了一个 stream 的概念,这个 stream 是什么呢,它被成为“流”,其实就是操作系统对于可以像文件一样操作的东西的一种抽象。它并非像自然界的小河流水一样潺潺细流,而通常是要么没有数据,要么一下子来一坨数据。当然 stream 也未必一定就是文件,比如系统为每个进程默认打开的三个 stream:stdin、stdout、stderr,它们本身就不是文件,就是与文件有着相同的操作方式,所以同样被抽象成了“流”。
这个函数并没有解决 gets(3) 函数可能会导致的数组越界问题,而是通过牺牲了获取数据的正确性来保证程序不会出现数组越界的错误,实际上是掩盖了 gets(3) 的问题。
该函数遇到如下四种情况会返回:
1.当读入的数据量达到 size - 1 时;
2.当读取的字符遇到 \n 时;
3.当读取的字符遇到 EOF 时;
4.当读取遇到错误时;
并且它会在读取到的数据的最后面添加一个 \0 到 s 中。
返回值:
成功时返回 s。
返回 NULL 时表示出现了错误或者读到了 strem 的末尾(EOF)。
利用fgets实现一个mycpy功能
#include <stdio.h>
#include <stdlib.h>
#define BUFSIZE 1024
int main(int argc, char **argv)
{
FILE *fps,*fpd;
char buf[BUFSIZE];
if (argc < 3)
{
fprintf(stderr,"Using:%s <src_file> <dis_file>\n",argv[0]);
exit(1);
}
fps = fopen(argv[1],"r");
if(fps == NULL)
{
perror("fopens()");
exit(1);
}
fpd = fopen(argv[2],"w");
if(fpd == NULL)
{
fclose(fps);//当上一个文件打开失败时关闭该文件描述符防止内存泄漏
perror("fopend()");
exit(1);
}
while(fgets(buf,BUFSIZE,fps) != NULL)
{
fputs(buf, fpd);
}
fclose(fpd);
fclose(fps);
}
fread(3)、fwrite(3)
fread, fwrite - binary stream input/output
#include <stdio.h>
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);**
这两个函数使用得最频繁,用来读写 stream,通常是用来读写文件。
参数列表:
ptr:fread(3) 将从 stream 中读取出来的数据回填到 ptr 所指向的位置;fwrite(3) 则将从 ptr 所只想的位置读取数据写入到 stream 中;
size:要读取的每个对象所占用的字节数;
nmemb:要读取出多少个对象;
stream:数据来源或去向;
返回值:
注意这两个函数的返回值表示的是成功读(写)的对象的个数,而不是字节数!
例如:
read(buf, 1, 10, fp); // 读取 10 个对象,每个对象 1 个字节
read(buf, 10, 1, fp); // 读取 1 个对象,每个对象 10 个字节
当数据量充足的时候,这两种方式是没有区别的。
但是!!当数据量少于 size 个字节的整倍数时,第二种方法的的最后一个对象会读取失败。比如数据只有 45 个字节,那么第二种方法的返回值为 4,因为它只能成功读取 4 个对象。
所以通常第一种方式读写数据使用得比较普遍。
利用fread和fwrite实现mycp例子
#include <stdio.h>
#include <stdlib.h>
#define BUFSIZE 1024
int main(int argc, char **argv)
{
FILE *fps,*fpd;
char buf[BUFSIZE];
int n;
if (argc < 3)
{
fprintf(stderr,"Using:%s <src_file> <dis_file>\n",argv[0]);
exit(1);
}
fps = fopen(argv[1],"r");
if(fps == NULL)
{
perror("fopens()");
exit(1);
}
fpd = fopen(argv[2],"w");
if(fpd == NULL)
{
fclose(fps);
perror("fopend()");
exit(1);
}
//fread在读写文件的时候每次读取若干分字节,当文件字符不是该文件的整倍数就会导致读取文件有丢失。
while((n = fread(buf, 1, BUFSIZE,fps)) > 0)
{
fwrite(buf, 1, n, fpd);
}
fclose(fpd);
fclose(fps);
}
atoi(3)
atoi, atol, atoll, atoq - convert a string to an integer
#include <stdlib.h>
int atoi(const char *nptr);
long atol(const char *nptr);
long long atoll(const char *nptr);
long long atoq(const char *nptr);
atoi(3) 函数族
在这里提一下,主要是为了下面的 printf(3) 函数族做一个铺垫。
这些函数的作用是方便的将一个字符串形式的数字转换为对应的数字类型的数字。
上面这句话可能有点坳口,给你看个例子就懂了,下面是伪代码。
char *str = "123abc456";
int i = 0;
i = atoi(str);
i 的结果会变成 123。这些函数会转换一个字符串中地一个非有效数字前面的数字。如果很不幸这个字符串中的第一个字符就不是一个有效数字时,那么它们会返回 0。
printf(3)
printf, fprintf, sprintf, snprintf - formatted output conversion
#include <stdio.h>
int printf(const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
int sprintf(char *str, const char *format, ...);
int snprintf(char *str, size_t size, const char *format, ...);
printf(3) 函数大家一定不会陌生了,应该从写 Hello World! 的时候就接触到了的吧,所以我也不多介绍了,主要介绍两个内容。
一个是面试常考的一个问题,用了这么久的 printf(3) 函数,大家有没有注意过它的返回值表示什么呢?
printf(3) 的返回值表示成功打印的有效字符数量,不包括 \0。
另一个要说的就是刚才我们提到了 atoi(3) 函数族,它们负责将字符串转换为数字,那么有没有什么函数可以将数字转换为字符串呢,其实通过 sprintf(3) 或 snprintf(3) 就可以了。
有了这两个函数,不仅可以方便的将数字转换为字符串,还可以将多个字符串任意拼接为一个完整的字符串。
snprintf(3)
参数列表:
str:拼接之后的结果会回填到这个指针所指向的位置;
size:size - 1 为回填到 str 中的最大长度,数据超过这个长度的部分则会被舍弃,然后会在拼接的字符串的尾部追加 \0;
format:格式化字符串,用法与 printf(3) 相同,这里不再赘述;
…:格式化字符串的参数,用法与 printf(3) 相同;
这个函数与 fputs(3) 一样,只是掩盖了 sprintf(3) 可能会导致的数组越界问题,通过牺牲数据的正确性来保证程序不会出现数组越界的错误。
scanf(3)
scanf, fscanf, sscanf - input format conversion
#include <stdio.h>
int scanf(const char *format, ...);
int fscanf(FILE *stream, const char *format, ...);
int sscanf(const char *str, const char *format, ...);
scanf(3) 函数族相信也不用过多的介绍了,这里唯一要强调的就是:scanf(3) 函数支持多种格式化参数,唯独 %s 是不能安全使用的,可能会导致数组越界,所以当需要接收用户输入的时候可以使用 fgets(3) 等函数来替代。
fseek(3)
fgetpos, fseek, fsetpos, ftell, rewind - reposition a stream
#include <stdio.h>
int fseek(FILE *stream, long offset, int whence);
long ftell(FILE *stream);
void rewind(FILE *stream);
fseek(3) 函数族的函数用来控制和获取文件位置指针所在的位置,从而能够使我们灵活的读写文件。
介绍一下 fseek(3) 函数的参数列表:
stream:这个已经不需要多介绍了吧,就是准备修改文件位置指针的文件流;
offset:基于 whence 参数的偏移量;
whence:相对于文件的哪里;有三个宏定义可以作为它的参数:SEEK_SET(文件首), SEEK_CUR(当前位置), or SEEK_END(文件尾);
返回值:
成功返回 0;失败返回 -1,并且会设置 errno。
单独看参数列表也许你还有所疑惑,那么我写点简单的伪代码作为例子:
fseek(fp, -10, SEEK_CUR); // 从当前位置向前偏移10个字节。
fseek(fp, 2GB, SEEK_SET); // 可以制造一个空洞文件,如迅雷刚开始下载时产生的文件。
ftell(3) 函数以字节为单位获得文件指针的位置。
fseek(fp, 0, SEEK_END) + ftell(3) 可以计算出文件总字节大小。
还有一个值得大家注意的问题:
fseek(3) 和 ftell(3) 的参数和返回值使用了 long,所以取值范围为 -2GB ~ (2GB-1),而 ftell(3) 只能表示 2G-1 之内的文件大小,所以可以使用 fseeko(3) 和 ftello(3) 函数替代它们,但它们只是方言(SUSv2, POSIX.1-2001.)。
由于这两个函数比较古老,所以设计的时候认为 ±2GB 的取值范围已经足够用了,而没有意识到科技发展如此迅速的今天,2GB 大小的文件已经完全不能满足实际的需求了。
根据fseek 和ftell计算一个文件的大小
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
FILE *fp;
if(argc < 2)
{
fprintf(stderr,"Using....\n");
exit(1);
}
fp = fopen(argv[1], "r");
if(fp == NULL)
{
perror("fopen()");
exit(1);
}
fseek(fp,0,SEEK_END);
printf("%ld\n", ftell(fp));//根据文件位置指针计算文件大小
exit(0);
}
rewind(3) 函数将文件位置指针移动到文件起始位置,相当于:
1 (void) fseek(stream, 0L, SEEK_SET)
getline(3)
getline - delimited string input
#include <stdio.h>
ssize_t getline(char **lineptr, size_t *n, FILE *stream);
Feature Test Macro Requirements for glibc (see feature_test_macros(7)):
getline():
Since glibc 2.10:
_POSIX_C_SOURCE >= 200809L || _XOPEN_SOURCE >= 700
Before glibc 2.10:
_GNU_SOURCE
这个函数是一个非常好用的函数,它能帮助我们一次获取一行数据,而无论这个数据有多长。
参数列表:
lineptr:一个一级指针的地址,它会将读取到的数据填写到一级指针指向的位置,并将>该位置回填到该参数中。指针初始必须置为NULL,该函数会根据指针是否为 NULL 来决定是否需要分配新的内存。
n:是由该函数回填的申请的内存缓冲区的总大小,长度初始必须置为0。
虽然很好用,该函数仅支持 GNU 标准,所以是方言,大家还是自己封装一个备用吧。
另外,想要使用这个函数必须在编译的时候指定 -D_GNU_SOURCE 参数:
$> gcc -D_GNU_SOURCE
当然如果不想在编译的时候添加参数,也可以在引用头文件之前 #define _GNU_SOURCE。
还有一个办法,是在 makefile 中配置 CFLAGS += -D_GNU_SOURCE,这样即省去了编译时手动写参数的麻烦。
利用getline读取文件的每一行例子
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char **argv)
{
char *linebuf;
size_t linesize;
FILE *fp;
int count;
if(argc < 2)
{
fprintf(stderr,"Usage.....\n");
exit(1);
}
fp = fopen(argv[1], "r");
if(fp == NULL)
{
perror("fopen_argv[1]");
exit(1);
}
linebuf = NULL;
linesize = 0;
while(1)
{
if(getline(&linebuf, &linesize, fp) < 0)
break;
printf("%s\n",linebuf);
printf("%d\n",strlen(linebuf));
//printf("%d\n",linesize);
}
fclose(fp);
exit(0);
}
fflush(3)
fflush - flush a stream
#include <stdio.h>
int fflush(FILE *stream);
fflush(3) 函数的作用是刷新缓冲区,提到这个函数就要讲讲缓冲区了。
Linux 系统中有三种缓冲形式:无缓冲、行缓冲和全缓冲。
无缓冲:需要立刻输出时使用,例如 stderr;
行缓冲:遇到换行符时进行刷新、缓冲区满了的时候刷新、强制刷新(fflush(3));而标准输出(stdout)是行缓冲,因为涉及到终端设备;
全缓冲:只有缓冲区满了的时候和强制刷新(fflush(3))时才会刷新,这是 Linux 默认的缓冲模式,但终端设备除外,终端设备使用行缓冲模式;
当数据被放入缓冲区的时候是不会通过系统调用(read(3)、write(3))送到内核中的,只有缓冲区被刷新的时候数据才会通过系统调用进入内核。而刷新缓冲区就是 fflush(3) 函数的作用。
fflush(3) 的参数是具体要刷新的流,当参数为 NULL 时会刷新所有的输出流。
修改缓冲区模式: setvbuf
二、文件IO
文件描述符的概念
(实质是一个整形数,文件描述符优先使用可用范围内最小的)
文件IO操作:
fileno(3)
#include <stdio.h>
int fileno(FILE *stream);
Feature Test Macro Requirements for glibc (see feature_test_macros(7)):
fileno(): _POSIX_C_SOURCE >= 1 || _XOPEN_SOURCE || _POSIX_SOURCE
这个函数的作用是从 STDIO 的 FILE 结构体指针中获得 SYSIO 的文件描述符。
fdopen(3)
#include <stdio.h>
FILE *fdopen(int fd, const char *mode);
Feature Test Macro Requirements for glibc (see feature_test_macros(7)):
fdopen(): _POSIX_C_SOURCE >= 1 || _XOPEN_SOURCE || _POSIX_SOURCE
这个函数和上面的 flieno(3) 函数的功能是反过来的,作用是把 SYSIO 的文件描述符转换为 STDIO 的 FILE 结构体指针。mode 参数的作用与 fopen(3) 中的 mode 参数相同,这里不再赘述。
虽然这两个函数可以在 STDIO 与 SYSIO 之间互相转换,但是并不推荐对同一个文件同时采用两种方式操作。因为 STDIO 和 SYSIO 之间它们处理文件的私有数据是不同步的,如果同时使用两种方式操作同一个文件则可能带来不可预知的后果,
open(2)
open - open and possibly create a file or device
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
想要使用 SYSIO 操作文件或设备,要先通过 open(2) 函数获得一个文件描述符。注意博文中在函数上方标识出来的头文件,大家在使用这个函数的时候一定要一个不少的全部包含到源代码中。
-
参数列表:
pathname:要打开的文件路径。
flags:指定文件的操作方式,多个选项之间用按位或( | )运算符链接。
必选项,三选一:O_RDONLY, O_WRONLY, O_RDWR
可选项:可选项有很多,这里只介绍常用的,想要查看完全的可选项,可以查阅 man 手
册。
| 选项 | 说明 |
|---|---|
| O_APPEND | 追加到文件尾部。 |
| O_CREAT | 创建新文件。 |
| O_DIRECT | 最小化缓冲。关于缓冲区的解释:buffer 是写操作的加速机制,cache 是读操作的加速机制。 |
| O_DIRECTORY | 强调一定要打开一个目录,如果 pathname 不是目录则会打开失败。 |
| O_LARGEFILE | 打开大文件的时候要加这个,会将 off_t 定义为 64 bit.。 |
| O_NOFOLLOW | 如果 pathname 是符号链接则不展开,也就是说打开的是符号链接文件本身,而不是符号链接指向的文件。 |
| O_NONBLOCK | 非阻塞形式。阻塞是读取不到数据时死等,非阻塞是尝试读取,无论能否读取到数据都返回。 |
| O_TRUNC | 将已存在的普通文件长度截断为0(也就是将文件内容清空)。 |
mode:8 进制文件权限。当 flags 包含 O_CREAT 选项时必须传这个参数,否则可以不用传这个参数。当然系统在创建文件的时候不会直接这个参数,而是通过如下的公式计算得到最终的文件权限:
mode & ~(umask)
具体的 umask 的值可以通过 umask(1) 命令获得。通过这样的公式进行计算可以避免程序中创建出权限过高的文件。
close(2)
close - close a file descriptor
#include <unistd.h>
int close(int fd);
关闭文件描述符。
参数是要关闭的文件描述符。注意当一个文件描述符被关闭之后就不能再使用了,虽然 fd 这个变量的值没有变,但是内核已经将相关的资源释放了,这个 fd 相当于一个野指针了。
返回值:
成功为0,失败为-1。但很少对它的返回值做校验,一般都认为不会失败。
read(2)
read - read from a file descriptor
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
这是 SYSIO 读取文件的函数,作用是从文件描述符 fd 中读取 count 个字节的数据到 buf 所指向的空间。
返回值:返回成功读取到的字节数;0 表示读取到了文件末尾;-1 表示出现错误并设置 errno。
注意 read(2) 函数与 STDIO 中的 fread(3) 函数的返回值是有区别的,fread(3) 返回的是成功读取到了多少个对象,而 read(2) 函数返回的是成功读取到的字节数量。
write(2)
write - write to a file descriptor
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
write(2) 是 SYSIO 向文件中写入数据的函数,作用是将 buf 中 count 字节的数据写入到文件描述符 fd 所对应的文件中。
返回值:返回成功写入的字节数;0 并不表示写入失败,仅仅表示什么都没有写入;-1 才表示出现错误并设置 errno。
注意 write(2) 函数与 STDIO 中的 fwrite(3) 函数的返回值是有区别的,fwrite(3) 返回的是成功写入了多少个对象,而 write(2) 函数返回的是成功写入的字节数量。
利用文件IO read、write实现mycpy例子
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define BUFSIZE 1024
/**
* r -> O_RDONLY
* r+ -> O_RDWR
* w -> O_WRONLY|O_CREAT|O_TUNC
* w+ -> O_RDWR|O_TRUNC|O_CREAT
*
*/
int main(int argc, char **argv)
{
int sfd, dfd;
char buf[BUFSIZE];
int len, ret;
int pos;
if (argc < 3)
{
fprintf(stderr, "Usage....\n");
exit(1);
}
sfd = open(argv[1], O_RDONLY);
if (sfd < 0)
{
perror("open_sfd()");
exit(1);
}
dfd = open(argv[2], O_WRONLY | O_CREAT, O_TRUNC, 0600);
if (sfd < 0)
{
close(sfd);
perror("open_dfd()");
exit(1);
}
while (1)
{
len = read(sfd, buf, BUFSIZE);
if (len < 0)
{
perror("read()");
break;
}
if (len == 0) //读完数据
break;
pos = 0;
while (len > 0) // 读到的字节个数
{
ret = write(dfd, buf + pos, len);
if (ret < 0)
{
perror("write()");
exit(1);
}
pos += ret;
len -= ret;
}
}
close(dfd);
close(sfd);
exit(0);
}
lseek(2)
lseek - reposition read/write file offset
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
它是系统为了方便我们读写文件而设定的一个标记,随着我们通过函数对文件的读写,它会自动相应的向文件尾部偏移。
-
参数列表:
fd:要操作的文件描述符;
offset:相对于 whence 的偏移量;
whence:相对位置;三选一:SEEK_SET、SEEK_CUR、SEEK_END
SEEK_SET 表示文件的起始位置;
SEEK_CUR 表示文件位置指针当前所在位置;
SEEK_END 表示文件末尾;
返回值:
成功时返回文件首相对于移动结束之后的文件位置指针所在位置的偏移量;失败时返回 -1 并设置 errno;
这个函数的 offset 参数和返回值都对基本数据类型进行了封装,这一点要比标准库的 fseek(3) 更先进。
写一段伪代码来说明这个函数的使用方法。
lseek(fd, -1024, SEEK_CUR); // 从文件位置指针当前位置向前偏移 1024 个字节
lseek(fd, 1024, SEEK_SET); // 从文件起始位置向后偏移 1kb
lseek(fd, 1024UL*1024UL*1024UL*5UL, SEEK_SET); // 产生一个 5GB 大小的空洞文件
利用lseek实现提个5G空洞文件的例子
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(int argc, char **argv)
{
int fd;
if(argc < 2)
{
fprintf(stderr, "Usage....\n");
exit(1);
}
fd = open(argv[1],O_WRONLY|O_CREAT|O_TRUNC,0600);
if(fd < 0)
{
perror("open() argv[1]");
exit(1);
}
lseek(fd, 5LL*1024LL*1024LL*1024LL-1LL,SEEK_SET);
write(fd,"",1);
close(fd);
exit(0);
}
time(1)
time(1) 命令的作用是监视一个程序的用户时间,从而可以粗略的帮助我们分析这个程序的执行效率
这是一块cp命令将/etc/services /tmp/out文件中所用的时间。
[root@VM-0-7-centos 02SYSIO]# time /bin/cp /etc/services /tmp/out
real 0m0.002s
user 0m0.000s
sys 0m0.002s
sys 是程序在内核态消耗的时间,也就是执行系统调用所消耗的时间。
user 是程序在用户态消耗的时间,也就是程序本身的代码所消耗的时间。
real 是用户等待的总时间,是 sys + user + CPU 调度时间,所以 real 时间会稍微比 sys + user 时间长一点。一个程序从提高响应素的的方式提高用户体验,一般指的就是提高 real 时间
原子操作
通俗来讲,原子操作就是将多个动作一气呵成的做完,中间不会被打断,要么执行完所有的步骤,要么一步也不会执行。这里用创建临时文件来举个栗子。
tmpnam, tmpnam_r - create a name for a temporary file
#include <stdio.h>
char *tmpnam(char *s);
如果我们需要创建一个临时文件,那么首先需要又操作系统提供一个文件名,然后再创建这个文件。
tmpnam(3)
函数就是用来获得临时文件的文件名的。为什么要通过这个函数由操作系统来为我们生成文件名呢?就是因为系统中进程比较多,临时文件也比较多,怕文件重名嘛。
但是这个函数只负责生成一个目前系统中不存在的临时文件名,并不负责创建一个文件,所以创建文件的任务要由我们自己使用 fopen(3) 或 open(2) 等手段创建。
假设在我们拿到这个文件名的时候,临时文件还没有在磁盘上真正创建,另一个进程拿到了一个与我们相同的文件名,那么这个时候再创建文件就是有问题的了。
这就是因为获得文件名与创建文件这个动作不原子造成的,如果获得唯一的文件名和创建文件这个动作一气呵成中间不会被打断,则这个问题就不会发生,我们创建好文件之后另一个进程就再也拿不到相同的文件名了。
dup(2)、dup2(2)
dup, dup2 - duplicate a file descriptor
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd, int newfd);
这两个函数是用来复制文件描述符的,就是 图1 中 文件描述符 3 和 6 指向了同一个文件表项的情况。
用 dup(2) 实现输出的重定向。
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
int main (void)
{
int fd = -1;
fd = open("tmp", O_WRONLY | O_CREAT | O_TRUNC, 0664);
/* if error */
#if 0
close(1); // 关闭标准输出
dup(fd);
#endif
dup2(fd, 1);
close(fd);
/* 要求在不改变下面的内容的情况下,使输出的内容到文件中 */
puts("dup test.");
return 0;
}
}
puts(3) 函数是将参数字符串写入到标准输出 stdout(文件描述符是 1) 中,而标准输出默认目标是我们的 shell。如果想要让 puts(3) 的参数输出到一个文件中,实现思路是:首先打开一个文件获得一个新的文件描述符,然后关闭标准输出文件描述符(1),然后使用 dup(2) 函数族复制产生一个新的文件描述符,此时的 1 号文件描述符就不是标准输出的文件描述符了,而是我们自己创建的文件的描述符了。还记得我们之前提到过吗,文件描述符优先使用可用范围内最小的。进程中当前打开的文件描述符有标准输入(0)、标准输出(1)、标准错误(2)和我们自己打开的文件(3),当我们关闭了 1 号文件描述符后,当前可用的最小文件描述符是 1,所以新复制的文件描述符就是 1。而标准库函数 puts(3) 在调用系统调用 write(2) 函数向 1 号文件描述符打印时,正好是打印到了我们所指定的文件中。
由于题目的要求是 puts(3) 上面注释以下的内容都不能修改,原则上 1 号文件描述符在这里使用完毕也需要 close(2),所以这里造成了一个内存泄漏,但并不影响对 dum(2) 函数族的解释和测试。
上面的代码用 close(2) + dup(2) 的方式或者 dup2(2) 的方式都可以实现。
dup(2) 和 dup2(2) 的作用是相同的,区别是 dum2(2) 函数可以用第二个参数指定新的文件描述符的编号。
如果新的文件描述符已经被打开则先关闭它再重新打开。
如果两个参数相同,则 dup2(2) 函数会返回原来的文件描述符,而不会关闭它。
另外一点比较重要,close(2) + dup(2) 的方式不原子,而 dup2(2) 这两步动作是原子的,在并发的情况下可能会出现问题。
**sync(2)**同步磁盘映射
sync, syncfs - commit buffer cache to disk
#include <unistd.h>
void sync(void);
sync(2) 函数族的函数作用是全局催促,将 buffer 和 cache 刷新和同步到 disk,一般在设备即将卸载的时候使用。
fcntl(2)
fcntl - manipulate file descriptor
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */ );
这是一个管家级别的函数,根据不同的 cmd 和 arg 读取或修改对已经打开的文件的操作方式。
ioctl(2)
ioctl - control device
#include <sys/ioctl.h>
int ioctl(int d, int request, ...);
Linux 的一切皆文件的设计原理将所有的设备都抽象为一个文件,当一个设备的某些操作不能被抽象成打开、关闭、读写、跳过等动作时,其它的动作都通过 ioctl(2) 函数控制。
例如将声卡设备抽象为一个文件,录制音频和播放音频的动作则可以被抽象为对声卡文件的读、写操作。但是像配置频率、音色等功能无法被抽象为对文件的操作形式,那么就需要通过 ioctl(2) 函数对声卡设备进行控制,具体的控制命令则由驱动程序提供。
fsync 同步一个文件的data
fdatasync只刷数据不刷亚数据(亚数据是指文件的修改时间,文件的属性)
fsync, fdatasync - synchronize a file's in-core state with storage device
SYNOPSIS
#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
/dev/fd
/dev/fd 是一个虚拟目录,它里面是当前进程所使用的文件描述符信息。如果用 ls(1) 查看,则里面显示的是 ls(1) 这个进程所使用的文件描述符信息。而打开里面的文件则相当于复制文件描述符。
文件IO与标准IO的区别
类型 可移植性 实时性 吞吐量 功能
STDIO 高 低 高 受限
SYSIO 低 高 低 自由
这里我一个一个的解释表格中的每一项,表格中的每一项都是两者之间相对而言,使用哪种 IO 并没有绝对的好坏之分,要根据实际的需求来决定应该使用哪个。
可移植性:
标准 IO 是 C89 支持的函数,所以使用了标准 IO 的程序无论在 Linux 平台还是换成了 Windows 平台,不用修改代码是可以直接编译运行的。
而系统 IO 是由内核直接提供的函数库实现的,不同的操作系统平台上提供的 IO 操作接口是不同的,所以想要移植使用了系统 IO 的程序,必须按照目标平台的 IO 库修改程序并重新调试。
所以你写的程序将来可能在不同的平台上运行,那么最好使用标准 IO 库;如果你的程序是专门针对于某个平台而开发的,那么使用系统 IO 库能够得到我们下面说的其它优势。
三、文件系统
stat(2)
stat, fstat, lstat - get file status
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *path, struct stat *buf);
int fstat(int fd, struct stat *buf);
int lstat(const char *path, struct stat *buf);
stat(2) 函数族是专门用来获取文件的亚数据信息的。系统中 stat(1) 命令就是利用这个函数实现的。
下面介绍下 struct stat 的字段含义:
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* inode 号 */
mode_t st_mode; /* 权限和文件类型,位图,权限位9位,类型3位,u+s 1位,g+s 1位,粘滞位(T位)1位。
位图是用一位或几位数据表示某种状态。许多要解决看似不可能的问题的面试题往往需要从位图着手。*/
nlink_t st_nlink; /* 硬链接数量 */
uid_t st_uid; /* 文件属主 ID */
gid_t st_gid; /* 文件属组 ID */
dev_t st_rdev; /* 设备号,只有设备文件才有 */
off_t st_size; /* 总大小字节数,编译时需要指定宏 -D_FILE_OFFSET_BITS=64,否则读取大文件可能导致溢出 */
blksize_t st_blksize; /* 文件系统块大小 */
blkcnt_t st_blocks; /* 每个 block 占用 512B,则整个文件占用的 block 数量。这个值是文件真正意义上所占用的磁盘空间 */
// 下面三个成员都是大整数,实际使用时需要先转换
time_t st_atime; /* 文件最后访问时间戳 */
time_t st_mtime; /* 文件最后修改时间戳 */
time_t st_ctime; /* 文件亚数据最后修改时间戳 */
}
在 Linux 系统中,一个文件实际占用了多大的磁盘空间要看 st_blocks 的数量,而不是看 st_size 的大小。
一般情况下文件系统的一个 block 的大小为 4KB,而每个 st_blocks 是 512B,所以一个有效文件占用磁盘空间最小的大小为 8 个 st_blocks。
它们会根据文件的路径(path)或是已打开的文件的文件描述符(fd)得到该文件的亚数据,并将他们回填到 struct stat 类型的结构体中供调用者使用
文件类型
通过 struct stat 结构体的 st_mode 成员可以获得文件类型信息。
st_mode 是使用位图的形式来保存文件的类型和权限信息的。
Linux 系统中的文件共分为 7 种类型:dcb-lsp
S_IFMT 0170000 bit mask for the file type bit fields 从 st_mode 中提取出文件类型位,其它位清零
S_IFSOCK 0140000 socket 套接字文件
S_IFLNK 0120000 symbolic link 符号链接文件
S_IFREG 0100000 regular file 普通文件
S_IFBLK 0060000 block device 块设备文件
S_IFDIR 0040000 directory 目录
S_IFCHR 0020000 character device 字符设备
S_IFIFO 0010000 FIFO 管道文件
根据stat结构体读取文件类型的例子
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
static int ftype(const char *fname)
{
struct stat startres;
if (stat(fname, &startres) < 0)
{
perror("stat()");
exit(1);
}
if (S_ISREG(startres.st_mode))
return '-'; // 普通文件
else if (S_ISDIR(startres.st_mode))
return 'd'; // 目录文件
else if (S_ISCHR(startres.st_mode))
return 'c'; // 字符设备文件
else if (S_ISBLK(startres.st_mode))
return 'b'; // 块设备文件
else if (S_ISFIFO(startres.st_mode))
return 'p'; // 管道文件
else if (S_ISLNK(startres.st_mode))
return 'l'; // 符号链接文件
else if (S_ISSOCK(startres.st_mode))
return 's'; // 套接字文件
else
return '?';
}
int main(int argc, char **argv)
{
int fd;
if (argc < 2)
{
fprintf(stderr, "Usage....\n");
exit(1);
}
printf("%c\n", ftype(argv[1]));
exit(0);
}
文件的访问权限
st_mode是一个16位的位图,用于表示文件类型,文件访问权限,及特殊权限位,文件访问权限就是 st_mode 位图中的低 9 位。
大家都知道,在 Linux 系统中文件的权限分为 3 个组:文件属主权限、文件属组权限、其它用户权限,而每个组又分为 4 种权限:读取、写入(w)、执行(x)、无权(-)。
所以在使用 ls(1) -l 命令时可以得到类似 -rwx-r-xr-x 的权限标志,这个标志就是这样来的。
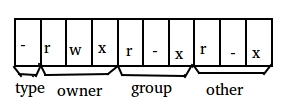
umask
作用:防止产生权限过松的文件
umask - set file mode creation mask
#include <sys/types.h>
#include <sys/stat.h>
mode_t umask(mode_t mask);
用于设定进程文件模式的掩码(又称屏蔽字),并返回之前的值。umask 值越大,权限越低。umask(1) 命令就是用这个函数封装的。
参数 mask 由以下位构成,使用按位或运算符指定多个模式:
| st_mode 屏蔽 | 含义 |
|---|---|
| S_IRUSR | 属主读 |
| S_IWUSR | 属主写 |
| S_IXUSR | 属主执行 |
| S_IRGRP | 属组读 |
| S_IWGRP | 属组写 |
| S_IXGRP | 属组执行 |
| S_IROTH | 其他读 |
| S_IWOTH | 其他写 |
| S_IXOTH | 其他执行 |
st_mode 掩码
access(2)
access - check real user's permissions for a file
#include <unistd.h>
int access(const char *pathname, int mode);
测试当前进程对 pathname 文件是否具有 mode 权限,成功返回 0,失败返回 -1 并设置具体的 errno。
如果 pathname 是符号链接,则不会展开,而是测试符号链接文件本身。
mode 可以选择:
F_OK:检测文件是否存在;
R_OK:检测是否具有读权限;
W_OK:检测是否具有写权限;
X_OK:检测是否具有执行权限;
chmod(2)
chmod, fchmod - change permissions of a file
#include <sys/stat.h>
int chmod(const char *path, mode_t mode);
int fchmod(int fd, mode_t mode);
chmod(2) 函数族的函数用于更改现有文件的访问权限。看到这两个文件的命名方式是不是觉得似曾相识?没错,上面我们讲 stat(2) 系统调用的时候就说过这种命名约定,fun()、ffun()、lfun()等等见名知义,系统中还有很多函数都是遵循这样的约定的。
chmod(1) 命令就是使用 chmod(2) 函数族封装的,mode 参数位图与 表1 中的掩码是一致的,另外还支持 S_ISUID (U+S)、S_ISGID (G+S) 和 S_ISVTX (T位)。多个位使用按位或的方式进行计算再传参
truncate(2)
truncate, ftruncate - truncate a file to a specified length
#include <unistd.h>
#include <sys/types.h>
int truncate(const char *path, off_t length);
int ftruncate(int fd, off_t length);
truncate(2) 函数族的文件用于截断 path 所指定的文件到 length 个字节。
如果想要清空一个文件,可以在 open(2) 的时候指定 flags 为 O_TRUNC。
如果 length 参数小于文件之前的长度,则 length 个字节后面的数据将被丢弃。
如果 length 参数大于文件之前的长度,则在文件末尾用 ‘\0’ 填充,使文件达到 length 指定的长度,也就是在文件的尾部创建了一个空洞。
硬链接,符号链接
. ln 产生硬链接。
ln -s 产生符号链接,s 是 symbol,不是 soft,所以不是软链接而是符号链接。
硬链接和符号链接有什么区别
硬链接的 inode 号没有改变,inode 号是文件的唯一标识。所以创建硬链接没有产生新文件,硬链接就是目录项的同义词,实际上就是在当前的目录项上多写了一条记录。
硬链接不能跨分区,不能为目录文件建立硬链接。
符号链接产生了新的 inode 号,说明产生了新的文件,但并不分配磁盘块(block)。
符号链接可以跨分区,可以为目录文件建立符号链接。
link(2)、unlink(2) 函数用于创建和删除符号链接。
remove(2)
相当于 rm(1) 命令,它是使用 unlink(2) 、rmdir(2) 函数封装的。它在删除文件的时候其实并没有立即将文件的数据块从磁盘上移除,而是在被删除的文件没有任何进程引用的时候才将它的数据块释放。
rename(2)
rename - change the name or location of a file
#include <stdio.h>
int rename(const char *oldpath, const char *newpath);
rename(2) 函数用于重命名文件或目录。
utime(2)
utime - change file last access and modification times
#include <sys/types.h>
#include <utime.h>
int utime(const char *filename, const struct utimbuf *times);
utime(2) 函数用于修改文件的最后访问时间戳和最后修改时间戳。
mkdir(2)、rmdir(2)
mkdir - create a directory
#include <sys/stat.h>
#include <sys/types.h>
int mkdir(const char *pathname, mode_t mode);
rmdir - delete a directory
#include <unistd.h>
int rmdir(const char *pathname);
与 mkdir(1) 和 rmdir(1) 命令一样,用于创建和删除目录。但是 rmdir(2) 只能删除空白目录,如果想要删除非空目录需要自行递归实现。
chdir(2)
chdir, fchdir - change working directory
#include <unistd.h>
int chdir(const char *path);
int fchdir(int fd);
getcwd(3)
getcwd - get current working directory
#include <unistd.h>
char *getcwd(char *buf, size_t size);
用于获取进程当前工作路径的绝对路径,pwd(1) 命令是用该函数封装的。
用于改变进程的工作目录,参数 path 和 fd 表示要修改到的目标目录。cd(1) 命令就是用这个函数封装的。这个函数在后面我们讲守护进程的时候会再次用到。
读目录
所谓读目录其实是读取出目录中的文件列表,对目录的访问分为两种方式:glob(3) 和 xxxxdir(3) 函数族。
我们先来说说使用 glob(3) 的方式访问目录。
glob, globfree - find pathnames matching a pattern, free memory from glob()
#include <glob.h>
int glob(const char *pattern, int flags,
int (*errfunc) (const char *epath, int eerrno),
glob_t *pglob);
void globfree(glob_t *pglob);
glob(3) 函数参数列表
pattern:匹配文件路径的表达式,可以是通配符。比如输入 “/home/*”,glob(3) 函数会解析到 /home/ 目录下所有的文件列表。
flags:特殊要求。
很多函数都支持特殊要求的设置,在遇到可以设定特殊要求的函数时,如果没有特殊要求,如果它是一个位图就传入0,如果它是一个指针就传入 NULL。
glob(3) 函数有很多特殊要求,常用的只有以下几个:
| GLOB_NOSORT: | 不排序,解析到哪个就是哪个。默认是排序的,使用这个选项可以提高效率。 |
|---|---|
| GLOB_APPEND: | 将多次调用 glob(3) 解析到的结果追加到一起。但是第一次调用的时候不能传入这个参数,否则会导致 glob(3) 动态内存分配失败。 |
| – | – |
| GLOB_NOCHECK: | 不检查是否匹配到文件,与 GLOB_APPEND 参数一同使用时,可以把 pglob 参数看作是一个像 argv 一样的可变长数组,可以存储任何字符串。 |
| errfunc: | 当 glob(3) 函数出错的时候的回调函数,如果不需要异常处理可以传入 NULL。 |
| pglob: | 将解析的结果回填到这个参数中。 |
typedef struct {
size_t gl_pathc; /* Count of paths matched so far */
char **gl_pathv; /* List of matched pathnames. */
size_t gl_offs; /* Slots to reserve in gl_pathv. */
} glob_t;
大家看 gl_pathc 和 gl_pathv 有木有觉得眼熟?是不是跟 argc 和 argv 很像?其实它们的用法和很相似。
gl_pathv 中存放的是根据 pattern 参数解析出来的所有文件列表的路径,而 gl_pathc 就是 gl_pathv 的数量。
一个目录中存放的文件的数量是不确定的,所以 gl_pathv 中的成员数量一定也是不确定的,那么它一定用到了 malloc(3) 函数族使用动态内存来保存解析出来的数据。根据“谁申请,谁释放”的原则, glob(3) 还提供了一个释放它所申请的资源的函数:
globfree(3)。
globfree(3) 函数的使用就很明了了,将 glob(3) 函数产生在 pglob 参数中所申请的内存释放掉。
用于获取某个目录下所有文件占用磁盘的空间(blocks / 2),模仿 du(1) 命令的实现。du(1) 命令是做了权限处理的,而我们的 mydu 没有处理文件权限,所以得出的结果可能略有差异。
#include <stdio.h>
#include <stdlib.h>
#include <glob.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#define BUFSIZE 1024
int path_noloop (const char *path) {
// 去除 . 和 ..
char *pos = strrchr(path, '/');
if (pos) {
if ((!strcmp("/.", pos))
|| (!strcmp("/..", pos))) {
return 0;
}
} else if ((!strcmp(".", path)) || (!strcmp("..", path))) {
return 0;
}
return 1;
}
int mydu(const char *path)
{
// /a/b/c/d/f/g
static char str[BUFSIZE] = "";
glob_t globt;
int i = 0, ret = 0;
struct stat buf;
lstat(path, &buf);
// path为目录文件
if (S_ISDIR(buf.st_mode))
{
// 非隐藏文件
snprintf(str, BUFSIZE, "%s/*", path);
glob(str, 0, NULL, &globt);
// 隐藏文件,将两次解析的结果追加到一块,所以特殊要求使用 GLOB_APPEND
snprintf(str, BUFSIZE, "%s/.*", path);
glob(str, GLOB_APPEND, NULL, &globt);
ret = buf.st_blocks;
for (i = 0; i < globt.gl_pathc; i++) {
// 递归目录的时候要注意,目录并不是一个典型的树状结构,它是具有回路的,所以向下递归时遇到 . 和 .. 的时候不要进行递归
if (path_noloop(globt.gl_pathv[i])) {
ret += mydu(globt.gl_pathv[i]);
}
}
// 用完了不要忘记释放资源
globfree(&globt);
} else {
// path 为非目录文件
ret = buf.st_blocks;
}
return ret;
}
int main(int argc, char **argv)
{
printf("%d\n",mydu(argv[1]) / 2);
exit(0);
}
opendir(3)
函数用于打开一个目录,并返回一个指向目录的结构体指针:DIR。
readdir(3)
函数用于读取目录项。每次调用会返回一个目录项,循环调用就可以读取出一个目录中的所有目录项,返回 NULL 表示目录中的目录项读取完毕了。
注意系统调用也有一个 readdir(2) 函数,不要弄混了哟,这里说的是标准库的 readdir(3)。
closedir(3)
函数用于回收资源,它和 opendir(3) 函数是成对使用的。在前两篇博文中学习各种 IO 的过程中,相信小伙伴们对于这种方式出现的函数已经不陌生了。
telldir(3) 和 seekdir(3)
函数是用来定位目录项位置指针的,使用场景很少。
模仿 du(1) 命令,运行结果和上面的栗子是一样的,不过这次是用 xxxxdir(3) 函数族的函数实现的。
#define NEWPATHSIZE 1024
int64_t mydudir (const char *path)
{
int64_t sum = 0;
struct stat buf;
struct dirent *de;
struct stat subbuf;
char newpath[NEWPATHSIZE];
if (lstat(path, &buf) < 0)
{
perror("lstat");
exit(1);
}
if (S_ISDIR(buf.st_mode)) // 文件夹
{
sum = buf.st_blocks;
DIR *dirp = opendir(path);
if (NULL == dirp)
{
perror("opendir");
//exit(1);
return sum;
}
while (NULL != (de = readdir(dirp)))
{
if (NULL != de)
{
snprintf(newpath, NEWPATHSIZE, "%s/%s", path, de->d_name);
if (DT_DIR == de->d_type) // 文件夹
{
if (strcmp(".", de->d_name) && strcmp("..", de->d_name))
{
strncat(newpath, "/", NEWPATHSIZE);
sum += mydudir(newpath);
}
}
else // 文件
{
if (lstat(newpath, &subbuf) < 0)
{
perror("lstat-sub");
//exit(1);
return sum;
}
sum += subbuf.st_blocks;
}
}
}
closedir(dirp);
}
else // 文件
{
sum = buf.st_blocks;
}
return sum;
}
四、 系统数据文件和信息
getpwnam(3)、getpwuid(3)
getpwnam, getpwuid - get password file entry
#include <sys/types.h>
#include <pwd.h>
struct passwd *getpwnam(const char *name);
struct passwd *getpwuid(uid_t uid);
在/etc/passwd 文件中保存了系统中每个用户的用户名、UID 和 GID 等信息。
但是这个文件在不同的系统中保存的格式是不一样的,如果一个程序直接用文件流去读取里面的内容,那么这个程序的可移植性就被降低了。
老版本的BSD 使用 BDB (BSDDB) 数据库保存用户信息;
HPUnix 使用文件系统 hash 方式保存用户信息;
POSIX.1、FreeBSD 8.0、Linux 3.2.0、Mac OS X 10.6.8、Solaris 10 等系统使用 /etc/passwd 文件保存用户信息。(详见 APUE 第三版 P142 图6-1)
正是由于操作系统之间的这种实现方式不统一,无论使用哪种方式保存用户信息,通过这两个函数都可以获得到用户的信息,保存在 struct passwd 中。
getpwnam(3) 的作用是根据用户名查找用户信息。
getpwuid(3) 的作用是根据用户 ID 查找用户信息。
struct passwd 定义在 pwd.h 头文件中,具体内容如下:
struct passwd {
char *pw_name; /* 用户名 */
char *pw_passwd; /* 用户口令 */
uid_t pw_uid; /* 用户 ID */
gid_t pw_gid; /* 用户组 ID */
char *pw_gecos; /* user information */
char *pw_dir; /* 用户的家目录 */
char *pw_shell; /* 用户登录 shell */
};
getgrnam(3)、getgrgid(3)
getgrnam, getgrgid - get group file entry
#include <sys/types.h>
#include <grp.h>
struct group *getgrnam(const char *name);
struct group *getgrgid(gid_t gid);
这两个函数的作用和上面那两个函数的作用类似,只不过这次获取的是用户组的数据。
getgrnam(3) 根据用户组名称获得用户组信息。
getgrgid(3) 根据用户组 ID 获得用户组信息。
struct group 定义在 grp.h 头文件中,下面是这个结构体中的内容
struct group {
char *gr_name; /* 用户组名称 */
char *gr_passwd; /* 用户组密码?什么鬼 */
gid_t gr_gid; /* 用户组 ID */
char **gr_mem; /* 用户组中的用户列表 */
};
解析一下/etc/shadow文件
tom:$y$j9T$k9hD614nCdi1b2f00t1oQ/$wp26/JVsNYxHwc1CBJ/lhweVP28T0kDsIPEZ9/XkOR2:19548:0:99999:7:::
文件中每一行是一个用户的信息,每一部分用冒号隔开,最终要的就是前两个冒号隔开的内容:用户名和密码。
而第二部分,也就是密码部分又用 $ 分隔成了3部分,第一部分为加密方式 ID,含义见表1;第二部分是加盐值,也就是密码中的一个杂字串,用于增加加密强度;第三部分就是明文密码 + 杂字串根据第一部分指定的加密方式计算出来的哈希散列密文。
加密方式 ID 对应的加密方式如下:
| ID | 加密方式 |
|---|---|
| 1 | MD5 |
| 2a | Blowfish |
| 5 | SHA-256 |
| 6 | SHA-512 |
getspnam(3)
函数可以根据用户名来获得用户的密码等信息。其实就是在读取 /etc/shadow 文件,所以请注意,使用这个函数的进程必须具有 root 权限。
getspnam - get shadow password file entry
#include <shadow.h>
struct spwd *getspnam(const char *name);
getspnam返回了一个结构体 struct spwd,我们来看下这个结构体里如下
struct spwd {
char *sp_namp; /* 登录用户名 */
char *sp_pwdp; /* 加密的密码,格式为 $ID$Salt$Pwd */
long sp_lstchg; /* Date of last change
(measured in days since
1970-01-01 00:00:00 +0000 (UTC)) */
long sp_min; /* Min # of days between changes */
long sp_max; /* Max # of days between changes */
long sp_warn; /* # of days before password expires
to warn user to change it */
long sp_inact; /* # of days after password expires
until account is disabled */
long sp_expire; /* Date when account expires
(measured in days since
1970-01-01 00:00:00 +0000 (UTC)) */
unsigned long sp_flag; /* 保留标志 */
};
crypt(3)
Linux 系统中也为我们提供了一个简便的加密函数:crypt(3)
crypt - password and data encryption
#define _XOPEN_SOURCE /* See feature_test_macros(7) */
#include <unistd.h>
char *crypt(const char *key, const char *salt);
Link with -lcrypt.
当然,用这个函数稍微有点麻烦,看见上面的宏定义了吧,前面我们遇到过类似的函数。我们再来说一次有关这种宏定义的用法,下次再遇到就不再赘述了。
如果 man 手册中说一个函数在使用之前需要定义一个宏,那么通常你有三种办法:
-
在包含头文件之前定义这个宏,就像手册中写的那样。
-
如果在源文件中没有定义宏,那么就需要在编译的时候通过 -D 参数来指定:gcc -D_XOPEN_SOURCE,注意 -D 参数后面不要加空格,直接写宏名。当然 gcc 是这样用的,其它编译器的用法需要你去查对应编译器的手册了。
-
在 Makefile 的 CFLAGS 中指定编译选项:CFLAGS += -D_XOPEN_SOURCE,这种方式也是针对 gcc 的,其它编译器的用法需要你去查对应的编译器手册。
还要注意的是,链接的时候要加上 -lcrypt 链接选项才行。
参数列表:
key: 加密前的明文。
salt: 用来指定加密算法和加盐值,格式为 $加密算法ID$Salt$被忽略,加密算法ID 可以从上面 表1 中选择。有木有觉得跟 /etc/shadow 文件中的密码部分很像?该函数只能看见第三个 $ 之前的部分,后面的内容将被忽略。
返回值就跟 /etc/shadow 文件中的密码部分一样了: 加密算法 I D 加密算法ID 加密算法IDSalt$密文。
getpass(3)
我们平时见到的 Shell 中要求输入口令的时候都是关闭回显的,输入完成后再恢复回显。当然可以通过手动设置参数的方式实现,但是比较麻烦,系统中已经提供了一个现成的函数专门用于获取口令:getpass(3)
getpass - get a password
#include <unistd.h>
char *getpass( const char *prompt);
参数是显示在 shell 中的提示性文字,返回的就是用户从控制台上输入的字符串。
用这getspnam、crypt 两个函数我们可以写一个程序模仿 shell 用户登录例子
#include <stdio.h>
#include <shadow.h>
#include <unistd.h>
#include <string.h>
int main (int argc, char **argv)
{
char name[32] = "", *pwd;
struct spwd *p;
size_t namelen = 0;
printf("请输入用户名:");
fgets(name, 32, stdin);
pwd = getpass("请输入密码:");
namelen = strlen(name);
name[namelen - 1] = 0; // 去掉读入的'\n'
p = getspnam(name);
if (!p) {
fprintf(stderr, "用户名或密码错误!\n");
return -1;
}
// 由于 getspnam(3) 返回的 sp_pwdp 部分正好符合 crpyt(3) 要求的 salt 参数的规则,所以可以直接作为参数使用,反正 crpyt(3) 会忽略第三个 $ 之后的内容
if (!strcmp(crypt(pwd, p->sp_pwdp), p->sp_pwdp)) {
printf("密码正确!\n");
} else {
fprintf(stderr, "用户名或密码错误!\n");
}
return 0;
}
uname(2)
uname - get name and information about current kernel
#include <sys/utsname.h>
int uname(struct utsname *buf);
uname(1) 命令大家都使用过吧,它就是通过 uname(2) 函数封装的,可以获取到一些内核中的信息。
时间和日期例程
时间格式通常分为三种:
第一种是人类喜欢的格式化字符串,例如:2015年 04月 19日 星期日 22:21:29 CST;
第二种是程序猿喜欢的格式:分解时间(struct tm)。其实就是将时间的各个部分分开,保存到一个结构体中,这样在使用的时候灵活性更高。
第三种是计算机喜欢的格式:日历时间(time_t),也就是大整数,硬件处理起来更方便。例如:1429455918。
time(3)
time - get time2
#include <time.h>
time_t time(time_t *t);
time(3) 函数的作用就是从内核中获取一个日历时间(time_t,大整数),参数传入 NULL 则可以获取到从 1970-01-01 00:00:00(UTC) 到现在的秒数。
localtime
localtime - transform date and time to broken-down time or ASCII
#include <time.h>
struct tm *localtime(const time_t *timep);
localtime(3) 函数的作用是将 time_t 大整数转换为程序员喜欢的 tm 结构体,并且是将日历时间转换为本地时间。
struct tm 成员包括:
struct tm {
int tm_sec; /* 秒,支持润秒 [0 - 60] */
int tm_min; /* 分钟 [0 - 59] */
int tm_hour; /* 小时 [0 - 23] */
int tm_mday; /* 一个月中的第几天 [1 - 31] */
int tm_mon; /* 月份 [0 - 11] */
int tm_year; /* 年,从 1900 开始 */
int tm_wday; /* 一星期中的第几天 [0 - 6] */
int tm_yday; /* 一年中的第几天 [0 - 365] */
int tm_isdst; /* 夏令时调整,基本不用,如果怕有影响可以设置为 0 */
};
gmtime
gmtime - transform date and time to broken-down time or ASCII
#include <time.h>
struct tm *gmtime(const time_t *timep);
gmtime(3) 函数与 localtime(3) 函数相同,作用也是将 time_t 大整数转换为程序员喜欢的 tm 结构体,但是它将日历时间转换为 UTC 时间而不是转换为本地时间。
mktime
mktime - transform date and time to broken-down time or ASCII
#include <time.h>
time_t mktime(struct tm *tm);
mktime(3) 函数的作用与上面两个函数的作用正好是相反的,将程序猿喜欢的 struct tm 转换为计算机喜欢的 time_t 类型。
注意到参数 tm 没有加 const 关键字修饰了吗?这说明函数的内部可能会修改入参的值。
它在转换之前会先调整入参的每一个成员,发现有越界的情况会将其调整为合法的状态
strftime
strftime - format date and time
#include <time.h>
size_t strftime(char *s, size_t max, const char *format, const struct tm *tm);
这个函数很复杂,使用起来就像 printf(3) 一样,可以通过格式化字符串来控制返回的字符串格式。
参数列表:
s:转换完成后的字符串保存在s所指向的空间;
max:s 的最大长度
format:格式化字符串;用法跟 printf(3) 的 format 是一样的,但是具体格式化参数是不同的,详细的内容请查阅 man 手册。
tm:转换的数据来源;
求取100天后是哪天
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define TIMESTRINGSIZE 1024
int main()
{
time_t stamp;
struct tm *tm;
char timestr[TIMESTRINGSIZE] = "";
stamp = time(NULL); //获取time时间
tm = localtime(&stamp);//将time时间转化为本地时间结构体
strftime(timestr,TIMESTRINGSIZE,"NOW:%Y-%m-%d",tm);//格式化输出时间格式
puts(timestr);
tm->tm_mday += 100;
(void)mktime(tm);// 时间结构体转化为time时间
strftime(timestr,TIMESTRINGSIZE,"100 days later:%Y-%m-%d",tm);
puts(timestr);
exit(0);
}
五、进程环境
进程终止
Linux 系统一共有 8 种进程终止方式,其中 5 种为正常终止方式:
1)从 main() 函数返回;
2)调用 exit(3) 函数;
3)调用 _exit(2) 或 _Exit(2) 函数;
4)最后一个线程从其启动例程返回;
5)从最后一个线程调用 pthread_exit(3) 函数。
剩下的 3 种为异常终止方式:
6)调用 abort(3) 函数;
7)接收到一个信号;
8)最后一个线程对取消请求作出响应。
第 1 条:在 main() 函数中执行 return 语句,可以将一个 int 值作为程序的返回值返回给调用者,一般是 shell。返回 0 表示程序正常结束,返回 非零值 表示程序异常结束。
第 2 条:在 main() 函数中执行 return 语句相当于调用 exit(3) 函数,exit(3) 是专门用于结束进程的,它依赖于 _exit(2) 或 _Exit(2) 系统调用。程序中任何地方调用 exit(3) 都会退出,但 return 语句只有在 main() 函数中才能结束进程,在其它函数中执行 return 语句只能退出当前函数。
第 3 条:_exit(2) 和 _Exit(2) 函数都是系统调用,在程序中的任何地方调用它们程序都会立即结束。
上面三条有两点需要大家注意,我先把问题提出来大家思考一下,下面会有讲解:
(1) return 、exit(3)、_exit(2) 和 _Exit(2) 的返回值取值范围是多少呢?
(2) exit(3)、_exit(2) 和 _Exit(2) 之间有什么区别呢?
第 4、5 条 等到第 11 章我们讨论线程的时候再说,总之进程就是线程的容器,最后一个线程的退出会导致整个进程的消亡。
第 6 条:abort(3) 函数一般用在程序中出现了不可预知的错误时,为了避免异常影响范围扩大,直接调用 abort(3) 函数自杀。实际上 abort(3) 函数也是通过信号实现的。
第 7 条:信号有很多种,有些默认动作是被忽略的,有些默认动作则是杀死进程。
比如程序接收到 SIGINT(Ctrl+C) 信号就会结束,Ctrl + C 是 SIGINT 的一个快捷方式,而不是 Ctrl + C 触发了 SIGINT 信号。
到第 10 章我们会详细的讨论信号。
第 8 条 也要等到第 11 章我们讨论线程的时候再详细说
exit(2)
exit - cause normal process termination
#include <stdlib.h>
void exit(int status);
status 参数的取值范围并非是所有 int 的取值范围,计算方法是 status & 0377,也就相当于一个有符号的 char 型数据,取值范围是 -128~127,最多256种可能。
所有通过 atexit(3) 和 on_exit(3) 注册的函数会被以注册的逆序来调用。
它在执行完钩子函数之后再执行IO清理,然后才使进程结束。
atexit(3)
atexit - register a function to be called at normal process termination
#include <stdlib.h>
int atexit(void (*function)(void));
用该函数注册过的函数会在程序正常终止之前被调用,被注册的函数称为“钩子函数”。
注册的钩子函数形式必须是这样:void (*function)(void),因为它不会接收任何参数,也没有任何机会返回什么值,所以是一个无参数无返回值的函数。
当多次调用 atexit(3) 函数注册了多个钩子函数的时候,程序结束时钩子函数是以注册的逆序被调用的。
比如按照 a()、b()、c()、d() 的形式注册了 4 个钩子函数,那么程序结束时,它们的调用顺序是:d()、c()、b()、a()。
下面举个栗子来说明这个逆序调用是怎么回事。
#include <stdio.h>
#include <stdlib.h>
void f1 (void)
{
puts("f1");
}
void f2 (void)
{
puts("f2");
}
void f3 (void)
{
puts("f3");
}
int main (void)
{
puts("Begin!");
atexit(f1); // 只是声明一个函数,相当于把一个函数挂在钩子上,并不调用
atexit(f2);
atexit(f3);
puts("End!");
exit(0);
}
编译并运行结果如下
Begin
End
f3() is working
f2() is working
f1() is working
_exit(2)、_Exit(2)
_exit, _Exit - terminate the calling process
#include <unistd.h>
void _exit(int status);
#include <stdlib.h>
void _Exit(int status);
在程序的任何地方调用 _exit(2) 或 _Exit(2) 函数程序都会立即结束,任何钩子函数都不会被调用。
_exit(2)、_Exit(2) 与 exit(3) 的区别就是 _exit(2) 和 _Exit(2) 函数不会调用钩子函数,也不会做 IO 清理。
在出现这种情况的时候一定是上面的代码出现了逻辑问题,或程序中出现了越界等问题,所以不能调用钩子函数执行清理了。为了防止故障扩散,一定要让程序立即结束。
命令行参数
我们在使用 shell 命令的时候经常为传递各种参数来完成不同的工作。这个参数实际上就是传递到程序 main() 函数的 argc 和 argv 两个参数中去了。
我们再来看一下 main() 函数的原型:
int main (int argc, char **argv);
参数列表:
argc:argv 中字符串的数量,也就是传递给程序的命令行参数的数量。
argv:在 shell 中传递给进程的命令行参数列表,argv[0] 永远是命令本身,第一个参数从 argv[1] 开始。
这是一个二维数组,其实就是一个字符串数组。
字符串本身就是一个 char 数组,而保存多个字符串的数组自然就是一个 char 型二维素组了。
常见的命令行参数分类:
>$ cmd [opt] [!opt]
>$ ls # 无参数
>$ ls -l -a -i # 仅选项
>$ ls /etc/ /tmp # 非选项传参
>$ ls -l /tmp -a /etc
>$ ./myplayer -H 500 -W 500 a.avi # 选项带参数
>$ ./myplayer -H -W a.avi # 假设 H 和 W 选项必须带参数,这样传惨会报错,因为找不到任何参数修饰 -H 和 -W
>$ cmd [opt opt-arg] [!opt]
>$ ./myplayer -H 100 px -W 500 cm a.avi # 选项带参数,参数又带参数,这种没有函数能搞定,只能自己写函数解析了
选项分为两种形式,一种是以 - 开头的短格式选项,只能是一个字母或一个数字;
另一种是长格式选项,以 – 开头,可以由多个字母和数字组成。
短格式最多支持 26个小写字母+26个大写字母+10个数字,共 62 个选项。这些选项足够一个程序的使用了,为什么还需要长格式的选项呢?
使用长格式选项是为了便于使用者记忆,辅助短格式参数的使用。如果有一些单词的缩写碰撞了或者不容易记忆,则可以选用长格式的参数。
这些命令行参数可以随意松散的传给命令,那么命令是如何解析这些参数的呢?别着急,其实已经有优秀的库函数供我们使用了。
getopt(3)
getopt, optind - Parse command-line options
#include <unistd.h>
int getopt(int argc, char * const argv[], const char *optstring);
extern int optind;
该函数用于解析短格式参数。
参数列表:
argc、argv:就是 main() 函数的 argc 和 argv 参数;
optstring:想要从 argv 中解析的所有选项列表,不用加 - 前导符;例如程序支持 -y -m -d -h -M -s 参数,则 optstring 填写 “y:mdh:Ms” 即可。
加冒号表示某个选项后面要带参数,比如 y 和 h 后面都需要带参数,需要用到全局变量:
extern char *optarg;
extern int optind;
optarg:表示选项后面的参数,也就是 -y 和 -h 后面的参数。例如:-y 4 -h 24。
optind:用于记录 getopt(3) 函数目前读到了 argv 的哪个下标。
通过一个getopt来实现mydate例子
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
#include <string.h>
#define TIMESTRINGSIZE 1024
#define FMTSTRSIZE 1024
int main(int argc, char **argv)
{
time_t stamp;
struct tm *tm;
FILE *fd = stdout;//文件描述符指向标准输出
char timestr[TIMESTRINGSIZE] = "";
stamp = time(NULL);
tm = localtime(&stamp);
int c;
char fmtstr[FMTSTRSIZE] = "";
fmtstr[0] = '\0';
while (1)
{
c = getopt(argc, argv, "-H:MSy:md"); //
if (c < 0)
break;
switch (c)
{
case 1:
fd = fopen(argv[optind - 1], "w"); // optind 为命令行argc位置
if (fd == NULL)
{
perror("fopen()");
fd = NULL;
}
break;
case 'H':
if (strcmp(optarg, "12") == 0) // 采取12小时制
{
strncat(fmtstr, "%I(%P) ", FMTSTRSIZE);
}
else if (strcmp(optarg, "24") == 0) //采取24小时制
{
strncat(fmtstr, "%H ", FMTSTRSIZE);
}
else
{
fprintf(stderr, "time hour error");
}
break;
case 'M':
strncat(fmtstr, "%M ", FMTSTRSIZE);
break;
case 'S':
strncat(fmtstr, "%S ", FMTSTRSIZE);
break;
case 'y':
if (strcmp(optarg, "2") == 0)//两位年单位输出
{
strncat(fmtstr, "%y ", FMTSTRSIZE);
}
else if (strcmp(optarg, "4") == 0)//四位年单位输出
{
strncat(fmtstr, "%Y ", FMTSTRSIZE);
}
else
{
fprintf(stderr, "time year error");
}
break;
case 'm':
strncat(fmtstr, "%m ", FMTSTRSIZE);
break;
case 'd':
strncat(fmtstr, "%d ", FMTSTRSIZE);
break;
default:
break;
}
}
strncat(fmtstr, "\n", FMTSTRSIZE);//增加一个自动换行
strftime(timestr, TIMESTRINGSIZE, fmtstr, tm);//格式化输出时间格式
fputs(timestr, fd);
exit(0);
}
getopt_long(3)
用于解析长格式参数,函数原型就不列出来了。
关于命令行参数要再补充一点,经常考运维人员的一道面试题大概是这样的:如何使用 touch(1) 命令在当前目录创建一个名字叫做 -a 的文件?
通常有两个办法可以实现:
-
touch – -a 当命令行遇到两个 - 和空格时(-- ),会认为后面不会有任何选项,也就不会将 - 再作为参数的前导符。
-
touch ./-a ./ 表示当前目录
环境表
export(1) 命令可以查看当前所有的环境变量或设置某个环境变量。
访问环境变量可以使用 getenv(3) 和 putenv(3) 函数,下面我们会提到它们。
环境表就是将环境变量保存在了一个字符指针数组中,很多 Unix 系统都支持三个参数的 main() 函数,第三个参数就是环境表。
环境变量是为了保存常用的数据。以当前 terminal 为例,把 terminal 当作是一个大的程序来跑,就可以将环境变量看作是这个程序的全局变量。
环境变量相当于在某个位置声明 extern char **environ;
上面说了,环境表就是一个字符指针数组,所以使用环境变量就相当于 environ[i] - >name=value;
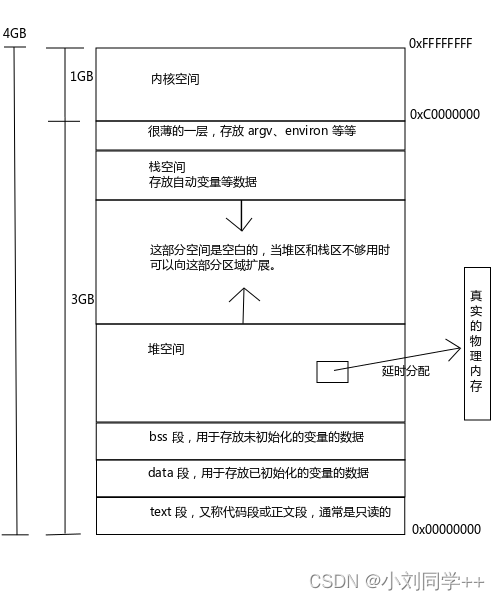
C 程序的存储空间布局
通常 malloc(3) 失败有两种情况,一种是内存真的耗尽了;另一种是不断的申请小的内存,即使堆上全部存放指针也有放满了的情况。
在 Linux 环境中内存是延时分配的,也就是说当 malloc(3) 分配内存时并没有真正的分配物理内存给你,只是给了你一个非空指针,当你真正使用内存的时候通过引发一个缺页异常,内核才真正分配内存给你。
好比有人跟你借100块钱,你也承诺了可以借,但是他并不马上要钱,等到当他跟你要的时候你已经花掉了50块钱,这时候你有两个选择:一是把借钱的人杀掉,这样就不用借钱给他了;二是去抢钱,抢够了足够的钱再给他。
如果让你选择,你会采用哪种方式呢?
内核采用的是第二种方式,当它发现内存不足够它承诺给你的容量时,它会结束某些不常用的后台进程,再将释放出来的内存分配给你。
共享库
类似于插件,当一个模块失败时不会影响其它模块。
内核采用插件的这种形式是有好处的,比如系统启动的时候,如果某个服务(如 ftp 服务、DHCP 等服务)启动未成功,系统会继续启动其它服务而不会立即关机。
否则如果因为 ftp 服务启动失败就关机那就坏了,想要修复 ftp 服务需要先开机,而开机需要成功启动 ftp 服务,那么系统就无法启动了。
内核中任何一个模块的加载都要以插件的形式运行,也就是尝试加载,即使加载失败也不能影响其它模块。
dlopen(3)
dlopen - programming interface to dynamic linking loader
#include <dlfcn.h>
void *dlopen(const char *filename, int flag);
该函数就是用来手工装载共享库的。
参数列表:
filename:加载的共享库文件路径
flag:打开方式
man 手册中有使用示例,如想了解详情请查询 man 手册。
存储空间分配
这部分理论性的内容详细见 《APUE》 P165,书上的内容 LZ 还没看,先占个位置,等 LZ 回过头来复习的时候再补充进来。
环境变量
上面提到了环境表,在这一节我们看看操作环境变量的两个函数如何使用。
环境变量的作用到底是什么?有很多小伙伴不明白环境变量是个什么东西,一听感觉好深奥啊,惧怕得不行。
就像我们使用 ls(1) 命令的时候是在任何位置都可以使用的,而没有用 /bin/ls 的方式来使用 ls(1),是因为有 PATH 环境变量的存在,它会保存所有常用的可执行文件的路径。
其实环境变量无非就是一个字符串而已,它由 key(变量名) 和 value 两部分组成,我们可以通过 key 来读写 value。
我们通常所说的环境变量就是环境表,也就是由多个环境变量组成的一个字符指针数组,它的存在也就是为了方便我们在程序中获得一些经常使用的变量数据,仅此而已。
小伙伴们害怕它,一定是因为在 windows 中遇到过太多的程序严重的依赖于它,尤其是系统应用,一旦把环境变量改坏了就玩儿完了,所以才有小伙伴觉得它很深奥很恐怖,今天大家见到了它的庐山真面目了,以后大家都不要害怕它了。
getenv(3)
getenv - get an environment variable
#include <stdlib.h>
char *getenv(const char *name);
这个函数的作用是获取一个环境变量,用法很简单,就是通过 name 获得 value, value 是返回值。
在这里补充一点,在程序中获得当前工作路径有两种办法,一种是通过环境变量,一种是通过专门的函数:
puts(getevn(“PWD”)); // 通过环境变量获取当前路径,也可以使用 getcwd(3) 函数获得当前路径。
setenv(3)
setenv - change or add an environment variable
#include <stdlib.h>
int setenv(const char *name, const char *value, int overwrite);
这个函数和 getenv(3) 函数的作用正好相反,是将 value 赋给 name 环境变量。
如果 name 不存在,则添加新的环境变量。
如果 name 存在:如果 overwrite 为真,就用 value 覆盖 name 原来的值;如果 overwrite 为假则保留 name 原来的值。
putenv(3)
putenv - change or add an environment variable
#include <stdlib.h>
int putenv(char *string);
用 “name=value” 的形式添加或修改环境变量的值。如果 name 已存在则会用新值覆盖原来的值。
小伙伴们要注意:参数不是 const 的,所以某些情况下可能会修改参数的值,所以还是使用 setenv(3) 更保险。
大家思考一个问题:如 图1 所示,环境表是存放在堆与内核空间之间的薄层中的,如果新字符串比原字符串长怎么办,会不会出现越界的情况呢?
其实不用担心这个问题,因为无论新的值与原来的值谁长谁短,都会先将原来的空间释放,在堆上新申请一块空间来存放新的值。
setjmp(3) 和 longjmp(3)
goto 语句想必大家都很熟悉了吧,但是它们有一个缺点,就是不能跨函数跳转。C 标准给我们提供了两个函数增强了程序跳转的能力,它们可以使程序跨函数跳转。
setjmp - save stack context for nonlocal goto
#include <setjmp.h>
int setjmp(jmp_buf env);
longjmp, siglongjmp - nonlocal jump to a saved stack context
#include <setjmp.h>
void longjmp(jmp_buf env, int val);
首先要通过 setjmp(3) 设置一个跳转点,然后可以通过 longjmp(3) 跳转到 setjmp(3) 所在的位置。
setjmp(3) 设置跳转点时返回值为0,被跳转过来时返回值为非零,也就是 longjmp(3) 的 val 参数。所以 setjmp(3) 下面一定跟着一组分支语句来根据不同的返回值做不同的操作。
longjmp(3) 无需返回值,因为执行的时候程序已经跳转了,无法获得返回值了。
参数列表:
env: 是指定条准到哪
val:带回去的值,如果值为 0,则 setjmp(3) 收到的返回值是 1,避免跳转出现死循环。
函数跳转例子
#include <stdio.h>
#include <stdlib.h>
#include <setjmp.h>
static jmp_buf save;
void d(void)
{
printf("%s():Begin.\n",__FUNCTION__);
printf("%s():Jump now.\n",__FUNCTION__);
longjmp(save,8); // 跳
printf("%s():End.\n",__FUNCTION__);
}
void c(void)
{
printf("%s():Begin.\n",__FUNCTION__);
printf("%s():Call d().\n",__FUNCTION__);
d();
printf("%s():d() returned.\n",__FUNCTION__);
printf("%s():End.\n",__FUNCTION__);
}
void b(void)
{
printf("%s():Begin.\n",__FUNCTION__);
printf("%s():Call c().\n",__FUNCTION__);
c();
printf("%s():c() returned.\n",__FUNCTION__);
printf("%s():End.\n",__FUNCTION__);
}
void a(void)
{
int ret;
printf("%s():Begin.\n",__FUNCTION__);
ret = setjmp(save);
if(ret == 0) // 设置跳转点
{
printf("%s():Call b().\n",__FUNCTION__);
b();
printf("%s():b() returned.\n",__FUNCTION__);
}
else // 跳回到这
{
printf("%s():Jumped back here with code %d\n",__FUNCTION__,ret);
}
printf("%s():End.\n",__FUNCTION__);
}
int main()
{
printf("%s():Begin.\n",__FUNCTION__);
printf("%s():Call a().\n",__FUNCTION__);
a();
printf("%s():a() returned.\n",__FUNCTION__);
printf("%s():End.\n",__FUNCTION__);
return 0;
}
运行结果
main():Begin.
main():Call a().
a():Begin.
a():Call b().
b():Begin.
b():Call c().
c():Begin.
c():Call d().
d():Begin.
d()Jump now.
$s():Jumped back here with code 4196687
a():End b().
main():a() retuned.
main():End.
注意:setjmp(3) 和 longjmp(3) 函数不能从信号处理函数中跳转
函数 getrlimit(2) 和 setrlimit(2)
getrlimit, setrlimit - get/set resource limits
#include <sys/time.h>
#include <sys/resource.h>
int getrlimit(int resource, struct rlimit *rlim);
int setrlimit(int resource, const struct rlimit *rlim);
每个进程都有一组对资源使用的上限,通过这两个函数可以获取或设置这些上限。
ulimit§ 命令就是使用这两个函数封装的。
getrlimit(2) 获取 resource 资源,并且把读取结果回填到 rlptr 中。
setrlimit(2) 设置 resource 资源,设置的值由用户填在 rlimit 中。
rlimit 结构体的内容也很简单,当然这些资源上限也不是随便可以修改的,下面的规则同样适用于 ulimit§ 命令。
struct rlimit {
rlim_t rlim_cur; /* 软限制。普通用户能提高和降低软限制,但是不能高过硬限制。超级用户也一样。 /
rlim_t rlim_max; / 硬限制。普通用户只能降低自己的硬限制,不能提高硬限制。超级用户能提高硬限制也能降低硬限制。 */
};
六、进程控制
进程主要就是围绕着 fork(2)、exec(2)、wait(2) 这三个函数来讨论 *nix 系统是如何管理进程的。
ps(1) 命令可以帮助我们分析本章中的一些示例,所以简单介绍一些参数的组合方式,更详细的信息请查阅 man 手册。
ps axf 主要用于查看当前系统中进程的 PID 以及执行终端(tty)和状态等信息,更重要的是它能显示出进程的父子关系。
ps axj 主要用于查看当前系统中进程的 PPID、PID、PGID、SID、TTY 等信息。
ps axm 显示进程的详细信息,PID 列下面的减号(-)是这个进程中的线程。
ps ax -L 以 Linux 的形式显示当前系统中的进程列表。
PID 是系统中进程的唯一标志,在系统中使用 pid_t 类型表示,它是一个非负整型。
1号 init 进程是所有进程的祖先进程(但不一定是父进程),内核启动后会启动 init 进程,然后内核就会像一个库一样守在后台等待出现异常等情况的时候再出来处理一下,其它的事情都由 init 进程创建子进程来完成。
进程号是不断向后使用的,当进程号达到最大值的时候,再回到最小一个可用的数值重新使用。
getpid, getppid
getpid, getppid - get process identification
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);
getpid(2) 获得当前进程 ID。
getppid(2) 获得父进程 ID。
现在轮到我们今天的主角之一:frok(2) 函数上场了。
fork - create a child process
#include <unistd.h>
pid_t fork(void);
fork(2) 函数的作用就是创建子进程。
调用 fork(2) 创建子进程的时候,刚开始父子进程是一模一样的,就连代码执行到的位置都是一模一样的。
fork(2) 执行一次,但返回两次。它在父进程中的返回值是子进程的 PID,在子进程中的返回值是 0。子进程想要获得父进程的 PID 需要调用 getppid(2) 函数。
一般来说调用fork后会执行 if(依赖fork的返回值) 分支语句,用来区分下面的哪些代码由父进程执行,哪些代码由子进程执行。
用户权限和组权限(u+s g+s )
shell 身份是从login 登录用户的身份获取
getuid()
geteuid()
getgid()
getegid()
setuid()
setgid()
setregid()//实现原子化的交换
setreuid()
seteuid()//更改有效用户id
setegid()
脚本文件会有脚本文件标记;
system() = fork() + exec() + wait()封装
守护进程
会话 session(一个正常的终端登录会产生一个终端)
终端
setsid(2)
setsid - create session and set process group ID
#include <unistd.h>
pid_t setsid(void);
创建一个会话并设置进程组的ID。这个函数是我们在第 9 章最有价值的函数,没有这个函数,我们后面就无法创建守护进程。
调用者不能是进程组组长,调用者在调用之后自动变为新进程组组长,并且脱离控制终端,进程 ID 将被设为进程组 ID 和会话 ID,所以守护进程通常 PID、PGID、SID 是相同的。通常的用法是父进程 fork(2) 一个子进程,然后子进程调用 setsid(2) 将自己变成守护进程,父进程退出即可。
setpgid()、getpgid()、setpgrp()和getpgrp()函数 - 设置或获取进程组ID.
单实例的守护进程 :锁文件/var/run/name.pid
启动脚本文件 /etc/rc.d/rc.local
系統日志
系统日志统一交给syslogd服务去写系统日志
openlog()
syslog()
closelog()
并发
同步
异步
异步事件处理:查询法(发送的数据比较繁忙), 通知法(发生的数据比较稀疏)
1.信号的概念
信号是软件层面的中断。
2. signal()
信号会打断阻塞的系统调用
3.信号的不可靠
可重入函数
第一次调用还没有结束,在进行第二次成功调用的
信号的响应过程
常用函数
kill()
reise()
alarm()
paude()
abort()
system()
sleep()
信号集
信号屏蔽字/pending集的处理
扩展
sigsupend()
sigsction()
setitimer()
实时信号
智能推荐
杀毒软件业野蛮生长法则:自己研发病毒自己杀-程序员宅基地
文章浏览阅读52次。时隔4个月后,瑞星杀毒造假案又有了戏剧性的变化。近日,瑞星杀毒造假案的主角——北京市公安局网监处原处长于兵的二审结果仍维持一审的死缓判决。而据于兵的最新供认资料,相当一部分病毒是杀毒软件公司自己的科技力量研制的。于兵供认,瑞星公司向其行贿时就提出条件,由公安机关发出病毒警报,提示用户下载该公司杀毒软件进行杀毒,而病毒则是由瑞星公司“研制”的。“其实这是杀毒软件行业里的公开秘密。”国内一家知名...
密码学考点整理_移位密码和vigenere密码的异同是什么-程序员宅基地
文章浏览阅读6k次,点赞4次,收藏35次。考试重点1. 密码体制分类对称密码体制和非对称密码体制;2. DES和AES算法的特点(结构、密钥长度,分组长度,DES弱密钥)及其过程(置换过程,S盒查表过程),AES的轮结构DESDES结构首先是一个初始置换IP,用于重排明文分组的64比特;相同功能的16轮变换,每轮都有置换和代换;第16轮的输出分为左右两半并被交换次序;最后经过一个逆初始置换产生64比特密文;DES结构图如下:密钥长度:56分组长度:64DES弱密钥:待续了解即可DES 分组长度_移位密码和vigenere密码的异同是什么
基于微信小程序+Springboot线上租房平台设计和实现【三端实现小程序+WEB响应式用户前端+后端管理】_微信小程序租房平台怎么弄-程序员宅基地
文章浏览阅读2.7w次,点赞97次,收藏158次。系统功能包括管理员服务端:首页、轮播图管理、公告信息管理、系统用户(管理员、租客用户、房主用户)资源管理(新闻列表、新闻分类列表)模块管理(房源信息、房源咨询、租赁申请、入住信息、房租信息、反馈信息、通知信息、房屋类型)个人管理;用户客户端:首页、公告信息、新闻资讯、房源信息等功能。_微信小程序租房平台怎么弄
JavaScript - 事件对象 - 鼠标操作_js鼠标点击事件菜鸟教程-程序员宅基地
文章浏览阅读417次。文章目录一、禁止鼠标右键菜单二、禁止鼠标选中三、鼠标事件对象四、鼠标事件对象clientXpageXscreenX五、常用键盘事件一、禁止鼠标右键菜单<body> <script> document.addEventListener('contextmenu', function (e) { e.preventDefault(); }) </script></body>二、禁止_js鼠标点击事件菜鸟教程
直流有刷电机位置环控制与位置速度双环控制(位置式PID)流程解析_偏位置环控制速度-程序员宅基地
文章浏览阅读7.1k次,点赞15次,收藏100次。PID算法中位置环与位置速度双环的对比分析_偏位置环控制速度
13. HTTP1.0 HTTP 1.1 HTTP 2.0主要区别_http 0.13.1-程序员宅基地
文章浏览阅读175次。HTTP1.0 HTTP 1.1 HTTP 2.0主要区别HTTP1.0 HTTP 1.1主要区别长连接节约带宽HOST域HTTP1.1 HTTP 2.0主要区别多路复用数据压缩服务器推送HTTP1.0 HTTP 1.1主要区别长连接HTTP 1.0需要使用keep-alive参数来告知服务器端要建立一个长连接,而HTTP1.1默认支..._http 0.13.1
随便推点
PowerDesigner16 时序图_使用powerdesiger 画出时序图有接口 控制-程序员宅基地
文章浏览阅读5.1k次,点赞5次,收藏10次。时序图(Sequence Diagram)是显示对象之间交互的图,这些对象是按时间顺序排列的。顺序图中显示的是参与交互的对象及其对象之间消息交互的顺序。时序图中包括的建模元素主要有:角色(Actor)、对象(Object)、生命线(Lifeline)、控制焦点(Focus of control)/ 激活(Activation)、消息(Message)、组合片段(Combined Fragments_使用powerdesiger 画出时序图有接口 控制
Doris系列17-动态分区_dynamic_partition.history_partition_num-程序员宅基地
文章浏览阅读1.2k次。文章目录一. 动态分区概述1.1 原理1.2 使用方式1.3 动态分区规则参数1.4 创建历史分区规则1.5 注意事项二. 案例2.1 案例12.2 案例22.3 案例3参考:一. 动态分区概述动态分区是在 Doris 0.12 版本中引入的新功能。旨在对表级别的分区实现生命周期管理(TTL),减少用户的使用负担。目前实现了动态添加分区及动态删除分区的功能。动态分区只支持 Range 分区。名词解释:FE:Frontend,Doris 的前端节点。负责元数据管理和请求接入。BE:Backend_dynamic_partition.history_partition_num
Linux命令_禅道的运行日志放在哪-程序员宅基地
文章浏览阅读309次。笔记_禅道的运行日志放在哪
Web实训项目--网页设计(附源码)_web前端网页设计代码-程序员宅基地
文章浏览阅读4.3w次,点赞79次,收藏882次。我们要使用这些知识实现一个简单的网页设计,利用HTML的a标签做文本内容跳转以及超链接的应用,CSS设计内容样式和图片、动画、视频的大小位置格式,JavaScript实现轮播图效果等。学习如何设计网页中的轮播图和动画效果,并掌握a标签文本内容跳转、超链接的应用、播放音乐与视频等操作。通过对Web知识内容的了解,我们掌握了HTML、CSS和JavaScript的基本知识以及利用它们实现一些简单的应用。1、使用Web知识实现一个简单的网页设计,利用HTML的a标签做文本内容跳转以及超链接的应用。_web前端网页设计代码
Matlab:非负 ODE 解_matlab銝要onnegative-程序员宅基地
Matlab中讲解了如何约束ODE解为非负解的示例,并以绝对值函数和膝盖问题为例进行了说明。文章指出在某些情况下,由于方程的物理解释或解性质的原因,施加非负约束是必要的。
关于g2o_viewer data/result_after.g2o使用过程中coredump、与lsd_slam依赖包libg2o冲突问题_libg2o_-程序员宅基地
文章浏览阅读1.1k次。电脑上装的东西多了就很容引起版本或者依赖问题。。。这不,按照高博教程做octomap实验时候运行g2o_viewer data/result_after.g2o时候就直接coredump。。。。回想起来自己ROS系统中装了libg2o,于是卸载之:sudo apt-get remove ros-indigo-libg2o然后重新执行g2o_viewer data/result_after.g2o注..._libg2o_