通俗易懂的YOLO系列(从V1到V5)模型解读!-程序员宅基地
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达0 前言
本文目的是用尽量浅显易懂的语言让零基础小白能够理解什么是YOLO系列模型,以及他们的设计思想和改进思路分别是什么。我不会把YOLO的论文给你用软件翻译一遍,这样做毫无意义;也不会使用太专业晦涩的名词和表达,对于每一个新的概念都会解释得尽量通俗一些,目的是使得你能像看故事一样学习YOLO模型,我觉得这样的学习方式才是知乎博客的意义所在。
为了使本文尽量生动有趣,我用葫芦娃作为例子展示YOLO的过程。

同时,会对YOLO v1和YOLOv5的代码进行解读,其他的版本就只介绍改进了。
1 先从一款强大的app说起

i detection APP
YOLO v5其实一开始是以一款app进入人们的视野的,就是上图的这个,叫:i detection(图上标的是YOLO v4,但其实算法是YOLO v5),使用iOS系列的小伙伴呢,就可以立刻点赞后关掉我这篇文章,去下载这个app玩一玩。在任何场景下(工业场景,生活场景等等)都可以试试这个app和这个算法,这个app中间还有一个button,来调节app使用的模型的大小,更大的模型实时性差但精度高,更小的模型实时性好但精度差。
值得一提的是,这款app就是YOLO v5的作者亲自完成的。而且,我写这篇文章的时候YOLO v5的论文还没有出来,还在实验中,等论文出来应该是2020年底或者2021年初了。
读到这里,你觉得YOLO v5的最大特点是什么?
答案就是:一个字:快,应用于移动端,模型小,速度快。
首先我个人觉得任何一个模型都有下面3部分组成:
前向传播部分:90%
损失函数部分
反向传播部分
其中前向传播部分占用的时间应该在90%左右,即搞清楚前向传播部分也就搞清楚了这模型的实现流程和细节。本着这一原则,我们开始YOLO系列模型的解读:
2 不得不谈的分类模型
在进入目标检测任务之前首先得学会图像分类任务,这个任务的特点是输入一张图片,输出是它的类别。
对于输入图片,我们一般用一个矩阵表示。
对于输出结果,我们一般用一个one-hot vector表示: ,哪一维是1,就代表图片属于哪一类。
所以,在设计神经网络时,结构大致应该长这样:
img cbrp16 cbrp32 cbrp64 cbrp128 ... fc256-fc[10]
这里的cbrp指的是conv,bn,relu,pooling的串联。
由于输入要是one-hot形式,所以最后我们设计了2个fc层(fully connencted layer),我们称之为“分类头”或者“决策层”。
3 YOLO系列思想的雏形:YOLO v0
有了上面的分类器,我们能不能用它来做检测呢?
要回答这个问题,首先得看看检测器和分类器的输入输出有什么不一样。首先他们的输入都是image,但是分类器的输出是一个one-hot vector,而检测器的输出是一个框(Bounding Box)。
框,该怎么表示?
在一个图片里面表示一个框,有很多种方法,比如:
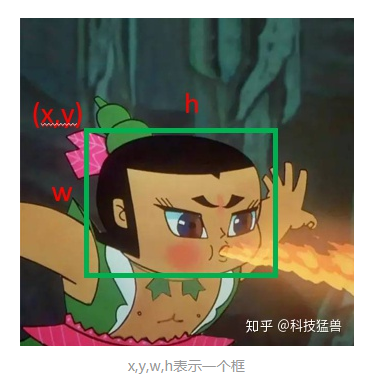
x,y,w,h(如上图)
p1,p2,p3,p4(4个点坐标)
cx,cy,w,h(cx,cy为中心点坐标)
x,y,w,h,angle(还有的目标是有角度的,这时叫做Rotated Bounding Box)
......
所以表示的方法不是一成不变的,但你会发现:不管你用什么形式去表达这个Bounding Box,你模型输出的结果一定是一个vector,那这个vector和分类模型输出的vector本质上有什么区别吗?
答案是:没有,都是向量而已,只是分类模型输出是one-hot向量,检测模型输出是我们标注的结果。
所以你应该会发现,检测的方法呼之欲出了。那分类模型可以用来做检测吗?
当然可以,这时,你可以把检测的任务当做是遍历性的分类任务。
如何遍历?
我们的目标是一个个框,那就用这个框去遍历所有的位置,所有的大小。
比如下面这张图片,我需要你检测葫芦娃的脸,如图1所示:
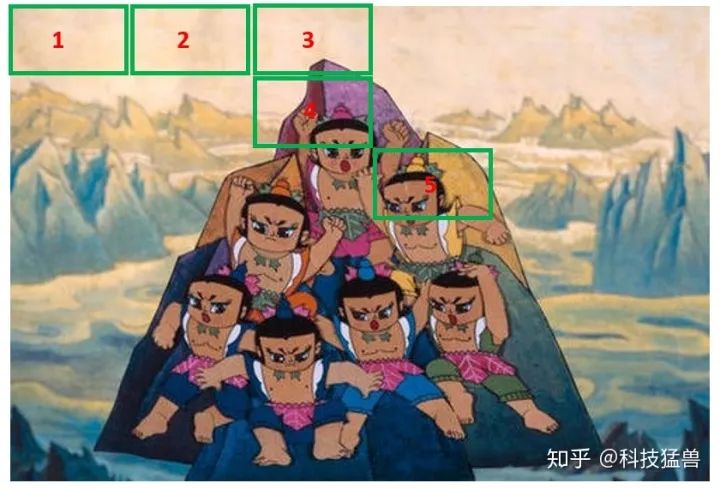
图1:检测葫芦娃的脸
我们可以对边框的区域进行二分类:属于头或者不属于头。
你先预设一个框的大小,然后在图片上遍历这个框,比如第一行全都不是头。第4个框只有一部分目标在,也不算。第5号框算是一个头,我们记住它的位置。这样不断地滑动,就是遍历性地分类。
接下来要遍历框的大小:因为你刚才是预设一个框的大小,但葫芦娃的头有大有小,你还得遍历框的大小,如下图2所示:
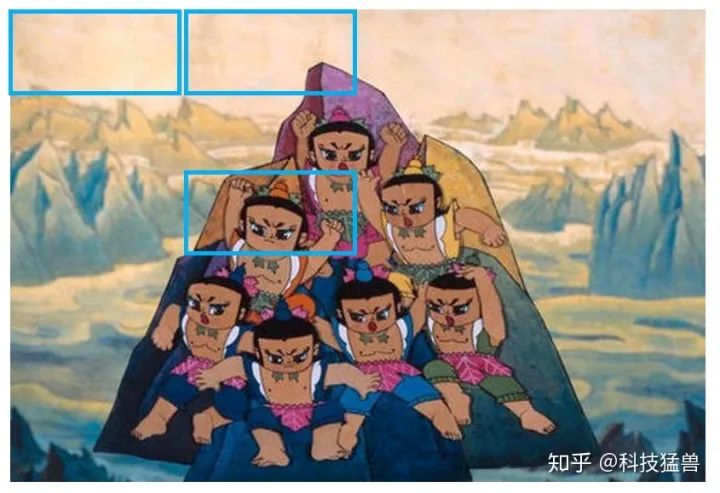
图2:遍历框的大小
还没有结束,刚才滑窗时是挨个滑,但其实没有遍历所有的位置,更精确的遍历方法应该如下图3所示:

图3:更精确地遍历框的位置
这种方法其实就是RCNN全家桶的初衷,专业术语叫做:滑动窗口分类方法。
现在需要你思考一个问题:这种方法的精确和什么因素有关?
答案是:遍历得彻不彻底。遍历得越精确,检测器的精度就越高。所以这也就带来一个问题就是:检测的耗时非常大。
举个例子:比如输入图片大小是(800,1000)也就意味着有800000个位置。窗口大小最小 ,最大 ,所以这个遍历的次数是无限次。我们看下伪代码:

滑动窗口分类方法伪代码
那这种方法如何训练呢?
本质上还是训练一个二分类器。这个二分类器的输入是一个框的内容,输出是(前景/背景)。
第1个问题:
框有不同的大小,对于不同大小的框,输入到相同的二分类器中吗?
是的。要先把不同大小的input归一化到统一的大小。
第2个问题:
背景图片很多,前景图片很少:二分类样本不均衡。
确实是这样,你看看一张图片有多少框对应的是背景,有多少框才是葫芦娃的头。
以上就是传统检测方法的主要思路:
耗时。
操作复杂,需要手动生成大量的样本。
到现在为止,我们用分类的算法设计了一个检测器,它存在着各种各样的问题,现在是优化的时候了(接下来正式进入YOLO系列方法了):
YOLO的作者当时是这么想的:你分类器输出一个one-hot vector,那我把它换成(x,y,w,h,c),c表示confidence置信度,把问题转化成一个回归问题,直接回归出Bounding Box的位置不就好了吗?
刚才的分类器是:img cbrp16 cbrp32 cbrp64 cbrp128 ... fc256-fc[10]
现在我变成:img cbrp16 cbrp32 cbrp64 cbrp128 ... fc256-fc[5],这个输出是(x,y,w,h,c),不就变成了一个检测器吗?
本质上都是矩阵映射到矩阵,只是代表的意义不一样而已。
传统的方法为什么没有这么做呢?我想肯定是效果不好,终其原因是算力不行,conv操作还没有推广。
好,现在模型是:
img cbrp16 cbrp32 cbrp64 cbrp128 ... fc256-fc[5] c,x,y,w,h

那如何组织训练呢?找1000张图片,把label设置为 。这里 代表真值。有了数据和标签,就完成了设计。
我们会发现,这种方法比刚才的滑动窗口分类方法简单太多了。这一版的思路我把它叫做YOLO v0,因为它是You Only Look Once最简单的版本。
4 YOLO v1终于诞生
需求1:YOLO v0只能输出一个目标,那比如下图4的多个目标怎么办呢?

图4:多个目标情况
你可能会回答:我输出N个向量不就行了吗?但具体输出多少个合适呢?图4有7个目标,那有的图片有几百个目标,你这个N又该如何调整呢?
答:为了保证所有目标都被检测到,我们应该输出尽量多的目标。

但这种方法也不是最优的,最优的应该是下图这样:

图5:用一个(c,x,y,w,h)去负责image某个区域的目标
如图5所示,用一个(c,x,y,w,h)去负责image某个区域的目标。
比如说图片设置为16个区域,每个区域用1个(c,x,y,w,h)去负责:
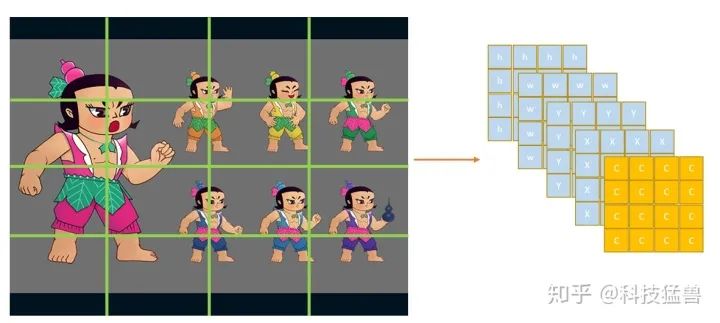
图6:图片设置为16个区域
就可以一次输出16个框,每个框是1个(c,x,y,w,h),如图6所示。
为什么这样子更优?因为conv操作是位置强相关的,就是原来的目标在哪里,你conv之后的feature map上还在哪里,所以图片划分为16个区域,结果也应该分布在16个区域上,所以我们的结果(Tensor)的维度size是:(5,4,4)。
那现在你可能会问:c的真值该怎么设置呢?
答:看葫芦娃的大娃,他的脸跨了4个区域(grid),但只能某一个grid的c=1,其他的c=0。那么该让哪一个grid的c=1呢?就看他的脸的中心落在了哪个grid里面。根据这一原则,c的真值为下图7所示:

但是你发现7个葫芦娃只有6个1,原因是某一个grid里面有2个目标,确实如此,第三行第三列的grid既有水娃又有隐身娃。这种一个区域有多个目标的情况我们目前没法解决,因为我们的模型现在能力就这么大,只能在一个区域中检测出一个目标,如何改进我们马上就讨论,你可以现在先自己想一想。
总之现在我们设计出了模型的输出结果,那距离完成模型的设计还差一个损失函数,那Loss咋设计呢?看下面的伪代码:
loss = 0
for img in img_all:
for i in range(4):
for j in range(4):
loss_ij = lamda_1*(c_pred-c_label)**2 + c_label*(x_pred-x_label)**2 +\
c_label*(y_pred-y_label)**2 + c_label*(w_pred-w_label)**2 + \
c_label*(h_pred-h_label)**2
loss += loss_ij
loss.backward()遍历所有图片,遍历所有位置,计算loss。
好现在模型设计完了,回到刚才的问题:模型现在能力就这么大,只能在一个区域中检测出一个目标,如何改进?
答:刚才区域是 ,现在变成 ,或者更大,使区域更密集,就可以缓解多个目标的问题,但无法从根本上去解决。
另一个问题,按上面的设计你检测得到了16个框,可是图片上只有7个葫芦娃的脸,怎么从16个结果中筛选出7个我们要的呢?
答:
法1:聚类。聚成7类,在这7个类中,选择confidence最大的框。听起来挺好。
法1的bug:2个目标本身比较近聚成了1个类怎么办?如果不知道到底有几个目标呢?为何聚成7类?不是3类?
法2:NMS(非极大值抑制)。2个框重合度很高,大概率是一个目标,那就只取一个框。
重合度的计算方法:交并比IoU=两个框的交集面积/两个框的并集面积。
具体算法:

面试必考的NMS
法1的bug:2个目标本身比较近怎么办?依然没有解决。
如果不知道到底有几个目标呢?NMS自动解决了这个问题。
面试的时候会问这样一个问题:NMS的适用情况是什么?
答:1图多目标检测时用NMS。
到现在为止我们终于解决了第4节开始提出的多个目标的问题,现在又有了新的需求:
需求2:多类的目标怎么办呢?
比如说我现在既要你检测葫芦娃的脸,又要你检测葫芦娃的葫芦,怎么设计?
img cbrp16 cbrp32 cbrp64 cbrp128 ... fc256-fc[5+2]*N [c,x,y,w,h,one-hot]*N
2个类,one-hot就是[0,1],[1,0]这样子,如下图8所示:

图8:多类的目标的label
伪代码依然是:
loss = 0
for img in img_all:
for i in range(3):
for j in range(4):
c_loss = lamda_1*(c_pred-c_label)**2
geo_loss = c_label*(x_pred-x_label)**2 +\
c_label*(y_pred-y_label)**2 + c_label*(w_pred-w_label)**2 + \
c_label*(h_pred-h_label)**2
class_loss = 1/m * mse_loss(p_pred, p_label)
loss_ij =c_loss + geo_loss + class_loss
loss += loss_ij
loss.backward()至此,多个类的问题也解决了,现在又有了新的需求:
需求3:小目标检测怎么办呢?
小目标总是检测不佳,所以我们专门设计神经元去拟合小目标。
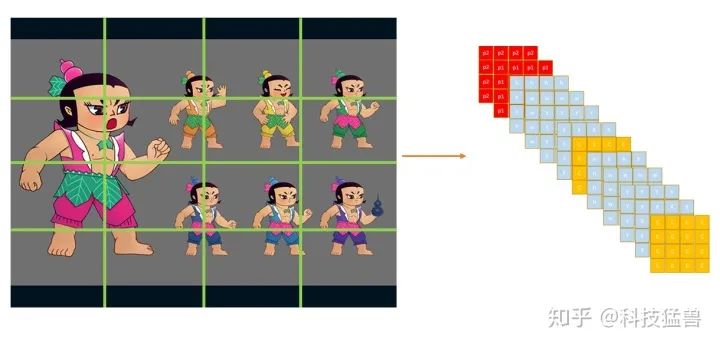
图9:多类的小目标的label,分别预测大目标和小目标
对于每个区域,我们用2个五元组(c,x,y,w,h),一个负责回归大目标,一个负责回归小目标,同样添加one-hot vector,one-hot就是[0,1],[1,0]这样子,来表示属于哪一类(葫芦娃的头or葫芦娃的葫芦)。
伪代码变为了:
loss = 0
for img in img_all:
for i in range(3):
for j in range(4):
c_loss = lamda_1*(c_pred-c_label)**2
geo_loss = c_label_big*(x_big_pred-x_big_label)**2 +\
c_label_big*(y_big_pred-y_big_label)**2 + c_label_big*(w_big_pred-w_big_label)**2 + \
c_label_big*(h_big_pred-h_big_label)**2 +\
c_label_small*(x_small_pred-x_small_label)**2 +\
c_label_small*(y_small_pred-y_small_label)**2 + c_label_small*(w_small_pred-w_small_label)**2 + \
c_label_small*(h_small_pred-h_small_label)**2
class_loss = 1/m * mse_loss(p_pred, p_label)
loss_ij =c_loss + geo_loss + class_loss
loss += loss_ij
loss.backward()至此,小目标的问题也有了解决方案。
到这里,我们设计的检测器其实就是YOLO v1,只是有的参数跟它不一样,我们看论文里的图:
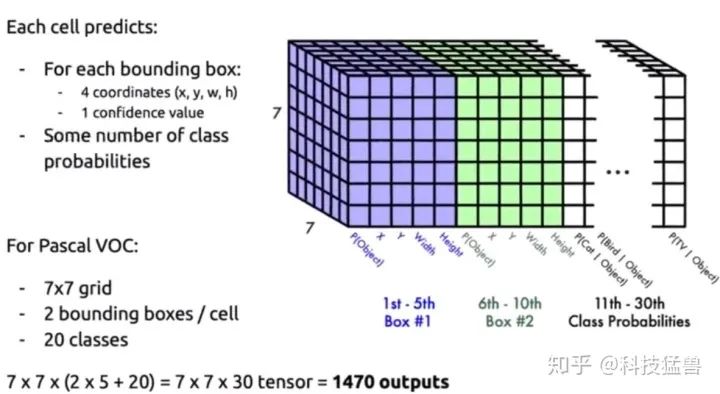
YOLO v1
YOLO v1
YOLO v1其实就是把我们划分的16个区域变成了 个区域,我们预测16个目标,YOLO v1预测49个目标。我们是2类(葫芦娃的头or葫芦娃的葫芦),YOLO v1是20类。
backbone也是一堆卷积+检测头(FC层),所以说设计到现在,我们其实是把YOLO v1给设计出来了。
再看看作者的解释:

发现train的时候用的小图片,检测的时候用的是大图片(肯定是经过了无数次试验证明了效果好)。
结构学完了,再看loss函数,并比较下和我们设计的loss函数有什么区别。

YOLO v1 loss函数
解读一下这个损失函数:
我们之前说的损失函数是设计了3个for循环,而作者为了方便写成了求和的形式:
前2行计算前景的geo_loss。
第3行计算前景的confidence_loss。
第4行计算背景的confidence_loss。
第5行计算分类损失class_loss。
伪代码上面已经有了,现在我们总体看一下这个模型:
img cbrp192 cbrp256 cbrp512 cbrp1024 ... fc4096-fc[5+2]*N
检测层的设计:回归坐标值+one-hot分类

检测层的设计
样本不均衡的问题解决了吗?
没有计算背景的geo_loss,只计算了前景的geo_loss,这个问题YOLO v1回避了,依然存在。
最后我们解读下YOLO v1的代码:
1.模型定义:
定义特征提取层:
class VGG(nn.Module):
def __init__(self):
super(VGG,self).__init__()
# the vgg's layers
#self.features = features
cfg = [64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512,512,512,'M']
layers= []
batch_norm = False
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2,stride = 2)]
else:
conv2d = nn.Conv2d(in_channels,v,kernel_size=3,padding = 1)
if batch_norm:
layers += [conv2d,nn.Batchnorm2d(v),nn.ReLU(inplace=True)]
else:
layers += [conv2d,nn.ReLU(inplace=True)]
in_channels = v
# use the vgg layers to get the feature
self.features = nn.Sequential(*layers)
# 全局池化
self.avgpool = nn.AdaptiveAvgPool2d((7,7))
# 决策层:分类层
self.classifier = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096,4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096,1000),
)
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.BatchNorm2d):
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias,1)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.constant_(m.bias,0)
def forward(self,x):
x = self.features(x)
x_fea = x
x = self.avgpool(x)
x_avg = x
x = x.view(x.size(0),-1)
x = self.classifier(x)
return x,x_fea,x_avg
def extractor(self,x):
x = self.features(x)
return x定义检测头:
self.detector = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096,1470),
)整体模型:
class YOLOV1(nn.Module):
def __init__(self):
super(YOLOV1,self).__init__()
vgg = VGG()
self.extractor = vgg.extractor
self.avgpool = nn.AdaptiveAvgPool2d((7,7))
# 决策层:检测层
self.detector = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(True),
nn.Dropout(),
#nn.Linear(4096,1470),
nn.Linear(4096,245),
#nn.Linear(4096,5),
)
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.BatchNorm2d):
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias,1)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.constant_(m.bias,0)
def forward(self,x):
x = self.extractor(x)
#import pdb
#pdb.set_trace()
x = self.avgpool(x)
x = x.view(x.size(0),-1)
x = self.detector(x)
b,_ = x.shape
#x = x.view(b,7,7,30)
x = x.view(b,7,7,5)
#x = x.view(b,1,1,5)
return x主函数:
if __name__ == '__main__':
vgg = VGG()
x = torch.randn(1,3,512,512)
feature,x_fea,x_avg = vgg(x)
print(feature.shape)
print(x_fea.shape)
print(x_avg.shape)
yolov1 = YOLOV1()
feature = yolov1(x)
# feature_size b*7*7*30
print(feature.shape)2.模型训练:
主函数:
if __name__ == "__main__":
train()下面看train()函数:
def train():
for epoch in range(epochs):
ts = time.time()
for iter, batch in enumerate(train_loader):
optimizer.zero_grad()
# 取图片
inputs = input_process(batch)
# 取标注
labels = target_process(batch)
# 获取得到输出
outputs = yolov1_model(inputs)
#import pdb
#pdb.set_trace()
#loss = criterion(outputs, labels)
loss,lm,glm,clm = lossfunc_details(outputs,labels)
loss.backward()
optimizer.step()
#print(torch.cat([outputs.detach().view(1,5),labels.view(1,5)],0).view(2,5))
if iter % 10 == 0:
# print(torch.cat([outputs.detach().view(1,5),labels.view(1,5)],0).view(2,5))
print("epoch{}, iter{}, loss: {}, lr: {}".format(epoch, iter, loss.data.item(),optimizer.state_dict()['param_groups'][0]['lr']))
#print("Finish epoch {}, time elapsed {}".format(epoch, time.time() - ts))
#print("*"*30)
#val(epoch)
scheduler.step()训练过程比较常规,先取1个batch的训练数据,分别得到inputs和labels,依次计算loss,反传,step等。
下面说下2个训练集的数据处理函数:
input_process:
def input_process(batch):
#import pdb
#pdb.set_trace()
batch_size=len(batch[0])
input_batch= torch.zeros(batch_size,3,448,448)
for i in range(batch_size):
inputs_tmp = Variable(batch[0][i])
inputs_tmp1=cv2.resize(inputs_tmp.permute([1,2,0]).numpy(),(448,448))
inputs_tmp2=torch.tensor(inputs_tmp1).permute([2,0,1])
input_batch[i:i+1,:,:,:]= torch.unsqueeze(inputs_tmp2,0)
return input_batchbatch[0]为image,batch[1]为label,batch_size为1个batch的图片数量。
batch[0][i]为这个batch的第i张图片,inputs_tmp2为尺寸变成了3,448,448之后的图片,再经过unsqueeze操作拓展1维,size=[1,3,448,448],存储在input_batch中。
最后,返回的是size=[batch_size,3,448,448]的输入数据。
target_process:
def target_process(batch,grid_number=7):
# batch[1]表示label
# batch[0]表示image
batch_size=len(batch[0])
target_batch= torch.zeros(batch_size,grid_number,grid_number,30)
#import pdb
#pdb.set_trace()
for i in range(batch_size):
labels = batch[1]
batch_labels = labels[i]
#import pdb
#pdb.set_trace()
number_box = len(batch_labels['boxes'])
for wi in range(grid_number):
for hi in range(grid_number):
# 遍历每个标注的框
for bi in range(number_box):
bbox=batch_labels['boxes'][bi]
_,himg,wimg = batch[0][i].numpy().shape
bbox = bbox/ torch.tensor([wimg,himg,wimg,himg])
#import pdb
#pdb.set_trace()
center_x= (bbox[0]+bbox[2])*0.5
center_y= (bbox[1]+bbox[3])*0.5
#print("[%s,%s,%s],[%s,%s,%s]"%(wi/grid_number,center_x,(wi+1)/grid_number,hi/grid_number,center_y,(hi+1)/grid_number))
if center_x<=(wi+1)/grid_number and center_x>=wi/grid_number and center_y<=(hi+1)/grid_number and center_y>= hi/grid_number:
#pdb.set_trace()
cbbox = torch.cat([torch.ones(1),bbox])
# 中心点落在grid内,
target_batch[i:i+1,wi:wi+1,hi:hi+1,:] = torch.unsqueeze(cbbox,0)
#else:
#cbbox = torch.cat([torch.zeros(1),bbox])
#import pdb
#pdb.set_trace()
#rint(target_batch[i:i+1,wi:wi+1,hi:hi+1,:])
#target_batch[i:i+1,wi:wi+1,hi:hi+1,:] = torch.unsqueeze(cbbox,0)
return target_batch要从batch里面获得label,首先要想清楚label(就是bounding box)应该是什么size,输出的结果应该是 的,所以label的size应该是:[batch_size,7,7,30]。在这个程序里我们实现的是输出 。这个 就是x,y,w,h,所以label的size应该是:[batch_size,7,7,5]
batch_labels表示这个batch的第i个图片的label,number_box表示这个图有几个真值框。
接下来3重循环遍历每个grid的每个框,bbox表示正在遍历的这个框。
bbox = bbox/ torch.tensor([wimg,himg,wimg,himg])表示对x,y,w,h进行归一化。
接下来if语句得到confidence的真值,存储在target_batch中返回。
最后是loss函数:
def lossfunc_details(outputs,labels):
# 判断维度
assert ( outputs.shape == labels.shape),"outputs shape[%s] not equal labels shape[%s]"%(outputs.shape,labels.shape)
#import pdb
#pdb.set_trace()
b,w,h,c = outputs.shape
loss = 0
#import pdb
#pdb.set_trace()
conf_loss_matrix = torch.zeros(b,w,h)
geo_loss_matrix = torch.zeros(b,w,h)
loss_matrix = torch.zeros(b,w,h)
for bi in range(b):
for wi in range(w):
for hi in range(h):
#import pdb
#pdb.set_trace()
# detect_vector=[confidence,x,y,w,h]
detect_vector = outputs[bi,wi,hi]
gt_dv = labels[bi,wi,hi]
conf_pred = detect_vector[0]
conf_gt = gt_dv[0]
x_pred = detect_vector[1]
x_gt = gt_dv[1]
y_pred = detect_vector[2]
y_gt = gt_dv[2]
w_pred = detect_vector[3]
w_gt = gt_dv[3]
h_pred = detect_vector[4]
h_gt = gt_dv[4]
loss_confidence = (conf_pred-conf_gt)**2
#loss_geo = (x_pred-x_gt)**2 + (y_pred-y_gt)**2 + (w_pred**0.5-w_gt**0.5)**2 + (h_pred**0.5-h_gt**0.5)**2
loss_geo = (x_pred-x_gt)**2 + (y_pred-y_gt)**2 + (w_pred-w_gt)**2 + (h_pred-h_gt)**2
loss_geo = conf_gt*loss_geo
loss_tmp = loss_confidence + 0.3*loss_geo
#print("loss[%s,%s] = %s,%s"%(wi,hi,loss_confidence.item(),loss_geo.item()))
loss += loss_tmp
conf_loss_matrix[bi,wi,hi]=loss_confidence
geo_loss_matrix[bi,wi,hi]=loss_geo
loss_matrix[bi,wi,hi]=loss_tmp
#打印出batch中每张片的位置loss,和置信度输出
print(geo_loss_matrix)
print(outputs[0,:,:,0]>0.5)
return loss,loss_matrix,geo_loss_matrix,conf_loss_matrix首先需要注意:label和output的size应该是:[batch_size,7,7,5]。
outputs[bi,wi,hi]就是一个5位向量: 。
我们分别计算了loss_confidence和loss_geo,因为我们实现的这个模型只检测1个类,所以没有class_loss。
总结:
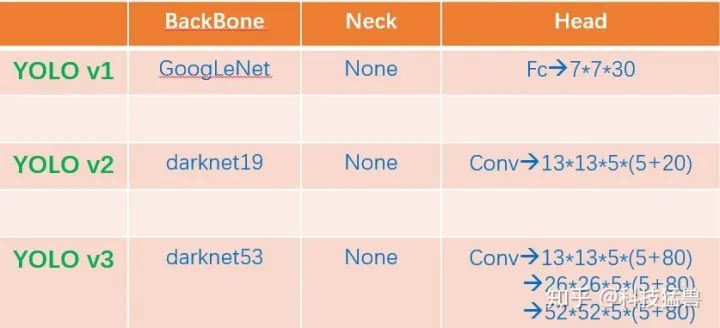
YOLO v1:直接回归出位置。
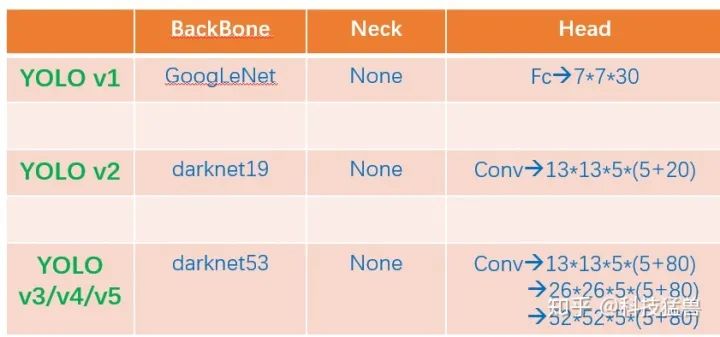
YOLO v2:全流程多尺度方法。
YOLO v3:多尺度检测头,resblock darknet53
YOLO v4:cspdarknet53,spp,panet,tricks
接下来,先回顾下YOLO v1的模型结构,如下面2图所示:
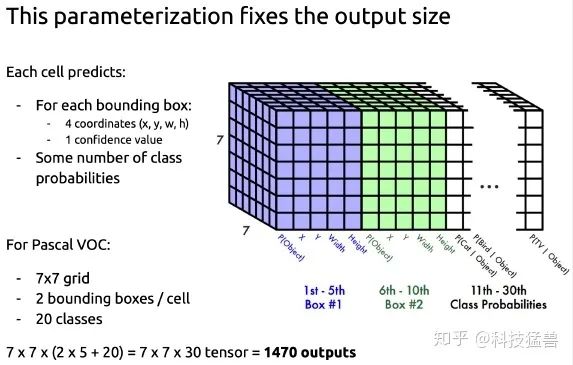
YOLO
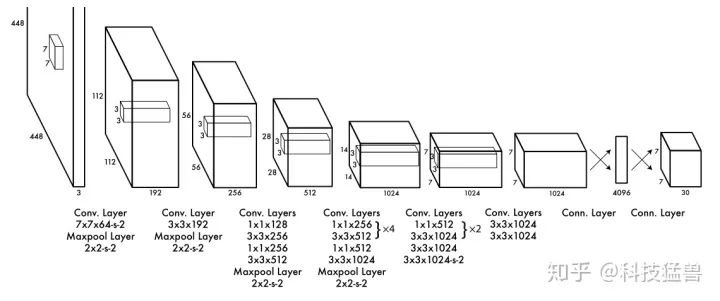
YOLO
我们认为,检测模型=特征提取器+检测头
在YOLO v1的模型中检测头就是最后的2个全连接层(Linear in PyTorch),它们是参数量最大的2个层,也是最值得改进的2个层。后面的YOLO模型都对这里进行改进:
YOLO v1一共预测49个目标,一共98个框。
5 YOLO v2
检测头的改进:
YOLO v1虽然快,但是预测的框不准确,很多目标找不到:
预测的框不准确:准确度不足。
很多目标找不到:recall不足。
我们一个问题一个问题解决,首先第1个:
问题1:预测的框不准确:
当时别人是怎么做的?
同时代的检测器有R-CNN,人家预测的是偏移量。
什么是偏移量?
YOLO v2
之前YOLO v1直接预测x,y,w,h,范围比较大,现在我们想预测一个稍微小一点的值,来增加准确度。
不得不先介绍2个新概念:基于grid的偏移量和基于anchor的偏移量。什么意思呢?
基于anchor的偏移量的意思是,anchor的位置是固定的,偏移量=目标位置-anchor的位置。
基于grid的偏移量的意思是,grid的位置是固定的,偏移量=目标位置-grid的位置。
Anchor是什么玩意?
Anchor是R-CNN系列的一个概念,你可以把它理解为一个预先定义好的框,它的位置,宽高都是已知的,是一个参照物,供我们预测时参考。
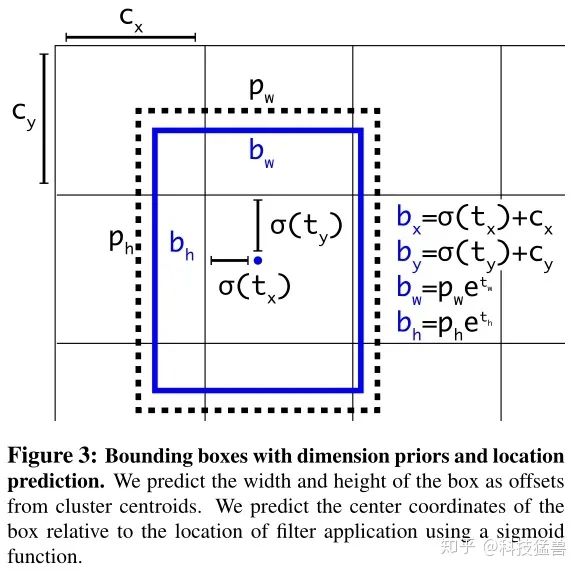
上面的图就是YOLO v2给出的改进,你可能现在看得一脸懵逼,我先解释下各个字母的含义:
:模型最终得到的的检测结果。
:模型要预测的值。
:grid的左上角坐标,如下图所示。
:Anchor的宽和高,这里的anchor是人为定好的一个框,宽和高是固定的。

通过这样的定义我们从直接预测位置改为预测一个偏移量,基于Anchor框的宽和高和grid的先验位置的偏移量,得到最终目标的位置,这种方法也叫作location prediction。
这里还涉及到一个尺寸问题:
刚才说到 是模型要预测的值,这里 为grid的坐标,画个图就明白了:
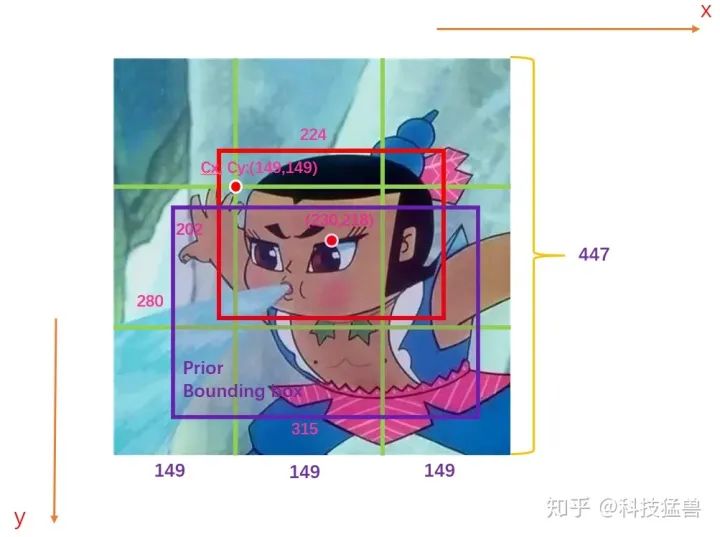
图1:原始值
如图1所示,假设此图分为9个grid,GT如红色的框所示,Anchor如紫色的框所示。图中的数字为image的真实信息。
我们首先会对这些值归一化,结果如下图2所示:
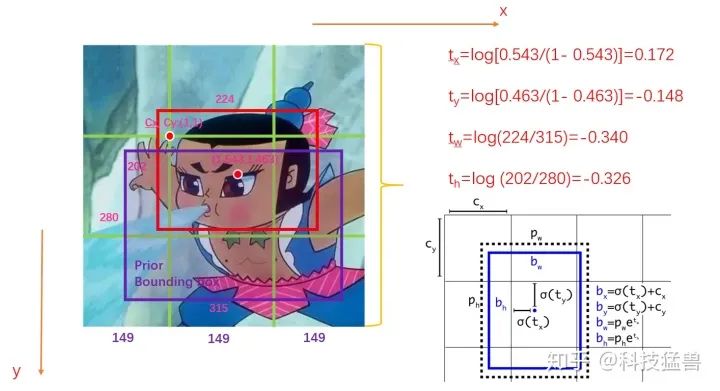
图2:要预测的值
归一化之后你会发现,要预测的值就变为了:
这是一个偏移量,且值很小,有利于神经网络的学习。
**你可能会有疑问:**为什么YOLO v2改预测偏移量而不是直接去预测 ?
上面我说了作者看到了同时代的R-CNN,人家预测的是偏移量。另一个重要的原因是:直接预测位置会导致神经网络在一开始训练时不稳定,使用偏移量会使得训练过程更加稳定,性能指标提升了5%左右。
位置上不使用Anchor框,宽高上使用Anchor框。以上就是YOLO v2的一个改进。用了YOLO v2的改进之后确实是更准确了,但别激动,上面还有一个问题呢~
问题2:很多目标找不到:
你还记得上一篇讲得YOLO v1一次能检测多少个目标吗?答案是49个目标,98个框,并且2个框对应一个类别。可以是大目标也可以是小目标。因为输出的尺寸是:[N, 7, 7, 30]。式中N为图片数量,7,7为49个区域(grid)。
YOLO v2首先把 个区域改为 个区域,每个区域有5个anchor,且每个anchor对应着1个类别,那么,输出的尺寸就应该为:[N,13,13,125]。
这里面有个bug,就是YOLO v2先对每个区域得到了5个anchor作为参考,那你就会问了:每个区域的5个anchor是如何得到的?
下图可以回答你的问题:
methods to get the 5 anchor
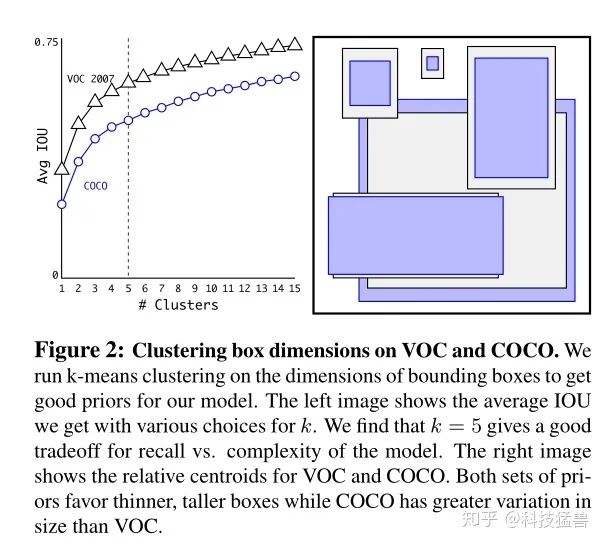
方法:对于任意一个数据集,就比如说COCO吧(紫色的anchor),先对训练集的GT bounding box进行聚类,聚成几类呢?作者进行了实验之后发现5类的recall vs. complexity比较好,现在聚成了5类,当然9类的mAP最好,预测的最全面,但是在复杂度上升很多的同时对模型的准确度提升不大,所以采用了一个比较折中的办法选取了5个聚类簇,即使用5个先验框。
所以到现在为止,有了anchor再结合刚才的 ,就可以求出目标位置。
anchor是从数据集中统计得到的。
损失函数为:
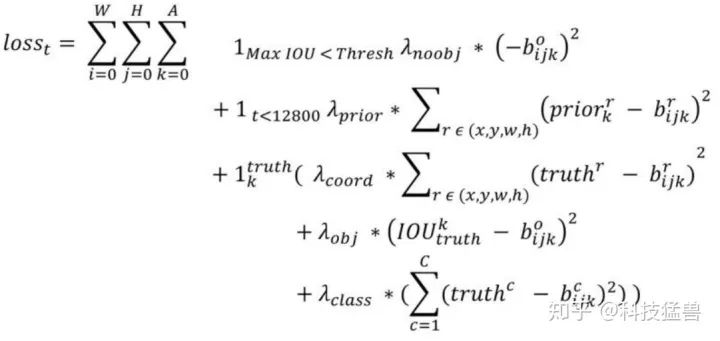
YOLO v2损失函数
这里的W=13,H=13,A=5。
每个都是一个权重值。c表示类别,r表示rectangle,即(x,y,w,h)。
第1,4行是confidence_loss,注意这里的真值变成了0和IoU(GT, anchor)的值,你看看这些细节......
第5行是class_loss。
第2,3行:t是迭代次数,即前12800步我们计算这个损失,后面不计算了。这部分意义何在?
意思是:前12800步我们会优化预测的(x,y,w,h)与anchor的(x,y,w,h)的距离+预测的(x,y,w,h)与GT的(x,y,w,h)的距离,12800步之后就只优化预测的(x,y,w,h)与GT的(x,y,w,h)的距离,为啥?因为这时的预测结果已经较为准确了,anchor已经满足我了我们了,而在一开始预测不准的时候,用上anchor可以加速训练。
你看看这操作多么的细节......
是什么?第k个anchor与所有GT的IoU的maximum,如果大于一个阈值,就,否则的话:。
好,到现在为止,YOLO v2做了这么多改进,整体性能大幅度提高,但是小目标检测仍然是YOLO v2的痛。直到kaiming大神的ResNet出现,backbone可以更深了,所以darknet53诞生。
最后我们做个比较:

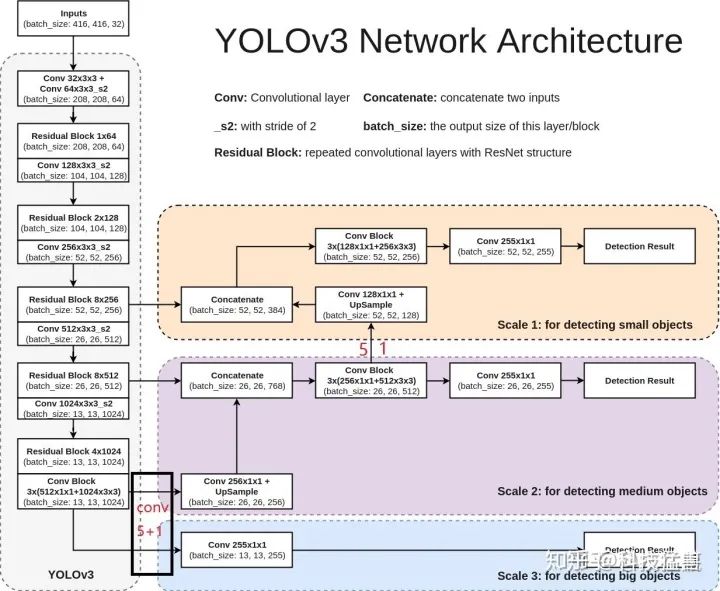
6 YOLO v3
检测头的改进:
之前在说小目标检测仍然是YOLO v2的痛,YOLO v3是如何改进的呢?如下图所示。
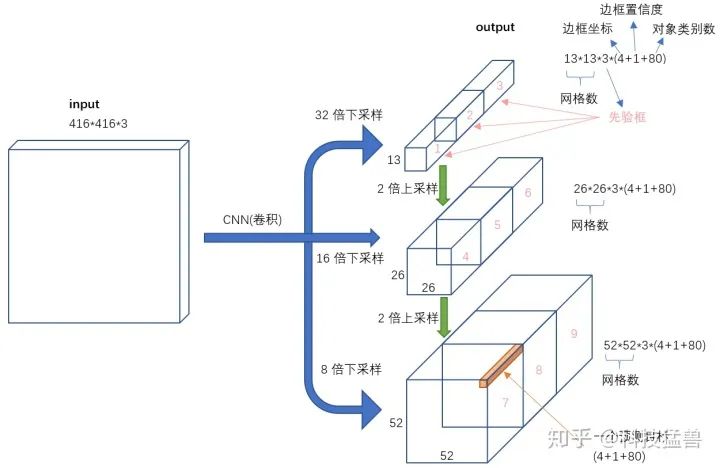
YOLO v3
我们知道,YOLO v2的检测头已经由YOLO v1的 变为 了,我们看YOLO v3检测头分叉了,分成了3部分:
13*13*3*(4+1+80)
26*26*3*(4+1+80)
52*52*3*(4+1+80)
预测的框更多更全面了,并且分级了。
我们发现3个分支分别为32倍下采样,16倍下采样,8倍下采样,分别取预测大,中,小目标。为什么这样子安排呢?
因为32倍下采样每个点感受野更大,所以去预测大目标,8倍下采样每个点感受野最小,所以去预测小目标。专人专事。
发现预测得更准确了,性能又提升了。
又有人会问,你现在是3个分支,我改成5个,6个分支会不会更好?
理论上会,但还是那句话,作者遵循recall vs. complexity的trade off。
图中的123456789是什么意思?
答:框。每个grid设置9个先验框,3个大的,3个中的,3个小的。
每个分支预测3个框,每个框预测5元组+80个one-hot vector类别,所以一共size是:
3*(4+1+80)
每个分支的输出size为:
[13,13,3*(4+1+80)]
[26,26,3*(4+1+80)]
[52,52,3*(4+1+80)]
当然你也可以用5个先验框,这时每个分支的输出size为:
[13,13,5*(4+1+80)]
[26,26,5*(4+1+80)]
[52,52,5*(4+1+80)]
就对应了下面这个图:
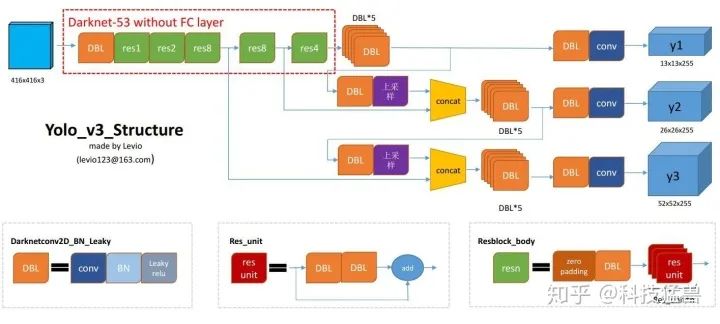
YOLO v3
检测头是DBL,定义在图上,没有了FC。
还有一种画法,更加直观一点:
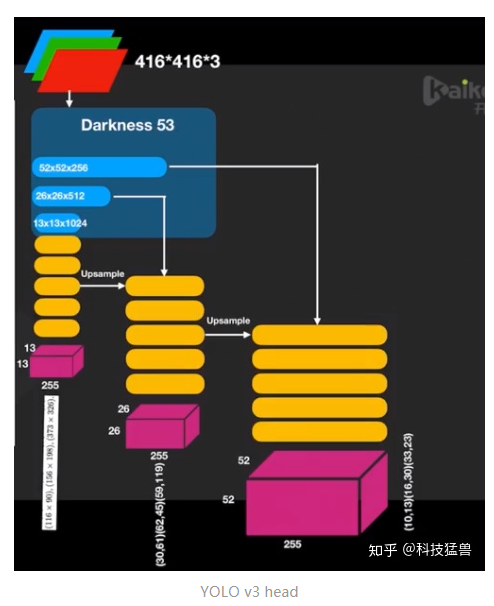
anchor和YOLO v2一样,依然是从数据集中统计得到的。
损失函数为:
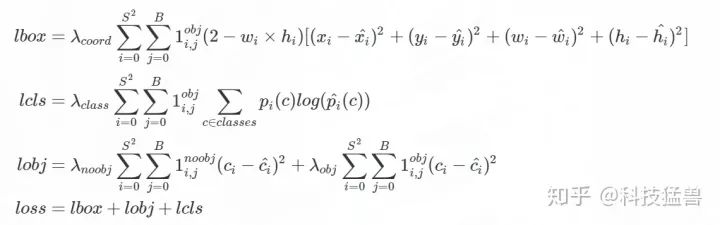
YOLO v3损失函数
第4行说明:loss分3部分组成。
第1行代表geo_loss,S代表13,26,52,就是grid是几乘几的。B=5。
第2行代表class_loss,和YOLO v2的区别是改成了交叉熵。
第3行代表confidence_loss,和YOLO v2一模一样。
最后我们做个比较:
YOLO v1 v2和v3的比较
7 疫情都挡不住的YOLO v4
第一次看到YOLO v4公众号发文是在疫情期间,那时候还来不了学校。不得不说疫情也挡不住作者科研的动力。。。
检测头的改进:
YOLO v4的作者换成了Alexey Bochkovskiy大神,检测头总的来说还是多尺度的,3个尺度,分别负责大中小目标。只不过多了一些细节的改进:
1.Using multi-anchors for single ground truth
之前的YOLO v3是1个anchor负责一个GT,YOLO v4中用多个anchor去负责一个GT。方法是:对于 来说,只要 ,就让 去负责 。
这就相当于你anchor框的数量没变,但是选择的正样本的比例增加了,就缓解了正负样本不均衡的问题。
2.Eliminate_grid sensitivity
还记得之前的YOLO v2的这幅图吗?YOLO v2,YOLO v3都是预测4个这样的偏移量
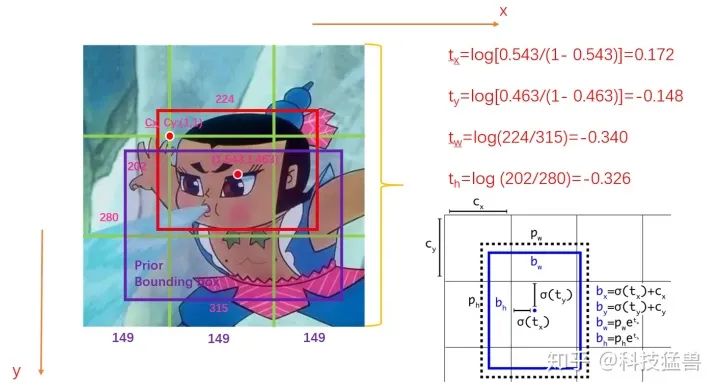
图3:YOLO v2,YOLO v3要预测的值
这里其实还隐藏着一个问题:
模型预测的结果是: ,那么最终的结果是: 。这个 按理说应该能取到一个grid里面的任意位置。但是实际上边界的位置是取不到的,因为sigmoid函数的值域是: ,它不是 。所以作者提出的Eliminate_grid sensitivity的意思是:将 的计算公式改为:
这里的1.1就是一个示例,你也可以是1.05,1.2等等,反正要乘上一个略大于1的数,作者发现经过这样的改动以后效果会再次提升。
3.CIoU-loss
之前的YOLO v2,YOLO v3在计算geo_loss时都是用的MSE Loss,之后人们开始使用IoU Loss。
它可以反映预测检测框与真实检测框的检测效果。
但是问题也很多:不能反映两者的距离大小(重合度)。同时因为loss=0,没有梯度回传,无法进行学习训练。如下图4所示,三种情况IoU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差:
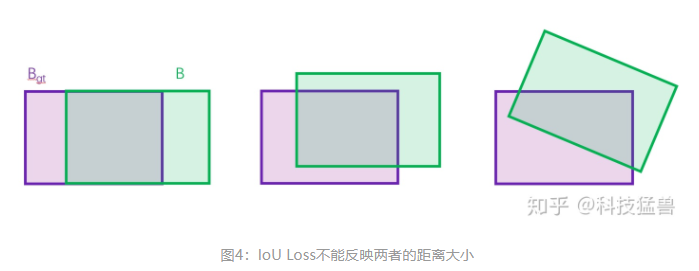
所以接下来的改进是:
, 为同时包含了预测框和真实框的最小框的面积。
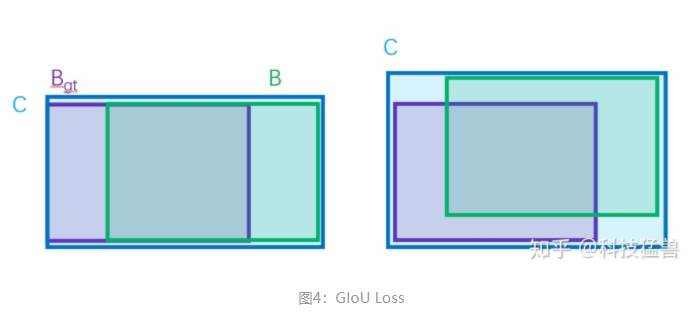
GIoU Loss可以解决上面IoU Loss对距离不敏感的问题。但是GIoU Loss存在训练过程中发散等问题。
接下来的改进是:
其中, , 分别代表了预测框和真实框的中心点,且代表的是计算两个中心点间的欧式距离。代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
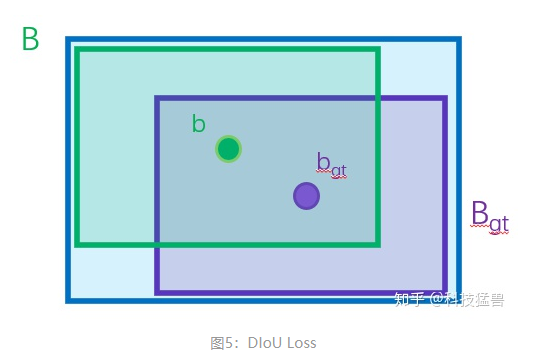
DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
但是DIoU loss依然存在包含的问题,即:
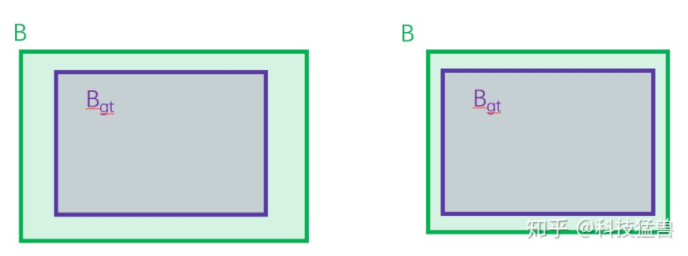
这2种情况 和 是重合的,DIoU loss的第3项没有区别,所以在这个意义上DIoU loss依然存在问题。
接下来的改进是:
惩罚项如下面公式:
其中 是权重函数,
而 用来度量长宽比的相似性,定义为
完整的 CIoU 损失函数定义:
最后,CIoU loss的梯度类似于DIoU loss,但还要考虑 的梯度。在长宽在 的情况下, 的值通常很小,会导致梯度爆炸,因此在 实现时将替换成1。
CIoU loss实现代码:
def bbox_overlaps_ciou(bboxes1, bboxes2):
rows = bboxes1.shape[0]
cols = bboxes2.shape[0]
cious = torch.zeros((rows, cols))
if rows * cols == 0:
return cious
exchange = False
if bboxes1.shape[0] > bboxes2.shape[0]:
bboxes1, bboxes2 = bboxes2, bboxes1
cious = torch.zeros((cols, rows))
exchange = True
w1 = bboxes1[:, 2] - bboxes1[:, 0]
h1 = bboxes1[:, 3] - bboxes1[:, 1]
w2 = bboxes2[:, 2] - bboxes2[:, 0]
h2 = bboxes2[:, 3] - bboxes2[:, 1]
area1 = w1 * h1
area2 = w2 * h2
center_x1 = (bboxes1[:, 2] + bboxes1[:, 0]) / 2
center_y1 = (bboxes1[:, 3] + bboxes1[:, 1]) / 2
center_x2 = (bboxes2[:, 2] + bboxes2[:, 0]) / 2
center_y2 = (bboxes2[:, 3] + bboxes2[:, 1]) / 2
inter_max_xy = torch.min(bboxes1[:, 2:],bboxes2[:, 2:])
inter_min_xy = torch.max(bboxes1[:, :2],bboxes2[:, :2])
out_max_xy = torch.max(bboxes1[:, 2:],bboxes2[:, 2:])
out_min_xy = torch.min(bboxes1[:, :2],bboxes2[:, :2])
inter = torch.clamp((inter_max_xy - inter_min_xy), min=0)
inter_area = inter[:, 0] * inter[:, 1]
inter_diag = (center_x2 - center_x1)**2 + (center_y2 - center_y1)**2
outer = torch.clamp((out_max_xy - out_min_xy), min=0)
outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)
union = area1+area2-inter_area
u = (inter_diag) / outer_diag
iou = inter_area / union
with torch.no_grad():
arctan = torch.atan(w2 / h2) - torch.atan(w1 / h1)
v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(w2 / h2) - torch.atan(w1 / h1)), 2)
S = 1 - iou
alpha = v / (S + v)
w_temp = 2 * w1
ar = (8 / (math.pi ** 2)) * arctan * ((w1 - w_temp) * h1)
cious = iou - (u + alpha * ar)
cious = torch.clamp(cious,min=-1.0,max = 1.0)
if exchange:
cious = cious.T
return cious所以最终的演化过程是:
MSE Loss IoU Loss GIoU Loss DIoU Loss CIoU Loss
8 代码比论文都早的YOLO v5
检测头的改进:
head部分没有任何改动,和yolov3和yolov4完全相同,也是三个输出头,stride分别是8,16,32,大输出特征图检测小物体,小输出特征图检测大物体。
但采用了自适应anchor,而且这个功能还可以手动打开/关掉,具体是什么意思呢?
加上了自适应anchor的功能,个人感觉YOLO v5其实变成了2阶段方法。
先回顾下之前的检测器得到anchor的方法:
Yolo v2 v3 v4:聚类得到anchor,不是完全基于anchor的,w,h是基于anchor的,而x,y是基于grid的坐标,所以人家叫location prediction。
R-CNN系列:手动指定anchor的位置。
基于anchor的方法是怎么用的:

anchor是怎么用的
有了anchor的 ,和我们预测的偏移量 ,就可以计算出最终的output: 。
之前anchor是固定的,自适应anchor利用网络的学习功能,让 也是可以学习的。我个人觉得自适应anchor策略,影响应该不是很大,除非是刚开始设置的anchor是随意设置的,一般我们都会基于实际项目数据重新运用kmean算法聚类得到anchor,这一步本身就不能少。
最后总结一下:
目标检测器模型的结构如下图1所示,之前看过了YOLO v2 v3 v4 v5对于检测头和loss函数的改进,如下图2所示,下面着重介绍backbone的改进:
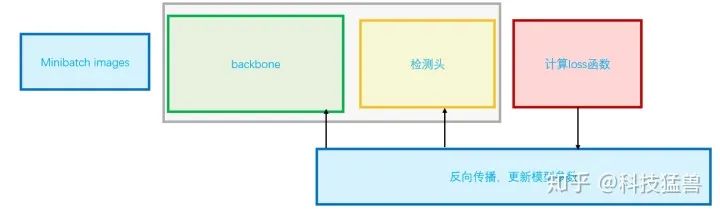
图1:检测器的结构

图2:YOLO系列比较
我们发现YOLO v1只是把最后的特征分成了 个grid,到了YOLO v2就变成了 个grid,再到YOLO v3 v4 v5就变成了多尺度的**(strides=8,16,32),更加复杂了。
那为什么一代比一代检测头更加复杂呢?答案是:因为它们的提特征网络更加强大了,能够支撑起检测头做更加复杂的操作。**换句话说,如果没有backbone方面的优化,你即使用这么复杂的检测头,可能性能还会更弱。所以引出了今天的话题:backbone的改进。
9 YOLO v1
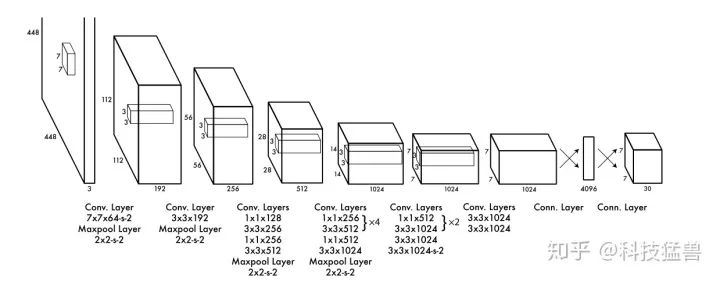
我们先看看YOLO v1的backbone长什么样子:
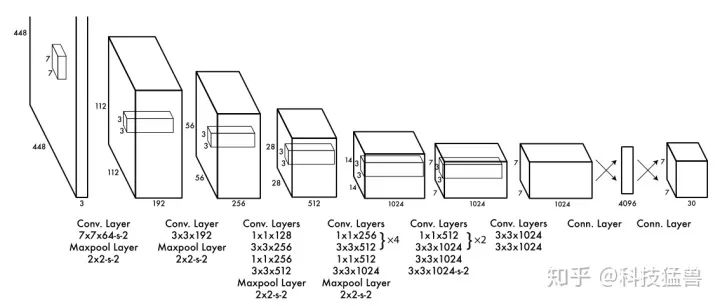
YOLO v1 backbone
最后2层是全连接层,其他使用了大量的卷积层,网络逐渐变宽,是非常标准化的操作。注意这里面试官可能会问你一个问题:为什么都是卷积,图上要分开画出来,不写在一起?答案是:按照feature map的分辨率画出来。分辨率A变化到分辨率B的所有卷积画在了一起。因为写代码时经常会这么做,所以问这个问题的意图是看看你是否经常写代码。
然后我们看下检测类网络的结构,如下图3所示,这个图是YOLO v4中总结的:
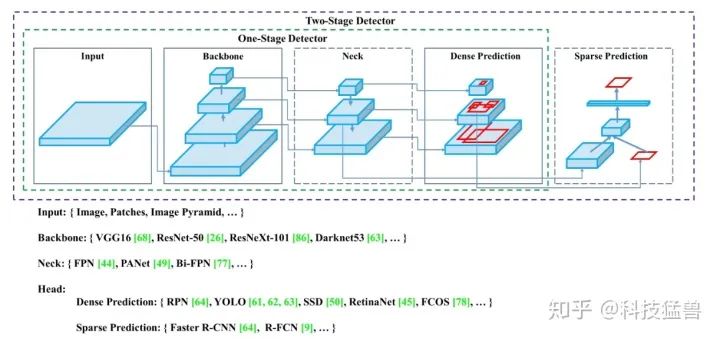
图3:检测类网络的结构
YOLO v1没有Neck,Backbone是GoogLeNet,属于Dense Prediction。1阶段的检测器属于Dense Prediction,而2阶段的检测器既有Dense Prediction,又有Sparse Prediction。
10 YOLO v2
为了进一步提升性能,YOLO v2重新训练了一个darknet-19,如下图4所示:
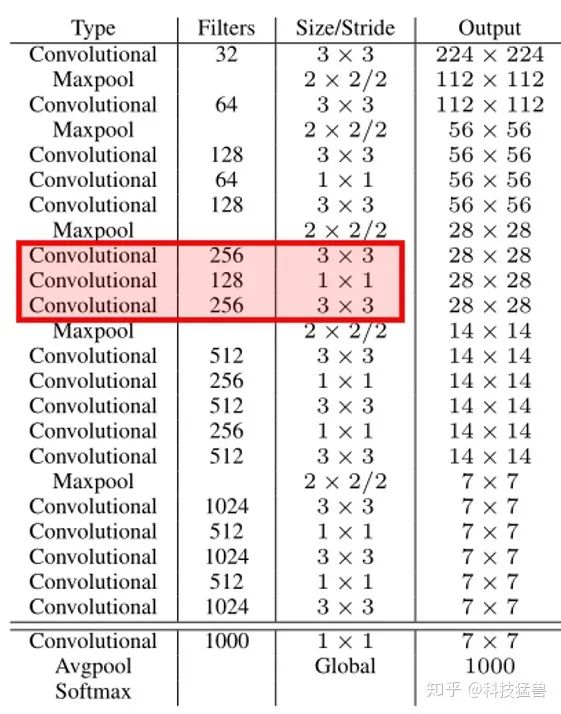
图4:darknet-19
仔细观察上面的backbone的结构(双横线上方),提出3个问题:
为什么没有 卷积了?只剩下了 卷积和 卷积了?
答:vgg net论文得到一个结论, 卷积可以用更小的卷积代替,且 卷积更加节约参数,使模型更小。
网络可以做得更深,更好地提取到特征。为什么?因为每做一次卷积,后面都会接一个非线性的激活函数,更深意味着非线性的能力更强了。所以,你可能以后再也见不到 卷积了。
另外还用了bottleneck结构(红色框):
卷积负责扩大感受野, 卷积负责减少参数量。
为什么没有FC层了?
答:使用了GAP(Global Average Pooling)层,把 映射为 ,满足了输入不同尺度的image的需求。你不管输入图片是 还是 ,最后都给你映射为 。
这对提高检测器的性能有什么作用呢?
对于小目标的检测,之前输入图片是固定的大小的,小目标很难被检测准确;现在允许多尺度输入图片了,只要把图片放大,小目标就变成了大目标,提高检测的精度。
为什么最后一层是softmax?
答:因为backbone网络darknet-19是单独train的,是按照分类网络去train的,用的数据集是imagenet,是1000个classes,所以最后加了一个softmax层,使用cross entropy loss。
接下来总结下YOLO v2的网络结构:
图4中的双横线的上半部分(第0-22层)为backbone,train的方法如上文。
后面的结构如下图5所示:
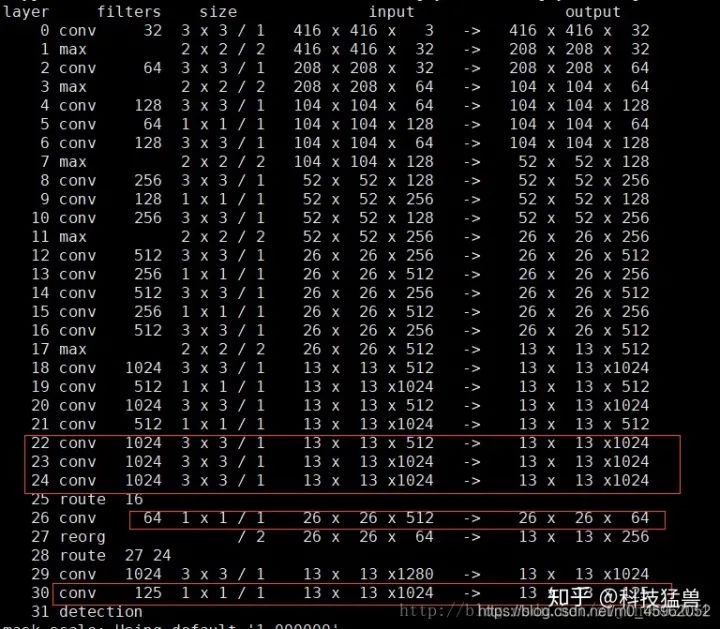
图5:YOLO v2网络结构
从第23层开始为检测头,其实是3个 3 * 3 * 1024 的卷积层。
同时增加了一个 passthrough 层(27层),最后使用 1 * 1 卷积层输出预测结果,输出结果的size为 。
route层的作用是进行层的合并(concat),后面的数字指的是合并谁和谁。
passthrough 层可以把 。
YOLO2 的训练主要包括三个阶段:
1、先在 ImageNet 分类数据集上预训练 Darknet-19,此时模型输入为 224 * 224 ,共训练 160 个 epochs。(为什么可以这样训练?因为有GAP)
2、将网络的输入调整为 448 * 448(注意在测试的时候使用 416 * 416 大小) ,继续在 ImageNet 数据集上 finetune 分类模型,训练 10 个 epochs。
3、修改 Darknet-19 分类模型为检测模型为图5形态,即:移除最后一个卷积层、global avgpooling 层以及 softmax 层,并且新增了3个 3 * 3 * 1024 卷积层,同时增加了一个 passthrough 层,最后使用 1 * 1 卷积层输出预测结果,并在检测数据集上继续finetune 网络。
注意这里图5有个地方得解释一下:第25层把第16层进行reorg,即passthrough操作,得到的结果为27层,再与第24层进行route,即concat操作,得到第28层。
可视化的图为:

图5:YOLO v2可视化结构
11 YOLO v3
先看下YOLO v3的backbone,如下图6所示:
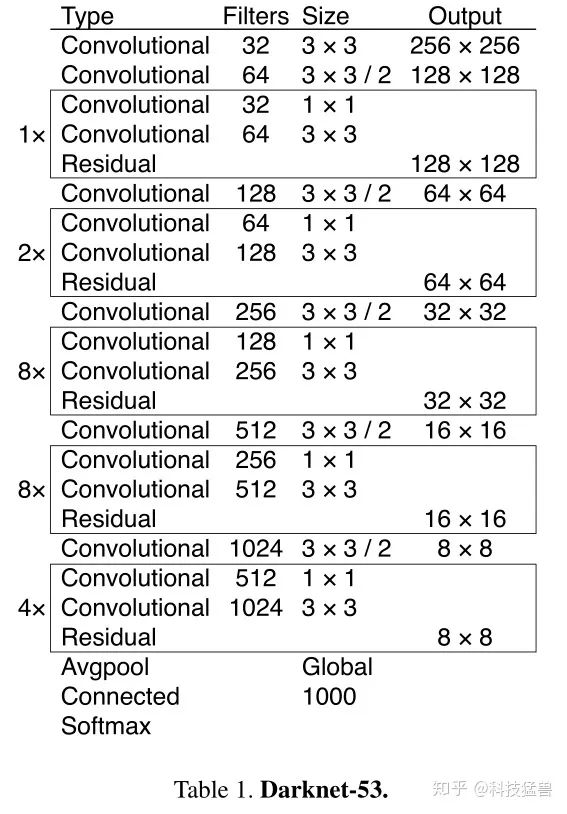
图6:YOLO v3 backbone
先声明下darknet 53指的是convolution层有52层+1个conv层把1024个channel调整为1000个,你会发现YOLO v2中使用的GAP层在YOLO v3中还在用,他还是在ImageNet上先train的backbone,
观察发现依然是有bottleneck的结构和残差网络。
为什么YOLO v3敢用3个检测头?因为他的backbone更强大了。
为什么更强大了?因为当时已经出现了ResNet结构。
所以YOLO v3的提高,有一部分功劳应该给ResNet。
再观察发现YOLO v3没有Pooling layer了,用的是conv(stride=2)进行下采样,为什么?
因为Pooling layer,不管是MaxPooling还是Average Pooling,本质上都是下采样减少计算量,本质上就是不更新参数的conv,但是他们会损失信息,所以用的是conv(stride = 2)进行下采样。
下图7是YOLO v3的网络结构:
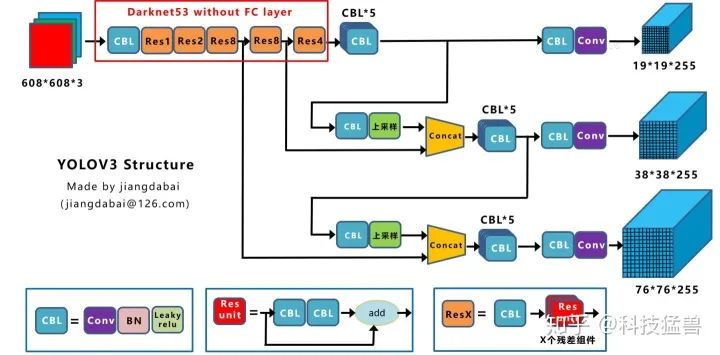
图7:YOLO v3 Structure
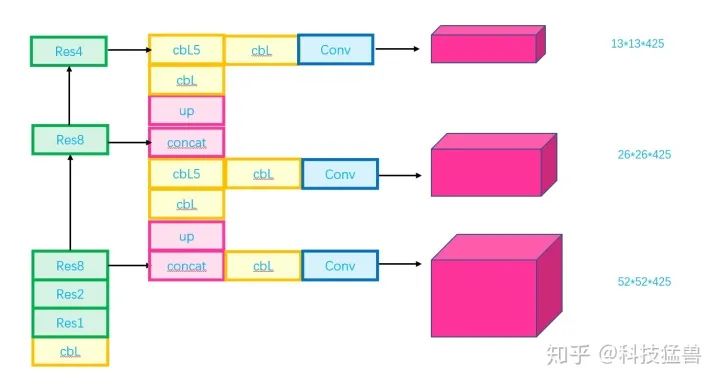
图8:YOLO v3 Structure
特征融合的方式更加直接,没有YOLO v2的passthrough操作,直接上采样之后concat在一起。
12 YOLO v4
图9和图10展示了YOLO v4的结构:
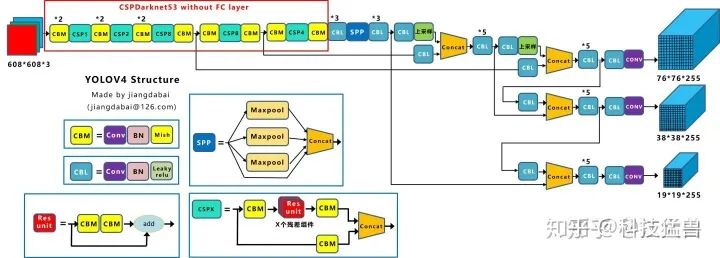
图9:YOLO v4 Structure
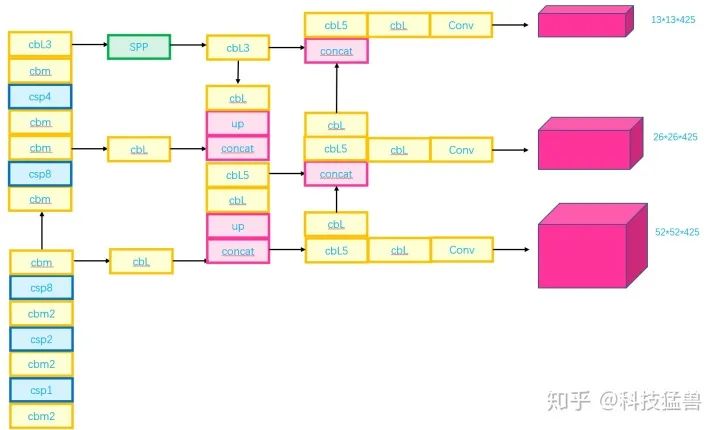
图10:YOLO v4 Structure
Yolov4的结构图和Yolov3相比,因为多了CSP结构,PAN结构,如果单纯看可视化流程图,会觉得很绕,不过在绘制出上面的图形后,会觉得豁然开朗,其实整体架构和Yolov3是相同的,不过使用各种新的算法思想对各个子结构都进行了改进。
Yolov4的五个基本组件:
CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
CSPX:借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
其他基础操作:
Concat:张量拼接,维度会扩充,和Yolov3中的解释一样,对应于cfg文件中的route操作。
add:张量相加,不会扩充维度,对应于cfg文件中的shortcut操作。
Backbone中卷积层的数量:
和Yolov3一样,再来数一下Backbone里面的卷积层数量。
每个CSPX中包含3+2*X个卷积层,因此整个主干网络Backbone中一共包含2+(3+2*1)+2+(3+2*2)+2+(3+2*8)+2+(3+2*8)+2+(3+2*4)+1=72。
输入端的改进:
YOLO v4对输入端进行了改进,主要包括数据增强Mosaic、cmBN、SAT自对抗训练,使得在卡不是很多时也能取得不错的结果。
这里介绍下数据增强Mosaic:

Mosaic数据增强
CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。
Yolov4的作者采用了Mosaic数据增强的方式。
主要有几个优点:
丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
cmBN的方法如下图:

cmBN的方法
13 YOLO v5
图11和图12展示了YOLO v5的结构:
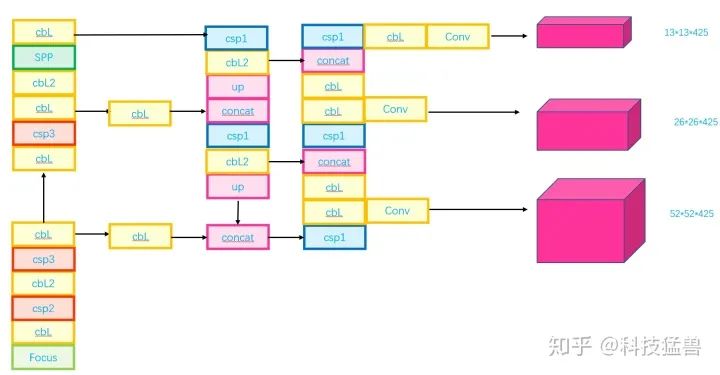
图11:YOLO v5 Structure
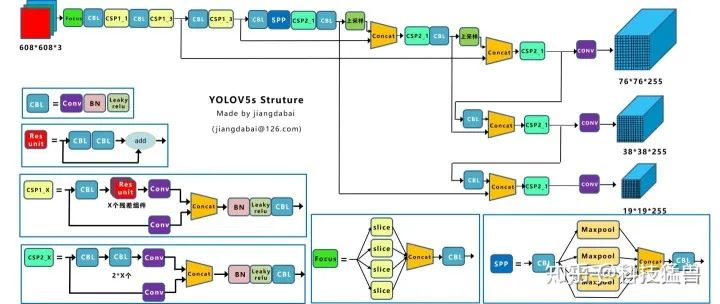
图12:YOLO v5 Structure
检测头的结构基本上是一样的,融合方法也是一样。
Yolov5的基本组件:
Focus:基本上就是YOLO v2的passthrough。
CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
CSP1_X:借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成。
CSP2_X:不再用Res unint模块,而是改为CBL。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合,如图13所示。
提特征的网络变短了,速度更快。YOLO v5的结构没有定下来,作者的代码还在持续更新。
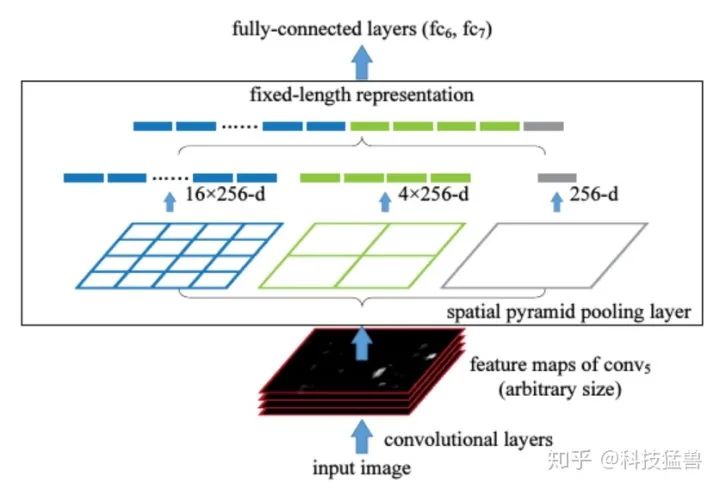
图13:SPP结构
Focus的slice操作如下图所示:
这里解释以下PAN结构是什么意思,PAN结构来自论文Path Aggregation Network,可视化结果如图15所示:
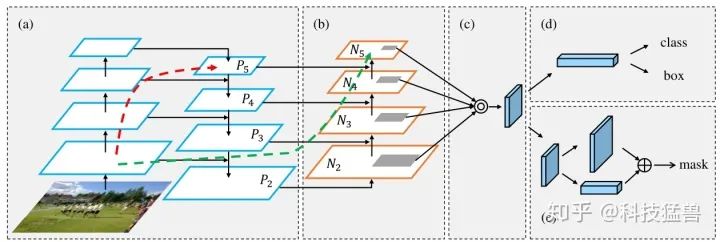
图15:PAN结构
可以看到包含了自底向上和自顶向下的连接,值得注意的是这里的红色虚线和绿色虚线:
FPN的结构把浅层特征传递给顶层要经历几十甚至上百层,显然经过这么多层的传递,浅层信息(小目标)丢失比较厉害。这里的红色虚线就象征着ResNet的几十甚至上百层。
自下而上的路径由不到10层组成,浅层特征经过FPN的laterial connection连接到 ,再经过bottom-up path augmentation连接到顶层,经过的层数不到10层,能较好地保留浅层的信息。这里的绿色虚线就象征着自下而上的路径的不到10层。
输入端的改进:
1.Mosaic数据增强,和YOLO v4一样。
2.自适应锚框计算:
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')设置成False,每次训练时,不会自动计算。
3.自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
比如Yolo算法中常用416*416,608*608等尺寸,比如对下面800*600的图像进行缩放:,如图15所示:

图15:Yolo算法的缩放填充
但Yolov5代码中对此进行了改进,也是Yolov5推理速度能够很快的一个不错的trick。
作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
因此在Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边,如图16所示:

图16:YOLO v5的自适应填充
图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。
通过这种简单的改进,推理速度得到了37%的提升,可以说效果很明显。
Yolov5中填充的是灰色,即(114,114,114),都是一样的效果,且训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
最后我们对YOLO series做个总体的比较,结束这个系列的解读:

YOLO v5 series的比较
部分图源:https://zhuanlan.zhihu.com/p/143747206
end
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~


智能推荐
HTML5标准学习 - 编码-程序员宅基地
文章浏览阅读60次。HTML5标准学习 - 编码 from:http://www.cnblogs.com/GrayZhang/archive/2011/04/11/learning-html5-charset.html相信每一个前端工程师都或多或少遇上过“乱码”这位仁兄,无论你的基...
AB压测工具的介绍及安装-程序员宅基地
文章浏览阅读1.9k次。今天我要和大家聊聊AB压测工具,如果你对网站性能测试感兴趣或有需要,那么这篇文章一定会帮到你。我曾经也因为缺少良好的压力测试工具而苦恼,直到我发现了AB压测工具。它可以帮助我们测试网站在高并发情况下的性能表现,让我们更好地了解网站的性能瓶颈和优化方向。接下来,我将为大家介绍AB压测工具的安装和使用方法,希望能够帮助大家更好地进行网站性能测试,提升网站的质量和用户体验。_ab压测工具
使用URL启动android默认浏览器,启动指定浏览器_scheme打开系统自带浏览器-程序员宅基地
文章浏览阅读847次。打开URL启动android默认浏览器,启动指定浏览器 分类: android2015-05-07 09:2718人阅读评论(0)收藏举报浏览器uri原文出自:http://blog.csdn.net/u013812046/article/details/39226515一、启动android默认浏览器 Intent intent _scheme打开系统自带浏览器
计算机网络学习建议_计算机网络课程设计的建议-程序员宅基地
文章浏览阅读863次,点赞2次,收藏2次。计算机网络+计算机网络课程设计这门课挺有意思,是真的有意思,知道一个网络具体是怎么运作,然后还能自己动手配置一个网络,观察一个数据包的流转过程,不过学校的课程不是那么全面,讲得不是那么浅显易懂,学完只是懂了一些老古董。除此之外,课程安排确实让人吐槽,连上四节课,一般上到第三节课就已经熄火了,听不进去。关于课程设计安排更是有问题,思科学院的东西,如此现代,如此浅显易懂,居然让我们用课设时间去看,最关键的是,课设只有四天,你要看完一本书,这是不切实际的,完完全全地浪费了那么好的课程,所以不建议的那么安排。_计算机网络课程设计的建议
第三章--第二篇--开放式对话系统_开放式对话不支持多轮-程序员宅基地
文章浏览阅读545次。概念:开放式对话系统是指一种可以与用户进行自由对话的系统,用户可以提出任意话题的问题或发表意见,而系统能够理解用户的输入并做出相应的回应。与任务导向的对话系统不同,开放式对话系统更注重与用户的自由互动,旨在模拟人类的对话能力和语言交流。目标:开放式对话系统的目标是实现自然、流畅、有趣的对话体验,使用户感到与真实人类对话类似。自然性:系统能够理解用户的语言表达,包括词汇、语法、语义等,并以自然、流畅的方式进行回应,使用户感到在与真人交谈。_开放式对话不支持多轮
个人网站制作源代码_个人网站源码-程序员宅基地
文章浏览阅读9.2k次。/ 01 /前话《周末·听雨》包含动态雨滴效果,采用Dreamweaver软件制作,代码结构简单,DIV+CSS布局,目录结构为index.html页面、js、css和images文件夹。/ 02 /图摘/ 03 /_个人网站源码
随便推点
<jsp:include page="" /> org.apache.jasper.JasperException: Unable to compile c-程序员宅基地
文章浏览阅读404次。[b]引入一个页面,出现如下异常:[/b] [code="java"] 2010-10-6 11:44:08 org.apache.catalina.core.ApplicationDispatcher invoke严重: Servlet.service() for servlet jsp threw exceptionorg.apache.jasper.JasperExcept..._exception: unable to compile expression "$.data": syntax error token recogni
Android5.0 WebView中Http和Https混合问题-程序员宅基地
文章浏览阅读981次。http://blog.csdn.net/luofen521/article/details/51783914http://blog.csdn.net/luofen521/article/details/51783914http://blog.csdn.net/luofen521/article/details/51783914场景复现:
Laravel微信静默登录教程_laravel 微信登录-程序员宅基地
文章浏览阅读252次。注:用户表字段必须有oppid & session_key。_laravel 微信登录
Resources (library) in JSF 2.0_outputscript-程序员宅基地
文章浏览阅读339次。In JSF 2.0, all your web resources files like css, images or JavaScript, should put in “resources” folder, under the root of your web application (same folder level with “WEB-INF“).The sub-folder under_outputscript
文本处理命令(增删改查文本)_grep 找到重复的字符,删除-程序员宅基地
文章浏览阅读402次。一、显示文本(一)more命令1.语法格式格式:more [选项] filename功能:读取filename中的内容,逐屏往下翻页显示,按h显示帮助,按q退出。2.选项-d, --silent display help instead of ringing bell-f, --logical count logical rather than screen lines-l, --no-pause suppress pause after form feed-c, --print-over do_grep 找到重复的字符,删除
Git忽略文件的几种方法,以及.gitignore文件的忽略规则_git 忽略-程序员宅基地
文章浏览阅读1.1w次,点赞7次,收藏37次。除了可以在项目中定义**.gitignore文件外,还可以设置全局的git .gitignore文件**来管理所有Git项目的行为。这种方式在不同的项目开发者之间是不共享的,是属于项目之上Git应用级别的行为。这种方式也需要创建相应的.gitignore文件,可以放在C:/Users/用户名/目录下。_git 忽略