Scrapy 安装介绍以及基本操作_怎么安装scrapy无pip-程序员宅基地
在写之前我们先来了解一下什么是Scrapy?
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求
Python3.6 Scrapy安装
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
第一种方法,windows安装
这种方式需要我们打开终端,步骤是windows+r,输入cmd回车进入终端
有时pip版本过于老旧不能使用,需要升级pip版本,输入pip install --upgrade pip回车,升级成功
安装scrapy命令:pip install Scrapy
直接使用命令安装不成功可以下载whl格式的包安装,安装whl格式包需要安装wheel库
输入:pip install wheel
安装完成后验证是否成功
scrapy的whl包地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/
搜索 scrapy
因为scrapy框架基于Twisted,所以先要下载其whl包安装
地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/
搜索 twisted 根据自己的版本下载
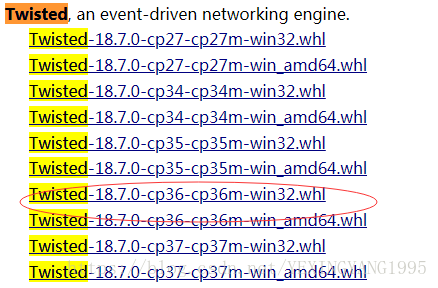
进行安装 xxxxxxxx是包的名字 进入whl包所在的路径,执行下面命令
pip install xxxxxxx.whl
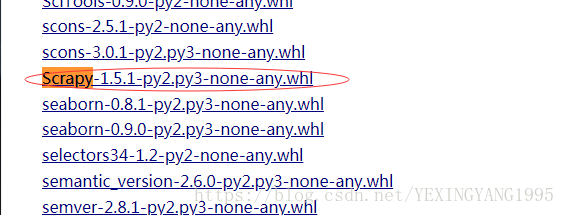
scrapy包使用相同的方式进行安装,进入所在目录,执行
pip install Scrapy‑1.5.1‑py2.py3‑none‑any.whl
第二种方法,利用anaconda安装scrapy框架
使用pip install 来安装scrapy需要安装大量的依赖库,这里我使用了Anaconda来安装scrapy,安装时只需要一条语句:conda install scrapy即可
安装Anaconda,在cmd窗口输入:conda install scrapy ,输入y回车表示允许安装依赖库
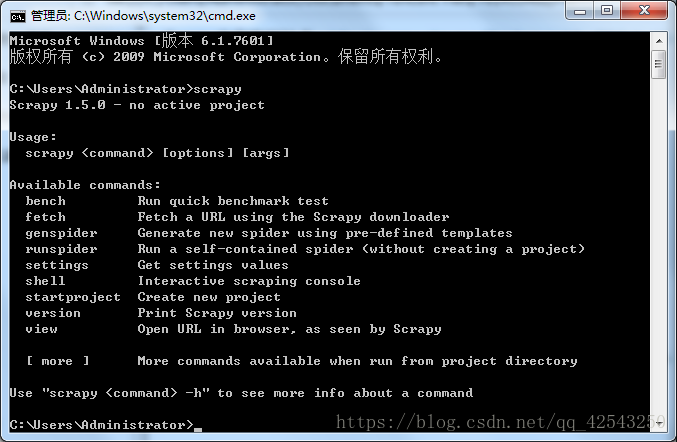
安装完成需要测试是否安装成功,在终端输入scrapy回车,如下图证明安装成功
scrapy 基本操作
安装成功后,在自己的pc工程里建一个文件
打开终端,输入cd 把工程里建的文件拖入 回车
提示下面结果 代表成功
二. Scrapy的基本用法
首先,在我们进行第一步——Scrapy的安装时,无论通过什么方式安装,都要进行验证,在验证时输入Scrapy命令后,会得到系统给出的类似于文档的提示,其中包括了Scrapy的可执行命令,即Available commands,具体如下图所示:

接下来我们通过建立一个简单的项目应用来了解这些命令的使用:
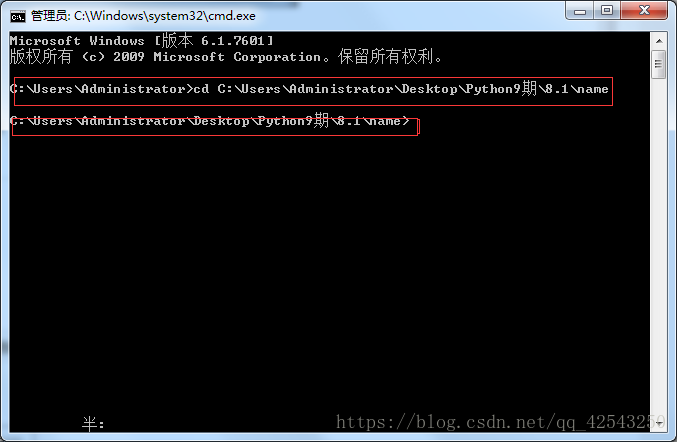
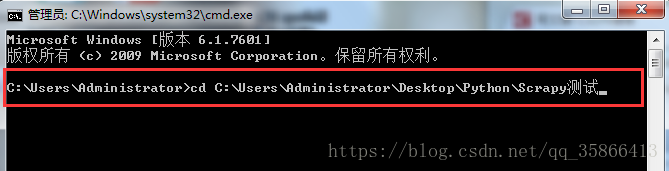
①. 在编译器PyCharm中新建一个文件夹“Scrapy测试”,然后在终端中输入: cd (注意cd后有一个空格),接着讲新建的文件夹拖入命令行,系统会自动补全该文件夹的完整路径,按下回车后就能进入该文件夹。
②. 在终端输入指令:scrapy startproject wxz 进行项目创建。scrapy startproject是创建项目的命令,后面跟的是项目名称。该指令执行后的结果如下图所示:
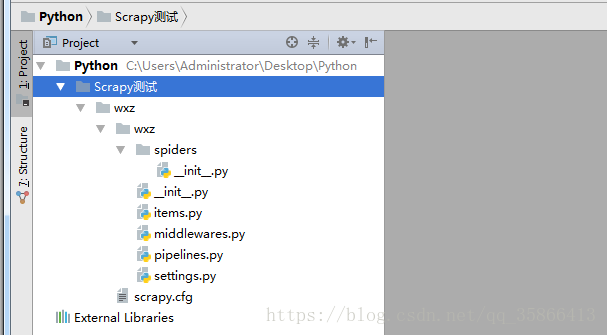
如图所示:Scrapy测试文件夹中,被创建几个文件夹和py文件,这就表示一个项目初步创建成功。
③. 通过cd命令进入wxz文件夹,命令为cd wxz
④. 再次输入cd命令,进入外层wxz文件夹中的wxz文件夹,为了快捷和减少出错,可以通过按“↑”键执行命令
⑤. 输入cd spiders , 进入spiders文件夹内
⑥. 在终端中输入scrapy genspider taobaoSpider baidu.com,这个命令是指定要爬取的网站的域名,命令格式为:scrapy genspider taobaoSpider + 目标网站的域名。执行效果如图所示:

至此,一个初步得scrapy项目就已经创建成功,下面我们了解一下这个框架的每个部分的功能:
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
三. 相关配置文件说明
在第二部分,我们初步创建了一步Scrapy项目,在自动创建的文件夹中,有着如图所示的几个文件:
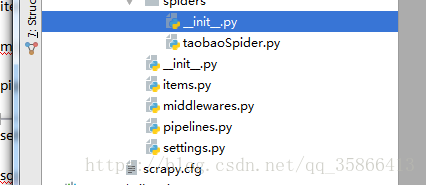
它们的作用分别是:
items.py:定义爬虫程序的数据模型
middlewares.py:定义数据模型中的中间件
pipelines.py:管道文件,负责对爬虫返回数据的处理
settings.py:爬虫程序设置,主要是一些优先级设置,优先级越高,值越小
scrapy.cfg:内容为scrapy的基础配置
值得注意的是,在学习阶段,我们要明白几点设置文件setting中的几处配置代码,它们影响着我们的爬虫的效率:
ROBOTSTXT_OBEY = True
这行代码意思是:是否遵守爬虫协议,学习阶段我们要改为False
-
SPIDER_MIDDLEWARES = { -
'wxz.middlewares.WxzSpiderMiddleware': 800, -
}
这里的数值越低,速度越快
四. 开始爬虫应用
在终端中输入:scrapy genspider 文件名 + 目标网站域名,比如本文所用的就是:scrapy genspider taobao_spider taobao.com

创建成功后,使用scrapy crawl taobao_spider命令,即可得到目标网站的源码:

以上便是Scrapy的安装和简单配置了,更多学习请关注我的博客更新。
智能推荐
Unity Shader - 水体交互_unity 水体-程序员宅基地
文章浏览阅读6.4k次,点赞10次,收藏87次。水体交互效果在游戏中是一个很常见的需求,这里简单实现一个可交互的水体。本篇文章主要是介绍水体交互的实现思路,水体的渲染这里就不再详细介绍,网上很多关于水体的渲染方法很多,可以自己百度、Google了解一下,这里不会过多提及。效果图。先放一张最终的GIF效果图!实现思路原理其实非常简单,就是通过粒子系统不断发射带有波纹法线贴图的面片,然后把这些法线渲染一张RenderTexture传输到Water Shader中,然后和Water Normal 叠加即可形成水波效果。实现步骤可以简单分为:简_unity 水体
SQL Server性能调教的小实验(2)-程序员宅基地
文章浏览阅读585次。上次说到当数据量提高之后,查询效率急剧下降,经过分析后,得到这个查询语句的效率是最低的。SELECT IDFROM Specimen_admin_specimen_TWHERE (Species_ID IN (SELECT DISTINCT (Species_ID) FROM View_All_Tree WHERE...
最少砝码—省赛java_两边砝码选择规律1 3 9 27-程序员宅基地
文章浏览阅读267次。十二届蓝桥杯省赛真题G题—砝码称重【问题描述】你有一架天平。现在你要设计一套砝码,使得利用这些砝码可以称出任意小于等于 N 的正整数重量。那么这套砝码最少需要包含多少个砝码?注意砝码可以放在天平两边。【输入格式】输入包含一个正整数 N。【输出格式】输出一个整数代表答案。【样例输入】7【样例输出】3【样例说明】3 个砝码重量是 1、4、6,可以称出 1 至 7 的所有重量。1 = 1;2 = 6 − 4 (天平一边放 6,另一边放 4);3 = 4 − 1;4 = 4;5_两边砝码选择规律1 3 9 27
数据录入界面的设计!!-程序员宅基地
文章浏览阅读1.3k次。最近设计了一个数据录入界面。在ACCESS中用VBA实现了,不知道在ASP.NET中应该如何实现?思路如下:1.根据相应的单据选择省份、商业单位,单击“开始录入”,激活下面的录入表格。2.在录入表格中选择地区、类别、商业名称、品名、规格后输入数量和发货日期。其中年份和月份、录入时间由系统自动生成。具体要求:1.省份、商业单位、地区等字段可以在组合框中选择,也可以直接输入,若输入的值在列表中存在,则..._收入预算基准数据录入功能界面
A2M人工智能与机器学习创新峰会参会感悟 by江舟_a2m峰会-程序员宅基地
文章浏览阅读937次。AI 研习社再前几周的时候,发文说能提供5张2018年A2M人工智能与机器学习创新峰会的门票,机缘巧合下,作为一个小小普通译者,我得到了门票一张,非常开心,于是在上周末(8月25-26日)就去听了下。 门票长下面这样(背后有两张午餐券) 现场是有3个会议厅,每个会议厅在当天上午或下午是进行同一个大主题下的不同的分享。门票上写着所有的会议题目,所以可以根据自己喜欢的自由搭配~ ..._a2m峰会
《通信工程》专业术语及其缩写大全_通信工程术语-程序员宅基地
文章浏览阅读1.5w次,点赞26次,收藏118次。此博客使用方法:点击“阅读更多”加载全文内容,ctrl键+F键,可呼出定位查找。缩写及其专业术语缩写 全称 释义 参考文献 6LoWPAN IPv6 over low-power wirelwss area networks 面向低功耗无线局域网的IPv6 AAL ATM adaptation layer ATM适配层 ..._通信工程术语
随便推点
TVS二极管(瞬变抑制)-程序员宅基地
文章浏览阅读1.8k次,点赞57次,收藏22次。TVS二极管通常可用于各种电子设备和系统中,如电源线路、通信接口、模拟输入输出、保险丝或保护管路、数据线保护等。它们具有快速响应、低残余电压和高能量吸收能力的特点,有效地保护设备免受静电击穿、雷击和电磁脉冲等瞬变电压的损害。TVS二极管(Transient Voltage Suppression Diode),也被称为瞬变抑制二极管,是一种用于保护电子设备和电路免受瞬变电压冲击的保护装置。
数据库_数据库员工编号数据类型-程序员宅基地
文章浏览阅读624次。数据库技术前言Q1.什么是数据库?存储数据的仓库Q2.常见的数据库有哪些?SQL server(微软)Access(微软)Oracle(甲骨文)Mysql(甲骨文)DB2(IBM)Kingbase(国产-人大金仓)Q3.哪些地方使用数据库?超市商品管理系统—商品信息银行管理系统—账户信息网上购物商场—商品信息和账..._数据库员工编号数据类型
Android——android:gravity 和 android:layout_Gravity-程序员宅基地
文章浏览阅读45次。LinearLayout有两个非常相似的属性:android:gravity与android:layout_gravity。他们的区别在于:android:gravity 属性是对该view中内容的限定.比如一个button 上面的text. 你可以设置该text 相对于view的靠左,靠右等位置.android:layout_gravity是用来设置该view相对与父view 的位置...
Python仿真优化与遗传算法_算法仿真实验可以使用python吗?-程序员宅基地
文章浏览阅读124次。Python提供了很多数值优化工具和算法,如scipy库、numpy库等,其中scipy库是一个强大的科学计算库,包括最优化、线性代数、统计分析等多个领域的功能,其中最优化模块提供了多种求解优化问题的算法,如Nelder-Mead、Powell、CG等,这些算法可以帮助用户求解各种优化问题,如非线性规划、函数拟合、曲线拟合等。在上述代码中,模拟了一个银行排队情景,有多个顾客到达银行,然后等待柜员服务,每个顾客的服务时间是1-3分钟,顾客的到达时间服从参数为5的指数分布。一、Python仿真优化。_算法仿真实验可以使用python吗?
SpringBoot Quartz 定时任务详解_springboot quartz standby shutdown-程序员宅基地
文章浏览阅读4.9k次。Quartz 简介在 JavaEE系统中,我们会经常用到定时任务,比如每天凌晨生成前天报表,每一小时生成汇总数据等等。我们可以使用java.util.Timer结合java.util.TimerTask来完成这项工作,但时调度控制非常不方便,并且我们需要大量的代码。使用Quartz框架无疑是非常好的选择,并且与Spring可以非常方便的集成,下面介绍它们集成方法和Cron表达式的详细介..._springboot quartz standby shutdown
hive函数之~reflect函数-程序员宅基地
文章浏览阅读1.6k次。reflect函数可以支持在sql中调用java中的自带函数,秒杀一切udf函数。使用java.lang.Math当中的Max求两列中最大值创建hive表create table test_udf(col1 int,col2 int) row format delimited fields terminated by ',';准备数据并加载数据cd /export/ser..._hive reflect