SAX解析与DOM解析_sax dom-程序员宅基地
前言
在Android中,解析xml文件比较常用的方法是Dom和SAX两种方式,简单对比以下这两种方式的优劣。
- DOM解析优点
1.XML树在内存中完整存储,因此可以直接修改其数据结构.
2.可以通过该解析器随时访问XML树中的任何一个节点.
3.DOM解析器的API在使用上也相对比较简单 - SAX解析优点
对内存的要求不高,它让开发人员自己来决定所要处理的标签.特别是当开发人员只需要处理文档中包含的部分数据时,SAX 这种扩展能力得到了更好的体现.
DOM缺点是需要将文件读到内存中,文件比较大时对内存要求高,其次它需要文件是层级结构的。SAX解析需要顺序执行,所以很难访问同一文档中的不同数据.此外,在基于该方式的解析编码程序也相对复杂.
SAX解析
sax解析需要继承DefaultHandler类,并且重写其中的几个方法。
public class MyHandler extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
}
@Override
public void endDocument() throws SAXException {
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
;
}
}
- startDocument()开始解析时调用,可以在里面完成一些容器的初始化等信息
- endDocument() 结束解析时调用,可以完成一些资源的释放。
- startElement()开始解析一个节点的时候调用,localName是节点名。
- endElement() 结束解析一个节点的时候调用。
- characters()解析节点的内容的时候调用。
这几个函数不必全部重写,根据需要即可,比较坑的是characters()函数,它在一个节点开始和结束都会调用,所以有时候会解析到一些换行等错误信息,需要加以控制,我的方法是在endElement时做一个标记。
下面看一个实例
xml_data
<?xml version="1.0" encoding="UTF-8"?>
<apps>
<app>
<id>1</id>
<name>google maps</name>
<veersion>1.0</veersion>
</app>
<app>
<id>2</id>
<name>Chrome</name>
<veersion>2.0</veersion>
</app>
</apps>
MyHandler类实现
public class MyHandler extends DefaultHandler {
private ArrayList<String> ids=new ArrayList<>();
private ArrayList<String> names = new ArrayList<>();
private ArrayList<String> versions=new ArrayList<>();
private String nodeName;
@Override
public void startDocument() throws SAXException {
Log.d("handler","开始解析");
super.startDocument();
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
switch(nodeName){
case "id": ids.add(new String(ch,start,length));break;
case "name":names.add(new String(ch,start,length));break;
case "version":versions.add(new String(ch,start,length));break;
}
}
@Override
public void endDocument() throws SAXException {
super.endDocument();
Log.d("handler","结束解析");
for (int i = 0; i < ids.size(); i++) {
Log.d("handler","id: "+ids.get(i)+" name: "+names.get(i)+" version: "+versions.get(i));
}
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
// 做一个标记,让结束的节点不被 characters函数处理
nodeName = "";
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// 记录当前节点的名字
nodeName = localName;
}
}
获取XMLParese实例开始解析
try{
// 获得一个xmlReader实例
XMLReader xmlReader= SAXParserFactory.newInstance().newSAXParser().getXMLReader();
// 设置内容解析器
xmlReader.setContentHandler(new MyHandler());
// 传入内容开始解析
xmlReader.parse(new InputSource(new StringReader(xmlData)));
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
DOM解析
DOM解析方式是将xml文档解析成一个对象的集合,利用树这种数据结构保存xml的全部信息,从而可以实现随机访问任何一个节点的过程,因为需要将xml文件的全部信息存储到内存中,所以对内存的要求比较高,在xml较大的时候转换速度也较慢,但是其随机访问的特性还是很好用的。
以之前的xml文件为例
<?xml version="1.0" encoding="UTF-8"?>
<apps>
<app>
<id>1</id>
<name>google maps</name>
<version>1.0</version>
</app>
<app>
<id>2</id>
<name>Chrome</name>
<version>2.0</version>
</app>
</apps>
转换后的结构
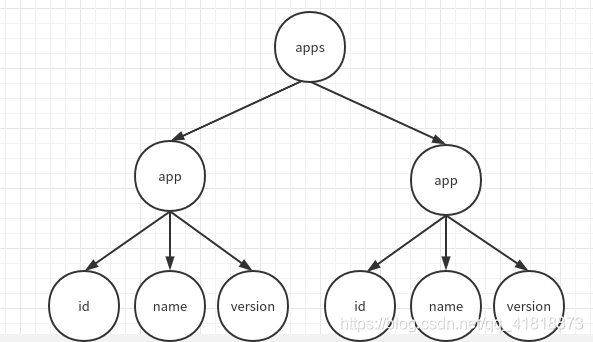 创建一个dom解析器的过程一般如下
创建一个dom解析器的过程一般如下
- 创建一个DocumentBuilderFactory实例
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
- 创建一个DocumentBuilder对象
DocumentBuilder builder=factory.newDocumentBuilder();
- 建立Document对象
Document doc=builder.parse(path);
- 查找节点或者其他操作
Nodelist nl=doc.getElementByTagName("apps");
节点类型
- Node
- Element
Document常用方法
| 方法 | 返回类型 | 作用 |
|---|---|---|
| getElementByTagName(String tagname) | NodeList | 获得指定名称的node集合 |
| createElement(String tagName) | Element | 创建一个指定名称的节点 |
| createTextNode(String data) | Text | 创建一个文本内容节点 |
| createAttribute(String name) | Attr | 创建一个节点属性 |
Node节点常用方法
| 方法 | 返回类型 | 作用 |
|---|---|---|
| getFirstChild() | Node | 获取该节点的第一个子节点 |
| getLastChild() | Node | 获取该节点的最后一个子节点 |
| getNodeValue() | String | 获取节点的内容 |
| getChildNodes | NodeList | 获取全部子节点 |
| hasChildNodes() | boolean | 判断是否还有子节点 |
| appendChild(Node newChild) | Node | 在当前节点下增加一个新的节点 |
NodeList常用方法
| 方法 | 返回值 | 作用 |
|---|---|---|
| getLength() | int | 获取节点的个数 |
| item(index) | Node | 根据节点获得节点对象 |
下面看一个例子
// factory
DocumentBuilderFactory facotory = DocumentBuilderFactory.newInstance();
// documentBuilder
DocumentBuilder builder = facotory.newDocumentBuilder();
// document
Document document = builder.parse(new ByteArrayInputStream(xmlData.getBytes()));
// nodelists
NodeList list=document.getElementsByTagName("app");
for (int i=0;i<list.getLength();i++){
Element e= (Element) list.item(i);
Log.d("dom","id : "+e.getElementsByTagName("id").item(0).getFirstChild().getNodeValue());
Log.d("dom","name: "+e.getElementsByTagName("name").item(0).getFirstChild().getNodeValue());
}
注意
Document document = builder.parse(path));
这里经常会报一个错误
err:java.net.MalformedURLException: no protocol: <?xml version="1.0" encoding="UTF-8"?>
应该是因为输入的字符串或者是文件路径的编码问题导致的,可以按照例子中方式转换一下,或者指定编码转换
new ByteArrayInputStream(xmlData.getBytes("UTF-8"))
智能推荐
python3基础知识复习 -- IO编程(文件操作,OS模块,格式化)_python3 io-程序员宅基地
文章浏览阅读345次。python3基础知识复习 -- IO编程(文件操作,OS模块,格式化)_python3 io
SQL注入【SQLi-LABS Page-1(Basic Challenges Less1-Less22)】_sqli-labs-page-1(basic challenges)-程序员宅基地
文章浏览阅读1.7k次,点赞7次,收藏14次。本篇博客用于记录`SQLi`实验中第一阶段,即基础的`sql`注入,包括了GET和POST联合注入、时间盲注、布尔盲注、报错盲注、文件上传注入等并且内含一些笔者写的自动化注入代码~_sqli-labs-page-1(basic challenges)
2008-2020年全国各省劳动生产率_31省劳动生产率-程序员宅基地
文章浏览阅读1.2k次。2008-2020年各省劳动生产率_31省劳动生产率
PHPExcel导出excel打开失败_phpspreadsheet生成的excel文件,office打不开-程序员宅基地
文章浏览阅读502次。PHPExcel文件导出打不开_phpspreadsheet生成的excel文件,office打不开
print语句使输出不自动换行-程序员宅基地
文章浏览阅读1k次。python 2: 在print语句最后加一个逗号即可实现 例如:print 1,2,python 3: 可在输出最后添加 end ='' ,即使用end的内容作为最后结束的符号,print在不手动设置end时,默认设置为‘\n'换行,所以只用print也可表示为换行,当然end中也可设置为其他值,如图: ..._js print()不换行
Linux Kernel线性映射代码分析_kernel 线性映射-程序员宅基地
文章浏览阅读34次。在Linux Kernel启动过程中,会根据物理内存的大小以及虚拟内存空间大小,决定线性映射区间的大小。在ARM64架构中,由于虚拟地址空间足够大,正常情况下都会对memory建立线性映射,有的也叫直接映射。本文主要是走读线性映射的代码。_kernel 线性映射
随便推点
Python学习:python time模块之time.mktime()_time.mktime()函数的作用-程序员宅基地
文章浏览阅读1w次,点赞3次,收藏16次。mktime()函数定义mktime()是 localtime() 的反函数。参数是 struct_time 或者完整的 9 元组,它表示 local 的时间,而不是 UTC 。返回一个浮点数,可以与 time() 兼容。如果输入值不能表示为有效时间,则 OverflowError 或 ValueError 将被引发(这取决于Python或底层C库是否捕获到无效值)。它可以生成时间的最早日期取决于平台。mktime()用法代码块import timeprint(time.localtime()_time.mktime()函数的作用
UVAlive6807 Túnel de Rata (最小生成树)-程序员宅基地
文章浏览阅读102次。题意题目链接Sol神仙题Orz我们考虑选的边的补集,可以很惊奇的发现,这个补集中的边恰好是原图中的一颗生成树;并且答案就是所有边权的和减去这个边集中的边的权值;于是我们只需要求最大生成树就好了;#include<bits/stdc++.h>using namespace std;const int MAXN = 2e6 + 10, INF = 1e9 +..._h - t煤nel de rata
实现Android手机中隐藏App图标_app 隐藏图标检测-程序员宅基地
文章浏览阅读2.6k次。在AndroidManifest中application节点下面intent-filter里面加入下面语句 android:host="MainActivity" android:scheme="com.zhangton.monitor" />android:scheme后面的是包名_app 隐藏图标检测
集成学习(ensemble learning)-程序员宅基地
文章浏览阅读2.7k次。文章目录一 引言二 Bagging三 Boosting参考一 引言集成学习(ensemble learning),它通过将多个学习器集成在一起来达到学习的目的。主要是将有限的模型相互组合,其名称有时也会有不同的叫法,有时也会被称为多分类器系统(multi-classifier system)、委员会学习(committee learning)。【1】集成学习利用一些方法改变原始训练样本的分布,构建多个不同的学习者器,然后将这些学习器组合起来完成学习任务,集成学习可获得比单一学习器显著优越的泛化性能,_集成学习
Javaweb环境搭建_搭建javaweb开发环境-程序员宅基地
文章浏览阅读7.5k次,点赞18次,收藏116次。目录一,Java Web介绍二,安装Java运行环境1.Java虚拟机(JVM)2.工具(1)如何下载编译器:(2)点击Download Pakeges(3)选择所需要的版本和系统(4)点击"select Another Mirror"展开选项chain(5)进入到支付界面,支付可选可不选,不支付可直接点击click here直接下载3.JDK的安装4.配置环境变量三,搭建Java web环境1.什么是Tomcat?(1)外界部署Tomcat..._搭建javaweb开发环境
毕业设计-最新计算机专业毕业设计选题推荐及源码下载(安卓app,Android,微信小程序,javaweb)不断更新中-程序员宅基地
文章浏览阅读1k次,点赞26次,收藏19次。毕业设计-基于Android的校园跳蚤市场二手物品交易系统源码下载毕业设计-基于Android的的计步器社交平台系统源码下载毕业设计基于Android的飞机票预定航班系统源码下载 基于Android的社区居家养老服务APP的设计系统源码下载基于Android的论坛校园论坛BBS的设计与实现源码下载基于android的医院挂号预约智慧医疗app资源-毕业设计-基于Android的手机商城app系统源码基于android的推理游戏源码信息下载资源基于Android的医护查房系统app源码下载基于Android的