Vision Transformer详解-程序员宅基地
技术标签: ViT 图像分类 Transformer 深度学习
论文名称: An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
论文下载链接:https://arxiv.org/abs/2010.11929
原论文对应源码:https://github.com/google-research/vision_transformer
Pytorch实现代码: pytorch_classification/vision_transformer
Tensorflow2实现代码:tensorflow_classification/vision_transformer
在bilibili上的视频讲解:https://www.bilibili.com/video/BV1Jh411Y7WQ
文章目录
前言
Transformer最初提出是针对NLP领域的,并且在NLP领域大获成功。这篇论文也是受到其启发,尝试将Transformer应用到CV领域。关于Transformer的部分理论之前的博文中有讲,链接,这里不在赘述。通过这篇文章的实验,给出的最佳模型在ImageNet1K上能够达到88.55%的准确率(先在Google自家的JFT数据集上进行了预训练),说明Transformer在CV领域确实是有效的,而且效果还挺惊人。
模型详解
在这篇文章中,作者主要拿ResNet、ViT(纯Transformer模型)以及Hybrid(卷积和Transformer混合模型)三个模型进行比较,所以本博文除了讲ViT模型外还会简单聊聊Hybrid模型。
Vision Transformer模型详解
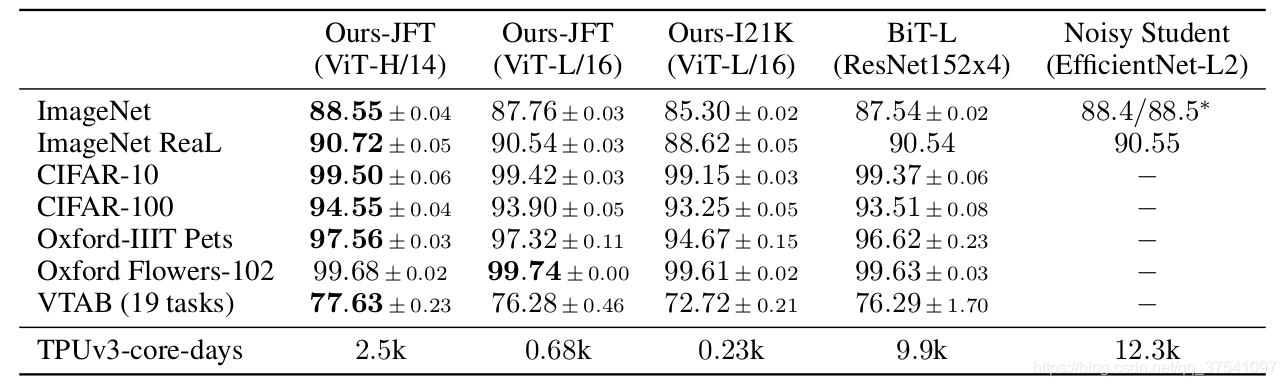
下图是原论文中给出的关于Vision Transformer(ViT)的模型框架。简单而言,模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)
Embedding层结构详解
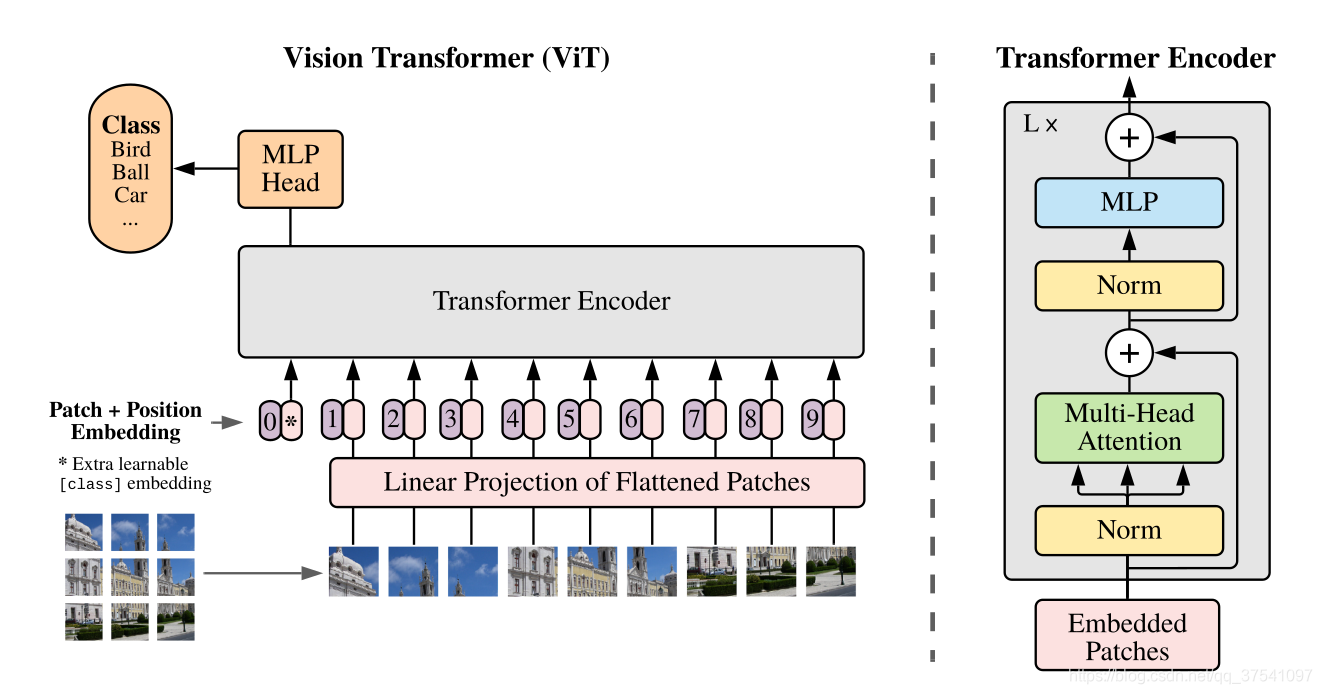
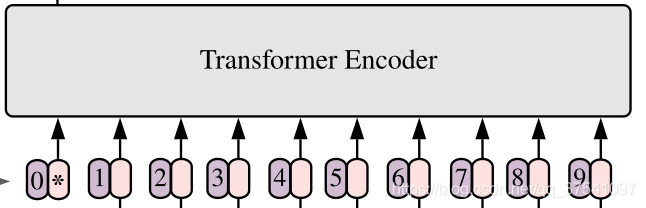
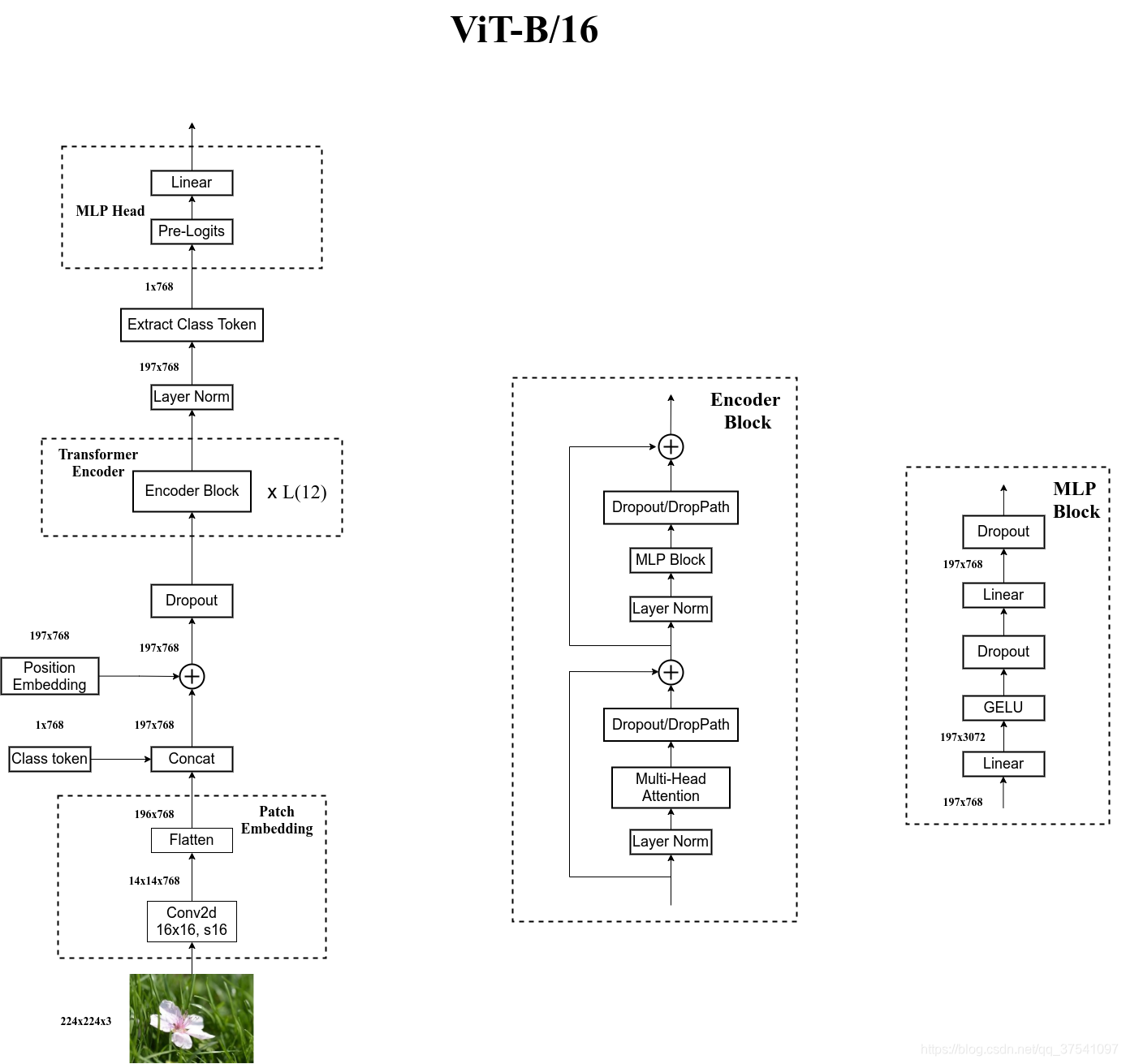
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9对应的都是向量,以ViT-B/16为例,每个token向量长度为768。
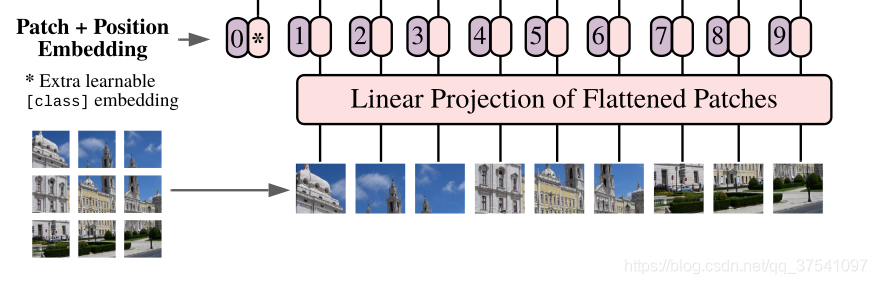
对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到 ( 224 / 16 ) 2 = 196 (224/16)^2=196 (224/16)2=196个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding。 在原论文中,作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。然后关于Position Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。
对于Position Embedding作者也有做一系列对比试验,在源码中默认使用的是1D Pos. Emb.,对比不使用Position Embedding准确率提升了大概3个点,和2D Pos. Emb.比起来没太大差别。
Transformer Encoder详解
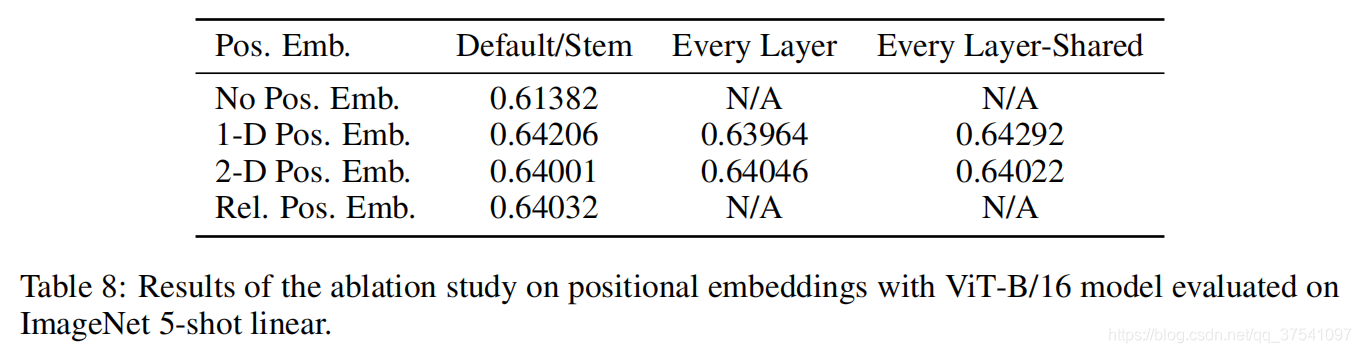
Transformer Encoder其实就是重复堆叠Encoder Block L次,下图是我自己绘制的Encoder Block,主要由以下几部分组成:
- Layer Norm,这种Normalization方法主要是针对NLP领域提出的,这里是对每个token进行Norm处理,之前也有讲过Layer Norm不懂的可以参考链接
- Multi-Head Attention,这个结构之前在讲Transformer中很详细的讲过,不在赘述,不了解的可以参考链接
- Dropout/DropPath,在原论文的代码中是直接使用的Dropout层,在但
rwightman实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。 - MLP Block,如图右侧所示,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍
[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
MLP Head详解
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。注意,在Transformer Encoder后其实还有一个Layer Norm没有画出来,后面有我自己画的ViT的模型可以看到详细结构。这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
自己绘制的Vision Transformer网络结构
为了方便大家理解,我自己根据源代码画了张更详细的图(以ViT-B/16为例):
Hybrid模型详解
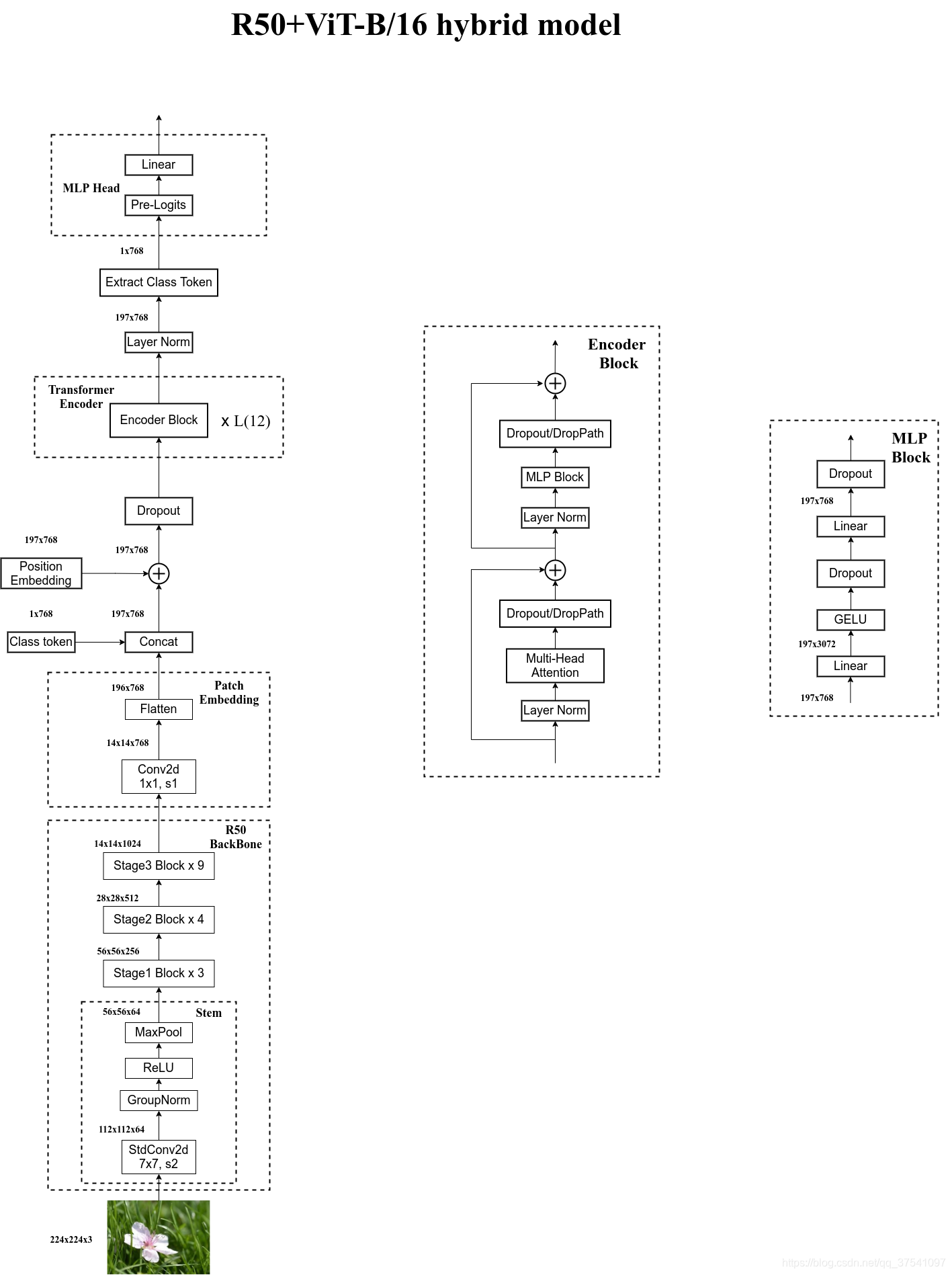
在论文4.1章节的Model Variants中有比较详细的讲到Hybrid混合模型,就是将传统CNN特征提取和Transformer进行结合。下图绘制的是以ResNet50作为特征提取器的混合模型,但这里的Resnet与之前讲的Resnet有些不同。首先这里的R50的卷积层采用的StdConv2d不是传统的Conv2d,然后将所有的BatchNorm层替换成GroupNorm层。在原Resnet50网络中,stage1重复堆叠3次,stage2重复堆叠4次,stage3重复堆叠6次,stage4重复堆叠3次,但在这里的R50中,把stage4中的3个Block移至stage3中,所以stage3中共重复堆叠9次。
通过R50 Backbone进行特征提取后,得到的特征矩阵shape是[14, 14, 1024],接着再输入Patch Embedding层,注意Patch Embedding中卷积层Conv2d的kernel_size和stride都变成了1,只是用来调整channel。后面的部分和前面ViT中讲的完全一样,就不在赘述。
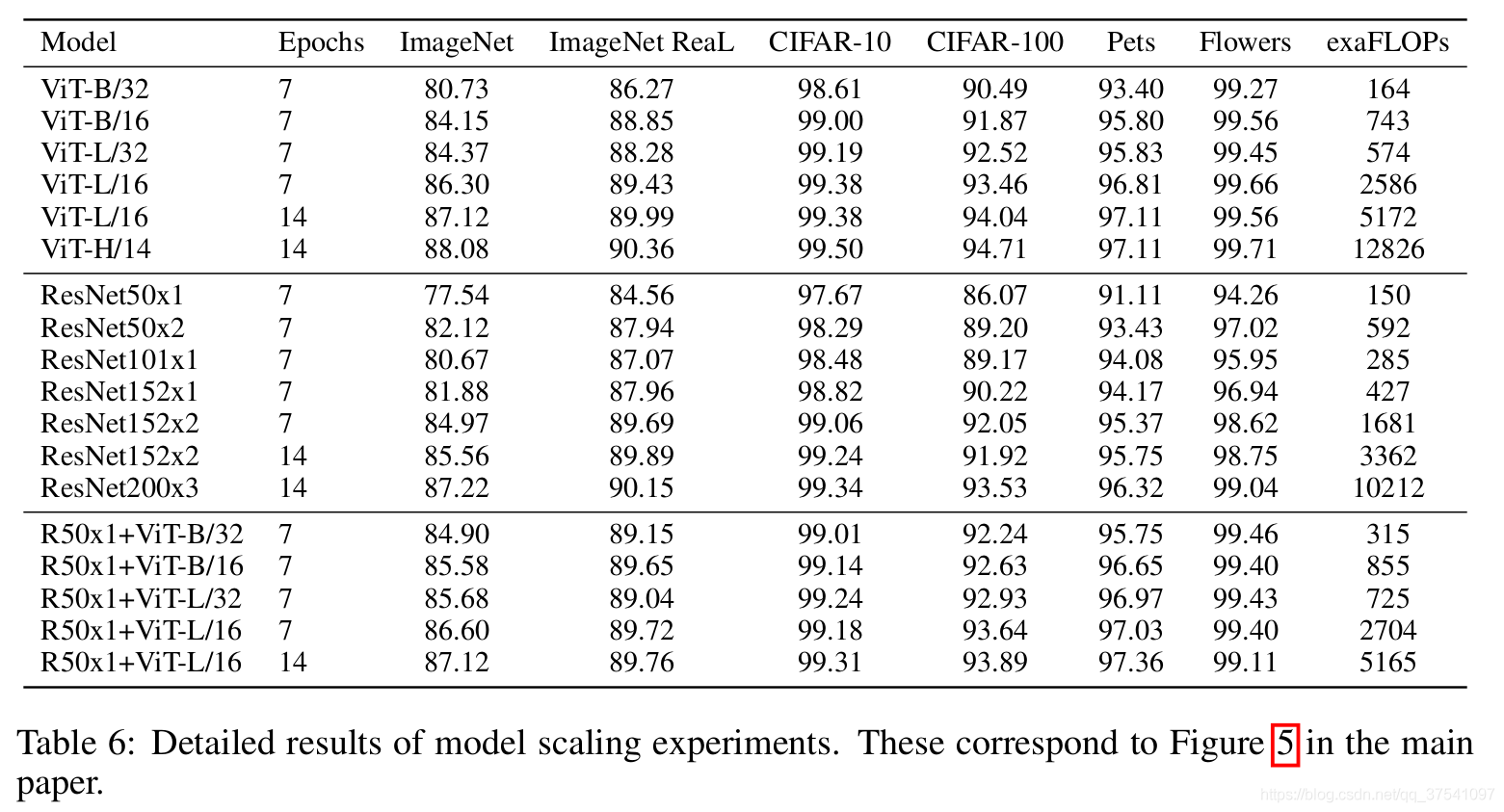
下表是论文用来对比ViT,Resnet(和刚刚讲的一样,使用的卷积层和Norm层都进行了修改)以及Hybrid模型的效果。通过对比发现,在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid。
ViT模型搭建参数
在论文的Table1中有给出三个模型(Base/ Large/ Huge)的参数,在源码中除了有Patch Size为16x16的外还有32x32的。其中的Layers就是Transformer Encoder中重复堆叠Encoder Block的次数,Hidden Size就是对应通过Embedding层后每个token的dim(向量的长度),MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍),Heads代表Transformer中Multi-Head Attention的heads数。
| Model | Patch Size | Layers | Hidden Size D | MLP size | Heads | Params |
|---|---|---|---|---|---|---|
| ViT-Base | 16x16 | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 16x16 | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 14x14 | 32 | 1280 | 5120 | 16 | 632M |
智能推荐
【SeedLab】BGP Exploration and Attack Lab_bgp seed-程序员宅基地
文章浏览阅读2.3k次。本实验需要使用SEED互联网仿真器(已集成到docker配置文件)。启动docker容器,配置文件在/Labsetup/outputs/目录下。由于要配置很多docker容器,所以构建+启动过程会比较漫长。.随着docker启动,仿真器也随之运行,仿真器所用到的设备均为docker容器。..._bgp seed
元素选择器之排除特定元素_input排他选择器-程序员宅基地
文章浏览阅读2.1k次。 需求如下:该搜索框是对整个页面的input检索 ,但与弹出层中的input冲突 博主几经辗转 简单处理 解决问题,思路如下:排除掉特定class的input。代码如下:$('input:not(.pop)', this.footer()).on('keyup change', function () { if (that.search() !== th..._input排他选择器
使用JAXB进行XML与JavaBean的转换(支持泛型)_jaxb 泛型-程序员宅基地
文章浏览阅读5.6k次,点赞6次,收藏20次。看到别人有个1024的勋章,特意留了一篇在今年的10.24日,看看会不会获得。在日常开发中可能涉及接口之间的相互调用,虽然在现在微服务的理念推广下,很多公司都采用轻量级的JSON格式做为序列化的格式,但是不乏有些公司还是有一些XML格式的报文,最近就在对接某个合作方的时候遇到了XML报文。在JSON报文爽快的转换下很难试用一个一个的拿报文参数,还是希望能直接将报文转换成Bean。接下来就了解到..._jaxb 泛型
python numpy学习笔记_ndarray的位置-程序员宅基地
文章浏览阅读1.2k次。numpy的主要数据对象是多维数组,其中包含相同类型的元素,通常是数字类型,每个元素都有一个索引。使用numpy前通常要导入包。import numpy as np目录类型维度创建运算索引和切片类型numpy的数组被称为ndarray。numpy.array只处理一维数组,而ndarray对象才提供更多功能。a = np.array([[1, 2, 3], [4, 5, 6]])type(a) # <class 'numpy.ndarray'>dtype属性可以获得元素的数_ndarray的位置
我的世界java版gamemode指令_《我的世界》Java版常用指令代码大全!你想要的都在这里了!...-程序员宅基地
文章浏览阅读1.6w次。还在苦于网上找到的一些指令已经不适用了吗?还在苦于有些地方的指令有误吗?还在苦于有些地方整理的指令不够全面吗?那么你来对地方了!小编为大家整理了《我的世界》原版游戏常用的指令,这些基本足以满足各位的基本需求了!大家来一起看看吧!注:表示的是必须输入的部分,[方括号]表示的是可选择性输入的部分基本命令列表命令描述/?/help的替代命令,提供命令使用帮助。/ban + 玩家名字将玩家加入封禁列表。/..._gamemode指令java
Spring Boot 结合shiro做第三方登录验证_shiro 第三方token登录-程序员宅基地
文章浏览阅读1.5w次,点赞3次,收藏3次。Spring Boot 结合shiro做第三方登录验证1、首先,说一下我的具体实现思路。在做spring boot拦截器的过程中,开始我准备用spring security来实现,但是研究了一段时间之后发现spring security的集成度太高,需要修改的东西比较多,而且对它本身的使用方法不是很了解,后来转而使用Apache shiro。由于是第三方登录,是不需要我来验证密码的。最开始,我陷入了_shiro 第三方token登录
随便推点
代码报错原因和处理方法-程序员宅基地
文章浏览阅读8.7k次。代码错误的原因和调试方法_代码报错
深度解析Java游戏服务器开发-程序员宅基地
文章浏览阅读5.2k次,点赞9次,收藏40次。---恢复内容开始---1.认识游戏 1.1什么是游戏 1.1.1游戏的定义 任何人类正常生理需求之外的活动均可称为游戏 1.1.2游戏的分类 RPG角色扮演游戏、ACT动作游戏、AVG冒险游戏、FPS第一人称视角射击游戏、TPS第三人称视角射击游戏、FTG格斗游戏、SPT体育游戏、RAC竞速游戏、RTS即时战略游戏、STG..._深度解析java游戏服务器开发
【ThinkPHP5初体验(二)1】CSRF防范原理(thinkphp5 CSRF ajax令牌)_tp5 开启csrf令牌-程序员宅基地
文章浏览阅读4k次。CSRF是什么我就不解释了,百度一搜全是,比波姐的片源还要多,千篇一律都他么是复制粘贴。那为什么这个令牌(token)操作可以防范CSRF呢?下面我就随便说说说错了大家不要介意。首先我们要知道令牌是存储在session里面的,这个很重要 php代码如下<?php namespace app\index\controller; //我直接允许跨域,因为伪装..._tp5 开启csrf令牌
市盈率、市净率、净资产收益率股息率介绍-程序员宅基地
文章浏览阅读1.7k次,点赞2次,收藏6次。市盈率PE市盈率 = 市值/净利润概念解析:买入一家公司,几年回本,年化收益率:净利润/市值(市盈率的倒数)举例:砖头10万买个砖头,每年拍人带来1万利润,需要10年回本市盈率:10/1 = 10年化收益率:1/10 = 10%市净率PB市净率 = 市值/净资产净资产 = 总资产 - 负债举例:张三便利店,净资产:120万市值:1..._净资产收益率和股息率
墨器杯垫 文创商品设计特优_杯垫文创设计说明-程序员宅基地
文章浏览阅读737次。教育部昨举行「102年国立馆所文创商品设计比赛」颁奖典礼,台北科技大学创新设计研究所硕士生谢镇宇,为TW艺术教育馆设计「墨器」杯垫,取「默契」谐音,用5片压克力板,展现水墨画层层渲染效果,增加立体视觉感受,并在杯架后方加入LED光源,获评审肯定夺特优奖和奖金10万元。台南应用科技大学商品设计系学生高郁翔,为国立自然科学博物馆设计「恐龙化石钉书机」,他认为小朋友把钉书机钉下去的那一刻,会觉得像暴龙準_杯垫文创设计说明
C#中关于XML与对象,集合的相互转换-程序员宅基地
文章浏览阅读404次。XML与对象,集合的相互转化 今天小伙伴在群里问了一下关于XML与对象之间的相互转换,作为菜鸟的我正好趁着闲着的时间学习了一波,直接上代码了,有疑问或者有错误的地方还请大家指正,谢谢。。。。 1 using System; 2 using System.Collections.Generic; 3 using System.IO; 4 using System...._c# xml转集合